论文阅读 - Detecting Social Bot on the Fly using Contrastive Learning

目录
摘要:
引言
3 问题定义
4 CBD
4.1 框架概述
4.2 Model Learning
4.2.1 通过 GCL 进行模型预训练
4.2.2 通过一致性损失进行模型微调
4.3 在线检测
5 实验
5.1 实验设置
5.2 性能比较
5.5 少量检测研究
6 结论
https://dl.acm.org/doi/pdf/10.1145/3583780.3615468
摘要:
社交机器人检测正在成为社会安全领域广泛关注的任务。一直以来,社交机器人检测技术的发展都因缺乏高质量的标注数据而受到阻碍。此外,人工智能生成内容(AIGC)技术的快速发展正在极大地提高社交机器人的创造力。例如,最近发布的ChatGPT[2]可以以74%的概率欺骗最先进的人工智能文本检测方法[3],这给基于内容的机器人检测方法带来了巨大的挑战。为了解决上述缺点,我们提出了一种对比学习驱动的社交机器人检测框架(CBD)。 CBD 的核心特点是两阶段模型学习策略:对比预训练阶段,从大量未标记的社交图中挖掘泛化模式,然后是半监督微调阶段,对潜藏在社交图中的特定任务知识进行建模,只需少量标注。上述策略赋予我们的模型在标记数据极度匮乏的情况下具有良好的检测性能。在系统架构方面,我们提出了智能反馈机制以进一步提高检测性能。对真实机器人检测数据集的综合实验表明,对于使用很少(5 个镜头)标记数据的少镜头机器人检测,CBD 始终大幅优于 10 个最先进的基线。 CBD已上线:robot-monitor
引言
大规模多媒体社交网络的普及使人们更多地参与日常生活。因此,人们不可避免地会受到社交网络的影响。与此同时,人工智能(AI)的快速发展在许多领域取得了惊人的成就,但也带来了挑战,例如恶意社交机器人。社交机器人是在社交媒体上自主通信的软件代理[43],而人工智能驱动的恶意机器人越来越多地在社交媒体上像人类一样思考、交谈和社交,这被用来从事破坏活动。在过去的十年中,恶意机器人被证明可以传播虚假信息和虚假新闻来影响公众情绪和股市[36, 37]。在COVID-19大流行期间,机器人被发现传播错误信息,例如质疑COVID-19的威胁、宣扬反疫苗阴谋论等,严重影响疫情防控[38, 49]。研究人员还发现,机器人被用来参与俄罗斯-乌克兰信息战[19]并干扰全国选举[44],即机器人被用来扰乱选举并攻击对手,例如2017年的法国大选总统选举[11]、2018年美国中期选举[47]等。马斯克斥资440亿美元收购Twitter的计划一度被终止,因为他质疑Twitter首席执行官声称的不到5%的虚假账户的准确性[40]。社交机器人带来的这些威胁严重危害社会安全。因此,迫切需要高效、有效的社交机器人检测方法来促进社会的和平与安全。
在社交机器人检测的早期阶段,常用的机器人检测方法是基于特征的,即根据用户属性[48]、推文特征[15]、行为特征[34]等从专家知识和统计信息构建特征。然而,基于特征的方法很容易受到基于对抗策略的特征的影响,即机器人创建者可以通过伪造特征来逃避检测[7]。由于社交机器人通常通过传播虚假信息来进行恶意活动,因此研究人员基于快速发展的自然语言处理(NLP)技术提出了基于内容的方法,利用内容挖掘技术来识别真实性和意图。例如,Kudugunta 等人[24] 使用长短期记忆(LSTM)处理推文并检测社交机器人。然而,大规模语言模型(LLM)的快速发展和应用使社交机器人具有更强的内容创造能力。例如,对于由 ChatGPT 生成的文本,只有 26% 的文本可以被识别[3],从而降低了基于内容的检测方法的性能。最近,由于图神经网络(GNN)在处理非欧几里得空间数据(如社交网络)方面的优越性,基于图的模型(如[ 9 ]、[ 4 ]等)被提出用于检测社交机器人,并有望解决复杂网络下的机器人群组攻击等问题。然而,近年来社交机器人的发展速度非常快[7],这导致高质量的标记数据非常稀缺。这使得传统监督模型(也包括基于 GNNs 的模型)无法满足训练需求成为一大挑战。换句话说,标签稀缺问题阻碍了bot检测的发展,使得有监督模型容易受到新社交bot的影响。
为了应对上述挑战,我们提出了一种对比学习驱动的社交bot检测框架(CBD),该框架由离线训练和在线检测两部分组成,支持少量学习。具体来说,它在预训练阶段采用图对比学习(只需使用未标记数据来学习包含语义信息的节点表征)来学习有价值的知识,并在微调阶段采用一致性损失来提高模型在标记数据极少的情况下的性能。
对于 CBD 的系统架构,我们提出了一种智能反馈策略,以进一步提高检测性能。因此,通过采用 CBD,只需要少量的标签数据(少量学习)就可以学习到足够的知识,并建立一个具有良好准确性的bot检测平台。而当遇到未知类型的bot时,我们的模型可以通过比较它们与已知类型社交账号的差异来增强效果,从而获得有效的检测结果。当然,预训练的特征提取器还可以与其他模型相结合,以提高其性能。我们将主要贡献总结如下:
我们提出了对比学习驱动的社交机器人检测框架--CBD,该框架支持少量学习,由两部分数据交互组成:离线训练和在线检测。
对于 CBD 的检测模型,我们在预训练阶段采用对比学习,从未标明的数据中提取有价值的知识;在微调阶段采用一致性损失,在标注数据极度缺乏的情况下提高检测性能。
在一个全面的社交bot检测数据集上进行的广泛实验证明了对比学习方法和一致性损失在社交bot检测中的有效性,以及 CBD 与最先进的基线模型相比的优越性。
3 问题定义
社交网络可以自然地表示为有向图 G = (V, E),其中 V = {v1, v2, ..., vN} 是社交网络中用户帐户组成的节点集,E ⊂ V × V 是描述用户之间关注关系的有向边集。节点的邻居集合表示为 。令 X = [x1, x2, . , xN ]⊤∈RN ×d 表示节点特征矩阵,G的第i个节点的特征向量可以表示为
,d表示特征维度。我们用 A∈R N×N 表示邻接矩阵,每个元素 A_ij = 1 表示节点 之间存在一条边,否则 A_ij = 0。D∈R N×N 是 A 的对角度矩阵,其中 D_ii =
在本文中,社交bot检测可被视为一项二元分类任务,其目标是预测给定的社交账号v_i∈ V 是否是社交bot。更正式地说,节点的标签向量表示为 Y∈{0, 1} ,其中 Y∈{0, 1} 表示基本事实。 这里,Y = 1 表示是社交bot,否则 Y = 0。因此,bot检测模型的工作是学习一个函数:(G,X)-→ Y。
4 CBD
4.1 框架概述
图 1 显示了 CBD 的架构,包括离线训练和在线检测。该框架通过离线训练和在线检测之间的持续数据交互,实现了实时bot检测和智能反馈。框架的工作流程介绍如下

