k8s集群调度
目录
1、理论:
1.1、 概述:
1.2、Pod 是 Kubernetes 的基础单元,Pod 启动典型创建过程如下: 工作机制 ****
1.3、调度过程 ***
1.4、Predicate 有一系列的常见的算法可以使用: **
1.5、 优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。有一系列的常见的优先级选项包括:
1.6.、常见的调度约束示例:
2、实验
2.1、实例:指定调度节点:
2.2、修改成 nodeSelector 调度方式
1、理论:
1.1、 概述:
Kubernetes 是通过 List-Watch **** 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。
用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。
APIServer 经过 API 调用,权限控制,调用资源和存储资源的过程,实际上还没有真正开始部署应用。这里 需要 Controller Manager、Scheduler 和 kubelet 的协助才能完成整个部署过程。
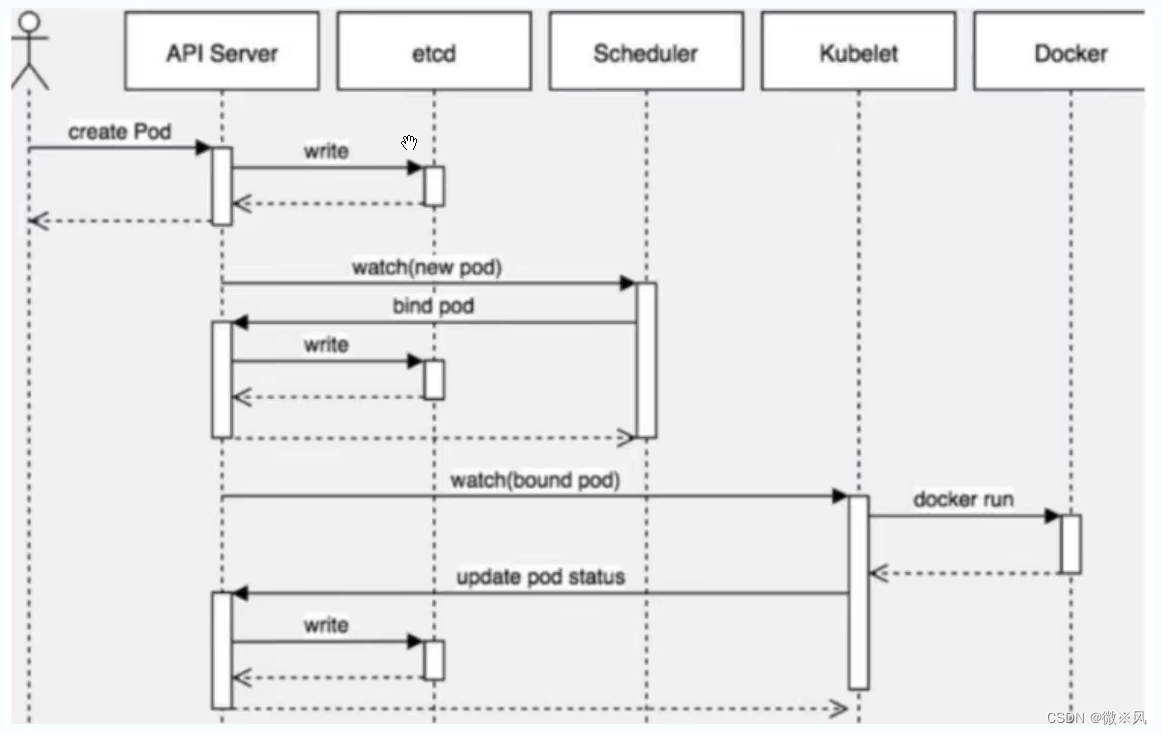
在 Kubernetes 中,所有部署的信息都会写到 etcd 中保存。实际上 etcd 在存储部署信息的时候,会发送 Create 事件给 APIServer,而 APIServer 会通过监听(Watch)etcd 发过来的事件。其他组件也会监听(Watch)APIServer 发出来的事件。
1.2、Pod 是 Kubernetes 的基础单元,Pod 启动典型创建过程如下: 工作机制 ****
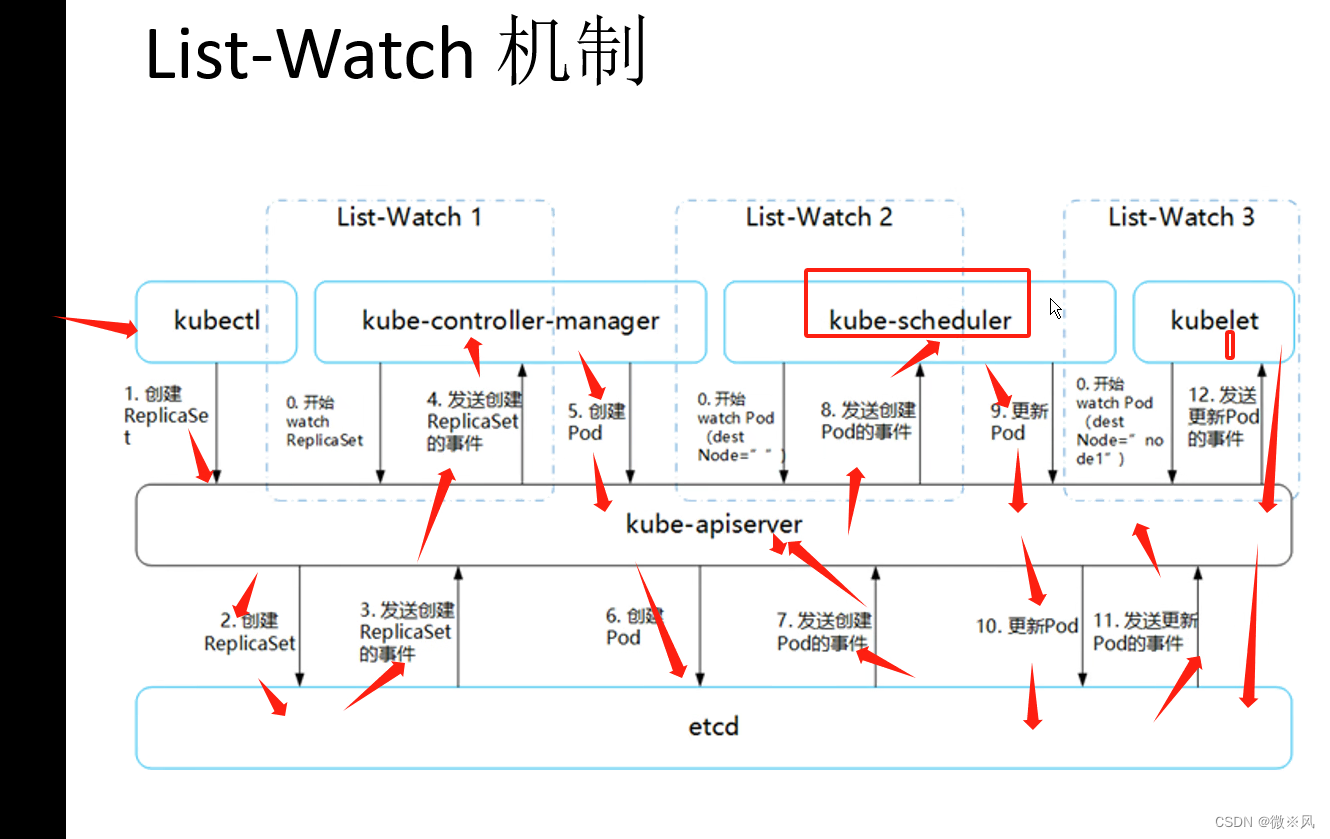
- 这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。 他们在进程已启动就会监听(Watch)APIServer 发出来的事件。
- 用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
- APIServer 尝试着将 Pod 对象的相关元信息存入 etcd 中,待写入操作执行完成,APIServer 即会返回确认信息至客户端。
- 当 etcd 接受创建 Pod 信息以后,会发送一个 Create 事件给 APIServer。
- 由于 Controller Manager 一直在监听(Watch,通过https的6443端口)APIServer 中的事件。此时 APIServer 接受到了 Create 事件,又会发送给 Controller Manager。
- Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证 Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的 Controller(PS:扩容缩容的担当)。
- 在 Controller Manager 创建 Pod 副本以后,APIServer 会在 etcd 中记录这个 Pod 的详细信息。例如 Pod 的副本数,Container 的内容是什么。
- 同样的 etcd 会将创建 Pod 的信息通过事件发送给 APIServer。
- 由于 Scheduler 在监听(Watch)APIServer,并且它在系统中起到了“承上启下”的作用,“承上”是指它负责接收创建的 Pod 事件,为其安排 Node;“启下”是指安置工作完成后,Node 上的 kubelet 进程会接管后继工作,负责 Pod 生命周期中的“下半生”。 换句话说,Scheduler 的作用是将待调度的 Pod 按照调度算法和策略绑定到集群中 Node 上。
- Scheduler 调度完毕以后会更新 Pod 的信息,此时的信息更加丰富了。除了知道 Pod 的副本数量,副本内容。还知道部署到哪个 Node 上面了。并将上面的 Pod 信息更新至 API Server,由 APIServer 更新至 etcd 中,保存起来。
- etcd 将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果。
- kubelet 是在 Node 上面运行的进程,它也通过 List-Watch 的方式监听(Watch,通过https的6443端口)APIServer 发送的 Pod 更新的事件。kubelet 会尝试在当前节点上调用 Docker 启动容器,并将 Pod 以及容器的结果状态回送至 APIServer。
- APIServer 将 Pod 状态信息存入 etcd 中。在 etcd 确认写入操作成功完成后,APIServer将确认信息发送至相关的 kubelet,事件将通过它被接受。
#注意:在创建 Pod 的工作就已经完成了后,为什么 kubelet 还要一直监听呢?原因很简单,假设这个时候 kubectl 发命令,要扩充 Pod 副本数量,那么上面的流程又会触发一遍,kubelet 会根据最新的 Pod 的部署情况调整 Node 的资源。又或者 Pod 副本数量没有发生变化,但是其中的镜像文件升级了,kubelet 也会自动获取最新的镜像文件并且加载。
