MongoDB基础知识~
引入MongoDB:
在面对高并发,高效率存储和访问,高扩展性和高可用性等的需求下,我们之前所学习过的关系型数据库(MySql,sql server…)显得有点力不从心,而这些需求在我们的生活中也是随处可见的,例如在社交中,使用它存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人,地点等功能。在游戏中,使用它存储游戏用户信息,用户的装备,积分等直接以内嵌文档的形式存储,方便查询,高效率存储和访问。还有我们熟悉的物流,使用它存储订单信息,订单状态在运送过程中会不断的更新,以内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来等等。这些场景中,数据操作都有共同的特点,数据量大,读写操作频繁,价值较低的数据(对事务性要求不高),对于这样的数据,我们更适合使用MongoDB去实现存储。
如何理解事务性要求不高?
事务性要求不高的意思是指对于一项任务或工作,对其完成的准确性、完整性和一致性的要求相对较低。这意味着即使在一些小的错误或不完美的情况下,任务仍然可以被接受或达到预期的结果。
例如,对于一项事务性要求不高的简单办公任务,如复制粘贴文本或整理文件等,只要大致完成了任务,小的错误或细微的差异通常被容忍。而对于事务性要求高的任务,如财务报表的编制或重要文件的审查,任何错误或不完美都可能导致严重后果,因此对其准确性和完整性的要求较高。
然而,尽管事务性要求不高,仍然需要保持对任务的专注和准确性,以确保任务的合理完成,并避免可能出现的问题或错误。
什么时候选择MongoDB?
是否需要选择它,我们可以考虑以下几个问题:应用不需要事务及复杂join支持新应用,需求会变,数据模型无法确定,想快速迭代开发应用需要2000-3000以上的读写QPS应用需要TB甚至PB级别数据存储应用发展迅速,需要能快速水平扩展应用要求存储的数据不丢失应用需要99.999%高可用应用需要大量的地理位置查询,文本查询
如果符合上述中的1个及以上,那么MongoDB是你绝不后悔的选择,一定会有人有这样的疑问,上述的这些问题就不能使用们么之前学习过的关系型数据库解决了吗?当然不是,只是在面对这些问题时,相比于MySQL或者SQL server,MongoDB无论是从开发还是运维都可以以更低的成本解决问题!
什么是MongoDB?
MongoDB是一个开源,高性能,无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NOSQL数据库产品中的一种,是最像关系型数据库(MySQL)的非关系型数据库,它所支持的数据结构非常松散,是一种类似于JSON的格式叫BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活,MongoDB中的记录是一个文档,它是一个由字段和值对组成的数据结构,MongoDB文档类似于JSON对象,即一个文档认为就是一个对象,字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档,普通数组和文档数组。
注:MongoDB的无模式是指在数据存储过程中不需要事先定义表结构,也不需要强制要求所有文档具有相同的字段。这意味着MongoDB允许在同一个集合中存储不同结构的文档。
