LLVM学习笔记(60)
4.4.3. X86Subtarget
在X86TargetMachine构造函数的105行调用了X86Subtarget构造函数来创建具体的目标机器对象。
4.4.3.1. FMV的支持(v7.0)
V7.0将具体目标机器对象的生成推迟到第一次调用getSubtarget ()时才创建。不过,为了方便起见,我们在这里把v7.0的实现也一起看了。在v7.0里getSubtarget ()是这样的:
122 template <typename STC> const STC &getSubtarget(const Function &F) const {
123 return *static_cast<const STC*>(getSubtargetImpl(F));
124 }
目标机器对象的创建由目标机器的getSubtargetImpl()完成。V7.0的这个改动是为了支持称为多版本函数的新特性。关于这个新特性,可以参考这个网址Function multi-versioning in GCC 6 [LWN.net],下面是它的翻译(关于LLVM有这么一篇论文)。
| CPU架构随着演进通常会获得有趣的新指令,但应用程序开发者通常发现利用这些指令是困难的。不愿意失去后向兼容是阻碍开发人员使用更新的计算架构的主要障碍之一。函数多版本化(function multi-versioning,FMV),首先出现在gcc 4.8,是拥有函数多个实现的方式,每个实现使用不同架构特定的指令集扩展。Gcc 6引入了对FMV的修改,更容易向应用程序代码引入基于架构的优化。 尽管gcc与内核的新版本尝试在平台面市前公开使用新架构特性的工具,但开发人员难以开始使用这些工具。当前,C开发者有几个选择:
通常使用新架构技术的好处足以压倒集成的挑战。例如,打开Intel先进向量扩展(AVX)会显著优化数学代码。AVX的第二个版本(AVX2),在第4代,也称为Haswell的Intel Core处理器里引入,是一个选择。在科学计算领域AVX2的好处广为人知。OpenBLAS库使用AVX2给予了像R语言这样的项目,执行上2倍的加速;它也在Python科学库里产生了显著的提高。这些性能提升是通过使用256比特指令、浮点融合乘加指令以及gather操作,使每秒浮点操作(FLOPS)加倍,获得的。 不过,使用向量扩展(VX)技术意味着大量的开发、部署以及维护性工作。维护多个版本二进制文件的想法(一个架构一个)阻止开发者以及发行版本支持这些特性。 为多个架构优化某些关键函数,当运行时二进制文件检测到CPU能力时执行它们,会更好吗?这样做的一个特性,FMV,实际上自gcc 4.8以来就存在,但仅用于C++。gcc 4.8里的FMV使得开发者容易指定一个函数的多个版本;每个针对特定目标机器指令集优化。Gcc负责创建执行函数正确版本所需的分发代码。 要在C++代码里使用FMV,用户要指定函数的多个版本。例如,在gcc 4.8 FMV文档里展示的代码: __attribute__ ((target ("sse4.2"))) int foo(){ // foo version for SSE4.2 return 1; } __attribute__ ((target ("arch=atom"))) int foo(){ // foo version for the Intel Atom processor return 2; } int main() { int (*p)() = &foo; assert((*p)() == foo()); return 0; } Target()指示将对指令集扩展(如sse4.2)或指定架构(如arch=atom)编译函数。 这里,对每个函数,开发者需要为每个目标创建特殊的函数与代码。这将要求代码里额外的开销;在FMV程序里代码行数的增加,使得它更难以管理与维护。 幸好,gcc 6解决了这个问题:它使用单个属性来定义要支持的最小架构集,在C及C++代码里支持FMV。这使得开发可以利用增强指令的Linux应用变得容易,无需为每个目标复制函数。 通过FMV来利用AVX的简单例子是使用数组加法(这个例子是array_addition.c): #define MAX 1000000 int a[256], b[256], c[256]; __attribute__((target_clones("avx2","arch=atom","default"))) void foo(){ int i,x;
for (x=0; x<MAX; x++){ for (i=0; i<256; i++){ a[i] = b[i] + c[i]; } } } int main() { foo(); return 0; } 正如我们可以看到的,使用target_clones()指示支持架构的选择是相当简单的。开发者仅需要选择架构或要支持指令集扩展的最小集:AVX2、Intel Atom、AMD或几乎任何gcc从命令行接受的架构选项。编译器将创建函数面向指定指令集的多个版本,并在运行时选择正确的版本。 最终,这个代码的object dump有对每个架构最优的汇编指令。例如: 非AVX代码(Atom): add %eax,%edx AVX: vpaddd 0x0(%rax),%xmm0,%xmm0 AVX2: vpaddd (%r9,%rax,1),%ymm0,%ymm0 注意FMV的新实现向array_addition.c提供了使用Intel AVX、AVX2甚至Atom平台的寄存器与指令的能力。这个能力增大了应用程序可以不出现非法指令错误运行的平台的范围。 在gcc 6以前,告诉编译器使用Intel AVX2指令将把二进制的兼容性限制在Haswell和更新的处理器。通过FMV里新加的特性,编译器还可以产生AVX优化的代码;在运行时,将自动确保仅使用合适的版本。换而言之,当二进制运行在Haswekk或更新的CPU上时,将使用Haswell特定的优化;当同一个二进制在前Haswell世代处理器上运行时,它将回退到使用旧处理器支持的标准指令。 CPUID选择 在gcc 4.8里,FMV有一个分发优先级,而不是一个CPUID选择。分发次序基于目标属性对每个函数版本排序。带有更先进特性的函数版本有更高的优先级。例如,面向AVX2的版本比面向SSE2的版本优先级更高。 为了保持分发的低代价,使用了间接函数(ifunc)机制。该机制是GNU工具链的一个特性,它允许开发者创建给定函数的多个实现,在运行时使用一个解析器函数在其中选择。在启动早期这个解析器函数由动态载入器调用,决定应用程序使用哪个实现。一旦做出了实现选择,就固定下来,在这个过程的生命期里不变了。 在gcc 6中,解析器检查CPUID并调用相应的函数。它对每个二进制执行文件都做一次。因此当存在对FMV函数的多个调用时,仅第一个调用会执行CPUID比较;后续调用将通过一个指针找到要求的版本。这个技术已经用于几乎所有的glibc函数。例如,glibc对每个架构都优化了memcpy(),因此当调用时,glibc将调用恰当优化的memcpy()。 代码大小影响 FMV将增加二进制代码的大小,但这个影响可以最小化。代码大小的增加依赖于应用FMV的函数有多大,以及要求版本的数量。如果最初二进制代码大小是C,N是请求的版本数(包括缺省),R是这些函数占整个应用程序代码的比例,新代码的大小将是: (1 - R) * C + R * C * N 如果一个应用程序最热代码占总大小的1%,且应用FMV支持三个架构(缺省,sse4.2,avx2),代码大小总共增加2%。在考虑今天的储存容量时,这是相当小的影响。但这种影响必须基于部署模型来考虑。性能、维护性与增加的二进制代码间存在权衡,因此对某种类型的部署FMV可能不是正确的选择(比如物联网设备)。 结果 下表展示了在不同处理器上,使用不同gcc标记运行array_addition.c的执行时间: 执行时间(ms)
