【深度学习实验】网络优化与正则化(三):随机梯度下降的改进——Adam算法详解(Adam≈梯度方向优化Momentum+自适应学习率RMSprop)
文章目录
- 一、实验介绍
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、实验内容
- 0. 导入必要的库
- 1. 随机梯度下降SGD算法
- a. PyTorch中的SGD优化器
- b. 使用SGD优化器的前馈神经网络
- 2.随机梯度下降的改进方法
- a. 学习率调整
- b. 梯度估计修正
- 3. 梯度估计修正:动量法Momentum
- 4. 自适应学习率
- RMSprop算法
- 5. Adam算法
- 更新公式
- 算法实现
- 算法测试
- 6. 代码整合
任何数学技巧都不能弥补信息的缺失。
——科尼利厄斯·兰佐斯(Cornelius Lanczos)匈牙利数学家、物理学家
一、实验介绍
深度神经网络在机器学习中应用时面临两类主要问题:优化问题和泛化问题。
-
优化问题:深度神经网络的优化具有挑战性。
- 神经网络的损失函数通常是非凸函数,因此找到全局最优解往往困难。
- 深度神经网络的参数通常非常多,而训练数据也很大,因此使用计算代价较高的二阶优化方法不太可行,而一阶优化方法的训练效率通常较低。
- 深度神经网络存在梯度消失或梯度爆炸问题,导致基于梯度的优化方法经常失效。
-
泛化问题:由于深度神经网络的复杂度较高且具有强大的拟合能力,很容易在训练集上产生过拟合现象。因此,在训练深度神经网络时需要采用一定的正则化方法来提高网络的泛化能力。
目前,研究人员通过大量实践总结了一些经验方法,以在神经网络的表示能力、复杂度、学习效率和泛化能力之间取得良好的平衡,从而得到良好的网络模型。本系列文章将从网络优化和网络正则化两个方面来介绍如下方法:
- 在网络优化方面,常用的方法包括优化算法的选择、参数初始化方法、数据预处理方法、逐层归一化方法和超参数优化方法。
- 在网络正则化方面,一些提高网络泛化能力的方法包括ℓ1和ℓ2正则化、权重衰减、提前停止、丢弃法、数据增强和标签平滑等。
本文将介绍基于自适应学习率的优化算法:Adam算法详解(Adam≈梯度方向优化Momentum+自适应学习率RMSprop)
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7
conda activate DL
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib
conda install scikit-learn
2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
|---|---|---|
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入必要的库
import torch
import torch.nn.functional as F
from d2l import torch as d2l
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
1. 随机梯度下降SGD算法
随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的优化算法,用于训练深度神经网络。在每次迭代中,SGD通过随机均匀采样一个数据样本的索引,并计算该样本的梯度来更新网络参数。具体而言,SGD的更新步骤如下:
- 从训练数据中随机选择一个样本的索引。
- 使用选择的样本计算损失函数对于网络参数的梯度。
- 根据计算得到的梯度更新网络参数。
- 重复以上步骤,直到达到停止条件(如达到固定的迭代次数或损失函数收敛)。
