三、机器学习基础知识:Python常用机器学习库(中文文本分析相关库)
文章目录
- 1、Jieba库
- 1.1 主要函数
- 1.2 词性标注
- 1.3 关键词提取
- 2、WordCloud库
- 2.1 常见参数
- 2.2 词云绘制
文本分析是指对文本的表示及其特征的提取,它把从文本中提取出来的特征词进行量化来表示文本信息,经常被应用到文本挖掘以及信息检索的过程当中。
1、Jieba库
在自然语言处理过程中,为了能更好地处理句子,往往需要把句子拆分成一个一个的词语,这样能更好地分析句子的特性,这个过程就称为分词。由于中文句子不像英文那样天然自带分属,并且存在各种各样的词组,从而使中文分词具有一定的难度。Jieba 是一个Python 语言实现的中文分词组件,在中文分词界非常出名,支持简体、繁体中文,高级用户还可以加入自定义词典以提高分词的准确率,其应用范围较广,不仅能分词,还提供关键词提取和词性标注等功能。
Jieba库的调用需要使用自动安装命令 pip install jieba进行安装,之后使用代码import jieba 引入即可。
1.1 主要函数
| 函数名 | 作用 |
|---|---|
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s.cut_all=True) | 全模式,输出文本s中的所有可能单词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| jieba.lcut(s) | 精确模式,返回一个列表类型 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型 |
| jieba.add_word(w) | 向分词词典中增加新词w |
精确分词实例:
import jieba
s = "我喜欢在图书馆学习"
for x in jieba.cut(s): #jieba.cut返回一个可迭代类型print(x,end=' ')
jieba.lcut(s)

全模式分词实例:
import jieba
s = "我喜欢在图书馆学习"
for x in jieba.cut(s,cut_all=True): print(x,end=' ')
jieba.lcut(s,cut_all=True)

搜索引擎模式分词实例:
import jieba
s = "我喜欢在武汉市图书馆学习"
jieba.lcut(s) #精确模式
jieba.lcut(s,cut_all=True) #全模式
jieba.lcut_for_search(s) #在搜索引擎分词模式,在精确分词的模式下对长词再次分割

1.2 词性标注
词性是词汇基本的语法范畴,通常也称为词类,主要用来描述一个词在上下文中的作用。例如人物、地名、事物等是名词,表示动作的词是动词等。词性标注的过程就是确定一个句子中出现的每个词分别属于名词、动词还是形容词等,它是语法分析、信息抽取等应用领域重要的信息处理基础性工作。
不同的语言有不同的词性标注集,为了方便指明词的词性,需要给每个词性编码,常用词性编码如下:
| 词性编码 | 词性 | 词性编码 | 词性 |
|---|---|---|---|
| n | 名词 | m | 数词 |
| v | 动词 | o | 拟声词 |
| a | 形容词 | y | 语气词 |
| p | 介词 | z | 状态词 |
| c | 连词 | nr | 人名 |
| d | 副词 | ns | 地名 |
| ul | 助词 | t | 时间 |
| q | 量词 | w | 标点符号 |
| r | 代词 | x | 未知符号 |
中文分词及词性的标注可以使用jieba.posseg模块,其中的cut()方法能够同时完成分词和词性标注两个功能,它返回一个数据序列,其中包含word和flag两个序列,word是分词得到的词语,flag是对各个词的词性标注。
词性标注实例:
import jieba.posseg as psg
text = "我喜欢在武汉市图书馆学习"
seg = psg.cut(text) #词性标注
for e in seg:print(e,end = ' ')

