深入理解网络IO复用并发模型
本文主要介绍服务端对于网络并发模型以及Linux系统下常见的网络IO复用并发模型。文章内容一共分为两个部分。
第一部分主要介绍网络并发中的一些基本概念以及我们Linux下常见的原生IO复用系统调用(epoll/select)等。第二部分主要介绍并发场景下常见的网络IO复用模型,以及各自的优缺点。
一、网络并发模型中的几个基本概念
1 流
开发过程中,一般给流的定义有很多种,这里面我们总结用三个特征来描述一个流的定义:
(1)可以进行I/O操作的内核对象。
(2)传输媒介可以是文件、管道、套接字等。
(3)数据的入口是通过文件描述符(fd)。
2 I/O操作
其实所有对流的读写操作,都可以称之为IO操作,如图1.1.2所示,是向一个已经满的流再去执行写入操作,那么这次的写入实际上就是一个IO操作。当然已经将流写满了,那么这次写入就会发生阻塞。

图1.1 传输媒介已满,再写入的IO操作
那么如果流为空的情况,再执行读操作,那么这次读取也是一个IO操作,也依然会发生阻塞的情况。

如图1.1和图1.2所示,他们都是对IO的操作,当我们向一个容量已经满的传输媒介写数据的时候,那么这个IO操作就会发生写阻塞。同理,当我们从一个容量为空的传输媒介读数据的时候,这个IO操作就会发生读阻塞。
3 阻塞等待
通过IO的读写过程,我们得到了阻塞的概念。那么我们如何来形象地表示一个阻塞的现象呢?

图1.3 阻塞等待
如图1.3所示,假设您今天清闲在家无事可做,您家里有一部座机,这个是您唯一可以和外界建立沟通的媒介。假设您今天准备洗一双袜子,但是缺少一块肥皂,这个肥皂在等待快递员给您送过来,而您又是一个“单细胞动物”,今天必须要先把袜子洗完才能做其他的事,否则无事可做。那么此时您的这种在一天的生活流程中因等待某个资源导致生活节奏暂停的状态,就是阻塞等待状态。
4 非阻塞,忙轮询
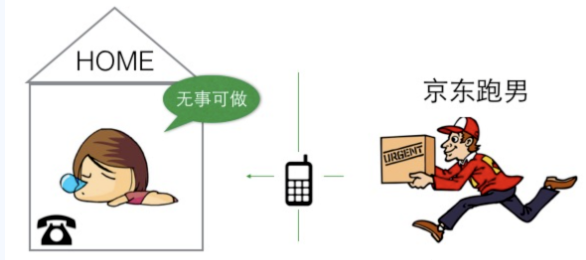
图1.4 非阻塞,忙轮询
与阻塞等待相对应的状态是非阻塞,忙轮询状态。假设您性子比较急躁,每分钟必须要打电话询问快递小哥一次,“到底有没有到?”,那么快递员每隔一段时间就会接听到你的电话询问,并告诉你是否到了,这样你就可以主动地指导你所缺的肥皂资源是否已经抵达。那么您此种不断通过通讯媒介询问对方并且循环往复的状态就是一种非阻塞忙轮询的状态。
5 阻塞与非阻塞对比
阻塞等待:空出大脑可以安心睡觉,不影响快递员工作(不占用CPU宝贵的时间片)。
非阻塞,忙轮询:浪费时间,浪费电话费,占用快递员时间(占用CPU,系统资源)。
很明显,通过上述的场景作为比较,阻塞等待这种方式,对于通信上是有明显优势的,阻塞等待也并非是没有弊端的。
二、解决阻塞等待缺点的办法
1 阻塞死等待的缺点
阻塞等待也是有非常明显的缺点的,现在我们比如有如下场景,如图1.5所示。

图1.5 阻塞
同一时刻,你只能被动地处理一个快递员的签收业务,其他快递员打电话打不进来,你的电话是座机,在签收的时候,接不到其他快递员的电话。所以阻塞等待的问题很明显,我们无法在同一时刻解决多个IO的读写请求。
2 解决阻塞等待的办法一:多线程/多进程
那么解决这个问题,即使家里多买N个座机, 但是依然是你一个人接,也处理不过来,所以就需要用“影分身术”创建都个自己来接电话(采用多线程或者多进程)来处理,如图1.6所示。
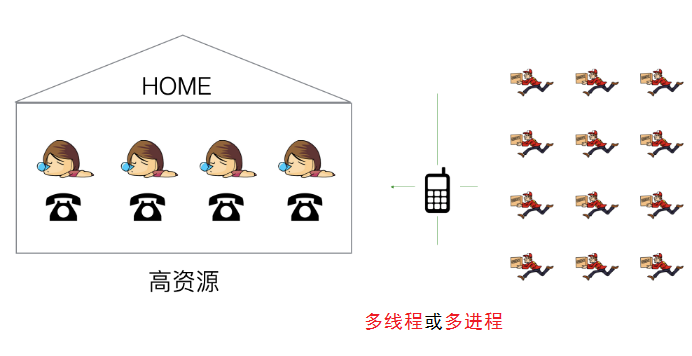
图1.6 办法一:提高资源(开多线程/多进程)
这种方式就是没有多路IO复用的情况的解决方案,但是大量的开辟线程和进程也是非常浪费资源的,我们知道一个操作系统能够同时运行的线程和进程都是有上限的,尤其是进程占用内存的资源极高,这样也就限定了能够同时处理IO数量的瓶颈。
3 解决阻塞等待的办法二:非阻塞、忙轮询
那么如果我们不借助影分身的方式(多线程/多进程),该如何解决阻塞死等待的方法呢?
如果我们是采用非阻塞的方式,那么可以用一个办法来监控多个IO的状态,我们可以采用粗暴的“非阻塞,忙轮询”方式,如图1.7所示。
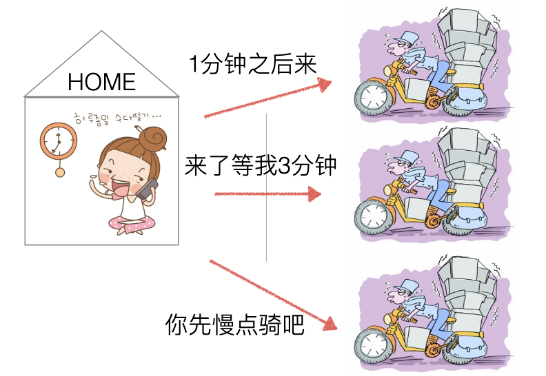
图1.7 办法二:非阻塞忙轮询
非阻塞忙轮询的方式,可以让用户分别与每个快递员取得联系,宏观上来看,是同时可以与多个快递员沟通(并发效果)、 但是快递员在于用户沟通时耽误前进的速度(浪费CPU)。
非阻塞忙轮询的方式具体的实现逻辑伪代码如下:
while true {for i in 流[] {if i has 数据 {读 或者 其他处理}}
}一层循环下,不断的遍历流是否有数据,如果没有或者有则进行逻辑处理,然后不停歇地进入下一次遍历,直到for循环出来,又回到while true的无限重复次数中。所以非阻塞忙轮询虽然能够在短暂的时间内监控到每个IO的读写状态,但是付出的代价是无限不停歇的判断,这样往往会使CPU过于劳累,把CPU资源打满,所以非阻塞忙轮询并不是一个非常好的解决方案。
相关视频推荐
手写一个epoll组件,为tcp并发实现epoll
服务端的网络并发,详解网络io与线程进程的关系
准备好4台虚拟机,实现服务器的百万级并发
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

