【pytorch源码分析--torch执行流程与编译原理】

背景
- 解读torch源码方便算子开发
- 方便后续做torch 模型性能开发
基本介绍
代码库
- https://github.com/pytorch/pytorch
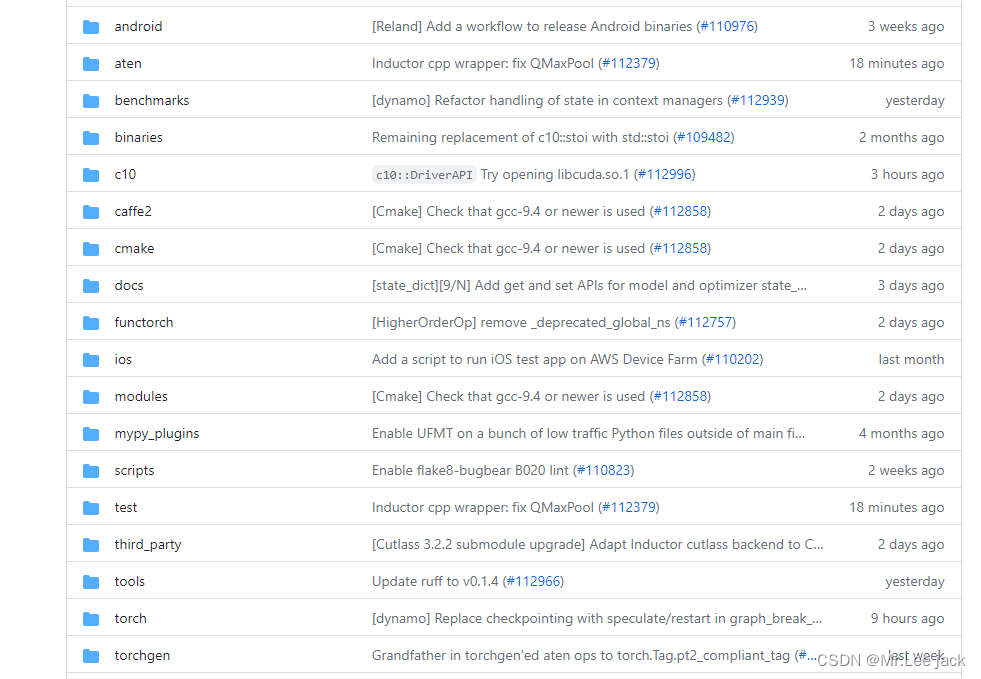
模块介绍
-
aten: A Tensor Library的缩写。与Tensor相关的内容都放在这个目录下。如Tensor的定义、存储、Tensor间的操作(即算子/OP)等
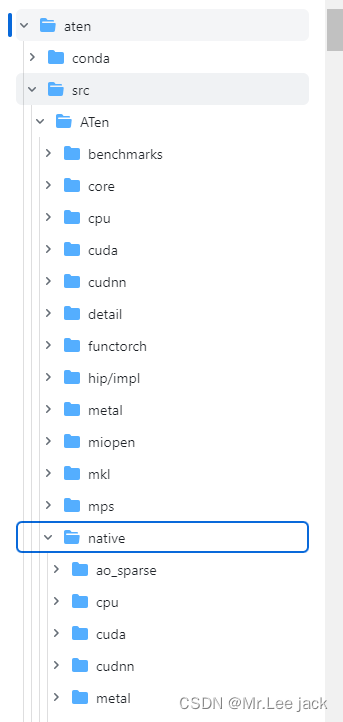
可以看到在aten/src/Aten目录下,算子实现都在native/目录中。其中有CPU的算子实现,以及CUDA的算子实现(cuda/)等 -
torch: 即PyTorch的前端代码。我们用户在import torch时实际引入的是这个目录。
其中包括前端的Python文件,也包括高性能的c++底层实现(csrc/)。为实现Python和c++模块的打通,这里使用了pybind作为胶水。在python中使用torch._C.[name]实际调用的就是libtorch.so中的c++实现,而PyTorch在前端将其进一步封装为python函数供用户调用 -
c10、caffe2:移植caffe后端,c10指的是caffe tensor library,相当于caffe的aten。
PyTorch1.0完整移植了caffe2的源码,将两个项目进行了合并。引入caffe的原因是Pytorch本身拥有良好的前端,caffe2拥有良好的后端,二者在开发过程中拥有大量共享代码和库。简而言之,caffe2是一个c++代码,实现了各种设备后端逻辑 -
tools:用于代码自动生成(codegen),例如autograd根据配置文件实现反向求导OP的映射。
-
scripts:一些脚本,用于不同平台项目构建或其他功能性脚本
小结
- PyTorch源码中,最重要的两个目录是aten和torch目录
- aten(A Tensor Library)目录主要是和Tensor相关实现的目录,包括算子的具体实现
- torch目录是PyTorch前端及其底层实现,用户import torch即安装的这个目录
torch前端与后端
-
PyTorch 中,前端指的是 PyTorch 的 Python 接口,
-
后端指的是 PyTorch 的底层 C++ 引擎,它负责执行前端指定的计算
-
后端引擎也负责与底层平台(如 GPU 和 CPU)进行交互,并将计算转换为底层平台能够执行的指令
-
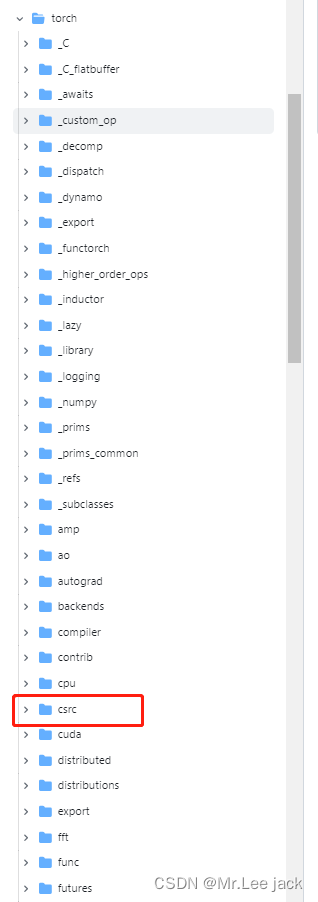
-
编译后的torch前端接口没有csrc后端接口,该部分c++内容(csrc目录)并没有被复制过来,而是以编译好的动态库文件(_C.cpython-*.so)
