【大模型应用开发教程】04_大模型开发整体流程 基于个人知识库的问答助手 项目流程架构解析
大模型开发整体流程 & 基于个人知识库的问答助手 项目流程架构解析
- 一、大模型开发整体流程
- 1. 何为大模型开发
- 定义
- 核心点
- 核心能力
- 2. 大模型开发的整体流程
- 1. 设计
- 2. 架构搭建
- 3. Prompt Engineering
- 4. 验证迭代
- 5. 前后端搭建
- 二、项目流程简析
- 步骤一:项目规划与需求分析
- 1.项目目标
- 2.核心功能
- 3.确定技术架构和工具
- 步骤二:数据准备与向量知识库构建
- 1. 收集和整理用户提供的文档。
- 2. 将文档词向量化
- 3. 将向量化后的文档导入Chroma知识库,建立知识库索引。
- 步骤三:大模型集成与API连接
- 步骤四:核心功能实现
- 步骤五:核心功能迭代优化
- 步骤六:前端与用户交互界面开发
- 步骤七:部署测试与上线
- 步骤八:维护与持续改进
- 三、项目架构简析
- 1. 整体架构
- 2. 代码结构
- 3. 项目逻辑
- 4. 各层简析
- 4.1 LLM 层
- 4.2 数据层
- 4.3 数据库层
- 4.4 应用层
- 4.5 服务层
项目仓库地址
项目学习地址
一、大模型开发整体流程
1. 何为大模型开发
定义
将开发以LLM为功能核心,通过LLM的强大理解能力和生成能力,结合特殊的数据或业务逻辑来提供独特功能的应用。
核心点
- 通过调用 API 或开源模型来实现核心的理解与生成
- 通过 Prompt Enginnering 来实现大语言模型的控制
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具。通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。这因此,作为大模型开发的初学者,我们并不需要深研大模型内部原理,而更需要掌握使用大模型的实践技巧。
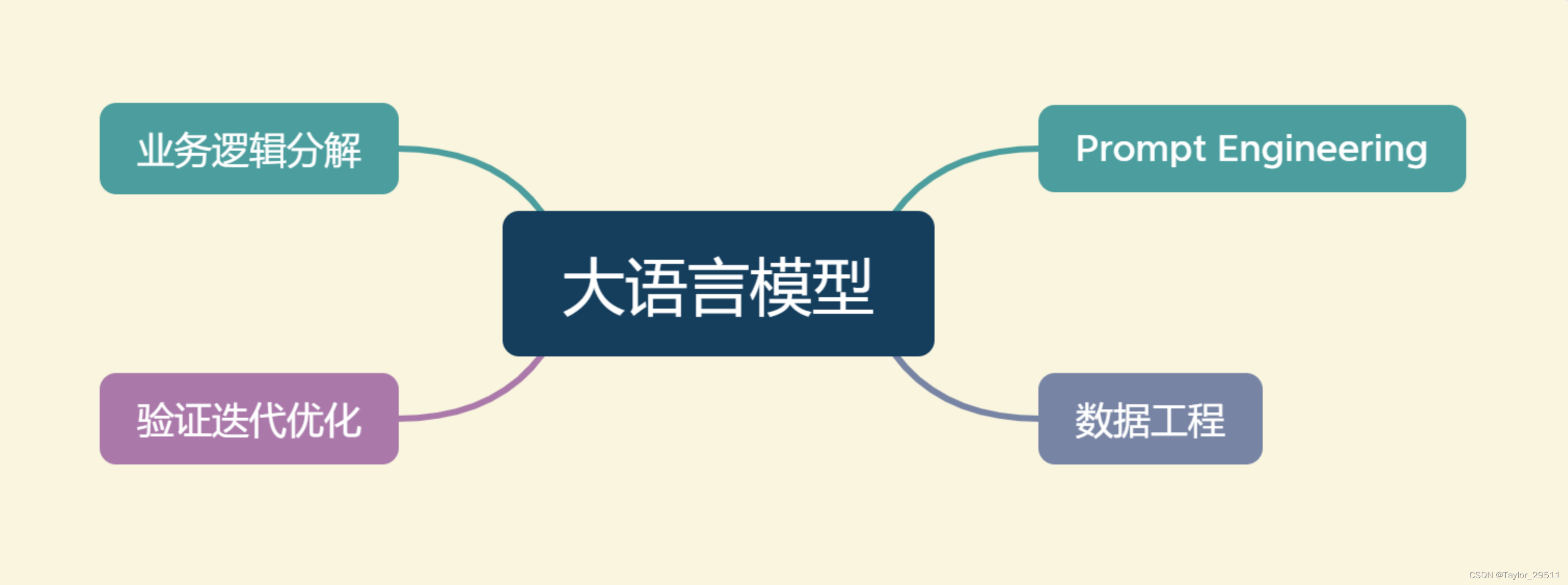
核心能力
指令理解与文本生成,提供了复杂业务逻辑的简单平替方案。
| 传统 AI | 大模型开发 | ||
|---|---|---|---|
| 开发 | 将复杂业务逻辑拆解,对于每一个子业务构造训练数据与验证数据,训练优化模型,形成完整的模型链路来解决整个业务逻辑。 | 用 Prompt Engineering 来替代子模型的训练调优。通过 Prompt 链路组合来实现业务逻辑,用一个通用大模型 + 若干业务 Prompt 来解决任务 | |
| 评估思路 | 训练集上训练、测试集调优、验证集验证 | 初始化验证集Prompt、收集BadCase、迭代优化Prompt |
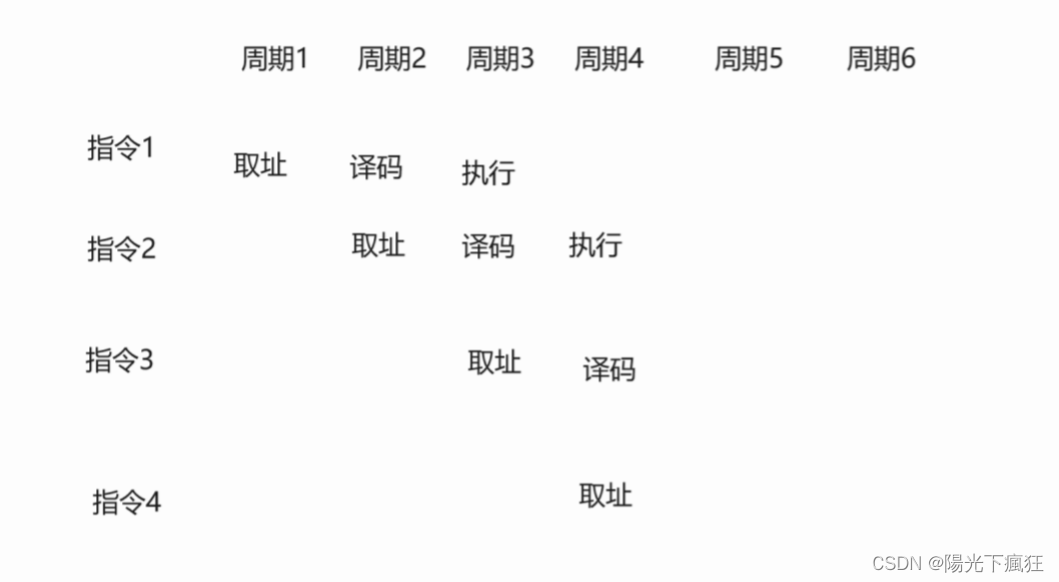
2. 大模型开发的整体流程
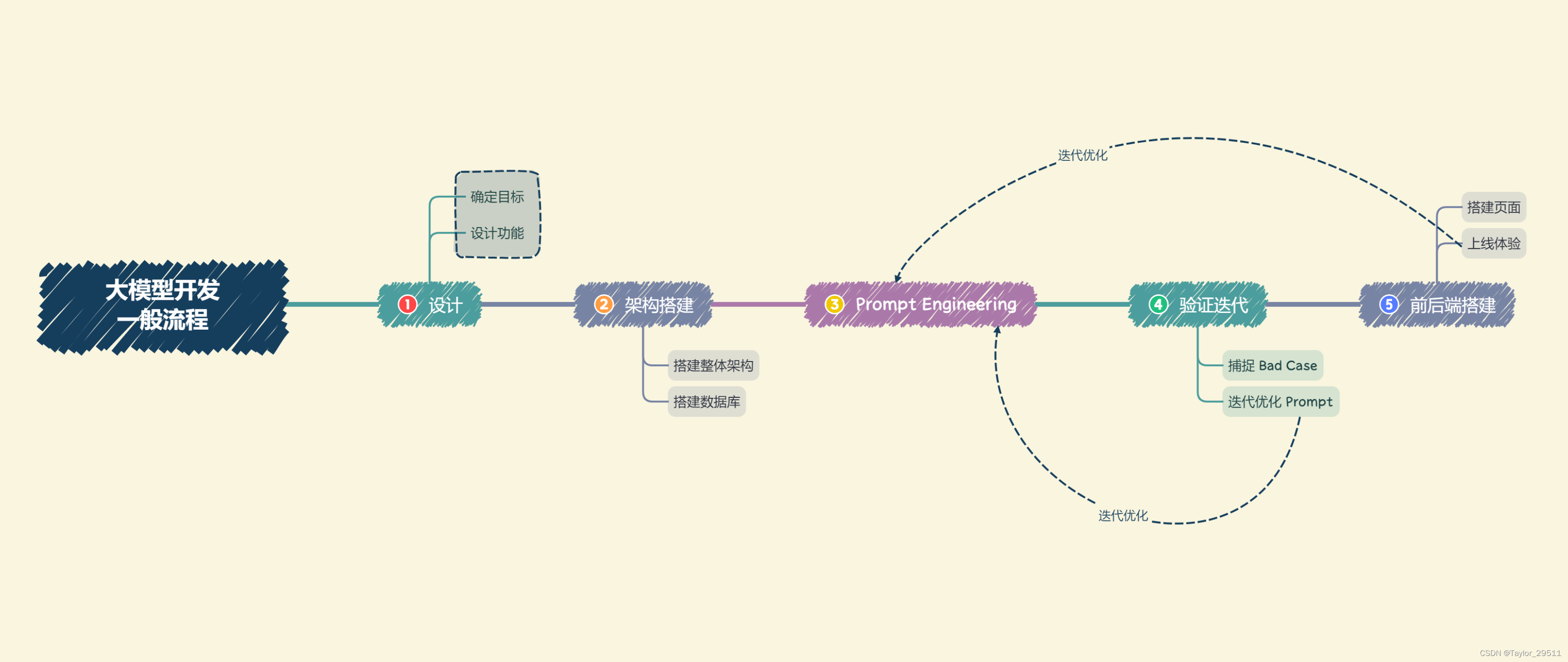
1. 设计