1.3、调度过程 ***
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。其主要考虑的问题如下:
- 公平:如何保证每个节点都能被分配资源
- 资源高效利用:集群所有资源最大化被使用
- 效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
- 灵活:允许用户根据自己的需求控制调度的逻辑
Sheduler 是作为单独的程序运行的,启动之后会一直监听 APIServer,获取 spec.nodeName 为空的 pod,对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上。
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为预算策略(predicate);然后对通过的节点按照优先级排序,这个是优选策略(priorities);最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
1.4、Predicate 有一系列的常见的算法可以使用: **
- PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源nodeName,检查节点名称是否和 NodeName 匹配。。
- PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配。
- PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突。
- PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点。
- NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读。
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。 经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。
1.5、 优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。有一系列的常见的优先级选项包括:
- LeastRequestedPriority:通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。也就是说,这个优先级指标倾向于资源使用比例更低的节点。
- BalancedResourceAllocation:节点上 CPU 和 Memory 使用率越接近,权重越高。这个一般和上面的一起使用,不单独使用。比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,虽然 node01 的总使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,从而调度时会优选 node02。
- ImageLocalityPriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。
通过算法对所有的优先级项目和权重进行计算,得出最终的结果。
1.6.、常见的调度约束示例:
- 节点选择器(Node Selector):通过标签选择器,在Pod配置中指定要求Pod只能调度到具有特定标签的节点上。
- 亲和性与反亲和性(Affinity and Anti-Affinity):使用亲和性规则来指定Pod应该调度到哪些节点上,或使用反亲和性规则来指定Pod不应该调度到哪些节点上。
- 资源限制(Resource Limits):通过设置资源需求和限制,例如CPU和内存,来影响Pod的调度和分配。
- 互斥锁(Taints and Tolerations):通过为节点添加“污点”(Taint),然后在Pod配置中设置“容忍”(Toleration),以确保只有满足特定条件的节点能够调度Pod。
- 优先级与抢占(Priority and Preemption):通过设置Pod的优先级,以及在资源紧张时可能发生的Pod抢占规则,来调整Pod的调度顺序。
这些调度约束可以根据业务需求和集群配置进行灵活的设置,以实现对Pod调度的控制和优化。
2、实验
2.1、实例:指定调度节点:
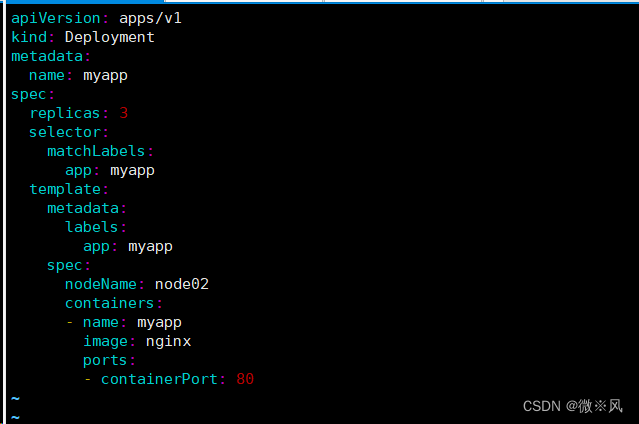
pod.spec.nodeName 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp
spec:replicas: 3selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:nodeName: node02containers:- name: myappimage: nginxports:- containerPort: 80
~ 
创建完成


