Spark的转换算子和操作算子
1 Transformation转换算子
1.1 Value类型
1)创建包名:com.shangjack.value
1.1.1 map()映射
参数f是一个函数可以写作匿名子类,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函数,从而产生一个新的RDD。即,这个新RDD中的每一个元素都是原来RDD中每一个元素依次应用f函数而得到的。
1)具体实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class Test01_Map {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<String> lineRDD = sc.textFile("input/1.txt");
// 需求:每行结尾拼接||
// 两种写法 lambda表达式写法(匿名函数)
JavaRDD<String> mapRDD = lineRDD.map(s -> s + "||");
// 匿名函数写法
JavaRDD<String> mapRDD1 = lineRDD.map(new Function<String, String>() {
@Override
public String call(String v1) throws Exception {
return v1 + "||";
}
});
for (String s : mapRDD.collect()) {
System.out.println(s);
}
// 输出数据的函数写法
mapRDD1.collect().forEach(a -> System.out.println(a));
mapRDD1.collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.2 flatMap()扁平化
1)功能说明
与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。
2)需求说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。

4)具体实现:
package com.shangjack.value;
import org.apache.commons.collections.ListUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class Test02_FlatMap {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
ArrayList<List<String>> arrayLists = new ArrayList<>();
arrayLists.add(Arrays.asList("1","2","3"));
arrayLists.add(Arrays.asList("4","5","6"));
JavaRDD<List<String>> listJavaRDD = sc.parallelize(arrayLists,2);
// 对于集合嵌套的RDD 可以将元素打散
// 泛型为打散之后的元素类型
JavaRDD<String> stringJavaRDD = listJavaRDD.flatMap(new FlatMapFunction<List<String>, String>() {
@Override
public Iterator<String> call(List<String> strings) throws Exception {
return strings.iterator();
}
});
stringJavaRDD. collect().forEach(System.out::println);
// 通常情况下需要自己将元素转换为集合
JavaRDD<String> lineRDD = sc.textFile("input/2.txt");
JavaRDD<String> stringJavaRDD1 = lineRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] s1 = s.split(" ");
return Arrays.asList(s1).iterator();
}
});
stringJavaRDD1. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.3 groupBy()分组
1)功能说明:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
2)需求说明:创建一个RDD,按照元素模以2的值进行分组。
3)具体实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test03_GroupBy {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
// 泛型为分组标记的类型
JavaPairRDD<Integer, Iterable<Integer>> groupByRDD = integerJavaRDD.groupBy(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1 % 2;
}
});
groupByRDD.collect().forEach(System.out::println);
// 类型可以任意修改
JavaPairRDD<Boolean, Iterable<Integer>> groupByRDD1 = integerJavaRDD.groupBy(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
groupByRDD1. collect().forEach(System.out::println);
Thread.sleep(600000);
// 4. 关闭sc
sc.stop();
}
}
- groupBy会存在shuffle过程
- shuffle:将不同的分区数据进行打乱重组的过程
- shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
1.1.4 filter()过滤
1)功能说明
接收一个返回值为布尔类型的函数作为参数。当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。
2)需求说明:创建一个RDD,过滤出对2取余等于0的数据

3)代码实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test04_Filter {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
JavaRDD<Integer> filterRDD = integerJavaRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
filterRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.5 distinct()去重
1)功能说明:对内部的元素去重,并将去重后的元素放到新的RDD中。
2)代码实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test05_Distinct {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6), 2);
// 底层使用分布式分组去重 所有速度比较慢,但是不会OOM
JavaRDD<Integer> distinct = integerJavaRDD.distinct();
distinct. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
注意:distinct会存在shuffle过程。
1.1.6 sortBy()排序
1)功能说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。Spark的排序结果是全局有序。
2)需求说明:创建一个RDD,按照数字大小分别实现正序和倒序排序