-
确定目标:在进行开发前,我们首先需要确定开发的目标,即要开发的应用的应用场景、目标人群、核心价值。对于个体开发者或小型开发团队而言,一般应先设定最小化目标,从构建一个 mvp(最小可行性产品)开始,逐步进行完善和优化。
-
设计功能:在确定开发目标后,需要设计本应用所要提供的功能,以及每一个功能的大体实现逻辑。虽然我们通过使用大模型来简化了业务逻辑的拆解,但是越清晰、深入的业务逻辑理解往往也能带来更好的 Prompt 效果。同样,对于个体开发者或小型开发团队来说,首先要确定应用的核心功能,然后延展设计核心功能的上下游功能;例如,我们想打造一款个人知识库助手,那么核心功能就是结合个人知识库内容进行问题的回答,那么其上游功能的用户上传知识库、下游功能的用户手动纠正模型回答就是我们也必须要设计实现的子功能。
2. 架构搭建
-
搭建整体架构:目前,绝大部分大模型应用都是采用的特定数据库+ Prompt + 通用大模型的架构。我们需要针对我们所设计的功能,搭建项目的整体架构,实现从用户输入到应用输出的全流程贯通。一般来说,我们推荐基于 LangChain 框架进行开发。LangChain 提供了 Chain、Tool 等架构的实现,我们可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
-
搭建数据库:个性化大模型应用需要有个性化数据库进行支撑。由于大模型应用需要进行向量语义检索,一般使用诸如 chroma 的向量数据库。在该步骤中,我们需要收集数据并进行预处理,再向量化存储到数据库中。数据预处理一般包括从多种格式向纯文本的转化,例如 pdf、markdown、html、音视频等,以及对错误数据、异常数据、脏数据进行清洗。完成预处理后,需要进行切片、向量化构建出个性化数据库。
3. Prompt Engineering
- Prompt Engineering:优质的 Prompt 对大模型能力具有极大影响,我们需要逐步迭代构建优质的 Prompt Engineering 来提升应用性能。在该步中,我们首先应该明确 Prompt 设计的一般原则及技巧,构建出一个来源于实际业务的小型验证集,基于小型验证集设计满足基本要求、具备基本能力的 Prompt。
4. 验证迭代
-
验证迭代:验证迭代在大模型开发中是极其重要的一步,一般指通过不断发现 Bad Case 并针对性改进 Prompt Engineering 来提升系统效果、应对边界情况。在完成上一步的初始化 Prompt 设计后,我们应该进行实际业务测试,探讨边界情况,找到 Bad Case,并针对性分析 Prompt 存在的问题,从而不断迭代优化,直到达到一个较为稳定、可以基本实现目标的 Prompt 版本。
-
体验优化:在完成前后端搭建之后,应用就可以上线体验了。接下来就需要进行长期的用户体验跟踪,记录 Bad Case 与用户负反馈,再针对性进行优化即可。
5. 前后端搭建