前后端交互流程
- 我们以torch.Tensor为例
import torch
torch.Tensor
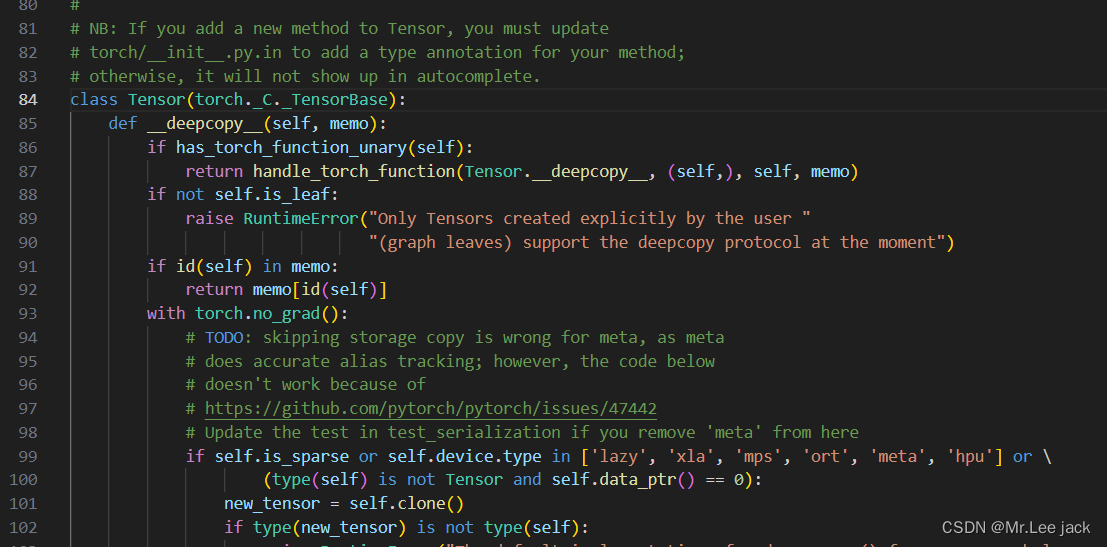
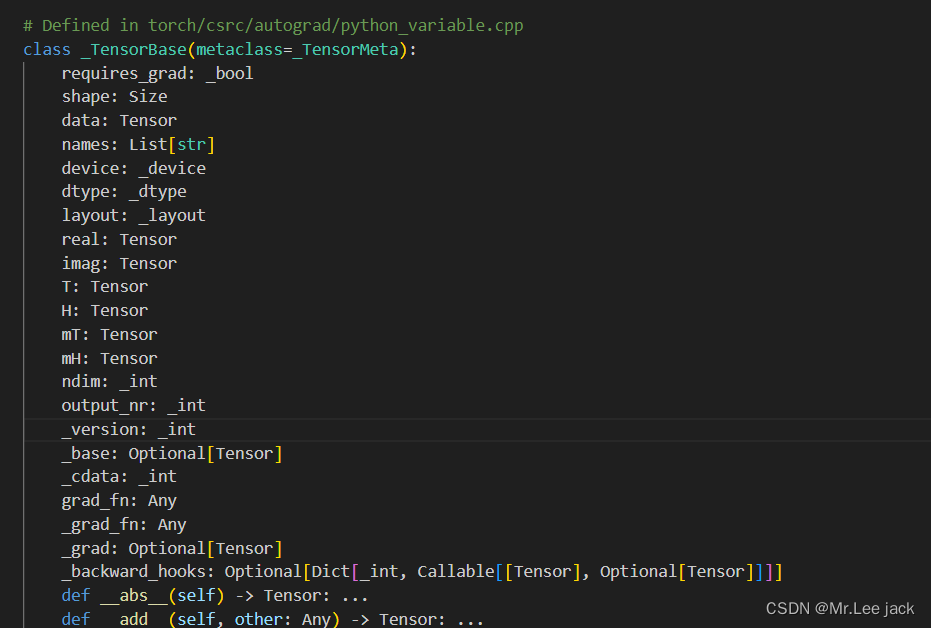
结论是对应实现在 torch/csrc/autograd/python_variable.cpp中,而这个是通过编译后的so包实现_C调用,因为pyi是一个python存根文件,只有定义没有实现,实现都在python_variable.cpp中
- 看看对应c++的实现逻
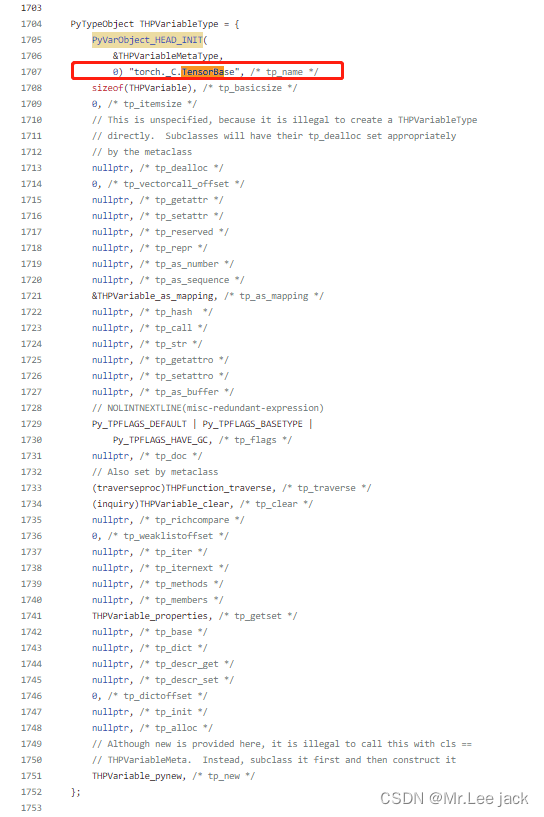


小结
- PyTorch前端主要是python API,在设计上采用Pythonic式的编程风格,可以让用户像使用python一样使用PyTorch
- 而后端主要指C++ API,其对外提供的C++接口,也可以一定程度上实现PyTorch的大部分功能,而且更适用于嵌入式等场景
- 而前端主要是通过pybind调用的后端c++实现,具体是c++被编译成_C.[***].so动态库,然后python调用torch._C实现调用c++中的函数
动态图与静态图
一个主流的训练框架需要有两大特征:
-
实现类似numpy的张量计算,可以使用GPU进行加速;
-
实现带自动微分系统的深度神经网络
静态图
- 在TensorFlow1.x中,我们如果需要执行计算,需要建立一个session,并执行session.run()来执行
import tensorflow as tfa = tf.ones(5)
b = tf.ones(5)
c = a + b
sess = tf.Session()
print(sess.run(c))
- 其整个过程其实是将计算过程构成了一张计算图,然后运行这个图的根节点。这样先构成图,再运行图的方式我们称为静态图或者图模式
动态图
- 在PyTorch中,我们可以在计算的任意步骤直接输出结果(当然最新的ensorflow已经支持动态模式)
- PyTorch每一条语句是同步执行的,即每一条语句都是一个(或多个)算子,被调用时实时执行。这种实时执行算子的方式我们称为动态图或算子模式
import tensorflow as tfa = tf.ones(5)
b = tf.ones(5)
c = a + b
print(c) # tf.Tensor([2. 2. 2. 2. 2.], shape=(5,), dtype=float32)
import torcha = torch.ones(5)
b = torch.ones(5)
c = a + b
print(c) # tensor([2., 2., 2., 2., 2.])