4 解决阻塞等待的办法三:select
我们可以开设一个代收网点,让快递员全部送到代收点。这个网店管理员叫select。这样我们就可以在家休息了,麻烦的事交给select就好了。当有快递的时候,select负责给我们打电话,期间在家休息睡觉就好了。
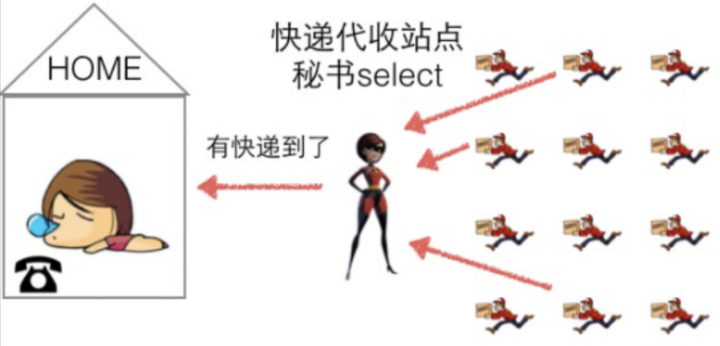
图1.8办法三:select
但select 代收员比较懒,她记不住快递员的单号,还有快递货物的数量。她只会告诉你快递到了,但是是谁到的,你需要挨个快递员问一遍。实现的逻辑伪代码如下:
while true {//阻塞select(流[]);//有消息抵达for i in 流[] {if i has 数据 {读 或者 其他处理}}
}Select的实现逻辑在while true的外层循环下,会有一个阻塞的过程,这个阻塞并不是永久阻塞,而是当select所监听的流中(多个IO传输媒介),有一个流可以读写,那么select就会立刻返回,当我们得知select已经返回,说目前的流一定是具备读写能力的,那么这时候就可以遍历这个流中,如果流有数据,我们就读出来处理,如果没有就看下一个流是否有。
用select并不会出现非阻塞忙轮询的无限判断情况的出现,因为select是可以阻塞的,阻塞的时候是不占用任何CPU资源的,但select有个明显的缺点,因为他每次都会返回全量的流集合,并不会告诉开发者哪个流可读写,哪个流不可读写,我们需要再循环全量的流集合,再进行判断是否读写,所以即使有一个流触发,我们依然for要全部流都扫描一遍,这显然是一种低效的方式。
5 解决阻塞等待的办法四:epoll
现在这个快递代收驿站升级了,服务更加友善且能力更强,与select一样,你依然可以在家休息,被动的接收epoll发来的通知,如图1.9所示。
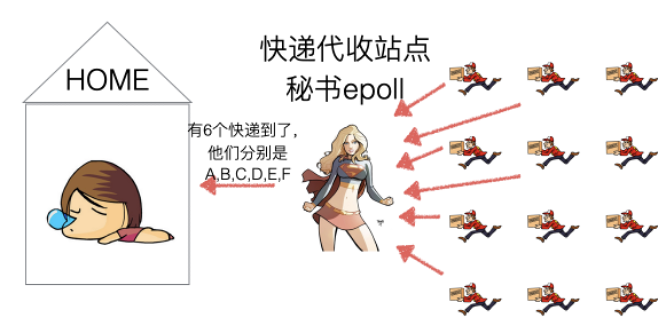
图1.9 办法四:epoll
epoll的服务态度要比select好很多,在通知我们的时候,不仅告诉我们有几个快递到了,还分别告诉我们是谁谁谁。我们只需要按照epoll给的答复,来询问快递员取快递即可。实现逻辑的伪代码如下:
while true {//阻塞可处理的流[] = epoll_wait(epoll_fd);//有消息抵达,全部放在 “可处理的流[]”中for i in 可处理的流[] {读 或者 其他处理}
}使用epoll来解决监听多个IO的逻辑和select极为相似,在使用过程中,有个重大的区别在于epoll_wait发生阻塞的时候,如果监控的流中有IO可以读写,那么epoll_wait会给我们返回一个可以读写流的集合,那么不可以读写的流epoll并不会返回给我们。这样实际上会减少我们的无效的遍历,这一点epoll要比select做得毕竟优秀。另外一个地方在实现逻辑中看不出来,select能够最大监听IO的数量是一个固定的数(这个可以修改,但是毕竟困难,需要重新编译操作系统),而且这个数量也不是很大,但是epoll能够监听的最大的IO数量是跟随当前操作系统的内存大小成正比的。所以epoll在监控IO数量这块也要比select优秀很多。
三、什么是epoll
epoll与select,poll一样,是对I/O多路复用的技术,它只关心“活跃”的链接,无须遍历全部描述符集合,它能够处理大量的链接请求(系统可以打开的文件数目,取决于内存大小)。
1 Linux提供的epoll的系统调用
epoll的开发流程是属于linux操作系统提供给用户态开发者的一系列系统调用函数,这些函数的直接接口都是C语言实现。所以开发者一般基于epoll进行开发的话,一般都是基于C语言进行开发,这样最接近操作系统,性能上也是最优的方法。
epoll的开发流程基本分为三大步骤:
第一步:创建epoll;
第二步:控制epoll;
第三步:等待epoll。
接下来我们来看一下Linux给开发者提供的epoll的原生接口是什么样子的。
1)创建EPOLL
原型如下:
/*** @param size 告诉内核监听的数目* @returns 返回一个epoll句柄(即一个文件描述符)*/
int epoll_create(int size);
int epfd = epoll_create(1000);当我们执行上述代码时,在内核中实则是创建一颗红黑树(平衡二叉树)的根节点root,如图1.10所示。
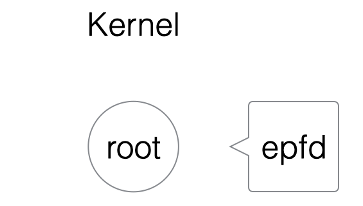
图1.10 epoll系统调用1
这个根节点的关系与epfd相对应。
2)控制EPOLL
原型如下:
/**
* @param epfd 用epoll_create所创建的epoll句柄
* @param op 表示对epoll监控描述符控制的动作
*
* EPOLL_CTL_ADD(注册新的fd到epfd)
* EPOLL_CTL_MOD(修改已经注册的fd的监听事件)
* EPOLL_CTL_DEL(epfd删除一个fd)
*
* @param fd 需要监听的文件描述符
* @param event 告诉内核需要监听的事件
*
* @returns 成功返回0,失败返回-1, errno查看错误信息
*/
int epoll_ctl(int epfd, int op, int fd,
struct epoll_event *event);struct epoll_event {__uint32_t events; /* epoll 事件 */epoll_data_t data; /* 用户传递的数据 */
}/** events : {EPOLLIN, EPOLLOUT, EPOLLPRI,EPOLLHUP, EPOLLET, EPOLLONESHOT}*/
typedef union epoll_data {void *ptr;int fd;uint32_t u32;uint64_t u64;
} epoll_data_t;struct epoll_event new_event;new_event.events = EPOLLIN | EPOLLOUT;
new_event.data.fd = 5;epoll_ctl(epfd, EPOLL_CTL_ADD, 5, &new_event);创建一个用户态的事件,绑定到某个fd上,然后添加到内核中的epoll红黑树中,如图1.11所示。
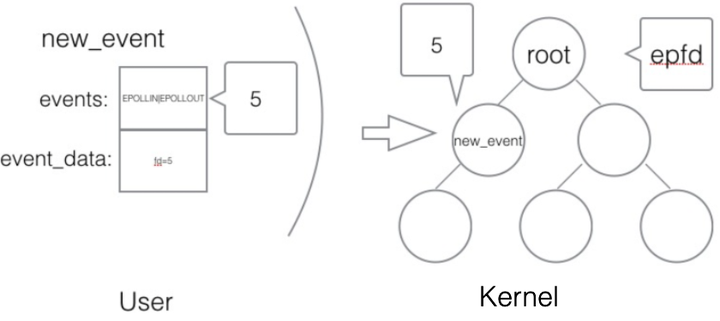
图1.11 epoll系统调用2
3)等待EPOLL
原型如下:
/**
*
* @param epfd 用epoll_create所创建的epoll句柄
* @param event 从内核得到的事件集合
* @param maxevents 告知内核这个events有多大,
* 注意: 值 不能大于创建epoll_create()时的size.
* @param timeout 超时时间
* -1: 永久阻塞
* 0: 立即返回,非阻塞
* >0: 指定微秒
*
* @returns 成功: 有多少文件描述符就绪,时间到时返回0
* 失败: -1, errno 查看错误
*/
int epoll_wait(int epfd, struct epoll_event *event,int maxevents, int timeout);struct epoll_event my_event[1000];int event_cnt = epoll_wait(epfd, my_event, 1000, -1);epoll_wait是一个阻塞的状态,如果内核检测到IO的读写响应,会抛给上层的epoll_wait, 返回给用户态一个已经触发的事件队列,同时阻塞返回。开发者可以从队列中取出事件来处理,其中事件里就有绑定的对应fd是具体哪一个(之前添加epoll事件的时候已经绑定),如图1.12所示。

