LLM时代中的分布式AI
深度学习相较传统机器学习模型,对算力有更高的要求。尤其是随着深度学习的飞速发展,模型体量也不断增长。于是,前几年,我们看到了芯片行业的百家争鸣和性能指标的快速提升。正当大家觉得算力问题已经得到较大程度的缓解时,大语言模型(LLM, Large language model)的兴起又带来了前所未有的挑战。当网络模型达到一定量级后(比如参数量达到10B级别),表现出In-context learning,Instruction following和Step-by-step reasoning等涌现能力(Emergent abilities)。这些能力是以往模型所不具备的,因此LLM引起了学术界与工业界的浓厚兴趣以及广泛关注。但是,得到这些能力的代价是模型的急剧膨胀。比较知名的如GPT-2(1.5B),Megatron-LM(8.3B),T5(11B),Turing-NLG(17B),LLaMA(65B),GPT-3(175B),Jurassic-1(178B),Gopher(280B),PaLM(540B),Switch Transformer(1.6T),参数量很快从B时代到达了T时代。如今,在这些“庞然大物”面前,那些历史上曾经的“巨无霸”,像GPT(110M)、BERT(340M)看起来都显得有些迷你了。根据论文《Machine Learning Model Sizes and the Parameter Gap》中提到的,从1950到2018年,语言模型的模型大小增长7个数量级,但从2018年到2022年,4年就暴涨5个数量级。网络模型的陡然增大,随之而来的是一系列数据集、训练方法、计算框架相关的问题。关于这些年大模型发展的回顾以及对这些问题业界的探索的阐述可参考论文《A Survey of Large Language Models》。LLM所涉及的东西非常多,这篇文章主要讨论的限于对计算框架带来的挑战及如何用分布式的方法解决。
从网络模型结构方面,好消息是自从2017年Google在《Attention Is All You Need》中提出Transformer后,近几年模型的结构开始趋同于它。它不仅在于效果好,而且相比之前的如RNN结构更便于计算。Transformer网络中的主要负载是MHA和FF,而它们本质上都是或大部分都是GEMM。而GEMM的计算是相对成熟的。这就将前沿的AI与成熟的计算理论与实践结合起来了。另一方面Transformer是相同模块的重复堆叠,这也给并行计算(如pipelining)提供了便利。因此,近几年主要的LLM也都是基于Transformer。
那模型变大后对计算框架会带来什么样的影响呢?最直接的就是memory不够用了。由于传统CPU对神经网络这种调度并行的workload效率不高,因此目前主流的都是用GPU或者各种加速器。但是,这些芯片的memory比CPU的memory要小很多。
在模型的训练过程中,通常需要参数量数倍的memory。其中,消耗memory的大户一般有这么几个:
- Weight:模型的权重参数
- Activation:中间层的输入与输出
- Gradient & Optimizer state:梯度及优化器状态(如Adam中的momentum和variance)
其它还有些如temporary buffer或者fragmented memory等由于占得不多,因此优化时放的精力也少。推理的话optimizer state就不用了,但weight与activation是训练与推理时都逃不了的。前面提到模型的size在短短数年增长了几个数量级,但相比之下,GPU的memory增长大概只有几倍。这让本就不太够用的GPU memory显得更加捉襟见肘。论文《ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》中分析了训练过程中的memory需求。它将weight,gradient和optimizer state归为model state。混合精度和使用Adam优化器情况下,单个参数应对model state需要用到20 bytes。这样,对于大模型的memory需求远远超过了单卡GPU(A100的话是80G)的承受范围。对于100 B参数量的模型,光model state就需要64 GPU,如果是1T参数量的模型则需要512 GPU。论文《ZeRO: Memory Optimization Towards Training A Trillion Parameter Models》中提到参数量1.5 B的GPT-2光是model state就需要至少24 G。另外activation需要8G左右。这意味着一张V100基本就撑爆了。论文《Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model》中指出530 B的模型需要超过10 T的memory用于model state。Activation则会占用大约16.9 T(通过gradient accumulation优化可减少到8.8 G)。此外,为了减少计算量使用KV cache的话,也会增加不少的memory开销。这使得大模型计算的memory问题变得非常严重,很多时候它直接决定模型是否能跑得起来。
业界从多个角度提出方案来缓解memory的问题,如:
- Activation checkpointing / rematerization
- Heterogeneous Memory Management
- Compression
- Mixed precision training
- Memory efficient optimizer
- Live analysis & Reuse
本文主要关于分布式的方法,因此对上面这些点不作展开。减少内存使用一定程度上解决“跑不起来”的问题。跑起来后,就需要考虑“跑得更快”的问题。毕竟大家都在折腾大模型,发展非常迅速,能早些得到结果就意味着领先。一个好的想法,如果实验它需要几年,那等结果出来黄花菜都凉了。这就要求框架在计算大型AI模型时还需要提高硬件效率,最终提升训练效率。
进入正题前,先过一些相关概念。
为了更快得到结果,直观的想法是会投入更多的资源来扩展系统,而系统的扩展可分为两种方式:scale up和Scale out。通俗点说,前者是为单个计算节点添加更多的资源(如CPU,memory等);后者是添加更多的计算节点。理想情况下,我们希望吞吐是随着资源的投入线性增长的,虽然现实情况中,由于同步、通信开销等原因总会有些开销。要达到近线性的加速,就需要算法与系统是易被并行的,而且硬件资源的使用平衡。
在分布式计算下,这些可并行的任务就可以放到多卡或多机上。这就涉及到通信问题。否则额外计算资源带来的性能收益可能还补不上通信开销。硬件上,可以通过NVLink,PCIe等(可参见论文《Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect》)。多机可以通过Ethernet,GDR(GPU Direct RDMA)等机制。为了使用更方便,Nvidia提供了NCCL通信库利用多种通信机制向上提供诸如AllReduce、AllGather、ReduceScatter等常见的collective primitive。其它类似的通信库还有OpenMPI、Gloo。
在讲分布式并行前,先提下一些并行相关概念。首先workload得并行起来,才能分布到多卡或者多机上。并行是分布的基础。关于在深度学习领域的并行可以参见2018年的综述文章《Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis》。在此不展开。
关于并行带来的加速影响,涉及两个重要定律,即Amdahl和Gustafson定律。Amdahl定律可能是计算机领域最广为人知的定律之一,它定量地给出了提升系统的部分性能对整个系统性能的影响。它有一个假设就是问题的规模是固定的。论文《Reevaluating Amdahl’s Law》中指出现实中,人们一般是为了解决更大规模问题而增加更多资源。Gustafson定律以此为假设给出了增加计算资源对系统性能的影响。这两个定律从两个不同角度阐述了加速比,处理器个数与串行比例之间的关系。前者强调了要降低程度的串行化比例,否则光摞计算资源性价比不高。后者强调当并行化部分足够大,加速比是可以随着计算资源线性增长的。
对于大模型的计算,目前流行的分布式并行方法可以大体分为几类:
Data parallelism
AI模型在训练时一般都会将多个样本数据组成mini-batch一起计算。DP利用了这一点,将mini-batch进一步分成多个更小的mini-batch,再分给多个worker去处理。在这种模式下,每个worker都有完整的模型,包括weight,optimizer state等。每个worker都可以独立完成整个模型的梯度计算,它们计算出来的梯度最终需要聚合到一起。
其实对于大模型的分布式计算框架的研究其实从很早就开始了。2012年Google的论文《Large Scale Distributed Deep Networks》中提到的DistBelief(也就是TensorFlow的前身)采用了DP和MP等并行技术,以及改进的优化器,可以用于在集群中训练参数超过1B的模型。只是由于当时的局限性,它用的是CPU集群,而且是基于parameter server的中心式架构。导致机器数一多后,PS成为通信瓶颈影响scalability。因此,后来越来越多使用AllReduce方法,因为可以充分利用所有device的带宽。可参见"Massively Scale Your Deep Learning Training with NCCL 2.4"。
按同步方式还可以分为BSP(Bulk synchronous parallel)与ASP(Asynchronous parallel)两种。前者会有同步开销,后者没有同步开销,但无法保证收敛。因此,还有一种SSP(Stale synchronous parallel)方式是这两者的折中。即每个worker允许使用stale的weight处理下一个mini-batch。这个staleness的阀值是可以定义的。
2017年论文《Integrated Model and Data Parallelism in Training Neural Networks》中将DP分为两种:一种是Batch parallelism,即平时常见的那种;另一种是Domain parallelism。它将输入图片切分成多块交给多个worker处理。这种方式中,每个worker与batch parallelism一样也包含完整的模型参数,但只处理图像的一部分。它在视觉网络前几层activation比较大的情况下有比较好的通信复杂度。
DP由于实现简单,在各种主流AI框架中基本都有支持。如PyTorch的DDP(DistributedDataParallel),可参见论文《PyTorch Distributed: Experiences on Accelerating Data Parallel Training》。TensorFlow中的tf.distribute.Strategy,可参见"Distributed training with TensorFlow"和"Multi-GPU and distributed training"。MXNet中可以参考"Run MXNet on Multiple CPU/GPUs with Data Parallelism"。
最基础的DP的优点除了实现简单外,它的计算与通信效率也很高。但是,它的缺点也很明显:一是当worker数增多时,mini-batch也会随之变大,而过大的mini-batch会让训练不稳定甚至不收敛。此外,它最大的问题还在于,它无法解决单卡放不下大模型的问题。