3)代码实现:
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test6_SortBy {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(5, 8, 1, 11, 20), 2);
// (1)泛型为以谁作为标准排序 (2) true为正序 (3) 排序之后的分区个数
JavaRDD<Integer> sortByRDD = integerJavaRDD.sortBy(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1;
}
}, true, 2);
sortByRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2 Key-Value类型
1)创建包名:com.shangjack.keyvalue
要想使用Key-Value类型的算子首先需要使用特定的方法转换为PairRDD
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test01_pairRDD{
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
JavaPairRDD<Integer, Integer> pairRDD = integerJavaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<>(integer, integer);
}
});
pairRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.1 mapValues()只对V进行操作
1)功能说明:针对于(K,V)形式的类型只对V进行操作
2)需求说明:创建一个pairRDD,并将value添加字符串"|||"

4)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import scala.Tuple2;
import java.util.Arrays;
public class Test02_MapValues {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD<String, String> javaPairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>("k", "v"), new Tuple2<>("k1", "v1"), new Tuple2<>("k2", "v2")));
// 只修改value 不修改key
JavaPairRDD<String, String> mapValuesRDD = javaPairRDD.mapValues(new Function<String, String>() {
@Override
public String call(String v1) throws Exception {
return v1 + "|||";
}
});
mapValuesRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.2 groupByKey()按照K重新分组
1)功能说明
groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合。
该操作可以指定分区器或者分区数(默认使用HashPartitioner)
2)需求说明:统计单词出现次数

4)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test03_GroupByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<String> integerJavaRDD = sc.parallelize(Arrays.asList("hi","hi","hello","spark" ),2);
// 统计单词出现次数
JavaPairRDD<String, Integer> pairRDD = integerJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
// 聚合相同的key
JavaPairRDD<String, Iterable<Integer>> groupByKeyRDD = pairRDD.groupByKey();
// 合并值
JavaPairRDD<String, Integer> result = groupByKeyRDD.mapValues(new Function<Iterable<Integer>, Integer>() {
@Override
public Integer call(Iterable<Integer> v1) throws Exception {
Integer sum = 0;
for (Integer integer : v1) {
sum += integer;
}
return sum;
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}}
1.2.3 reduceByKey()按照K聚合V
1)功能说明:该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。其存在多种重载形式,还可以设置新RDD的分区数。
2)需求说明:统计单词出现次数

3)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test04_ReduceByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<String> integerJavaRDD = sc.parallelize(Arrays.asList("hi","hi","hello","spark" ),2);
// 统计单词出现次数
JavaPairRDD<String, Integer> pairRDD = integerJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
// 聚合相同的key
JavaPairRDD<String, Integer> result = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.4 reduceByKey和groupByKey区别
1)reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
2)groupByKey:按照key进行分组,直接进行shuffle。
3)开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。影响业务逻辑时建议先对数据类型进行转换再合并。
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test06_ReduceByKeyAvg {
public static void main(String[] args) throws InterruptedException {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD<String, Integer> javaPairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>("hi", 96), new Tuple2<>("hi", 97), new Tuple2<>("hello", 95), new Tuple2<>("hello", 195)));
// ("hi",(96,1))
JavaPairRDD<String, Tuple2<Integer, Integer>> tuple2JavaPairRDD = javaPairRDD.mapValues(new Function<Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Integer v1) throws Exception {
return new Tuple2<>(v1, 1);
}
});
// 聚合RDD
JavaPairRDD<String, Tuple2<Integer, Integer>> reduceRDD = tuple2JavaPairRDD.reduceByKey(new Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> v1, Tuple2<Integer, Integer> v2) throws Exception {
return new Tuple2<>(v1._1 + v2._1, v1._2 + v2._2);
}
});
// 相除
JavaPairRDD<String, Double> result = reduceRDD.mapValues(new Function<Tuple2<Integer, Integer>, Double>() {
@Override
public Double call(Tuple2<Integer, Integer> v1) throws Exception {
return (new Double(v1._1) / v1._2);
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.5 sortByKey()按照K进行排序
1)功能说明
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD。
2)需求说明:创建一个pairRDD,按照key的正序和倒序进行排序