1.3 关键词提取
关键词抽取就是从文本里面把与这篇文档意义最相关的一些词抽取出来。关键词在文本聚类、分类、自动摘要等领域中有着重要的作用。例如,在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;将某段时问内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。因此,关键词是最能够反应文本主题或者意思的词语。
可以利用jieba分词系统中的TF-IDF接口抽取关键词,实例如下:
from jieba import analyse# 原始文本
text = '''关键词抽取就是从文本里面把与这篇文档意义最相关的一些词抽取出来。关键词在文本聚类、分类、自动摘要等领域中有着重要的作用。例如,在聚类时将关键词相似的几篇文档看成一个团簇,可以大大提高聚类算法的收敛速度;从某天所有的新闻中提取出这些新闻的关键词,就可以大致了解那天发生了什么事情;将某段时问内几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论什么话题。'''# 基于TF-IDF算法进行关键词抽取
# topK表示最大抽取个数,默认为20个
# withWeight表示是否返回关键词权重值,默认值为 False
# 还有一个参数allowPOS默认为('ns','n','vn','v')即仅提取地名、名词、动名词、动词
keywords = analyse.extract_tags(text, topK = 10, withWeight = True)
print ("keywords by tfidf:")
# 输出抽取出的关键词
for keyword in keywords:print ("{:<5} weight:{:4.2f}".format(keyword[0], keyword[1]))

2、WordCloud库
词云(WordCloud)是对文本中出现频率较高的关键词数据给予视觉差异化的展现方式。词云图突出展示高频高质的信息,也能过滤大部分低频的文本。利用词云,可以通过可视化形式凸显数据所体现的主旨,快速显示数据中各种文本信息的频率。
2.1 常见参数
Python中的词云(WordCloud)库中存在一个WordCloud()函数,可以利用该函数进行词云对象的构造,该函数中的主要参数如下所示:
| 属性 | 数据类型 | 说明 |
|---|---|---|
| font_path | string | 字体文件所在的路径 |
| width | int | 画布宽度,默认为400px |
| height | int | 画布高度,默认为400px |
| min_font_size | int | 显示的最小字体大小,默认为4 |
| max_font_size | int | 显示的最大字体大小,默认为None |
| max_words | number | 显示的词的最大个数,默认为200 |
| relative_scaling | float | 词频和字体大小的关联性,默认为5 |
| color_func | callable | 生成新颜色的函数,默认为空 |
| prefer_horizontal | float | 词语水平方向排版出现的频率,默认为0.9 |
| mask | ndarray | 默认为None,使用二维遮罩绘制词云。如果mask非空,将忽略画布的宽度和高度,遮罩形状为mask |
| scale | float | 放大画布的比例,默认为1(1倍) |
| stopwords | 字符串 | 停用词,需要屏蔽的词,默认为空。如果为空,则使用内置的STOPWORDS |
| background_color | 字符串 | 背景颜色,默认为‘black’ |
2.2 词云绘制
例如将26个大写英文字母作为字典的键,针对每个键随机生成1-100之间的正整数作为,基于此字典生成词云:
import wordcloud
import random
import string # 导入string库
# string.ascii_uppercase可以获取所有的大写字母
lstChar = [x for x in string.ascii_uppercase]
# 使用randint获取26个随机整数
lstfreq = [random.randint(1,100) for i in range(26)]
# 使用字典生成式,产生形式如{'A': 80, 'B': 11, 'C': 38……}的字典
freq = {x[0]:x[1] for x in zip(lstChar,lstfreq)}
print(freq)
wcloud = wordcloud.WordCloud(background_color = "white",width=1000,max_words = 50,height = 860, margin = 1).fit_words(freq)# 利用字典freq生成词云
wcloud.to_file("resultcloud.png") # 将生成的词云图片保存
print('结束')
生成的字典如下:

生成的词云如下图所示:

相关文章:
三、机器学习基础知识:Python常用机器学习库(中文文本分析相关库)
文章目录 1、Jieba库1.1 主要函数1.2 词性标注1.3 关键词提取 2、WordCloud库2.1 常见参数2.2 词云绘制 文本分析是指对文本的表示及其特征的提取,它把从文本中提取出来的特征词进行量化来表示文本信息,经常被应用到文本挖掘以及信息检索的过程当中。 1、…...
Nginx 使用笔记大全(唯一入口)
Linux服务器因为Nginx日志access.log文件过大项目无法访问 项目处于运行状态下无法访问,第一步查看磁盘状态 1、查看磁盘状态 df -h 2、查找100M以上的文件 find / -size 100M |xargs ls -lh 3、删除文件 rm -rf /usr/local/nginx/logs/access.log 4、配置nginx.…...
)
数据结构-二叉排序树(建立、查找、修改)
二叉排序树概念 二叉排序树是动态查找表的一种,也是常用的表示方法。 其中,它具有如下性质: 1.若它的左子树非空,则其左子树的所有节点的关键值都小于根节点的关键值。 2.若它的右子树非空,则其右子树的所有节点的…...