- 前后端搭建:完成 Prompt Engineering 及其迭代优化之后,我们就完成了应用的核心功能,可以充分发挥大语言模型的强大能力。接下来我们需要搭建前后端,设计产品页面,让我们的应用能够上线成为产品。前后端开发是非常经典且成熟的领域,此处就不再赘述,我们将主要介绍两种快速开发 Demo 的框架:Gradio 和 Streamlit,可以帮助个体开发者迅速搭建可视化页面实现 Demo 上线。
二、项目流程简析
以下我们将结合本实践项目与上文的整体流程介绍,简要分析本项目开发流程如下:
步骤一:项目规划与需求分析
1.项目目标
基于个人知识库的问答助手
2.核心功能
- 上传文档、创建知识库;
- 选择知识库,检索用户提问的知识片段;
- 提供知识片段与提问,获取大模型回答;
- 流式回复;
- 历史对话记录
3.确定技术架构和工具
- LangChain框架
- Chroma知识库
- 大模型使用 GPT、Claude、科大讯飞的星火大模型、文心一言、Chat-GLM2等
- 前后端使用 Gradio 和 Streamlit。
步骤二:数据准备与向量知识库构建
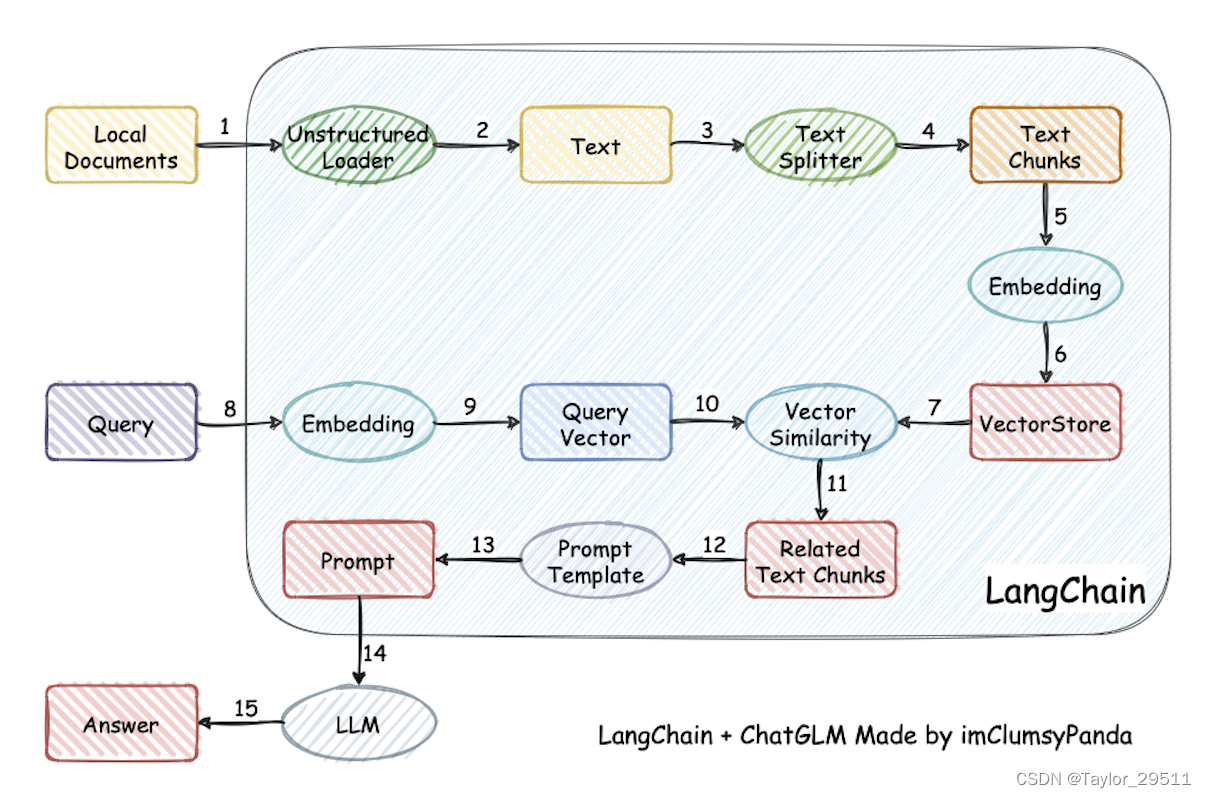
本项目实现原理如下图所示(图片来源),过程包括:
- 加载本地文档
- 读取文本
- 文本分割
- 文本向量化
- Query 向量化
- 向量匹配,最相似的 top k个
- 匹配出的文本作为上下文和问题一起添加到 prompt中
- 提交给 LLM做生成回答
1. 收集和整理用户提供的文档。
用户常用文档格式有 pdf、txt、doc 等,首先使用工具读取文本,通常使用 langchain 的文档加载器模块可以方便的将用户提供的文档加载进来,也可以使用一些 python 比较成熟的包进行读取。
由于目前大模型使用 token 限制,我们需要对读取的文本进行切分,将较长的文本切分为较小的文本,这时一段文本就是一个单位的知识。
2. 将文档词向量化
使用文本嵌入(Embeddings)对分割后的文档进行向量化,使语义相似的文本片段具有接近的向量表示。然后,存入向量数据库,这个流程正是创建索引(index)的过程。
向量数据库对各文档片段进行索引,支持快速检索。这样,当用户提出问题时,可以先将问题转换为向量,在数据库中快速找到语义最相关的文档片段。然后将这些文档片段与问题一起传递给语言模型,生成回答。
3. 将向量化后的文档导入Chroma知识库,建立知识库索引。
Langchain集成了超过30个不同的向量存储库。我们选择 Chroma 向量库是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 prompt 提交给 LLM 回答。
步骤三:大模型集成与API连接
- 集成GPT、Claude、星火、文心、GLM等大模型,配置API连接。
- 编写代码,实现与大模型API的交互,以便获取问题答案。
步骤四:核心功能实现
- 构建 Prompt Engineering,实现大模型回答功能,根据用户提问和知识库内容生成回答。
