NLP之Bert多分类实现案例(数据获取与处理)
文章目录
- 1. 代码解读
- 1.1 代码展示
- 1.2 流程介绍
- 1.3 debug的方式逐行介绍
- 3. 知识点
1. 代码解读
1.1 代码展示
import json
import numpy as np
from tqdm import tqdmbert_model = "bert-base-chinese"from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(bert_model)
# spo中所有p的关系标签 (text --> p label)
p_entitys = ['丈夫', '上映时间', '主持人', '主演', '主角', '作曲', '作者', '作词', '出品公司', '出生地', '出生日期', '创始人', '制片人', '号', '嘉宾', '国籍','妻子', '字', '导演', '所属专辑', '改编自', '朝代', '歌手', '母亲', '毕业院校', '民族', '父亲', '祖籍', '编剧', '董事长', '身高', '连载网站']max_length = 300
train_list = []
label_list = []
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:data = json.load(f)for line in tqdm(data):text = tokenizer.encode(line['text'])token = text[:max_length] + [0] * (max_length - len(text))train_list.append(token)# 获取当前文本的标准答案 (spo中的p)new_spo_list = line['new_spo_list']label = [0.] * len(p_entitys) # 确定label的标签长度for spo in new_spo_list:p_entity = spo['p']['entity']label[p_entitys.index(p_entity)] = 1.0 label_list.append(label)
train_list = np.array(train_list)
label_list = np.array(label_list)
val_train_list = []
val_label_list = []
# 加载和预处理验证集
with open('../data/valid_data.json', 'r', encoding="UTF-8") as f:data = json.load(f)for line in tqdm(data):text = line["text"]new_spo_list = line["new_spo_list"]label = [0.] * len(p_entitys)for spo in new_spo_list:p_entity = spo["p"]["entity"]label[p_entitys.index(p_entity)] = 1. token = tokenizer.encode(text)token = token[:max_length] + [0] * (max_length - len(token))val_train_list.append((token))val_label_list.append(label)
val_train_list = np.array(val_train_list)
val_label_list = np.array(val_label_list)
1.2 流程介绍
这段代码的整体流程和目的是为了对中文文本进行自然语言处理任务的准备工作,这里似乎是为了一个文本分类或关系提取任务。具体步骤如下:
-
导入必要的库:
json:用于处理JSON数据格式。numpy:科学计算库,用于高效地处理数组操作。tqdm:用于在循环操作中显示进度条。
-
指定BERT模型的类型(
bert-base-chinese),用于中文文本。 -
使用
transformers库中的AutoTokenizer来加载指定BERT模型的分词器。 -
定义一组中文实体关系标签(
p_entitys),这些看起来是用于文本中特定实体之间关系的标签。 -
设置一个最大序列长度(
max_length)为300,以限制处理文本的长度。 -
初始化两个空列表
train_list和label_list,用于存储训练数据的特征和标签。 -
加载并处理训练数据(
train_data.json):- 使用
json.load()读取文件内容。 - 使用
tokenizer.encode()将每行文本转换为BERT词汇表中的token IDs。 - 如果文本长度短于
max_length,则用0填充。 - 解析每个文本的
new_spo_list以构建标签向量,其中如果关系存在于文本中,则相应位置为1,否则为0。
- 使用
-
将
train_list和label_list转换为NumPy数组,以便进一步处理。 -
对验证集进行与训练集相同的处理,并存储在
val_train_list和val_label_list。
代码的目的是将中文文本及其对应的实体关系标签转换为机器学习模型可以接受的数值格式。这个过程通常是自然语言处理任务中文本预处理的一部分,特别是在使用BERT这类预训练语言模型的情况下。
你需要完成的工作可能包括:
- 确保你有正确配置的环境和库来运行这段代码。
- 如果这是第一次运行,确保你下载了
bert-base-chinese模型和分词器。 - 准备
train_data.json和valid_data.json数据文件。 - 运行代码并监视进度条以确保数据正在被正确处理。
1.3 debug的方式逐行介绍
下面逐行解释代码的功能:
import json
import numpy as np
from tqdm import tqdm
这三行代码是导入模块,json用于处理JSON格式的数据,numpy是一个广泛使用的科学计算库,tqdm是一个用于显示循环进度的库,可以在长循环中给用户反馈。
bert_model = "bert-base-chinese"
这行代码定义了变量bert_model,将其设置为"bert-base-chinese",指的是BERT模型的中文预训练版本。
from transformers import AutoTokenizer
从transformers库导入AutoTokenizer,这是Hugging Face提供的一个用于自动获取和加载预训练分词器的类。
tokenizer = AutoTokenizer.from_pretrained(bert_model)
使用from_pretrained方法创建了一个tokenizer对象,这个分词器将根据bert_model变量指定的模型进行加载。
p_entitys = [...]