离线训练。这部分主要负责数据预处理和模型训练两大功能。数据预处理包括数据采集、整合和存储,数据源涵盖 Twitter、微博等几大社交网络。具体来说,它提供了数据采集工具、信息处理方法和数据持久化组件,所有这些组件都可以分布式部署。模型训练包括预训练和微调,可采用不同的训练策略.
在线检测。这部分提供对社交机器人的在线实时检测,并处理用户提交的反馈。具体来说,注册用户可以针对可疑的检测结果向系统提交反馈。如果反馈通过,则会在检测结果数据库中更新,从而为模型的微调提供基于反馈的注释数据。
在线检测模型会定期从离线端更新,以确保模型学到的最新知识能及时应用到实时检测中。除了网页端检测,它还提供bot检测应用程序接口(API),开发人员可以利用这些应用程序接口为自己的应用程序提供bot检测功能。
4.2 Model Learning
模型学习在我们的框架中扮演着核心角色,其目的是从收集到的数据中挖掘潜在的模式来检测社交机器人。如图 1 右上方所示(深色背景突出显示),模型训练包括两个阶段(如图 2 所示):模型预训练和模型微调。前者是基于历史非标注数据的对比学习过程;后者则采用半监督式微调过程,利用基于标注数据的在线反馈注释信息。这种两阶段模型训练设计使我们的框架能够同时受益于大规模未标注数据和动态增量标注数据,从而使其具有良好的性能。下面我们将详细介绍这两个学习阶段。
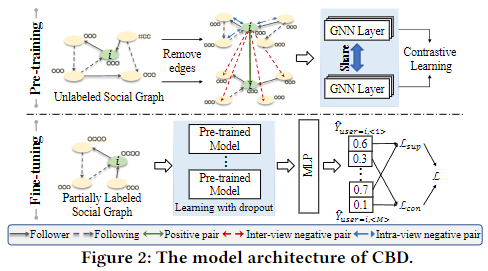
4.2.1 通过 GCL 进行模型预训练
CBD 的预训练阶段遵循 GCL 的通用范式,即通过最大化来自同一输入图的两个不同视图之间的表征 MI 来实现自我监督。具体来说,两个图视图是通过对输入图随机执行数据增强而生成的。然后,优化对比目标,强制同一节点的增强表示相互一致,但与其他节点的表示不同 .
图增强 对于输入的社交图 G = (X,A),通过从 G 中删除边,生成两个视图 ![]() ,其中
,其中 ![]() 表示第m个视图的相邻矩阵。然后将两个视图输入 GNN 编码器,生成它们的表示。具体来说,对于
表示第m个视图的相邻矩阵。然后将两个视图输入 GNN 编码器,生成它们的表示。具体来说,对于 ,第l个 GNN 层的过程可以简化为
![]() ,其中表示 ReLU 激活;
,其中表示 ReLU 激活;![]() 是采用重正化技巧的卷积信号矩阵[22],
是采用重正化技巧的卷积信号矩阵[22], 是
的对角度矩阵。
![]() 代表
代表 的第 l 层节点表示,特别是
![]() .通过迭代执行
.通过迭代执行 ![]() L次,我们获得编码表示:
L次,我们获得编码表示:
![]()
对比目标。通过两个视图表示法 H(1)和 H(2),对比目标用于区分同一节点的表示法和其他节点的表示法。具体来说,对于节点来说,它在两个视图 H(1)和 H(2)中的表示构成一对正样本,而其他节点在两个视图中的表示被视为负样本。那么正样本对的 InfoNCE 损失[29]计算公式为
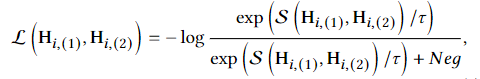
其中,S (-, -) 表示两个代表之间的相似性,是温度超参数。 Neg代表负对影响,其定义为