- 实现流式回复,允许用户进行多轮对话。
- 添加历史对话记录功能,保存用户与助手的交互历史。
步骤五:核心功能迭代优化
- 进行验证评估,收集 Bad Case。
- 根据 Bad Case 迭代优化核心功能实现。
步骤六:前端与用户交互界面开发
- 使用 Gradio 和 Streamlit 搭建前端界面。
- 实现用户上传文档、创建知识库的功能。
- 设计用户界面,包括问题输入、知识库选择、历史记录展示等。
步骤七:部署测试与上线
- 部署问答助手到服务器或云平台,确保可在互联网上访问。
- 进行生产环境测试,确保系统稳定。
- 上线并向用户发布。
步骤八:维护与持续改进
- 监测系统性能和用户反馈,及时处理问题。
- 定期更新知识库,添加新的文档和信息。
- 收集用户需求,进行系统改进和功能扩展。
整个流程将确保项目从规划、开发、测试到上线和维护都能够顺利进行,为用户提供高质量的基于个人知识库的问答助手。
三、项目架构简析
1. 整体架构
经过上文分析,本项目为搭建一个基于大模型的个人知识库助手,基于 LangChain 框架搭建,核心技术包括 LLM API 调用、向量数据库、检索问答链等。项目整体架构如下:
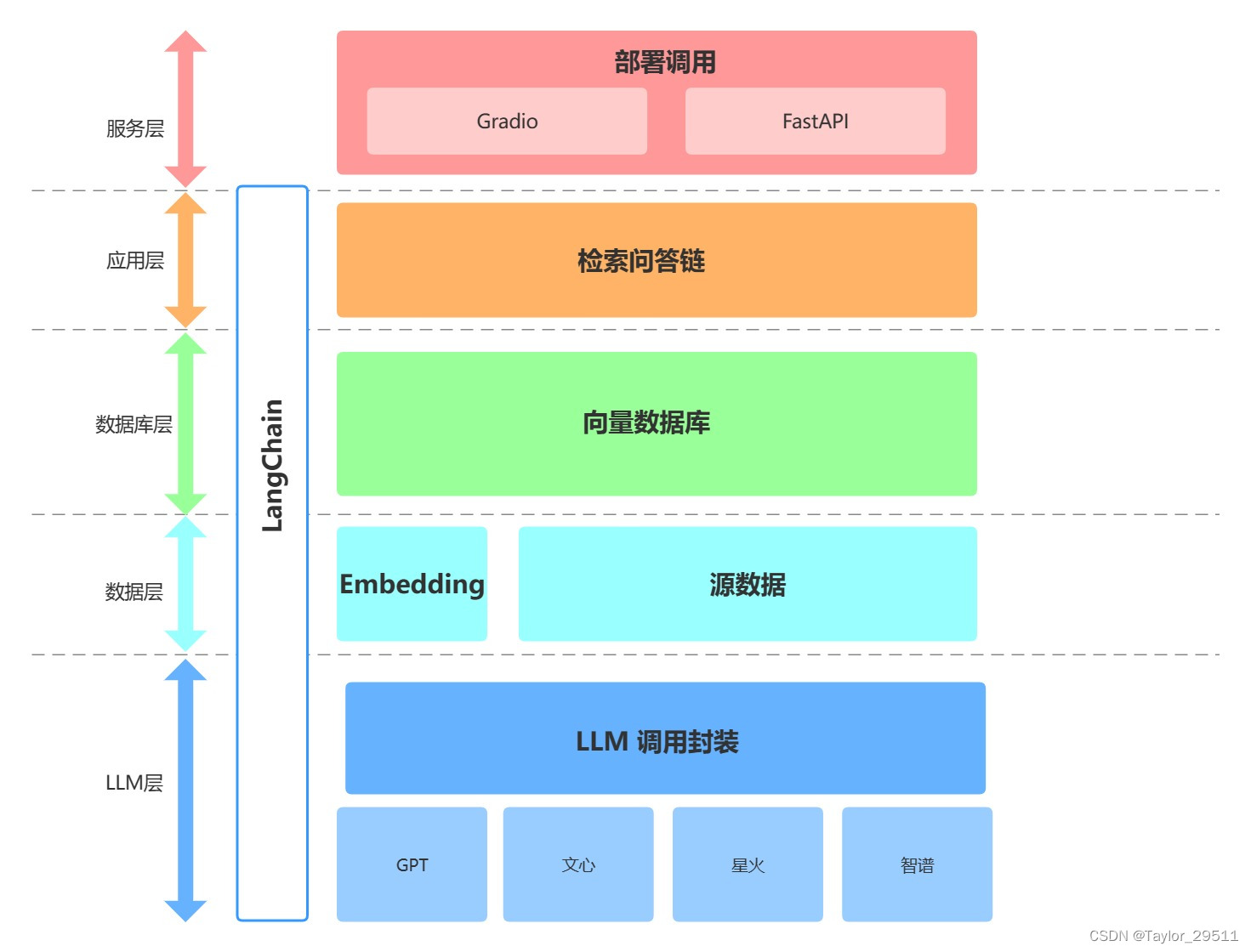
如上,本项目从底向上依次分为 LLM 层、数据层、数据库层、应用层与服务层。
- LLM 层:主要基于四种流行 LLM API 进行了 LLM 调用封装,支持用户以统一的入口、方式来访问不同的模型,支持随时进行模型的切换;
- 数据层:主要包括个人知识库的源数据以及 Embedding API,源数据经过 Embedding 处理可以被向量数据库使用;
- 数据库层:主要为基于个人知识库源数据搭建的向量数据库,在本项目中我们选择了 Chroma;
- 应用层:为核心功能的最顶层封装,我们基于 LangChain 提供的检索问答链基类进行了进一步封装,从而支持不同模型切换以及便捷实现基于数据库的检索问答;
- 服务层:分别实现了 Gradio 搭建 Demo 与 FastAPI 组建 API 两种方式来支持本项目的服务访问。
2. 代码结构
本项目的完整代码存放于 project 目录下,实现了项目的全部功能及封装,代码结构如下:
-project
-readme.md 项目说明
-llm LLM调用封装
-self_llm.py 自定义 LLM 基类
-wenxin_llm.py 自定义百度文心 LLM
-spark_llm.py 自定义讯飞星火 LLM
-zhipu_llm.py 自定义智谱 LLM
-call_llm.py 将各个 LLM 的原生接口封装在一起
-embedding embedding调用封装
-zhipu_embedding.py 自定义智谱embedding
-data 源数据路径
-database 数据库层封装
-create_db.py 处理源数据及初始化数据库封装
-chain 应用层封装
-qa_chain.py 封装检索问答链,返回一个检索问答链对象