由上可看出全部都在节点node02
查看详细事件(发现未经过 scheduler 调度分配)

pod.spec.nodeSelector:通过 kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,然后调度 Pod 到目标节点,该匹配规则属于强制约束
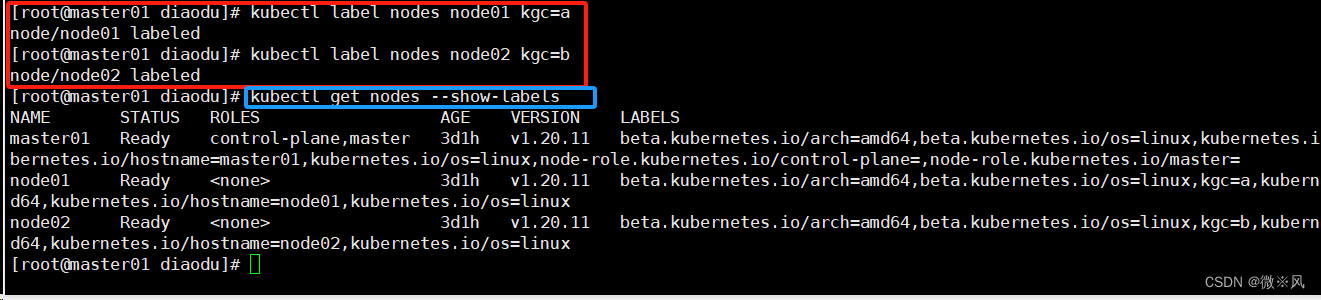
kubectl label --help
Usage:kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version] [options]
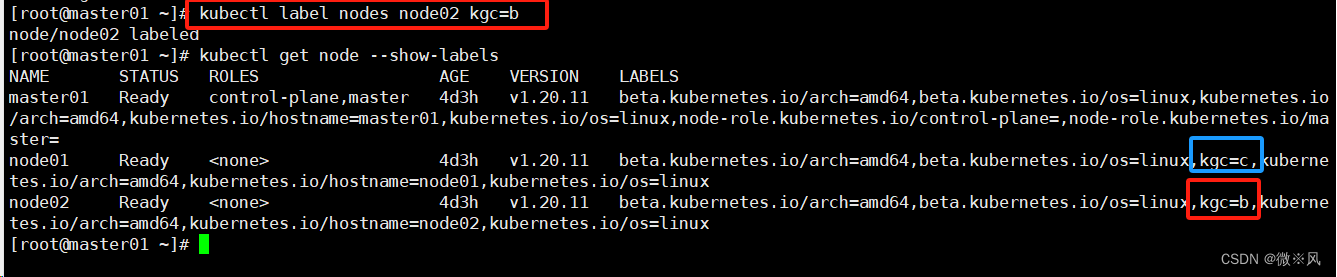
kubectl get node给对应的 node 设置标签分别为 kgc=a 和 kgc=b
2.2、修改成 nodeSelector 调度方式
apiVersion: apps/v1
kind: Deployment
metadata:labels:app myapp1name: myapp1spec:replicas: 3selector:matchLabels:app: myapp1template:metadata:labels:app: myapp1spec:nodeSelector:kgc: acontainers:- name: myapp1image: nginxports:- containerPort: 80~ 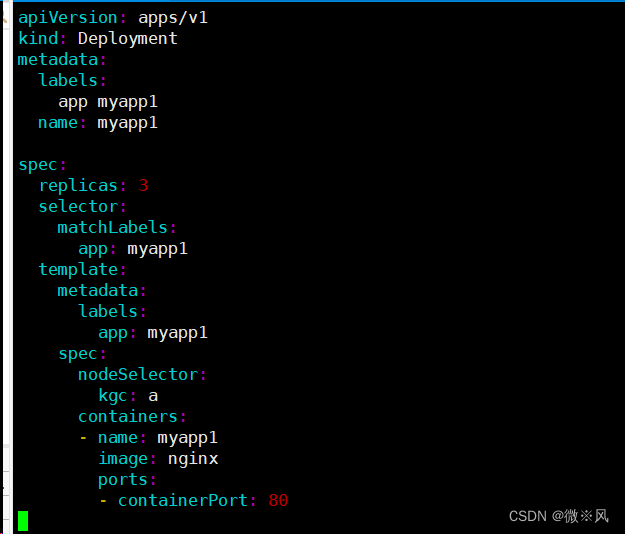

创建

kubectl get pod -o wide
查看详细事件(通过事件可以发现要先经过 scheduler 调度分配)
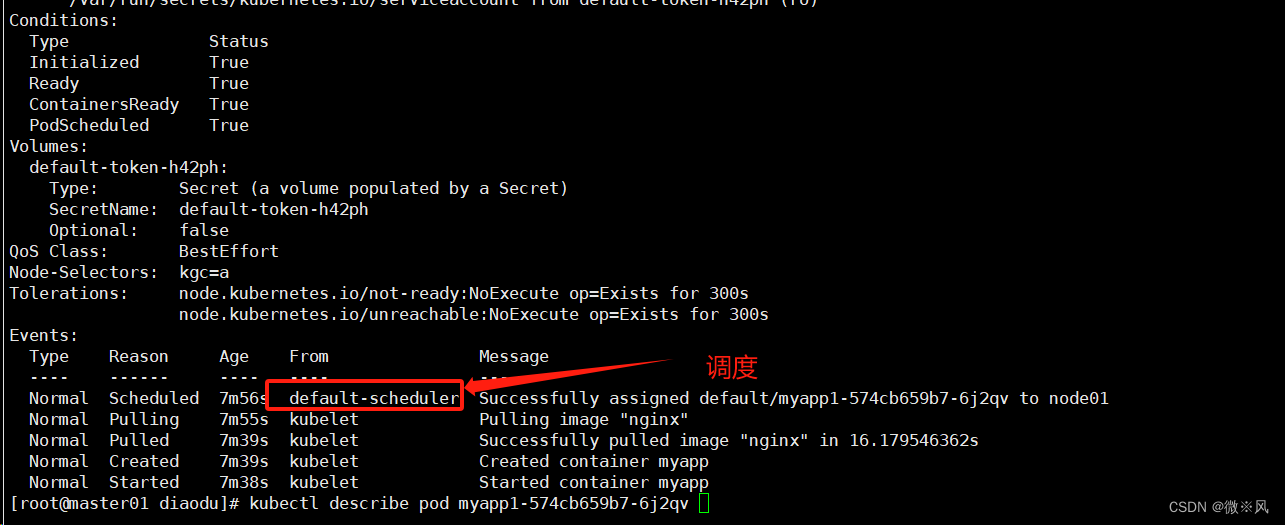