a. PyTorch中的SGD优化器
Pytorch官方教程
optimizer = torch.optim.SGD(model.parameters(), lr=0.2)
b. 使用SGD优化器的前馈神经网络
【深度学习实验】前馈神经网络(final):自定义鸢尾花分类前馈神经网络模型并进行训练及评价
2.随机梯度下降的改进方法
传统的SGD在某些情况下可能存在一些问题,例如学习率选择困难和梯度的不稳定性。为了改进这些问题,提出了一些随机梯度下降的改进方法,其中包括学习率的调整和梯度的优化。
a. 学习率调整
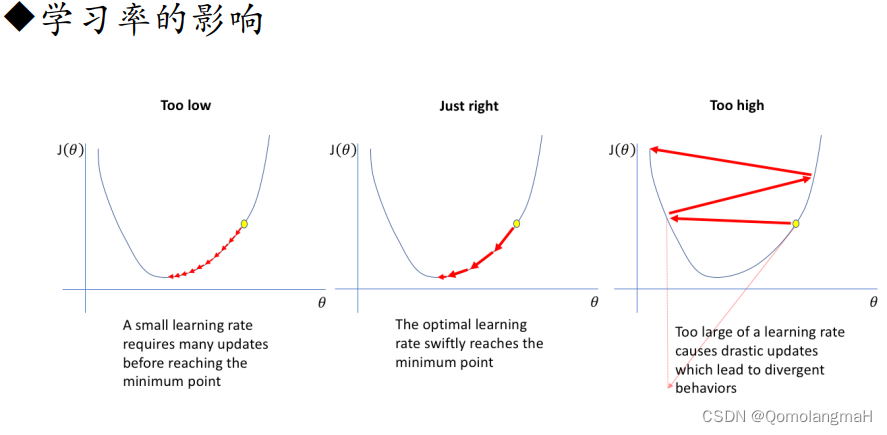
- 学习率衰减(Learning Rate Decay):随着训练的进行,逐渐降低学习率。常见的学习率衰减方法有固定衰减、按照指数衰减、按照时间表衰减等。
- Adagrad:自适应地调整学习率。Adagrad根据参数在训练过程中的历史梯度进行调整,对于稀疏梯度较大的参数,降低学习率;对于稀疏梯度较小的参数,增加学习率。这样可以在不同参数上采用不同的学习率,提高收敛速度。
- Adadelta:与Adagrad类似,但进一步解决了Adagrad学习率递减过快的问题。Adadelta不仅考虑了历史梯度,还引入了一个累积的平方梯度的衰减平均,以动态调整学习率。
- RMSprop:也是一种自适应学习率的方法,通过使用梯度的指数加权移动平均来调整学习率。RMSprop结合了Adagrad的思想,但使用了衰减平均来减缓学习率的累积效果,从而更加稳定。
b. 梯度估计修正
- Momentum:使用梯度的“加权移动平均”作为参数的更新方向。Momentum方法引入了一个动量项,用于加速梯度下降的过程。通过积累之前的梯度信息,可以在更新参数时保持一定的惯性,有助于跳出局部最优解、加快收敛速度。
- Nesterov accelerated gradient:Nesterov加速梯度(NAG)是Momentum的一种变体。与Momentum不同的是,NAG会先根据当前的梯度估计出一个未来位置,然后在该位置计算梯度。这样可以更准确地估计当前位置的梯度,并且在参数更新时更加稳定。
- 梯度截断(Gradient Clipping):为了应对梯度爆炸或梯度消失的问题,梯度截断的方法被提出。梯度截断通过限制梯度的范围,将梯度控制在一个合理的范围内。常见的梯度截断方法有阈值截断和梯度缩放。
3. 梯度估计修正:动量法Momentum
【深度学习实验】网络优化与正则化(一):优化算法:使用动量优化的随机梯度下降算法(Stochastic Gradient Descent with Momentum)
def init_momentum_states(feature_dim):v_w = torch.zeros((feature_dim, 3))v_b = torch.zeros(3)return (v_w, v_b)def sgd_momentum(params, states, hyperparams):for p, v in zip(params, states):with torch.no_grad():v[:] = hyperparams['momentum'] * v + p.gradp[:] -= hyperparams['lr'] * vp.grad.data.zero_()4. 自适应学习率
【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
RMSprop算法
RMSprop(Root Mean Square Propagation)算法是一种针对Adagrad算法的改进方法,通过引入衰减系数来平衡历史梯度和当前梯度的贡献。它能够更好地适应不同参数的变化情况,对于非稀疏数据集表现较好。