为了解决DP无法减少memory footprint的问题,2019年的论文《ZeRO: Memory Optimization Towards Training A Trillion Parameter Models》提出了ZeRO(Zero Redundancy Optimizer)。ZeRO-DP用ZeRO扩展了DP,在达到DP的计算与通信效率的同时还能达到MP的内存效率。它通过将model state(parameter, gradient与optimizer state)在data parallel processes间进行切分,从而消除memory redundancy,同时它使用dynamic communication schedule利用model state时间上的使用特性减少通信量。根据切分model state的程度不同,ZeRO可分为三级,或三个stage。即ZeRO-1切分optimizer state;ZeRO-2切分optimizer state与gradient;ZeRO-3切分optimizer state,gradient和parameter。第三级可以支持在1024张Nvidia GPU上训练T级别参数的模型。
而后,论文《ZeRO-Offload: Democratizing Billion-Scale Model Training》中基于ZeRO提出ZeRO-Offload改进ZeRO-DP。它将optimizer state放在CPU memory中,同时每个process将自己的那份梯度也放到CPU memory中。ADAM优化器的更新在CPU上完成,更新完了再放回GPU。再使用GPU上的all-gather收集所有更新好的参数。论文《ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》中提出ZeRO-Infinity利用了NVMe memory进一步改进了ZeRO-Offload。这些属于异构内存管理的范畴,不是讨论重点,就不展开了。
它有点类似于后面要提到的TP,因为它会切tensor分到多个worker上。但它与TP的显著差别是TP是切完后在worker内部算完再聚合计算结果,因此它需要对代码有修改。而ZeRO只是利用多个worker来分布式地存tensor,在算之前会先聚合它们,算完了再把除了自己要维护的部分丢掉,从而减少memory占用。总得来说,MP会传输activation,而ZeRO不会。MP处理的切分的输入,而ZeRO处理的完整的输入。这样的话基本不需要修改代码。有些地方也将它区别于DP和TP,单独作为一类来介绍。这里为了乘法,同时因为论文中称为ZeRO-DP,因此放到DP这一节来一并提了。
ZeRO实现于Microsoft自家的框架DeepSpeed中。由于它的有效性,其思想也被其它的框架所吸收。比如PyTorch中的FSDP(Fully Sharded Data Parallel)就是受ZeRO与FairScale的Fully Sharded Data Parallel的影响。详细可以参见"Introducing PyTorch Fully Sharded Data Parallel (FSDP) API"和"GETTING STARTED WITH FULLY SHARDED DATA PARALLEL(FSDP)"。
在DP中,由于每个data-parallel process都会有完整的模型,它们需要一致地被更新。这个weight的更新操作需要在所有的模型replica上进行。这是一个冗余操作。2020年的论文《Automatic Cross-Replica Sharding of Weight Updates in Data-Parallel Training》针对这个问题,提出了shareded DP。该方法在XLA框架上实现,用于Cloud TPU。它利用all-reduce操作可分为reduce-scatter与all-gather两个阶段的特点,使用静态分析与变换,使多个replica共同分担weight update计算。
关于DP的优化也有不少相关工作,如论文《Preemptive All-reduce Scheduling for Expediting Distributed DNN Training》中的PACE是一个communication scheduler,用于抢占式调度all-reduce操作,从而最大化计算与通信的overlapping;论文《Supporting Very Large Models using Automatic Dataflow Graph Partitioning》中的ByteScheduler也是用于提升了DP中的overlapping ratio。
Model parallelism
MP是一类将model state在多个device上切分的方法。它的优点是可以让多卡分担memory占用,从而解决模型放不下单卡的问题。但缺点是要使切分的工作量平衡不太容易,计算间有依赖,activation需要传输导致通信量增加。
对于一个模型,切法有很多。有些是比较通用的,有些适用于特定网络。因此MP也可细分为好几类:
Tensor parallelism
又称为operator parallelism,operator-level parallelism,或horizontal MP。它将单个算子在多个device间切分。通常用于单个算子的weight就占用大量GPU memory的情况,如embedding layer。
最早,在论文《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》中使用了TP来并行化连续的FF层(Transformer中的self-attention与feed-forward)。它利用矩阵的分块相乘性质将weight切分,从而将相乘的计算量分到多个worker上。由于目前流行的Transformer网络其主要计算量为矩阵相乘。TP应用于GEMM就可以看作并行矩阵相乘(Parallel GEMM)问题。并行矩阵相乘按并行的维度可分为:
- 1D:上面提到的Megatron中将weight在单个维度上切分,是1D的。
- 1.5D:如论文《Communication-Avoiding Parallel Sparse-Dense Matrix-Matrix Multiplication》
- 2D:如经典的Cannon’s algorithm和SUMMA(Scalable Universal Matrix Multiplication Algorithm)。还有论文《An Efficient 2D Method for Training Super-Large Deep Learning Models》中的Optimus使用SUMMA来提升内存与通信效率。
- 2.5D:如论文《Tesseract: Parallelize the Tensor Parallelism Efficiently》是基于SUMMA与2.5D Matrix Multiplication。论文《Communication-Optimal Parallel 2.5D Matrix Multiplication and LU Factorization Algorithms》提升了Cannon’s algorithm的效率。
- 3D:原始3D并行矩阵乘法可参见论文《A three-dimensional approach to parallel matrix multiplication. IBM Journal of Research and Development》。论文《Maximizing Parallelism in Distributed Training for Huge Neural Networks》做了改进,消除了原算法中广播数据的冗余。论文《Communication-Optimal Parallel Recursive Rectangular Matrix Multiplication》提出CARMA是一种达到asymptotic lower bound的递归算法。论文《Red-blue pebbling revisited: near optimal parallel matrix-matrix multiplication》提出COSMA(Communication Optimal S-partition-based Matrix multiplication Algorithm)使用red-blue pebble游戏来建模数据依赖,并推出I/O最优schedule。
Colossal-AI中集成了多种并行矩阵相乘方法,有兴趣可以参考。
论文《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》中提出的GShard模块包含一组轻量级的annotation API和XLA compiler的扩展。它采用automatic sharding的方法,用于有600 B参数的带Sparsely-Gated Mixture-of-Experts的transformer网络。
基于GShard,论文《GSPMD: General and Scalable Parallelization for ML Computation Graphs》中的GSPMD使用了tensor sharding annotations来以一种统一的方式达到不同的并行(DP, in-layer MP和spatial partitioning等)。切分的方式很灵活,不同层可以用不同的方法切分,同一层可以使用不同方法切分。GSPMD泛化了其后端GShard,以partial tiling和manual subgroups扩展了sharding representation,实现了像priority sharding propagation, recursive partitioning和pipepiling等特性。该方法可用于上千个TPUv3 cores上的视觉、语音和语言模型。
Pipeline parallelism
又称为vertical MP。与TP切分单个算子不同,PP是将整个网络在层间进行切分。这样整个计算图就分为几个子图。对于有依赖的子图计算时就像工厂的流水线一样,没有依赖的部分可以在多device上并行执行。PP与TP相比,通信量更小。在TP中,每个Transformer layer需要两次activation上的all-reduce操作。而对于PP,只需要点到点的通信。因此PP需要更少的通信,但它的问题是会有bubble和weight staleness。因此,两者是正交互补的关系。
PP早期比较经典的工作大致开始于2018年,包括Microsoft论文《PipeDream: Fast and Efficient Pipeline Parallel DNN Training》中提出的PipeDream和Google论文《GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism》中提出的GPipe。
