Flink SQL 窗口聚合详解
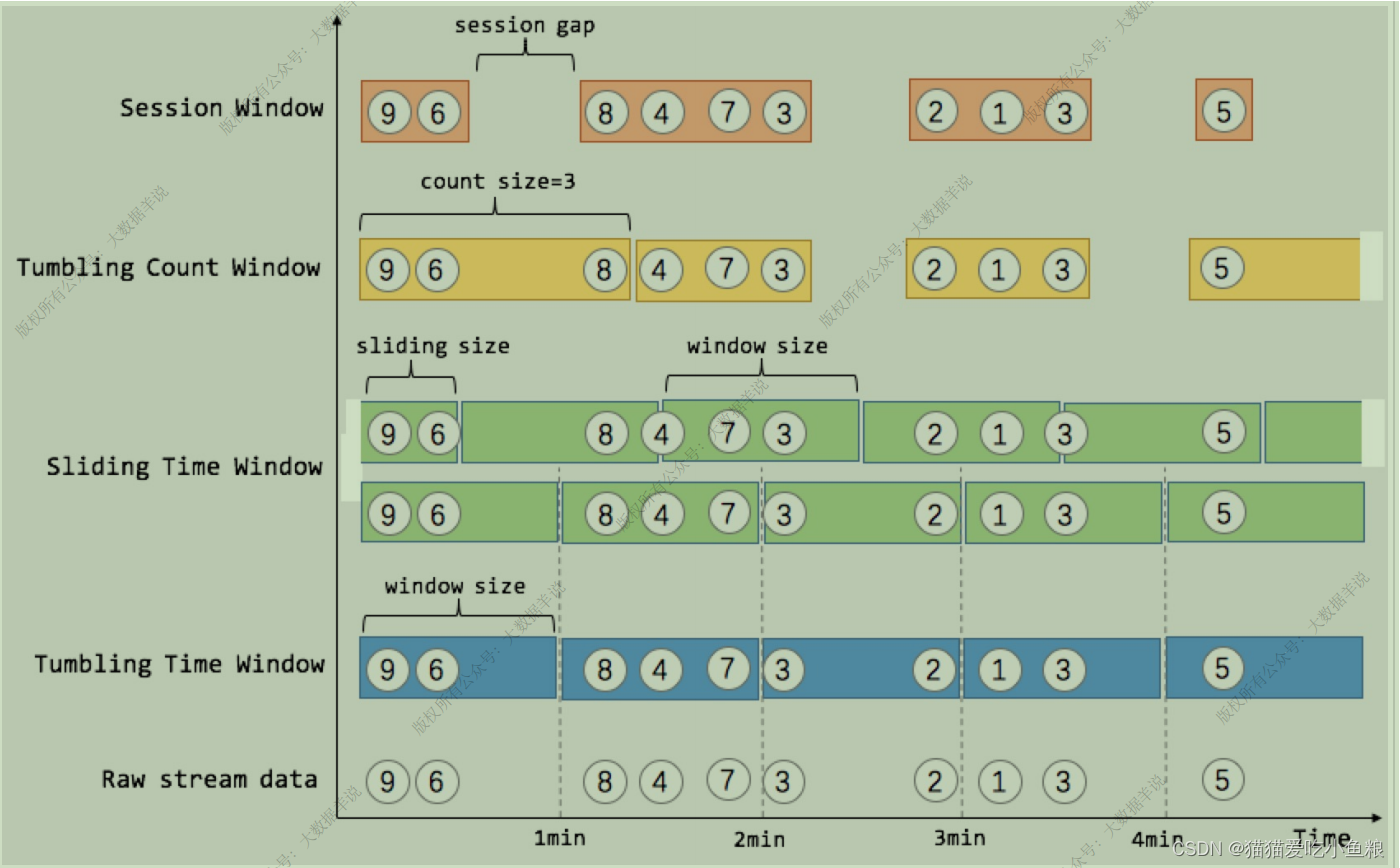
1.滚动窗⼝(TUMBLE)
**滚动窗⼝定义:**滚动窗⼝将每个元素指定给指定窗⼝⼤⼩的窗⼝,滚动窗⼝具有固定⼤⼩,且不重叠。
例如,指定⼀个⼤⼩为 5 分钟的滚动窗⼝,Flink 将每隔 5 分钟开启⼀个新的窗⼝,其中每⼀条数都会划分到唯⼀⼀个 5 分钟的窗⼝中。
**应⽤场景:**按照⼀分钟对数据进⾏聚合,计算⼀分钟内 PV,UV 数据。
**实际案例:**分维度分钟级别统计在线⽤户数、总销售额。
滚动窗⼝在 1.13 版本之前和 1.13 及版本之后有两种 Flink SQL 实现⽅式
Group Window Aggregation(1.13 之前)和 Windowing TVF(1.13 及之后)
Group Window Aggregation ⽅案(⽀持 Batch\Streaming 任务):
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- ⽤户 iduser_id BIGINT,-- ⽤户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
)-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT,sum_price BIGINT,max_price BIGINT,min_price BIGINT,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
)-- 数据处理逻辑
insert into sink_table
selectdim,count(*) as pv,sum(price) as sum_price,max(price) as max_price,min(price) as min_price,-- 计算 uv 数count(distinct user_id) as uv,UNIX_TIMESTAMP(CAST(tumble_start(row_time, interval '1' minute) AS STRING)) * 10
from source_table
group bydim,tumble(row_time, interval '1' minute)
Group Window Aggregation 滚动窗⼝的 SQL 语法,把 tumble window 的声明写在了 group by ⼦句中,即 tumble(row_time, interval ‘1’ minute) ,第⼀个参数为事件时间的时间戳,第⼆个参数为滚动窗⼝⼤⼩。
Window TVF ⽅案(1.13 只⽀持 Streaming 任务):
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- ⽤户 iduser_id BIGINT,-- ⽤户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