FMV版本使用下面的指示: __attribute__((target_clones("avx2","arch=atom","default"))) SIGILL项表示对某些组合是非法指令。缺省的CFLAGS(不是特别值得注意),配置作为Clear Linux for Intel Architecture项目部分说明。 实例 今天,越来越多行业部门从基于云的科学计算中获益。这些部门包括化工、财务以及分析应用程序。其中一个更受欢迎的科学计算库是用于Python的NumPy库。它包括了对大的、多维数组与矩阵的支持。它还有用于线性代数、傅里叶变换以及随机数生成等等的特性。 在一个诸如NumPy的科学库里使用FMV技术的好处通常是它得到良好的理解与接受。如果没有启用向量化,SIMD寄存器里许多未用的空间浪费了。如果启用向量化,在一条指令里编译器使用额外的寄存器执行更多的操作(比如我们例子里更多整数加法)。 由于FMV技术性能的提升(运行在带有AVX2指令的Haswell机器上),对科学计算内容可以到达3%。我们使用运行在1.8GHz的Skylake系统上的OpenBenchmarking.org numpy-1.0.2,使用FMV运行时间是8400秒,而在使用-O3编译时是8600秒。 性能提升归功于从向量化受益的NumPy代码里的函数。为了检测这些函数,gcc提供了标记-fopt-info-vec。这个标记用于检测向量化候选函数。例如,以这个标记构建NumPy将告诉我们文件fftpack.c有可以使用向量化的代码: numpy/fft/fftpack.c:813:7: note: loop peeled for vectorization to enhance alignment 查看NumPy源代码显示radfg()函数,这是NumPy里支持的快速傅里叶变换的一部分,执行大量可以使用AVX优化的数组加法。NumPy的补丁还未升级,但指日可待。 |
250 const X86Subtarget *
251 X86TargetMachine::getSubtargetImpl(const Function &F) const {
252 Attribute CPUAttr = F.getFnAttribute("target-cpu");
253 Attribute FSAttr = F.getFnAttribute("target-features");
254
255 StringRef CPU = !CPUAttr.hasAttribute(Attribute::None)
256 ? CPUAttr.getValueAsString()
257 : (StringRef)TargetCPU;
258 StringRef FS = !FSAttr.hasAttribute(Attribute::None)
259 ? FSAttr.getValueAsString()
260 : (StringRef)TargetFS;
261
262 SmallString<512> Key;
263 Key.reserve(CPU.size() + FS.size());
264 Key += CPU;
265 Key += FS;
266
267 // FIXME: This is related to the code below to reset the target options,
268 // we need to know whether or not the soft float flag is set on the
269 // function before we can generate a subtarget. We also need to use
270 // it as a key for the subtarget since that can be the only difference
271 // between two functions.
272 bool SoftFloat =
273 F.getFnAttribute("use-soft-float").getValueAsString() == "true";
274 // If the soft float attribute is set on the function turn on the soft float
275 // subtarget feature.
276 if (SoftFloat)
277 Key += FS.empty() ? "+soft-float" : ",+soft-float";
278
279 // Keep track of the key width after all features are added so we can extract
280 // the feature string out later.
281 unsigned CPUFSWidth = Key.size();
282
283 // Extract prefer-vector-width attribute.
284 unsigned PreferVectorWidthOverride = 0;
285 if (F.hasFnAttribute("prefer-vector-width")) {
286 StringRef Val = F.getFnAttribute("prefer-vector-width").getValueAsString();
287 unsigned Width;
288 if (!Val.getAsInteger(0, Width)) {
289 Key += ",prefer-vector-width=";
290 Key += Val;
291 PreferVectorWidthOverride = Width;
292 }
293 }
294
295 // Extract required-vector-width attribute.
296 unsigned RequiredVectorWidth = UINT32_MAX;
297 if (F.hasFnAttribute("required-vector-width")) {
298 StringRef Val = F.getFnAttribute("required-vector-width").getValueAsString();
299 unsigned Width;
300 if (!Val.getAsInteger(0, Width)) {
301 Key += ",required-vector-width=";
302 Key += Val;
303 RequiredVectorWidth = Width;
304 }
305 }
306
307 // Extracted here so that we make sure there is backing for the StringRef. If