这里列出了所有可能的关系标签,用于将文本中的关系映射为一个固定长度的标签向量。
max_length = 300
定义了一个变量max_length,设置为300,用于后面文本序列的最大长度。
train_list = []
label_list = []
初始化两个列表train_list和label_list,分别用于存储处理后的文本数据和对应的标签数据。
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:
打开训练数据文件train_data.json,以只读模式('r')和UTF-8编码。
data = json.load(f)
加载整个JSON文件内容到变量data。
for line in tqdm(data):
对data中的每一项进行迭代,tqdm将为这个循环显示一个进度条。
text = tokenizer.encode(line['text'])
使用分词器将文本编码为BERT的输入ID。
token = text[:max_length] + [0] * (max_length - len(text))
这行代码截取或填充编码后的文本至max_length长度。
train_list.append(token)
将处理后的文本添加到train_list列表中。
new_spo_list = line['new_spo_list']
提取当前条目的关系列表。
label = [0.] * len(p_entitys)
创建一个与关系标签数量相同长度的零向量。
for spo in new_spo_list:
遍历当前条目的每一个关系。
p_entity = spo['p']['entity']
从关系中提取实体。
label[p_entitys.index(p_entity)] = 1.0
在标签向量中,将对应实体的索引位置设为1.0,表示该关系在文本中出现。
label_list.append(label)
将构建好的标签向量添加到label_list。
train_list = np.array(train_list)
label_list = np.array(label_list)
将列表转换为NumPy数组,便于后续处理。
接下来的代码块与之前的相似,只是针对验证数据集valid_data.json进行操作。
val_train_list = []
val_label_list = []
初始化用于验证集的两个列表。
with open('../data/valid_data.json', 'r', encoding="UTF-8") as f:
打开验证数据文件。
接下来的代码块与处理训练数据时相同,也是加载数据、对文本进行编码、生成标签向量、然后将它们添加到相应的验证集列表中。
val_train_list = np.array(val_train_list)
val_label_list = np.array(val_label_list)
最后,同样地,将验证集的列表转换为NumPy数组。
这段代码整体上是用来处理和准备数据,使其适合输入到一个神经网络模型中去。它不仅编码文本,还构造了与之相对应的标签,这在训练和验证机器学习模型时是必需的。
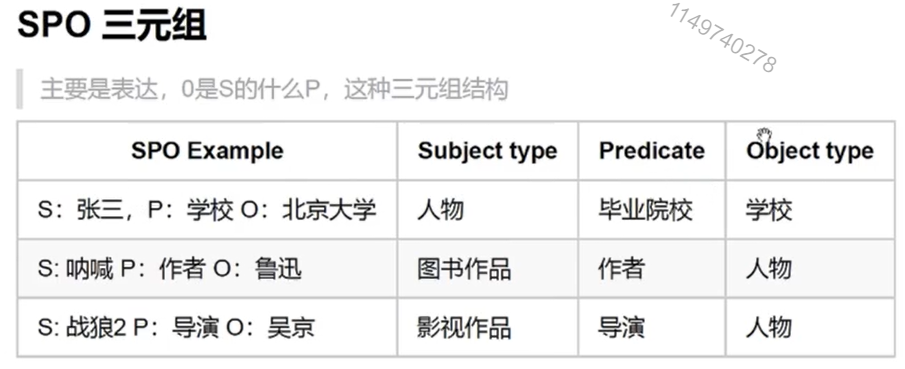
3. 知识点

三元组解释了两个实体或者实体和属性之间的关系。
O是S的什么P,例如鲁迅是《呐喊》的导演;吴京是《战狼》的导演。
相关文章:
NLP之Bert多分类实现案例(数据获取与处理)
文章目录 1. 代码解读1.1 代码展示1.2 流程介绍1.3 debug的方式逐行介绍 3. 知识点 1. 代码解读 1.1 代码展示 import json import numpy as np from tqdm import tqdmbert_model "bert-base-chinese"from transformers import AutoTokenizertokenizer AutoToken…...
