足足68个!Python函数合集请收好!
内置函数就是python给你提供的, 拿来直接用的函数,比如print.,input等。
#68个内置函数
# abs() dict() help() min() setattr()
# all() dir() hex() next() slice()
# any() divmod() id() object() sorted()
# ascii() enumerate() input() oct() staticmethod()
# bin() eval() int() open() str()
# bool() exec() isinstance() ord() sum()
# bytearray() filter() issubclass() pow() super()
# bytes() float() iter() print() tuple()
# callable() format() len() property() type()
# chr() frozenset() list() range() vars()
# classmethod() getattr() locals() repr() zip()
# compile() globals() map() reversed() __import__()
# complex() hasattr() max() round()
# delattr() hash() memoryview() set()
和数字相关
1. 数据类型
-
bool : 布尔型(True,False)
-
int : 整型(整数)
-
float : 浮点型(小数)
-
complex : 复数
2. 进制转换
-
bin() 将给的参数转换成二进制
-
otc() 将给的参数转换成八进制
-
hex() 将给的参数转换成十六进制
print(bin(10)) # 二进制:0b1010
print(hex(10)) # 十六进制:0xa
print(oct(10)) # 八进制:0o12
3. 数学运算
-
abs() 返回绝对值
-
divmode() 返回商和余数
-
round() 四舍五入
-
pow(a, b) 求a的b次幂, 如果有三个参数. 则求完次幂后对第三个数取余
-
sum() 求和
-
min() 求最小值
-
max() 求最大值
print(abs(-2)) # 绝对值:2
print(divmod(20,3)) # 求商和余数:(6,2)
print(round(4.50)) # 五舍六入:4
print(round(4.51)) #5
print(pow(10,2,3)) # 如果给了第三个参数. 表示最后取余:1
print(sum([1,2,3,4,5,6,7,8,9,10])) # 求和:55
print(min(5,3,9,12,7,2)) #求最小值:2
print(max(7,3,15,9,4,13)) #求最大值:15
和数据结构相关
1. 序列
(1)列表和元组
-
list() 将一个可迭代对象转换成列表
-
tuple() 将一个可迭代对象转换成元组
print(list((1,2,3,4,5,6))) #[1, 2, 3, 4, 5, 6]
print(tuple([1,2,3,4,5,6])) #(1, 2, 3, 4, 5, 6)
(2)相关内置函数
-
reversed() 将一个序列翻转, 返回翻转序列的迭代器
-
slice() 列表的切片
lst = "你好啊"
it = reversed(lst) # 不会改变原列表. 返回一个迭代器, 设计上的一个规则
print(list(it)) #['啊', '好', '你']
lst = [1, 2, 3, 4, 5, 6, 7]
print(lst[1:3:1]) #[2,3]
s = slice(1, 3, 1) # 切片用的
print(lst[s]) #[2,3]
(3)字符串
- str() 将数据转化成字符串
print(str(123)+'456') #123456format() 与具体数据相关, 用于计算各种小数, 精算等.
s = "hello world!"
print(format(s, "^20")) #剧中
print(format(s, "<20")) #左对齐
print(format(s, ">20")) #右对齐
# hello world!
# hello world!
# hello world!
print(format(3, 'b' )) # 二进制:11
print(format(97, 'c' )) # 转换成unicode字符:a
print(format(11, 'd' )) # ⼗进制:11
print(format(11, 'o' )) # 八进制:13
print(format(11, 'x' )) # 十六进制(⼩写字母):b
print(format(11, 'X' )) # 十六进制(大写字母):B
print(format(11, 'n' )) # 和d⼀样:11
print(format(11)) # 和d⼀样:11print(format(123456789, 'e' )) # 科学计数法. 默认保留6位小数:1.234568e+08
print(format(123456789, '0.2e' )) # 科学计数法. 保留2位小数(小写):1.23e+08
print(format(123456789, '0.2E' )) # 科学计数法. 保留2位小数(大写):1.23E+08
print(format(1.23456789, 'f' )) # 小数点计数法. 保留6位小数:1.234568
print(format(1.23456789, '0.2f' )) # 小数点计数法. 保留2位小数:1.23
print(format(1.23456789, '0.10f')) # 小数点计数法. 保留10位小数:1.2345678900
print(format(1.23456789e+3, 'F')) # 小数点计数法. 很大的时候输出INF:1234.567890
- bytes() 把字符串转化成bytes类型