图1.12 epoll系统调用3
比如这次epoll_wait返回的就是一个my_event集合,其中每一个元素均是一个event结构体,结构体里面有两个重要的元素,第一个是当前的事件类型(如:EPOLLIN或者EPOLLOUT,分别对应读写事件),一个是当前event所绑定的fd(也可以绑定任意指针)。如图10.12所示,epoll_wait触发了2个事件,那么开发者只需要遍历my_event依次处理每个event事件就可以了。
4)使用epoll编程主流程骨架
下面一段代码是基于epoll开发的一段主干代码:
int epfd = epoll_create(1000);//将 listen_fd 添加进 epoll 中
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd,&listen_event);while (1) {//阻塞等待 epoll 中 的fd 触发int active_cnt = epoll_wait(epfd, events, 1000, -1);for (i = 0 ; i < active_cnt; i++) {if (evnets[i].data.fd == listen_fd) {//accept. 并且将新accept 的fd 加进epoll中.}else if (events[i].events & EPOLLIN) {//对此fd 进行读操作}else if (events[i].events & EPOLLOUT) {//对此fd 进行写操作}}
}这里并没有加数据处理和网络处理实现,只是说明epoll的事件交互流程。我们一般写一个服务端代码,首先要对listen_fd(监听端口的fd)进行读事件的监听,并且将这个事件放置在epoll堆里,当listen_fd触发可读事件,那就说明有新的客户端链接创建过来,那么epoll_wait的阻塞就会返回,我们通过判断fd是否为listen_fd来做与客户端建立链接的动作, 那么将建立好的链接添加放置到epoll堆里,等待下次可读可写事件触发,这就是epoll开发的基本流程。
四、epoll的触发模式
本节作为附加小节,实则介绍epoll的触发模式种类,如果不想进一步关心epoll的触发方式的读者可以越过本节。
epoll给开发者提供了两种触发模式,他们分别是水平触发与边缘触发。
1 水平触发
水平触发(Level Triggered,简称:LT)的主要特点是,如果用户在监听epoll事件,当内核有事件的时候,会拷贝给用户态事件,但是如果用户只处理了一次,那么剩下没有处理的会在下一次epoll_wait再次返回该事件,如图1.13和1.14所示。
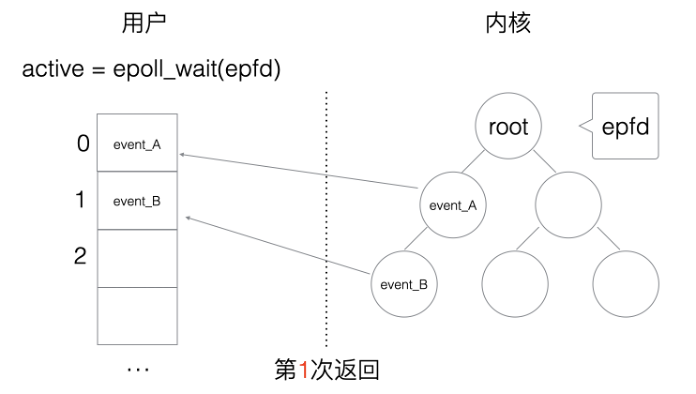
图1.13 epoll系统调用4
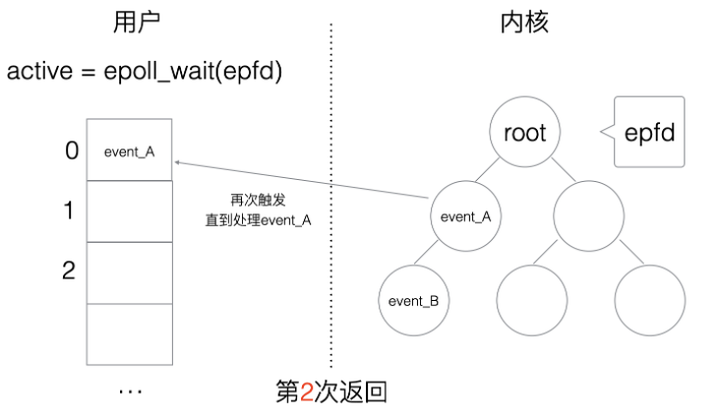
图1.14 epoll系统调用5
这样如果用户永远不处理这个事件,就导致每次都会有该事件从内核到用户的拷贝,如图1.15所示,耗费性能,但是水平触发相对安全,最起码事件不会丢掉,除非用户处理完毕。

图1.15 epoll系统调用6
2 边缘触发
边缘触发(Edge Triggered,简称:ET)相对跟水平触发相反,当内核有事件到达, 只会通知用户一次,至于用户处理还是不处理,以后将不会再通知。这样减少了拷贝过程,增加了性能,但是相对来说,如果用户马虎忘记处理,将会产生事件丢的情况,如图1.16所示。
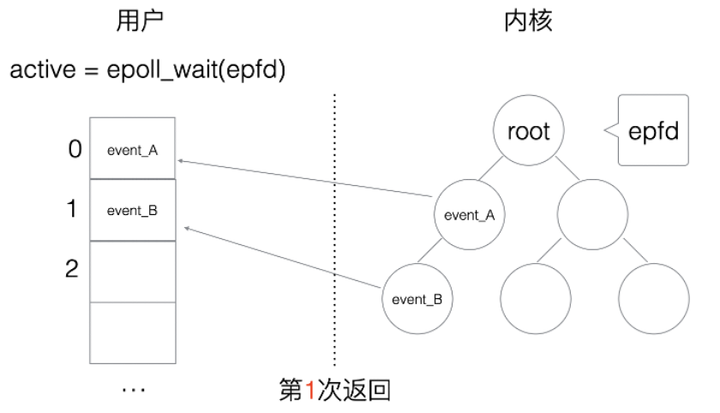
图1.16 epoll系统调用7
五、简单的epoll服务器
1 服务端实现
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <string.h>#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>#include <sys/epoll.h>#define SERVER_PORT (7778)
#define EPOLL_MAX_NUM (2048)
#define BUFFER_MAX_LEN (4096)char buffer[BUFFER_MAX_LEN];void str_toupper(char *str)
{int i;for (i = 0; i < strlen(str); i ++) {str[i] = toupper(str[i]);}
}int main(int argc, char **argv)
{int listen_fd = 0;int client_fd = 0;struct sockaddr_in server_addr;struct sockaddr_in client_addr;socklen_t client_len;int epfd = 0;struct epoll_event event, *my_events;/ socketlisten_fd = socket(AF_INET, SOCK_STREAM, 0);// bindserver_addr.sin_family = AF_INET;server_addr.sin_addr.s_addr = htonl(INADDR_ANY);server_addr.sin_port = htons(SERVER_PORT);bind(listen_fd, (struct sockaddr*)&server_addr, sizeof(server_addr));// listenlisten(listen_fd, 10);// epoll createepfd = epoll_create(EPOLL_MAX_NUM);if (epfd < 0) {perror("epoll create");goto END;}// listen_fd -> epollevent.events = EPOLLIN;event.data.fd = listen_fd;if (epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &event) < 0) {perror("epoll ctl add listen_fd ");goto END;}my_events = malloc(sizeof(struct epoll_event) * EPOLL_MAX_NUM);while (1) {// epoll waitint active_fds_cnt = epoll_wait(epfd, my_events, EPOLL_MAX_NUM, -1);int i = 0;for (i = 0; i < active_fds_cnt; i++) {// if fd == listen_fdif (my_events[i].data.fd == listen_fd) {//acceptclient_fd = accept(listen_fd, (struct sockaddr*)&client_addr, &client_len);if (client_fd < 0) {perror("accept");continue;}char ip[20];printf("new connection[%s:%d]\n", inet_ntop(AF_INET, &client_addr.sin_addr, ip, sizeof(ip)), ntohs(client_addr.sin_port));event.events = EPOLLIN | EPOLLET;event.data.fd = client_fd;epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &event);}else if (my_events[i].events & EPOLLIN) {printf("EPOLLIN\n");client_fd = my_events[i].data.fd;// do readbuffer[0] = '\0';int n = read(client_fd, buffer, 5);if (n < 0) {perror("read");continue;}else if (n == 0) {epoll_ctl(epfd, EPOLL_CTL_DEL, client_fd, &event);close(client_fd);}else {printf("[read]: %s\n", buffer);buffer[n] = '\0';str_toupper(buffer);write(client_fd, buffer, strlen(buffer));printf("[write]: %s\n", buffer);memset(buffer, 0, BUFFER_MAX_LEN);/*event.events = EPOLLOUT;event.data.fd = client_fd;epoll_ctl(epfd, EPOLL_CTL_MOD, client_fd, &event);*/}}else if (my_events[i].events & EPOLLOUT) {printf("EPOLLOUT\n");/*client_fd = my_events[i].data.fd;str_toupper(buffer);write(client_fd, buffer, strlen(buffer));printf("[write]: %s\n", buffer);memset(buffer, 0, BUFFER_MAX_LEN);event.events = EPOLLIN;event.data.fd = client_fd;epoll_ctl(epfd, EPOLL_CTL_MOD, client_fd, &event);*/}}}END:close(epfd);close(listen_fd);return 0;
}2 客户端实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <strings.h>#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <fcntl.h>#define MAX_LINE (1024)
#define SERVER_PORT (7778)void setnoblocking(int fd)
{int opts = 0;opts = fcntl(fd, F_GETFL);opts = opts | O_NONBLOCK;fcntl(fd, F_SETFL);
}int main(int argc, char **argv)
{int sockfd;char recvline[MAX_LINE + 1] = {0};struct sockaddr_in server_addr;if (argc != 2) {fprintf(stderr, "usage ./client <SERVER_IP>\n");exit(0);}// 创建socketif ( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {fprintf(stderr, "socket error");exit(0);}// server addr 赋值bzero(&server_addr, sizeof(server_addr));server_addr.sin_family = AF_INET;server_addr.sin_port = htons(SERVER_PORT);if (inet_pton(AF_INET, argv[1], &server_addr.sin_addr) <= 0) {fprintf(stderr, "inet_pton error for %s", argv[1]);exit(0);}// 链接服务端if (connect(sockfd, (struct sockaddr*) &server_addr, sizeof(server_addr)) < 0) {perror("connect");fprintf(stderr, "connect error\n");exit(0);}setnoblocking(sockfd);char input[100];int n = 0;int count = 0;// 不断的从标准输入字符串while (fgets(input, 100, stdin) != NULL){printf("[send] %s\n", input);n = 0;// 把输入的字符串发送 到 服务器中去n = send(sockfd, input, strlen(input), 0);if (n < 0) {perror("send");}n = 0;count = 0;// 读取 服务器返回的数据while (1){n = read(sockfd, recvline + count, MAX_LINE);if (n == MAX_LINE){count += n;continue;}else if (n < 0){perror("recv");break;}else {count += n;recvline[count] = '\0';printf("[recv] %s\n", recvline);break;}}}return 0;
}六、Linux下常见的网络IO复用并发模型
本节主要介绍常见的Server的并发模型,这些模型与编程语言本身无关,有的编程语言可能在语法上直接透明了模型本质,所以开发者没必要一定要基于模型去编写,只是需要知道和了解并发模型的构成和特点即可,本节的一些使用模型需要读者了解基本的多路IO复用知识,如一~六章节介绍。
1 模型一:单线程Accept(无IO复用)
模型一是单线程的Server,并且不适用任何IO复用机制,来实现一个基本的网络服务器。其结构如图1.17所示。