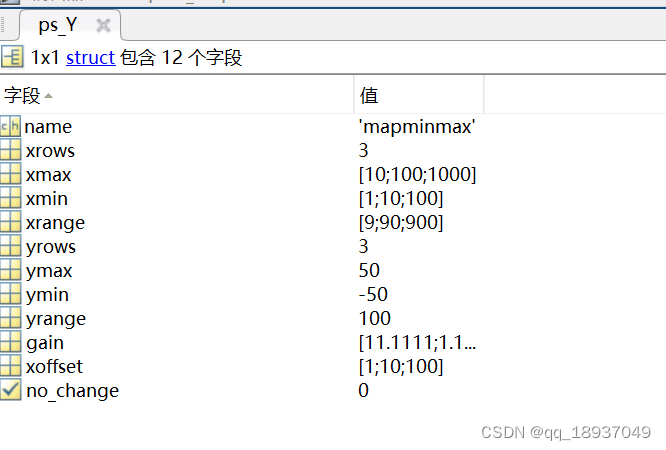
matlab中的mapminmax函数初步理解和应用
matlab中的mapminmax函数初步认识 一、mapminmax 顾名思义:映射最大最小 二、语法及举例 2.1 语法1 [Y,PS] mapminmax(X) 将矩阵X映射形成矩阵Y, Y中每行中的最小值对应-1,最大值对应1。PS是一个包含映射信息的结构体。 举例: clc cle…...

svc和ingress的关系
在Kubernetes中,SVC有三种类型,分别是ClusterIP、NodePort和LoadBalancer。而Ingress则是一种服务类型的扩展,它主要用于处理HTTP和HTTPS流量,并提供了对集群内部服务的路由和负载均衡功能。 下面简要介绍SVC的三种类型和Ingress…...

可以使用以下代码对数据库查询结果进行分组统计
public static void GroupAndStatistic(string connectionString, string query) {// 创建一个SQLSugar实例var db new SQLSugarClient(connectionString);// 使用QueryHelper类执行查询var dataTable db.Query<DataRow>().From(query).ExecuteDataTable();// 使用LINQ…...
win10提示mfc100u.dll丢失的解决方法,快速解决dll问题
在计算机使用过程中,我们经常会遇到一些错误提示,其中之一就是“mfc100u.dll丢失”。那么,mfc100u.dll是什么?mfc100u.dll是Microsoft Visual C Redistributable文件之一,它包含了用于MFC (Microsoft Foundation Class…...
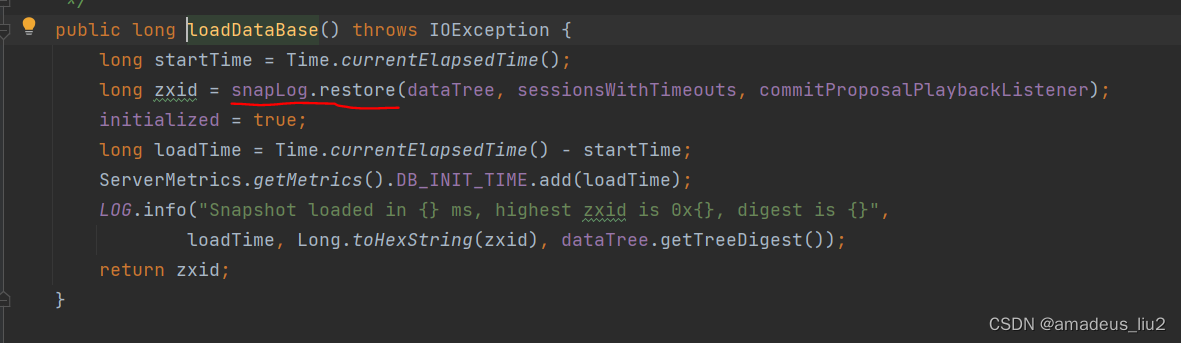
zookeeper:启动原理
主类: QuorumPeerMain, 其中调用了main对象的initializeAndRun方法, 首先定义了QuorumPeerConfig对象,然后调用了parse方法,parse方法代码如下: 其中调用的parseProperties方法的代码如下: 可以看到&am…...