def init_rmsprop_states(feature_dim):s_w = torch.zeros((feature_dim, 3))s_b = torch.zeros(3)return (s_w, s_b)def rmsprop(params, states, hyperparams):gamma, eps = hyperparams['gamma'], 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()5. Adam算法
Adam算法(Adaptive Moment Estimation Algorithm)[Kingma et al., 2015]可以看作动量法和 RMSprop 算法的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
更新公式

算法实现
def init_adam_states(feature_dim):v_w, v_b = torch.zeros((feature_dim, 3)), torch.zeros(3)s_w, s_b = torch.zeros((feature_dim, 3)), torch.zeros(3)return ((v_w, s_w), (v_b, s_b))def adam(params, states, hyperparams):beta1, beta2, eps = 0.9, 0.999, 1e-6for p, (v, s) in zip(params, states):with torch.no_grad():v[:] = beta1 * v + (1 - beta1) * p.grads[:] = beta2 * s + (1 - beta2) * torch.square(p.grad)v_bias_corr = v / (1 - beta1 ** hyperparams['t'])s_bias_corr = s / (1 - beta2 ** hyperparams['t'])p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)p.grad.data.zero_()hyperparams['t'] += 1 init_adam_states函数用于初始化Adam优化算法的状态。它接受一个特征维度feature_dim作为输入,并返回包含权重和偏置项的状态变量((v_w, s_w), (v_b, s_b))。这些状态变量用于存储权重和偏置项的一阶矩估计(动量)和二阶矩估计(RMSProp)。
adam函数是Adam优化算法的主要实现部分,它接受三个参数:params(待优化的参数),states(状态变量),和hyperparams(超参数)。
- 在函数内部,使用一个循环来遍历待优化的参数
params和对应的状态变量states,然后根据Adam算法的更新规则,对每个参数进行更新:- 在更新过程中,使用
torch.no_grad()上下文管理器,表示在更新过程中不会计算梯度。- 根据Adam算法的公式,计算动量和二阶矩估计的更新值,并将其累加到对应的状态变量中。
- 根据偏差修正公式,计算修正后的动量和二阶矩估计。
- 根据修正后的动量和二阶矩估计,计算参数的更新量,并将其应用到参数上。
- 使用
p.grad.data.zero_()将参数的梯度清零,以便下一次迭代时重新计算梯度。
- 在更新过程中,使用
- 在代码的最后,
hyperparams['t'] += 1用于更新迭代次数t的计数器。
算法测试
# batch_size = 1
batch_size = 24
# batch_size = 120# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)lr = 0.02
train(adam, init_adam_states(4), {'lr': lr, 't': 1}, train_loader, 4)-
IrisDataset类:
- 参照前文:【深度学习实验】前馈神经网络(七):批量加载数据(直接加载数据→定义类封装数据)
-
train函数:
- 参照前文:【深度学习实验】网络优化与正则化(一):优化算法:使用动量优化的随机梯度下降算法(Stochastic Gradient Descent with Momentum)
6. 代码整合
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from d2l import torch as d2l
from sklearn.datasets import load_iris
from torchvision.io import read_image
from torch.utils.data import Dataset, DataLoaderclass FeedForward(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(FeedForward, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.fc2 = nn.Linear(hidden_size, output_size)self.act = nn.Sigmoid()def forward(self, inputs):outputs = self.fc1(inputs)outputs = self.act(outputs)outputs = self.fc2(outputs)return outputsdef evaluate_loss(net, data_iter, loss):"""评估给定数据集上模型的损失Defined in :numref:`sec_model_selection`"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:X = X.to(torch.float32)out = net(X)# y = d2l.reshape(y, out.shape)l = loss(out, y.long())metric.add(d2l.reduce_sum(l), d2l.size(l))return metric[0] / metric[1]def train(trainer_fn, states, hyperparams, data_iter, feature_dim, num_epochs=2):"""Defined in :numref:`sec_minibatches`"""# 初始化模型w = torch.normal(mean=0.0, std=0.01, size=(feature_dim, 3),requires_grad=True)b = torch.zeros((3), requires_grad=True)# 训练模型animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[0, num_epochs], ylim=[0.9, 1.1])n, timer = 0, d2l.Timer()# 这是一个单层线性层net = lambda X: d2l.linreg(X, w, b)loss = F.cross_entropyfor _ in range(num_epochs):for X, y in data_iter:X = X.to(torch.float32)l = loss(net(X), y.long()).mean()l.backward()trainer_fn([w, b], states, hyperparams)n += X.shape[0]if n % 48 == 0:timer.stop()animator.add(n / X.shape[0] / len(data_iter),(evaluate_loss(net, data_iter, loss),))timer.start()print(f'loss: {animator.Y[0][-1]:.3f}, {timer.avg():.3f} sec/epoch')return timer.cumsum(), animator.Y[0]def load_data(shuffle=True):x = torch.tensor(load_iris().data)y = torch.tensor(load_iris().target)# 数据归一化x_min = torch.min(x, dim=0).valuesx_max = torch.max(x, dim=0).valuesx = (x - x_min) / (x_max - x_min)if shuffle:idx = torch.randperm(x.shape[0])x = x[idx]y = y[idx]return x, yclass IrisDataset(Dataset):def __init__(self, mode='train', num_train=120, num_dev=15):super(IrisDataset, self).__init__()x, y = load_data(shuffle=True)if mode == 'train':self.x, self.y = x[:num_train], y[:num_train]elif mode == 'dev':self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]else:self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.x)def init_adam_states(feature_dim):v_w, v_b = torch.zeros((feature_dim, 3)), torch.zeros(3)s_w, s_b = torch.zeros((feature_dim, 3)), torch.zeros(3)return ((v_w, s_w), (v_b, s_b))def adam(params, states, hyperparams):beta1, beta2, eps = 0.9, 0.999, 1e-6for p, (v, s) in zip(params, states):with torch.no_grad():v[:] = beta1 * v + (1 - beta1) * p.grads[:] = beta2 * s + (1 - beta2) * torch.square(p.grad)# 偏差修正,请在下方实现偏差修正的计算公式v_bias_corr = v / (1 - beta1 ** hyperparams['t'])s_bias_corr = s / (1 - beta2 ** hyperparams['t'])p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)p.grad.data.zero_()hyperparams['t'] += 1# batch_size = 1
batch_size = 24
# batch_size = 120# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)lr = 0.02
train(adam, init_adam_states(4), {'lr':lr, 't':1}, train_loader, 4, num_epochs=200)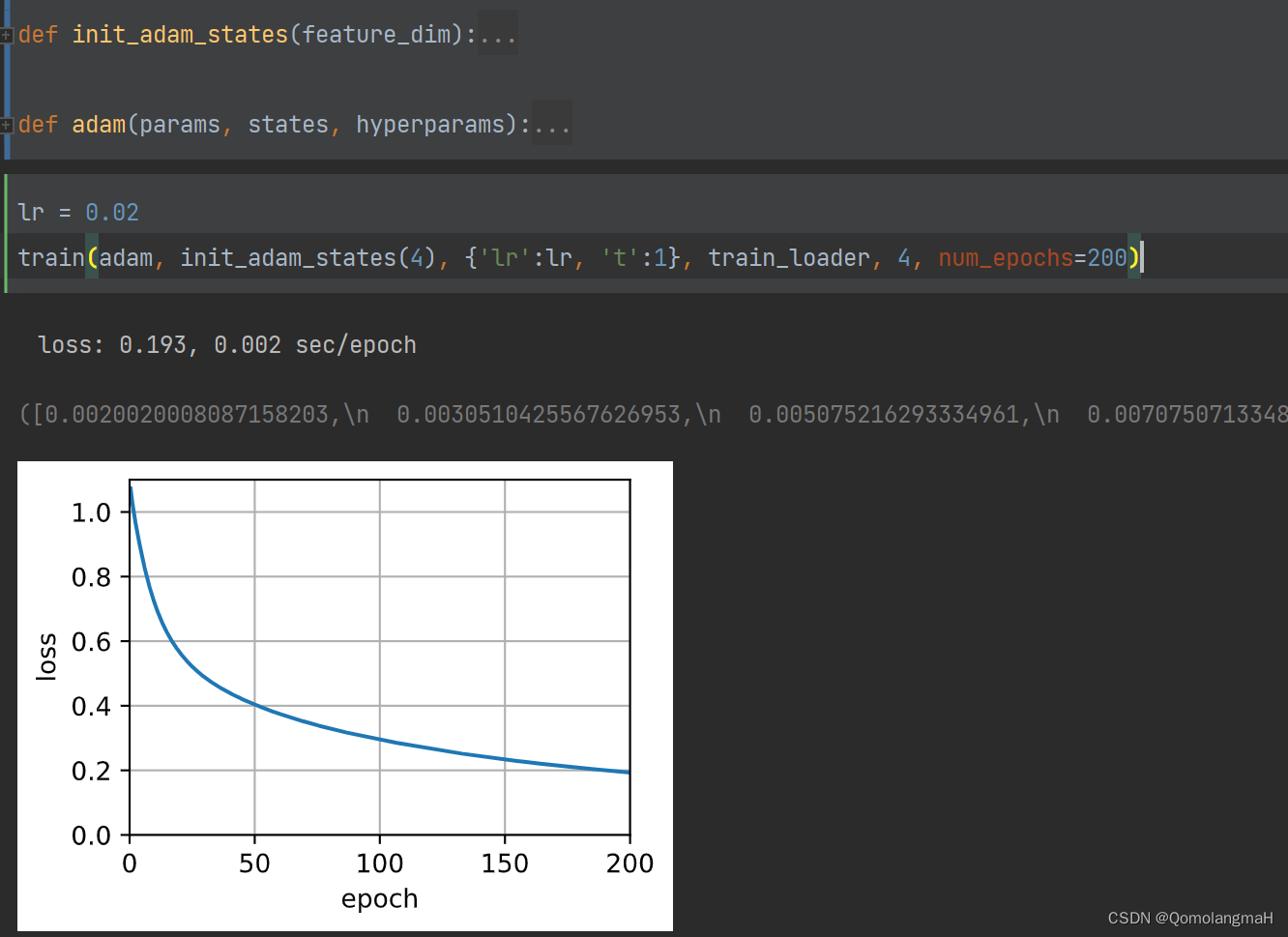
相关文章:
【深度学习实验】网络优化与正则化(三):随机梯度下降的改进——Adam算法详解(Adam≈梯度方向优化Momentum+自适应学习率RMSprop)
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momen…...

