NeRF神经辐射场渲染过程详解,三维重建渲染过程基本原理_光线采样sample_pdf()和光线渲染render_rays ()代码详解
目录
1 神经辐射场
1.1 基本原理
1.2 基本流程
1.3 数学解释
2 三维场景图像渲染详解
2.1射线采样
2.2 NeRF 模型预测
2.3 体积渲染
3 采样与渲染代码详解 (rending.py)
3.1 神经体积渲染代码解析
3.2 sample_pdf 函数
3.3 render_rays 函数
1 神经辐射场
神经辐射场(Neural Radiance Fields,NeRF)是一种用于生成三维场景的方法,其核心概念是使用神经网络来学习场景中光线的辐射属性。NeRF 通过学习场景中密度和颜色随着光线方向的变化而变化的函数来实现。
1.1 基本原理
NeRF 试图学习将三维场景中每个点(或每个空间方向)处的颜色和密度映射到对应的 RGB 颜色值和密度值。NeRF 假设场景中的辐射函数(radiance function)是光线方向的连续函数,它描述了从特定方向观察场景时,光线的颜色和密度如何随着距离而变化。
1.2 基本流程
-
场景表示: NeRF用场景中的点来表示三维物体。每个点包括其三维位置(空间坐标)和对应的颜色。而场景中的每个点都对应于射线空间的采样点,即相机到场景中某一点的射线上的所有采样点。
-
神经网络建模: NeRF使用神经网络来表示场景中的辐射场,将这个场景建模为一个密集的、连续的辐射场。这个场景可以被看作是一个从空间坐标到颜色和密度的函数映射。
-
采样和渲染: NeRF利用相机射线对场景进行采样,即对射线上的点进行密集采样。通过神经网络,为每个采样点估计其颜色和密度。这些信息被用于计算渲染图像时,即从相机视点沿射线渲染的过程。
1.3 数学解释
-
场景表示: NeRF将场景表示为一个由空间坐标 �x 到颜色和密度的函数映射,即 f:x→(C(x),σ(x)),其中C(x) 表示颜色,σ(x) 表示密度。对于一个场景中的点 x,这个函数会返回该点的颜色和密度。
-
辐射场建模: NeRF采用了一个深度神经网络,这个网络被称为 NeRF。这个网络输入场景中的点 x,输出其颜色和密度。这种函数表示法是一个用于密集、连续辐射场的表示。这个神经网络采用了 MLP(多层感知器)的结构。
-
采样和渲染: 对于每个相机射线上的点 x,NeRF会对其进行密集采样,获得该点的颜色和密度估计值。这些估计值被用于渲染图像,计算从相机视点沿射线到达的颜色值。通过对采样点进行体积渲染和光线投射,得到了最终的渲染图像。
总的来说,NeRF利用神经网络对场景中的辐射场进行建模,然后对相机射线进行采样和渲染,以生成逼真的三维场景渲染图像。
2 三维场景图像渲染详解
2.1射线采样
对于每个像素,NeRF会沿着相机视点到场景中的某一点的射线进行采样。这些采样点代表了相机到场景中特定点的视线路径。
射线表示:对于每个像素 (i,j),相机位置为 o,在图像平面上的点到场景中的某一点 p 的射线由其方向向量 d=normalize(p−o) 表示。这个射线由射线的原点 o 和方向 d 表示。
NeRF 在每个像素处发出一条射线,从相机通过像素位置发出。这些光线在场景中传播,并与场景中的物体相交。每条光线由其起点和方向向量定义。
采样点:每条射线由一系列采样点组成,这些采样点位于射线上,表示为 x=o+t⋅d,其中 t 为射线方向上的距离。
对于每条光线,NeRF 需要在其路径上进行均匀的样本点采样。采样点通常在光线路径的连续空间中,比如在光线上等距离采样或根据场景深度进行采样。
2.2 NeRF 模型预测
对于每个采样点,NeRF 模型给出了该点的颜色和密度估计值。
- NeRF 函数:场景中的每个点 x 都对应着颜色 C(x) 和密度σ(x)。这些值由神经网络表示的函数预测得出。
在每个采样点,NeRF 的神经网络会根据该点的三维位置 x 来预测两个关键参数:颜色值 C(x) 和密度值 σ(x)。
这个预测是由观察光线经过该点处的场景属性得出的,这包括光线经过的位置 x 以及光线的方向。
颜色和密度预测:沿着光线的采样点预测颜色和密度,神经网络输出颜色和密度值。
2.3 体积渲染
NeRF 使用采样点的颜色和密度估计值进行体积渲染,计算最终的像素值。
-
体积渲染方程:对于每个像素(i,j),体积渲染方程是一个积分,表示了从相机视点沿着射线看到的颜色值。
-
这里,C 是颜色值,σ 是密度,δt 是采样点之间的距离,T 是射线长度。这个方程基于体积渲染的基本原理,根据颜色和密度的累积,计算出最终的颜色值。
-
NeRF 使用渲染方程进行体积渲染(Volume Rendering)。渲染方程描述了沿光线的传播,考虑了光线传播路径上的各个采样点的颜色和密度,以估算最终的像素颜色值。
-
NeRF 通过沿光线对预测的颜色值 C(x) 和密度值 σ(x) 进行蒙特卡洛积分来近似渲染方程。这个积分的结果将近似光线路径上所有采样点的光线传播和场景颜色的影响。
-
-
权重计算:NeRF 根据颜色和密度估计值计算每个采样点的权重。权重表示了沿着射线的能量传输情况。
-
颜色积分:NeRF 将每个采样点的颜色和权重进行积分,然后加权求和,得出了最终的像素颜色值。
总结:基于颜色和密度值,NeRF 使用体积渲染方程进行积分,计算最终的像素颜色值。这个过程类似于光线追踪中的反射和折射计算,但是是通过神经网络来近似和预测。
3 采样与渲染代码详解 (rending.py)
3.1 神经体积渲染代码解析
rending.py 主要用于神经体积渲染(NeRF)方面的工作。它实现了光线在空间中的渲染和采样,结合了深度学习模型和光线投射技术,用于从数据中合成逼真的三维场景。代码主要包含两个主要函数:
sample_pdf函数用于根据权重(weights)的分布从 bins 中采样 N_importance 个样本。此函数用于在体积渲染中对rending.py光线采样进行处理。
render_rays函数是执行光线渲染的主函数。它接受NeRF模型、嵌入模型、光线的起始点和方向等参数,然后执行光线的采样、模型推断和体积渲染。
这些函数涉及到的主要步骤包括:
- 解析光线的起始点和方向。
- 在深度空间或视差空间中对光线进行采样。
- 调用
inference函数,该函数执行模型推断,获取 RGB 和原始 sigma 等值。 - 使用体积渲染算法对这些值进行处理,计算光线的颜色和深度。
- 如果需要精细模型的采样,还会对精细模型进行类似的操作。
3.2 sample_pdf () 光线采样
- 这个函数从 bins 和 weights 中根据给定的分布,抽取 N_importance 个样本。
- 参数 bins 是射线的采样点(N_rays, N_samples_+1),其中 N_samples_ 是每条射线的粗略样本数减去 2。
- 参数 weights 是权重(N_rays, N_samples_)。
- 函数首先计算归一化的概率密度函数(PDF),然后计算累积分布函数(CDF),用于采样。
- 如果是确定性采样(det=True),则等间隔采样 N_importance 个点;否则在 [0, 1] 范围内随机采样。
- 通过 CDF 和随机数采样的结果得到实际采样的位置 samples。
def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):"""从 @weights 定义的分布中采样 @N_importance 个样本。输入:bins: 形状为 (N_rays, N_samples_+1),其中 N_samples_ 是“每条射线的粗糙样本数 - 2”weights: 形状为 (N_rays, N_samples_)N_importance: 从分布中抽取的样本数量det: 是否确定性采样eps: 用于防止除以零的小数值输出:samples: 采样的样本"""N_rays, N_samples_ = weights.shapeweights = weights + eps # 防止除零错误(不要进行就地操作!)pdf = weights / reduce(weights, 'n1 n2 -> n1 1', 'sum') # 形成概率密度函数 (N_rays, N_samples_)cdf = torch.cumsum(pdf, -1) # 累积分布函数 (N_rays, N_samples),累积概率cdf = torch.cat([torch.zeros_like(cdf[:, :1]), cdf], -1) # (N_rays, N_samples_+1),填充至 0~1 区间if det:u = torch.linspace(0, 1, N_importance, device=bins.device)u = u.expand(N_rays, N_importance)else:u = torch.rand(N_rays, N_importance, device=bins.device)u = u.contiguous()inds = torch.searchsorted(cdf, u, right=True)below = torch.clamp_min(inds - 1, 0)above = torch.clamp_max(inds, N_samples_)inds_sampled = rearrange(torch.stack([below, above], -1), 'n1 n2 c -> n1 (n2 c)', c=2)cdf_g = rearrange(torch.gather(cdf, 1, inds_sampled), 'n1 (n2 c) -> n1 n2 c', c=2)bins_g = rearrange(torch.gather(bins, 1, inds_sampled), 'n1 (n2 c) -> n1 n2 c', c=2)denom = cdf_g[..., 1] - cdf_g[..., 0]denom[denom < eps] = 1 # 如果 denom 为 0,表示某个区间的权重为 0,不会被采样,因此可以将其设为任何值(此处设为 1)samples = bins_g[..., 0] + (u - cdf_g[..., 0]) / denom * (bins_g[..., 1] - bins_g[..., 0])return samples
输入参数解释:
bins: 形状为 (N_rays, N_samples_+1),描述了采样区间的边界。weights: 形状为 (N_rays, N_samples_),表示每个区间的权重值。N_importance: 要从分布中抽取的样本数量。det: 布尔值,确定是否进行确定性采样。eps: 用于防止除零错误的小数值。步骤:
a. 对权重值应用一个微小的修正(eps),以防止权重为零导致的除零错误。
b. 通过对权重值进行归一化,生成概率密度函数(PDF)。这是通过将权重值除以所有权重值的总和得到的。
c. 计算累积分布函数(CDF),将概率密度函数进行累积求和,得到每个区间的累积概率。
d. 生成均匀分布的随机数 u,以便对每条光线进行重要性采样。根据
det的取值,选择确定性采样或随机采样。e. 根据生成的随机数 u,在累积分布函数中寻找对应的位置。这是通过
torch.searchsorted函数实现的。f. 确定采样点所在的区间。根据得到的索引,选择下界和上界的采样点,以便进行线性插值采样。
g. 计算采样点的位置。通过线性插值,从区间的边界值中计算出采样点的实际位置。
h. 返回生成的样本。
这段代码主要用于神经渲染中对概率分布进行采样,以获取重要的样本点,以便更准确地估算光线在场景中的传播和颜色变化。
3.3 render_rays()光线渲染
- 这个函数执行渲染操作,将给定的射线渲染成图像。
- 参数 models 是 NeRF 模型字典(粗糙和细致模型)。
- 参数 embeddings 是原点和方向的嵌入模型字典。
- 参数 rays 是射线的起始点和方向。
- 参数 ts 是射线时间作为嵌入索引。
- N_samples 是每条射线的粗略样本数。
- use_disp 表示是否在视差空间中采样。
- perturb 是对粗糙模型射线采样位置的扰动因子。
- noise_std 是扰动模型 sigma 预测的因子。
- N_importance 是每条射线的细致样本数。
- chunk 是批处理推断中的块大小。
- white_back 表示背景颜色是否为白色。
- test_time 表示是否为测试(只进行推断)。
- 函数输出结果存储在 result 字典中,包含粗糙模型和细致模型的最终 RGB 和深度图。
