Golang爬虫封装
引言
爬虫是一种自动化地从网页中提取信息的程序,它在现代互联网的数据获取和分析中扮演着重要的角色。Golang作为一门强大的编程语言,也提供了丰富的工具和库来实现爬虫功能。在本文中,我们将探讨如何使用Golang来封装一个灵活、高效的爬虫程序。
1. Golang爬虫概述
在开始讨论封装爬虫之前,我们先来了解一下Golang中的爬虫概念和基本原理。爬虫通常由以下几个组件组成:
- 网页下载器:负责从URL中下载网页内容。
- 网页解析器:负责解析网页内容,提取所需的数据。
- 数据存储器:负责将提取的数据存储到本地或者数据库中。
Golang提供了许多强大的库和工具来实现这些组件,如net/http库用于下载网页,goquery库用于解析HTML,database/sql库用于数据存储等。
2. 封装爬虫功能模块
为了提高代码的可读性和可维护性,我们将爬虫功能模块进行封装。以下是一个简单的爬虫封装示例:
package crawlerimport ("fmt""io/ioutil""net/http"
)type Crawler struct {
}func (c *Crawler) Download(url string) ([]byte, error) {resp, err := http.Get(url)if err != nil {return nil, err}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body)if err != nil {return nil, err}return body, nil
}func (c *Crawler) Parse(body []byte) {// 解析网页内容// 提取所需的数据
}func (c *Crawler) Store(data string) {// 存储数据到本地或数据库
}func (c *Crawler) Run(url string) {body, err := c.Download(url)if err != nil {fmt.Println("下载网页失败:", err)return}c.Parse(body)c.Store("提取的数据")
}
在上面的示例中,我们定义了一个Crawler结构体,其中包含了下载、解析和存储等功能。Download方法负责从给定的URL下载网页内容,并返回字节切片。Parse方法负责解析网页内容,提取所需的数据。Store方法负责将提取的数据存储到本地或数据库中。Run方法是爬虫的入口,负责调用其他功能方法来完成整个爬取流程。
3. 使用爬虫封装模块
使用封装的爬虫模块非常简单,只需实例化Crawler结构体并调用Run方法即可。以下是一个使用示例:
package mainimport "crawler"func main() {c := crawler.Crawler{}c.Run("http://example.com")
}
在上面的示例中,我们导入了封装的爬虫模块,实例化Crawler结构体并调用Run方法来启动爬虫程序。这样就完成了一个简单的爬虫任务。
4. 爬虫的进一步封装
上面的示例只是一个简单的爬虫封装模块,实际应用中可能需要更多的功能和扩展。下面是一些可以进一步封装的功能点:
并发爬取
使用Golang的并发特性,可以实现爬虫的并发执行,提高爬取效率。我们可以使用goroutine和channel来实现并发爬取,例如使用一个WorkPool来控制并发数量,每个goroutine负责一个URL的下载、解析和存储。
定时爬取
如果需要定时执行爬取任务,可以使用Golang的time包来实现定时任务。可以创建一个定时器,在每个时间间隔内执行爬取任务。
动态配置
为了增加灵活性,可以将爬虫的配置参数进行动态化。可以使用Golang的flag包来定义命令行参数,或者使用配置文件来配置爬虫的各项参数。
错误处理
在爬虫过程中可能会遇到网络异常、解析错误等问题,我们需要对这些错误进行恰当的处理。可以使用Golang的error类型来表示错误,并进行适当的错误处理和日志记录。
5. 案例1:爬取图片链接
在这个案例中,我们将演示如何使用封装的爬虫模块来爬取网页中的图片链接。我们将使用goquery库来解析HTML并提取图片链接。
首先,我们在Parse方法中添加以下代码来解析网页并提取图片链接:
func (c *Crawler) Parse(body []byte) {doc, err := goquery.NewDocumentFromReader(bytes.NewReader(body))if err != nil {log.Fatal(err)}doc.Find("img").Each(func(i int, s *goquery.Selection) {link, exists := s.Attr("src")if exists {fmt.Println(link)}})
}
在上述代码中,我们使用goquery库的NewDocumentFromReader方法将HTML内容解析为Document对象。然后,我们使用Find方法和选择器img来找到网页中的所有图片元素。然后,我们使用Attr方法获取图片元素的src属性值,即图片链接。最后,我们将图片链接打印出来。