-chat_qa_chian.py:封装对话检索链,返回一个对话检索链对象
-prompt_template.py 存放多个版本的 Template
-serve 服务层封装
-run_gradio.py 启动 Gradio 界面
-api.py 封装 FastAPI
-run_api.sh 启动 API
3. 项目逻辑
- 用户:可以通过
run_gradio或者run_api启动整个服务; - 服务层调用
qa_chain.py或chat_qa_chain实例化对话检索链对象,实现全部核心功能; - 服务层和应用层都可以调用、切换
prompt_template.py中的 prompt 模板来实现 prompt 的迭代; - 也可以直接调用
call_llm中的get_completion函数来实现不使用数据库的 LLM; - 应用层调用已存在的数据库和 llm 中的自定义 LLM 来构建检索链;
- 如果数据库不存在,应用层调用
create_db.py创建数据库,该脚本可以使用 openai embedding 也可以使用embedding.py中的自定义 embedding。
4. 各层简析
4.1 LLM 层
LLM 层主要功能为:将国内外四种知名 LLM API(OpenAI-ChatGPT、百度文心、讯飞星火、智谱GLM)进行封装,隐藏不同 API 的调用差异,实现在同一个对象或函数中通过不同的 model 参数来使用不同来源的 LLM。
在 LLM 层,我们首先构建了一个 Self_LLM 基类,基类定义了所有 API 的一些共同参数(如 API_Key,temperature 等);然后我们在该基类基础上继承实现了上述四种 LLM API 的自定义 LLM。同时,我们也将四种 LLM 的原生 API 封装在了统一的 get_completion 函数中。
在上一章,我们已详细介绍了每一种 LLM 的调用方式、封装方式,项目代码中的 LLM 层封装就是上一章讲解的代码实践。
4.2 数据层
数据层主要包括:个人知识库的源数据(包括 pdf、txt、md 等)和 Embedding 对象。源数据需要经过 Embedding 处理才能进入向量数据库,我们在数据层自定义了智谱提供的 Embedding API 的封装,支持上层以统一方式调用智谱 Embedding 或 OpenAI Embedding。
在上一章,我们也已详细介绍了 Embdding API 的调用及封装方式。
4.3 数据库层
数据库层主要:存放了向量数据库文件。同时,我们在该层实现了源数据处理、创建向量数据库的方法。
我们将在第四章详细介绍向量数据库、源数据处理方法以及构建向量数据库的具体实现。
4.4 应用层
应用层:封装了整个项目的全部核心功能。我们基于 LangChain 提供的检索问答链,在 LLM 层、数据库层的基础上,实现了本项目检索问答链的封装。自定义的检索问答链除具备基本的检索问答功能外,也支持通过 model 参数来灵活切换使用的 LLM。我们实现了两个检索问答链,分别是有历史记录的 Chat_QA_Chain 和没有历史记录的 QA_Chain。