修改一个 label 的值,需要加上 --overwrite 参数
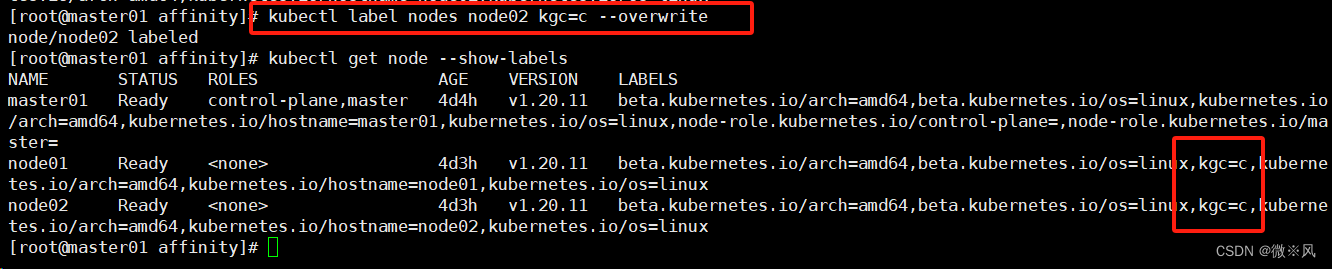
kubectl label nodes node01 kgc=c --overwrite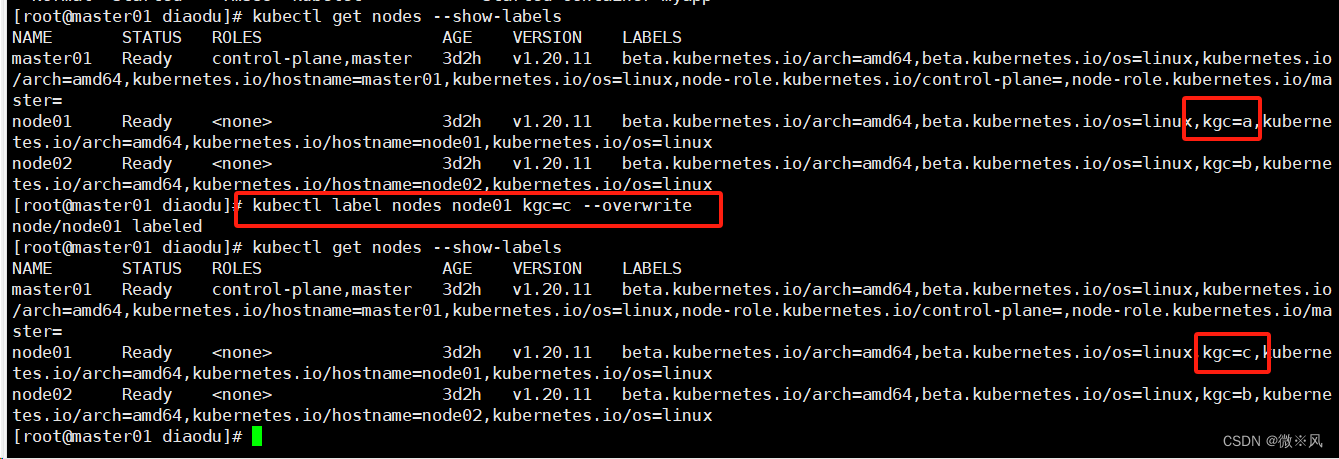
删除一个 label,只需在命令行最后指定 label 的 key 名并与一个减号相连即可:
kubectl label nodes node02 kgc- 
指定标签查询 node 节点
kubectl get node -l kgc=c
亲和性
官网:
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
节点亲和性
pod.spec.nodeAffinity
●preferredDuringSchedulingIgnoredDuringExecution:软策略
●requiredDuringSchedulingIgnoredDuringExecution:硬策略
Pod 亲和性
pod.spec.affinity.podAffinity/podAntiAffinity
●preferredDuringSchedulingIgnoredDuringExecution:软策略
●requiredDuringSchedulingIgnoredDuringExecution:硬策略
可以把自己理解成一个Pod,当你报名来学云计算,如果你更倾向去zhangsan老师带的班级,把不同老师带的班级当作一个node的话,这个就是节点亲和性。如果你是必须要去zhangsan老师带的班级,这就是硬策略;而你说你想去并且最好能去zhangsan老师带的班级,这就是软策略。
如果你有一个很好的朋友叫lisi,你倾向和lisi同学在同一个班级,这个就是Pod亲和性。如果你一定要去lisi同学在的班级,这就是硬策略;而你说你想去并且最好能去lisi同学在的班级,这就是软策略。软策略是不去也可以,硬策略则是不去就不行。
/键值运算关系
- In:label 的值在某个列表中 pending
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值.
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
实验:
硬策略:
requiredDuringSchedulingIgnoredDuringExecutionmkdir /opt/affinity
cd /opt/affinityvim pod1.yaml
apiVersion: v1
kind: Pod
metadata:name: affinitylabels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: soscscs/myapp:v1affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostname #指定node的标签operator: NotIn #设置Pod安装到kubernetes.io/hostname的标签值不在values列表中的node上values::- node02
可以通过该命令进行命令以及格式的查询
创建完成


一共两个节点,不能在node02上只有在node01上

如果硬策略不满足条件,Pod 状态一直会处于 Pending 状态。
kubectl delete pod --all && kubectl apply -f pod1.yaml && kubectl get pods -o wide
软策略
preferredDuringSchedulingIgnoredDuringExecutionapiVersion: v1
kind: Pod
metadata:name: affinity01labels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: nginxaffinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1 #如果有多个软策略选项的话,权重越大,优先级越高preference:matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- node03
软策略创建在node03节点上,但因为没有node03节点,也可以在其他节点创建
由下面可以看出来在node02节点创建,

把values:的值改成node01,则会优先在node01上创建Pod
kubectl delete pod --all && kubectl apply -f pod2.yaml && kubectl get pods -o wide
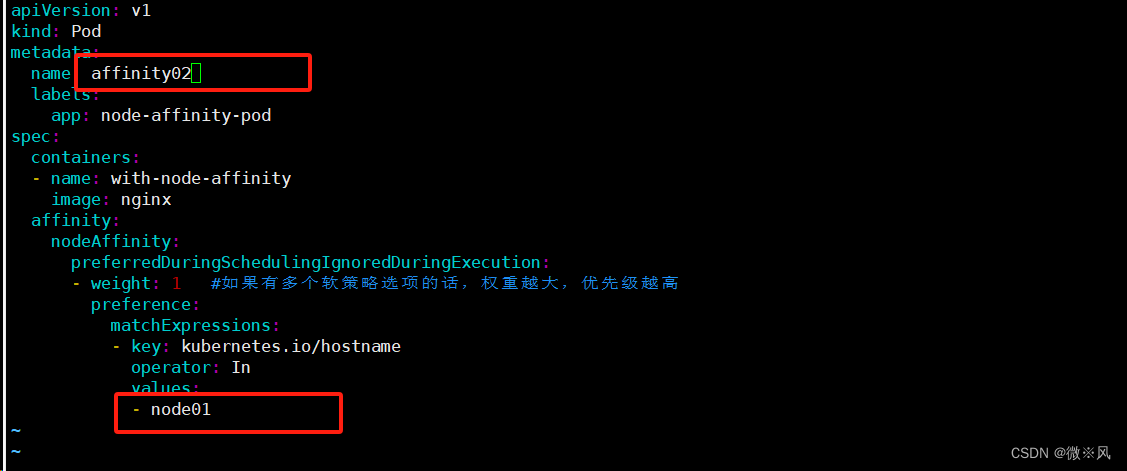

也可以通过标签来选择在那个节点上创建
如果把硬策略和软策略合在一起使用,则要先满足硬策略之后才会满足软策略
apiVersion: v1
kind: Pod
metadata:name: affinity04labels:app: node-affinity-pod
spec:containers:- name: with-node-affinityimage: nginxports:- name: httpcontainerPort: 80affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution: #先满足硬策略,排除有kubernetes.io/hostname=node02标签的节点nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- node02preferredDuringSchedulingIgnoredDuringExecution: #再满足软策略,优先选择有kgc=a标签的节点- weight: 100preference:matchExpressions:- key: kgcoperator: Invalues:- c
~
node01标签为kgc=c