308 // we assigned earlier, its possible the SmallString reallocated leaving a
309 // dangling StringRef.
310 FS = Key.slice(CPU.size(), CPUFSWidth);
311
312 auto &I = SubtargetMap[Key];
313 if (!I) {
314 // This needs to be done before we create a new subtarget since any
315 // creation will depend on the TM and the code generation flags on the
316 // function that reside in TargetOptions.
317 resetTargetOptions(F);
318 I = llvm::make_unique<X86Subtarget>(TargetTriple, CPU, FS, *this,
319 Options.StackAlignmentOverride,
320 PreferVectorWidthOverride,
321 RequiredVectorWidth);
322 }
323 return I.get();
324 }
MFV需要多个目标机器可用,因此现在使用容器SubtargetMap(类型mutable StringMap<std:: unique_ptr<X86Subtarget>>)来保存多个X86Subtarget实例,键值是描述目标CPU以及各方面特性的字符串,这个字符串确保唯一。
317行的resetTargetOptions()根据当前函数的属性改写由InitTargetOptionsFromCodeGenFlags()等根据编译命令行设置的属性。
在318行创建X86Subtarget实例。
289 X86Subtarget::X86Subtarget(const Triple &TT, const std::string &CPU,
290 const std::string &FS, const X86TargetMachine &TM,
291 unsigned StackAlignOverride)
292 : X86GenSubtargetInfo(TT, CPU, FS), X86ProcFamily(Others),
293 PICStyle(PICStyles::None), TargetTriple(TT),
294 StackAlignOverride(StackAlignOverride),
295 In64BitMode(TargetTriple.getArch() == Triple::x86_64),
296 In32BitMode(TargetTriple.getArch() == Triple::x86 &&
297 TargetTriple.getEnvironment() != Triple::CODE16),
298 In16BitMode(TargetTriple.getArch() == Triple::x86 &&
299 TargetTriple.getEnvironment() == Triple::CODE16),
300 TSInfo(), InstrInfo(initializeSubtargetDependencies(CPU, FS)),
301 TLInfo(TM, *this), FrameLowering(*this, getStackAlignment()) {
302 // Determine the PICStyle based on the target selected.
303 if (TM.getRelocationModel() == Reloc::Static !isPositionIndependent()) {
304 // Unless we're in PIC or DynamicNoPIC mode, set the PIC style to None.
305 setPICStyle(PICStyles::None);
306 } else if (is64Bit()) {
307 // PIC in 64 bit mode is always rip-rel.
308 setPICStyle(PICStyles::RIPRel);
309 } else if (isTargetCOFF()) {
310 setPICStyle(PICStyles::None);
311 } else if (isTargetDarwin()) {
312 if (TM.getRelocationModel() == Reloc::PIC_) ß v7.0删除
313 setPICStyle(PICStyles::StubPIC);
314 else {
315 assert(TM.getRelocationModel() == Reloc::DynamicNoPIC);
316 setPICStyle(PICStyles::StubDynamicNoPIC);
317 }
318 } else if (isTargetELF()) {
319 setPICStyle(PICStyles::GOT);
320 }
CallLoweringInfo.reset(new X86CallLowering(*getTargetLowering())); ß v7.0增加
Legalizer.reset(new X86LegalizerInfo(*this, TM));
auto *RBI = new X86RegisterBankInfo(*getRegisterInfo());
RegBankInfo.reset(RBI);
InstSelector.reset(createX86InstructionSelector(TM, *this, *RBI));
321 }
基类X86GenSubtargetInfo的构造函数是TableGen生成的,前面我们已经看到,它将MC层的一组指针指向X86目标机器特定的参数。300行的成员TSInfo的类型是X86SelectionDAGInfo,目标机器通过它可以提供对memcpy、memmove、memset、memcmp、memchr、strcpy、strcmp、strlen,这些操作的专属处理代码(v7.0删除这个调用)。
303行的isPositionIndependent()检查使用的重定位模型是否为Reloc::PIC_,这些重定位模型用于动态库的生成。V7.0简化为这几种:StubPIC(i386-darwin的pic),GOT(全局对象表,32位elf的pic),RIPRel(相对RIP,64位elf的pic),None(没有使用pic)。位置无关代码参考有关资料(如《C++高级编译》)。
相关文章:
)
LLVM学习笔记(60)
4.4.3. X86Subtarget 在X86TargetMachine构造函数的105行调用了X86Subtarget构造函数来创建具体的目标机器对象。 4.4.3.1. FMV的支持(v7.0) V7.0将具体目标机器对象的生成推迟到第一次调用getSubtarget ()时才创建。不过,为了方便起见&am…...