图1.17 网络并发模型一:单线程Accept
1) 流程
(1)我们首先启动一个Server服务端进程,其中进程包括主线程main thread。我们知道一个基本的服务端Socket编程需要的几个关键步骤,创建一个ListenFd(服务端监听套接字),将这个ListenFd绑定到需要服务的IP和端口上,然后执行阻塞Accept被动等待远程的客户端建立链接,每次客户端Connect链接过来,main thread中accept响应并建立连接。
(2)这里第一个链接过来的Client1请求服务端链接,服务端Server创建链接成功,得到Connfd1套接字后, 依然在main thread串行处理套接字读写,并处理业务。
(3) 在(2)处理业务中,如果有新客户端Connect过来,Server无响应,直到当前套接字全部业务处理完毕。
(4)当前客户端处理完后,完毕链接,处理下一个客户端请求。
以上是模型一的服务端整体执行逻辑,我们来分析一下模型一的优缺点:
2)优点
模型一的socket编程流程清晰且简单,适合学习使用,可以基于模型一很快地了解socket基本编程流程。
3)缺点
该模型并非并发模型,是串行的服务器,同一时刻,监听并响应最大的网络请求量为1。即并发量为1。
所以综上,仅适合学习基本 socket编程,不适合任何服务器Server构建。
2 模型二:单线程Accept+多线程读写业务(无IO复用)
模型二是主进程启动一个main thread线程,其中main thread在进行socket初始化的过程和模型一是一样的,那么对于如果有新的Client建立链接请求进来,就会出现和模型一不同的地方,如图1.18所示。
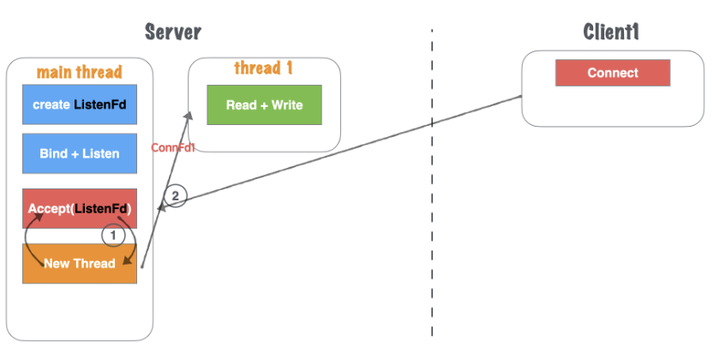
图1.18 网络并发模型二:单线程Accept+多线程读写-1
1)流程
(1)主线程main thread执行阻塞Accept,每次客户端Connect链接过来,main thread中accept响应并建立连接。
(2)创建链接成功,得到Connfd1套接字后,创建一个新线程thread1用来处理客户端的读写业务。main thead依然回到Accept阻塞等待新客户端。
(3)thread1通过套接字Connfd1与客户端进行通信读写。
(4)server在(2)处理业务中,如果有新客户端Connect过来,main thread中Accept依然响应并建立连接,重复(2)过程,如图1.19所示。
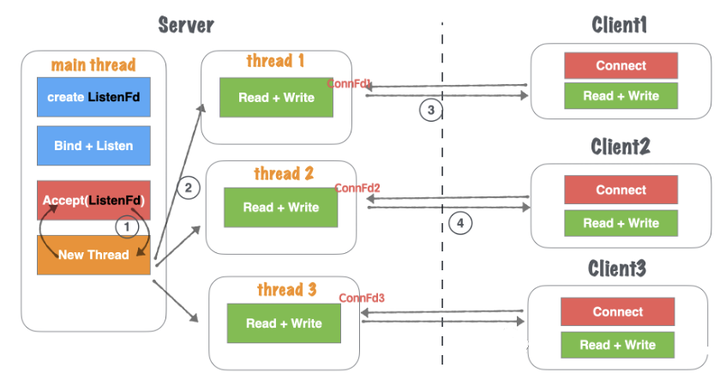
图1.19 网络并发模型二:单线程Accept+多线程读写-2
以上是模型二的服务端整体执行逻辑,我们来分析一下模型一的优缺点:
2)优点
基于模型一:单线程Accept(无IO复用) 支持了并发的特性。使用灵活,一个客户端对应一个线程单独处理,server处理业务内聚程度高,客户端无论如何写,服务端均会有一个线程做资源响应。
3)缺点
随着客户端的数量增多,需要开辟的线程也增加,客户端与server线程数量1:1正比关系,一次对于高并发场景,线程数量收到硬件上限瓶颈。对于长链接,客户端一旦无业务读写,只要不关闭,server的对应线程依然需要保持连接(心跳、健康监测等机制),占用连接资源和线程开销资源浪费。仅适合客户端数量不大,并且数量可控的场景使用。仅适合学习基本socket编程,不适合任何服务器Server构建。
3 模型三、单线程多路IO复用
1)流程
模型三是在单线程的基础上添加多路IO复用机制,这样就减少了多开销线程的弊端,模型三的流程如下:
(1)主线程main thread创建 listenFd 之后,采用多路I/O复用机制(如:select、epoll)进行IO状态阻塞监控。有Client1客户端Connect请求,I/O复用机制检测到ListenFd触发读事件,则进行Accept建立连接,并将新生成的connFd1加入到监听I/O集合中,如图1.20所示。
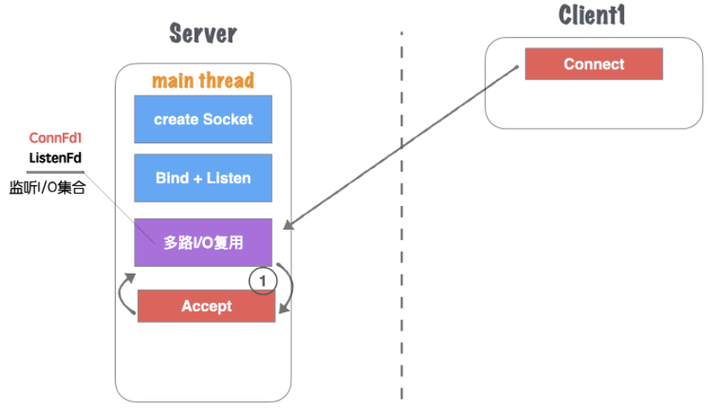
图1.20 网络并发模型三:单线程Accept多路IO复用-1
(2)Client1再次进行正常读写业务请求,main thread的多路I/O复用机制阻塞返回,会触该套接字的读/写事件等,如图1.21所示。
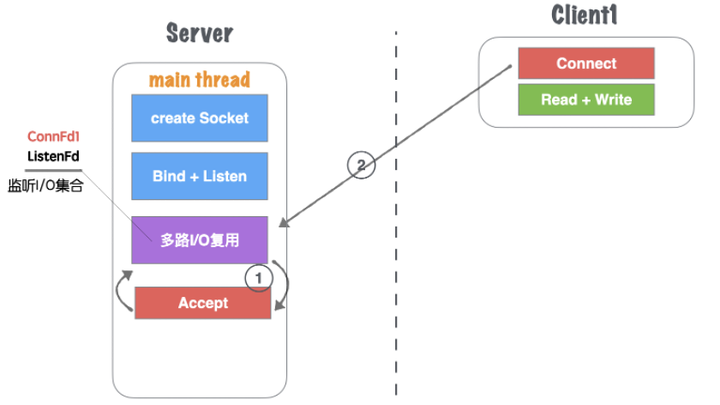
图1.21 网络并发模型三:单线程Accept多路IO复用-2
(3)对于Client1的读写业务,Server依然在main thread执行流程提继续执行,此时如果有新的客户端Connect链接请求过来,Server将没有及时响应,如图1.22所示。
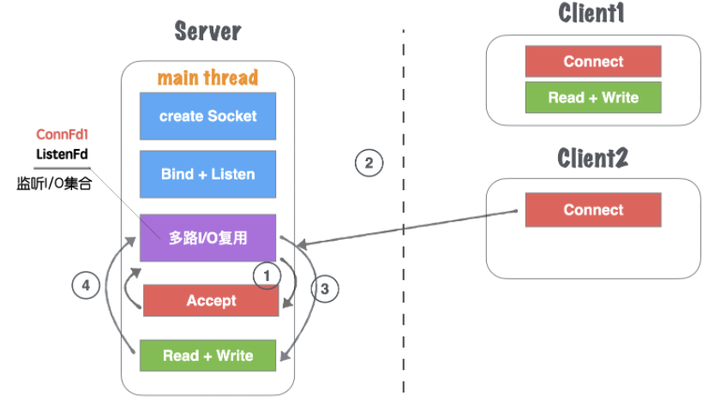
图1.22 网络并发模型三:单线程Accept多路IO复用-3
(4)等到Server处理完一个连接的Read+Write操作,继续回到多路I/O复用机制阻塞,其他链接过来重复(2)、(3)流程。
以上是模型二的服务端整体执行逻辑,我们来分析一下模型一的优缺点:
2)优点
单流程解决了可以同时监听多个客户端读写状态的模型,不需要1:1与客户端的线程数量关系。多路I/O复用阻塞,非忙询状态,不浪费CPU资源, CPU利用率较高。
3)缺点
虽然可以监听多个客户端的读写状态,但是同一时间内,只能处理一个客户端的读写操作,实际上读写的业务并发为1。多客户端访问Server,业务为串行执行,大量请求会有排队延迟现象,当Client3占据main thread流程时,Client1,Client2流程卡在IO复用等待下次监听触发事件。
4 模型四-单线程多路IO复用+多线程读写业务(业务工作池)
模型四是基于模型三的一种改进版,但是赶紧的地方是在处理应用层消息业务本身,将这部分承担的压力交给了一个Worker Pool工作池来处理。
1)流程
(1)主线程main thread创建listenFd之后,采用多路I/O复用机制(如:select、epoll)进行IO状态阻塞监控。有Client1客户端Connect请求,I/O复用机制检测到ListenFd触发读事件,则进行Accept建立连接,并将新生成的connFd1加入到监听I/O集合中,如图1.23所示。
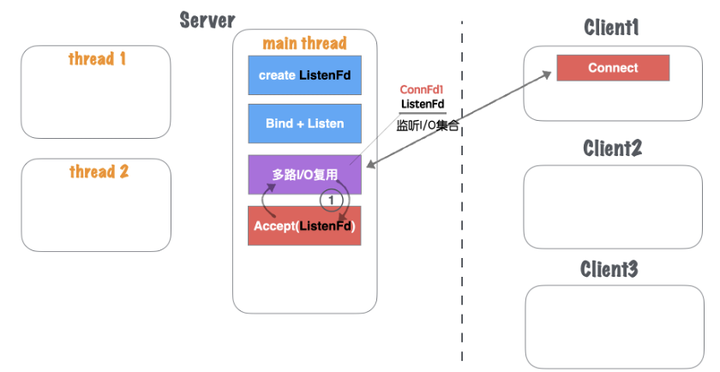
图1.23 网络并发模型四:单线程多路IO复用+业务工作池-1
(2)当connFd1有可读消息,触发读事件,并且进行读写消息。
(3)main thread按照固定的协议读取消息,并且交给worker pool工作线程池, 工作线程池在server启动之前就已经开启固定数量的thread,里面的线程只处理消息业务,不进行套接字读写操作,如图1.24所示。