而在传统的关系型数据库中,需要定义表结构和字段类型,然后才能存储数据。而在MongoDB中,可以直接将文档插入到集合中,MongoDB会自动为每个文档创建一个唯一的_id字段,并且不限制其他字段的存在和类型。
这种无模式的特性使得MongoDB非常灵活,能够适应数据结构的变化和快速迭代。开发人员可以根据具体需求来设计文档的结构,而不需要事先定义固定的表结构。这使得MongoDB适用于需要频繁更改和扩展数据模型的场景,如大数据、实时分析和快速迭代的应用程序。
然而,尽管MongoDB允许灵活的无模式设计,但在实际使用中也需要谨慎。过于灵活的结构可能导致数据冗余、查询复杂和数据一致性问题。因此,在设计数据库时,仍然需要考虑数据的结构和关系,以保证数据的一致性和查询性能。
关系型数据库与MongoDB对比:
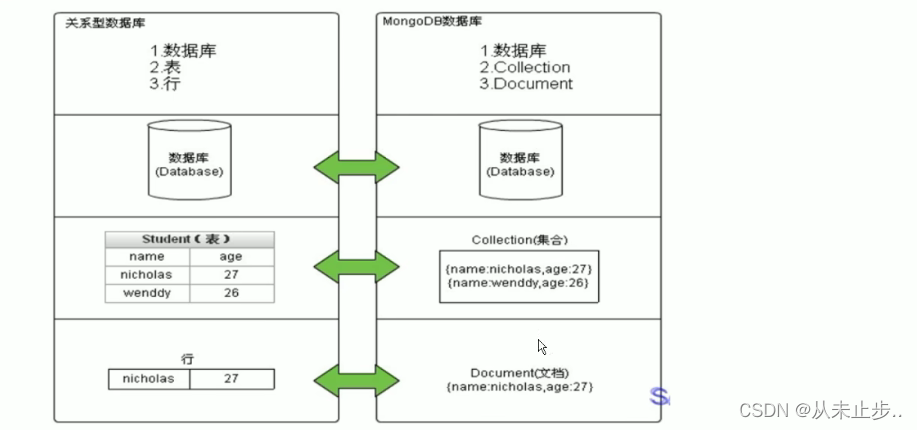
| SQL术语/概念 | MongoDB术语/概念 |
|---|---|
| database 数据库 | database 数据库 |
| table 数据库表 | collection 集合 |
| row 数据记录行 | document 文档 |
| column 数据字段 | filed 域 |
| index 索引 | index 索引 |
| table joins 表连接 | 不支持 |
| 嵌入文档 通过嵌入文档来代替表连接 | |
| primary key 主键 | primary key MongoDB自动将_id字段设置为主键 |
MongoDB中的数据模型:
MongoDB的最小存储单位就是文档对象,文档对象对应于关系型数据库的行,数据在MongoDB中以BSON文档的格式存储在磁盘上,BSON是类JSON的一种二进制形式的存储格式,简称Binary JSON,BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型,BSON采用了类似于C语言结构体的名称,对表示方法,支持内嵌的文档对象和数组对象,具有轻量级,可遍历性,高效性三个优点,可以有效描述非结构化数据和结构化数据,这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想,BSON中,除了基本的JSON类型:string,integer,boolean,double,null,array和object,Mongo还使用了特殊的数据类型,这些类型包括date,object,id,binary,data,regular,expression和code,每一个驱动都以特定语言的方式实现了这些类型。
在Windows下启动和部署MongoDB:
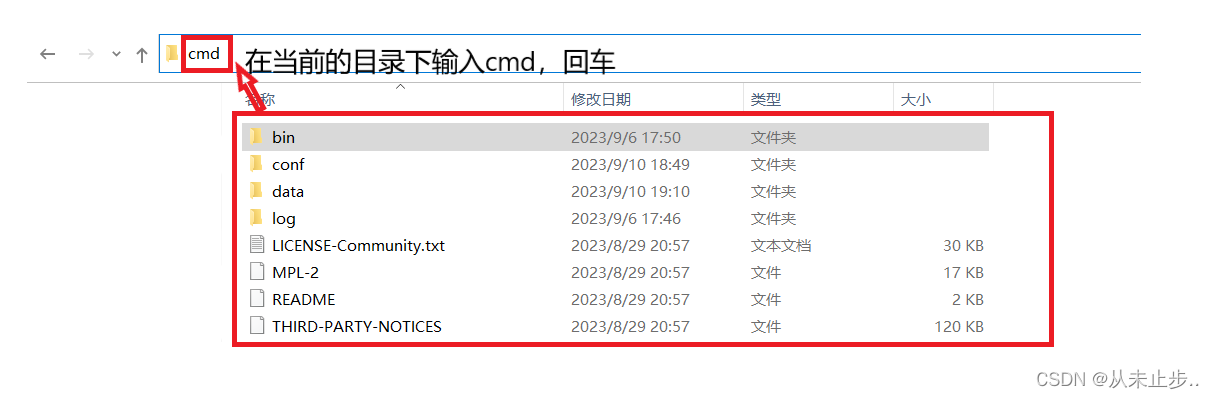
mongod --dbpath=..\data\db
我们在启动信息中可以看到,mongoDB的默认端口号是27017
连接mongoDB:
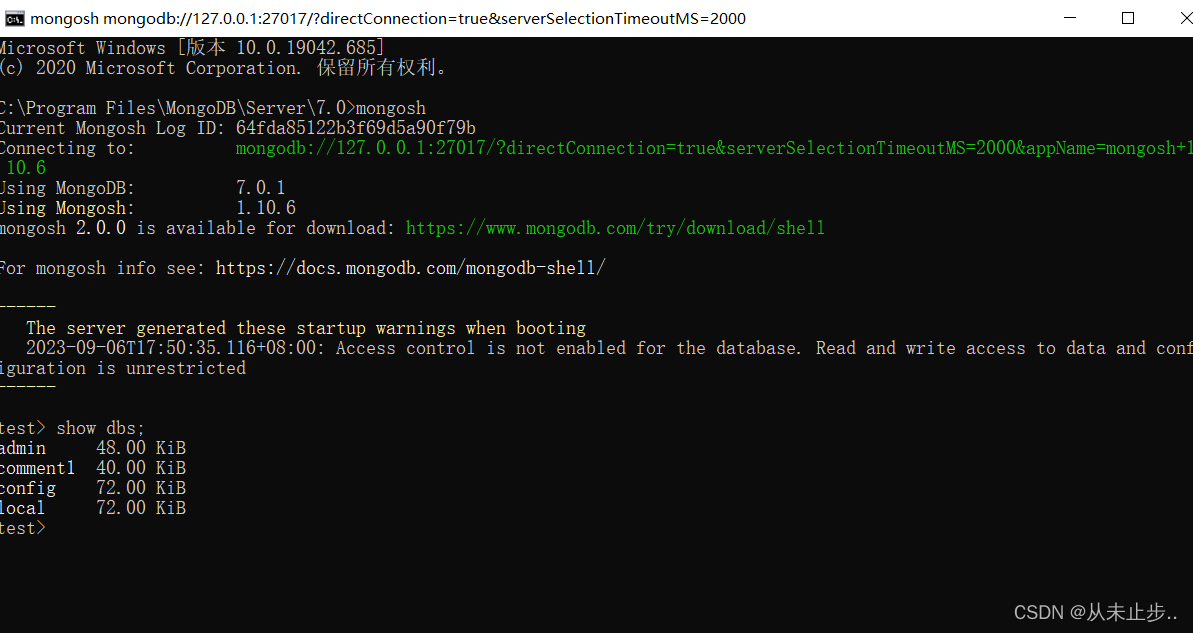
通过shell连接:
在mongoDB的bin目录下cmd回车,输入mongosh,如下所示
通过图形可视化界面来连接:
在官网下载该软件即可!传送门
MongoDB对数据库进行操作的基本命令:
默认数据库的作用:
在MongDB中有以下四个是MongoDB为我们创建的数据库:

admin:从权限的角度看,这是"root"数据库,如果我们将一个用户添加到该数据库,那么这个用户就自动被赋予所有数据库的权限,一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合
config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息
comment1:在MongoDB中,comment1是一个特殊的数据库名称,它并没有特殊的作用或功能。这个名称仅仅是一个示例,用于说明如何在MongoDB中添加注释。注释可以在MongoDB命令中使用。
查看当前的所有数据库:
show dbs或show databases
选择和创建数据库的语法格式:
use 数据库名;
如果该数据库名不存在,那么会自动创建,如下所示:

第二次显示所有数据库时,我们会发现articledb数据库并没有被包含其中呀,原因是在MongoDB中,它的存储分为两部分,一部分是内存存储,一部分是磁盘存储,而当我们使用use articledb;进行存放时,实际上是存放在内存中,此时MongoDB并没有将该数据库持久化到磁盘中,因此,我们当前使用show命令是无法查出该数据库的,而只有当该数据库中包含数据,不为空时,它就会被持久化到磁盘中
查看当前使用正在使用的数据库:
db
虽然我们创建的articledb数据库并没有被持久化到磁盘中,但我们已经将其创建到了内存中,因此也是可以直接使用的,如下所示:

MongoDB中默认的数据库为test,如果我们没有选择数据库,那么所有的数据都会被放在test数据库中
数据库的命名要求和我们之前学过的结构化数据库(MySql,SQL server)是完全一样的,这里我们就不过多赘述了
删除持久化数据库:
db.dropDatabase()