创建成功

硬策略与软策略(优先级设最高),但该是硬策略优先

Pod亲和性与反亲和性
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
| nodeAffinity | 主机 | In, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod同一拓扑域 |
| podAntiAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod不在同一拓扑域 |
创建一个标签为 app=myapp01 的 Pod
apiVersion: v1
kind: Pod
metadata:name: myapp01labels:app: myapp01
spec:containers:- name: with-node-affinityimage: nginx创建


myapp01在node01节点上
使用 Pod 亲和性调度,创建多个 Pod 资源
apiVersion: v1
kind: Pod
metadata:name: myapp02labels:app: myapp02
spec:containers:- name: myapp02image: nginxaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- namespaces:- defaulttopologyKey: kgclabelSelector:matchExpressions:- key: appoperator: Invalues:- myapp01
创建完成:

由下可知,node01和node02不是同一个域,所以不能通过调度算法 进行创建,只能在node01节点上创建,

若件变迁切换为一样的,
由于node02节点资源创建的东西多,通过调度算法会有现在node01上创建

调度算法随机分配

相关文章:
k8s集群调度
目录 1、理论: 1.1、 概述: 1.2、Pod 是 Kubernetes 的基础单元,Pod 启动典型创建过程如下: 工作机制 **** 1.3、调度过程 *** 1.4、Predicate 有一系列的常见的算法可以使用: ** 1.5、 优先级由一系列键…...
Scala中类的继承、抽象类和特质
1. 类的继承 1.1 Scala中的继承结构 Scala 中继承关系如下图: Any 是整个继承关系的根节点; AnyRef 包含 Scala Classes 和 Java Classes,等价于 Java 中的 java.lang.Object; AnyVal 是所有值类型的一个标记; Nul…...

小程序如何实现登录数据持久化
在小程序中实现登录数据的持久化可以通过以下几种方式: 使用本地缓存 在用户登录成功后,将登录凭证或用户信息等数据使用 wx.setStorageSync 方法存储到本地缓存中: // 存储登录数据到本地缓存 wx.setStorageSync(token, 登录凭证); wx.set…...
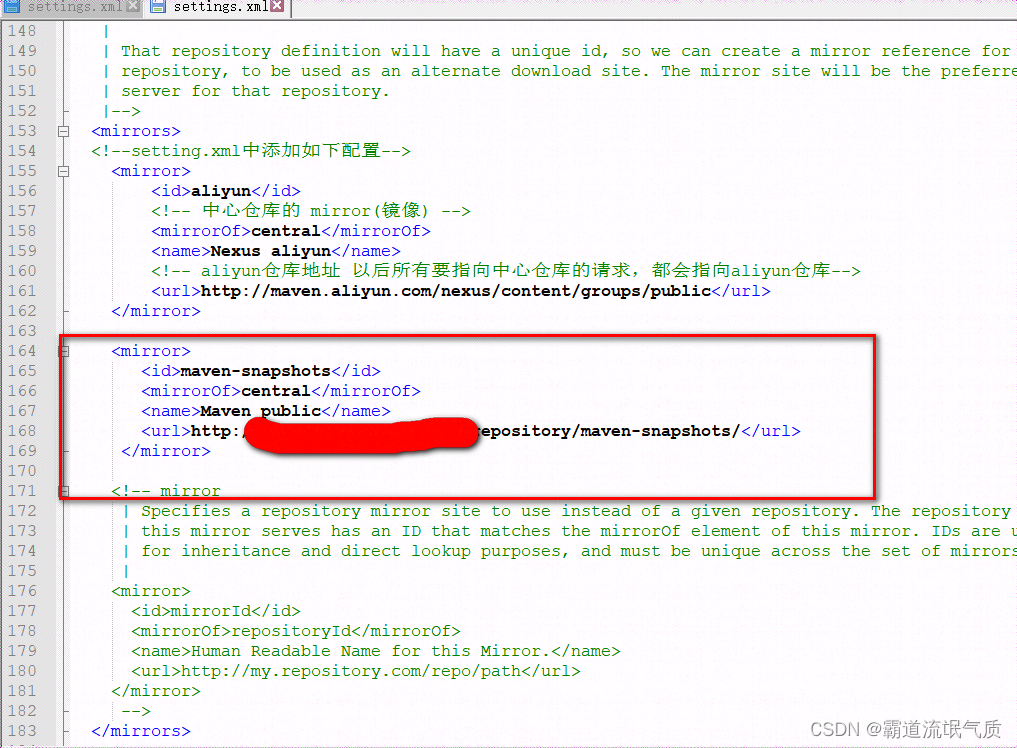
Maven本地配置获取nexus私服的依赖
场景 Nexus-在项目中使用Maven私服,Deploy到私服、上传第三方jar包、在项目中使用私服jar包: Nexus-在项目中使用Maven私服,Deploy到私服、上传第三方jar包、在项目中使用私服jar包_nexus maven-releases 允许deploy-CSDN博客 在上面讲的是…...

第02章-变量与运算符
1 关键字 关键字:被Java语言赋予了特殊含义,用作专门用途的字符串(或单词)。如class、public、static、void等,这些单词都被Java定义好了,称为关键字。 特点:关键字都是小写字母;官…...

SpringBoot数据响应、分层解耦、三层架构
响应数据 ResponseBody 类型:方法注解、类注解位置:Controller方法、类上作用:将方法返回值直接响应,如果返回值类型是 实体对象/集合 ,将会转换为json格式响应说明:RestController Controller Respons…...

go测试库之apitest
📢专注于分享软件测试干货内容,欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!📢交流讨论:欢迎加入我们一起学习!📢资源分享:耗时200小时精选的「软件测试」资…...
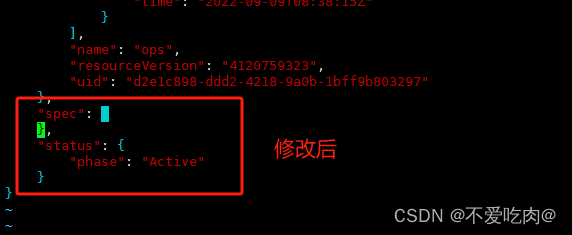
K8S删除资源后一直处于Terminating状态无法删除解决方法
原因 使用kubectl delete 删除某命名空间是一直处于Terminating状态无法删除,首先排查了该命名空间下是否还存在deployment pod等资源发现没有后,等了很久还是无法删除后发现是因为该名称空间的“finalizers”字段有值导致 Finalizer(终结器…...
jvm实践
说一下JVM中的分代回收 堆的区域划分 1.堆被分为了两份:新生代和老年代[1:2] 2.对于新生代,内部又被分为了三个区域。Eden区,幸存者区survivor(分成from和to)[8:1:1] 对象回收分代回收策略 1.新创建的对象,都会先分配到eden区 2.当伊园内存…...