kafka问题汇总
报错1: 解决方式 1、停止docker服务 输入如下命令停止docker服务 systemctl stop docker 或者service docker stop1 停止成功的话,再输入docker ps 就会提示出下边的话: Cannot connect to the Docker daemon. Is the docker daem…...
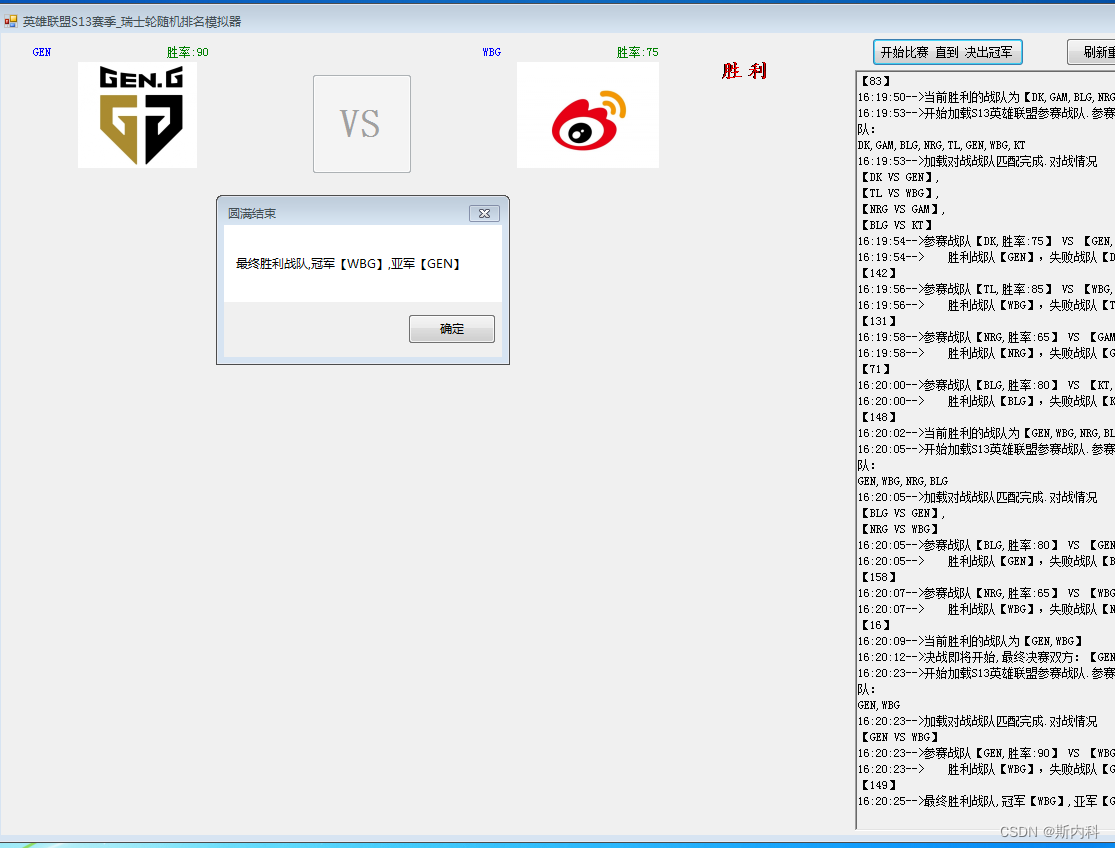
C#使用随机数模拟英雄联盟S13瑞士轮比赛
瑞士轮赛制的由来 瑞士制:又称积分循环制,最早出现于1895年在瑞士苏黎世举办的国际象棋比赛中,故而得名。其基本原则是避免种子选手一开始就交锋、拼掉,是比较科学合理、用得最多的一种赛制;英语名称为Swiss System。…...