def render_rays(models,embeddings,rays,ts,N_samples=64,use_disp=False,perturb=0,noise_std=1,N_importance=0,chunk=1024*32,white_back=False,test_time=False,**kwargs):"""渲染光线,通过对 @model 应用在 @rays 和 @ts 上计算输出Inputs:models: 在 nerf.py 中定义的 NeRF 模型的字典(粗糙模型和精细模型)embeddings: 在 nerf.py 中定义的原点和方向嵌入模型的字典rays: (N_rays, 3+3),光线的起始点和方向ts: (N_rays),作为嵌入索引的光线时间N_samples: 每条光线的粗糙采样数量use_disp: 是否在视差空间(逆深度)中采样perturb: 对光线上采样位置的扰动因子(仅适用于粗糙模型)noise_std: 扰动模型预测 sigma 的因子N_importance: 每条光线的精细采样数量chunk: 批量推断的块大小white_back: 背景是否为白色(依赖于数据集)test_time: 是否为测试(仅推断),如果为 True,将不进行粗糙 RGB 的推断以节省时间Outputs:result: 包含粗糙模型和精细模型的最终 RGB 和深度图的字典"""def inference(results, model, xyz, z_vals, test_time=False, **kwargs):"""辅助函数,执行模型推断Inputs:results: 存储所有结果的字典model: NeRF 模型(粗糙或精细)xyz: (N_rays, N_samples_, 3) 采样位置N_samples_ 是每条光线上采样点的数量;对于粗糙模型,N_samples_ = N_samples对于精细模型,N_samples_ = N_samples + N_importancez_vals: (N_rays, N_samples_) 采样位置的深度test_time: 是否为测试时间"""typ = model.typN_samples_ = xyz.shape[1]xyz_ = rearrange(xyz, 'n1 n2 c -> (n1 n2) c', c=3)# 执行模型推断以获取 RGB 和原始 sigmaB = xyz_.shape[0]out_chunks = []if typ == 'coarse' and test_time:for i in range(0, B, chunk):xyz_embedded = embedding_xyz(xyz_[i:i+chunk])out_chunks += [model(xyz_embedded, sigma_only=True)]out = torch.cat(out_chunks, 0)static_sigmas = rearrange(out, '(n1 n2) 1 -> n1 n2', n1=N_rays, n2=N_samples_)else: # 推断 RGB、sigma 和其他值dir_embedded_ = repeat(dir_embedded, 'n1 c -> (n1 n2) c', n2=N_samples_)# 创建其他必要的输入if model.encode_appearance:a_embedded_ = repeat(a_embedded, 'n1 c -> (n1 n2) c', n2=N_samples_)if model.encode_random:a_embedded_random_ = repeat(a_embedded_random, 'n1 c -> (n1 n2) c', n2=N_samples_)for i in range(0, B, chunk):# 原始 NeRF 的输入inputs = [embedding_xyz(xyz_[i:i+chunk]), dir_embedded_[i:i+chunk]]# NeRF-W 的额外输入if model.encode_appearance:inputs += [a_embedded_[i:i+chunk]]if model.encode_random:inputs += [a_embedded_random_[i:i+chunk]]out_chunks += [model(torch.cat(inputs, 1), output_random=output_random)]out = torch.cat(out_chunks, 0)out = rearrange(out, '(n1 n2) c -> n1 n2 c', n1=N_rays, n2=N_samples_)static_rgbs = out[..., :3] # (N_rays, N_samples_, 3)static_sigmas = out[..., 3] # (N_rays, N_samples_)################################################################if output_random:static_rgbs_random = out[..., 4:]################################################################# 使用体积渲染转换这些值deltas = z_vals[:, 1:] - z_vals[:, :-1] # (N_rays, N_samples_-1)delta_inf = 1e2 * torch.ones_like(deltas[:, :1]) # (N_rays, 1) 最后一个 delta 是无穷大deltas = torch.cat([deltas, delta_inf], -1) # (N_rays, N_samples_)noise = torch.randn_like(static_sigmas) * noise_stdalphas = 1 - torch.exp(-deltas * torch.relu(static_sigmas + noise))alphas_shifted = torch.cat([torch.ones_like(alphas[:, :1]), 1 - alphas], -1) # [1, 1-a1, 1-a2, ...]transmittance = torch.cumprod(alphas_shifted[:, :-1], -1) # [1, 1-a1, (1-a1)(1-a2), ...]weights = alphas * transmittanceweights_sum = reduce(weights, 'n1 n2 -> n1', 'sum')results[f'weights_{typ}'] = weightsresults[f'opacity_{typ}'] = weights_sumif test_time and typ == 'coarse':returnrgb_map = reduce(rearrange(weights, 'n1 n2 -> n1 n2 1') * static_rgbs,'n1 n2 c -> n1 c', 'sum')if white_back:rgb_map += 1 - rearrange(weights_sum, 'n -> n 1')results[f'rgb_{typ}'] = rgb_mapif output_random:rgb_map_random = reduce(rearrange(weights, 'n1 n2 -> n1 n2 1') * static_rgbs_random,'n1 n2 c -> n1 c', 'sum')if white_back:rgb_map_random += 1 - rearrange(weights_sum, 'n -> n 1')results[f'rgb_{typ}_random'] = rgb_map_randomresults[f'depth_{typ}'] = reduce(weights * z_vals, 'n1 n2 -> n1', 'sum')returnembedding_xyz, embedding_dir = embeddings['xyz'], embeddings['dir']# 拆解输入N_rays = rays.shape[0]rays_o, rays_d = rays[:, 0:3], rays[:, 3:6] # 都是 (N_rays, 3)near, far = rays[:, 6:7], rays[:, 7:8] # 都是 (N_rays, 1)# 嵌入方向dir_embedded = embedding_dir(kwargs.get('view_dir', rays_d))rays_o = rearrange(rays_o, 'n1 c -> n1 1 c')rays_d = rearrange(rays_d, 'n1 c -> n1 1 c')# 采样深度点z_steps = torch.linspace(0, 1, N_samples, device=rays.device)if not use_disp: # 在深度空间中进行线性采样z_vals = near * (1 - z_steps) + far * z_stepselse: # 在视差空间中进行线性采样z_vals = 1 / (1 / near * (1 - z_steps) + 1 / far * z_steps)z_vals = z_vals.expand(N_rays, N_samples)if perturb > 0: # 扰动采样深度(z_vals)z_vals_mid = 0.5 * (z_vals[:, :-1] + z_vals[:, 1:]) # (N_rays, N_samples-1) 间隔中点# 获取采样点之间的间隔upper = torch.cat([z_vals_mid, z_vals[:, -1:]], -1)lower = torch.cat([z_vals[:, :1], z_vals_mid], -1)perturb_rand = perturb * torch.rand_like(z_vals)z_vals = lower + (upper - lower) * perturb_randxyz_coarse = rays_o + rays_d * rearrange(z_vals, 'n1 n2 -> n1 n2 1')results = {}output_random = Falseinference(results, models['coarse'], xyz_coarse, z_vals, test_time, **kwargs)if N_importance > 0: # 为精细模型采样点z_vals_mid = 0.5 * (z_vals[:, :-1] + z_vals[:, 1:]) # (N_rays, N_samples-1) 间隔中点z_vals_ = sample_pdf(z_vals_mid, results['weights_coarse'][:, 1:-1].detach(),N_importance, det=(perturb == 0))# detach,使得梯度不会从此处传播到 weights_coarsez_vals = torch.sort(torch.cat([z_vals, z_vals_], -1), -1)[0]xyz_fine = rays_o + rays_d * rearrange(z_vals, 'n1 n2 -> n1 n2 1')model = models['fine']if model.encode_appearance:if 'a_embedded_from_img' in kwargs:a_embedded = kwargs['a_embedded_from_img'].repeat(xyz_fine.size(0), 1)elif 'a_embedded' in kwargs:a_embedded = kwargs['a_embedded']else:a_embedded = embeddings['a'](ts)if model.encode_random:a_embedded_random = kwargs['a_embedded_random'].repeat(xyz_fine.size(0), 1)output_random = kwargs.get('output_random', True) and model.encode_randominference(results, model, xyz_fine, z_vals, test_time, **kwargs)return results
以上代码是一个用于光线追踪的函数,主要执行的是将模型应用在给定的光线和时间上,输出包含了粗糙和精细模型的最终 RGB 和深度图。
这个函数
render_rays返回一个结果字典result,包含了渲染的各种输出:
result['weights_coarse']: 粗糙模型每个采样点的权重。result['opacity_coarse']: 粗糙模型的每条光线的总透明度。result['rgb_coarse']: 粗糙模型的最终颜色图。result['depth_coarse']: 粗糙模型的深度图。如果启用了精细模型:
result['weights_fine']: 精细模型每个采样点的权重。result['opacity_fine']: 精细模型的每条光线的总透明度。result['rgb_fine']: 精细模型的最终颜色图。result['depth_fine']: 精细模型的深度图。此外,如果存在额外的随机信息输出:
result['rgb_coarse_random']: 粗糙模型的随机信息的颜色图。result['rgb_fine_random']: 精细模型的随机信息的颜色图。这些输出提供了对光线渲染过程中每个模型的计算结果。
weights表示每个采样点的权重,opacity是每条光线的总透明度,rgb包含颜色信息,而depth是渲染的深度信息。如果指定了
white_back为True,背景将被假定为白色(依赖于数据集)。这些输出对于可视化渲染结果非常有用,提供了每条光线上的颜色、透明度和深度信息,可以在场景渲染中用于后续处理和可视化。
-
函数
render_rays接收一些模型、嵌入、光线、时间、以及一些其他参数,例如N_samples、use_disp、perturb、noise_std等。这些参数会影响光线追踪的采样和推断。 -
函数中嵌套了一个名为
inference的子函数。这个子函数用于执行模型推断。它接收了模型、采样位置的坐标(xyz)、深度信息(z_vals)等参数,并根据模型类型进行推断。对于粗糙模型(typ=='coarse')在测试时间(test_time)下,只推断出sigma值。而对于其他情况,它会通过模型计算RGB、sigma以及其他值。 -
针对模型的输出,它通过体积渲染的方式进行转换,计算光线的透明度、权重等,最终得到最终的RGB图和深度值。这些结果存储在名为
results的字典中。 -
函数的其余部分用于处理输入数据,对光线、采样的深度点等进行处理和采样。
总体而言,这些函数的目标是根据给定的射线、时间和模型数据渲染出图像和深度信息。渲染是通过对射线进行采样并应用神经网络模型来获取颜色和深度信息。
相关文章:
NeRF神经辐射场渲染过程详解,三维重建渲染过程基本原理_光线采样sample_pdf()和光线渲染render_rays ()代码详解
目录 1 神经辐射场 1.1 基本原理 1.2 基本流程 1.3 数学解释 2 三维场景图像渲染详解 2.1射线采样 2.2 NeRF 模型预测 2.3 体积渲染 3 采样与渲染代码详解 (rending.py) 3.1 神经体积渲染代码解析 3.2 sample_pdf 函数 3.3 render_rays 函数 …...