小结
- 动态图的优点显而易见,可以兼容Python式的编程风格,实时打印编程结果,用户友好性做到最佳;
- 静态图则在性能方面有一定优势,即在整个图执行前,可以将整张图进行编译优化,通过融合等策略改变图结构,从而实现较好的性能
- PyTorch原生支持动态图,但是也在静态图方面做了诸多尝试,例如 torchscript(jit.script、jit.trace)、TorchDynamo、torch.fx、LazyTensor
图原理
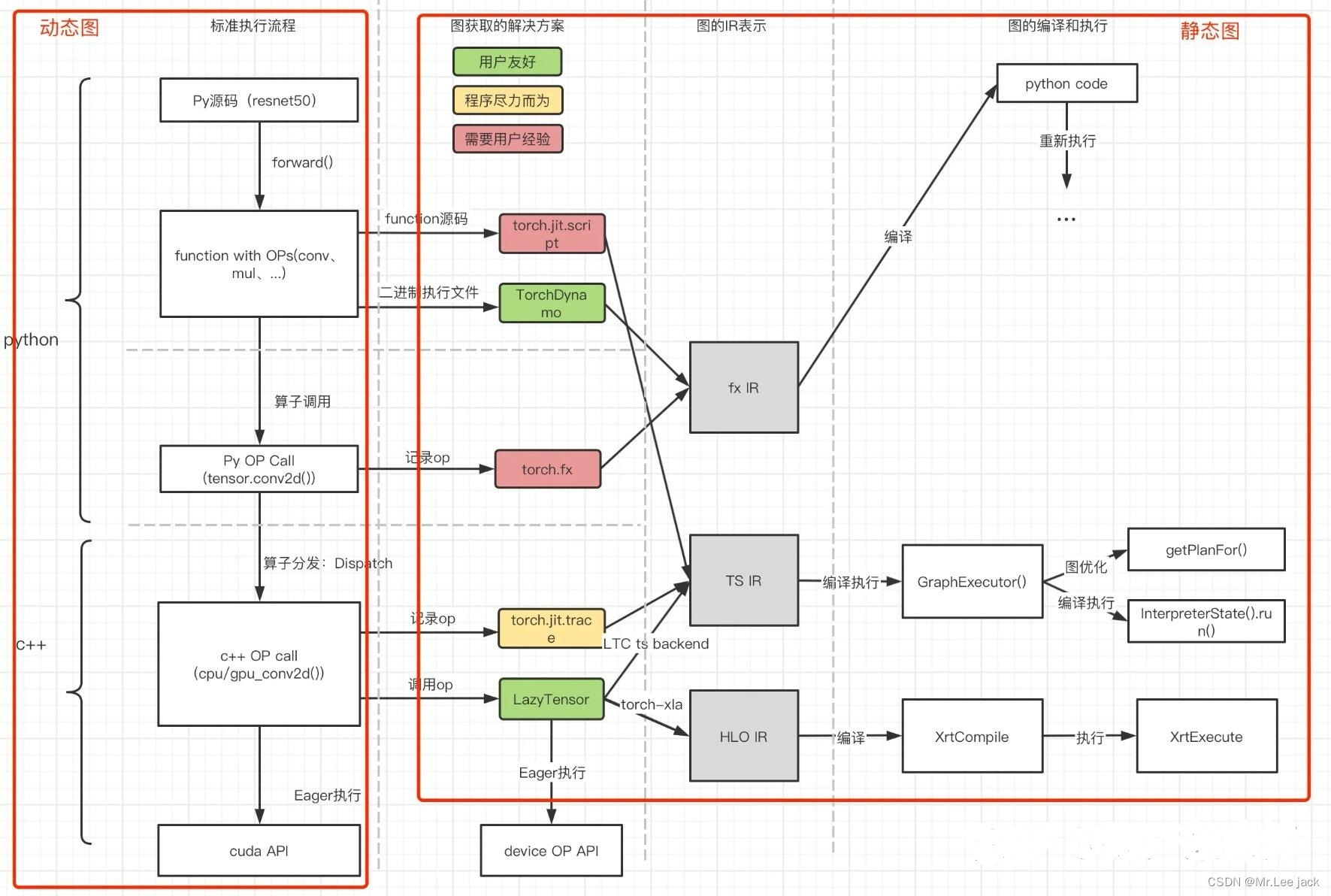
动态图&静态图&dispatch原理解读视频
动态图
- 首先PyTorch的动态图是从Python源码下降,拆分成多个python算子调用,具体调用到tensor的OP。经过pybind转换到c++,并通过dispatch机制选择不同设备下的算子实现,最终实现调用的底层设备实现(如Nvidia cudnn、intel mkl等)
静态图
jit.script
- jit.script是在python源码角度分析function的源码,将python code转换为图(torchscript IR格式)。由于是直接从python源码转的,因此有许多python语法无法完备支持,存在转换失败的可能性
jit.trace
- jit.trace则是在c++层面获取算子,在算子调用时记录成图(torchscript IR格式)。由于需要下降到c++,因此需要输入一遍数据真正“执行”一遍。而获取的图具有确定性,即如果图存在分支,则只能被trace记录其中一个分支的计算路线
torch.fx
- python层面算子调用时记录的算子,输出是fx IR格式的图
LazyTensor
- 在算子调用时记录成的图,该调用会截获正常算子的运行,在用户指定同步时再整体运行已积累的图
TorchDynamo
- 将python源码转变成二进制后,通过分析二进制源码,获取分析的算子和图。最新的PyTorch1.14(2.0)中将其作为torch.compile()的主要路线
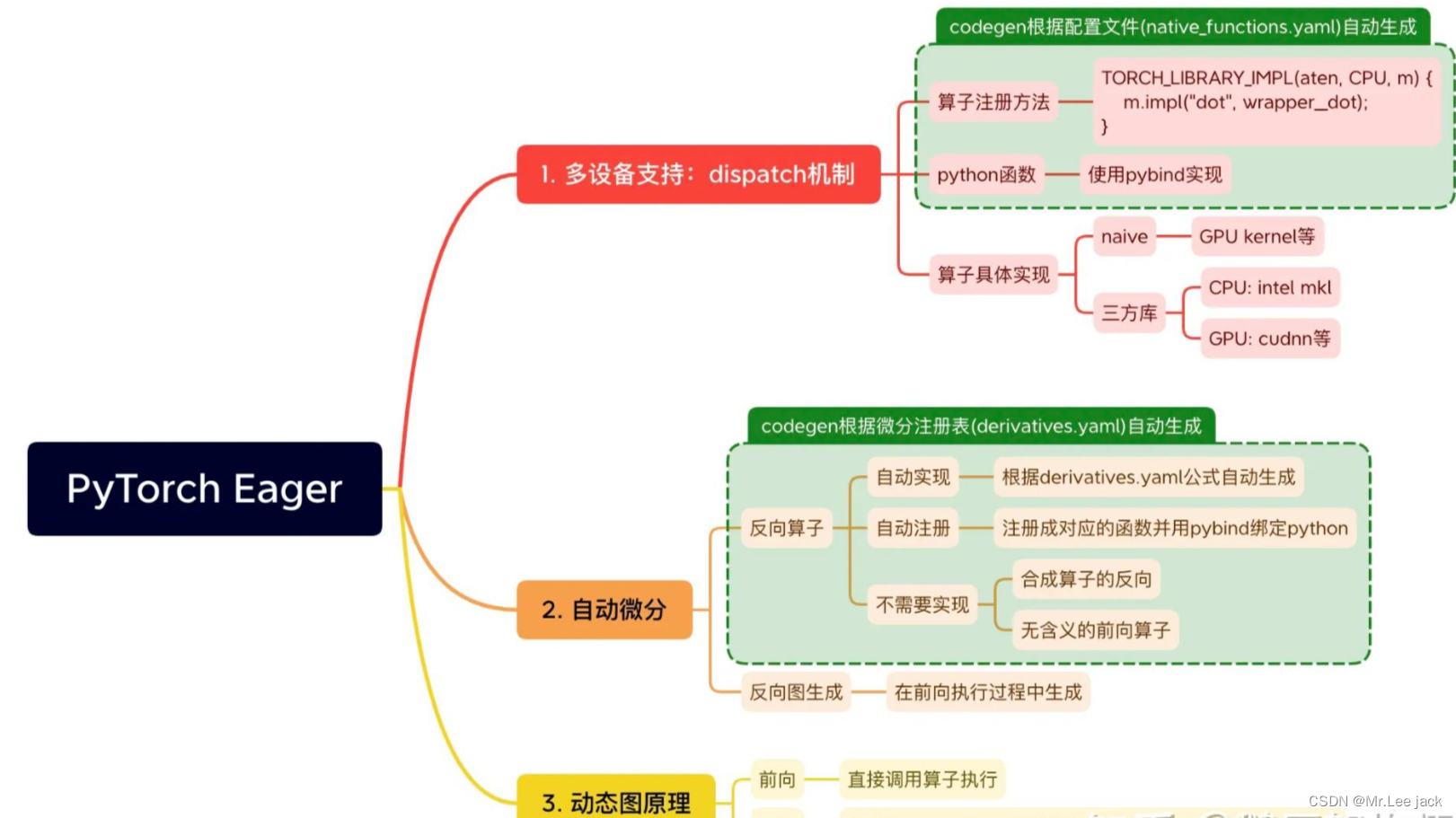
算子支持与dispatch机制
-
小结训练框架最重要的特点是:
- 支持类似numpy的张量计算,可以使用GPU加速;
- 支持带自动微分系统的深度神经网络;
- 原生支持动态图执行
针对以上问题,提出3个问题:
- PyTorch如何支持CPU、GPU等诸多设备的?