图1.24 网络并发模型四:单线程多路IO复用+业务工作池-2
(4)工作池处理完业务,触发connFd1写事件,将回执客户端的消息通过main thead写给对方,如图1.25所示。
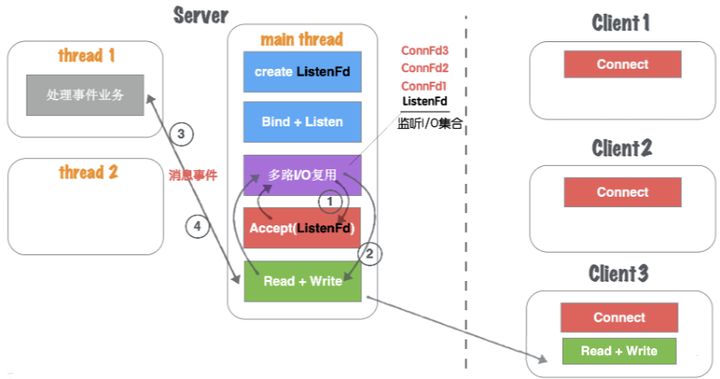
图1.25 网络并发模型四:单线程多路IO复用+业务工作池-3
那么接下来Client2的读写请求的逻辑就是重复上述(1)-(4)的过程,一般我们把这种基于消息事件的业务层处理的线程称之为业务工作池,如图1.26所示。
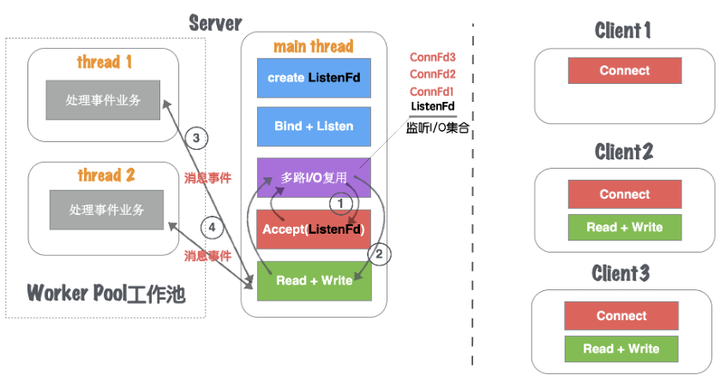
图1.26 网络并发模型四:单线程多路IO复用+业务工作池-4
以上是模型四的服务端整体执行逻辑,我们来分析一下模型一的优缺点:
2)优点
对于模型三, 将业务处理部分,通过工作池分离出来,减少多客户端访问Server,业务为串行执行,大量请求会有排队延迟时间。实际上读写的业务并发为1,但是业务流程并发为worker pool线程数量,加快了业务处理并行效率。
3)缺点
读写依然为main thread单独处理,最高读写并行通道依然为1。虽然多个worker线程处理业务,但是最后返回给客户端,依旧需要排队,因为出口还是main thread的Read + Write。
5 模型五:单线程IO复用+多线程IO复用(链接线程池)
模型五是单线程IO复用机制上再加上多线程的IO复用机制,看上去很繁琐,但是这种模型确实当下最通用和高效的解决方案。
1)流程
(1)Server在启动监听之前,开辟固定数量(N)的线程,用Thead Pool线程池管理,如图1.27所示。
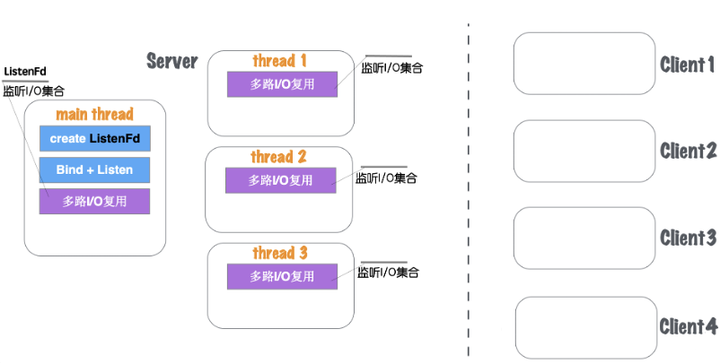
图1.27 网络并发模型五:单线程多路IO复用+多线程IO复用-1
(2)主线程main thread创建listenFd之后,采用多路I/O复用机制(如:select、epoll)进行IO状态阻塞监控。有Client1客户端Connect请求,I/O复用机制检测到ListenFd触发读事件,则进行Accept建立连接,并将新生成的connFd1分发给Thread Pool中的某个线程进行监听。
(3) Thread Pool中的每个thread都启动多路I/O复用机制(select、epoll),用来监听main thread建立成功并且分发下来的socket套接字。
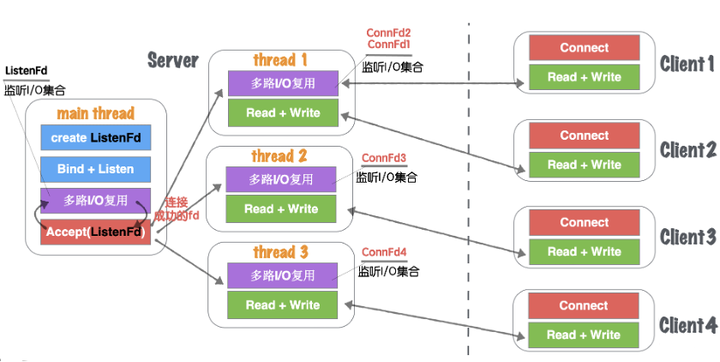
图1.28 网络并发模型五:单线程多路IO复用+多线程IO复用-2
(4)如图1.28所示, thread监听ConnFd1、ConnFd2, thread2监听ConnFd3,thread3监听ConnFd4. 当对应的ConnFd有读写事件,对应的线程处理该套接字的读写及业务。
所以我们将这些固定承担epoll多路IO监控的线程集合,称之为线程池,如图1.29所示。
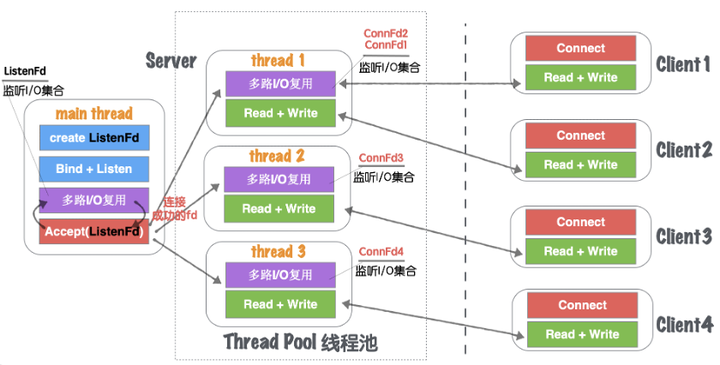
图1.29 网络并发模型五:单线程多路IO复用+多线程IO复用-3
以上是模型五的服务端整体执行逻辑,我们来分析一下模型一的优缺点。
2)优点
将main thread的单流程读写,分散到多线程完成,这样增加了同一时刻的读写并行通道,并行通道数量N, N为线程池Thread数量。server同时监听的ConnFd套接字数量几乎成倍增大,之前的全部监控数量取决于main thread的多路I/O复用机制的最大限制 (select 默认为1024, epoll默认与内存大小相关,约3~6w不等),所以理论单点Server最高响应并发数量为N*(3~6W)(N为线程池Thread数量,建议与CPU核心成比例1:1)。如果良好的线程池数量和CPU核心数适配,那么可以尝试CPU核心与Thread进行绑定,从而降低CPU的切换频率,提升每个Thread处理合理业务的效率,降低CPU切换成本开销。
3)缺点
虽然监听的并发数量提升,但是最高读写并行通道依然为N,而且多个身处同一个Thread的客户端,会出现读写延迟现象,实际上每个Thread的模型特征与模型三:单线程多路IO复用一致。
6 模型五(进程版):单进程多路I/O复用+多进程IO复用
模型五进程版和模型五的流程大致一样,这里的区别是由线程池更编程进程池,如图1.30所示。
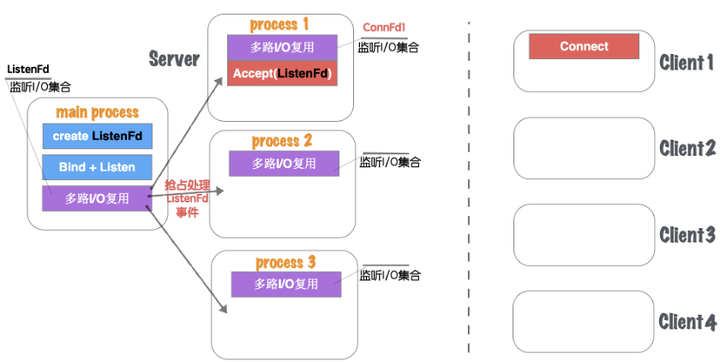
图1.30 网络并发模型五-进程池版本-1
在模型五进程版要注意的是,进程之间的资源都是独立的,所以当有客户端(如:Client1)建立请求的时候,main process(主进程)的IO复用会监听到ListenFd的可读事件,如果在线程模型中,可以直接Accept将链接创建,并且将新创建的ConnFd交给线程中的某个线程中的IO复用机制来监控,因为线程与线程中资源是共享的。但是在多进程中则不能这么做。Main Process如果进行Accept得到的ConnFd并不能传递给子进程,因为他们都有各自的文件描述符序列。所以在多进程版本,主进程listenFd触发读事件,应该由主进程发送信号告知子进程目前有新的链接可以建立,最终应该由某个子进程来进行Accept完成链接建立过程,同时得到与客户端通信的套接字ConnFd。最终在用自己的多路IO复用机制来监听当前进程创建的ConnFd。