Msa类处理多序列比对数据
同源搜索,多序列比对等都是常用的方式,但是有很多的软件可以实现这些同源搜索和多序列比对,但是不同的软件输出的文件格式却是不完全一致,有熟悉的FASTA格式的,也有A2M, A3M,stockholm等格式。 详细介绍: …...

ChatGPT如何管理对话历史?
问题 由于现在开始大量使用ChatGPT对话功能,认识到他在提供启发方面具有一定价值。比如昨天我问他关于一个微习惯的想法,回答的内容还是很实在,而且能够通过他的表达理解自己的问题涉及到的领域是什么。 此外,ChatGPT能够总结对话…...
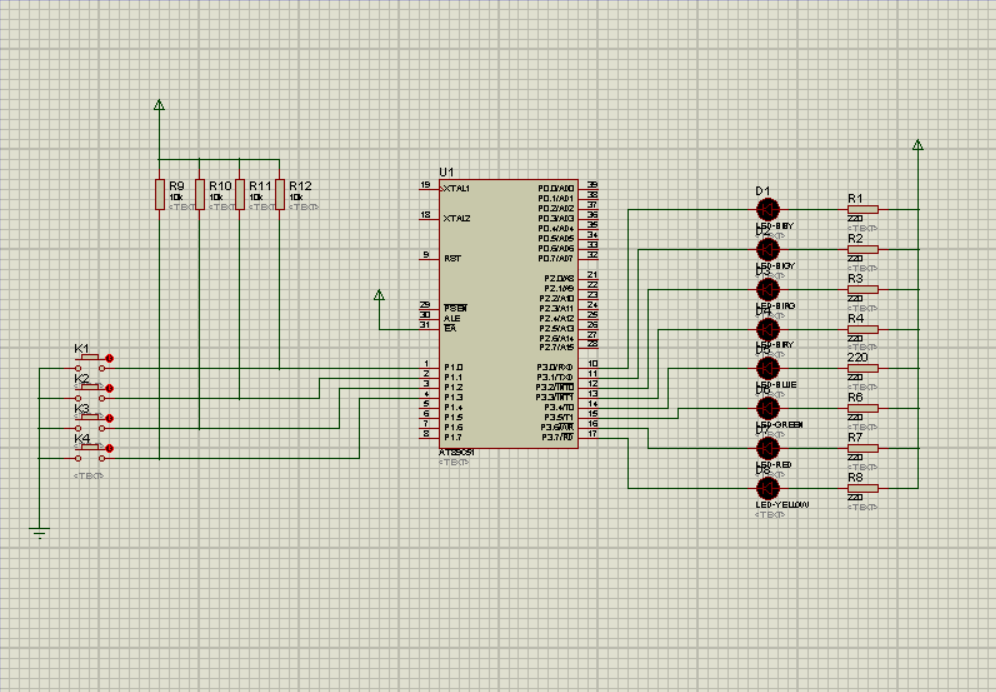
独立键盘接口设计(Keil+Proteus)
前言 软件的操作参考这篇博客。 LED数码管的静态显示与动态显示(KeilProteus)-CSDN博客https://blog.csdn.net/weixin_64066303/article/details/134101256?spm1001.2014.3001.5501实验:用4个独立按键控制8个LED指示灯。 按下k1键&#x…...
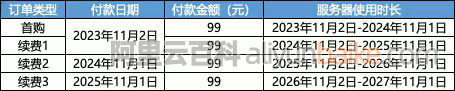
阿里云99元服务器2核2G3M带宽_4年396元_新老用户同享
阿里云99元服务器新老用户同享活动 aliyunfuwuqi.com/go/aliyun 首先要在2023年11月1日去阿里云活动页下单新购这个套餐,享受99元包1年。同天再续费1年又享受了99元包1年;等到明年2024年11月1日之后,又可以以99元续1年;最后等到20…...