其中,第一项和第二项分别惩罚视图内和视图间负对之间的相似性。由于两个视图是对称的,因此另一个视图的损失函数也类似。需要最小化的总体对比度目标定义为
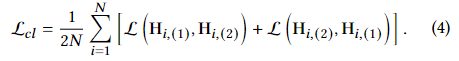
4.2.2 通过一致性损失进行模型微调
在对未标记的社交图进行预训练后,根据在线检测和反馈结果(将在第 4.3 节中详细介绍),通过对社交图进行微调,进一步增强了预训练的 GNN 模型。为此,CBD 采用了半监督一致性学习策略,旨在通过增强模型对随机性的鲁棒性来学习更有把握的表征。如图 2 下部所示,给定一个带有部分注释的社交图 G = (X,A),通过将 G 送入预先训练好的模型并随机丢弃M次,生成 G 的M种不同表示 ![]() [39]。然后,M种不同的表征被发送到 MLP,以产生相应的输出:
[39]。然后,M种不同的表征被发送到 MLP,以产生相应的输出:![]() 。然后,我们对
。然后,我们对 ![]() 进行优化,对已注释节点 Ω_a 和未注释节点 Ω_u 分别采用监督损失和置信度感知一致性损失进行优化。
进行优化,对已注释节点 Ω_a 和未注释节点 Ω_u 分别采用监督损失和置信度感知一致性损失进行优化。
监督损失。监督损失被形式化为带注释的节点在M次表征上的平均交叉熵:![]() 其中 H (·,·) 表示交叉熵函数,Y ∈ R 是节点 的 one-hot ground-truth 标签。
其中 H (·,·) 表示交叉熵函数,Y ∈ R 是节点 的 one-hot ground-truth 标签。
置信感知一致性损失。为了以半监督的方式进一步利用未注释数据背后的信息模式,我们设计了一种置信感知一致性损失,它将表示的预测与锐化的平均预测对齐。具体来说,我们计算平均预测并使用以下公式对其进行锐化:![]()
其中,Normalize(-) 将非负矩阵的每一行归一化为合法分布,并代表锐化系数,即系数越小,分布越锐利。有了锐化后的平均预测值
,置信度感知一致性损失会将所有预测值与置信度阈值
∈ [0, 1] 以上的
保持一致:
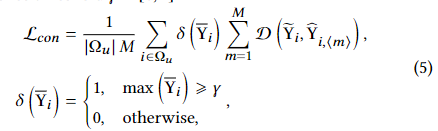
其中 D (-, -) 可以是任何距离度量,如 KL 散度和 L2 准则。指示函数 会过滤掉所有置信度较低的
,以降低误差风险。
因此,结合 ![]() 会产生最终的微调损失:
会产生最终的微调损失:![]() ,其中
,其中 是权衡超参数。算法2总结了模型微调的过程。

