Elasticsearch学习(一)
ElasticSearch学习(一)
1 什么是Elasticsearch
1.什么是搜索?
百度:我们比如说想找寻任何信息时候就会上百度上搜索一下
比如说:电影、图片、小说等等…(提到搜索的第一印象)
百度 != 搜索
百度是公共的搜索引擎
垂直搜索(站内搜索)
互联网的搜索:电商网站、招聘网站、新闻网站、各种app
IT系统的搜索:OA软件、办公自动化软件、会议管理、日程管理、项目管理、员工管理、搜索"张三",“张三儿”…等等
后台管理系统
搜索,就是在任何场景下找寻你想要的信息,这个时候会输入你搜索的关键字然后找到这个关键字相关的有些信息
2.如果用数据库做搜索会怎么样?
做软件开发都知道数据都是存储在数据库里面的,比如说电商网站的网站信息,招聘网站的职位信息,新闻网站的新闻信息
等等,所以说的自然一点如果从技术的角度来考虑如果实现电商网站内部的搜索功能的话就可以考虑去使用数据库进行搜索。
| 商品id | 商品名称 | 商品描述 | 商品图片 | 商品卖家 |
|---|---|---|---|---|
| 1 | 高露洁牙膏 | |||
| 2 | 中华牙膏 | |||
| 3 | 佳洁士牙膏 |
这个时候我们的电商系统:
select * from products where product_name like “%牙膏%”
会去做全表扫描
缺点:
1.比方说:每条记录的指定字段的文本可能会很长比如说商品描述的字段很长,这个时候我们对每条记录的所有文本进行扫描
来判断说你包不包含我的指定词
2.比如说我们有一个叫牙刷膏,就会搜索不到牙膏这个term(还不能将搜索词拆分开去尽可能搜索符合你期望的结果 )
用数据库来实现搜索不太靠谱且性能较差
3.什么是全文检索和Lucene?
全文检索,倒排索引
举个例子下面有四个词条
生化危机电影 1
生化危机海报 2
生化危机文章 3
生化危机新闻 4
我们的倒排索引是下面这样的
| 关键词 | ids |
|---|---|
| 生化 | 1,2,3,4 |
| 危机 | 1,2,3,4 |
| 电影 | 1 |
| 海报 | 2 |
| 文章 | 3 |
| 新闻 | 4 |
我们的数据库里面的数据一共有100万条,按照之前的思路其实就要扫描100万次,并且每次扫描都要匹配那个文本的字符,确认是否包含搜索的关键词,而且还不能将搜索词拆解开来进行检索。
利用倒排索引进行所搜的话,假设100万条数据,拆分出来的词语,假设有1000万个词语,那么在倒排索引中,就有1000万行,我们可能不需要搜索1000万次,很有可能说在搜索到第一次的时候。我们就可以找到这个搜索词对应的数据,也可能是第100次或者第1000次。
上述过程就叫做全文检索
Lucene 就是一个jar包,里面封装好了各种建立倒排索引,以及进行搜索的代码,包括各种算法,我们就用java开发的时候引入lucene jar,然后基于lucene的api进行开发就行。用lucene我们就可以去将已有的数据进行建立索引,lucene会在本地磁盘上面给我们组织索引的数据结构。另外的话,我们也可以用lucene提供的一些功能和api来针对磁盘上的索引数据,进行搜索。
4.什么是Elasticsearch?
我们的lucene封装了搜索引擎的功能
但是部署在单台机器上,假设我们磁盘就500个G的空间
但是如果我们的数据量很大有1个T的数据,那这个时候在一台机器上是放不下的
这个时候有多台机器(分布式),那我们要搜索的话是不是就需要去多台机器来进行通信,这不是就很麻烦吗
而且我们建立索引放在哪一台服务器上,我们的搜索内容放在哪一台呢?
我们还要保证系统的数据不丢失,系统的高可用呢?