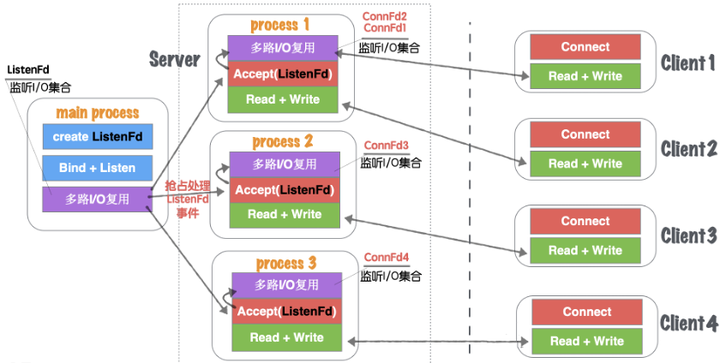
图1.31 网络并发模型五-进程池版本-2
如图1.31所示,进程版与“模型五-单线程IO复用+多线程IO复用(链接线程池)”无大差异。
1)不同
(1)进程和线程的内存布局不同导致,main process(主进程)不再进行Accept操作,而是将Accept过程分散到各个子进程(process)中。
(2)进程的特性,资源独立,所以main process如果Accept成功的fd,其他进程无法共享资源,所以需要各子进程自行Accept创建链接。
(3)main process只是监听ListenFd状态,一旦触发读事件(有新连接请求)。通过一些IPC(进程间通信:如信号、共享内存、管道)等, 让各自子进程Process竞争Accept完成链接建立,并各自监听。
2)优缺点
与五、单线程IO复用+多线程IO复用(链接线程池)无大差异。多进程内存资源空间占用稍微大一些,多进程模型安全稳定型较强,这也是因为各自进程互不干扰的特点导致。
7 模型六:单线程多路I/O复用+多线程I/O复用+多线程
本小节介绍一个更加复杂的模型六,我们在基于模型五上再加上一个多线程处理读写,服务端逻辑如下。
1)流程
(1)Server在启动监听之前,开辟固定数量(N)的线程,用Thead Pool线程池管理,如图1.32所示。
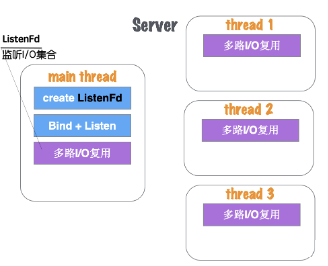
图1.32 网络并发模型六-1
(2)主线程main thread创建listenFd之后,采用多路I/O复用机制(如:select、epoll)进行IO状态阻塞监控。有Client1客户端Connect请求,I/O复用机制检测到ListenFd触发读事件,则进行Accept建立连接,并将新生成的connFd1分发给Thread Pool中的某个线程进行监听,如图1.33所示。
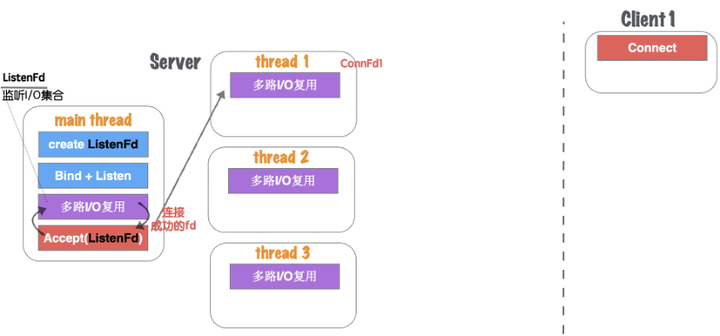
图10.33 网络并发模型六-2
(3)Thread Pool中的每个thread都启动多路I/O复用机制(select、epoll),用来监听main thread建立成功并且分发下来的socket套接字。一旦其中某个被监听的客户端套接字触发I/O读写事件,那么,会立刻开辟一个新线程来处理I/O读写业务,如图1.34所示。
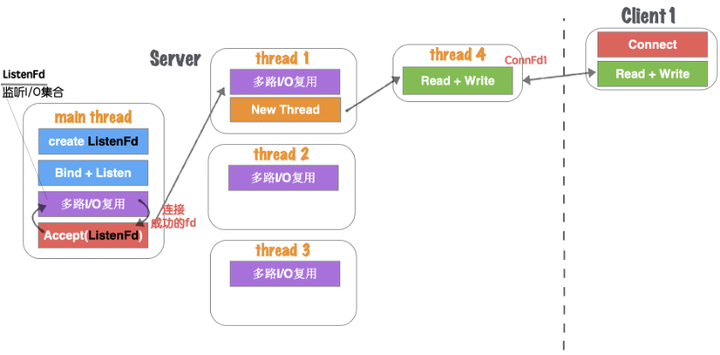
图1.34 网络并发模型六-3
(4)但某个读写线程完成当前读写业务,如果当前套接字没有被关闭,那么将当前客户端套接字(如:ConnFd3)重新加回线程池的监控线程中,同时自身线程自我销毁。
以上是模型六的处理逻辑,我们来分析一下他的优缺点:
2)优点
在模型五、单线程IO复用+多线程IO复用(链接线程池)基础上,除了能够保证同时响应的最高并发数,又能解决读写并行通道局限的问题。同一时刻的读写并行通道,达到最大化极限,一个客户端可以对应一个单独执行流程处理读写业务,读写并行通道与客户端数量1:1关系,如图1.35所示。
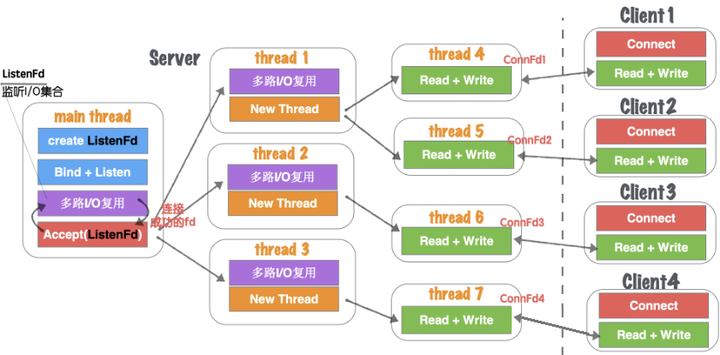
图1.35 网络并发模型六-4
3)缺点
该模型过于理想化,因为要求CPU核心数量足够大。如果硬件CPU数量可数(目前的硬件情况),那么该模型将造成大量的CPU切换成本浪费。因为为了保证读写并行通道与客户端1:1的关系,那么Server需要开辟的Thread数量就与客户端一致,那么线程池中做多路I/O复用的监听线程池绑定CPU数量将变得毫无意义。如果每个临时的读写Thread都能够绑定一个单独的CPU,那么此模型将是最优模型。但是目前CPU的数量无法与客户端的数量达到一个量级,目前甚至差的不是几个量级的事。
七、小结
本章我们首先介绍了多路IO复用机制解决的问题,以及Epoll的常用接口和基本的结构分析,那么在基于IO复用机制的理论基础上,我们整理了七种Server服务器并发处理结构模型,每个模型都有各自的特点和优势,那么对于多少应付高并发和高CPU利用率的模型,目前多数采用的是模型五(或模型五进程版,如Nginx就是类似模型五进程版的改版)。
至于并发模型并非设计的越复杂越好,也不是线程开辟得越多越好,我们要考虑硬件的利用与和切换成本的开销。模型六设计就极为复杂,线程较多,但以当今的硬件能力无法支撑,反倒导致该模型性能极差。所以对于不同的业务场景也要选择适合的模型构建,并不是一定固定就要使用某个来应用。
相关文章:
深入理解网络IO复用并发模型
本文主要介绍服务端对于网络并发模型以及Linux系统下常见的网络IO复用并发模型。文章内容一共分为两个部分。 第一部分主要介绍网络并发中的一些基本概念以及我们Linux下常见的原生IO复用系统调用(epoll/select)等。第二部分主要介绍并发场景下常见的网…...
二叉树采用二叉链表存储:编写计算整个二叉树高度的算法
二叉树采用二叉链表存储:编写计算整个二叉树高度的算法 (二叉树的高度也叫二叉树的深度) 代码思路: 首先你要明白什么是树的高度,简言之就是树有多少层,如下图: 下面这棵树的高度就是4 首先我们观察根节点࿰…...