redis-plus-plus访问REDIS集群
编程语言:C 开源库:redis-plus-plus 接口类:RedisCluster 初始化需要输入任意一个结点的IP和端口,如果设置了密码,还需要密码的明文并使用ConnectionOptions类。 初始化完成后可以直接进行读/写操作。 RedisClust…...
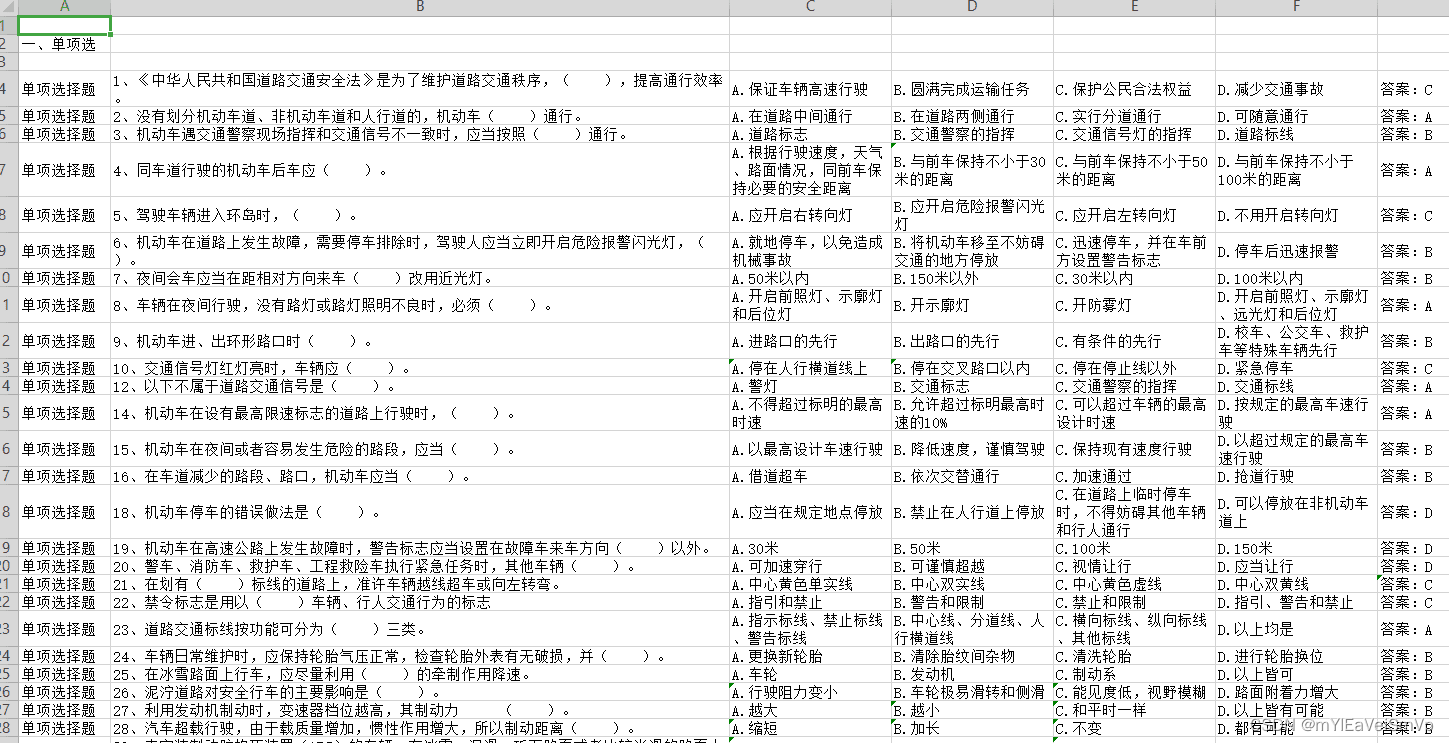
python把Word题库转成Excle题库
又到了一年一度的背题时刻,但是收到的题库是Word版的,页数特别多 话不多说,上代码,有图有真相,代码里面备注的很详细 # 导入所需库 import csv import os import refrom docx import Document from win32com import c…...
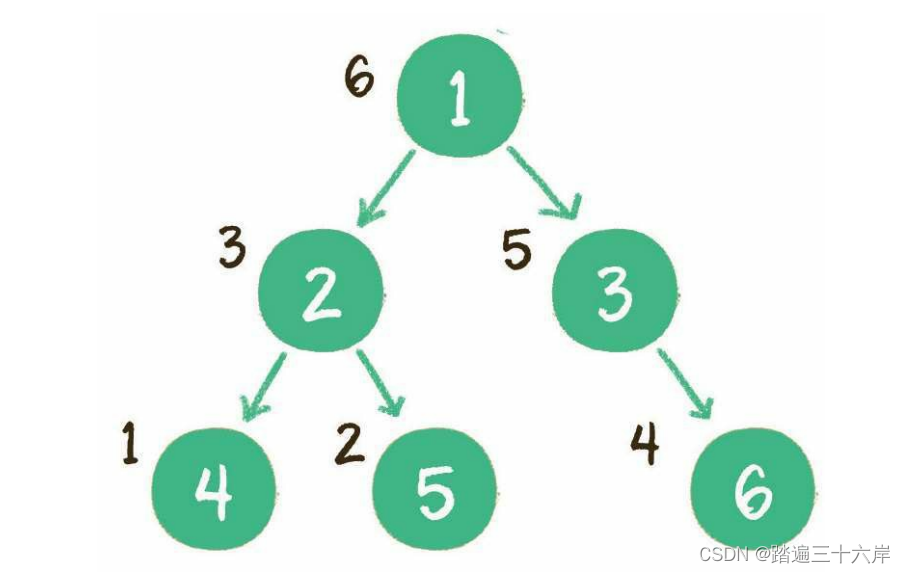
算法通关村第六关-白银挑战树
大家好我是苏麟 , 今天聊聊树 . 大纲 树的概念二叉树满二叉树完全二叉树 树的性质树的定义与存储方式树的遍历通过序列构造二叉树前中序列遍历 树的概念 树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物&…...
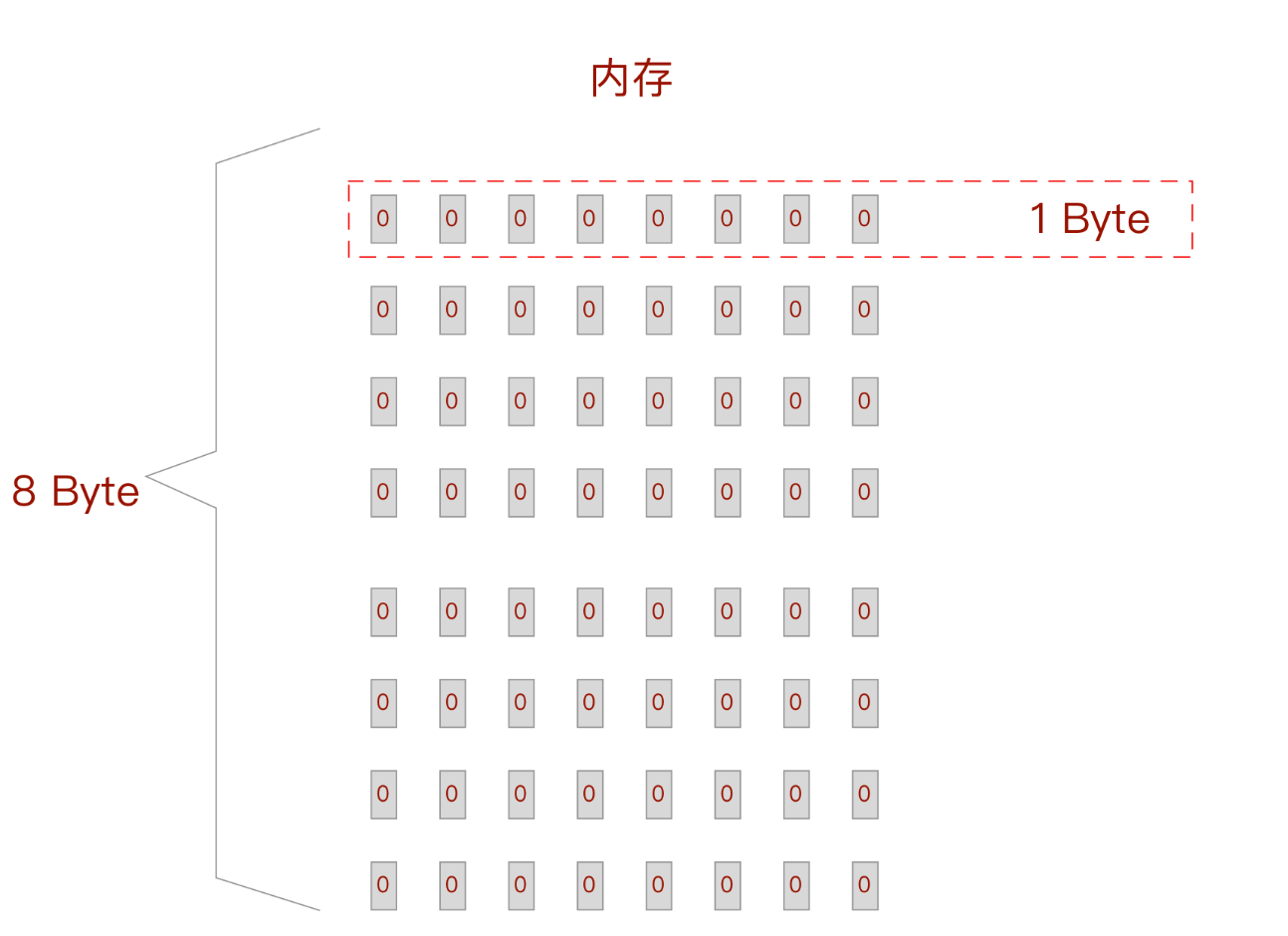
【Java对象】一文读懂 Java 对象庐山真面目及指针压缩
文章目录 版本及工具介绍Java 对象结构对象头mark word 标记字mark word 标记字解析Lock Record class point 类元数据指针 实例数据对齐填充为什么需要对齐填充 常见 Java 数据类型对象分析ArrayListLongStringByteBoolean 其它指针压缩前置知识:32位操作系统为什么…...