PipeDream以一种通用和自动的方式结合PP, MP和DP。PipeDream将DNN切成多个Stage。为了将这个过程自动化,它通过profiler估计每个layer的计算时间与output size。基于这些估计,optimizer对之进行切分。切分算法的目标是最小化总训练时间,等价于最小化最慢的stage的时间。该问题具有optimal sub-problem property(即给定机器数量最大化吞吐的pipeline,包含了最少机器数量时最大化吞吐的sub-pipeline),因此可以用DP求解。Work scheduling使用1F1B(one-forward-one-backward)来避免GPU的idle时间。将forward和backward的执行交替,这样就不需要等到所有的forward完成再执行backward,从而提升硬件利用率。它采用异步backward update的pipeline中每个mini-batch的forward和backward pass使用不同的参数,即weight staleness问题,这可能导致训练无法收敛。另外,不同的stage可能面临不同程度的staleness。这也会导致收敛性受影响。PipeDream使用了两种技术:一是Weight Stashing维护多份weight,每个active mini-batch一份;二是Vertical Sync用于估计potential inconsistency across stages。
与PipeDream不同,GPipe使用的是同步SGD。因此,它会产生bubble。为了减少bubble的开销,GPipe采用batch splitting技术,将mini-batch切分为更小的micro-batches,然后对其用pipeline。每个micro-batch称为一个chunk。同步发生在mini-batch结束时。一个mini-batch中的micro-batches的梯度进行累加后在mini-batch的结尾一次应用。这个同步产生的bubble,当device越多越严重。当M >= 4 x K(M为micro-batches,K为accelerator数量)时bubble overhead可以忽略。另外,由于它需要将中间activation的结果存下来,因此内存需求很大。
简单的pipelining会因为inconsistent weight的问题影响模型收敛性。为了解决这种问题需要在memory footprint与throughput间做trade-off。以前面的两种方法为例,它维护一份weight,并周期性地进行pipeline flush。而PipeDream采用的是weight stashing策略。它没有周期性的pipeline flush,代价是需要维护多份weight。前者降低了throughput,后者增加了memory footprint。
2020年的论文《Memory-Efficient Pipeline-Parallel DNN Training》提出的PipeDream-2BW(2BW是double-buffered weight updates的缩写)及使内存更加高效。它使用weight gradient coalescing strategy和double buffering of weights技术。该方法利用了每个输入产生的梯度不需要马上应用,因此可以被累加,从而减少需要维护的weight。它将1F1B与2BW scheme结合,在每个wokrer上最多stash两份weight。避免pipeline flush同时降低memory footprint。梯度以micro-batches的粒度来计算。多个micro-batches的更新会累加,然后以batch为粒度来应用梯度。PipeDream-2BW结合了PP与DP,它将模型分为多个stage放到多个worker中用PP,然后将每个stage复制多份用DP。PipeDream-2BW的planner基于cost model,通过搜索的方法决定如何在worker间切分模型。其变体PipeDream-Flush有比2BW更低的memory footprint,但吞吐也低一些。它维护一份weight,引入周期性的pipeline flush来保证consistent weight。
Megatron在"Scaling Language Model Training to a Trillion Parameters Using Megatron"一文中提到Interleaved schedule。它不限制将连续的layer分到一个device上,而是允许多个stage分到一个device上。在Interleaved 1F1B schedule中,device上的stage依次执行。这样的优点是可以减少bubble,但缺点是由于stage数量加倍,导致通信量增加。
2019年论文《PipeMare: Asynchronous Pipeline Parallel DNN Training》提出的PipeMare是一种异步方法,文中它和前面提到的同步方法(PipeDream与GPipe)从delay, pipeline utilization和memory usage角度做了对比。现有PP方法为了保证sync execution(即forward中的wegith和backward中用于计算gradient的是同一份),会引入了bubble,或者存micro-batch的多份weight。这些方法会降低硬件效率。PipeMare去除了sync execution的限制。为了解决由此引入的对收敛性的影响,它提出两种技术:Learning rate rescheduling(step size与delay反比)和Discrepancy correction(调节backward中的weight)。
2020年论文《DAPPLE: A Pipelined Data Parallel Approach for Training Large Models》中的DAPPLE是一个结合了DP和PP的同步的分布式训练框架。其中的Profiler以DNN模型为输入,然后对每一层的执行时间,activation size和parameter size进行profile。基于这些profile结果,以及硬件配置等信息,并行策略的planner基于动态规划算法解决partition与placement(device mapping)问题,从而得到执行时间最优的DP与PP混合策略。另外它还提出一种运行时调度算法来减少device memory的占用。它的特点是可以确定和交叉的方式来执行forward与backward,从而让每个pipeline任务的内存可以尽早释放。
2020年论文《Pipelined Backpropagation at Scale: Training Large Models without Batches》改进了PB(Pipelined Backpropagation)方法。PP一般会将mini-batch切成micro-batch,并组成pipeline。同步方式中,需要等pipeline空了才开始下一轮mini-batch的参数更新。但这个pipeline的fill和drain的过程会严重降低硬件利用率,尤其是当batch size相对pipeline stage数较小时。而PB是一种异步训练方法,它不需要等pipeline清空,因此避免了fill和drain带来的开销。但是它会带来inconsistent weight和stale gradient的问题,导致准确率下降和训练不稳定。另一方面,fine-grained pipelining将每一层作为一个pipeline stage(也就是每个process处理一层),被发现在一些场景下有很好的性能。但它会使得pipeline stage变多,从而加重weight inconsistency问题。另外,small micro-batch size能减少fine-grained PB中的gradient delay与weight inconsistency问题。针对fine-grained, small batch场景下PB的准确率退化问题,本文引入SC(Spike Compensation)和LWP(Linear Weight Prediction)两个方法来解决。
2020年论文《HetPipe: Enabling Large DNN Training on (Whimpy) Heterogeneous GPU Clusters through Integration of Pipelined Model Parallelism and Data Parallelism》结合PP与DP,应用在异构GPU cluster上。这些cluster中有不同型号的GPU,有一些可能是几代前的,单卡无法进行训练。HetPipe(Heterogeneous Pipeline)中,一组GPU,称为virtual worker,以pipeline方式处理minibatch。多个virtual worker采用DP。另外,还提出Wave Synchronous Parallel(WSP)。所谓wave指在一个virtual worker中可以并行处理的一串minibatch。每个virtual worker一次性更新wave的所有minibatch,而不是每个minibatch更新一次到PS。它会通过profile得到perf model。然后将partitioning问题建模成linear programming问题,最后通过CPLEX求解。
2020年论文《GEMS: GPU-Enabled Memory-Aware Model-Parallelism System for Distributed DNN Training》中的GEMS是GPU上的Memory-Aware MP系统。它结合了MP和DP。为了克服现有系统资源利用率低和实现复杂的缺点,它提出了两种设计:MAST(Memory Aware Synchronize Training)和MASTER(Memory Aware Synchronized Training with Enhanced Replications)。通过训练额外一份模型replica,来填满做完一次forward与backward后空闲的硬件资源。在1024张V100上来训练1K层的ResNet,并达到相当高的scaling-efficiency。
2021年论文《Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines》提出的Chimera也是一种PP方法。它结合了bidirectional pipeline方法。其主要思想是结合不同方向的两个pipeline。与最新的同步pipeline方法相比,它减少最多50%的bubble。它是一种同步方法,因此不影响accuracy和convergence。与SOTA方法具有相同的peak activation memory用量,且memory消耗更加平衡。
2021年论文《PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers》中的automated elastic piplining提升了Transformer分布式训练的效率。调节PP与DP的程度。Freeze training的研究表明神经网络中的参数常常是由下而上收敛的,因此就可以动态分配资源使它们聚焦于某一些active layer。在训练过程中,它渐进地识别并冻结一些layer,将资源用于训练其它的active layer。PipeTransformer由几部分组成:1) Freeze Algorithm从training loop中采样,并作出freezing的决策。2) AutoPipe是一个elastic pipeline module将frozen layer剔除,剩下的active layer打包塞入GPU。3) AutoDP得到AutoPipe传来的pipeline length信息,它会spawn更多的pipeline replica,尽可能提升DP宽度。4) AutoCache是跨pipeline的caching module。它有专门的模块在shared memory中维护cache,这样所有的训练进程可以实时访问。当activation太大无法放入CPU memory,它还会将之swap到disk,并自动做pre-fetching。