我们将在第五章讲解 Prompt 的构造与检索问答链的构建细节。
4.5 服务层
服务层主要是:基于应用层的核心功能封装,实现了 Demo 的搭建或 API 的封装。在本项目中,我们分别实现了通过 Gradio 搭建前端界面与 FastAPI 进行封装,支持多样化的项目调用。
我们将在第六章详细介绍如何使用 Gradio 以及 FastAPI 来实现服务层的设计。
相关文章:
【大模型应用开发教程】04_大模型开发整体流程 基于个人知识库的问答助手 项目流程架构解析
大模型开发整体流程 & 基于个人知识库的问答助手 项目流程架构解析 一、大模型开发整体流程1. 何为大模型开发定义核心点核心能力 2. 大模型开发的整体流程1. 设计2. 架构搭建3. Prompt Engineering4. 验证迭代5. 前后端搭建 二、项目流程简析步骤一:项目规划与…...

【Unity ShaderGraph】| 快速制作一个 表面水纹叠加效果
前言 【Unity ShaderGraph】| 快速制作一个 表面水纹叠加效果一、效果展示二、表面水纹叠加效果三、应用实例 前言 本文将使用ShaderGraph制作一个表面水纹叠加效果,可以直接拿到项目中使用。对ShaderGraph还不了解的小伙伴可以参考这篇文章:【Unity Sh…...
大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法。 Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均…...
用友U8定制版在集简云:无需API即可集成客服系统和用户运营
无代码开发的新时代 在这个信息化、自动化的时代,无代码开发已经成为一种新的趋势。集简云就是这样的一款工具,可以轻松连接用友U8 定制版与近千款软件系统,无需开发、无需代码知识就可以打通各种软件之间的数据连接,构建自动化与…...
APP埋点:页面统计与事件统计
我们平时所说的埋点,可以大致分为两部分,一部分是统计APP页面访问情况,即页面统计;另外一部分是统计APP内的操作行为,及自定义事件统计。 一、页面统计 页面统计,可以统计应用内各个页面的访问次数&#x…...

Kotlin学习笔记-Kotlin基础-01
变量声明 var:用于值不改变的变量,使用val声明的变量无法重新赋值 val:用于值可以改变的变量 变量声明格式 var/val data(变量名称) : Int(变量类型) Kotlin基本数据类: Int、Byte、Short、Long、Float、Double Kotlin类型推…...
gma 1.x 气候气象指数计算源代码(分享)
本模块的主要内建子模块如下: 如何获得完整代码: 回复博主 或者 留言/私信 。 注意:本代码完全开源,可随意修改使用。 但如果您的成果使用或参考了本段代码,给予一定的引用说明(非强制)…...