)-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT,sum_price BIGINT,max_price BIGINT,min_price BIGINT,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
)-- 数据处理逻辑
insert into sink_table
SELECTdim,UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,count(*) as pv,sum(price) as sum_price,max(price) as max_price,min(price) as min_price,count(distinct user_id) as uv
FROM TABLE(TUMBLE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND))
GROUP BY window_start, window_end,dim
Windowing TVF 滚动窗⼝的写法把 tumble window 的声明写在了数据源的 Table ⼦句中,包含三部分参数:
TABLE(
TUMBLE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND)
)
第⼀个参数 TABLE source_table 声明数据源表;
第⼆个参数 DESCRIPTOR(row_time) 声明数据源的时间戳字段;
第三个参数 INTERVAL ‘60’ SECOND 声明滚动窗⼝⼤⼩为 1 min。
实时场景 SQL 语义: 假设 Orders 为 kafka,target_table 也为 Kafka,这个 SQL ⽣成的实时任务,在执⾏时,会⽣成三个算⼦。
数据源算⼦(From Order):
连接到 Kafka topic,数据源算⼦⼀直运⾏,实时的从 Order Kafka 中⼀条⼀条的读取数据,然后⼀条⼀条发送给下游的 窗⼝聚合算⼦
窗⼝聚合算⼦(TUMBLE 算⼦):
接收到上游算⼦发的⼀条⼀条的数据,然后将每⼀条数据按照时间戳划分到对应的窗⼝中(根据事件时间、处理时间的不同语义进⾏划分),上述案例为事件时间,事件时间中,滚动窗⼝算⼦接收到上游的 Watermark ⼤于窗⼝的结束时间时,则说明当前这⼀分钟的滚动窗⼝已经结束了,将窗⼝计算完的结果发往下游算⼦(⼀条⼀条发给下游 数据汇算⼦ )
数据汇算⼦(INSERT INTO target_table):
接收到上游发的⼀条⼀条的数据,写⼊到 target_table Kafka 中
注意: 事件时间中滚动窗⼝的窗⼝计算触发是由 Watermark 推动的。
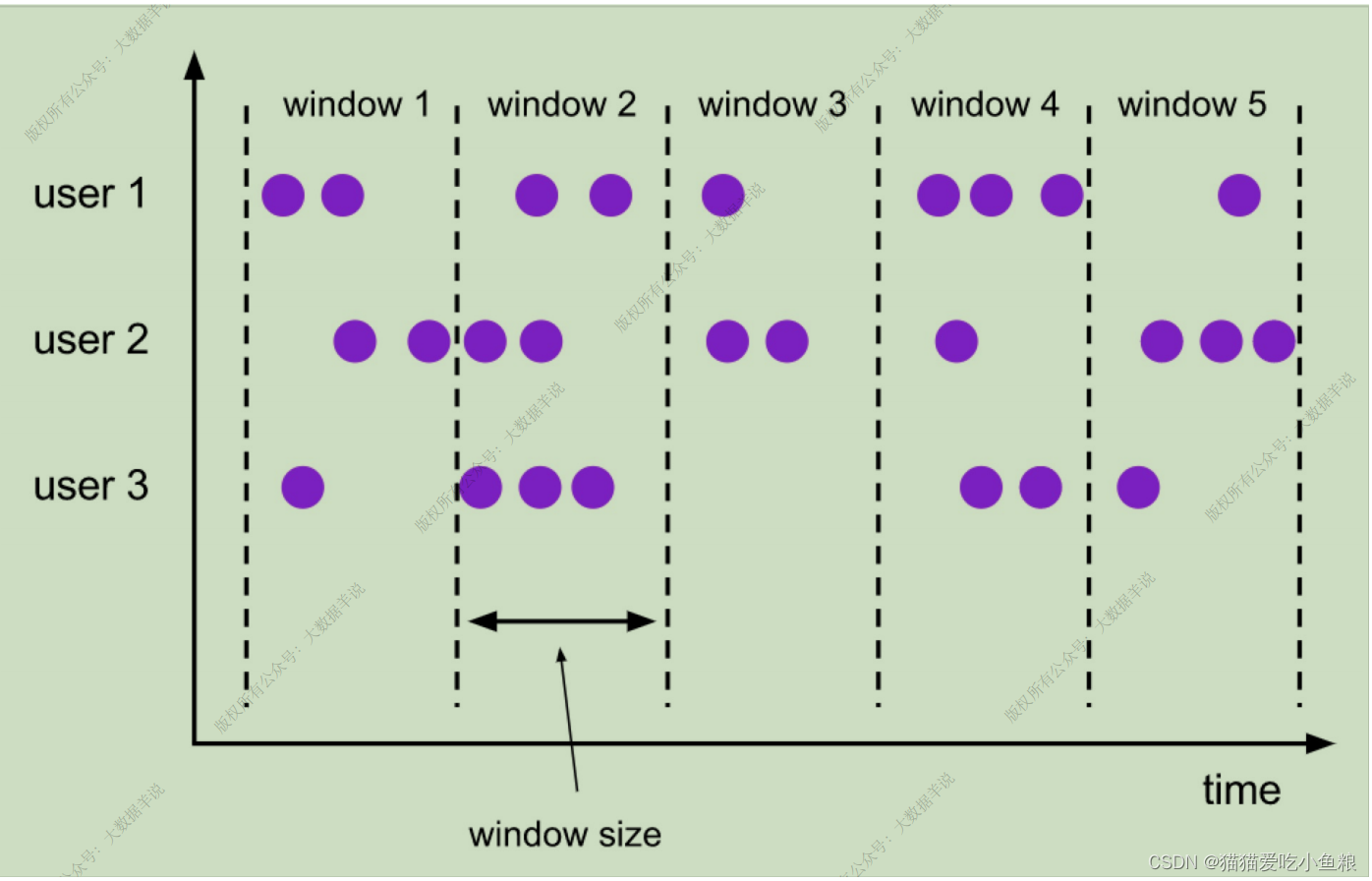
2.滑动窗⼝(HOP)
**滑动窗⼝定义:**滑动窗⼝是将元素指定给固定⻓度的窗⼝,与滚动窗⼝功能⼀样,也有窗⼝⼤⼩的概念,不⼀样的地⽅在于,滑动窗⼝有另⼀个参数控制窗⼝计算的频率(滑动窗⼝滑动的步⻓),如果滑动的步⻓⼩于窗⼝⼤⼩,则滑动窗⼝之间每个窗⼝是可以重叠,在这种情况下,⼀条数据就会分配到多个窗⼝当中。
**举例:**有 10 分钟⼤⼩的窗⼝,滑动步⻓为 5 分钟,每 5 分钟会划分⼀次窗⼝,这个窗⼝包含的数据是过去 10 分钟内的数据。