如何解决网页中的pdf文件无法下载?pdf打印显示空白怎么办?
问题描述 偶然间,遇到这样一个问题,一个网页上的附件pdf想要下载打印下来,奈何尝试多种办法都不能将其下载下载,点击打印出现的也是一片空白 百度搜索了一些解决方案都不太行,主要解决方案如:https://zh…...

【JVM】类加载器 Bootstrap、Extension、Application、User Define 以及 双亲委派
以下环境为 jdk1.8 两大类 分类成员语言继承关系引导类加载器bootstrap 引导类加载器C/C无自定义类加载器extension 拓展类加载器、application 系统/应用类加载器、user define 用户自定义类加载器Java继承于 java.lang.ClassLoader 四小类 Bootstrap 引导类加载器 负责加…...

读书笔记:彼得·德鲁克《认识管理》第15章 使工作富有成效:工作和过程
一、章节内容概述 不同员工在技术熟练程度、知识掌握程度方面有所不同,但所有工 作本质上都是相同的,为了实现富有成效,需要遵循同样的步骤,划分 为同样的阶段,受到同样的对待,需要分析、综合、控制以及相…...

媒体软文投放的流程与媒体平台的选择
海内外媒体软文:助力信息传播与品牌建设 在当今数字化时代,企业如何在庞大的信息海洋中脱颖而出,成为品牌建设的领军者?媒体软文投放无疑是一项强大的策略,通过选择合适的平台,精准投放,可以实…...
【excel技巧】如何取消excel隐藏?
Excel工作表中的行列隐藏了数据,如何取消隐藏行列呢?今天分享几个方法给大家 方法一: 选中隐藏的区域,点击右键,选择【取消隐藏】就可以了 方法二: 如果工作表中有多个地方有隐藏的话,还是建…...
AIGC专栏8——EasyPhoto 视频领域拓展-让AIGC肖像动起来
AIGC专栏8——EasyPhoto 视频领域初拓展-让AIGC肖像动起来 学习前言源码下载地址技术原理储备Video Inference 功能说明 & 效果展示1、Text2Video功能说明a、实现原理简介b、文到视频UI介绍c、结果展示 2、Image2Video功能说明a、实现原理简介i、单图模式ii、首尾图模式 b、…...
C++ RBTree 理论
目录 这个性质可以总结为 红黑树的最短最长路径 红黑树的路径范围 code 结构 搞颜色 类 插入 插入逻辑 新插入节点 思考:2. 检测新节点插入后,红黑树的性质是否造到破坏? 解决方法 变色 旋转变色 第三种情况,如果根…...