可以看到,以上方法大致可分为两步和异步两种。同步方法,像GPipe, GEMS, DAPPLE, Chimera通过periodic pipeline flush保证weight的一致性,从而保证了收敛性。因此更convergence-friendly,但有bubble。而异步方法(如PipeDream, PipeMare)没有flush,虽然吞吐会更高,但会导致forward与backward的weight版本mismatch(如AMPNet和PipeMare),或者虽然weight版本一致,但是会有weight staleness问题(如PipeDream)。这样虽然能减少或者消除bubble,但有stale weight的问题。为了使得weight版本一致,就需要保留多份weight,从而使memory footprint增大。
Sequence parallelism
相比前两种,SP是一种更加针对特定模型的方法。语言类的模型一般要处理或者生成token序列,SP在这个维度上做并行。
2022年论文《Sequence Parallelism: Long Sequence Training from System Perspective》中讨论了sequence parallelism。Transformer模型中self-attention的memory消耗与sequence length是平方关系,因此大的sequence length常常会限制大模型的运行。现有的并行方法都要求整个sequence放在一个device上。SP将activation沿着sequence维度进行切分,然后分到多个device上,让每个device只维护一部分sequence。为了跨device计算attention score,SP使用了ring-style communication,提出Ring Self-Attention(RSA)。其实现基于PyTorch,且与DP, PP和TP兼容,因此称为4D parallelism。该方法和DP类似,需要参数和optimizer state在所有device上拷贝,因此对于大模型仍然不是很友好。
2021年论文《TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models》中的TeraPipe利用了Transformer-based model的auto-regressive性质,用于single training sequence内的PP。
2022年的论文《Reducing Activation Recomputation in Large Transformer Models》提出两种技术:sequence parallelism和selective activation recomputation。两者都可以将内存需求减少约一半。其中的SP结合了TP。
Expert Parallelism
在不显著增加计算量的情况下增加模型capacity一个方法是利用网络结构上的sparsity(注意不要与诸如矩阵计算中的sparsity混淆)。近几年比较火的一种网络范式就是Mix of Expert(MoE)。这种结构是由2017年论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》提出。它拥有一个很好的性质,就是可以在计算代码不增加的情况下增加参数量。方法是添加sparsely activated expert block,并添加一个parameterized routing function在它们前面。
2021年论文《FastMoE: A Fast Mixture-of-Expert Training System》中的FastMoE是一个开源的基于PyTorch的分布式的MoE训练系统。FastMoE支持将expoert分布到多个计算节点的多个worker上。
2023年论文《A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training》提出了DeepSpeed-TED。它结合了ZeRO的DP,MegatronLM的TP和DeepSpeed-MoE的expert parallelism。其中expert Parallelism利用了expert block可以并行计算的特点,将它们放到不同的GPU上。
Hybrid parallelism
2022年论文《Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model》中从memory和compute efficiency角度比较了几种并行方法的优劣。
- DP的compute efficiency高,易于实现,但是随着worker增加,batch size也需要对应地增加,但增加batch size会影响收敛。Memory efficiency由于复制了model和optimizer,因此不高。梯度需要在worker间通信与聚合,而梯度的通信开销随着模型增大而增大。这会让通信带宽限制compute efficiency。
- TP的memory footprint随着worker数量增加同比减少。每个worker的计算量减少,会影响compute efficiency。
- PP的memory footprint随着pipeline stage同比减少,但不减少activation的memory footprint。PP的通信开销最小,它要求切分尽可能均衡。
实际工程中,几种并行方式是可以同时使用的,这样可以结合各种并行方法的优势。前面提到的很多论文中的工作其实都结合了多种并行方式,比如PipeDream就结合了DP和MP。另外像论文《Integrated Model and Data Parallelism in Training Neural Networks》中也结合了DP与MP。
结合多种并行方法的一般原则是节点内使用TP,节点间使用PP。再用DP复制到更多节点。比如论文《Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model》提到Megatron-Turing NLG 530B在280 A100集群中在node内部使用8-way TP,在node间使用35-way PP。然后用DP扩展到千卡。
基础设施
为了支持灵活的分布式并行,不能啥都从头手撸,还需要一些软件基础设施还提高效率。业界在这方面也有一些相关探索。
2018年论文《Mesh-TensorFlow: Deep Learning for Supercomputers》中的Mesh-TensorFlow支持SPMD式的per-operator partitioning。Mesh-TF引入了一种tensor partition的表达。它将processors视作多维mesh。张量可以沿着mesh维度复制或切分。Mesh-TensorFlow引入了一种可以指定分布式TP计算的语言,可以编译计算图,加上collective primitive。使用的案例比如Switch Transformers。
2021年论文《CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning》提到目前机器学习中的计算与通信是独立的抽象,由不同的库实现。而打破这个边界可以解锁更多优化。比如 Interface(模型参数放在非连续buffer中,而要调用collective communication(如AllReduce)前需要拷贝到一个单独的buffer中),Fusion(产生执行多个通信与计算操作的kernel,从而减少memory bandwidth),Reorder(将计算移到通信前或后,这样可以分散计算或者使能fusion),Overlapping(多个计算和通信操作以细粒度编排,充分利用计算与网络资源)。
2021年论文《CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning》中的CoCoNET(Communication and Computation optimization for neural networks)使用了嵌入于C++的DSL表达包含计算与通信操作的kernel。受Halide启发,CoCoNET包含scheduling语言,用一组变换指定执行调度。然后由AutoTuner自动应用这些变换优化程序。最后Code generator根据程序和schedule生成高性能kernel。
2022年论文《MSCCL: Microsoft Collective Communication Library》
GC3提供面向数据的DSL用于写自定义的collective communication algorithm,optimizing compiler将之lower成可执行形式。最后基于interpreter runtime来执行。它可用于AllReduce和AllToAll操作。GC3是一种内嵌于Python的声明式语言,采用chunk-oriented programming style(受dataflow编译语言启发)。它可以为特定的topology和input size,又或者是自定义collective(如AllToNext)产生MPI抽象的新算法。
2022年论文《OneFlow: Redesign the Distributed Deep Learning Framework from Scratch》中的OneFlow提出了SBP(split, broadcast, partial-value)抽象,包含S,B和P(分别对应split, broadcast, partial-value)。它用于指定global tensor和对应local tensor的对应关系。这个对应关系称为SBP signature。通过对应的API,用户就无需接触low-level的通信原语,只需指定placement和SBP signature。基于这些,compiler可以自动生成DP, MP和PP的执行计划。
自动化策略
上面讲了分布式并行的方法,以及相应的基础设施,那剩下的核心问题就是切分策略了。
最简单就是方式当然是手工制定切分策略。如2021年论文《GSPMD: General and Scalable Parallelization for ML Computation Graphs》中提出的GSPMD需要用户通过annotation的方式指定sharding strategy。也就是说,这种方式中,如何切分就需要使用者来制定。
随着网络模型和硬件越来越大,越来越复杂,手工配置的缺点就越来越明显了。精力花费不说,模型或者运行环境一变可能就得重来。
更自动化一些的方式是针对特定的网络结构与硬件特性,根据经验制定切分的规则。如2014年的论文《One weird trick for parallelizing convolutional neural networks》中讨论针对CNN的Conv与FC制定的并行策略。Conv由于计算量大但参数少,适合DP,而FC相比之下正好相反,适合MP。2022年的论文《Efficiently Scaling Transformer Inference》讨论了TPU v4(3D torus topology)上运行PaLM模型的一些方法。其中就针对网络中的Attention与FF,结合硬件特性提出了切分的策略。
根据给定网络模型与硬件配置找最优的并行策略本质上是一个组合优化问题。对于这样一类问题,更加理想一些的方式是自动化地找出最优解。常见的方式比如整数线性规划,启发式搜索或者强化学习。