**应⽤场景:**计算同时在线的数据,要求结果的输出频率是 1 分钟⼀次,每次计算的数据是过去 5 分钟的数据(有的场景下⽤户可能在线,但是可能会 2 分钟不活跃,但是这也要算在同时在线数据中,所以取最近 5 分钟的数据就能计算进去了)
**实际案例:**分维度分钟级别同时在线⽤户数,1 分钟输出⼀次,计算最近 5 分钟的数据,Group Window Aggregation、Windowing TVF 两种⽅案
Group Window Aggregation ⽅案(⽀持 Batch\Streaming 任务):
CREATE TABLE source_table (-- 维度数据dim STRING,-- ⽤户 iduser_id BIGINT,-- ⽤户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT dim,
UNIX_TIMESTAMP(CAST(hop_start(row_time, interval '1' minute, interval '5' minute) AS STRING)) * 10,
count(distinct user_id) as uv
FROM source_table
GROUP BY dim, hop(row_time, interval '1' minute, interval '5' minute)
Group Window Aggregation 滚动窗⼝的写法把 hop window 的声明写在了 group by ⼦句中,即
hop(row_time, interval '1' minute, interval '5' minute)
第⼀个参数为事件时间的时间戳字段;
第⼆个参数为滑动窗⼝的滑动步⻓;
第三个参数为滑动窗⼝⼤⼩。
Windowing TVF ⽅案(1.13 只⽀持 Streaming 任务):
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- ⽤户 iduser_id BIGINT,-- ⽤户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECTdim,UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start, count(distinct user_id) as bucket_uv
FROM TABLE(HOP(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '1' MINUTES, INTERVAL '5' MINUTES))
GROUP BY window_start, window_end,dim
Windowing TVF 滑动窗⼝的写法把 hop window 的声明写在了数据源的 Table ⼦句中,即
TABLE(HOP(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '1' MINUTES, INTERVAL '5' MINUTES))
第⼀个参数 TABLE source_table 声明数据源表;
第⼆个参数 DESCRIPTOR(row_time) 声明数据源的时间戳;
第三个参数 INTERVAL ‘1’ MINUTES 声明滚动窗⼝滑动步⻓⼤⼩为 1 min。
第四个参数 INTERVAL ‘5’ MINUTES 声明滚动窗⼝⼤⼩为 5 min。
3.Session 窗⼝
**Session 窗⼝定义:**Session 时间窗⼝和滚动、滑动窗⼝不⼀样,其没有固定的持续时间,如果在定义的间隔期(Session Gap)内没有新的数据出现,则 Session 就会窗⼝关闭。
**实际案例:**计算每个⽤户在活跃期间(⼀个 Session)总共购买的商品数量,如果⽤户 5 分钟没有活动,则视为 Session 断开
⽬前 1.13 版本中 Flink SQL 不⽀持 Session 窗⼝的 Window TVF,只介绍 Group Window Aggregation ⽅案。
Group Window Aggregation ⽅案(⽀持 Batch\Streaming 任务):
-- 数据源表,⽤户购买⾏为记录表
CREATE TABLE source_table (-- 维度数据dim STRING,-- ⽤户 iduser_id BIGINT,-- ⽤户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT, -- 购买商品数量window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECTdim,UNIX_TIMESTAMP(CAST(session_start(row_time, interval '5' minute) AS STRING)) * 10,count(1) as pv
FROM source_table
GROUP BY dim, session(row_time, interval '5' minute)
**注意:**上述 SQL 任务是在整个 Session 窗⼝结束之后才会把数据输出,Session 窗⼝⽀持 处理时间 和 事件时间,但是处理时间只⽀持在 Streaming 任务中运⾏,Batch 任务不⽀持。
Group Window Aggregation 中 Session 窗⼝的写法把 session window 的声明写在了 group by ⼦句中
session(row_time, interval '5' minute)
第⼀个参数为事件时间的时间戳;
第⼆个参数为 Session gap 间隔。
4.渐进式窗⼝(CUMULATE)
**渐进式窗⼝定义(1.13 只⽀持 Streaming 任务):**渐进式窗⼝可以认为是⾸先开⼀个最⼤窗⼝⼤⼩的滚动窗⼝,然后根据⽤户设置的触发的时间间隔将这个滚动窗⼝拆分为多个窗⼝,这些窗⼝具有相同的窗⼝起点和不同的窗⼝终点。
**示例:**从每⽇零点到当前这⼀分钟绘制累积 UV,其中 10:00 时的 UV 表示从 00:00 到 10:00 的 UV 总数。
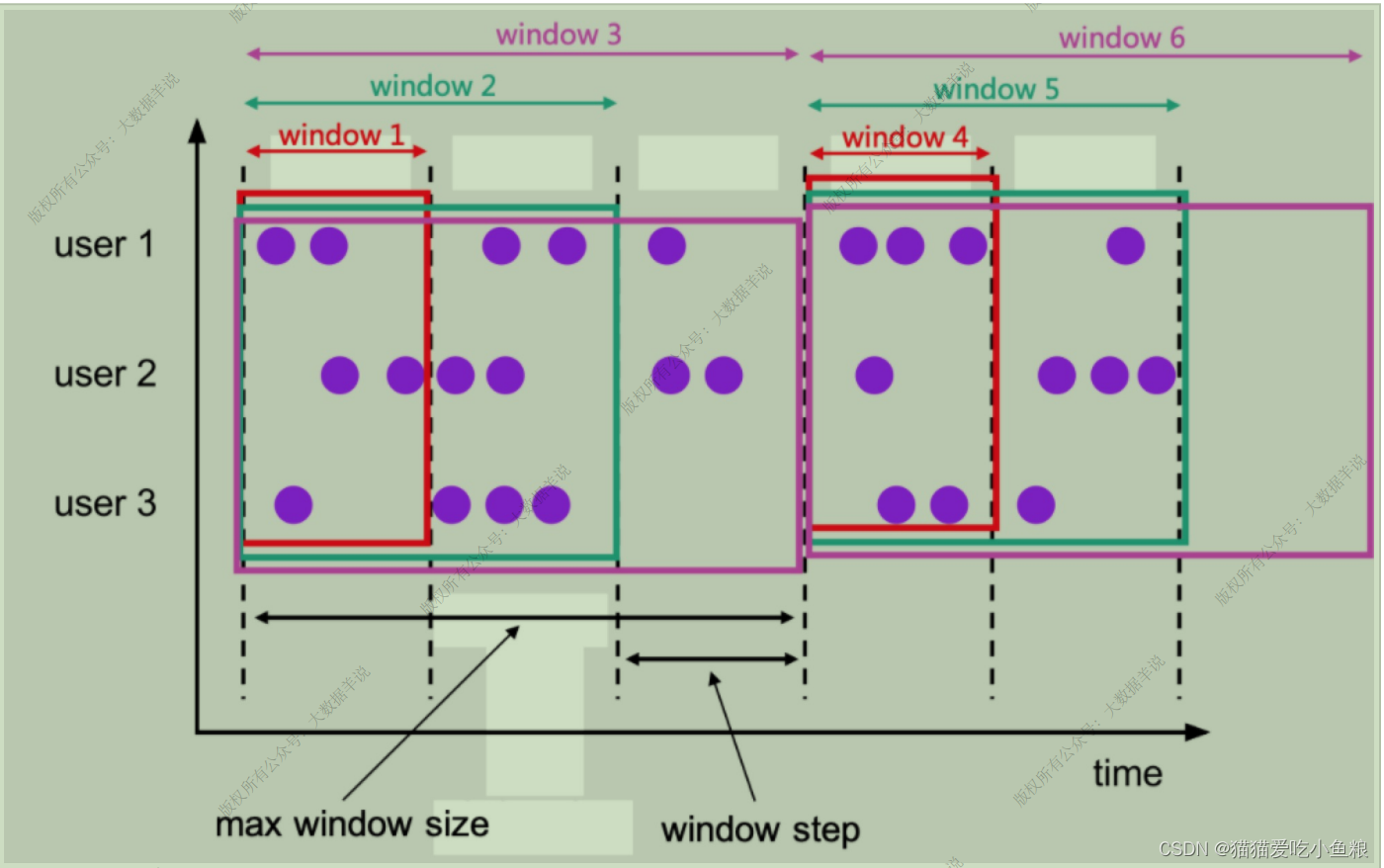