MongoDB对集合操作的基本命令:
创建集合:
集合类似于关系型数据库中的表,可以显式的创建,也可以隐式地创建
显式创建:通过操作命令将其创建
//创建集合
db.createCollection(name)
//查询集合
show collections
举例:
//集合名无论什么类型都要使用双引号引用
db.createCollection("MyMongoDB");
隐式创建:
直接插入文档如下所示,如果当前集合不存在,那么会直接创建一个集合
//插入文档后,查询所有的集合就包括My
db.My.insert({id:1,name:"张三",age:10
})
删除集合:
db.要删除的集合名称.drop()
MongoDB对文档操作的基本命令:
单个文档插入:
使用insert()方法:
db.要插入的集合名称.insert(document)
批量文档插入:
使用insertMany():
db.要插入的集合名称.insertMany([{document1},{document2}....])
举例:
db.wjr.insertMany([{id:2,name:"易烊千玺",age:19},{id:3,name:"王俊凯",age:24},{id:4,name:"王源",age:23}]);
查询集合中的所有文档:
//查询所有的
db.要查询的集合名称.find()
//条件查询
db.要查询的集合名称.find(限制条件)
//条件查询--返回符合条件的第一条数据
db.要查询的集合名称.findOne(限制条件)
//投影查询--将某个字段名的值设置成1表示查询结果只显示该字段的内容,将_id的值设置成0表示不显示默认字段_id这一列
db.要查询的集合名称.find([字段名:1,_id:0])
文档使用插入try-catch:
插入时指定了_id,则主键就是该值,如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉,因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理
//如果插入数据时发生错误,那么错误信息会被输出
try{db.要插入数据的集合名称.insert([{"_id":1,"姓名":"Lisa"}]);}catch(e){print(e);}
文档的更新:
通过使用修改器$set来实现:
//将_id为1的名字修改为李萍
db.要修改的集合名称.update({_id:1},{$set:{"姓名":"李萍"}})
批量的修改:
//将id为2的所有姓名修改为张明
db.要修改的集合的名称.update({id:"2"},{$set:{"姓名":"张明"}},{multi:true})
注意:{multi:true}不能省略,否则会出现只将满足条件的第一条数据修改
列值增长的修改:
//将_id为9的用户年龄设置为+1,通过$inc运算符来实现
db.要修改的集合名称.update({_id:9},{$inc:{"年龄":NumberInt(1)}})
文档的删除:
删除文档的命令:
//条件删除
db.要删除的集合名称.remove(条件)
//删除所有的数据
db.要删除的集合名称.remove({})
文档的分页查询:
统计所有的记录数:
//统计当前集合中的所有记录条数
db.要统计的集合名称.count()
//统计该集合中姓名为张三的记录条数
db.要统计的集合名称.count({姓名:"张三"})
分页列表查询:
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据
//返回当前集合查询结果的Number条数据
db.要查询的集合名称.find().limit(Number)
//将当前集合查询结果的前Number条数据不显示,默认值是0
db.要查询的集合名称.find().skip(Number)
两者也可以同时使用:
//返回当前集合查询结果的Number1条数据,并不显示查询结果的前Number2条数据
db.要查询的集合名称.find().limit(Number1).skip(Number2)
排序查询:
sort()方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序排列,而-1是用于降序排列
//将查询结果根据_id进行降序排列,字段也可以指定多个,比如我们可以同时设定根据某个字段进行升序排列,某个字段进行降序排列
db.要查询的集合名称.find().sort({_id:-1})
注:skip(),limit(),sort()三个同时执行时,执行的顺序是先sort(),然后是skip(),最后是显示的limit(),和命令编写的顺序无关
正则的复杂条件查询:
MongoDB的模糊查询是通过正则表达式的方式实现的,格式为:
//查询该集合中姓名以张开头的文档
db.要查询的集合名称.find({"姓名":/^张/})
//查询该集合中姓名中包含明的文档
db.要查询的集合名称.find({"姓名":/明/})
比较查询:
//查询该集合中age大于12的所有文档
db.要查询的集合名称.find({age:{$gt:NumberInt(12)}})//查询该集合中age小于12的所有文档
db.要查询的集合名称.find({age:{$lt:NumberInt(12)}})//查询该集合中age大于等于12的所有文档