接下来,我们在main函数中添加以下代码来运行爬虫:
func main() {crawler := NewCrawler()crawler.Run("https://www.example.com")
}
这个案例将爬取https://www.example.com网页中的所有图片链接,并将其打印出来。
6. 案例2:爬取文章标题和内容
在这个案例中,我们将使用封装的爬虫模块来爬取网页中的文章标题和内容。我们将使用goquery库来解析HTML并提取文章标题和内容。
首先,我们在Parse方法中添加以下代码来解析网页并提取文章标题和内容:
func (c *Crawler) Parse(body []byte) {doc, err := goquery.NewDocumentFromReader(bytes.NewReader(body))if err != nil {log.Fatal(err)}title := doc.Find("h1").Text()fmt.Println("标题:", title)content := doc.Find("div.content").Text()fmt.Println("内容:", content)
}
在上述代码中,我们使用goquery库的NewDocumentFromReader方法将HTML内容解析为Document对象。然后,我们使用Find方法和选择器h1来找到网页中的标题元素,使用Text方法获取标题文本,并将其打印出来。接着,我们使用Find方法和选择器div.content来找到网页中的内容元素,使用Text方法获取内容文本,并将其打印出来。
接下来,我们在main函数中添加以下代码来运行爬虫:
func main() {crawler := NewCrawler()crawler.Run("https://www.example.com/article/1")
}
这个案例将爬取https://www.example.com/article/1网页中的文章标题和内容,并将其打印出来。
7. 案例3:爬取商品信息
在这个案例中,我们将使用封装的爬虫模块来爬取网页中的商品信息。我们将使用goquery库来解析HTML并提取商品信息。
首先,我们定义一个Product结构体来表示商品信息:
type Product struct {Name stringPrice string
}
然后,我们在Parse方法中添加以下代码来解析网页并提取商品信息:
func (c *Crawler) Parse(body []byte) {doc, err := goquery.NewDocumentFromReader(bytes.NewReader(body))if err != nil {log.Fatal(err)}doc.Find("div.product").Each(func(i int, s *goquery.Selection) {name := s.Find("h3").Text()price := s.Find("span.price").Text()product := Product{Name: name,Price: price,}fmt.Println("商品:", product)})
}
在上述代码中,我们使用goquery库的NewDocumentFromReader方法将HTML内容解析为Document对象。然后,我们使用Find方法和选择器div.product来找到网页中的所有商品元素。然后,我们使用Find方法和选择器h3来找到商品元素中的名称元素,使用Text方法获取名称文本。接着,我们使用Find方法和选择器span.price来找到商品元素中的价格元素,使用Text方法获取价格文本。最后,我们将商品名称和价格组成一个Product对象,并将其打印出来。
接下来,我们在main函数中添加以下代码来运行爬虫:
func main() {crawler := NewCrawler()crawler.Run("https://www.example.com/products")
}
这个案例将爬取https://www.example.com/products网页中的所有商品信息,并将其打印出来。
结论
Golang提供了丰富的库和工具来实现爬虫功能。通过封装爬虫模块,我们可以提高代码的可读性和可维护性,并实现更多的功能扩展。希望本文对你理解和使用Golang爬虫封装有所帮助。
参考文献
- “Building a Web Scraper with Golang” - https://towardsdatascience.com/building-a-web-scraper-with-golang-3f8605543051
- “An Introduction to Web Scraping with Golang” - https://www.scrapingbee.com/blog/web-scraping-golang/
- “Web scraping in Go, the easy way” - https://hackernoon.com/web-scraping-in-go-the-easy-way-93a34f3278c7
相关文章:

Golang爬虫封装
引言 爬虫是一种自动化地从网页中提取信息的程序,它在现代互联网的数据获取和分析中扮演着重要的角色。Golang作为一门强大的编程语言,也提供了丰富的工具和库来实现爬虫功能。在本文中,我们将探讨如何使用Golang来封装一个灵活、高效的爬虫…...

技术分享 | 抓包分析 TCP 协议
TCP 协议是在传输层中,一种面向连接的、可靠的、基于字节流的传输层通信协议。 环境准备 对接口测试工具进行分类,可以如下几类: 网络嗅探工具:tcpdump,wireshark代理工具:fiddler,charles&a…...

基于前馈神经网络完成鸢尾花分类
目录 1 小批量梯度下降法 1.0 展开聊一聊~ 1.1 数据分组 1.2 用DataLoader进行封装 1.3 模型构建 1.4 完善Runner类 1.5 模型训练 1.6 模型评价 1.7 模型预测 思考 总结 参考文献 首先基础知识铺垫~ 继续使用第三章中的鸢尾花分类任务,将Softm…...

软考高级系统架构设计师系列之:UML建模、设计模式和软件架构设计章节选择题详解
软考高级系统架构设计师系列之:UML建模、设计模式和软件架构设计章节选择题详解 一、设计模式二、4+1模型三、面向对象的分析模型四、构件五、基于架构的软件设计六、4+1视图七、软件架构风格八、特定领域软件架构九、虚拟机十、架构评估十一、敏感点和权衡点十二、分层结构十…...

成集云 | 电商平台、ERP、WMS集成 | 解决方案
电商平台ERPWMS 方案介绍 电商平台即是一个为企业或个人提供网上交易洽谈的平台。企业电子商务平台是建立在Internet网上进行商务活动的虚拟网络空间和保障商务顺利运营的管理环境;是协调、整合信息流、货物流、资金流有序、关联、高效流动的重要场所。企业、商家…...

吴恩达《机器学习》4-6->4-7:正规方程
一、正规方程基本思想 正规方程是一种通过数学推导来求解线性回归参数的方法,它通过最小化代价函数来找到最优参数。 代价函数 J(θ) 用于度量模型预测值与实际值之间的误差,通常采用均方误差。 二、步骤 准备数据集,包括特征矩阵 X 和目标…...

VO、DTO
DTO DTO(Data Transfer Object) 数据传输对象【前后端交互】 也就是后端开发过程中,用来接收前端传过来的参数,一般会创建一个Java对应的DTO类(UserDTO等等) 因为前端一般传来的是Json格式的数据…...

RK3566上运行yolov5模型进行图像识别
一、简介 本文记录了依靠RK官网的文档,一步步搭建环境到最终在rk3566上把yolov5 模型跑起来。最终实现的效果如下: 在rk3566 板端运行如下app: ./rknn_yolov5_demo model/RK356X/yolov5s-640-640.rknn model/bus.jpg其中yolov5s-640-640.r…...

汽车标定技术(一):XCP概述
目录 1.汽车标定概述 2.XCP协议由来及版本介绍 3.XCP技术通览 3.1 XCP上下机通信模型 3.2 XCP指令集 3.2.1 XCP帧结构定义 3.2.2 标准指令集 3.2.3 标定指令集 3.2.4 页切换指令集 3.2.5 数据采集指令集 3.2.6 刷写指令集 3.3 ECU描述文件(A2L)概述 3.3.1 标定上位…...

短视频的运营方法
尊敬的用户们,你们好!今天我将为大家带来一篇关于短视频运营的专业文章。在当今互联网时代,短视频已经成为了一个重要的流量入口,掌握正确的运营方法对于企业的发展至关重要。接下来,我将通过以下几个方面为大家详细介…...
GitLab CI/CD 持续集成/部署 SpringBoot 项目
一、GitLab CI/CD 介绍 GitLab CI/CD(Continuous Integration/Continuous Deployment)是 GitLab 提供的一种持续集成和持续部署的解决方案。它可以自动化软件的构建、测试和部署过程,以便开发者更快地、更频繁地发布可靠的产品。 整体过程如…...

第二证券:政策效应逐步显现 A股修复行情有望持续演绎
上星期,A股商场延续企稳反弹的态势,上证指数震荡上涨0.43%;沪深两市日均成交额回升至8700亿元左右;北向资金近一个月初次转为周净买入5.57亿元。 安排观点一起认为,在稳增加、稳预期相关政策持续发力,上市…...