- PyTorch如何实现自动微分的?
- 动态图的原理是什么?
动态图Dispatch机制
import torcha = torch.randn(5, 5)
b = torch.randn(5, 5)
c = a.add(b)
print(c.device) # cpua = a.to("cuda")
b = b.to("cuda")
c = a.add(b)
print(c.device) # cuda
- 上述示例中,a.add(b)这个算子,无论是cpu设备的tensor还是gpu设备的tensor,都可以得以支持
- 为什么同一个算子在不同设备上都能运行呢?
dispatch机制
- 文档:
https://pytorch.org/tutorials/advanced/dispatcher.html
原理
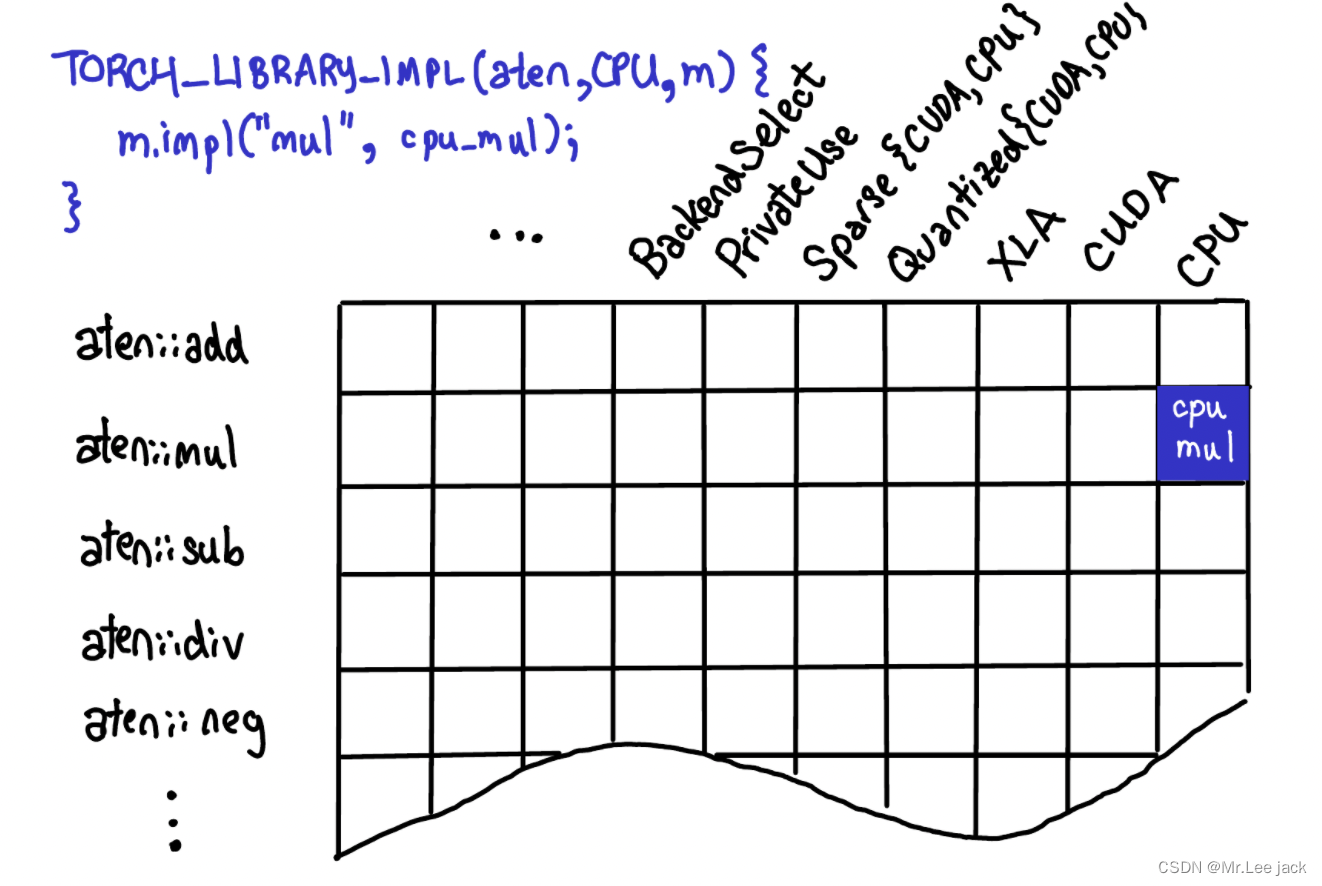

- 我们可以将Dispatch机制看做一个二维的表结构。其一个维度是各类设备(CPU、CUDA、XLA、ROCM等等),一个维度是各类算子(add、mul、sub等等)。
- PyTorch提供了一套定义(def)、实现(impl)机制,可以实现某算子在某设备(dispatch key)的绑定
aten/src/ATen/core/NamedRegistrations.cpp算子注册机制
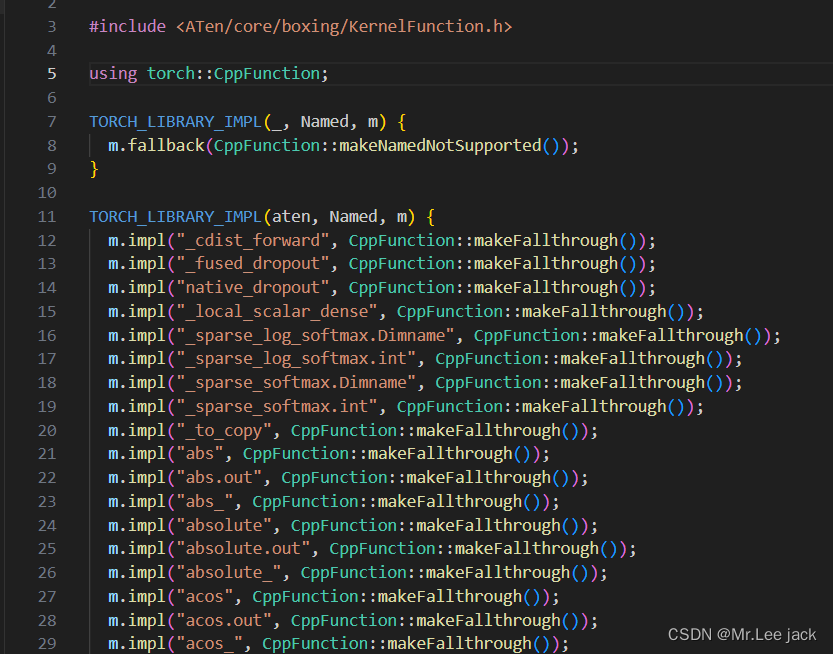
例如m.impl()中就是对dispatch key为CPU时neg算子的实现绑定,其绑定了neg_cpu()这个函数
大多数情况我们只需要实现m.impl,并绑定一个实现函数即可
-
除了m.def以及m.impl之外,还有m.fallback作为回退
在没有m.impl实现的情况下,默认回退的实现(例如fallback回cpu实现)。这样我们将不需要对cuda实现100%的算子实现,而是优先实现高优先级的算子,减少新设备情况下的开发量,而未被实现的算子则默认被fallback实现 -
实现一个定义算子add覆盖原始add算子(todo)
-
算子配置文件
native_functions.yaml
PyTorch中采用了算子配置文件aten/src/ATen/native/native_functions.yaml,配合codegen模块自动完成整个流程
也就是多有的自动注册流程会基于当前这个yaml配置文件自动生成算子注册方法与python bind实现
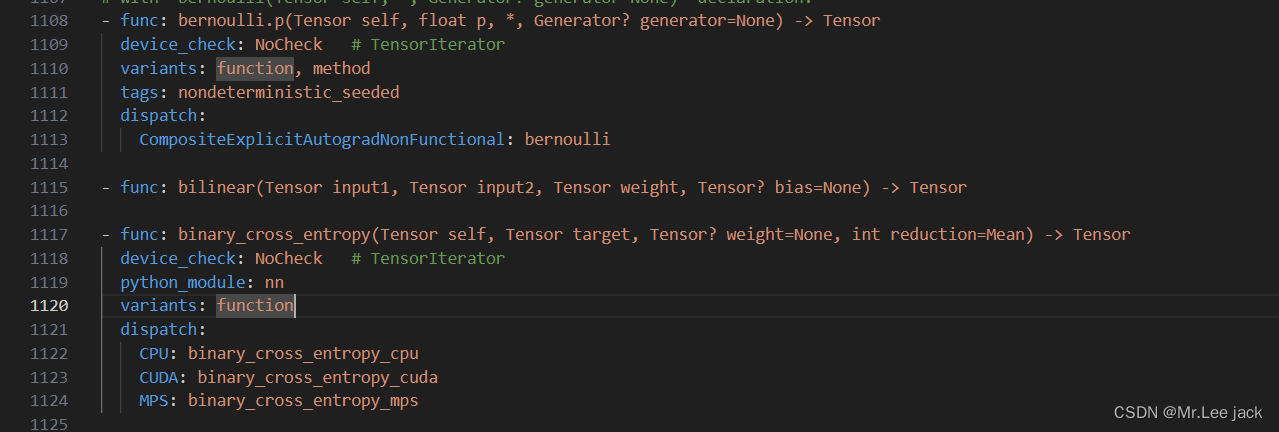
举例说明
以dot算子为例
- 配置
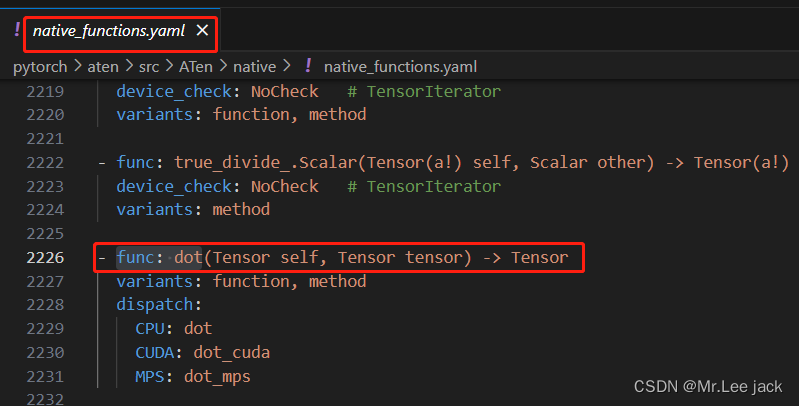
- 算子实现