Linux 性能优化之使用 Tuned 配置优化方案
写在前面 考试整理相关笔记博文内容涉及 Linux tuned 调优工具的简单认知调优配置文件的简单说明,自定义调优方案介绍理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意ÿ…...

Day02_《MySQL索引与性能优化》
文章目录 一、SQL执行顺序二、索引简介1、关于索引2、索引的类型Btree 索引Btree 索引 三、Explain简介四、Explain 详解1、id2、select_type3、table4、type5、possible_keys6、key7、key_len8、ref9、rows10、Extra11、小案例 五、索引优化1、单表索引优化2、两表索引优化3、…...
(只需三步)Vmvare tools安装教程,实现与windows互通复制粘贴与文件拖拽
首先确保Ubuntu是联网的,如果连不上网可以参考我的这个联网教程,也很简单 (只需三步)虚拟机上vm的ubuntu不能联上网怎么办-CSDN博客 第一步:卸载之前的tools,确保没有残留 sudo apt-get autoremove open-vm-tools 第…...

Android自定义控件:一款多特效的智能loadingView
先上效果图(如果感兴趣请看后面讲解): 1、登录效果展示 2、关注效果展示 1、【画圆角矩形】 画图首先是onDraw方法(我会把圆代码写上,一步一步剖析): 首先在view中定义个属性:priv…...
C语言之初阶指针
一、指针: 其实按照我的理解,当我们写c语言程序的时候,创建的变量,数组等都要在内存上开辟空间。而每一个内存都有一个唯一的编号,这个编号也被称为地址编号,就相当于,编号地址指针。 二、指针…...
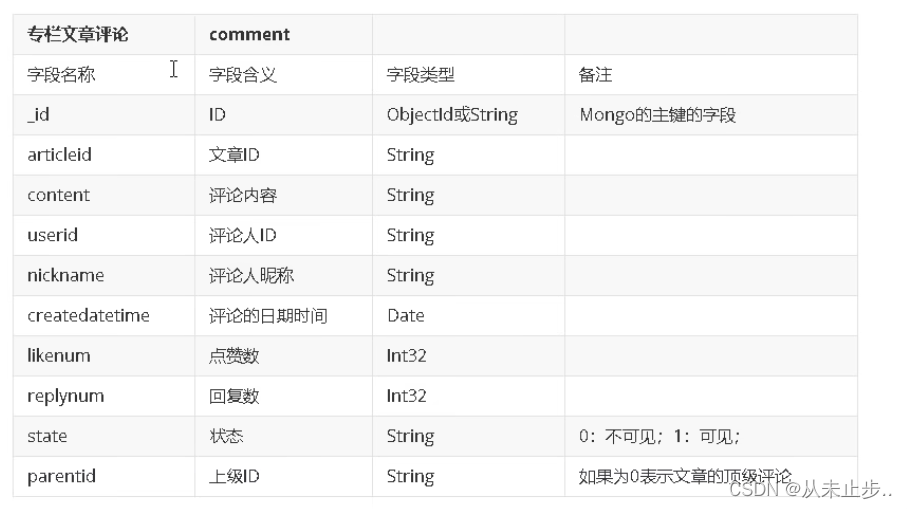
MongoDB基础知识~
引入MongoDB: 在面对高并发,高效率存储和访问,高扩展性和高可用性等的需求下,我们之前所学习过的关系型数据库(MySql,sql server…)显得有点力不从心,而这些需求在我们的生活中也是随处可见的,例如在社交中…...

41. 缺失的第一个正数
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3示例 2: 输入:nums [3…...
数据结构—数组栈的实现
前言:各位小伙伴们我们前面已经学习了带头双向循环链表,数据结构中还有一些特殊的线性表,如栈和队列,那么我们今天就来实现数组栈。 目录: 一、 栈的概念 二、 栈的实现 三、 代码测试 栈的概念: 栈的概念…...