db.要查询的集合名称.find({age:{$gte:NumberInt(12)}})//查询该集合中age小于等于12的所有文档
db.要查询的集合名称.find({age:{$lte:NumberInt(12)}})//查询该集合中age不等于12的所有文档
db.要查询的集合名称.find({age:{$ne:NumberInt(12)}})
包含查询:
包含使用$in操作符
//查询该集合中姓名字段包含a或者c
db.要查询的集合名称.find({"姓名":{$in:["a","c"]}})
不包含使用$nin操作符
//查询该集合中姓名字段不包含a或者c
db.要查询的集合名称.find({"姓名":{$in:["a","c"]}})
条件连接查询:
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联,相当于我们之前学学过的结构化数据库中的and
格式为:
$and:[{},{},{},....]
//查询该集合中age大于等于12并且小于等于19的文档
db.要查询的集合.find({$and:[{age:{$gte:NumberInt(12)}},{age:{$lt:NumberInt(19)}}]})
如果两个以上条件之间是或者的关系,我们使用$or操作符进行关联,与前面的and格式相同
$or:[{},{},{},....]
//查询该集合中age大于等于12或者小于等于19的文档
db.要查询的集合.find({$or:[{age:{$gte:NumberInt(12)}},{age:{$lt:NumberInt(19)}}]})
索引—Index:
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒其至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文栏数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
单字段索引:
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single FieldIndex)。对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。
复合索引:
MongoDB还支持多个字段的用户定义索引,即复合索引(CompoundIndex)。复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由[ userid: 1,score:-1组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。
索引的管理操作:
索引的查看:
说明:返回一个集合中的所有索引的数组。
语法:
db.collection.getIndexes()
注:该语法命令运行要求是MongoDB3.0+
索引的创建:
在集合上创建索引:
语法:
db.collection.createIndex(keys,options)
keys:它的类型为document,包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型,对于字段上的升序索引,请指定值1;对于降序索引,请指定值-1;比如:{字段:1或-1},其中1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可,另外,MongoDB支持几种不同的索引类型,包括文本,地理空间和哈希索引。
options:它的类型为document,它是可选的,包含一组控制索引创建的选项的文档。
options的常见可选参数如下所示:
unique:它的类型为Boolean,它表示创建的索引是否唯一,指定true创建唯一索引,默认为false
name:它的类型为String,它表示索引的名称,如果未指定,MongoDB通过连接索引的字段名和排序顺序生成一个索引名称。
索引的移除:
说明:可以移除指定的索引,或者移除所有索引
指定索引的移除:
db.collection.dropIndex(index)
参数:
index:它的类型为string或者document,它用来指定要删除的索引,可以通过索引名称或索引规范文档指定索引,若要删除文本索引,请指定索引名称。
所有索引的删除:
db.collection.dropIndexs()
索引的使用:
执行计划:
分析查询性能通常使用执行计划(解释计划)来查看查询的情况,如查询耗费的时间,是否基于索引查询等。
那么通常,我们想知道建立的索引是否有效,效果如何,都需要通过执行计划查看。
语法:
db.collection.find(query,options).explain(options)
涵盖的查询:
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存,这些覆盖的查询可以非常有效。
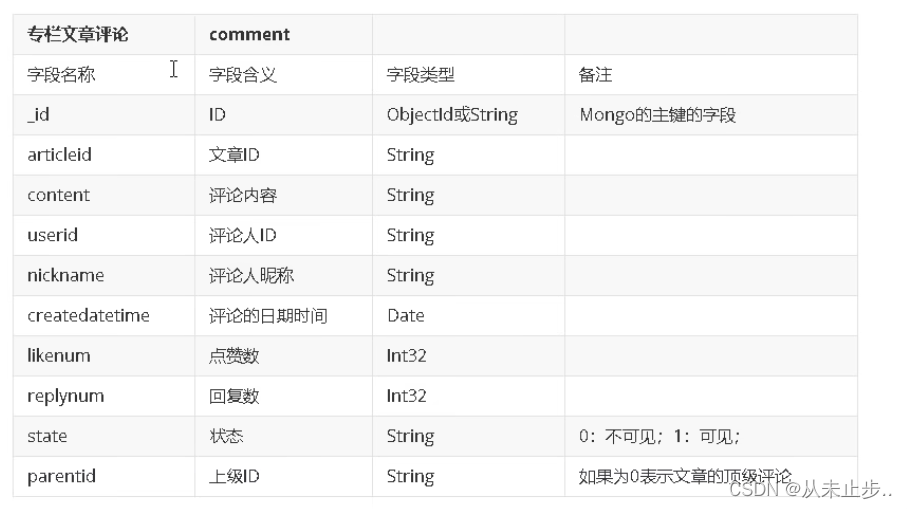
存放文章评论的数据放入MongoDB中,数据结构参考如下:
相关文章:
MongoDB基础知识~
引入MongoDB: 在面对高并发,高效率存储和访问,高扩展性和高可用性等的需求下,我们之前所学习过的关系型数据库(MySql,sql server…)显得有点力不从心,而这些需求在我们的生活中也是随处可见的,例如在社交中…...