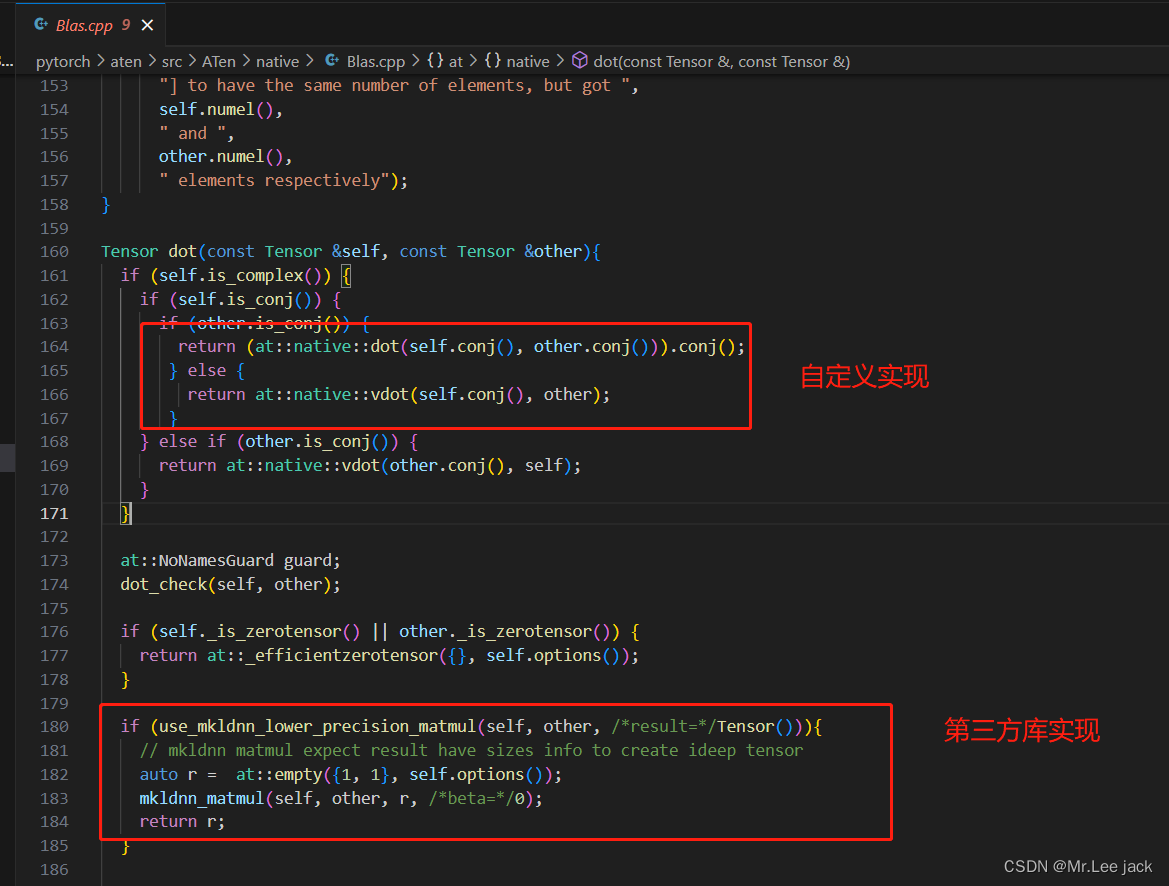
上诉代码手动编译后,由codegen会自动生成def、impl的实现,也会自动生成pybind的实现 - build文件夹找到自动生成的代码
pytorch/build/aten/src/ATen/RegisterCPU.cpptorch/csrc/autograd/generated/python_variable_methods.cpp
反向传播
-
dispatch实际是前向算子
-
类似的也有反向算子,配置文件derivatives.yaml,其位于
tools/autograd/derivatives.yaml
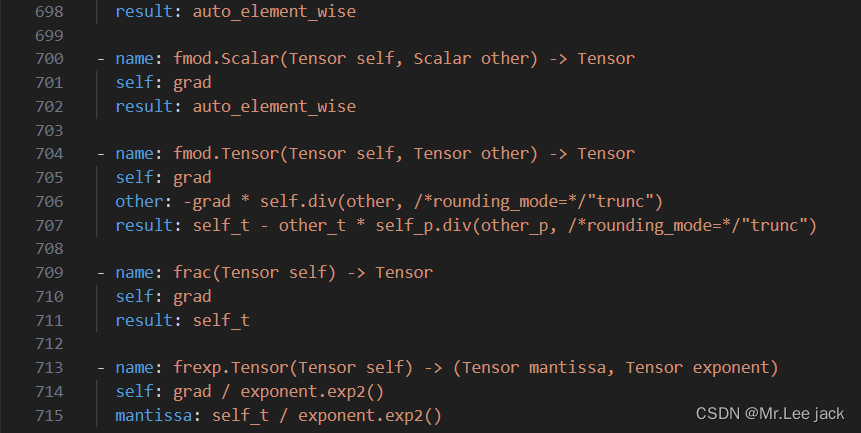
可以看到,每一个算子以“- name:”开头。
然后还包含一个result字段,这个字段其实就是这个算子的求导公式
前向算子会利用codegen自动生成注册部分的代码。同理,反向算子也可以根据算子微分注册表自动生成dispatch注册,然后被绑定到Python的函数中
有关梯度计算请参考
举例说明
- 配置

最后利用codegen根据算子微分注册表自动生成dispatch注册,然后被绑定到Python的函数中
动态图执行过程
- 前向过程
import torcha = torch.ones(5, 5)
b = torch.ones(5, 5)
c = a + b
print(c)
实际上在每执行一条python代码时,前向传播的算子都会被实时调用执行
在用户调用某算子(例如dot时),其实调用的是Tensor下的dot()函数实现。其具体实现在c++中,经过pybind和dispatch(选择设备)机制后定位带at::native::dot()函数。而后对于CPU来说,可以调用intel MKL库的mkldnn_matmul()实现
- 反向过程
import torcha = torch.ones(5, 5, requires_grad=True)
b = torch.ones(5, 5, requires_grad=True)
c = (a + b).sum()
c.backward()
print(c)
print(c.grad_fn)
# tensor(50., grad_fn=<SumBackward0>)
# <SumBackward0 object at 0x0000015E8DA2A730>
在执行loss.backward()时,实际调用执行的是各中间tensor的grad_fn,由于反向计算时会组成一个由grad_fn为节点,next_functions为边的反向图,因此如何高效执行这个图成为一个问题
为了解决这个问题,引入了根据设备数建立的线程池调度引擎
总结