Linux命令查看pcap包报文数量、包体包含内容、包长
查看pcap包内容 要查看pcap文件中的包数量,可以使用网络分析工具,如Wireshark或Tcpdump,或者使用编程语言中的网络分析库,如Python中的Scapy或Sniffy。 使用Wireshark的方法如下: 打开Wireshark软件。选择要查看的p…...

C++二分算法: 找出第 K 小的数对距离
题目 数对 (a,b) 由整数 a 和 b 组成,其数对距离定义为 a 和 b 的绝对差值。 给你一个整数数组 nums 和一个整数 k ,数对由 nums[i] 和 nums[j] 组成且满足 0 < i < j < nums.length 。返回 所有数对距离中 第 k 小的数对距离。 示例 1&#x…...
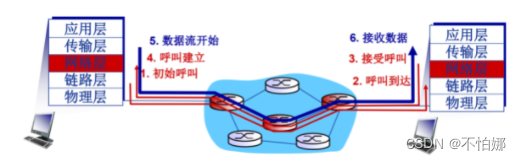
【计算机网络笔记】网络层服务模型——虚电路网络
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...
软文推广过程中,如何精准定位受众
互联网发展带来信息的爆炸式增长,消费者的注意力成为稀缺资源,传统硬广很难获取用户注意,而软文凭借故事化、针对性的特点更能吸引用户注意,在软文推广中,我们只有精准定位受众才能更好地传播,今天媒介盒子…...
说说对React中类组件和函数组件的理解?有什么区别?
一、类组件 类组件,顾名思义,也就是通过使用ES6类的编写形式去编写组件,该类必须继承React.Component 如果想要访问父组件传递过来的参数,可通过this.props的方式去访问 在组件中必须实现render方法,在return中返回…...