41. 缺失的第一个正数
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3示例 2: 输入:nums [3…...
数据结构—数组栈的实现
前言:各位小伙伴们我们前面已经学习了带头双向循环链表,数据结构中还有一些特殊的线性表,如栈和队列,那么我们今天就来实现数组栈。 目录: 一、 栈的概念 二、 栈的实现 三、 代码测试 栈的概念: 栈的概念…...

AI大模型低成本快速定制秘诀:RAG和向量数据库
文章目录 1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式 1. 前言 当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。 这种背景下,向量数据库凭借其独特…...

Please No More Sigma(构造矩阵)
Please No More Sigma 给f(n)定义如下: f(n)1 n1,2; f(n)f(n-1)f(n-2) n>2; 给定n,求下式模1e97后的值 Input 第一行一个数字T,表示样例数 以下有T行,每行一个数,表示n。 保证T<100,n<100000…...
HTML设置标签栏的图标
添加此图标最简单的方法无需修改内容,只需按以下步骤操作即可: 1.准备一个 ico 格式的图标 2.将该图标命名为 favicon.ico 3.将图标文件置于index.html同级目录即可 为什么我的没有变化? 答曰:ShiftF5强制刷新一下网页就行了...

4.CentOS7安装MySQL5.7
CentOS7安装MySQL5.7 2023-11-13 小柴你能看到嘛 哔哩哔哩视频地址 https://www.bilibili.com/video/BV1jz4y1A7LS/?vd_source9ba3044ce322000939a31117d762b441 一.解压 tar -xvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz1.在/usr/local解压 tar -xvf mysql-5.7.44-…...

【华为OD题库-014】告警抑制-Java
题目 告警抑制,是指高优先级告警抑制低优先级告警的规则。高优先级告警产生后,低优先级告警不再产生。请根据原始告警列表和告警抑制关系,给出实际产生的告警列表。不会出现循环抑制的情况。告警不会传递,比如A->B.B->C&…...