3)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class Test05_SortByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD<Integer, String> javaPairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>(4, "a"), new Tuple2<>(3, "c"), new Tuple2<>(2, "d")));
// 填写布尔类型选择正序倒序
JavaPairRDD<Integer, String> pairRDD = javaPairRDD.sortByKey(false);
pairRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
2 Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
1)创建包名:com.shangjack.action
2.1 collect()以数组的形式返回数据集
1)功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素。
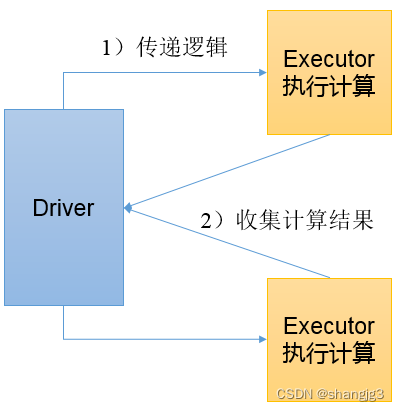
注意:所有的数据都会被拉取到Driver端,慎用。
2)需求说明:创建一个RDD,并将RDD内容收集到Driver端打印
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class Test01_Collect {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
List<Integer> collect = integerJavaRDD.collect();
for (Integer integer : collect) {
System.out.println(integer);
}
// 4. 关闭sc
sc.stop();
}
}
2.2 count()返回RDD中元素个数
1)功能说明:返回RDD中元素的个数

3)需求说明:创建一个RDD,统计该RDD的条数
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test02_Count {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
long count = integerJavaRDD.count();
System.out.println(count);
// 4. 关闭sc
sc.stop();
}
}
2.3 first()返回RDD中的第一个元素
1)功能说明:返回RDD中的第一个元素

2)需求说明:创建一个RDD,返回该RDD中的第一个元素
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test03_First {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
Integer first = integerJavaRDD.first();
System.out.println(first);
// 4. 关闭sc
sc.stop();
}
}
2.4 take()返回由RDD前n个元素组成的数组
1)功能说明:返回一个由RDD的前n个元素组成的数组

2)需求说明:创建一个RDD,取出前两个元素
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class Test04_Take {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
List<Integer> list = integerJavaRDD.take(3);
list.forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
2.5 countByKey()统计每种key的个数
1)功能说明:统计每种key的个数
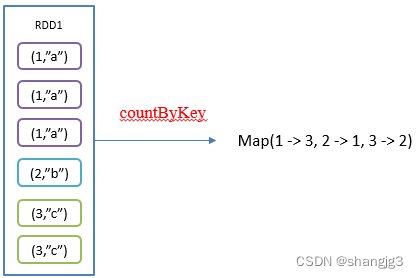
2)需求说明:创建一个PairRDD,统计每种key的个数
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Map;
public class Test05_CountByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD<String, Integer> pairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 8), new Tuple2<>("b", 8), new Tuple2<>("a", 8), new Tuple2<>("d", 8)));
Map<String, Long> map = pairRDD.countByKey();
System.out.println(map);
// 4. 关闭sc
sc.stop();
}
}
2.6 save相关算子
1)saveAsTextFile(path)保存成Text文件
功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
2)saveAsObjectFile(path) 序列化成对象保存到文件
功能说明:用于将RDD中的元素序列化成对象,存储到文件中。
3)代码实现
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class Test06_Save {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2);
integerJavaRDD.saveAsTextFile("output");
integerJavaRDD.saveAsObjectFile("output1");
// 4. 关闭sc
sc.stop();
}
}
2.7 foreach()遍历RDD中每一个元素
2)需求说明:创建一个RDD,对每个元素进行打印
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
public class Test07_Foreach {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),4);
integerJavaRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
});
// 4. 关闭sc
sc.stop();
}
}
2.8 foreachPartition ()遍历RDD中每一个分区
package com.shangjack.spark.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
import java.util.Iterator;
public class Test08_ForeachPartition {
public static void main(String[] args) {
// 1. 创建配置对象
SparkConf conf = new SparkConf().setAppName("core").setMaster("local[*]");
// 2. 创建sc环境
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6), 2);
// 多线程一起计算 分区间无序 单个分区有序
parallelize.foreachPartition(new VoidFunction<Iterator<Integer>>() {
@Override
public void call(Iterator<Integer> integerIterator) throws Exception {
// 一次处理一个分区的数据
while (integerIterator.hasNext()) {
Integer next = integerIterator.next();
System.out.println(next);
}
}
});
// 4. 关闭sc
sc.stop();
}
}
相关文章:
Spark的转换算子和操作算子
1 Transformation转换算子 1.1 Value类型 1)创建包名:com.shangjack.value 1.1.1 map()映射 参数f是一个函数可以写作匿名子类,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函…...
传奇手游天花板赤月【盛世遮天】【可做底版】服务端+自主授权+详细教程
搭建资源下载地址:传奇手游天花板赤月【盛世遮天】【可做底版】服务端自主授权详细教程-海盗空间...