Unity 实例化物体以及赋予到父物体之下
Unity 实例化物体并赋予父物体操作如下: public class ExampleScript : MonoBehaviour { public GameObject prefab; // 引用预制体 public Transform parentTran; // 引用父物体的 Transform void Update() { if (Input.GetKeyDown(KeyCode.Space)) { //…...
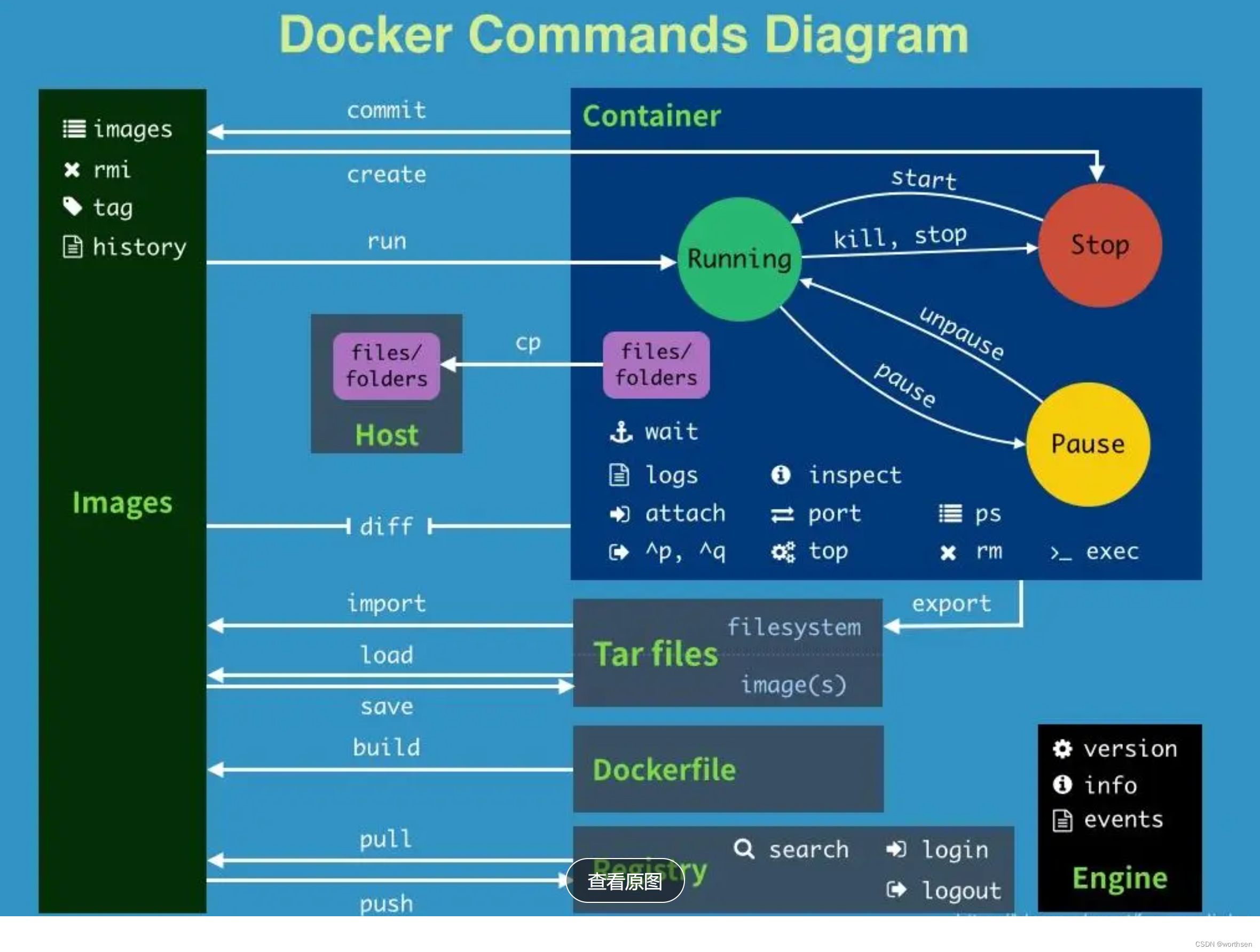
Docker 介绍
Docker 介绍 1 介绍1.1 概述1.2 资源高效利用1.3 发展历程1.4 组件1.5 工具1.6 对环境部署和虚拟化的影响1.7 优点1.8 容器技术核心CgroupNamespaceUnionFS 2 命令信息、状态、配置info命令用于显示当前系统信息、docker容器、镜像个数、设置等信息 镜像容器资源 3 安装3.1 版本…...
VScode连接Xshell 并解决【过程试图写入的管道不存在】报错
一.下载vscode 国内镜像: https://vscode.cdn.azure.cn/stable/6c3e3dba23e8fadc360aed75ce363ba185c49794/VSCodeUserSetup-x64-1.81.1.exe二.打开vscode在扩展搜索SSH并安装 三.添加主机 按F1选择添加新的ssh主机 按格式输入后在左边会出现电视的图标 之后输入…...