制作这种在线宣传画册,可轻松收获客户!
制作企业宣传画册,首先要了解企业制作宣传画册的需求以及展示方向,如今互联网时代,宣传画册的制作也应该要创新,而制作一本在线电子宣传画册用于线上宣传是非常有必要的。如何制作呢? 我们 可以使用FLBOOK平台在线制作…...
数据结构 | 图
最小生成树算法 Prime算法 算法思路:从已选顶点所关联的未选边中找出权重最小的边,并且生成树不存在环。 其中,已选顶点是构成最小生成树的结点,未选边是不属于生成树中的边。 例子: 第一步: 假设我们从顶…...

[文件读取]shopxo 文件读取(CNVD-2021-15822)
1.1漏洞描述 漏洞编号CNVD-2021-15822漏洞类型文件读取漏洞等级⭐⭐漏洞环境VULFOCUS攻击方式 描述: ShopXO是一套开源的企业级开源电子商务系统。 ShopXO存在任意文件读取漏洞,攻击者可利用该漏洞获取敏感信息。 1.2漏洞等级 高危 1.3影响版本 ShopXO 1.4漏洞复现…...

zookeeper应用之分布式锁
在分布式系统中多个服务需要竞争同一个资源时就需要分布式锁,这里使用zookeeper的临时顺序节点来实现分布式锁。 在节点X下创建临时顺序节点,getChildren()获取节点X的所有子节点,判断当前节点是否是第一个子节点,如果是就获取锁…...

20. 机器学习——PCA 与 LDA
机器学习面试题汇总与解析——PCA 与 LDA 本章讲解知识点 什么是数据降维PCA本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。 本专栏针对面试题答案进行了优化,尽量做到好记、言简意赅。这才是一…...

深度学习准召
准确率(Precision)和召回率(Recall)是两个用来评价一个模型的好坏的指标,它们有不同的意义: 准确率(Precision):准确率是在所有被模型判断为正例的样本中,有…...

AtCoder ABC154
C - Distinct or Not 签到题,注意大小写和以前的不一样 D - Dice in Line 签到题2,用个窗口即可 E - Almost Everywhere Zero 数位DP(搜索)的例题 pos表示当前搜索到的位置(开始为0,结束为n) …...

可以非常明显地感受到,一场有关直播带货的暗流正在涌动
虽然有关直播带货的争论依然还在持续,但是,我们依然无法否认今年的双十一依然是直播带货的高光时刻。无论是以淘宝、京东和拼多多为代表的传统电商平台,还是以抖音、快手为代表的新电商平台,几乎都将今年双十一的重心放在了直播带…...

C++中的四种构造函数
在C中,有几种不同类型的构造函数,基于它们的特性和用途,可以将它们分类为以下四种: 默认构造函数(Default Constructor): 如果没有为类定义任何构造函数,编译器将为其提供一个默认构造函数。这种…...

通过反射获取某个对象属性是否存在,并获取对象值
SneakyThrowspublic static void main(String[] args) {User user new User("张三", 10);// 获取指定属性名的值String propertyName "name2";Field[] fields user.getClass().getDeclaredFields();// 输出属性名Boolean flag false;for (Field field …...

【MySQL】存储过程与函数
一、存储过程 1、什么是存储过程 它是一组经过预先编译的SQL的封装它被存储在MySQL服务器上,当需要执行它时,客户端只需要向服务器发出调用命令,就可以把这一系列预先存储好的SQL语句全部执行 2、存储过程的优缺点 优点 简化操作…...

【数学】Pair of Topics—CF1324D
Pair of Topics—CF1324D 思路 很明显,需要对 a i a j > b i b j a_i a_j > b_i b_j aiaj>bibj 化简: a i − b i > b j − a j a_i - b_i > b_j - a_j ai−bi>bj−aj a i − b i > − ( a j − b j ) a_…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...