TP触摸屏调试
此处以MT6739 1g版本敦泰TP为例(kernel 4.19),主要修改点如下: 1. 两个配置文件defconfig: kernel-4.19\arch\arm\configs\k39tv1_bsp_1g_k419_debug_defconfig: kernel-4.19\arch\arm\configs\k39tv1_bsp_1g_k419_defconfig: CONFIG_INPUT_TOUCHSCREEN=y CONFIG_TOUCHSCRE…...
11-13 spring整合web
spring注解 把properties文件中的key注入到属性当中去 xml配置文件拆分 -> import标签 注解开发中 import 实现 搞一个主配置类,其他配置类全部导入进来这个这个主配置类 而且其他配置类不需要 加上configuration注解 之前这个注解用于表示这是一个配置文件 …...
基于C#开发的任天堂 Switch 开源模拟器
今天给大家推荐一款基于C#开发的任天堂 Switch 开源模拟器,可方便开发人员来测试游戏,也用于娱乐。 01 项目简介 Ryujinx 是一个开源的任天堂 Switch 模拟器,可以在 PC 上模拟运行 Switch 游戏。采用C#开发,基于 .NET Core技术框…...

做一个Sprngboot文件上传-阿里云
概述 这个模块是用来上传头像以及文章封面的,图片的值是一个地址字符串,一般存放在本地或阿里云服务中 1、本地文件上传 我们将文件保存在一个本地的文件夹下,由于可能两个人上传不同图片但是却同名的图片,那么就会一个人的图片就…...

k8s ----对外暴露
目录 一、Ingress 简介 1、Ingress 组成 2、Ingress 工作原理 二、部署Ingress 1、部署 nginx-ingress-controller 2、暴露ingress 4.1 DaemonSetHostNetworknodeSelector模式的service 4.2 DeploymentNodePort模式的Service 三、Ingress HTTP 代理访问 四、Ingress …...

每日一题(LeetCode)----数组--长度最小的子数组
每日一题(LeetCode)----数组–长度最小的子数组 1.题目( 209.长度最小的子数组) 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] &…...
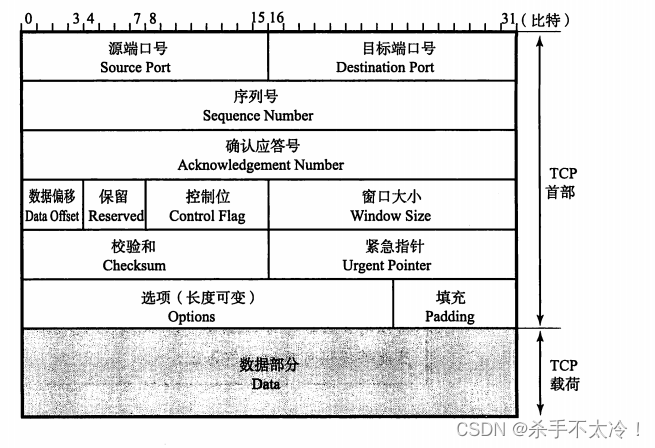
TCP与UDP
文章目录 TCP与UDP传输层的作用端口号UDPTCPUDP首部的格式TCP首部格式 TCP与UDP TCP/IP中有两个具有代表性的传输层协议,它们分别是TCP和UDP。TCP提供可靠的通信传输,而UDP则常被用于让广播和细节控制交给应用的通信传输。总之,根据通信的具…...