bs = bytes("今天吃饭了吗", encoding="utf-8")
print(bs) #b'\xe4\xbb\x8a\xe5\xa4\xa9\xe5\x90\x83\xe9\xa5\xad\xe4\xba\x86\xe5\x90\x97'bytearray() 返回一个新字节数组. 这个数字的元素是可变的, 并且每个元素的值得范围是[0,256)ret = bytearray("alex" ,encoding ='utf-8')
print(ret[0]) #97
print(ret) #bytearray(b'alex')
ret[0] = 65 #把65的位置A赋值给ret[0]
print(str(ret)) #bytearray(b'Alex')
-
ord() 输入字符找带字符编码的位置
-
chr() 输入位置数字找出对应的字符
-
ascii() 是ascii码中的返回该值 不是就返回u
print(ord('a')) # 字母a在编码表中的码位:97
print(ord('中')) # '中'字在编码表中的位置:20013print(chr(65)) # 已知码位,求字符是什么:A
print(chr(19999)) #丟for i in range(65536): #打印出0到65535的字符print(chr(i), end=" ")print(ascii("@")) #'@'
- repr() 返回一个对象的string形式
s = "今天\n吃了%s顿\t饭" % 3
print(s)#今天# 吃了3顿 饭
print(repr(s)) # 原样输出,过滤掉转义字符 \n \t \r 不管百分号%
#'今天\n吃了3顿\t饭'
2. 数据集合
-
字典:dict 创建一个字典
-
集合:set 创建一个集合
frozenset() 创建一个冻结的集合,冻结的集合不能进行添加和删除操作。
3. 相关内置函数
-
len() 返回一个对象中的元素的个数
-
sorted() 对可迭代对象进行排序操作 (lamda)
**语法:**sorted(Iterable, key=函数(排序规则), reverse=False)
-
Iterable: 可迭代对象
-
key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数. 根据函数运算的结果进行排序
-
reverse: 是否是倒叙. True: 倒叙, False: 正序
lst = [5,7,6,12,1,13,9,18,5]
lst.sort() # sort是list里面的一个方法
print(lst) #[1, 5, 5, 6, 7, 9, 12, 13, 18]ll = sorted(lst) # 内置函数. 返回给你一个新列表 新列表是被排序的
print(ll) #[1, 5, 5, 6, 7, 9, 12, 13, 18]l2 = sorted(lst,reverse=True) #倒序
print(l2) #[18, 13, 12, 9, 7, 6, 5, 5, 1]
#根据字符串长度给列表排序
lst = ['one', 'two', 'three', 'four', 'five', 'six']
def f(s):return len(s)
l1 = sorted(lst, key=f, )
print(l1) #['one', 'two', 'six', 'four', 'five', 'three']
- enumerate() 获取集合的枚举对象
lst = ['one','two','three','four','five']
for index, el in enumerate(lst,1): # 把索引和元素一起获取,索引默认从0开始. 可以更改print(index)print(el)
# 1
# one
# 2
# two
# 3
# three
# 4
# four
# 5
# five
-
all() 可迭代对象中全部是True, 结果才是True
-
any() 可迭代对象中有一个是True, 结果就是True
print(all([1,'hello',True,9])) #True
print(any([0,0,0,False,1,'good'])) #True
- zip() 函数用于将可迭代的对象作为参数, 将对象中对应的元素打包成一个元组, 然后返回由这些元组组成的列表. 如果各个迭代器的元素个数不一致, 则返回列表长度与最短的对象相同
lst1 = [1, 2, 3, 4, 5, 6]
lst2 = ['醉乡民谣', '驴得水', '放牛班的春天', '美丽人生', '辩护人', '被嫌弃的松子的一生']
lst3 = ['美国', '中国', '法国', '意大利', '韩国', '日本']
print(zip(lst1, lst1, lst3)) #<zip object at 0x00000256CA6C7A88>
for el in zip(lst1, lst2, lst3):print(el)
# (1, '醉乡民谣', '美国')
# (2, '驴得水', '中国')
# (3, '放牛班的春天', '法国')
# (4, '美丽人生', '意大利')
# (5, '辩护人', '韩国')
# (6, '被嫌弃的松子的一生', '日本')
- fiter() 过滤 (lamda)
语法 : fiter(function. Iterable)
function: 用来筛选的函数. 在filter中会自动的把iterable中的元素传递给function. 然后根据function返回的True或者False来判断是否保留留此项数据 , Iterable: 可迭代对象
def func(i): # 判断奇数return i % 2 == 1lst = [1,2,3,4,5,6,7,8,9]
l1 = filter(func, lst) #l1是迭代器
print(l1) #<filter object at 0x000001CE3CA98AC8>
print(list(l1)) #[1, 3, 5, 7, 9]
- map() 会根据提供的函数对指定序列列做映射(lamda)
语法 : map(function, iterable)