**应⽤场景:**周期内累计 PV,UV 指标(如每天累计到当前这⼀分钟的 PV,UV),这类指标是⼀段周期内的累计状态。
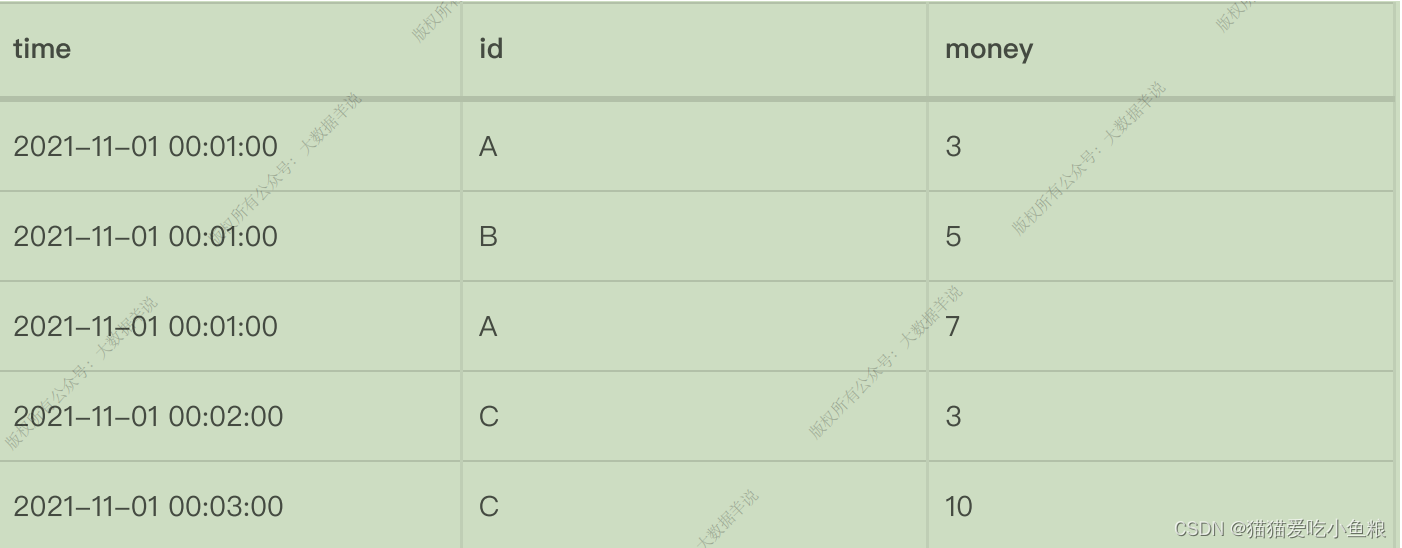
**实际案例:**每天的截⽌当前分钟的累计 money(sum(money)),去重 id 数(count(distinct id)),每天代表渐进式窗⼝⼤⼩为 1 天,分钟代表渐进式窗⼝移动步⻓为分钟级别。
明细输⼊数据:
预期经过渐进式窗⼝计算的输出数据:
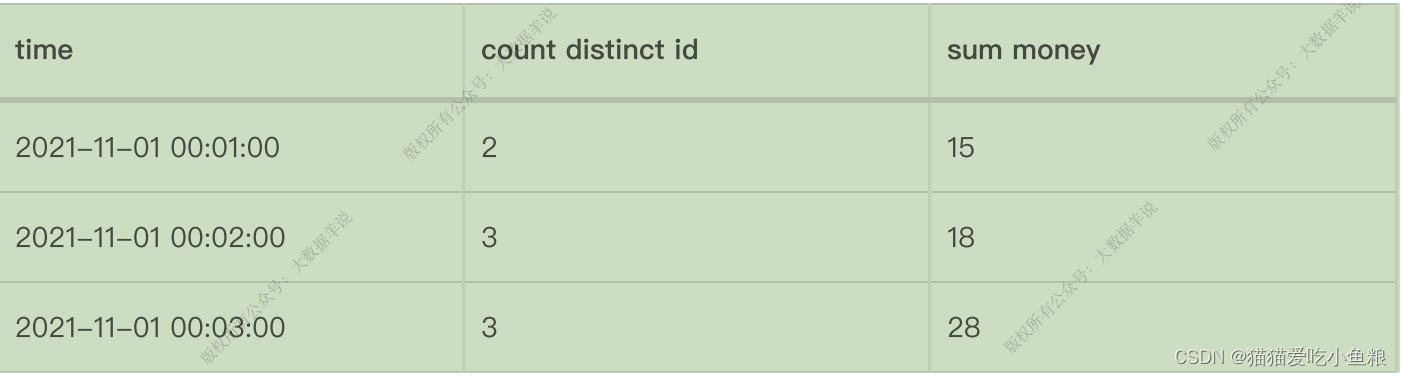
**特点:**每⼀分钟的输出结果都是当天零点累计到当前的结果,渐进式窗⼝只有 Windowing TVF ⽅案⽀持。
Windowing TVF ⽅案(1.13 只⽀持 Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- ⽤户 iduser_id BIGINT,-- ⽤户money BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.money.min' = '1','fields.money.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (window_end bigint,window_start bigint,sum_money BIGINT,count_distinct_id bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECTUNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, window_start, sum(money) as sum_money,count(distinct user_id) as count_distinct_id
FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND, INTERVAL '1' DAY))
GROUP BYwindow_start, window_end
Windowing TVF 滚动窗⼝的写法把 cumulate window 的声明写在了数据源的 Table ⼦句中
TABLE(CUMULATE(TABLE source_table,DESCRIPTOR(row_time),INTERVAL '60' SECOND, INTERVAL '1' DAY)
)
第⼀个参数 TABLE source_table 声明数据源表;
第⼆个参数 DESCRIPTOR(row_time) 声明数据源的时间戳;
第三个参数 INTERVAL ‘60’ SECOND 声明渐进式窗⼝触发的渐进步⻓为 1 min。
第四个参数 INTERVAL ‘1’ DAY 声明整个渐进式窗⼝的⼤⼩为 1 天,到了第⼆天新开⼀个窗⼝重新累计。
5.Window TVF ⽀持 Grouping Sets、Rollup、Cube
**应⽤场景:**多个维度组合(cube)计算,把每个维度写⼀遍 union all 起来麻烦⽽且会导致⼀个数据源读取多遍。
⽤ Grouping Sets 将维度组合写在⼀条 SQL 中,⽅便且执⾏效率⾼,⽬前 Grouping Sets 只在 Window TVF 中⽀持,不⽀持 Group Window Aggregation。
**示例:**计算每⽇零点累计到当前这⼀分钟的,分汇总、age、sex、age+sex 维度的⽤户数。
-- ⽤户访问明细表
CREATE TABLE source_table (age STRING,sex STRING,user_id BIGINT,row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.age.length' = '1','fields.sex.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000'
);CREATE TABLE sink_table (age STRING,sex STRING,uv BIGINT,window_end bigint
) WITH ('connector' = 'print'
);insert into sink_table
SELECTUNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end,if (age is null, 'ALL', age) as age,if (sex is null, 'ALL', sex) as sex,count(distinct user_id) as bucket_uv
FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '5' SECOND, INTERVAL '1' DAY))
GROUP BYwindow_start, window_end,-- grouping sets 写法GROUPING SETS ((), (age), (sex), (age, sex))
Flink SQL 中 Grouping Sets 的语法和 Hive SQL 的语法有不同,使⽤ Hive SQL 实现上述 SQL 的语义,实现如下:
insert into sink_table
SELECTUNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, if (age is null, 'ALL', age) as age,if (sex is null, 'ALL', sex) as sex,count(distinct user_id) as bucket_uv
FROM source_table
GROUP BYage, sex
-- hive sql grouping sets 写法
GROUPING SETS ((), (age), (sex), (age, sex)
)
相关文章:
Flink SQL 窗口聚合详解
1.滚动窗⼝(TUMBLE) **滚动窗⼝定义:**滚动窗⼝将每个元素指定给指定窗⼝⼤⼩的窗⼝,滚动窗⼝具有固定⼤⼩,且不重叠。 例如,指定⼀个⼤⼩为 5 分钟的滚动窗⼝,Flink 将每隔 5 分钟开启⼀个新…...