js实现对象数组去重
数组去重,一般会在面试的时候才会碰到,要求手写数组去重方法的代码。如果是被提问到,数组去重的方法有哪些?你能答出其中的10种,面试官很有可能对你刮目相看。 在实际项目中碰到的数组去重,一般都是后台去处…...

2023 极术通讯-安谋科技发布“山海”S20F安全解决方案,持续加码智能汽车“芯”赛道
导读:极术社区推出极术通讯,引入行业媒体和技术社区、咨询机构优质内容,定期分享产业技术趋势与市场应用热点。 芯方向 AMBA向多芯片和CHI C2C进发 Arm的Advanced Microcontroller Bus Architecture(AMBA)在与生态系…...

GRPC学习
GRPC元数据 在gRPC中,元数据(metadata)是用于在gRPC请求和响应中传递附加信息的一种机制。元数据是以键值对(key-value pairs)的形式组织的信息,它可以包含请求的上下文信息、安全凭证、消息传输相关的信息…...

c++ latch 使用详解
c latch 使用详解 std::latch c20 头文件 #include <latch>。作用:提供了一种机制,可以让一个或多个线程等待,直到计数器减为零。注意事项: latch 为向下计数器,即只能减少不能增加或者重置。这也使得其只能单…...

linux 下正确使用cp命令复制目录
linux下复制目录时,cp -r 没有 cp -a 好: 使用cp -r 拷贝数据,拷贝的结果是生成新的时间戳等信息 使用cp -a 相当于将原数据原封不动的拷贝过来,不改变里面的任何信息 指定目录时, 源目录/* 【说明:斜…...

CTF----Web真零基础入门
目录 前置知识导图: TCP/IP体系结构(IP和端口): IP是什么:是计算机在互联网上的唯一标识(坐标,代号),用于在互联网中寻找计算机。 内网(局域网…...

css实现元素四周阴影
前言 首先确定的是需要使用box-shadow这一属性 语法如下: box-shadow: h-shadow v-shadow blur spread color inset; h-shadow:表示水平方向上的阴影偏移量,必须指明,可以是正数、负数、0,如果为正数左方有阴影&…...

《QT从基础到进阶·二十五》界面假死处理
假如有这样一种情况,我们在主线程写了一个死循环,当程序运行到主线程的死循环代码后界面便卡死点了没有反应,这里提供几种方法处理界面假死的情况,保证比如主线程在执行死循环没有退出的时候点击界面不会卡死能继续执行其他功能。…...
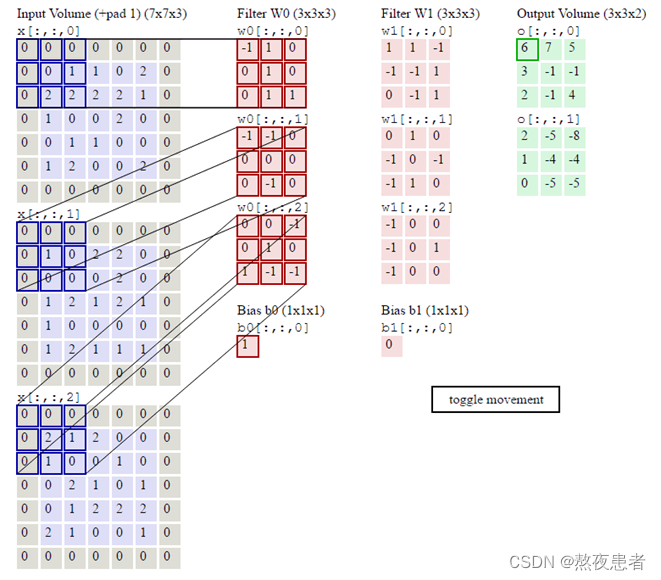
卷积神经网络(1)
目录 卷积 1 自定义二维卷积算子 2 自定义带步长和零填充的二维卷积算子 3 实现图像边缘检测 4 自定义卷积层算子和汇聚层算子 4.1 卷积算子 4.2 汇聚层算子 5 学习torch.nn.Conv2d()、torch.nn.MaxPool2d();torch.nn.avg_pool2d(),简要介绍使用方…...