数据库实验:SQL的数据控制
目录 数据控制实验目的实验内容实验要求实验过程实验内容提纲实验过程 数据控制 数据控制SQL语句(DCL)是一类可对用户数据访问权进行控制的操作语句,可以控制特定用户或角色对数据表、视图、存储过程、触发器等数据对象的访问权限。主要有GRANT、REVOKE、DENY语句操…...
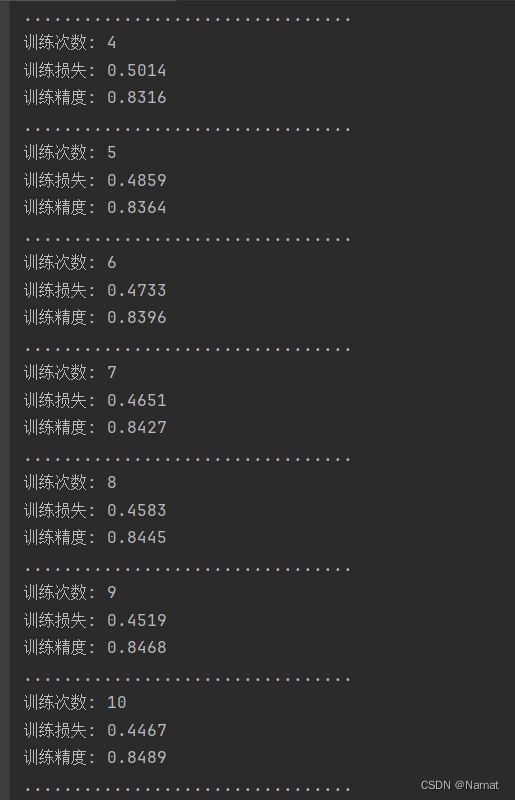
深度学习_10_softmax_实战
由于网上代码的画图功能是基于jupyter记事本,而我用的是pycham,这导致画图代码不兼容pycharm,所以删去部分代码,以便能更好的在pycharm上运行 完整代码: import torch from d2l import torch as d2l"创建训练集&创建检测集合"…...