加入索引或者数据的服务器一宕机马上就寄啦
我们这不麻烦死了
这个时候我们的Elasticsearch就孕育而生了
我们的只需要发送请求给我们的es集群
我们就会收到我们es集群的响应,就能得到搜索内容
我们的es会底层进行性能优化保证我们的性能最高,基于我们分布式的特性还封装了一些我们lucene所做不到的事情
1.自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行
2.自动维护数据的冗余副本,保证说一些机器宕机了我们不会丢失任何的数据
3.封装了更多的高级功能,以给我们提供更多高级的支持,让我们快速的开发应用,开放更加复杂的应用:
复杂的搜索功能,聚合分析的功能,基于地理位置的搜索(距离我当前位置1km以内的xxxx)
这个就是我们的Elasticsearch
2.Elasticsearch的功能,干什么的
1.Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近一个月访问量排名前3的
新闻板块有哪些
分布式,搜索,数据分析
(2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称含有牙膏的商品,select * from products where product_name like “%牙膏%”
结构化搜索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id = ‘日化用品’
部分匹配、自动完成、搜索纠错、搜索推荐
数据分析:我们分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
(3)对海量数据进行近实时的处理
分布式:ES自动将海量数据分散到多台服务器上存储和检索
海联数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费1小时(这就不是近实时了,而是离线批处理);在秒级别对数据进行搜索和分析
跟分布式相反的lucene,单机应用,只能在单台服务器上使用,只能处理有限的数据量
2.Elasticsearch的适用场景
国外
(1)维基百科,类似于百度百科,全文检索、高亮、搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击、浏览、收藏、评论)+社交网络数据,数据分析,给到每篇新闻的作者让其
知道自己的文章反馈
(3)Stack Overflow(国外程序异常讨论论坛),IT错误,程序报错提交有人会和你讨论和回答,全文检索,搜索相关问题和答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站检索商品
(6)日志数据分析,logstash采集日志,ES进行复炸数据分析(ELK技术)
(7)商品架构监控网站,用户设定某商品阈值,当低于阈值会进行发送消息提醒
(8)BI系统,辅助商业决策报表,ES执行数据分析与挖掘,Kibana进行数据可视化
国内
站内搜索(电商、招聘等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
3.Elasticsearch的特点
(1)可以作为一个大型分布式集群技术,处理PB级数据,服务大小公司
(2)Elasticsearch不是什么新技术,主要是全文检索,数据分析以及分布式技术合并在一起才形成了独一无二的ES
(3)对用户开箱即用
(4)数据库的功能面对很多领域是不够用的,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理,ES作为传统数据库的一个补充
提供了数据库所不能提供的很多功能
3.剖析Elasticsearch核心概念
1.lucene和elasticsearch的前世今生
lucene,最先进功能最强大的搜索库,直接基于lucene开发,非常复杂,阿皮、复杂,需要深入理解原理(各种索引结构)
elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口,java api接口(以及其他语言)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何其他额外设置,完全开源
2.elasticsearch的核心概念
1.Near Realtime
NRT近实时,两个意思,从写入到数据可以被搜索到有一个小延迟,基于es执行搜索和分析可以达到秒级
当这个延迟是ms级才可以算是实时
2.Cluster
集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
3.Node
集群中的一个节点,节点也是有名称的并且十分重要,默认节点会加入到名为”elasticsearch“的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个es集群
4.Document