可以对可迭代对象中的每一个元素进行映射. 分别去执行 function
def f(i): return i
lst = [1,2,3,4,5,6,7,]
it = map(f, lst) # 把可迭代对象中的每一个元素传递给前面的函数进行处理. 处理的结果会返回成迭代器print(list(it)) #[1, 2, 3, 4, 5, 6, 7]
和作用域相关
-
locals() 返回当前作用域中的名字
-
globals() 返回全局作用域中的名字
def func():a = 10print(locals()) # 当前作用域中的内容print(globals()) # 全局作用域中的内容print("今天内容很多")
func()
# {'a': 10}
# {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__':
# <_frozen_importlib_external.SourceFileLoader object at 0x0000026F8D566080>,
# '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins'
# (built-in)>, '__file__': 'D:/pycharm/练习/week03/new14.py', '__cached__': None,
# 'func': <function func at 0x0000026F8D6B97B8>}
# 今天内容很多
和迭代器、生成器相关
-
range() 生成数据
-
next() 迭代器向下执行一次, 内部实际使⽤用了__ next__()⽅方法返回迭代器的下一个项目
-
iter() 获取迭代器, 内部实际使用的是__ iter__()⽅方法来获取迭代器
for i in range(15,-1,-5):print(i)
# 15
# 10
# 5
# 0
lst = [1,2,3,4,5]
it = iter(lst) # __iter__()获得迭代器
print(it.__next__()) #1
print(next(it)) #2 __next__()
print(next(it)) #3
print(next(it)) #4
字符串类型代码的执行
-
eval() 执行字符串类型的代码. 并返回最终结果
-
exec() 执行字符串类型的代码
-
compile() 将字符串类型的代码编码. 代码对象能够通过exec语句来执行或者eval()进行求值
s1 = input("请输入a+b:") #输入:8+9
print(eval(s1)) # 17 可以动态的执行代码. 代码必须有返回值
s2 = "for i in range(5): print(i)"
a = exec(s2) # exec 执行代码不返回任何内容# 0
# 1
# 2
# 3
# 4
print(a) #None# 动态执行代码
exec("""
def func():print(" 我是周杰伦")
""" )
func() #我是周杰伦
code1 = "for i in range(3): print(i)"
com = compile(code1, "", mode="exec") # compile并不会执行你的代码.只是编译
exec(com) # 执行编译的结果
# 0
# 1
# 2code2 = "5+6+7"
com2 = compile(code2, "", mode="eval")
print(eval(com2)) # 18code3 = "name = input('请输入你的名字:')" #输入:hello
com3 = compile(code3, "", mode="single")
exec(com3)
print(name) #hello
输入输出
-
print() : 打印输出
-
input() : 获取用户输出的内容
print("hello", "world", sep="*", end="@") # sep:打印出的内容用什么连接,end:以什么为结尾
#hello*world@
内存相关
hash() : 获取到对象的哈希值(int, str, bool, tuple). hash算法:(1) 目的是唯一性 (2) dict 查找效率非常高, hash表.用空间换的时间 比较耗费内存
s = 'alex'
print(hash(s)) #-168324845050430382lst = [1, 2, 3, 4, 5]
print(hash(lst)) #报错,列表是不可哈希的id() : 获取到对象的内存地址s = 'alex'
print(id(s)) #2278345368944
文件操作相关
- open() : 用于打开一个文件, 创建一个文件句柄
f = open('file',mode='r',encoding='utf-8')
f.read()
f.close()
模块相关
- __ import__() : 用于动态加载类和函数
# 让用户输入一个要导入的模块
import os
name = input("请输入你要导入的模块:")
__import__(name) # 可以动态导入模块
帮助
- help() : 函数用于查看函数或模块用途的详细说明
print(help(str)) #查看字符串的用途
调用相关
- callable() : 用于检查一个对象是否是可调用的. 如果返回True, object有可能调用失败, 但如果返回False. 那调用绝对不会成功
a = 10
print(callable(a)) #False 变量a不能被调用
#
def f():print("hello")print(callable(f)) # True 函数是可以被调用的
查看内置属性
- dir() : 查看对象的内置属性, 访问的是对象中的__dir__()方法
print(dir(tuple)) #查看元组的方法
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
点击免费领取《CSDN大礼包》:Python入门到进阶资料 & 实战源码 & 兼职接单方法 安全链接免费领取