中间件redis的使用
Java中的中间件配置体现在springboot的yml配置文件中。Springboot框架支持微服务和中间件和restful api远程服务的调用。中间件是Java web系统的中间层的服务系统的调用接口。Springboot的自动装配和约定大于配置机制初始化springcontext的容器空间和注册组件。使用容器管理服务…...

Why delete[] array when deepcopying with “=“?
代码负责释放对象之前已经分配的资源,比如堆上的内存。在执行深拷贝之前,你需要确保对象不再引用之前的资源,以避免内存泄漏。通过删除先前的资源,你可以确保在进行深拷贝之前,已经释放了之前的资源,从而避…...
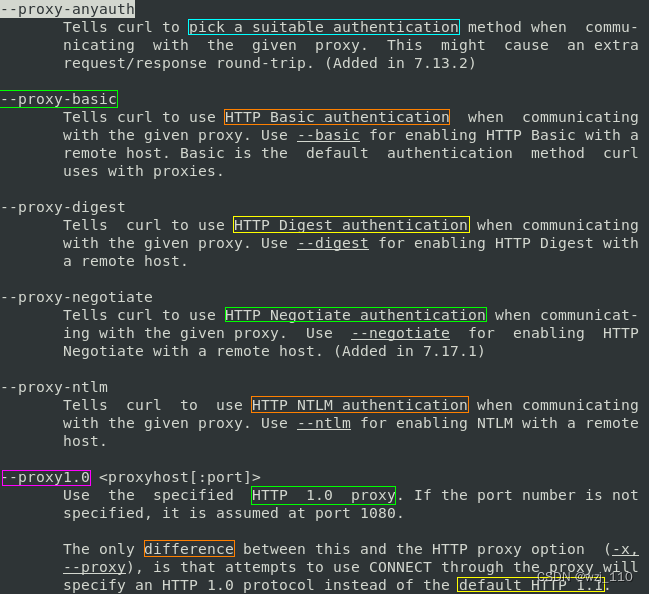
curl(六)DNS解析、认证、代理
一 DNS解析 ① ip协议 使用ipv4 [-4] 还是ipv6 [-6] ② --resolve 场景: 在不修改系统配置文件 /etc/hosts 的情况下将单个请求临时固定到 ip 地址 1、使用 * 作为通配符,这样请求中调用的所有 Host 都 会转到你指定的 ip curl https://www.wzj.com --resolv…...
(免费领源码)PHP#MySQL高校学生信息管理系统28099-计算机毕业设计项目选题推荐
摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用php技术建设学生信息管理系统设计。…...
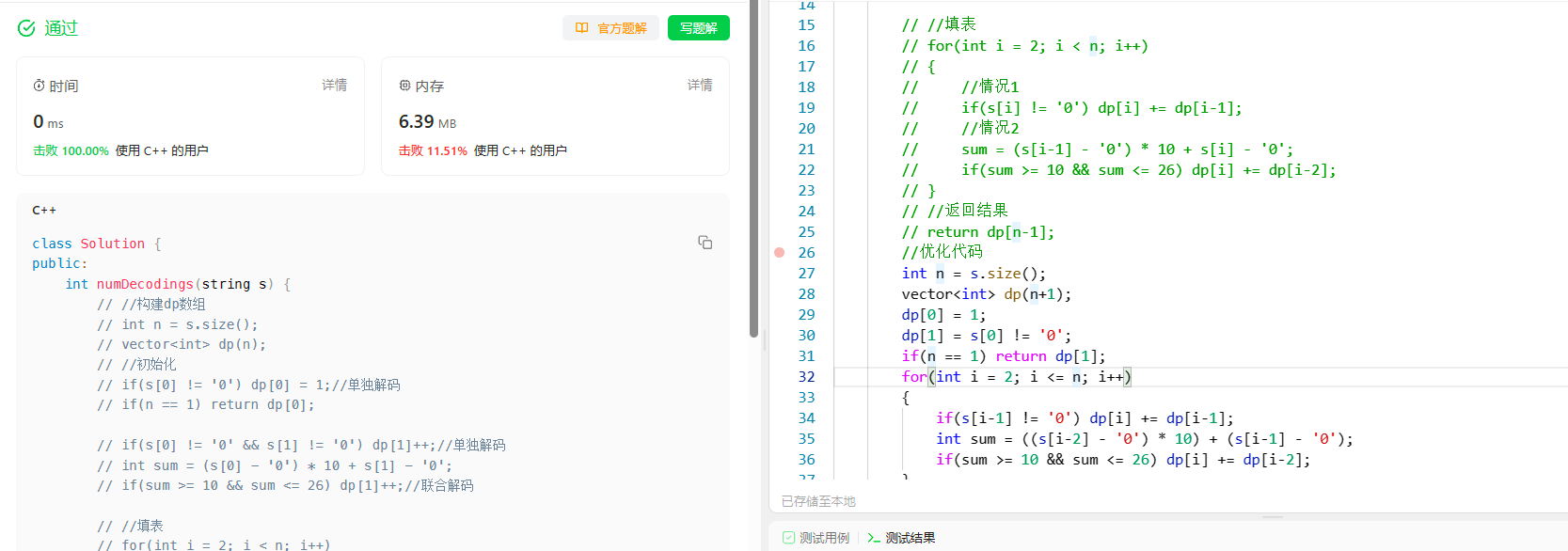
[动态规划] (四) LeetCode 91.解码方法
[动态规划] (四) LeetCode 91.解码方法 91. 解码方法 题目解析 (1) 对字母A - Z进行编码1-26 (2)11106可以解码为1-1-10-6或者11-10-6, 但是11-1-06不能解码 (3) 0n不能解码 (4) 字符串非空,返回解码方法的总数 解题思路 状态表示 dp[i]:以i为结…...