- 源码编译:https://github.com/pytorch/pytorch/tree/main#adjust-build-options-optional
# 拉取依赖
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive# 编包
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
python setup.py build --cmake-only
ccmake build # or cmake-gui build
相关文章:
【pytorch源码分析--torch执行流程与编译原理】
背景 解读torch源码方便算子开发方便后续做torch 模型性能开发 基本介绍 代码库 https://github.com/pytorch/pytorch 模块介绍 aten: A Tensor Library的缩写。与Tensor相关的内容都放在这个目录下。如Tensor的定义、存储、Tensor间的操作(即算子/OPÿ…...

编辑器报警处理
1、warning CS8600: 将 null 文本或可能的 null 值转换为不可为 null 类型。 原代码 string returnedString Marshal.PtrToStringAuto(pReturnedString, (int)bytesReturned); 处理后的代码 string returnedString Marshal.PtrToStringAuto(pReturnedString, (int)bytesR…...
Python库学习(十二):数据分析Pandas[下篇]
接着上篇《Python库学习(十一):数据分析Pandas[上篇]》,继续学习Pandas 1.数据过滤 在数据处理中,我们经常会对数据进行过滤,为此Pandas中提供mask()和where()两个函数; mask(): 在 满足条件的情况下替换数据,而不满足条件的部分…...

工具: MarkDown学习
具体内容看官方教程: Markdown官方教程...
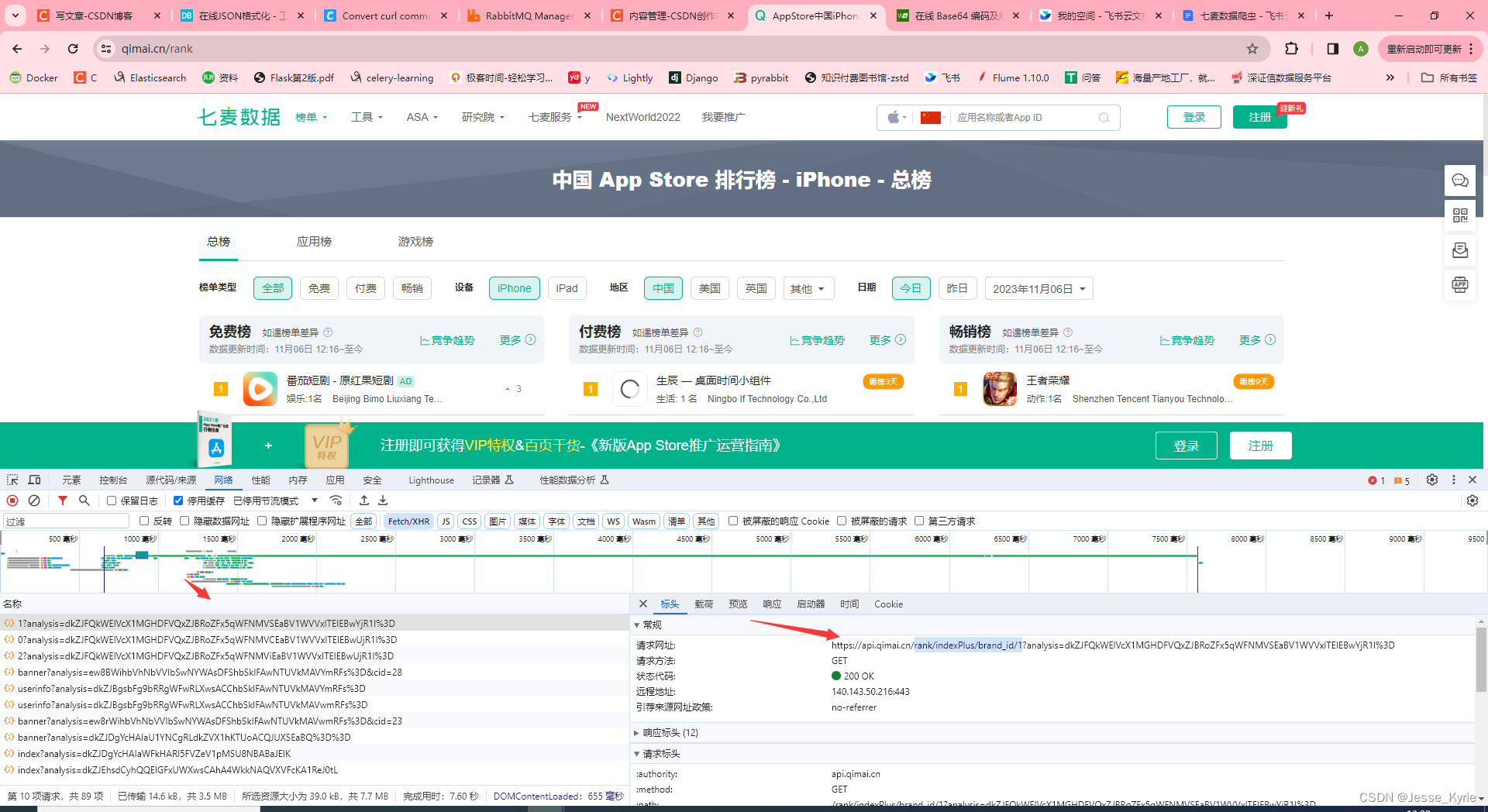
JS逆向爬虫---请求参数加密②【某麦数据analysis参数加密】
主页链接: https://www.qimai.cn/rank analysis逆向 完整参数生成代码如下: const {JSDOM} require(jsdom) const dom new JSDOM(<!DOCTYPE html><p>hello</p>) window dom.windowfunction customDecrypt(n, t) {t t || generateKey(); //…...