4.3 在线检测
在线检测模块提供实时社交僵尸检测和智能反馈两大功能,由在线管理器和在线检测模型两大部分管理。其工作流程和实现原理介绍如下
实时社交机器人检测。当用户在社交活动中遇到可疑账号时,可以在检测网页的文本框中输入该账号,然后提交检测。在线管理器收到并识别该账号检测请求后,首先从检测结果数据库中查询该账号的检测结果。如果找不到结果,它将重新向数据提供者查询账户数据,并向在线检测模型进行在线检测。具体来说,构建包含目标账户的社交图谱 G,并将其输入在线检测模型进行检测。在线检测模型利用社交图 G 检测目标账户及其邻居,并返回检测结果.
智能反馈。除了实时检测,在线模块还提供智能反馈,以进一步提高检测性能,图 1 中的蓝线就是智能反馈的标志。当注册用户对检测结果有疑问时,可以就某个账号是否为社交僵尸的概率提出反馈意见。然后,在线管理员会收到这些反馈,并由系统和人工进行审核。如果审核通过,反馈结果将被更新到检测结果数据库中。同时,反馈结果将用于离线微调,以便更新检测模型,获得更准确的结果。
5 实验
5.1 实验设置
数据集。我们的模型在 TwiBot-22 [ 10] 上进行了评估,在该数据集中,我们随机选取了 81,433 个人类作为正例,81,432 个机器人作为负例,以保持它们的比例相对平衡,从而得到了 162,865 个社交账号。我们随机将训练集、验证集和测试集按 7:2:1 的比例进行划分,以确保比较实验的公平性。
基线。为了构建 CBD 模型,我们选择了两个具有代表性的基于 GNNs 的模型 GCN [ 22] 和 GIN [ 45 ] 作为编码器,并在实验中将它们与十个基线模型进行比较。这些基线模型包括五个通用 GNN: GCN [ 22]、GAT [42]、JKNet (GCNJK) [46]、APPNP [23]、R-GCN [35];四种最新方法: LINKX[28]、MixHop[1 ]、GPR-GNN[6 ]、H2GCN[50];一种具有异质性的僵尸检测方法: Feng等人[ 9 ]。所有实验都使用了相同的输入特征,包括用户的 1) 用户属性:用户名、描述、位置、注册时间、验证状态、关注数、粉丝数、列表数、推文数;2) 内容信息:推文内容、评论;3) 社交关系信息:关注者和粉丝的好友列表;4) 社交关系信息:关注者和粉丝的好友列表;5) 社交关系信息:关注者和粉丝的好友列表;6) 社交关系信息:关注者和粉丝的好友列表;7) 社交关系信息:关注者和粉丝的好友列表。
实施细节。基于社交网络的交互特性,我们将社交数据构建为有向图。实验采用 AdamW 优化器 [ 21 ] 进行训练和优化。预训练阶段的学习率和权重衰减分别为 10-3 和 10-5。在微调阶段,我们采用权重衰减为 3 × 10-5 的分层学习率策略,其中预训练 GNN 层的学习率设置为 10-4,其他层的学习率设置为 10-3。为了避免过拟合,我们在训练时使用了 dropout [39] 和早期停止技术。
网格搜索用于找到 CBD 预测的最佳超参数。具体来说,该模型在三个编码通道上采用了两个隐藏层,隐藏层大小为 512.锐化参数、可信阈值和一致性损失的距离函数分别设为 0.3、0.6 和 L2 准则。其他基线方法的模型配置沿用了之前的研究[9, 28 , 35]。F1 分数、准确率和 ROC-AUC 用于评估我们的模型和基线模型。我们使用 PyTorch Geometric(MIT 许可)[12] 和 PyTorch(BSD 许可)[30]来实现实验,所有实验均在 Tesla A100 GPU(80GB 内存)上进行。