文档,es中最小的数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用json表示,每个idnex下的type中可以存多个document
5.Index
索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称
6.Type
类型,每个索引里面可以有一个或多个type,type是index中的一个逻辑分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type
例子:商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,可能有的还包含一些特殊的filed例如生鲜保鲜期之类的
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一推document
7.shard
单台机器无法存储大量数据,es可以将一个index 中的数据切分为多个shard,分布在多台服务器上存储,有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多个服务器上执行,提升吞吐量和性能,每个shard都是一个lucene index
8.replica
任何一个服务器随时可能故障或者宕机,此时shard可能会丢失,因此可以为每个shard创建多个replica副本,repliac可以在shard故障时提供备用服务保障数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时第一次设置,不能修改,默认5个),replica shard(随时修改,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置是两台服务器
注意: shard(primary shard),replica(replica shard)是一样的都是shard,只是简称
优点:
1.如果存放日化商品的shard的节点宕机,这个时候没关系我们还有replica,在另一个节点,可以直接继续搜索,请求会打到replica节点上去,数据不会丢很爽
2.提升了搜索这类请求的吞吐量和性能,例如我们的日化商品的shard搜索的qps已经打满了,我们可以继续去请求我们的replica的shard来提高吞吐量和性能
3.elasticsearch核心概念vs数据库核心概念
Elasticsearch 数据库
Document 行
Type 表
Index 数据库
4.在windows上安装和启动Elasticsearch
1.安装JDK,说是1.8.0_73以上但我1.8.0_321上了
2.下载解压
3.去bin里面的elasticseach.bat启动
4.检查localhost:9200
{"name": "JmSo6tA","cluster_name": "elasticsearch","cluster_uuid": "tiiuyMTWSvKA9kvRx9XNNA","version": {"number": "5.2.0","build_hash": "24e05b9","build_date": "2017-01-24T19:52:35.800Z","build_snapshot": false,"lucene_version": "6.4.0"},"tagline": "You Know, for Search"
}
我相信你看得懂
5.修改集群名称:elasticsearch.yml
6.下载和解压Kinana安装包,使用里面的开发界面操作elasticsearch,作为我们学习es知识点的主要的界面入口
7.启动Kinaba,bin\kibana.bat
8.进入Dev Tools界面
相关文章:
)
Elasticsearch学习(一)
ElasticSearch学习(一) 1 什么是Elasticsearch 1.什么是搜索? 百度:我们比如说想找寻任何信息时候就会上百度上搜索一下 比如说:电影、图片、小说等等…(提到搜索的第一印象) 百度 &#x…...

CSS3的常见边框汇总
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>CSS3 边框</title><style>body, ul, li, dl, dt, dd, h1, h2, h3, h4, h5 {margin: 0;padding: 0;}body {background-color: #F7F7F7;}.wr…...
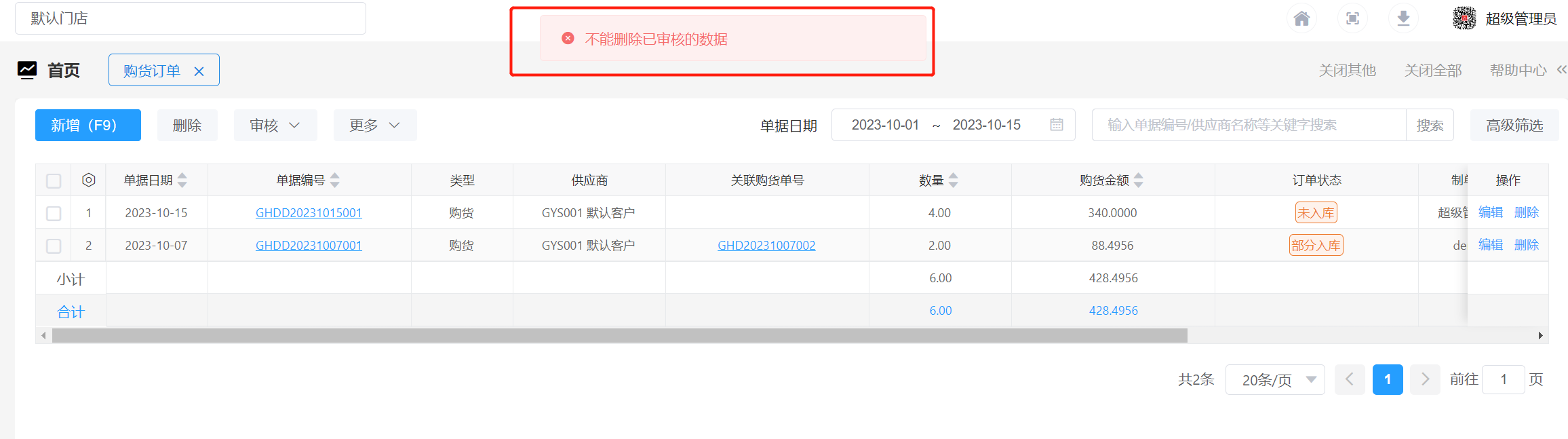
酷柚易汛ERP-购货订单操作指南
1、应用场景 先下购货订单,收货入库后生成购货单。 2、主要操作 2.1 新增购货订单 打开【购货】-【购货订单】新增购货订单。(*为必填项,其他为选填) ① 录入供应商:点击供应商字段框的 ,在弹框中选择供…...