sql逻辑优化
1.分页 通常使用每页条数及第一页作为参数 开发接口 GetMapping("/querySystemList") public List<SystemAduit> querySystemList(RequestParam("keyword") String keyword,RequestParam(name "offset", defaultValue "0") i…...
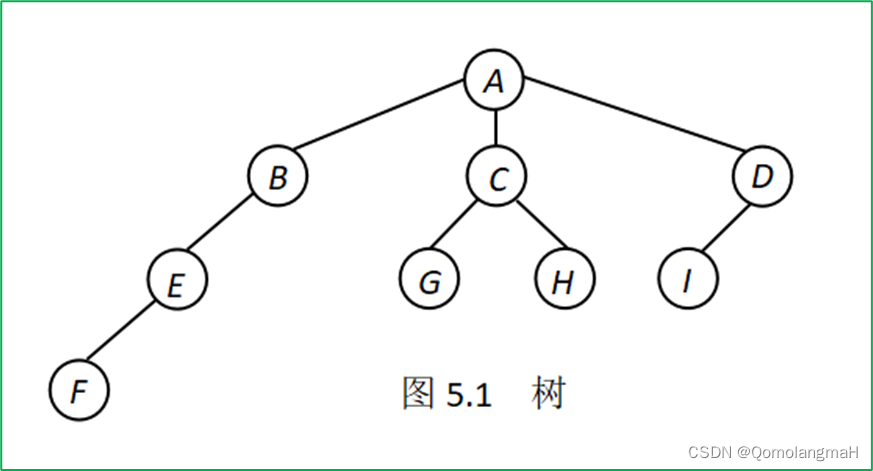
【数据结构】树与二叉树(一):树(森林)的基本概念:父亲、儿子、兄弟、后裔、祖先、度、叶子结点、分支结点、结点的层数、路径、路径长度、结点的深度、树的深度
文章目录 5.1 树的基本概念5.1.1 树的定义树有序树、无序树 5.1.2 森林的定义5.1.3 树的术语1. 父亲(parent)、儿子(child)、兄弟(sibling)、后裔(descendant)、祖先(anc…...

2024 Android Framework学习大纲之基础理论篇
2024 Android Framework学习大纲之基础理论篇 受到当前经济影响,互联网越来越不景气了,因此Android App开发也是越来越不景气,中小型公司越来越偏向跨平台开发,比如Flutter,这样能节省成本,笔者也曾经是一名6年多工作经…...

【深度学习】Yolov8 区域计数
git:https://github.com/ultralytics/ultralytics/blob/main/examples/YOLOv8-Region-Counter/readme.md 很长时间没有做yolov的项目了,最近一看yolov8有一个区域计数的功能,不得不说很实用啊。 b站:https://www.bilibili.com/vid…...
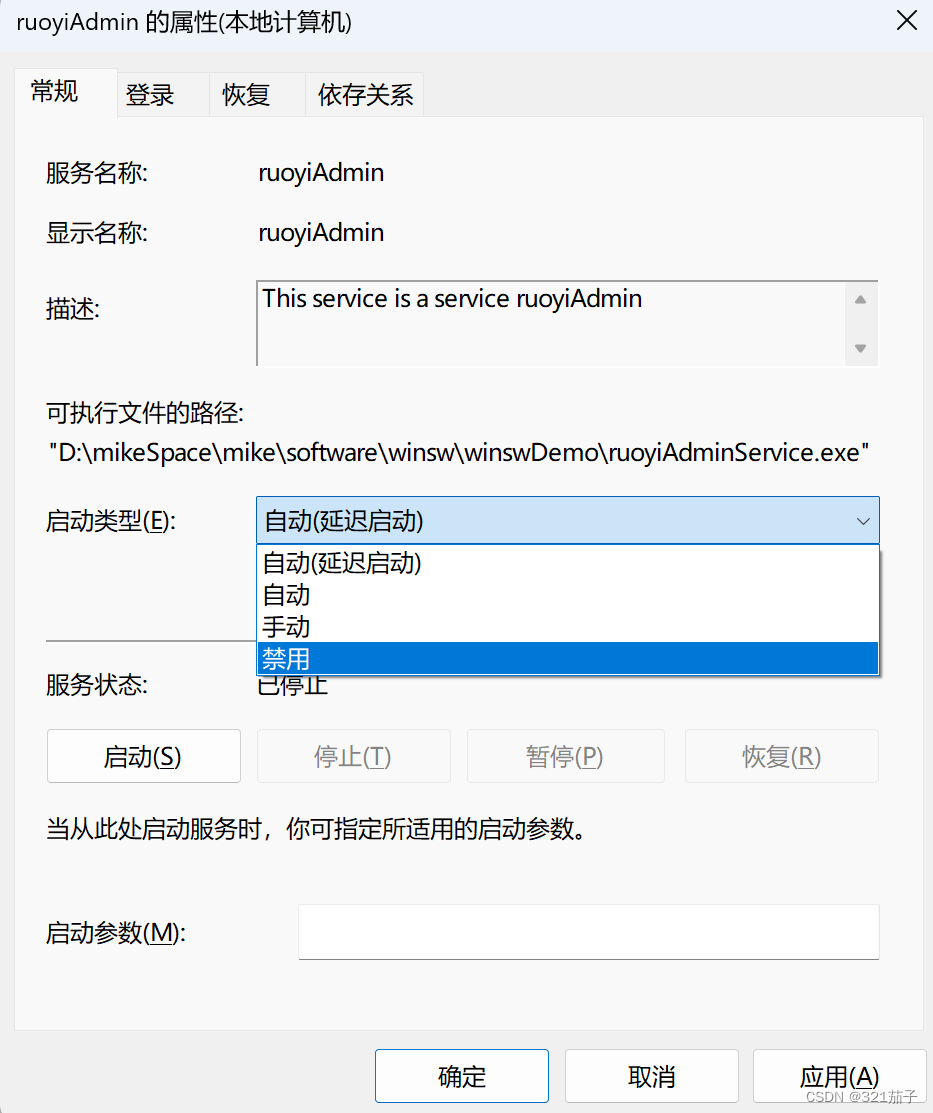
Windows 系统服务器部署jar包时,推荐使用winsw,将jar包注册成服务,并设置开机启动。
一、其他方式不推荐的原因 1、Spring Boot生成的jar包,可以直接用java -jar运行,但是前提是需要登录用户,而且注销用户后会退出程序,所以不可用。 2、使用计划任务,写一个bat处理文件,里面写java -jar运行…...