5.2 性能比较
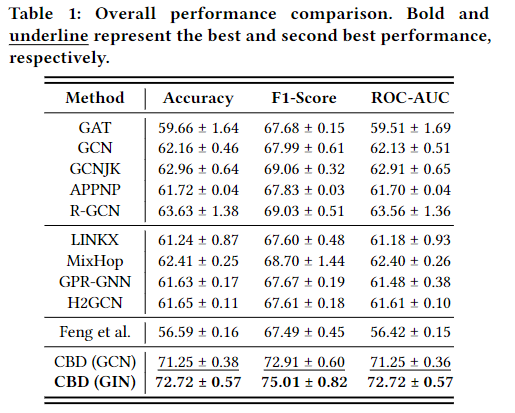
在比较实验中,我们对每个实验进行 5 次随机权重初始化,并报告测试集上的平均值和标准偏差,其中 CBD 与 10 个基线模型进行了比较。实验结果如表 1 所示。从测试结果来看,我们的模型达到了最先进的僵尸检测性能,此外,使用 GIN 作为编码器的模型的性能优于使用 GCN 作为编码器的模型,达到了前 2 名的性能。
5.5 少量检测研究
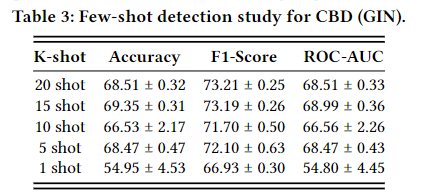
对于新的社交机器人,只能获得很少的标签。有鉴于此,我们进一步探讨了 CBD 的少量检测能力。具体来说,我们只从训练集中随机抽取每个类别的标签来微调模型,然后在测试集中进行测试。表 3 显示了实验结果。不出所料,当取值减小到 1 时,即单次检测时,性能下降,方差增大。 然而,随着k增加,其性能呈上升趋势,并且可以超越所有每个类别只有五个标签的基线模型(五次检测),这归功于预训练阶段从未标记数据中学到的宝贵知识以及一致性损失进一步减少了依赖在微调阶段的标签上。
6 结论
本文研究了社交机器人检测任务,该任务面临着标签数据缺乏和 LLM 导致机器人内容创作能力不断增强的挑战。为了解决这些难题,我们提出了 CBD,它在预训练中采用对比学习,从无标签数据中提取有价值的知识;在微调中采用一致性损失,进一步减少对标签的依赖,从而在标签数据极度匮乏的情况下,在算法层面提高模型性能。此外,在系统架构层面,还采用了智能反馈策略来进一步提高检测性能。广泛的实验表明,在一个全面的僵尸检测基准上,CBD 始终优于最先进的基准模型。其他研究进一步证明了我们模型的有效性。到目前为止,我们已经在线部署了 CBD,并得到了广泛关注和使用。据我们所知,CBD 目前在谷歌和百度搜索中排名第一。我们希望我们的框架能帮助人们免受社交机器人及其传播的错误信息的影响,从而创建一个更安全的社交网络。
相关文章:
论文阅读 - Detecting Social Bot on the Fly using Contrastive Learning
目录 摘要: 引言 3 问题定义 4 CBD 4.1 框架概述 4.2 Model Learning 4.2.1 通过 GCL 进行模型预训练 4.2.2 通过一致性损失进行模型微调 4.3 在线检测 5 实验 5.1 实验设置 5.2 性能比较 5.5 少量检测研究 6 结论 https://dl.acm.org/doi/pdf/10.1145/358…...
)
PaddleMIX学习笔记(1)
写在前面 之前对HyperLedger的阅读没有完全结束,和很多朋友一样,同时也因为工作的需要,最近开始转向LLM方向。 国内在大模型方面生态做的最好的,目前还是百度的PaddlePaddle,所以自己也就先从PP开始看起了。 众所周知…...
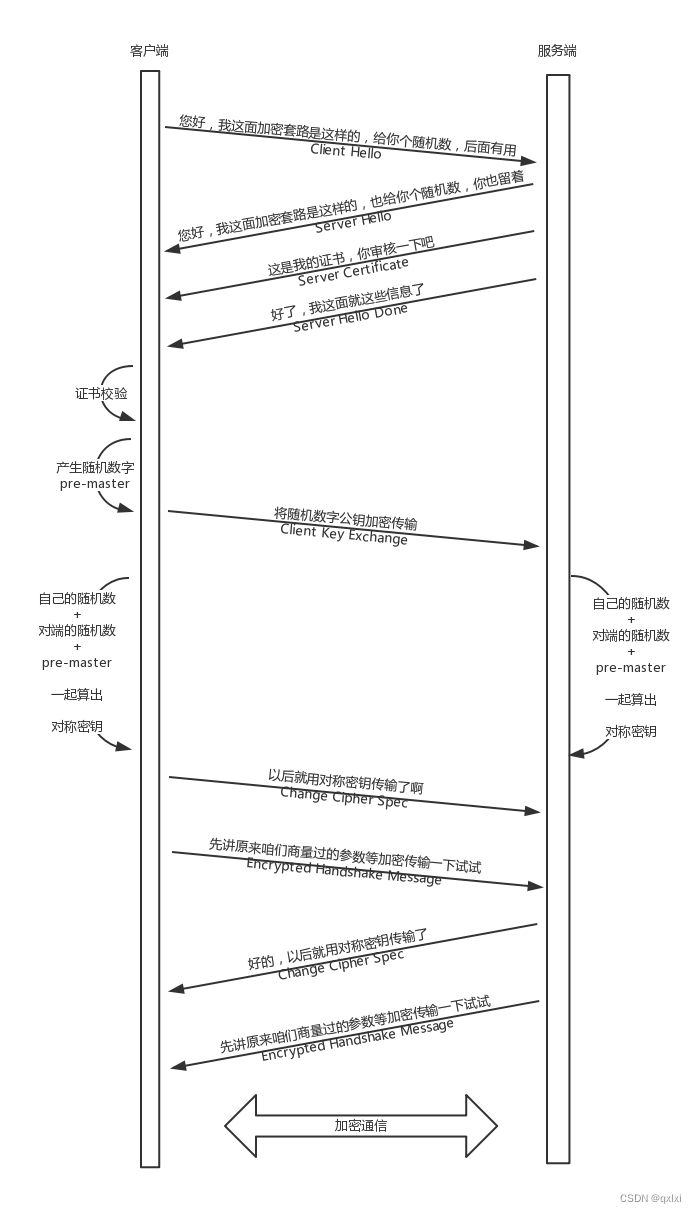
【网络协议】聊聊HTTPS协议
前面的文章,我们描述了网络是怎样进行传输数据包的,但是网络是不安全的,对于这种流量门户网站其实还好,对于支付类场景其实容易将数据泄漏,所以安全的方式是通过加密,加密方式主要是对称加密和非对称加密。…...