antd Cascader级联菜单无法赋值回显问题
说起来太丢人了,自己还拿官网例子在这里调试半天,最后发现是一个特别小儿科的问题哈哈 Cascader级联数据是服务端返回然后自己处理过的,使用了cascader的fileNames属性重置字段名,最后发现服务端回传的数据无法赋值回显在组件上&…...

在react中使用redux react-redux的使用demo
前言: redux是一种状态管理工具,可以存储和操作一些全局或者很多组件需要使用的公共数据。 平心而论,redux的使用对于新上手来说不太友好,多个依赖包的,多种api的结合使用,相对来说比做同样一件事的vuex用起来比较麻烦.不过,熟能生巧,用多了也就习惯了,下面是个人的一个demo,…...

Flutter 06 动画
一、动画基本原理以及Flutter动画简介 1、动画原理: 在任何系统的Ul框架中,动画实现的原理都是相同的,即:在一段时间内,快速地多次改变Ul外观;由于人眼会产生视觉暂留,所以最终看到的就是一个…...
)
优化改进YOLOv5算法之添加MS-Block模块,有效提升目标检测效果(超详细)
目录 前言 1 MS-Block原理 1.1 Multi-Scale Building Block Design 1.2 Heterogeneous Kernel Selection Protocol 2 YOLOv5算法中加入MS-Block...
 for Unoriented Points)
【论文阅读】Iterative Poisson Surface Reconstruction (iPSR) for Unoriented Points
文章目录 声明作者列表核心思想归纳算法流程机器翻译声明 本帖更新中如有问题,望批评指正!如果有人觉得帖子质量差,希望在评论中给出建议,谢谢!作者列表 FEI HOU(侯飞)、CHIYU WANG、WENCHENG WANG:中国科学院大学 HONG QIN CHEN QIAN、YING HE 核心思想归纳 当一条从…...