对于MP的策略搜索其实也可以看作device placement问题。对于该问题,几年前就有不少相关工作。虽然大部分是针对单机多卡,或者CPU与GPU的异构计算等小规模场景,但原理是类似的。其中很多是基于强化学习方法。如2017年的论文《Device Placement Optimization with Reinforcement Learning》中的ColocRL使用强化学习让RNN策略网络来预测计算图中操作的placement,从而来解决CPU与多GPU环境中的device placement问题。2018年的论文《A Hierachical Model for Device Placement》是对它的改进,引入了更加灵活的方式,免除了需要人工对算子分组的繁琐。还有2018年的论文《Spotlight: Optimizing Device Placement for Training Deep Neural Networks》中的Spotlight基于强化学习中的PPO算法。2018年的论文《Post: Device Placement with Cross-entropy Minimization and Proximal Policy Optimization》结合了cross-entropy minimization和PPO算法。前者用于batch间,后者用于batch内,从而提高学习效率。2018年的论文《Placeto: Efficient Progressive Device Placement Optimization》中的Placeto也是基于强化学习。它通过迭代式生成placement方案和使用graph embedding提高了模型的泛化能力。2019年的论文《REGAL: Transfer Learning For Fast Optimization of Computation Graphs》中提出的REGAL(REINFORCE-based Genetic Algorithm Learning)则是结合了强化学习与遗传算法(更具体地,BRKGA)。该算法由强化学习(REINFORCE算法)训练GNN表示的策略网络,负责输出分布,用于遗传算法中的mutation和crossover。
2018年的论文《Beyond Data and Model Parallelism for Deep Neural Networks》中的FlexFlow使用自动搜索的方法来找图中operation在考虑DP与MP情况下的最优切分。FlexFlow是一个高用编排TP计算的DP框架。它使用Markov Chain Monte Carlo算法来进行策略的搜索。其中会考虑sharding strategy和placement。
2019年的论文《Optimizing Multi-GPU Parallelization Strategies for Deep Learning Training》提出MP与DP结合可以有效解决DP的scaling与statistical效率降低的问题。为了找到混合DP与MP下的最优策略,它使用了基于整数线性规划的工具-DLPlacer用于求解device placement问题,最大化并行度,减少数据通信开销。它以最小化单步的训练时间为目标,给出operation在硬件资源上的分配方案,schedule与activation等数据的通信路径。
2020年的论文《Efficient Algorithms for Device Placement of DNN Graph Operators》基于cost model自动切分模型到多个device。Device placement问题中的核心是组合优化问题。文中使用基于Integer Programming(IP)与Dynamic Programming(DP)来解决。并且支持non-contiguous fragment of graph。类似的DP也在PipeDream中使用,区别是PipeDream只支持线性的layer-granularity graphs。
2020年的论文《Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training》是一种在DP中对weight update做自动切分的方法。在DP中,所有的replica都会做weight update计算(因为weight没有batch维)。一种方案是weight update计算sharding。但简单的做法会导致data formatting和replica间通信开销极大增加。该文自动将weight update计算在replica间做sharding。它基于XLA,基于static analysis(为了正确性与性能)和graph transformation。不需要修改模型代码。
2020年的论文《Optimizing Distributed Training Deployment in Heterogeneous GPU Clusters》提出的HeteroG是一个用于异构GPU集群中加速深度神经网络训练的模块。HeteroG使用operation-level的hybrid parallelism,communication architecture selection和execution scheduling。它基于GNN-based learning和组合优化。
2021年的论文《Amazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training》中介绍了Amazon的SageMaker。它采用module server架构,支持PP,TP和DP多种并行方法,并可以对模型进行自动的切分与分布。切分算法的目标是尽可能使device上的计算与访存平衡,并减少通信次数。它还为PP提供专用的通信后端。它管理node内与node间的device-to-device通信,而无需依赖NCLL。
2021年的论文《Varuna: Scalable, Low-cost Training of Massive Deep Learning Models》中的Varuna自动配置分布式(MP与DP)的训练,它可以利用spot VMs而非dedicated VMs,使成本降低5倍。它解决三个挑战:慢及不稳定的网络,资源可能被抢占,对用户透明。对于网络问题,它的micro-batch调度算法可能更加高效应对network jitter,另一方面stage的切分还考虑了网络带宽。对于抢占问题,它采用了一种dynamic, semantics-preserving reconfiguration方法,称为Job morphing。它可以在训练过程中配置pipeline depth等参数,从而适配资源。为了找到更优的配置,它有提供了micro-benchmark-driven simulation机制。对于易用性问题,它引入了自动找模型中cut-points的机制。
2022年的论文《Accelerating Large-Scale Distributed Neural Network Training with SPMD Parallelism》根据DNN model与cluster specification自动找sharding strategy。它通过overlap通信与计算来减少通信开销。两个device上计算两个micro-batch可以并行,一个通信时另一个计算。构建training time cost model,并设计基于DP的搜索算法。基本思想是将每个device上分配的计算图复制一份。每个用一半的输入数据训练。这样,两个micro-batch就能形成pipeline,从而将计算与通信overlap。 基于PyTorch实现系统HiDup。它的输入为模型和集群的 spec。输出是可用于运行在多个GPU上的模型。
2022年论文《Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning》中的Alpa是一个用于GPU cluster的DL编译系统。它构建于Jax之上,支持自动地将JAX函数并行化,分析计算图并根据计算图与cluster产生并行执行计划,从而结合DP,TP和PP将DL运行在分布式集群上。Alpa将并行分为两个层次:inter-operator与intra-operator并行,将它们分别看作子问题来求解。后者由于通信量需求大,一般分配在由高带宽连接的设备中。它将device cluster切成若干device mesh。首先,Inter-op pass使用DP将stage分配给mesh。然后,Intra-op pass使用ILP优化给定stage与mesh上的并行执行计划,再将cost反馈给inter-op pass。这些信息帮助inter-op pass使用DP最小化inter-op的执行时间,从而获得更优的stage与mesh划分策略。此外,runtime orchestration pass用来满足相邻stage的通信需求。
2023年的论文《Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models》是一个基于PyTorch的自动化的intra-op (不考虑inter-op)并行系统。可以对分布式并行和activation checkpoint进行联合优化。它使用anayzer模块收集硬件性能和计算图开销信息,采用采用two-stage的求解器找到执行计划,最后将PyTorch模型编译成分布式的模型。Analyzer包含三个部分:symbolic profiler收集由PyTroch FX模块生成的静态计算图的计算和访存开销。Cluster detector收集硬件特性和集群的拓扑结构信息。Tensor layout manager用于确定tensor layout的conversion策略。并行执行计划的搜索分为intra-op与activation checkpoint两层。前者采用的是Alpa中用于处理intra-op的ILP求解器;后者采用Rotor算法。Generator将生成的执行计划应用于原图,然后将优化过的图编译成PyTorch代码。其中的pass会插入通信节点,对参数做sharding和对参数做reshape conversion。
2023年的论文《OSDP: Optimal Sharded Data Parallel for Distributed Deep Learning》中的OSDP(Optimal Sharded Data Parallel)是结合DP与MP的自动并行训练系统。它在内存使用与硬件利用率间做trade-off,自动产生最大化吞吐率的分布式的计算图。它指出ZeRO系统的两个缺点:与vanilla DP比有额外50%的通信开销,中间的巨大张量会使peak memory usage超限。对于第一个问题,它对于每个operator确定是否要做parameter sharding。对于第二个问题,它使用operator splitting技术。OSDP包含三个modules:Profiler, Search Engine和Scheduler。Profiler负责根据Search Engine给的execution plan与batch size,基于cost model估计memory和time cost。Search Engine基于Profiler的cost估计,用DFS遍历所有operator,生成memory不超过限制下的最优execution plan。Scheduler迭代地收集Search Engine给出的plan与throughput作为candidate,同时增加batch size直到所需memory超过device限制。
相关文章:

LLM时代中的分布式AI
深度学习相较传统机器学习模型,对算力有更高的要求。尤其是随着深度学习的飞速发展,模型体量也不断增长。于是,前几年,我们看到了芯片行业的百家争鸣和性能指标的快速提升。正当大家觉得算力问题已经得到较大程度的缓解时…...
Zinx框架-游戏服务器开发003:架构搭建-需求分析及TCP通信方式的实现
文章目录 1 项目总体架构2 项目需求2.1 服务器职责2.2 消息的格式和定义 3 基于Tcp连接的通信方式3.1 通道层实现GameChannel类3.1.1 TcpChannel类3.1.2 Tcp工厂类3.1.3 创建主函数,添加Tcp的监听套接字3.1.4 代码测试 3.2 协议层与消息类3.2.1 消息的定义3.2.2 消息…...

如何使用Pyarmor保护你的Python脚本
目录 一、Pyarmor简介 二、使用Pyarmor保护Python脚本 1、安装Pyarmor 2、创建Pyarmor项目 3、添加Python脚本 4、配置执行环境 5、生成保护后的脚本 三、注意事项与未来发展 四、未来发展 五、总结 本文深入探讨了如何使用Pyarmor工具保护Python脚本。Pyarmor是一个…...

【c++】搜索二叉树的模拟实现
搜索二叉树的模拟实现 k模型完整代码 #pragma once namespace hqj1 {template<class K>struct SBTreeNode{public://这里直接用匿名对象作为缺省参数SBTreeNode(const K& key K()):_key(key), _cleft(nullptr), _cright(nullptr){}public:K _key;SBTreeNode* _cle…...
)
Kubeadm - K8S1.20 - 高可用集群部署(博客)
这里写目录标题 Kubeadm - K8S1.20 - 高可用集群部署一.环境准备1.系统设置 二.所有节点安装docker三.所有节点安装kubeadm,kubelet和kubectl1.定义kubernetes源2.高可用组件安装、配置 四.部署K8S集群五.问题解决1.加入集群的 Token 过期2.master节点 无法部署非系…...
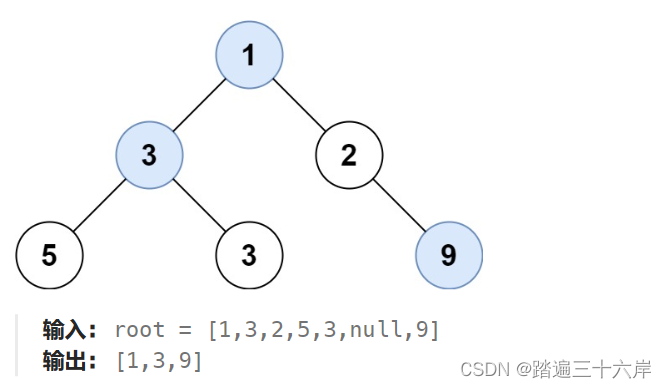
515. 在每个树行中找最大值
描述 : 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 题目 : LeetCode 在每个树行中找最大值 : 515. 在每个树行中找最大值 分析 : 这里其实就是在得到一层之后使用一个变量来记录当前得到的最大值 , 懂了前面的几道这就是小菜 解析 : /…...
基于springboot+vue的图书馆管理系统
图书馆管理系统 springboot32阿博图书馆管理系统 源码合集: www.yuque.com/mick-hanyi/javaweb 源码下载:博主私 摘 要 随着社会的发展,计算机的优势和普及使得阿博图书馆管理系统的开发成为必需。阿博图书馆管理系统主要是借助计算机&…...