相关文章:
足足68个!Python函数合集请收好!
内置函数就是python给你提供的, 拿来直接用的函数,比如print.,input等。 #68个内置函数 # abs() dict() help() min() setattr() # all() dir() hex() next() sli…...

vue2.0 打包,nginx部署
1、修改这里为空 否则报错:vue is undefined 2、修改为hash,重点:打包dist文件运行,必须这样 3、安装ngnix,重点:使用node的包:httpserve,失败 4、重点:配置代理转发 前端…...

微服务架构之路1,服务如何拆分?使用微服务的注意事项?
目录 一、前言二、单体服务的弊端三、微服务化四、服务如何拆分?五、使用微服务的注意事项1、服务如何定义2、服务如何发布和订阅3、服务如何监控4、服务如何治理5、故障如何定位 大家好,我是哪吒。 一、前言 微服务已经是Java开发的必备技能ÿ…...

解决Mac电脑音乐显示歌名的乱码问题
最近想听「万能青年旅店」的歌,结果在Mac电脑的「音乐」里面打开后是乱码。 【原因】(求助于chatGPT) 乱码问题可能是由于MP3文件的元数据(比如歌曲名、艺术家、专辑等信息)的编码问题导致的。如果这些信息是用非标准的或者不兼容的字符编码…...

赢在电商设计!2024年最新电商设计实战技巧盘点
双十一、双十二、黑五的电商大促即将轮番将至,电商运营人迎来大忙季,选品、直播、采购入库、售后……各种环节都是影响电商转化的关键因素,而电商设计作为打通这些环节,打造高转化率电商平台的关键要素,能够吸引用户注…...

约数之和 (普通快速幂求逆元做法)
假设现在有两个自然数 A 和 B,S 是 AB 的所有约数之和。 请你求出 Smod9901 的值是多少。 输入格式 在一行中输入用空格隔开的两个整数 A 和 B 。 输出格式 输出一个整数,代表 Smod9901 的值。 数据范围 0≤A,B≤5107 输入样例: …...

每日一题(LeetCode)----二分查找(三)
每日一题(LeetCode)----二分查找(三) 1.题目(69. x 的平方根 ) 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 **注意…...

使用 TensorFlow FasterRCNN 网络进行目标检测
目录 描述 此示例的工作原理 处理输入图形 数据准备 sampleUffFasterRCNN 插件 验证输出 TensorRT API 层和操作 TensorRT API 层和操作 先决条件 运行示例 示例 --help 选项 附加资源 许可 变更记录 已知问题 本示例,sampleUffFasterRCNN࿰…...