2023.11.2事件纪念
然而造化又常常为庸人设计,以时间的流逝,来洗涤旧迹,仅以留下淡红的血色和微漠的悲哀。 回顾这次事件,最深的感触就是什么是团队的力量! 当我们看到希望快要成功的时候,大家洋溢出兴奋开心的表情,一起的欢声笑语;但看…...

Scala和Play WS库编写的爬虫程序
使用Scala和Play WS库编写的爬虫程序,该程序将爬取网页内容: import play.api.libs.ws._ import scala.concurrent.ExecutionContext.Implicits.global object BaiduCrawler {def main(args: Array[String]): Unit {val url ""val proxy…...
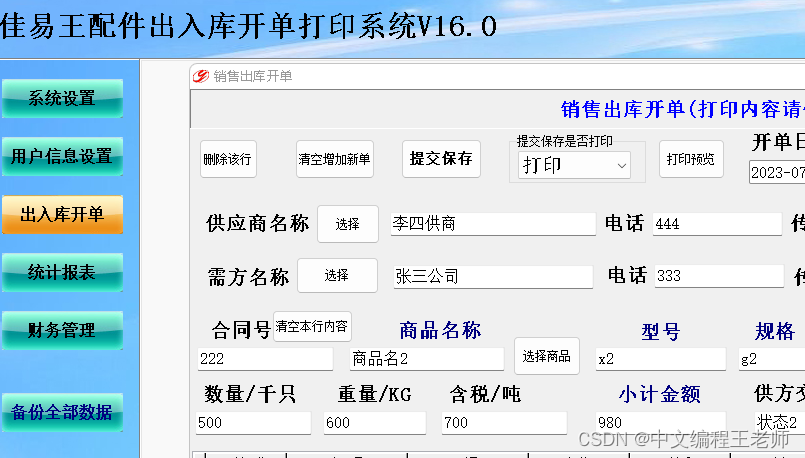
佳易王配件进出库开单打印进销存管理系统软件下载
用版配件进出库开单打印系统,可以有效的管理:供货商信息,客户信息,进货入库打印,销售出库打印,进货明细或汇总统计查询,销售出库明细或汇总统计查询,库存查询,客户往来账…...
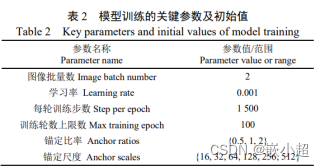
【深度学习基础】专业术语汇总(欠拟合和过拟合、泛化能力与迁移学习、调参和超参数、训练集、测试集和验证集)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
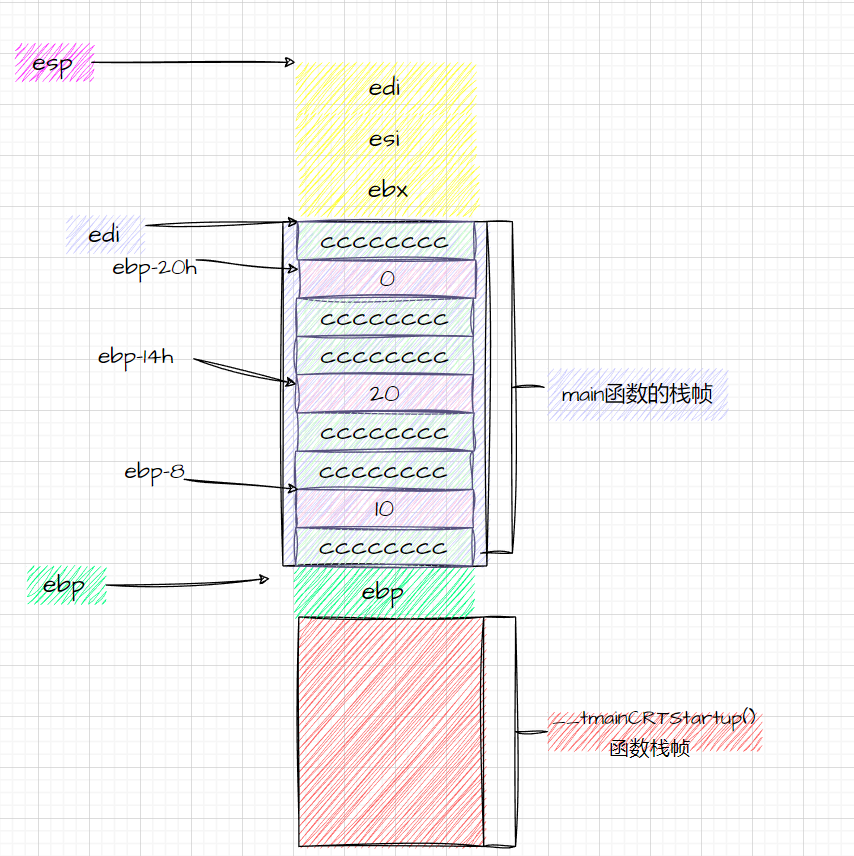
【C语言:函数栈帧的创建与销毁】
文章目录 前言一、前期准备1.寄存器2.汇编指令3.测试代码 二、解开函数栈帧的神秘面纱1.栈帧大体轮廓2.main函数栈帧的创建3.main函数内执行有效代码4.烫烫烫5.函数参数的传递6.add函数栈帧的创建7.add函数内执行有效代码8.add是如何获得参数的9. add函数栈帧的销毁10.main函数…...