Redis之事务
文章目录 前言一、概述二、Redis事务使用1.正常执行事务2.取消事务3.编译型异常4.运行时异常(1/0)5.清空数据库6.监控1.乐观锁正常执行成功2.多线程 总结 前言 Redis事务本质:一组命令的集合!一个事务中的所有命令都会被序列化&a…...

【数据结构】树与二叉树(五):二叉树的顺序存储(初始化,插入结点,获取父节点、左右子节点等)
文章目录 5.1 树的基本概念5.1.1 树的定义5.1.2 森林的定义5.1.3 树的术语5.1.4 树的表示 5.2 二叉树5.2.1 二叉树1. 定义2. 特点3. 性质引理5.1:二叉树中层数为i的结点至多有 2 i 2^i 2i个,其中 i ≥ 0 i \geq 0 i≥0。引理5.2:高度为k的二叉…...
【HarmonyOS】HarmonyOS备案获取公钥和指纹
【关键字】 HarmonyOS应用、鸿蒙应用、元服务、应用备案 HarmonyOS应用在华为云等平台进行应用备案时,平台需要提供用公钥和签名指纹的信息,Android可以直接通过keystore或jks签名文件进行签名信息获取,HarmonyOS签名方式与Android不同&…...
,多数据源+Mybatisplus + Sharding JDBC同一库中分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中,多数据源采用 mybatis-plus的dynamic-datasource 分库分表采用sharding-jdbc 数据库连接池管理是alibaba的druid-spring-boot-starter 同一个数据库内分表 目录 1.数据库表 2.配置 3.引入的…...
Docsify 和 Hugo 之间的选型
对文档的编译,目前的发布方案是越来越注重 MD 的编辑和发布。 针对其他 Wiki 的选择,MD 文件的编辑通常会保留修改记录,同时不依赖中央数据库和其他类型的 Web 应用服务。 随着各大云平台的支持,包括 GitHub Page 和 Google 的 …...