Vue Vuex的使用和原理 专门解决共享数据的问题
Vuex专门解决共享数据的问题 多组件共享时使用,如用户ID各组件需要根据ID发送请求获取数据,任意组件可以进行增删改,相当于全局变量 Vuex 工作流程 如果确定值参数可以不经过Actions 直接走 安装Vuex vue2使用 vuex3 vue3使用 vuex4 npm i…...

第九周实验记录
1、安装Nerfstudio 环境配置 首先需要创建环境python3.8,接着需要安装cuda11.7或11.3 这里安装cuda11.7 pip uninstall torch torchvision functorchpip install torch1.13.1 torchvision functorch --extra-index-url https://download.pytorch.org/whl/cu117安…...
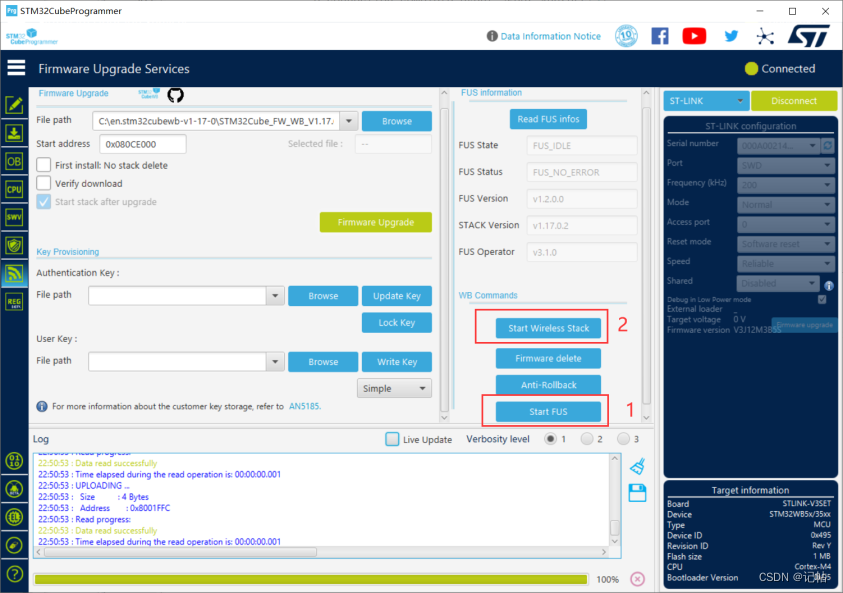
STM32WB55开发(6)----FUS更新
STM32WB55开发.6--FUS更新 概述视频教学硬件准备存储器映射FLASH安全区设置SRAM安全区设置通过USB进行下载注意事项 概述 在 STM32WB 微控制器中,FUS(Firmware Upgrade Services)是用于固件升级的一种服务。这项服务可以让你更新设备上的无…...