基于APM(PIX)飞控和missionplanner制作遥控无人车-从零搭建自主pix无人车无人坦克
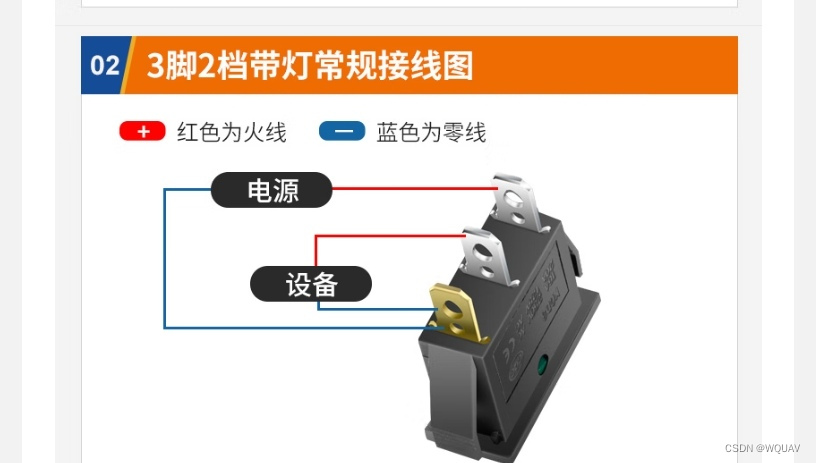
前面的步骤和无人机调试一样,可以参考无人机相关专栏。这里不再赘述。 1.安装完rover的固件后,链接gps并进行校准。旋转小车不同方向,完成校准,弹出成功窗口。 2.校准遥控器。 一定要确保遥控器模式准确,尤其是使用没…...
学习笔记)
Vue3的手脚架使用和组件父子间通信-插槽(Options API)学习笔记
Vue CLI安装和使用 全局安装最新vue3 npm install vue/cli -g升级Vue CLI: 如果是比较旧的版本,可以通过下面命令来升级 npm update vue/cli -g通过脚手架创建项目 vue create 01_product_demoVue3父子组件的通信 父传子 父组件 <template>…...

第九章软件管理
云计算第九章软件管理 概述 1RPM包 RPM Package Manager 由Red Hat公司提出被众多Linux发现版所采用 也称二进制无需编译可以直接使用 无法设定个人设置开关功能 软件包示例 认识ROM包 2源码包 source code 需要经过GCC,C编辑环境编译才能运行 可以设定个人设置&…...

Web渗透编程语言基础
Web渗透初学者JavaScript专栏汇总-CSDN博客 Web渗透Java初学者文章汇总-CSDN博客 一 Web渗透PHP语言基础 PHP 教程 | 菜鸟教程 (runoob.com) 一 PHP 语言的介绍 PHP是一种开源的服务器端脚本语言,它被广泛用于Web开发领域。PHP可以与HTML结合使用,创建动态网页。 PHP的特…...
Vue-router 路由的基本使用
Vue-router是一个Vue的插件库,专门用于实现SPA应用,也就是整个应用是一个完整的页面,点击页面上的导航不会跳转和刷新页面。 一、安装Vue-router npm i vue-router // Vue3安装4版本 npm i vue-router3 // Vue2安装3版本 二、引入…...
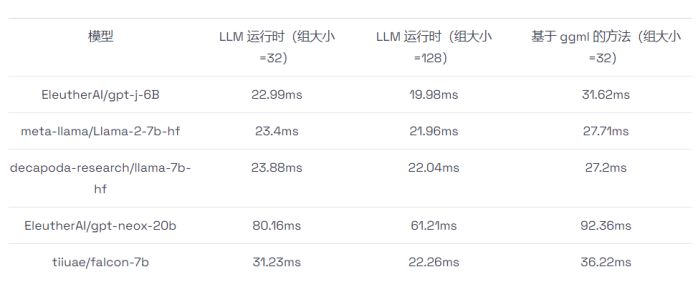
如何在CPU上进行高效大语言模型推理
大语言模型(LLMs)已经在广泛的任务中展示出了令人瞩目的表现和巨大的发展潜力。然而,由于这些模型的参数量异常庞大,使得它们的部署变得相当具有挑战性,这不仅需要有足够大的内存空间,还需要有高速的内存传…...
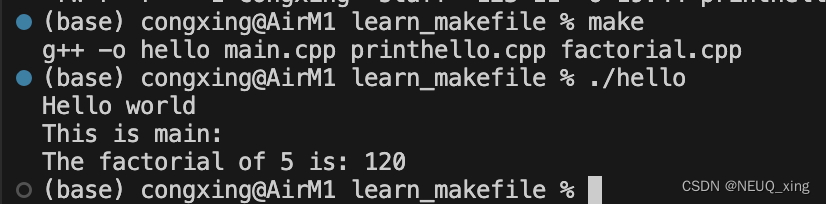
简简单单入门Makefile
笔记来源:于仕琪教授:Makefile 20分钟入门,简简单单,展示如何使用Makefile管理和编译C代码 操作环境 MacosVscode 前提准备 新建文件夹 mkdir learn_makefile新建三个cpp文件和一个头文件 // mian.cpp #include <iostrea…...