高频SQL50题(基础题)-5
文章目录 主要内容一.SQL练习题1.602-好友申请:谁有最多的好友代码如下(示例): 2.585-2016年的投资代码如下(示例): 3.185-部门工资前三高的所有员工代码如下(示例): 4.1667-修复表中的名字代码…...

Spring IoC DI 使⽤
关于 IoC 的含义,推荐看IoC含义介绍(Spring的核心思想) 喜欢 Java 的推荐点一个免费的关注,主页有更多 Java 内容 前言 通过上述的博客我们知道了 IoC 的含义,既然 Spring 是⼀个 IoC(控制反转)…...

Zigbee智能家居方案设计
背景 目前智能家居物联网中最流行的三种通信协议,Zigbee、WiFi以及BLE(蓝牙)。这三种协议各有各的优势和劣势。本方案基于CC2530芯片来设计,CC2530是TI的Zigbee芯片。 网关使用了ESP8266CC2530。 硬件实物 节点板子上带有继电器…...

机器视觉目标检测 - opencv 深度学习 计算机竞赛
文章目录 0 前言2 目标检测概念3 目标分类、定位、检测示例4 传统目标检测5 两类目标检测算法5.1 相关研究5.1.1 选择性搜索5.1.2 OverFeat 5.2 基于区域提名的方法5.2.1 R-CNN5.2.2 SPP-net5.2.3 Fast R-CNN 5.3 端到端的方法YOLOSSD 6 人体检测结果7 最后 0 前言 ǵ…...
无监督学习的集成方法:相似性矩阵的聚类
在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。 这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样…...

16. 机器学习——决策树
机器学习面试题汇总与解析——决策树 本章讲解知识点 什么是决策树决策树原理决策树优缺点决策树的剪枝决策树的改进型本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。 本专栏针对面试题答案进行了…...

DevOps系列---【jenkinsfile使用sshpass发送到另一台服务器】
1.首先在宿主机安装sshpass 2.把物理机的sshpass复制到容器中 which sshpass cp $(which sshpass) /usr/local/app/ docker cp sshpass 容器id:/usr/local/bin/sshpass 3.在jenkinsfile中添加 #在stages中添加stage stage(部署TEST服务){steps{sh "sshpass -p root1234 sc…...

Docker 和 Kubernetes:技术相同和不同之处
Docker和Kubernetes是当今最流行的容器化技术解决方案。本文将探讨Docker和Kubernetes的技术相似之处和不同之处,以帮助读者更好地理解这两种技术。 Docker和Kubernetes:当今最流行的容器化技术解决方案 在当今的IT领域,Docker和Kubernetes无…...

通信世界扫盲基础二(原理部分)
上次我们刚学习了关于通信4/G的组成和一些通识,今天我们来更深层次了解一些原理以及一些新的基础~ 目录 专业名词 LTE(4G系统) EPC s1 E-UTRAN UE UU X2 eNodeB NR(5G系统) NGC/5GC NG NG-RAN Xn gNodeB N26接口 手机的两种状态 空闲态 连接态 …...

手机厂商参与“百模大战”,vivo发布蓝心大模型
在2023 vivo开发者大会上,vivo发布自研通用大模型矩阵——蓝心大模型,其中包含十亿、百亿、千亿三个参数量级的5款自研大模型,其中,10亿量级模型是主要面向端侧场景打造的专业文本大模型,具备本地化的文本总结、摘要等…...

【微软技术栈】C#.NET 中的泛型
本文内容 定义和使用泛型泛型的利与弊类库和语言支持嵌套类型和泛型 借助泛型,你可以根据要处理的精确数据类型定制方法、类、结构或接口。 例如,不使用允许键和值为任意类型的 Hashtable 类,而使用 Dictionary<TKey,TValue> 泛型类并…...
【毕业论文】基于微信小程序的植物分类实践教学系统的设计与实现
基于微信小程序的植物分类实践教学系统的设计与实现https://download.csdn.net/download/No_Name_Cao_Ni_Mei/88519758 基于微信小程序的植物分类实践教学系统的设计与实现 Design and Implementation of Plant Classification Practical Teaching System based on WeChat Mini…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...