通过akshare获取股票分钟数据
参考:https://blog.csdn.net/qnloft/article/details/131218295 import akshare as ak 个股的 df ak.stock_zh_a_hist_min_em(symbol“000001”, start_date“2023-11-03 09:30:00”, end_date“2023-11-03 15:00:00”, period‘1’, adjust‘’) print(df) date_info df[‘…...

【论文阅读笔记】Traj-MAE: Masked Autoencoders for Trajectory Prediction
Abstract 通过预测可能的危险,轨迹预测一直是构建可靠的自动驾驶系统的关键任务。一个关键问题是在不发生碰撞的情况下生成一致的轨迹预测。为了克服这一挑战,我们提出了一种有效的用于轨迹预测的掩蔽自编码器(Traj-MAE),它能更好地代表驾驶…...
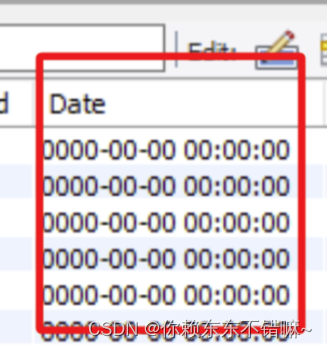
MySQL - Zero date value prohibited
问题: timestamp字段报Caused by: com.mysql.cj.exceptions.DataReadException: Zero date value prohibited 原因: timestamp字段存入了0值, 超出了最小值1900-01-01 00:00:00, 转Java对象的时候报错 解决: 1.修复或删除原数据 2. mysqlurl 中添加zeroDateTimeBehaviorconve…...
+ Spring相关源码)
设计模式——迭代器模式(Iterator Pattern)+ Spring相关源码
文章目录 一、迭代器模式二、例子2.1 菜鸟例子2.1.1 定义迭代器接口2.1.2 定义迭代对象接口——用于返回一个迭代器2.1.3 实现 迭代对象 和 迭代器2.1.4 使用 2.2 JDK源码——ArrayList2.3 Spring源码——DefaultListableBeanFactory 三、其他设计模式 一、迭代器模式 类型&am…...
【word技巧】ABCD选项如何对齐?
使用word文件制作试卷,如何将ABCD选项全部设置对齐?除了一直按空格或者Tab键以外,还有其他方法吗?今天分享如何将ABCD选项对齐。 首先,我们打开【替换和查找】,在查找内容输入空格,然后点击全部…...

如何在uni-app小程序端实现长按复制功能
在开发小程序应用中,常常需要使用到长按复制功能。本文将介绍如何在uni-app小程序端实现长按复制功能。 uni-app是一个跨平台的开发框架,可以基于vue.js语法开发小程序、H5、APP等多个平台的应用。uni-app提供了一些内置组件和API,可以方便地…...

基于springboot实现在线考试平台项目【项目源码+论文说明】计算机毕业设计
基于springboot实现在线考试演示 摘要 网络的广泛应用给生活带来了十分的便利。所以把在线考试管理与现在网络相结合,利用java技术建设在线考试系统,实现在线考试的信息化。则对于进一步提高在线考试管理发展,丰富在线考试管理经验能起到不少…...

【移远QuecPython】EC800M物联网开发板的内置GNSS定位获取(北斗、GPS和GNSS)
【移远QuecPython】EC800M物联网开发板的内置GNSS定位获取(北斗、GPS和GNSS) 测试视频(其中的恶性BUG会在下一篇文章阐述): 【移远QuecPython】EC800M物联网开发板的内置GNSS定位的恶性BUG(目前没有完全的…...

软件设计师2016下半年下午——KMP算法和装饰设计模式
下面是提供的代码的逐行注释,以及对next数组在KMP算法中的作用的解释: #include <iostream> #include <vector> using namespace std;void buildNextArray(const char* pattern, vector<int>& next) {int m strlen(pattern); …...
方法报错)
Android Studio run main()方法报错
在studio中想要测试某个功能直接执行main()方法报错如下: * What went wrong: A problem occurred configuring project :app. > Could not create task :app: **** .main().> SourceSet with name main not found.解决方案: 执行run ** main() w…...

CM3D2 汉化杂记
老物难找资源,于是尝试自己汉化,皆源于有一个好的汉化插件。 资源:LMMT 工具:CM3D2.SubtitleDumper.exe,有道翻译(可以翻译文档),Libreoffice(文档、表格) cmd(资源管理器的结果可以拖进去&…...

分类预测 | Matlab实现SMA-KELM黏菌优化算法优化核极限学习机分类预测
分类预测 | Matlab实现SMA-KELM黏菌优化算法优化核极限学习机分类预测 目录 分类预测 | Matlab实现SMA-KELM黏菌优化算法优化核极限学习机分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现SMA-KELM黏菌优化算法优化核极限学习机分类预测(完整源码和数…...
linux的环境安装以及部署前后端分离后台接口
⭐⭐ linux专栏:linux专栏 ⭐⭐ 个人主页:个人主页 目录 一.linux安装环境 1.1 jdk和tomcat的安装配置 1.1.1 解压jdk和tomcat的安装包 解压jdk安装包 解压tomcat安装包 1.2 jdk环境变量配置 1.3 tomcat启动 1.4 MySQL的安装 二.部署前后端分离…...

从NUCLEO板载调试器到独立ST-LINK:打造高效STM32开发环境
1. 为什么需要独立ST-LINK调试器? 很多STM32开发者刚开始接触NUCLEO开发板时,都会发现板子上自带了一个ST-LINK调试器。这个设计本来是为了方便初学者快速上手,但随着项目复杂度提升,你会发现这个板载调试器存在不少限制。比如每次…...

伯远生物:告别 “靠天碰运气”,育种进入标记时代
在现代育种科学的演进历程中,从依赖表型选择的传统经验育种,到基于基因型精准筛选的分子育种,技术变革正深刻地重塑着作物改良的路径与效率。分子标记辅助育种技术作为这一变革中的核心技术之一,正以其精准、高效的特点࿰…...

自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现
自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 【下载地址】自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 本项目提供了一个完整的工程代码,用于实现自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现。自适应滤波器是一种能够根据环境变化自动调整滤波器参数…...

别再死记硬背!用Python+Verilog双视角图解2ASK/2FSK调制解调原理
PythonVerilog双视角图解2ASK/2FSK调制解调原理 通信工程的学习者常常陷入理论公式与硬件实现之间的认知断层。当教科书上的数学表达式突然变成硬件描述语言时,那种手足无措的感觉我深有体会——三年前第一次接触Verilog实现调制解调时,盯着代码里那些分…...

网易云音乐API深度解析:模块化接口开发与实战应用指南
网易云音乐API深度解析:模块化接口开发与实战应用指南 【免费下载链接】NeteaseCloudMusicApiBackup 项目地址: https://gitcode.com/gh_mirrors/ne/NeteaseCloudMusicApiBackup 在当今音乐应用开发领域,后端服务的稳定性和可扩展性至关重要。网…...

手把手教你用CT107D板子复现蓝桥杯省赛题:光敏传感器触发与长按按键的实战编程
从零实现CT107D光敏传感与长按按键:蓝桥杯省赛级开发指南 硬件准备与环境搭建 打开CT107D开发板的包装盒时,那股新电路板特有的松香味总是让人兴奋。作为蓝桥杯官方指定平台,这块板子集成了我们需要的所有外设模块。先找到板子右下角的光敏…...

终极SQLite数据库管理指南:DB Browser for SQLite完整使用手册
终极SQLite数据库管理指南:DB Browser for SQLite完整使用手册 【免费下载链接】sqlitebrowser Official home of the DB Browser for SQLite (DB4S) project. Previously known as "SQLite Database Browser" and "Database Browser for SQLite&quo…...

如何扛住十万级流量洪峰?扒开高并发架构的五层防御体系
在互联网的残酷战场上,流量既是黄金,也是洪水。试想这样一个场景:你们公司花重金请了一位顶流代言人,晚上 8 点准时开启一场“一元秒杀”活动。时间一到,原本平时只有几百 QPS(每秒请求数)的系统…...

3分钟解决游戏操作冲突:Hitboxer SOCD工具让你的键盘操作职业化
3分钟解决游戏操作冲突:Hitboxer SOCD工具让你的键盘操作职业化 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在玩《街头霸王6》时连招总是失败?或者在《Apex英雄》中急停转向时…...

Taotoken的用量看板如何帮助团队清晰管理AI模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的用量看板如何帮助团队清晰管理AI模型调用成本 作为团队的技术负责人,我的一项重要职责是确保技术投入的每一…...