leetcode做题笔记210. 课程表 II
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。 例如,想要学习课程 0 ,你需要先完成课程 1…...
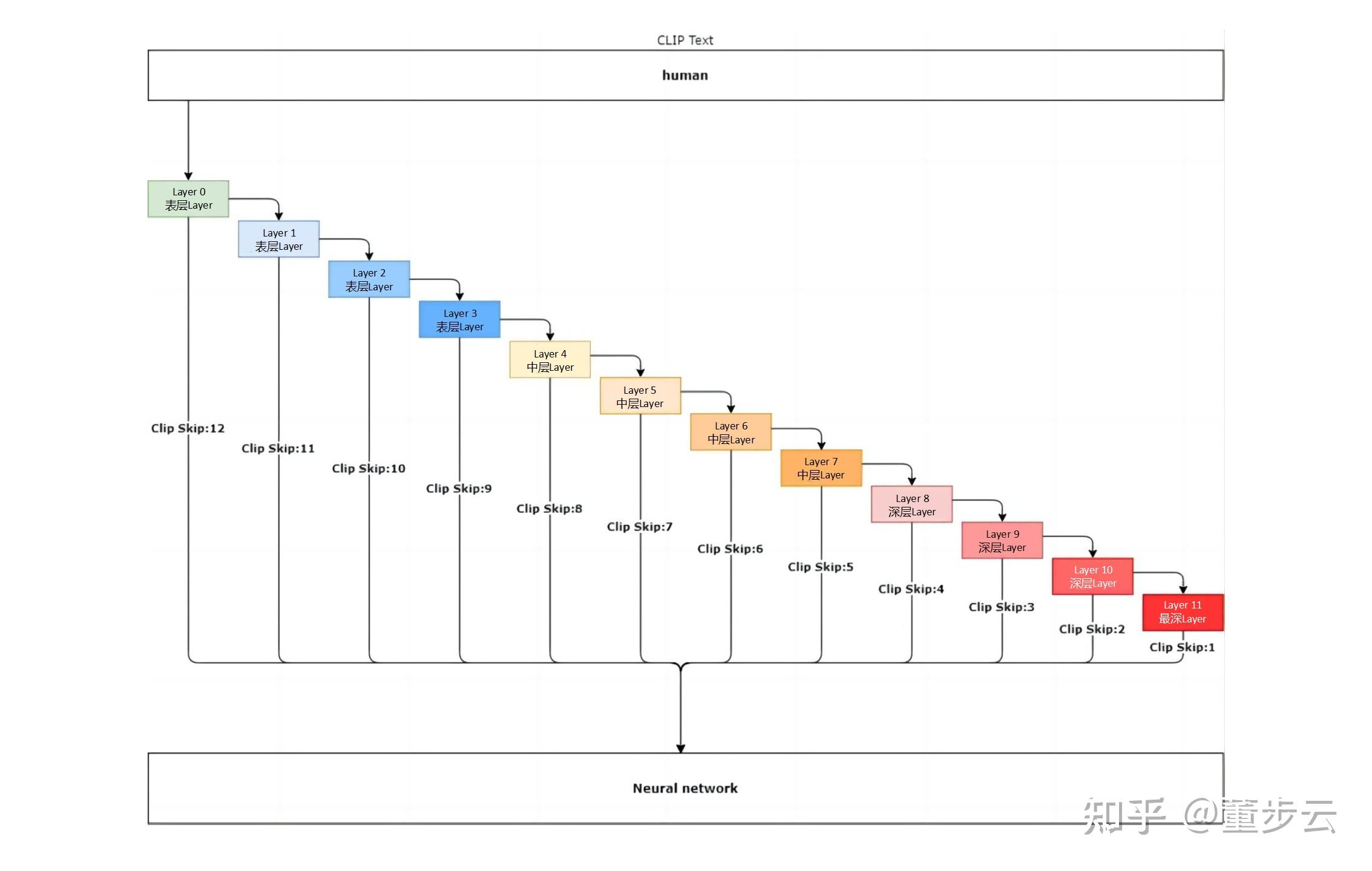
【深度学习 AIGC】stable diffusion webUI 使用过程,参数设置,教程,使用方法
文章目录 docker快速启动vae.ckpt或者.safetensorsCFG指数/CFG Scale面部修复/Restore facesRefinerTiled VAEClip Skipprompt提示词怎么写 docker快速启动 如果你想使用docker快速启动这个项目,你可以按下面这么操作(显卡支持CUDA11.8)。如…...
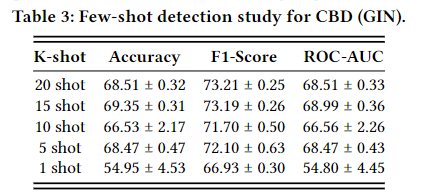
论文阅读 - Detecting Social Bot on the Fly using Contrastive Learning
目录 摘要: 引言 3 问题定义 4 CBD 4.1 框架概述 4.2 Model Learning 4.2.1 通过 GCL 进行模型预训练 4.2.2 通过一致性损失进行模型微调 4.3 在线检测 5 实验 5.1 实验设置 5.2 性能比较 5.5 少量检测研究 6 结论 https://dl.acm.org/doi/pdf/10.1145/358…...
)
PaddleMIX学习笔记(1)
写在前面 之前对HyperLedger的阅读没有完全结束,和很多朋友一样,同时也因为工作的需要,最近开始转向LLM方向。 国内在大模型方面生态做的最好的,目前还是百度的PaddlePaddle,所以自己也就先从PP开始看起了。 众所周知…...
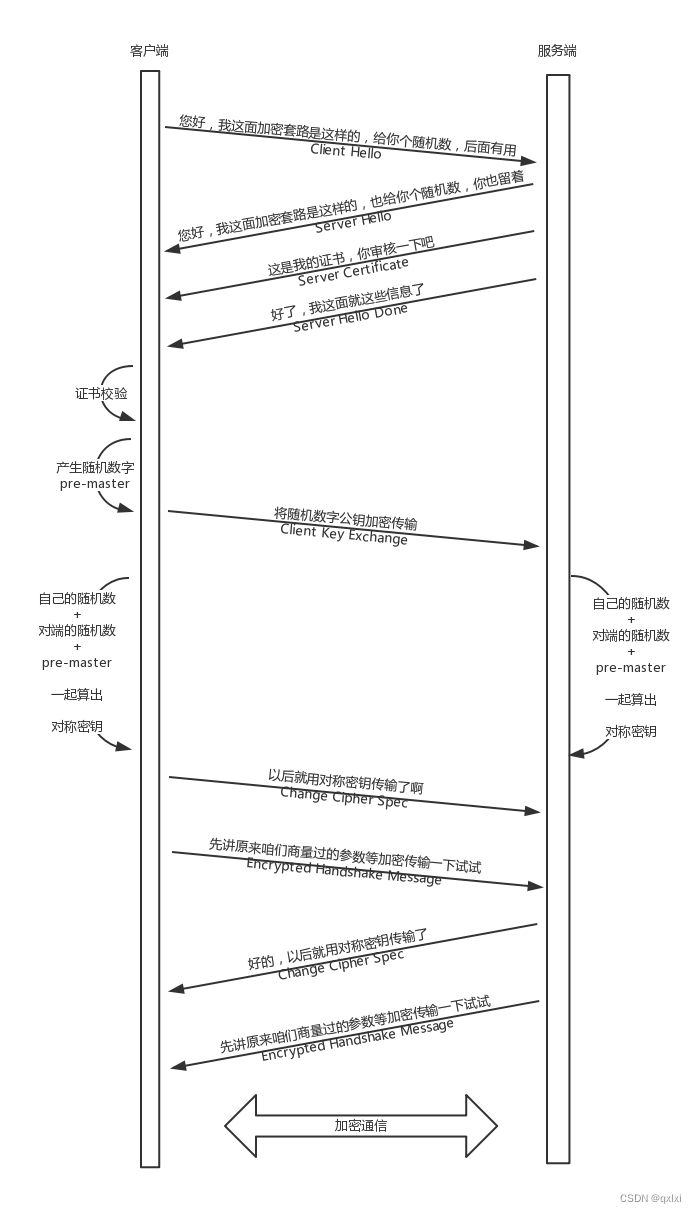
【网络协议】聊聊HTTPS协议
前面的文章,我们描述了网络是怎样进行传输数据包的,但是网络是不安全的,对于这种流量门户网站其实还好,对于支付类场景其实容易将数据泄漏,所以安全的方式是通过加密,加密方式主要是对称加密和非对称加密。…...