诊断刷写流程中使用到的诊断服务
10 01:诊断刷写完成后让目标ECU重置或让整车网络中其他ECU切换回默认会话 10 02:设置外部编程请求标志位或切换到编程会话(诊断刷写需要在编程会话下进行) 10 03:让目标ECU切换到扩展会话,以便进行其他诊断…...
pytorch 中 nn.Conv2d 解释
1. pytorch nn.Con2d 中填充模式 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride1, padding0, dilation1, groups1, biasTrue, padding_mode‘zeros’, deviceNone, dtypeNone) 1.1 padding 参数的含义 首先 ,padd N, 代表的是 分别在 上下&…...
漏刻有时百度地图API实战开发(2)文本标签显示和隐藏的切换开关
项目说明 在百度地图开发的过程中,如果遇见大数据量POI标注展示或在最佳视野展示时,没有文本标签,会不清楚具体标注的代表的意义;如果同时显示大量的文本标签,又会导致界面杂乱且无法清晰查看,因此&#x…...

Flink往Starrocks写数据报错:too many filtered rows
Bug信息 Caused by: com.starrocks.data.load.stream.exception.StreamLoadFailException: {"TxnId": 2711690,"Label": "cd528707-8595-4a35-b2bc-39b21087d6ec","Status": "Fail","Message": "too many f…...
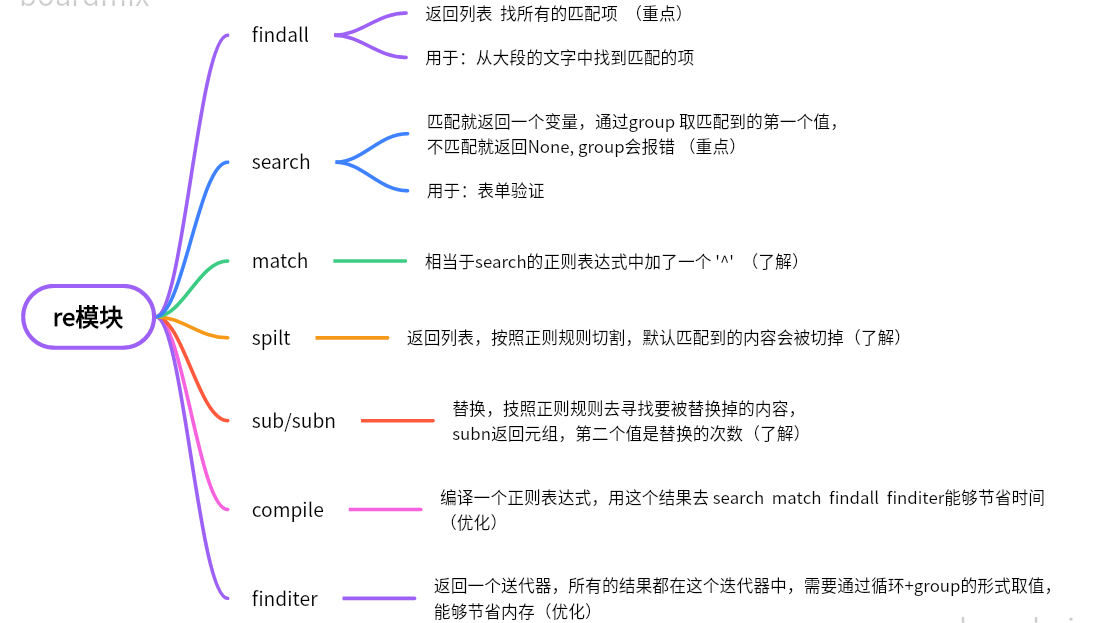
python-re模块
python之正则表达式-基础匹配https://blog.csdn.net/Python_1981/article/details/133777795python之正则表达式-元字符匹配https://blog.csdn.net/Python_1981/article/details/133778805 一、查找 1、findall 2、search 如果没有匹配到,会返回None, 使用group会报…...