利用限流实现不公平分发)
RabbitMQ(高级特性)利用限流实现不公平分发
在RabbitMQ中,多个消费者监听同一条队列,则队列默认采用的轮询分发。但是在某种场景下这种策略并不是很好,例如消费者1处理任务的速度非常快,而其他消费者处理速度却很慢。此时如果采用公平分发,则消费者1有很大一部分…...

3 网络协议入门
从淘宝买东西举例来说明一次请求中的,网络有关的部分是打开浏览器,输入购物网站的地址: https://www.taobao.com/那么浏览器是怎么打开购物网站的首页的呢? (1)首先受到了一段http报文 HTTP/1.1 200 OK Date: Tue, 27 Mar 2018 …...
)
【星海出品】VUE(五)
表单 表单输入绑定 只需要v-model声明一下这个变量就可以。 还可以选择不同的类型,例如 type"checkbox“ v-model 也提供了 lazy、number、.trim 功能,只需要在v-model后面加入.lazy 例如:v-model.lazy”message“ <template><…...
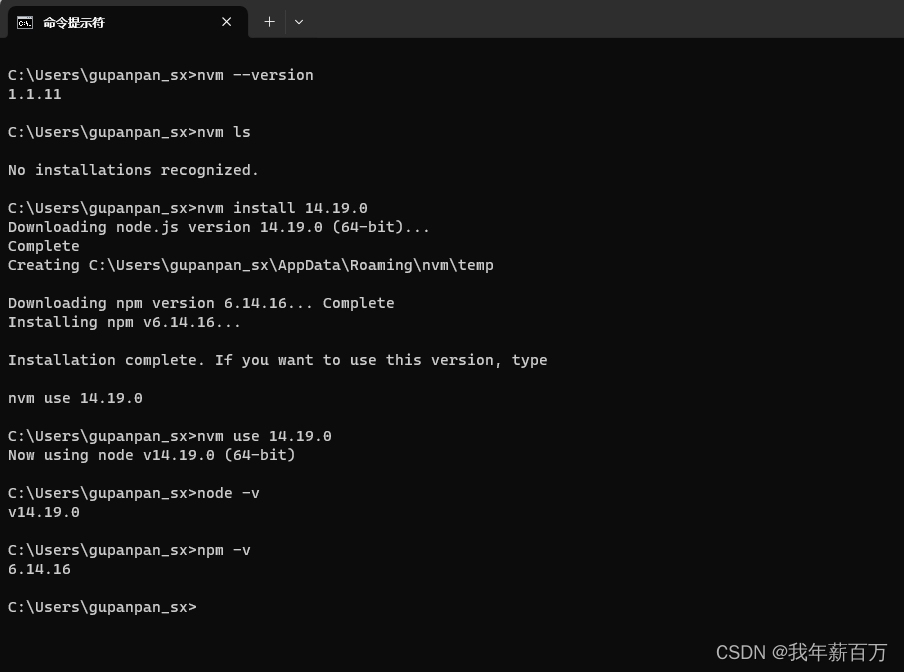
项目实战之安装依赖npm install
文章目录 nvmdeasync包和node-gyp报错deasync包node-gyp报错 前言:有些人看着还活着其实已经凉了好一会儿了。 初拿到项目 初拿到项目肯定是先看配置 package.json的啦,看看都需要安装什么依赖,然后 npm install,OK结束 皆大欢喜。 ————…...

Java之图书管理系统
🤷♀️🤷♀️🤷♀️ 今天给大家分享一下Java实现一个简易的图书管理系统! 清风的个人主页🎉✏️✏️ 🌂c/java领域新星创作者 🎉欢迎👍点赞✍评论❤️收藏 😛&…...