基于SpringBoot+Vue的博物馆管理系统
基于springbootvue的博物馆信息管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 登录界面 管理员界面 用户界面 摘要 基于SpringBoot和Vue的博物馆…...
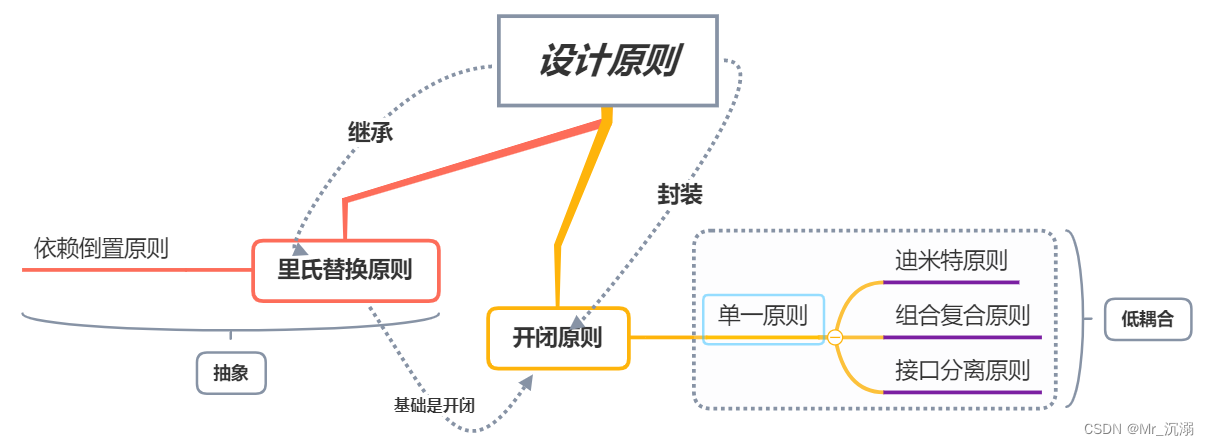
软件开发中常见的设计原则
软件开发中常见的设计原则 1. 单一责任原则2. 开放封闭原则3. 里氏替换原则4. 接口分离原则5. 依赖倒置原则6. 迪米特法则7. 合成复用原则8. 共同封闭原则9. 稳定抽象原则10. 稳定依赖原则 简写全拼中文翻译SRPThe Single Responsibility Principle单一责任原则OCPThe Open Clo…...