第二十章 ObjectScript 应用程序中的数值计算 - 转换:十进制到 $DOUBLE
文章目录 第二十章 ObjectScript 应用程序中的数值计算 - 转换:十进制到 $DOUBLE 转换:十进制到 $DOUBLE转换:$DOUBLE 到十进制$DECIMAL(x)$DECIMAL(x, n) 转换:十进制到字符串 第二十章 ObjectScript 应用程序中的数值计算 - 转…...
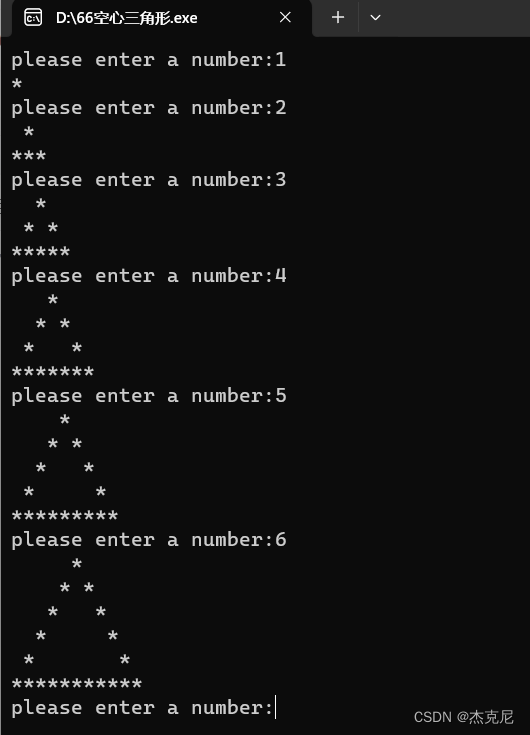
C语言【趣编程】我们怎样便捷输出空心的金字塔
目录 1问题: 2解题思路: 3代码如下: 4代码运行结果如下图所示: 5总结: r如若后续有不会的问题,可以和我私聊; 1问题: 2解题思路: 方法:找规律࿰…...

《JavaScript设计模式》笔记 - - - 超全设计模式概览
该篇文章用于记录阅读《JavaScript设计模式》后归纳的读书笔记,主要以代码形式进行展示,用于快速回顾对应设计模式的代码构造 1.面向对象编程 1.使用对象收编变量 优点:避免全局变量冲突与覆盖 缺点:不利于复用 var CheckObj {c…...