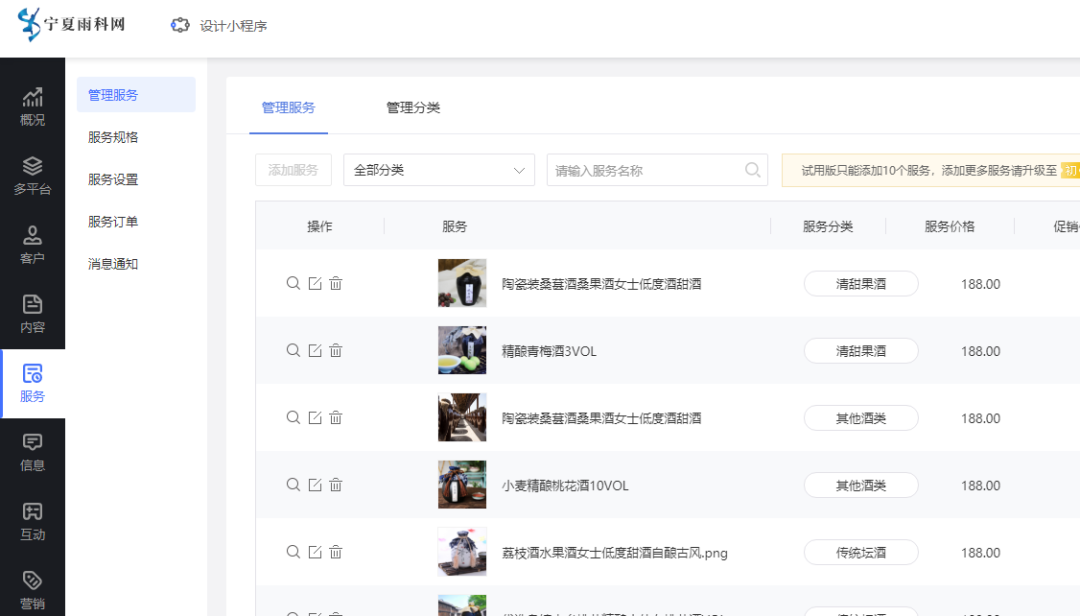
酒水展示预约小程序的效果如何
酒的需求度非常高,各种品牌、海量经销商组成了庞大市场,而在实际经营中,酒水品牌、经销商、门店经营者等环节往往也面临着品牌传播拓客引流难、产品展示预约订购难、营销难、销售渠道单一等痛点。 那么商家们应该怎样解决呢? 可以…...

蓝桥杯练习
即约分数 题目 思路 遍历所有的x,y,判断x/y是不是即越约分数。 代码 #include <iostream> using namespace std; int gcd(int x,int y) {int r;while(y!0){rx%y;xy;yr;}return x; } int main() {// 请在此输入您的代码int sum4039;//1/y和x/1都…...

python设计模式11:观察者模式
观察者模式 单个对此(发布者,也称为主体或是可观察对象)和一个或是多个对象(订阅者,也称为观察者)之间的发布-订阅关系。增加发布者和订阅这个之间解耦,使得在运行时添加、删除订阅者变得容易。…...

STM32 GPIO 描述
一、GPIO功能描述 每个GPIO端口有两个32位配置寄存器(GPIOx_CRL,GPIOx_CRH) ,两个32位数据寄存器 (GPIOx_IDR和GPIOx_ODR) ,一个32位置位/复位寄存器(GPIOx_BSRR),一个16位复位寄存器(GPIOx_BRR)和一个32位锁定寄存器(GPIOx_LCKR…...

lerna在项目中使用
1. 检查lerna.json文件中的版本号是否正确,确保版本号与安装的lerna版本一致; 2. 检查package.json文件中的依赖是否正确,确保依赖的版本号与安装的lerna版本一致; 3. 检查node_modules文件夹是否存在,如果存在&…...