怎么在C++中实现云端存储变量
随着云计算技术的快速发展,现在我们可以将数据存储在云端,以便于在不同设备和地点访问。在C中,我们也可以通过一些方法来实现这个功能。本文将详细介绍如何在C中实现云端存储变量。 首先,我们需要理解,C本身并没有直接…...

短视频矩阵营销系统工具如何助力商家企业获客?
1.批量剪辑技术研发 做的数学建模算法,数学阶乘的组合乘组形式,采用两套查重机制,一套针对素材进行查重抽帧素材,一套针对成片进行抽帧素材打分制度查重,自动滤重计入打分。 2.账号矩阵分发开发 多平台,…...

PCL 计算一个平面与包围盒体素的相交线
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 基于之前计算的包围盒体素(PCL 包围盒体素化显示),这里使用一个平面与其进行相交,并求出与其中体素单元的相交线。 二、实现代码 //标准文件 #include <iostream> #include <thread>//PCL...

面向教育的计算机视觉和深度学习5
面向教育的计算机视觉和深度学习5 1. 好处智能内容(Smart Content)任务自动化(Task Automation)缩小技能差距(Closing Skill Gap) 2. 应用程序学生学习与福利(Student Learning and Welfare&…...

FPGA芯片内部结构
参考链接:FPGA的进阶之第二章FPGA芯片内部结构(2)...
人工智能AI创作系统ChatGPT网站系统源码+AI绘画系统支持GPT4.0/支持Midjourney局部重绘
一、前言 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建…...

Google 开源项目风格指南
目录 C 风格指南 Objective-C 风格指南 Python 风格指南 Shell 风格指南 TypeScript 风格指南 Javascript 风格指南 HTML/CSS 风格指南 C 风格指南 C 风格指南 - 内容目录 — Google 开源项目风格指南 Objective-C 风格指南 Objective-C 风格指南 - 内容目录 — Googl…...

无限上下文,多级内存管理!突破ChatGPT等大语言模型上下文限制
目前,ChatGPT、Llama 2、文心一言等主流大语言模型,因技术架构的问题上下文输入一直受到限制,即便是Claude 最多只支持10万token输入,这对于解读上百页报告、书籍、论文来说非常不方便。 为了解决这一难题,加州伯克利…...

学习剑指jvm
一直弱,jvm 1、主要解决运行状态的线上系统突然卡死,造成系统无法访问,甚至直接内存溢出异常(Out of Memory,OOM) 2、希望解决线上JVM垃圾回收的相关问题,但无从下手。 3、新项目上线,对设置…...
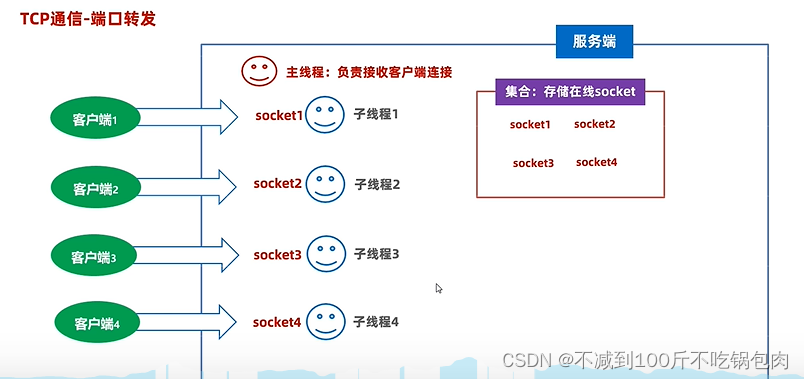
java网络通信
浏览器中输入:“www.woaijava.com”之后都发生了什么? 请详细阐述 由域名→IP地址 寻找IP地址的过程依次经过了浏览器缓存、系统缓存、hosts文件、路由器缓存、 递归搜索根域名服务器。 建立TCP/IP连接(三次握手具体过程) 由浏览…...