用「埋点」记录自己,不妄过一生
最近有朋友问我「埋点怎么做」,给朋友讲了一些互联网广告的案例,从源头的数据采集讲到末尾的应用分析和流量分配等(此处省略N多字) 解释完以后,我想到一个问题:有了埋点可以做分析,那我们对自己…...

运维知识点-Docker从小白到入土
Docker从小白到入土 安装问题-有podmanCentos8使用yum install docker -y时,默认安装的是podman-docker软件 安装docker启动dockeryum list installed | grep dockeryum -y remove xxxx安装Docker安装配置下载安装docker启动docker,并设置开机启动下载所…...
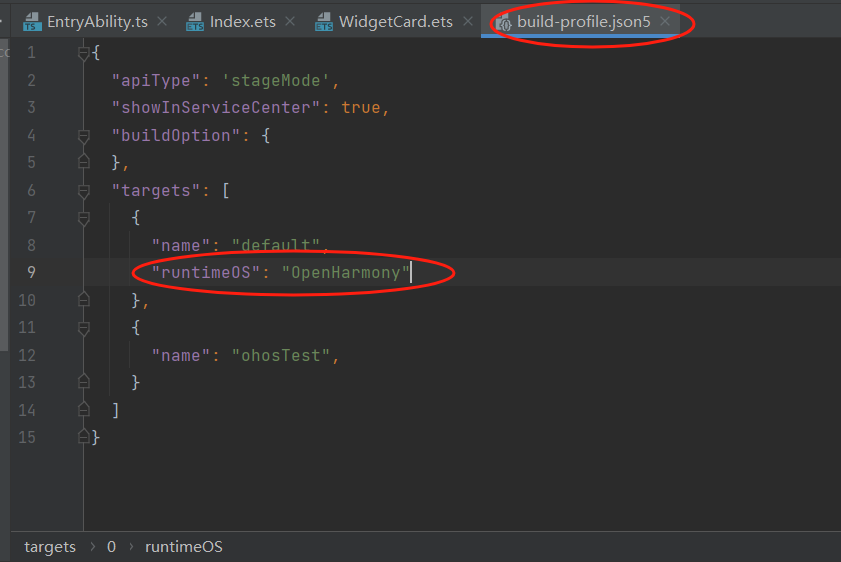
基于DevEco Studio的OpenHarmony应用原子化服务(元服务)入门教程
一、创建项目 二、创建卡片 三、应用服务代码 Index.ets Entry Component struct Index {State TITLE: string OpenHarmony;State CONTEXT: string 创新召见未来!;build() {Row() {Column() {Text(this.TITLE).fontSize(30).fontColor(0xFEFEFE).fontWeight(…...
,一个SQL语句是如何执行的呢?)
MySQL和Java程序建立连接的底层原理(JDBC),一个SQL语句是如何执行的呢?
Java程序方面 1. JDBC驱动程序:JDBC驱动程序是连接MySQL数据库的核心组件。它是一组Java类,用于实现与MySQL数据库的通信协议和数据传输。驱动程序负责将Java程序发送的请求转化为MySQL数据库能够理解的格式,并将数据库返回的结果转化为Java…...
uniapp踩坑之项目:uniapp数字键盘组件—APP端
//在components文件夹创建digitKeyboard文件夹,再创建digitKeyboard.vue <!-- 数字键盘 --> <template><view class"digit-keyboard"><view class"digit-keyboard_bg" tap"hide"></view><view clas…...

聊一聊GPT——让我们的写作和翻译更高效
1 介绍 GPT(Generative Pre-trained Transformer)是一种基于Transformer的语言生成模型,由OpenAI开发。它采用了无监督的预训练方式,通过处理大量的文本数据进行自我学习,从而提高其语言生成的能力。 GPT在自然语言…...

413 (Payload Too Large) 2023最新版解决方法
文章目录 出现问题解决方法 出现问题 博主在用vue脚手架开发的时候,在上传文件的接口中碰到 这样一个错误,查遍所有csdn,都没有找到解决方法,通过一些方式,终于解决了。 解决方法 1.打开Vue项目的根目录。 2.在根目…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...