Linux安装ffmpeg并截取图片和视频的缩略图使用
Linux安装ffmpeg并截取图片和视频的缩略图使用 官方下载地址: http://www.ffmpeg.org/download.html#releases 我这里使用版本: ffmpeg_3.2_repo.tar.gz 可以百度网盘分享给大家 安装的环境为 Centos 64位操作系统 安装时须为 root 用户进行操作 #解压 tar -zxvf ffmpeg_3…...
)
第三章:人工智能深度学习教程-基础神经网络(第一节-ANN 和 BNN 的区别)
你有没有想过建造大脑之类的东西是什么感觉,这些东西是如何工作的,或者它们的作用是什么?让我们看看节点如何与神经元通信,以及人工神经网络和生物神经网络之间有什么区别。 1.人工神经网络:人工神经网络(…...

高防CDN与高防服务器:为什么高防服务器不能完全代替高防CDN
在当今的数字化时代,网络安全已经成为企业不容忽视的关键问题。面对不断增长的网络威胁和攻击,许多企业采取了高防措施以保护其网络和在线资产。然而,高防服务器和高防CDN是两种不同的安全解决方案,各自有其优势和局限性。在本文中…...
关于卷积神经网络的多通道
多通道输入 当输入的数据包含多个通道时,我们需要构造一个与输入通道数相同通道数的卷积核,从而能够和输入数据做卷积运算。 假设输入的形状为n∗n,通道数为ci,卷积核的形状为f∗f,此时,每一个输入通道都…...