数据结构——顺序表(SeqList)
目录 1. 顺序表介绍 2. 顺序表工程 2.1 顺序表定义 2.1.1 静态顺序表 2.1.2 动态顺序表 2.2顺序表接口 2.2.1 顺序表初始化 2.2.2 顺序表打印 2.2.3 顺序表销毁 2.2.4 顺序表数据插入 2.2.4.1 容量检查 2.2.4.2 顺序表尾插 2.2.4.3 顺序表头插 2.2.4.4 顺序表随机…...

Uni-App 快捷登录
uniapp 实现一键登录前置条件: 开通uniCloud, 开通一键登录功能参考的文档 : 官网 - 一键登录uniapp指南 : https://uniapp.dcloud.net.cn/univerify.html#%E6%A6%82%E8%BF%B0 官网 - 一键登录开通指南 : https://ask.dcloud.net.cn/article/37965 官网 - unicloud使用指南 htt…...

DbUtils + Druid 实现 JDBC 操作 --- 附BaseDao
文章目录 Apache-DBUtils实现CRUD操作1 Apache-DBUtils简介2 主要API的使用2.1 DbUtils2.2 QueryRunner类2.3 ResultSetHandler接口及实现类 3 JDBCUtil 工具类编写3.1 导包3.2 编写配置文件3.3 编写代码 4 BaseDao 编写 Apache-DBUtils实现CRUD操作 1 Apache-DBUtils简介 com…...

css:元素居中整理水平居中、垂直居中、水平垂直居中
目录 1、水平居中1.1、行内元素1.2、块级元素 2、垂直居中2.1、单行文字2.2、多行文字2.3、图片垂直居中 3、水平垂直居中参考文章 1、水平居中 1.1、行内元素 行内元素(比如文字,span,图片等)的水平居中,其父元素中…...

从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型
从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型 一、config文件解读二、开始训练三、数据集分析四、ncnn部署 从零开始的目标检测和关键点检测(一):用labelme标注数据集 从零开始的目标检测…...

React18新特性?
文章目录 前言Automatic BatchingTransitionsSuspenseNew Hooks后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:react.js 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。…...
筹码博弈K线长阳选股公式,穿越筹码密集区
普通K线是由最高价、开盘价、最低价、收盘价四个价格构成的,而博弈K线是以这个四个价格对应的获利盘构成K线,反映筹码的获利情况。把鼠标移动到K线上,停留在对应的价格,就可以在右侧的筹码分布图看到相应的获利盘数据。࿰…...
)
微服务设计模式-架构真题(六十八)
UNIX的源代码控制工具(Source Code control System,SCCS)是项目开发中常用的()。 源代码静态分析工具文档分析工具版本控制工具再工程工具 答案:C 解析: SCCS是版本控制工具 网闸的描述错误的是()。 双…...

LeetCode----52. N 皇后 II
题目 n 皇后问题 研究的是如何将 n 个皇后放置在 n n 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。 示例 1: 输入:n = 4 输出:2 解释:如上图所示,4 皇后问题存在两个不同的解法。 示例 2: 输入:n = …...
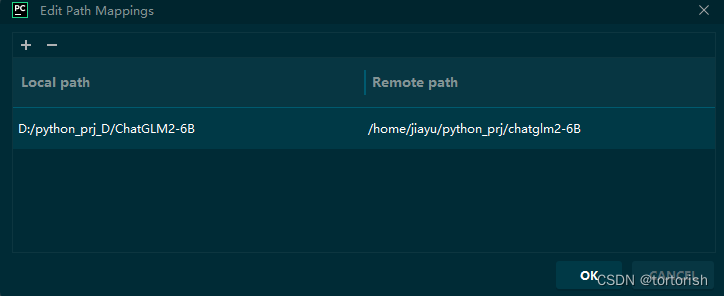
解决pycharm中,远程服务器上文件找不到的问题
一、问题描述 pycharm中,当我们连接到远程服务器上时。编译器中出现报错问题: cant open file /tmp/OV2IRamaar/test.py: [Errno 2] No such file or directory 第二节是原理解释,第三节是解决方法。 二、原理解释 实际上这是由于我们没有设置…...

虹科荣誉 | 喜讯!虹科成功入选“广州首届百家新锐企业”!!
文章来源:虹科品牌部 阅读原文:虹科荣誉 | 喜讯!虹科成功入选“广州首届百家新锐企业”!! 近日,由中共广州市委统战部、广州市工商业联合会、广州市工业和信息化局、广州市人民政府国有资产监督管理委员会…...