centos关闭Java进程的脚本
centos关闭Java进程的脚本,有时候服务就是个jar包,关闭程序又要找到进程ID,在kill掉,麻烦,这里就写了个脚本 小白教程,一看就会,一做就成。 1.脚本如下 #!/bin/bash ps -ef | grep java | gre…...
深度学习网络模型 MobileNet系列MobileNet V1、MobileNet V2、MobileNet V3网络详解以及pytorch代码复现
深度学习网络模型 MobileNet系列MobileNet V1、MobileNet V2、MobileNet V3网络详解以及pytorch代码复现 1、DW卷积与普通卷积计算量对比DW与PW计算量普通卷积计算量计算量对比 2、MobileNet V1MobileNet V1网络结构MobileNet V1网络结构代码 3、MobileNet V2倒残差结构模块倒残…...

Spring 中 BeanFactory 和 FactoryBean 有何区别?
这也是 Spring 面试时一道经典的面试问题,今天我们来聊一聊这个话题。 其实从名字上就能看出来个一二,BeanFactory 是 Factory 而 FactoryBean 是一个 Bean,我们先来看下总结: BeanFactory 是 Spring 框架的核心接口之一…...
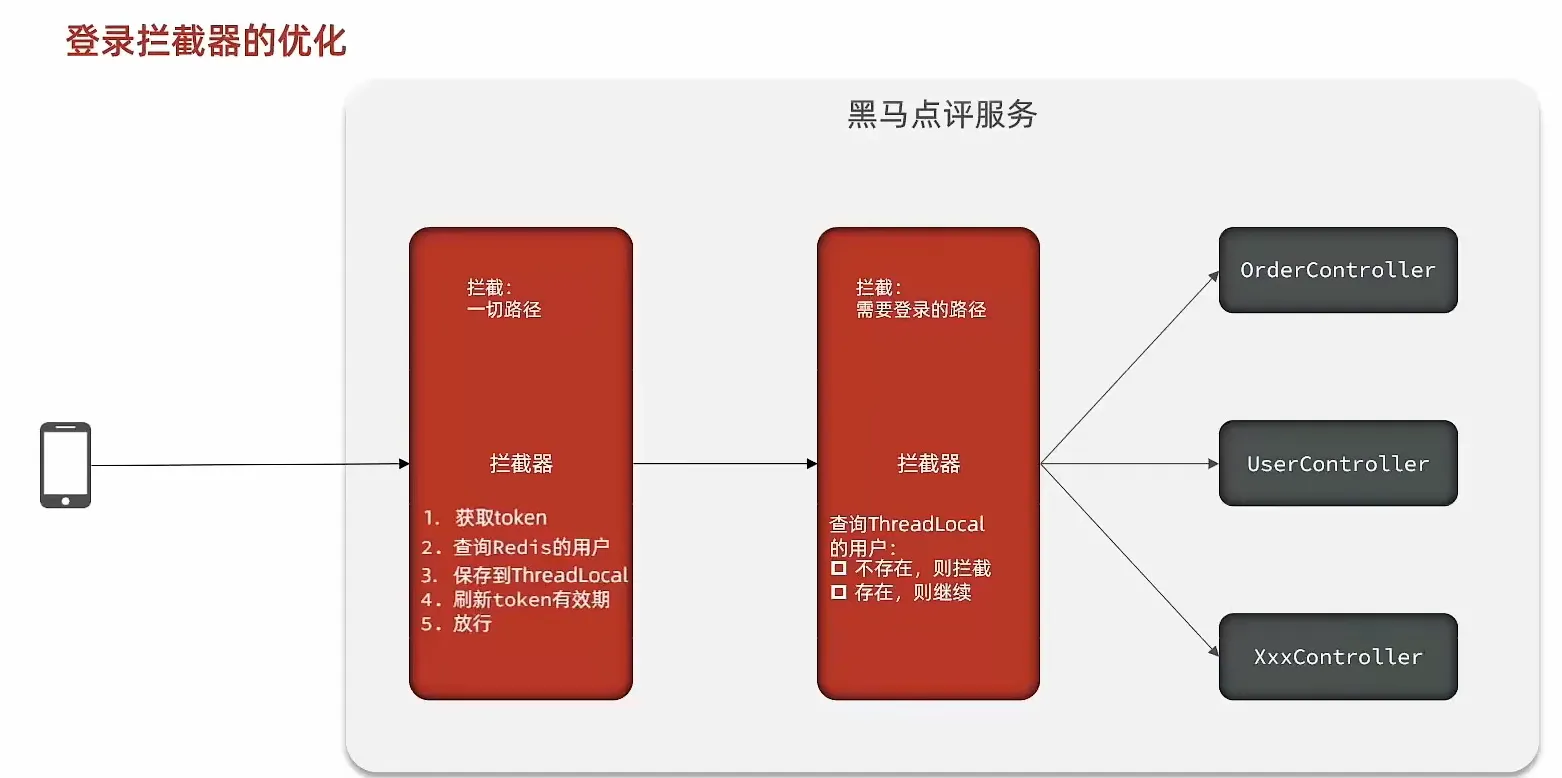
黑马程序员项目-黑马点评
黑马点评1 短信登录 基于Session实现登录流程 发送验证码: 用户在提交手机号后,会校验手机号是否合法,如果不合法,则要求用户重新输入手机号 如果手机号合法,后台此时生成对应的验证码,同时将验证码进行…...
)
ubuntu 20.04 + Anaconda + cuda-11.8 + opencv-4.8.0(cuda)
环境:一键编译opencv-4.8.0(cuda),前提是已经安装好了cuda和cudnn Anaconda安装 参考: https://blog.csdn.net/weixin_46947765/article/details/130980957 opencv4.8.0编译安装 一键编译shell脚本 VERSION4.8.0test -e ${VERSION}.zip || wget http…...