npm 包管理
1. 命令 // 查看是否登录 npm who am i // 登录:输入用户名、密码、邮箱、一次性登录密码(邮箱接收) npm login // 创建 npm init // 快速创建 npm init -y // 发包 npm publish // 发包(开源) npm publish --access …...
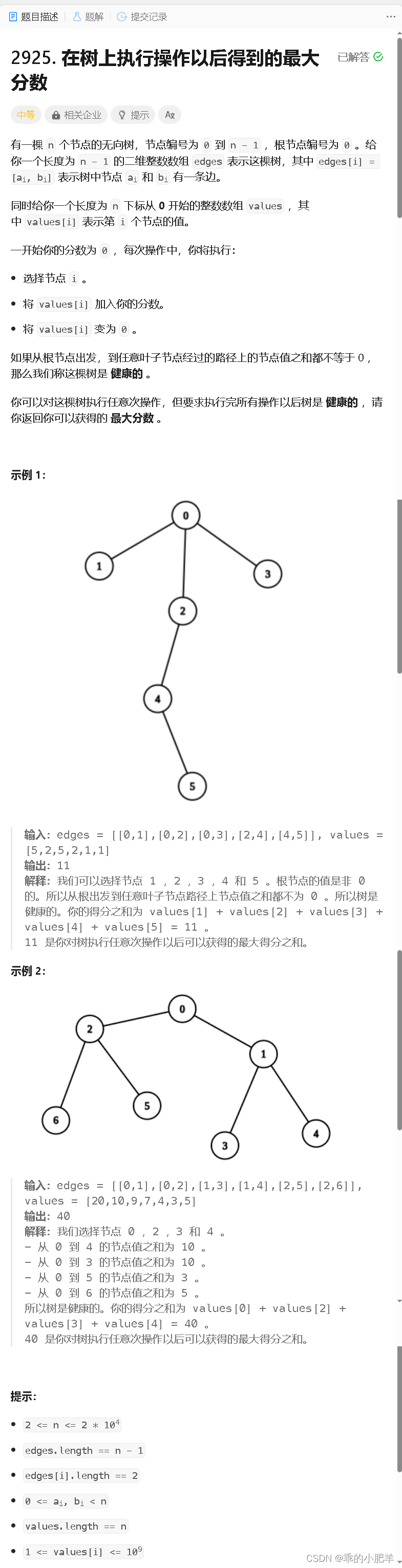
力扣370周赛 -- 第三题(树形DP)
该题的方法,也有点背包的意思,如果一些不懂的朋友,可以从背包的角度去理解该树形DP 问题 题解主要在注释里 //该题是背包问题树形dp问题的结合版,在树上解决背包问题 //背包问题就是选或不选当前物品 //本题求的是最大分数 //先转…...

GPT学习笔记
百度的文心一言 阿里的通义千问 通过GPT能力,提升用户体验和产品力 GPT的出现是AI的iPhone时刻。2007年1月9日,第一代iPhone发布,开启移动互联网时代。新一轮的产业革命。 GPT模型发展时间线: Copilot - 副驾驶 应用…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...