SSM之spring注解式缓存redis
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《Vue.js使用》 ⛺️ 越努力 ,越幸运。 1.Redis与SSM的整合 1.1.添加Redis依赖 在Maven中添加Redis的依赖 <redis.version>2.9.0</redis.…...

jmeter压测问题分析
1、 目录 1、jmeter压测java.net.BindException: Address already in use: connect问题处理: 2、jmeter压测:java.net.SocketException: Socket closed: : 之前未勾选same user on each iteration中报问题java.net.BindExcept…...

threejs CSS3DRenderer添加标签并设置朝向摄像机
一.由于CSS3DRenderer 是附加组件,必须显式导入 import { CSS3DRenderer, CSS3DObject } from three/examples/jsm/renderers/CSS3DRenderer.js;二.CSS3DRenderer特点 CSS3D不面向摄像机,会跟随场景缩放,不被模型遮挡,通过DOM事…...
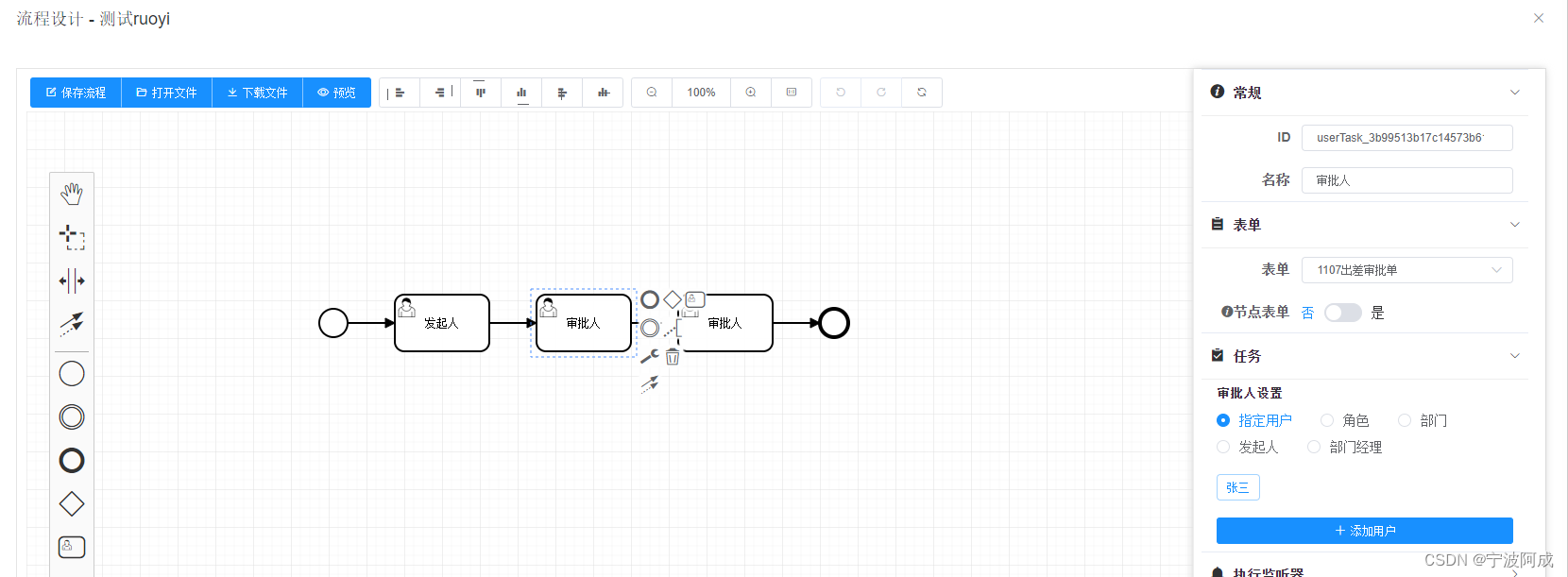
基于若依的ruoyi-nbcio流程管理系统仿钉钉流程json转bpmn的flowable的xml格式(简单支持发起人与审批人的流程)续
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 之前生产的xml,在bpmn设计里编辑有些内容不正确,包括审批人,关联表单等…...
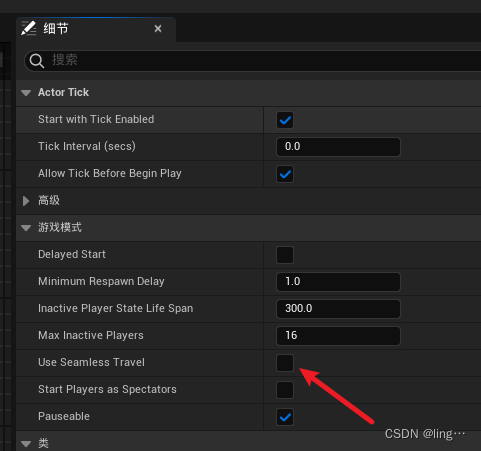
虚幻引擎:如何进行关卡切换?
一丶非无缝切换 在切换的时候会先断开连接,等创建好后才会链接,造成体验差 蓝图中用到的节点是 Execute Console Command 二丶无缝切换 链接的时候不会断开连接,中间不会出现卡顿,携带数据转换地图 1.需要在gamemode里面开启无缝漫游,开启之后使用上面的切换方式就可以做到无缝…...

工具类xxxUtil从application.properties中读取参数
一.原因 编写一个服务类的工具类,想做成一个灵活的配置,各种唯一code想从配置文件中读取,便有了这个坑。 二.使用value获取值为null, 这是因为这个工具类没有交给spring boot 来管理,导致每次都是new 一个新的,所以每…...
三国志14信息查询小程序(历史武将信息一览)制作更新过程05-后台接口的编写及调用
1,创建ASP.NET Web API项目 生成完毕,项目结构如下: 运行看一下: 2,后台接口编写 (1)在Models文件夹中新建一个sandata.cs文件(就是上篇中武将信息表的model文件) u…...

时序预测 | MATLAB实现基于SVM-Adaboost支持向量机结合AdaBoost时间序列预测
时序预测 | MATLAB实现基于SVM-Adaboost支持向量机结合AdaBoost时间序列预测 目录 时序预测 | MATLAB实现基于SVM-Adaboost支持向量机结合AdaBoost时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab实现SVM-Adaboost时间序列预测(风…...

如何利用QOwnNotes托盘图标提升效率:快速访问与系统通知设置终极指南
如何利用QOwnNotes托盘图标提升效率:快速访问与系统通知设置终极指南 【免费下载链接】QOwnNotes QOwnNotes is a plain-text file notepad and todo-list manager with Markdown support and Nextcloud / ownCloud integration. 项目地址: https://gitcode.com/g…...

别再只盯着IOU了!手把手拆解DeepSort级联匹配,看它如何用‘优先级’解决ID跳变
别再只盯着IOU了!手把手拆解DeepSort级联匹配,看它如何用‘优先级’解决ID跳变 当你在监控视频中看到行人ID突然从"007"跳变成"1024"时,是否曾怀疑自己的多目标跟踪系统被黑客入侵?这种被称为ID跳变ÿ…...

希望中国出现越来越多的张雪!!!——他很单纯,他说,人生很短,掐头去尾,就是20-30年,为何不做一些有意义的事情呢?
重庆张雪机车工业有限公司(Chongqing Zhangxue Machinery Industry Co., Ltd.),简称:张雪机车,由成立于2024年4月2日,总部位于重庆市两江新区 [1],由张雪创立 [5],是一家主营集摩托车整车生产制造和销售服务的有限责任公司。法定代表人张雪。 [1] 2024年7月,张雪机车…...

Jenkins使用手册
前提是Jenkins已经部署好在服务器上了,这个手册适用于Jenkins建一个新项目档案点击New Item创建一个新的项目档案点击ok后进入以下配置页面建议勾选第一个选项 Discard builds其他选项的含义这就是让 Jenkins 知道“去哪里拿代码”的核心关卡。去git还是svn厂库去拉…...

2026年4月OpenClaw部署方法:本地服务器部署OpenClaw、配置百炼APIKey、集成Skill详细教程
2026年4月OpenClaw部署方法:本地服务器部署OpenClaw、配置百炼APIKey、集成Skill详细教程。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉&#x…...

内网渗透零基础入门教程!小白也能轻松搞懂内网渗透基础知识点
内网渗透初探 | 小白简单学习内网渗透 0x01 基础知识 内网渗透,从字面上理解便是对目标服务器所在内网进行渗透并最终获取域控权限的一种渗透。内网渗透的前提需要获取一个Webshell,可以是低权限的Webshell,因为可以通过提权获取高权限。 …...
)
Vitis 2021.1下,手把手教你为Xilinx LWIP库适配国产YT8511以太网芯片(附完整代码)
Vitis 2021.1环境下国产YT8511以太网芯片与Xilinx LWIP库的深度适配指南 当Artix-7 FPGA遇上国产PHY芯片,开发者常常面临官方驱动不兼容的困境。本文将彻底解决Vitis 2021.1环境中LWIP库对YT8511的适配问题,提供从寄存器配置到代码移植的全套方案。 1. 环…...

OpenClaw+千问3.5-9B:自动化周报生成与数据分析
OpenClaw千问3.5-9B:自动化周报生成与数据分析 1. 为什么需要自动化周报 每周五下午三点,我的日历总会准时弹出提醒:"该写周报了"。这个重复了三年多的机械动作,消耗了我大量本该用于创造性工作的时间。直到上个月&am…...

Kubernetes集群快速搭建指南
Kubernetes集群快速搭建指南 引言:Kubernetes的时代 哥们,别整那些花里胡哨的!作为一个前端开发兼摇滚鼓手,我最烦的就是复杂的环境搭建。但Kubernetes作为云原生时代的基础设施,你不得不掌握它。今天,我就…...

接cst-matlab自动化建模,cst天线/超表面数据集自动化计算和收集,提供建模代码
接cst-matlab自动化建模,cst天线/超表面数据集自动化计算和收集,提供建模代码,提供数据集数据CST和MATLAB这对组合最近被我玩出花了。搞天线设计的朋友应该都懂,手动建模调参简直是精神折磨——尤其是超表面这种动辄几十个单元的结…...