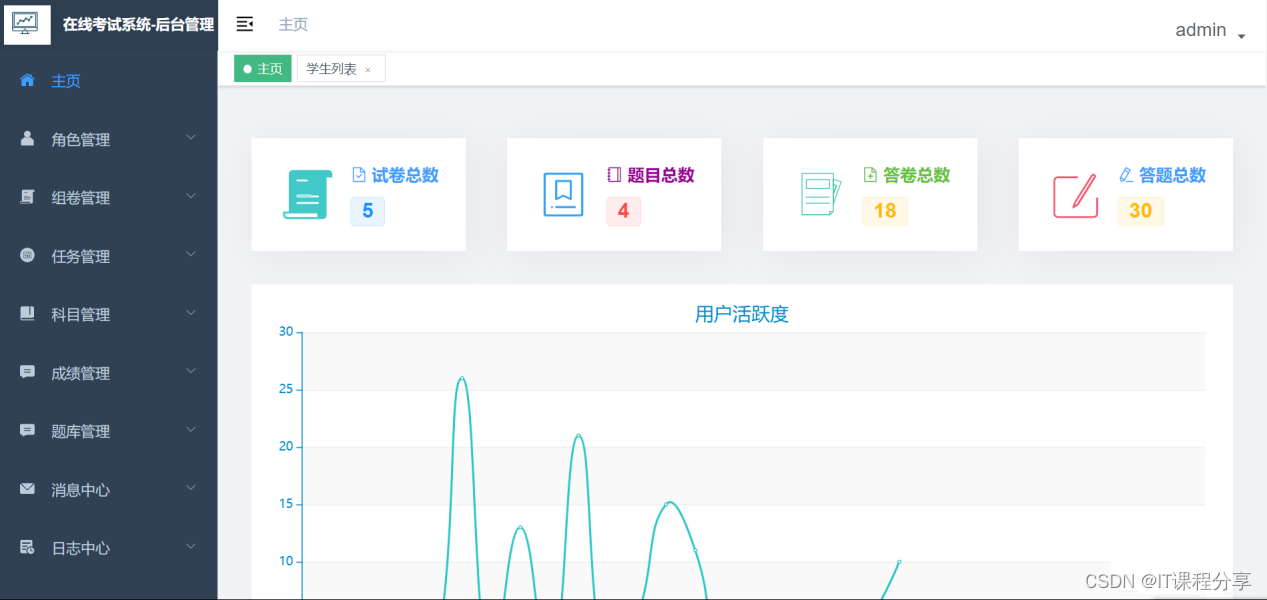
java智能在线考试系统源码 基于SpringBoot+Vue开发
java智能在线考试系统源码 基于SpringBootVue开发 环境介绍 语言环境:Java: jdk1.8 数据库:Mysql: mysql5.7 应用服务器:Tomcat: tomcat8.5.31 开发工具:IDEA或eclipse 开发技术:SpringbootVue 项目简介&…...
防逆流系统中防逆流电表的正确安装位置-安科瑞黄安南
随着光伏行业的发展,部分地区村级变压器及工业用电变压器容量与光伏项目的装机容量处于饱和。电网公司要求对后建的光伏并网系统为不可逆流发电系统,指光伏并网系统所发生的电由本地负载消耗,多余的电不允许通过低压配电变压器向上级电网逆向…...
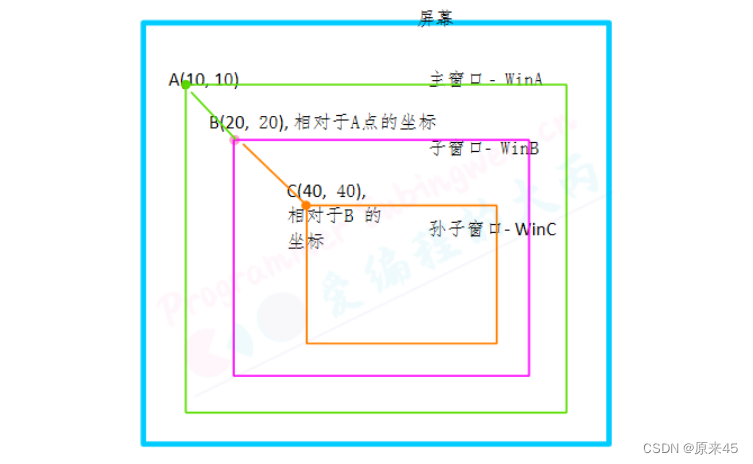
Hello Qt!
目录 1. 什么是Qt 2. Qt中的模块 3. 下载安装 4. QtCreator 4. Hello Qt 解释 .pro 解释 main.cpp 解释 mainwindow.ui 解释 mainwindow.h 解释 mainwindow.cpp 5. Qt 中的窗口类 5.1 基础窗口类 5.2 窗口的显示 6. Qt 的坐标体系 7. 内存回收 1. 什么是Qt 是一…...

pytorch加载的cifar10数据集,到底有没有经过归一化
pytorch加载cifar10的归一化 pytorch怎么加载cifar10数据集torchvision.datasets.CIFAR10transforms.Normalize()进行归一化到底在哪里起作用?【CIFAR10源码分析】 torchvision.datasets加载的数据集搭配Dataloader使用model.train()和model.eval() pytorch怎么加载…...
Day1 ARM基础
【ARM课程认知】 1.ARM课程的作用 承上启下 基础授课阶段:c语言、数据结构、linux嵌入式应用层课程:IO、进程线程、网络编程嵌入式底层课程:ARM体系结构、系统移植、linux设备驱动c/QT 2.ARM课程需要掌握的内容 自己能够实现简单的汇编编…...

ns3入门基础教程
ns3入门基础教程 文章目录 ns3入门基础教程ns环境配置测试ns3环境ns3简单案例 ns环境配置 官方网站:https://www.nsnam.org/releases/ 代码仓库:https://gitlab.com/nsnam/ns-3-dev 如果安装遇到问题,可以参考以下博文: https://…...

计算机视觉
目录 一、图像处理 main denoise 二、Harris角点检测 三、Hough变换直线检测 四、直方图显著性检测 五、人脸识别 六、kmeans import 函数 kmeanstext 七、神经网络 常用函数: imread----------读取图像 imshow---------显示图像 rgb2hsv---------RGB转…...

NSSCTF第10页(3)
[LitCTF 2023]彩蛋 第一题: LitCTF{First_t0_The_k3y! (1/?) 第三题: <?php // 第三个彩蛋!(看过头号玩家么?) // R3ady_Pl4yer_000ne (3/?) ?> 第六题: wow 你找到了第二个彩蛋哦~ _S0_ne3t? (2/?) 第七题…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...