AI大模型低成本快速定制秘诀:RAG和向量数据库
文章目录 1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式 1. 前言 当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。 这种背景下,向量数据库凭借其独特…...

Please No More Sigma(构造矩阵)
Please No More Sigma 给f(n)定义如下: f(n)1 n1,2; f(n)f(n-1)f(n-2) n>2; 给定n,求下式模1e97后的值 Input 第一行一个数字T,表示样例数 以下有T行,每行一个数,表示n。 保证T<100,n<100000…...
HTML设置标签栏的图标
添加此图标最简单的方法无需修改内容,只需按以下步骤操作即可: 1.准备一个 ico 格式的图标 2.将该图标命名为 favicon.ico 3.将图标文件置于index.html同级目录即可 为什么我的没有变化? 答曰:ShiftF5强制刷新一下网页就行了...

4.CentOS7安装MySQL5.7
CentOS7安装MySQL5.7 2023-11-13 小柴你能看到嘛 哔哩哔哩视频地址 https://www.bilibili.com/video/BV1jz4y1A7LS/?vd_source9ba3044ce322000939a31117d762b441 一.解压 tar -xvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz1.在/usr/local解压 tar -xvf mysql-5.7.44-…...

【华为OD题库-014】告警抑制-Java
题目 告警抑制,是指高优先级告警抑制低优先级告警的规则。高优先级告警产生后,低优先级告警不再产生。请根据原始告警列表和告警抑制关系,给出实际产生的告警列表。不会出现循环抑制的情况。告警不会传递,比如A->B.B->C&…...

高频SQL50题(基础题)-5
文章目录 主要内容一.SQL练习题1.602-好友申请:谁有最多的好友代码如下(示例): 2.585-2016年的投资代码如下(示例): 3.185-部门工资前三高的所有员工代码如下(示例): 4.1667-修复表中的名字代码…...

Spring IoC DI 使⽤
关于 IoC 的含义,推荐看IoC含义介绍(Spring的核心思想) 喜欢 Java 的推荐点一个免费的关注,主页有更多 Java 内容 前言 通过上述的博客我们知道了 IoC 的含义,既然 Spring 是⼀个 IoC(控制反转)…...

Zigbee智能家居方案设计
背景 目前智能家居物联网中最流行的三种通信协议,Zigbee、WiFi以及BLE(蓝牙)。这三种协议各有各的优势和劣势。本方案基于CC2530芯片来设计,CC2530是TI的Zigbee芯片。 网关使用了ESP8266CC2530。 硬件实物 节点板子上带有继电器…...

机器视觉目标检测 - opencv 深度学习 计算机竞赛
文章目录 0 前言2 目标检测概念3 目标分类、定位、检测示例4 传统目标检测5 两类目标检测算法5.1 相关研究5.1.1 选择性搜索5.1.2 OverFeat 5.2 基于区域提名的方法5.2.1 R-CNN5.2.2 SPP-net5.2.3 Fast R-CNN 5.3 端到端的方法YOLOSSD 6 人体检测结果7 最后 0 前言 ǵ…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...

CANN runtime:昇腾NPU 运行时的职责边界
个人主页:ujainu 文章目录前言为什么需要运行时这一层runtime管什么,不管什么Stream:并行的基本调度单位Event:跨Stream的同步锚点内存池化:少一次malloc就少一次卡顿任务队列:从计算图到硬件指令的最后一跳…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...

Playwright文件上传避坑指南:遇到动态生成的文件选择框怎么办?
Playwright文件上传避坑指南:动态生成文件选择框的实战解决方案最近在为一个电商平台做自动化测试时,遇到了一个棘手的问题——商品图片上传功能总是失败。页面上的"上传图片"按钮明明可以点击,但传统的set_input_files()方法却毫无…...

VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC++运行库
VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC运行库 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经…...

开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开
更多请点击: https://intelliparadigm.com 第一章:开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开 近期第三方审计机构对主流AI增强型开源扫描工具开展交叉验证测试,结果显示DeepSeek-R…...