如何利用Jmeter从0到1做一次完整的压测?这2个步骤很关键!
压测,在很多项目中都有应用,是测试小伙伴必备的一项基本技能,刚好最近接手了一个小游戏的压测任务,一轮压测下来,颇有收获,赶紧记录下来,与大家分享一下,希望大家能少踩坑。 一、压…...

终极指南:掌握WinPmem Windows内存取证采集核心技术
终极指南:掌握WinPmem Windows内存取证采集核心技术 【免费下载链接】WinPmem The multi-platform memory acquisition tool. 项目地址: https://gitcode.com/gh_mirrors/wi/WinPmem WinPmem作为Windows平台物理内存采集的标杆工具,为安全分析师和…...

FF14副本动画跳过插件终极指南:3分钟告别冗长等待
FF14副本动画跳过插件终极指南:3分钟告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 你是否曾在《最终幻想14》国服副本中,看着那些无法跳过的动画感到无比焦虑&…...

如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰
如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为本地音乐播放时没有歌词而烦恼吗&am…...

告别Keil/MDK!用Clion+插件打造STM32的现代化开发工作流
从Keil到Clion:STM32开发者的现代化工作流迁移指南 当稚晖君在B站展示他用Clion开发STM32的流畅体验时,整个嵌入式社区都为之震动。那个视频像一束光,照进了我们这些常年与Keil/MDK为伴的开发者世界——原来嵌入式开发可以如此优雅。但兴奋之…...

Jenkins 安装Publish over SSH插件远程发布执行shell脚本
1.在jenkins安装Publish over SSH插件,在Manage Jenkins–Plugins–Available plugins中搜索Publish over SSH,然后安装即可。2.安装成功以后,需要到系统设置DashBoard—Manage Jenkins—System中进行配置,如图 可以通过密码链接也…...

正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置
正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置 当工程师在ABAQUS中遇到材料刚度矩阵非正定警告时,往往意味着仿真结果可能失去物理意义。这种警告背后隐藏着深刻的张量数学原理——正定张量的性质直接决定了材料本构模型的稳…...
)
从碰撞到安全路径:在MATLAB里为你的机械臂规划一条无碰撞轨迹(附完整代码)
七轴机械臂无碰撞轨迹规划实战:从MATLAB基础到高级避障策略 机械臂在复杂环境中的自主运动一直是工业自动化和服务机器人领域的核心挑战。想象一下,当一台七轴机械臂需要在布满障碍物的空间里精准抓取物品时,如何确保它不会撞上周围的工作台、…...

雀巢冰淇淋在华投资的首家冰淇淋工厂迎来成立40周年 | 美通社头条
、美通社消息:近日,雀巢冰淇淋华南生产基地 —— 广州冷冻食品有限公司迎来成立40周年。该工厂是雀巢冰淇淋在华投资的首家冰淇淋工厂,陪伴一代代华南消费者成长的经典甜筒、飞鱼脆皮等产品皆出自广冻厂。1986年,在改革开放的时代…...

别再只调图表了!用Vue+Echarts做大屏,这5个布局与性能优化技巧才是关键
VueEcharts大屏实战:从布局到性能优化的进阶指南 当数据可视化大屏成为企业展示核心指标的标准配置,开发者们逐渐从"能实现功能"转向追求"极致体验"。本文将分享五个鲜少被系统总结的实战技巧,这些经验来自多个千万级PV项…...
——将两个不同影像系列的影像通过join联合在一起并获取统一的时间)
Google Earth Engine(GEE)——将两个不同影像系列的影像通过join联合在一起并获取统一的时间
想组合 2 个从 Modis 数据中填补空白的图像集合。但是它们没有相同的系统时间或相同的系统索引。像下面的照片是 2 个图像集合的不同属性。 才能给每个图像一个系统时间,它可以匹配 2 个图像集合? 本次用到的函数: 代码: 联接函数 ee.Join.inner(primaryKey, secondary…...