浅谈Vue 3的响应式对象: ref和reactive
Vue 3是一个流行的前端框架,它引入了一些新的特性来提高开发者的体验和性能。其中,响应式对象是 Vue 3 中一个非常重要的概念。在这篇博客中,我们将重点介绍 Vue 3 中的响应式对象,并深入探讨其中的 ref 和 reactive。 引言 在现…...
怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载
怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的…...

Alphago Zero的原理及实现:Mastering the game of Go without human knowledge
近年来强化学习算法广泛应用于游戏对抗上,通用的强化学习模型一般包含了Actor模型和Critic模型,其中Actor模型根据状态生成下一步动作,而Critic模型估计状态的价值,这两个模型通过相互迭代训练(该过程称为Generalized …...

终极指南:如何用HMCL启动器轻松管理你的Minecraft游戏世界
终极指南:如何用HMCL启动器轻松管理你的Minecraft游戏世界 【免费下载链接】HMCL A Minecraft Launcher which is multi-functional, cross-platform and popular 项目地址: https://gitcode.com/gh_mirrors/hm/HMCL HMCL(Hello Minecraft! Launc…...
)
实测雷达数据处理避坑:用MATLAB手把手教你计算信噪比(附代码与数据)
雷达数据处理实战:信噪比计算中的关键陷阱与MATLAB解决方案 雷达信号处理中,信噪比(SNR)是评估系统性能的核心指标之一。但看似简单的功率比值计算,在实际操作中却暗藏诸多陷阱。本文将从一个工程师的实际项目复盘视角,剖析雷达数…...
)
CMake死活找不到OpenCV?别急着重装,先试试这几招(附Windows/Linux/Mac通用解法)
CMake死活找不到OpenCV?别急着重装,先试试这几招(附Windows/Linux/Mac通用解法) 当你满心欢喜地在CMakeLists.txt中写下find_package(OpenCV REQUIRED),准备开始一个酷炫的计算机视觉项目时,突然蹦出的&quo…...

5分钟搞定 小龙虾 AI OpenClaw v2.6.6 一键安装|办公自动化神器
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置【含最新安装包】 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万 ,凭借本地运行 零代码操作 …...

品牌护城河:在信任稀缺的时代,农业品牌如何赢得人心
在消费升级和食品安全意识日益增强的今天,消费者对农产品和农资产品的品牌信任,正在变得越来越稀缺,也越来越珍贵。营养土行业便是这一趋势的典型写照。过去几年里,我们见证了一些品牌的迅速崛起——它们依靠低价和流量打法&#…...

如何用The Super Tiny Compiler掌握作用域与符号表管理:完整指南
如何用The Super Tiny Compiler掌握作用域与符号表管理:完整指南 【免费下载链接】the-super-tiny-compiler :snowman: Possibly the smallest compiler ever 项目地址: https://gitcode.com/gh_mirrors/th/the-super-tiny-compiler The Super Tiny Compiler…...

终极指南:os-tutorial引导加载器与二级引导程序深度解析
终极指南:os-tutorial引导加载器与二级引导程序深度解析 【免费下载链接】os-tutorial How to create an OS from scratch 项目地址: https://gitcode.com/gh_mirrors/os/os-tutorial os-tutorial是一个从零开始创建操作系统的开源项目,本文将深入…...

SD-PPP插件架构解析:Photoshop与AI绘图平台的无缝集成技术实现
SD-PPP插件架构解析:Photoshop与AI绘图平台的无缝集成技术实现 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP作为一款革命性的Photoshop AI插件,通过创新的架构设计实现了Adobe Pho…...

【含最新安装包】OpenClaw 保姆级实操教学,零基础一键部署即开即用
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置【点击下载最新安装包】 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万 ,凭借本地运行 零代码…...

Source Han Serif CN:企业级字体架构设计与技术决策框架
Source Han Serif CN:企业级字体架构设计与技术决策框架 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 中文字体技术栈的现代化挑战与架构演进 在数字化转型浪潮中&#…...