Three.js之加载外部三维模型
参考资料 建模软件绘制3D场景…加载.gltf文件(模型加载全流程) 知识点 注:基于Three.jsv0.155.0 三维建模软件gltf格式加载.gltf文件 三维建模软件 D美术常用的三维建模软件,比如Blender、3dmax、C4D、maya等等 Blender(轻量开源)3dmaxC4Dmaya 特…...

【机器学习】正规方程与梯度下降API及案例预测
正规方程与梯度下降API及案例预测 文章目录 正规方程与梯度下降API及案例预测1. 正规方程与梯度下降正规方程(Normal Equation)梯度下降(Gradient Descent) 2. API3. 波士顿房价预测 1. 正规方程与梯度下降 回归模型是机器学习中…...

HDRP光照性能优化:探针体内存、阴影贴图与反射烘焙的底层控制
1. 这不是又一个“灯光插件”,而是HDRP光照工作流的手术刀我第一次在客户项目里看到UPGEN Lighting HDRP,是在一个实时虚拟制片场景的紧急优化现场。美术总监指着渲染帧率从28fps掉到14fps的监控面板说:“灯光一开,GPU就喘不上气—…...

GOM三维扫描在GDT分析中的应用:几何公差评价为何越来越依赖全场数据
随着工业产品结构复杂度持续提高,传统基于尺寸链的质量控制方式正在逐步向几何公差控制体系演进。尤其在汽车制造、精密模具、航空零部件及新能源结构件等领域,产品质量评价已不仅取决于尺寸是否符合要求,更关注零件在真实装配条件下的几何状…...
)
毕业设计 深度学习车道线检测(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV56 数据集处理7 模型训练8 最后 0 前言 🔥这两年开始毕业设计和毕业答辩的要求和难度不断…...

ChatGPT-web-midjourney-proxy 项目常见问题解决方案
ChatGPT-web-midjourney-proxy 项目常见问题解决方案 1. 项目基础介绍和主要编程语言 ChatGPT-web-midjourney-proxy 是一个开源项目,它基于 ChatGPT 和 Midjourney-proxy 技术构建,提供了丰富的文生图、图生文、文生视频等功能。该项目支持自定义 API k…...

LicenseFinder高级配置指南:自定义许可证规则与决策继承
LicenseFinder高级配置指南:自定义许可证规则与决策继承 【免费下载链接】LicenseFinder Find licenses for your projects dependencies. 项目地址: https://gitcode.com/gh_mirrors/li/LicenseFinder LicenseFinder是一款强大的开源许可证管理工具…...

长期使用后回顾 Taotoken 在 API 调用稳定性与客服响应上的综合体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后回顾 Taotoken 在 API 调用稳定性与客服响应上的综合体验 作为一项服务于项目开发的基础设施,大模型 API 的…...

深度解析AI游戏瞄准辅助:从YOLOv10模型到实时视觉识别的完整技术架构
深度解析AI游戏瞄准辅助:从YOLOv10模型到实时视觉识别的完整技术架构 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 在当今FPS游戏竞技领域,AI瞄准辅助技术…...
)
限时开放!ElevenLabs未公开东北话语音微调接口文档(含token绕过+方言embedding注入完整POC)
更多请点击: https://codechina.net 第一章:ElevenLabs东北话语音微调接口的发现与边界定义 ElevenLabs 官方 API 文档未显式标注“东北话”支持,但通过其语音克隆(Voice Cloning)与声音微调(Fine-tuning&…...

终极指南:如何在Windows上简单快速实现SSH远程文件系统挂载
终极指南:如何在Windows上简单快速实现SSH远程文件系统挂载 【免费下载链接】sshfs-win SSHFS For Windows 项目地址: https://gitcode.com/gh_mirrors/ss/sshfs-win SSHFS-Win是一个革命性的开源工具,它让你能够在Windows操作系统中通过SSH协议直…...

独立开发者如何利用Taotoken构建多模型备用方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken构建多模型备用方案 对于独立开发者而言,项目的技术栈选择与成本控制至关重要。在集成大模…...