19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

<a>标签的download属性部分浏览器无法自动识别文件后缀
问题 最近开发中遇到的问题,文件名中含有点和逗号字符,当使用a标签的download属性下载内容时,如果不指定后缀,部分浏览器无法自动识别文件后缀。如下图所示: 定义用法 download 属性定义了下载链接的地址。 href 属性…...

前端图片压缩上传,减少等待时间!优化用户体检
添加图片注释,不超过 140 字(可选) 这里有两张图片,它们表面看上去是一模一样的,但实际上各自所占用的内存大小相差了180倍。 添加图片注释,不超过 140 字(可选) 添加图片注释&…...

Ionic header content footer toolbar UI实例
1 ionic的button图标 <ion-header [translucent]"true"><ion-toolbar><ion-buttons slot"start"><ion-back-button default-href"/tabs/tab1" text"back" icon"caret-back"></ion-back-button&…...
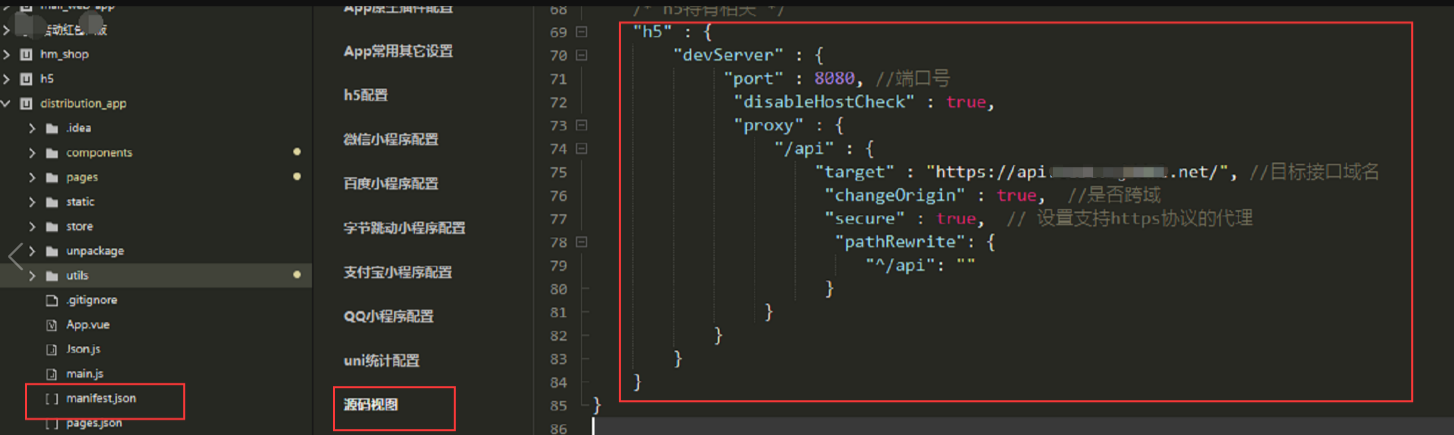
uniapp 解决H5跨域的问题
uniapp 解决h5跨域问题 manifest.json manifest.json文件中,点击“源码视图”,在此对象的最后添加以下代码: "h5" : {"devServer" : {"port" : 8080, //端口号"disableHostCheck" : true,"proxy" :…...
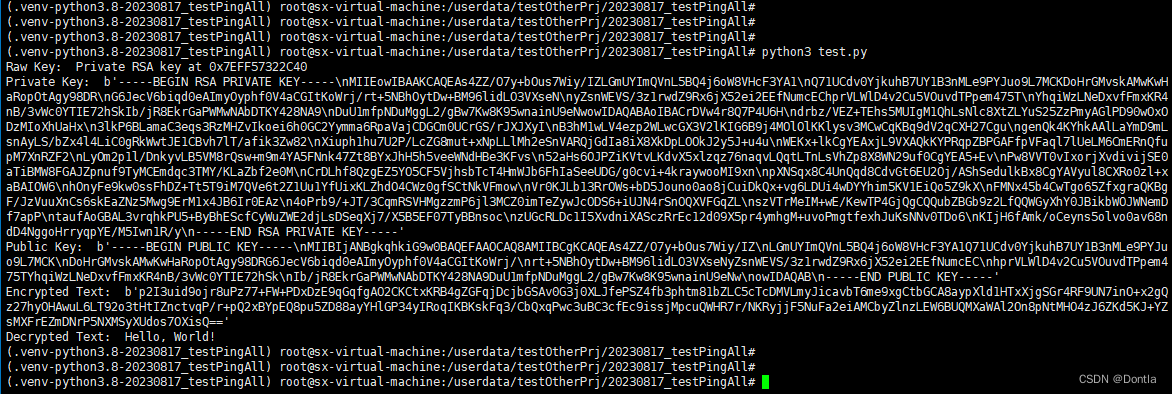
对称加密(symmetric encryption)和非对称加密(Asymmetric Encryption)(密钥、公钥加密、私钥解密)AES、RSA
文章目录 对称加密与非对称加密对称加密1.1 定义1.2 工作原理1.3 场景分析1.4 算法示例(以AES为例)1.5 对称加密的优点与缺点优点缺点 非对称加密2.1 定义2.2 工作原理注意:每次生成的RSA密钥对都会不一样 2.3 场景分析2.4 算法示例ÿ…...
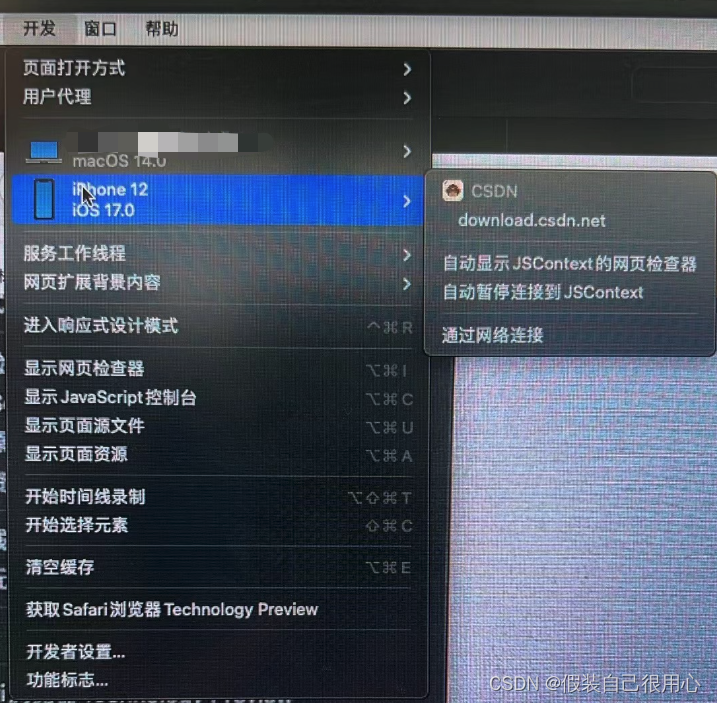
iOS 16.4 之后真机与模拟器无法使用Safari调试H5页面问题
背景 iOS 16.4之后用真机调试H5时候发现,Safari中开发模块下面无法调试页面 解决方案 在WKWebView中设置以下代码解决 if (available(iOS 16.4, *)) {[_webView setInspectable:YES];}然后再次调试就可以了...