Linux 目录
目录 1. Linux 目录1.1. 目录 /usr/bin 和 /usr/local/bin 区别 1. Linux 目录 1.1. 目录 /usr/bin 和 /usr/local/bin 区别 /usr/bin 下面的都是系统预装的可执行程序, 系统升级有可能会被覆盖。/usr/local/bin 目录是给用户放置自己的可执行程序。...

Linux shell编程学习笔记21:用select in循环语句打造菜单
一、select in循环语句的功能 Linux shell脚本编程提供了select in语句,这是 Shell 独有的一种循环语句,非常适合终端(Terminal)这样的交互场景,它可以根据用户的设置显示出带编号的菜单,用户通过输入不同…...
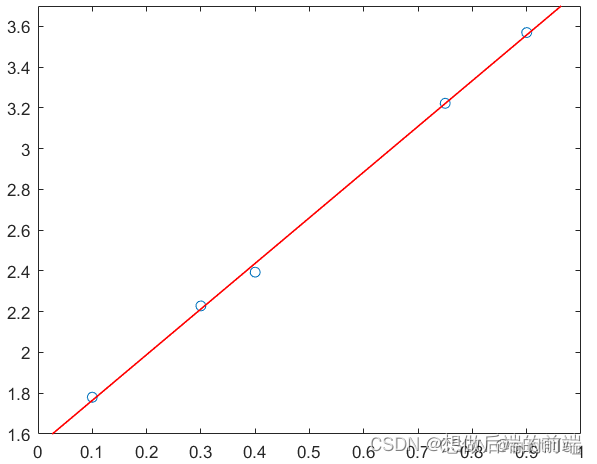
线性回归与线性拟合的原理、推导与算法实现
关于回归和拟合,从它们的求解过程以及结果来看,两者似乎没有太大差别,事实也的确如此。从本质上说,回归属于数理统计问题,研究解释变量与响应变量之间的关系以及相关性等问题。而拟合是把平面的一系列点,用…...

【C++】set和multiset
文章目录 关联式容器键值对一、set介绍二、set的使用multiset 关联式容器 STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元…...

二十、泛型(1)
本章概要 基本概念 与 C 的比较 简单泛型 一个元组类库一个堆栈类RandomList 基本概念 普通的类和方法只能使用特定的类型:基本数据类型或类类型。如果编写的代码需要应用于多种类型,这种严苛的限制对代码的束缚就会很大。 多态是一种面向对象思想的泛…...

【Unity数据交互】游戏中常用到的Json序列化
ˊˊ 👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏࿱…...

从ERR_CERT_COMMON_NAME_INVALID错误,聊聊SSL证书里的Common Name和SAN到底有什么区别?
从ERR_CERT_COMMON_NAME_INVALID错误解析SSL证书中CN与SAN的演进逻辑 当你在Chrome浏览器中看到鲜红色的ERR_CERT_COMMON_NAME_INVALID警告页面时,背后隐藏的是一场持续二十年的证书标准进化史。这个看似简单的域名验证错误,实际上是现代网络安全体系对传…...
)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层(丝印、装配、阻焊)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层 在PCB设计领域,封装设计往往被视为"简单"的基础工作。许多工程师认为,只要焊盘位置正确、丝印轮廓大致匹配,一个封装就算完成了。直到某天,工…...

长沙自动变速箱维修哪家强?这些公司口碑好
好的,遵照您的指示,我将以资深变速箱维修领域分析者的身份,围绕“长沙自动变速箱维修哪家强”这一核心问题,撰写一篇客观、实用、合规的深度分析文章。车主选维修店,最怕被“宰”与被“拖”在长沙,如果你的…...

某包丨图片+视频去水印去除工具
首先下载软件(工具在末尾),然后运行,自动打开网页如下: 接着打开某包,找到你要去除水印的图片或者视频的链接: 工具下载: 链接:https://pan.quark.cn/s/aec2cdde94ed...

Android 相机有线连接开发复盘:PTP/MTP 协议适配与稳定性实践
一、项目背景在做一个相机互联类 App 的过程中,我们需要在 Android 设备上通过 USB 有线方式 连接相机,实现:遥控拍摄实时获取照片稳定地进行文件同步最初评估时以为只要调用系统 API 就能跑起来,但实际开发中发现,标…...

智能安卓主板选型指南:从需求分析到量产落地的全流程解析
1. 项目概述:智能安卓主板选型的核心价值在嵌入式开发和智能硬件项目里,选对一块主板,往往意味着项目成功了一半。我见过太多团队,前期功能设计得天花乱坠,结果卡在了硬件选型上,要么性能过剩成本失控&…...
别再死记硬背Transformer了!用大白话和代码图解,5分钟搞懂Self-Attention核心
用图书馆借书的故事讲透Transformer自注意力机制 想象你走进一个巨大的图书馆,书架上摆满了各种书籍。你需要找到一本关于"深度学习"的书,但你不确定具体是哪一本。这时候,图书管理员会怎么做?她会根据你的需求…...

【Windows版Redis安装本地使用】
本地安装运行 一、Redis官网 二、下载 三、配置redis服务 一、Redis官网 官网: redis 二、下载 下载版本:版本下载 下载完后,解压文件到文件夹 三、配置redis服务 打开目录对应的终端 安装redis服务 redis-server.exe --service-install redis.windows.conf --loglevel verbos…...

不止于测试:用GStreamer打造你的树莓派低成本视频监控/图传系统
树莓派视频监控实战:用GStreamer构建低成本图传系统 树莓派搭配普通USB摄像头能做什么?大多数人可能只想到简单的视频采集测试。但如果你掌握GStreamer这个多媒体框架的进阶用法,就能将它变成一套功能完整的视频监控或无线图传系统。本文将彻…...

Obsidian 完整使用手册 — 目录与索引
Obsidian 完整使用手册 — 目录与索引 一份从入门到精通的 Obsidian 全面指南,涵盖基础操作、核心功能、插件生态、同步备份与进阶技巧。 手册列表 编号手册名称内容概要01基础入门篇软件安装、界面布局、库管理、核心设置02Markdown 语法篇格式化语法、扩展语法、…...