2023.11.2事件纪念
然而造化又常常为庸人设计,以时间的流逝,来洗涤旧迹,仅以留下淡红的血色和微漠的悲哀。 回顾这次事件,最深的感触就是什么是团队的力量! 当我们看到希望快要成功的时候,大家洋溢出兴奋开心的表情,一起的欢声笑语;但看…...

Scala和Play WS库编写的爬虫程序
使用Scala和Play WS库编写的爬虫程序,该程序将爬取网页内容: import play.api.libs.ws._ import scala.concurrent.ExecutionContext.Implicits.global object BaiduCrawler {def main(args: Array[String]): Unit {val url ""val proxy…...

[智能体-7]:业务数据序列化为 JSON 字符串 完整示例
一、概念序列化:把程序里的对象 / 字典 / 实体数据 → 转换成JSON 格式字符串,用于网络传输、接口请求、存储。反序列化:JSON 字符串 → 还原成程序可直接使用的数据对象。二、Python 示例(最常用,对接 OpenAI / 大模型…...

大规模数据降维中迹比率问题与非负矩阵分解的快速算法【附代码】
✨ 长期致力于数据降维、大规模判别分析、迹比率问题、快速算法、非负矩阵分解研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)随机迹比率问题的显式解…...

聊一聊5家软件许可优化公司,哪个更适合你?
做软件资产管理的朋友应该都有同感:软件许可这事儿,水太深了。尤其这几年大厂审计越来越狠,一不小心就是几百万的罚单。所以很多公司开始找专门做软件许可优化的服务商。今天聊聊5家比较有代表性的:、Flexera、Snow、Anglepoint和…...

mpv.net:Windows平台最强大的开源媒体播放器解决方案
mpv.net:Windows平台最强大的开源媒体播放器解决方案 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 在Windows平台上寻找一款既强大又简洁的媒体…...

基于 Python 有限元法的光子微腔仿真:从理论到代码实现
引言:光子微腔与有限元法的结合实例# 安装基础依赖 pip install numpy matplotlib scipy# 安装GMSH网格生成器 pip install gmsh# 安装FEMWELL光子学有限元库 pip install femwell# 安装FEniCSx(FEMWELL的底层依赖) # 对于Ubuntu/Debian系统 …...

双榜第一!文心5.1登顶中文创意写作综合实力评测
【大力财经】5月18日,全球权威ICT领域市场研究机构Omdia发布《2026 年基础模型中文创意写作能力评估》报告,围绕中文创意写作七大核心维度,对 DeepSeek V4、文心5.1(ERNIE 5.1)、GPT 5.5 等 8大国内外主流顶级文本模型…...

如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南
如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSe…...

AI写作辅助网站的使用规范:如何让AI生成内容通过严格学术审查
"论文写到一半卡住了,还能不能用AI?""AI生成的内容会被查出来吗?""学校不让用AI,但不靠它我真的写不完!"2026年的毕业季,论文写作的焦虑比往年更甚。面对日益严格的学术审查…...

将Claude Code编程助手无缝对接至Taotoken解决账号与Token限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Claude Code编程助手无缝对接至Taotoken解决账号与Token限制 对于依赖Claude Code进行编程辅助的开发者而言,遇到官方…...

工厂实验室建设公司厂家:建不好,产品质量白搞|中南实验室建设
在工业4.0浪潮席卷全球的今天,工厂实验室早已不是传统意义上"摆几台仪器、刷几面墙"的简单工程。它是企业质量管控的第一道闸门,是工艺优化的数据引擎,更是技术创新的核心载体。从新能源电池的毫秒级安全测试,到半导体工…...