汽车电子电气架构演进:从分布式 ECU 到中央计算平台
目录 一、电子电气架构的六大演进阶段 二、高性能处理器与软件平台重构 三、宝马分层式电子电气架构设计 四、中央通信服务器与可扩展网络 五、车云一体架构与软件开发变革 六、架构升级代码示例:SOA 服务注册与调用 七、中央计算平台配置示例(代码…...

AntimicroX:解放游戏体验的手柄映射工具,让每款游戏都支持手柄
AntimicroX:解放游戏体验的手柄映射工具,让每款游戏都支持手柄 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https:…...

FireRedASR-AED-L本地化教程:国产统信UOS/麒麟系统全兼容部署方案
FireRedASR-AED-L本地化教程:国产统信UOS/麒麟系统全兼容部署方案 提示:本教程已在统信UOS 20、麒麟V10系统完成实测验证,同样适用于Ubuntu、CentOS等Linux发行版 1. 项目简介:为什么选择这个工具? 如果你正在寻找一个…...

扩散模型技术演进三部曲:从理论奠基到产业落地的核心突破
1. 扩散模型:一场关于"破坏与重建"的技术革命 想象你正在教一个孩子画画,但用的是一种特别的方式:先给他看一张完整的画作,然后你不断地在上面涂抹修改,直到画作变成一团杂乱无章的线条。接着,你…...

别再浪费手机性能了!Blackmagic Camera 搭配 LUT 滤镜包,解锁夜景和人物拍摄的隐藏技巧
Blackmagic Camera 与 LUT 滤镜包:解锁手机摄影的隐藏潜力 手机摄影早已不再是简单的记录工具,而是可以创作出专业级影像的利器。对于追求画质的摄影爱好者和小型工作室来说,Blackmagic Camera 这款专业级拍摄应用配合精心调校的 LUT 滤镜包&…...

STM32F407 HAL库实战:TIM触发ADC+DMA实现多通道信号实时统计与可视化
1. 为什么需要TIM触发ADCDMA的多通道采集方案 在嵌入式数据采集系统中,实时性和效率往往是核心诉求。想象一下这样的场景:我们需要同时监测工业设备上的4个振动传感器,每个传感器的信号都需要以10kHz的频率采样。如果采用传统的轮询方式&…...

OpenClaw小团队协作:千问3.5-35B-A3B-FP8共享技能库搭建
OpenClaw小团队协作:千问3.5-35B-A3B-FP8共享技能库搭建 1. 为什么我们需要共享技能库 去年冬天,我们团队在尝试用OpenClaw自动化周报生成时遇到了一个典型问题——每个人都在重复造轮子。小王写了个飞书日程抓取脚本,小李开发了Git提交记录…...

OpenClaw学习助手方案:Qwen2.5-VL-7B解析教材插图生成记忆卡片
OpenClaw学习助手方案:Qwen2.5-VL-7B解析教材插图生成记忆卡片 1. 为什么需要AI辅助学习工具 去年备考专业认证时,我发现自己总在重复低效的学习循环——花大量时间手动整理教材图表中的关键数据,再誊写到Anki卡片上。这种机械劳动不仅耗时…...

湖南石材结晶公司
在长沙,无论是高端商场、星级酒店,还是政务大厅、三甲医院,光洁如镜、平整如砥的石材地面,都是其专业形象与高端质感的直接体现。然而,石材作为“面子工程”,长期承受高频人流、设备碾压,极易出…...

电路原理与人生哲学的奇妙对应关系
1. 电路与人生的奇妙映射作为一名在电子行业摸爬滚打十多年的工程师,我常常惊叹于电路原理与人生百态之间的惊人相似。记得刚入行时,我的导师就说过:"读懂电路,就读懂了人生。"当时只觉得是句玩笑话,直到这些…...