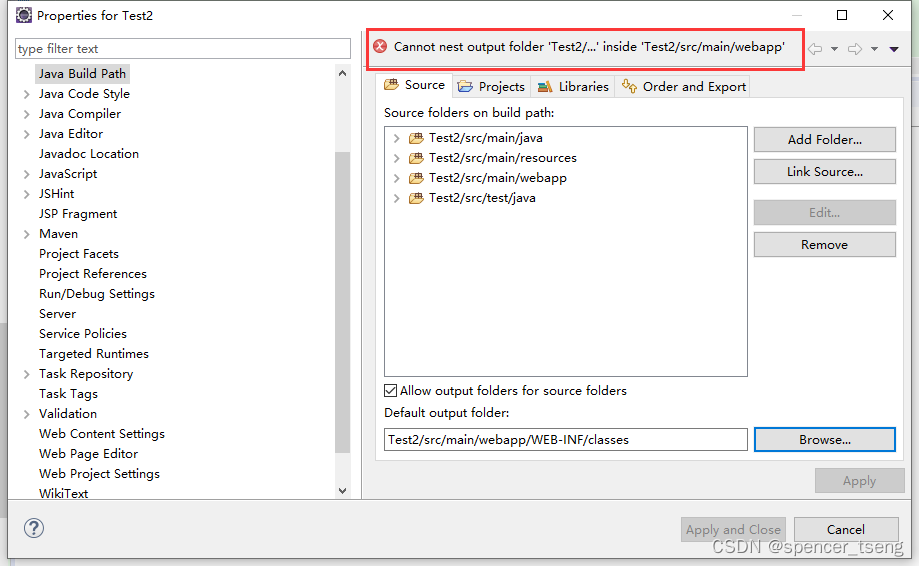
New Maven Project
下面两个目录丢失了: src/main/java(missing) src/test/java(missing) 换个JRE就可以跑出来了 变更目录...
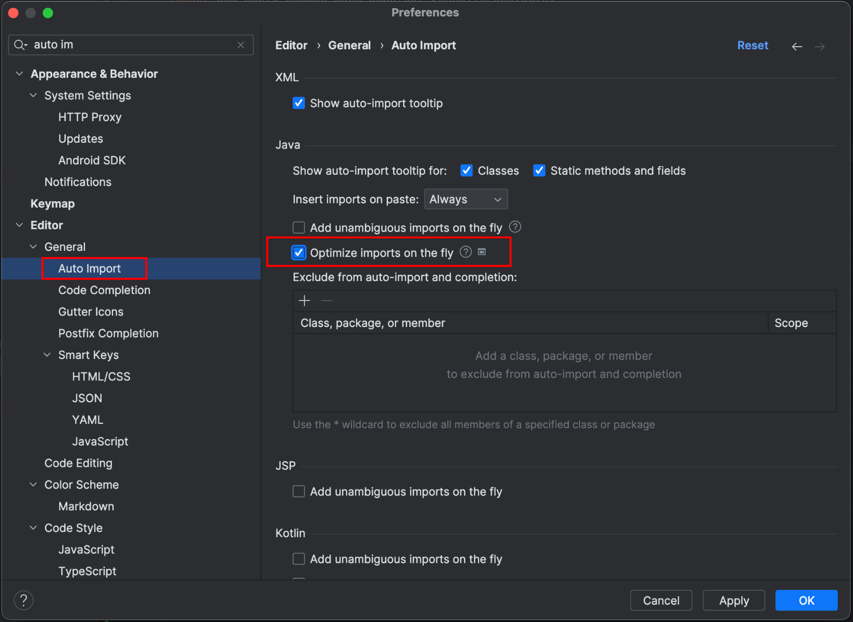
IDEA中如何移除未使用的import
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是全栈工…...
)
第18章_MySQL8新特性之CTE(公用表表达式)
文章目录 新特性:公用表表达式(cte)普通公用表表达式递归公用表表达式小 结 新特性:公用表表达式(cte) 公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集&am…...

MySQL的备份恢复
数据备份的重要性 1.生产环境中,数据的安全至关重要 任何数据的丢失都会导致非常严重的后果。 2.数据为什么会丢失 :程序操作,运算错误,磁盘故障,不可预期的事件(地震,海啸)&#x…...
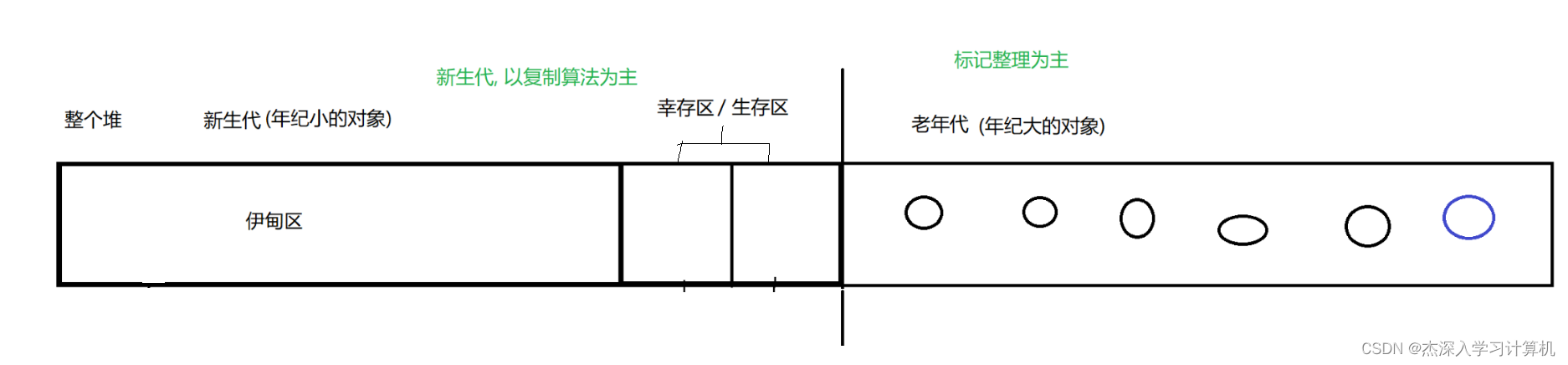
【JavaEE】JVM 剖析
JVM 1. JVM 的内存划分2. JVM 类加载机制2.1 类加载的大致流程2.2 双亲委派模型2.3 类加载的时机 3. 垃圾回收机制3.1 为什么会存在垃圾回收机制?3.2 垃圾回收, 到底实在做什么?3.3 垃圾回收的两步骤第一步: 判断对象是否是"垃圾"第二步: 如何回收垃圾 1. JVM 的内…...
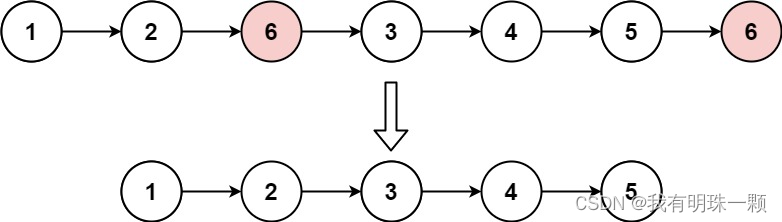
算法题:203. 移除链表元素(递归法、设置虚拟头节点法等3种方法)Java实现创建链表与解析链表
1、算法思路 讲一下设置虚拟头节点的那个方法,设置一个新节点指向原来链表的头节点,这样我们就可以通过判断链表的当前节点的后继节点值是不是目标删除值,来判断是否删除这个后继节点了。如果不设置虚拟头节点,则需要将头节点和后…...

ubuntu18.04 多版本opencv配置记录
多版本OpenCV过程记录 环境 ubuntu18.04 python2.7 python3.6 python3.9 opencv 3.2 OpenCV 4.4.0安装 Ubuntu18.04 安装 Opencv4.4.0 及 Contrib (亲测有效) 暂时不清楚Contrib的作用,所以没安装,只安装最基础的 下载opencv4.4.0并解压 opencv下载…...

Spring Security—OAuth 2.0 资源服务器的多租户
一、同时支持JWT和Opaque Token 在某些情况下,你可能需要访问两种令牌。例如,你可能支持一个以上的租户,其中一个租户发出JWT,另一个发出 opaque token。 如果这个决定必须在请求时做出,那么你可以使用 Authenticati…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...