Mysql中名叫infomaiton_schema的数据库是什么东西?
在 MySQL 中,information_schema 是一个系统数据库,用于存储关于数据库服务器元数据的信息。它并不存储用户数据,而是包含有关数据库、表、列、索引、权限等方面的元数据信息。这些信息可以通过 SQL 查询来获取,用于了解和管理数据…...
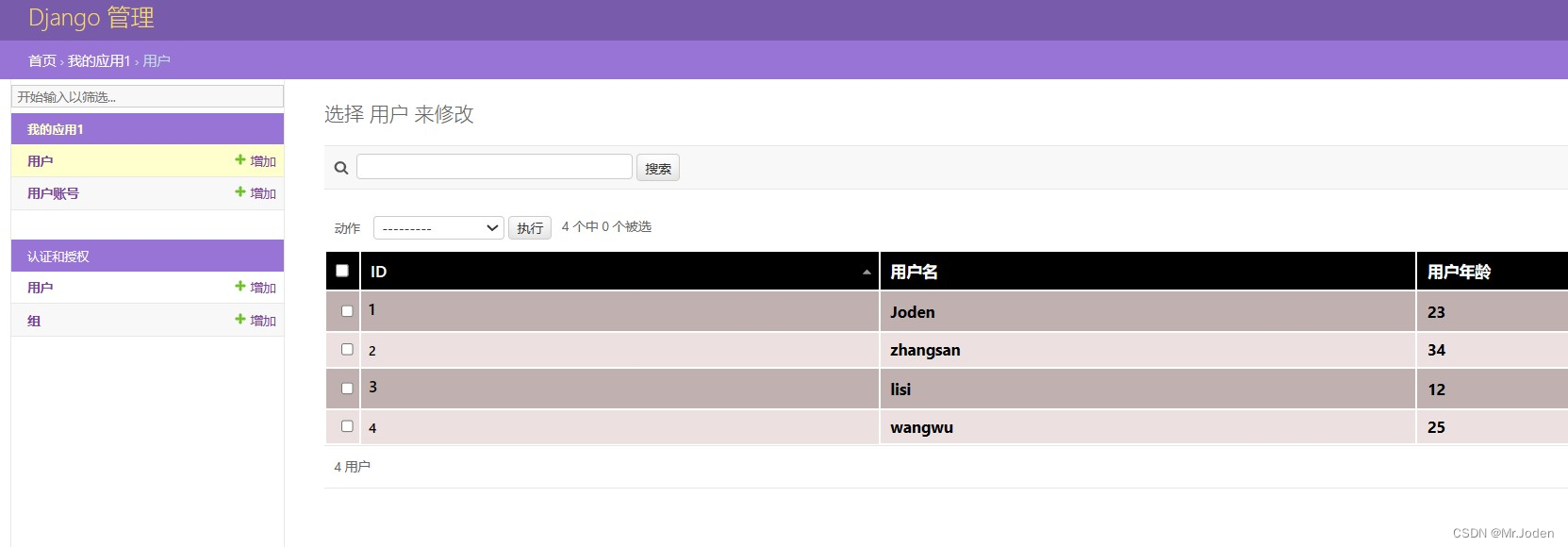
Django(复习篇)
项目创建 1. 虚拟环境 python -m venv my_env cd my_env activate/deactivate pip install django 2. 项目和app创建 cd mypros django-admin startproject Pro1 django-admin startapp app1 3. settings配置INSTALLED_APPS【app1"】TEMPLATES【 DIRS: [os.pat…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...