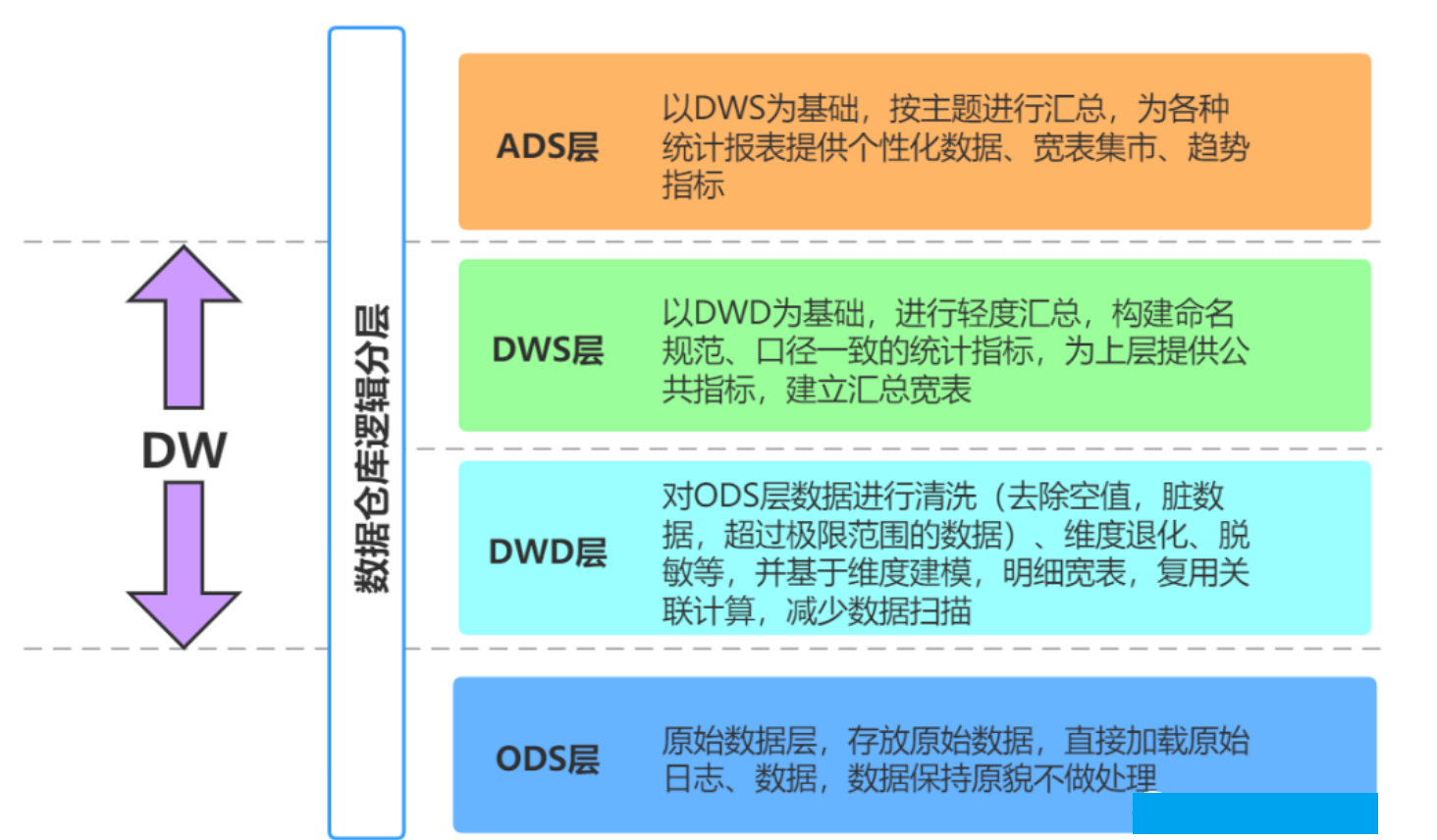
【数据仓库】数仓分层方法详解与层次调用规范
文章目录 一. 数仓分层的意义1. 清晰数据结构。2. 减少重复开发3. 方便数据血缘追踪4. 把复杂问题简单化5. 屏蔽原始数据的异常6. 数据仓库的可维护性 二. 如何进行数仓分层?1. ODS层2. DW层2.1. DW层分类2.2. DWD层2.3. DWS 3. ADS层 4、层次调用规范 一. 数仓分层…...
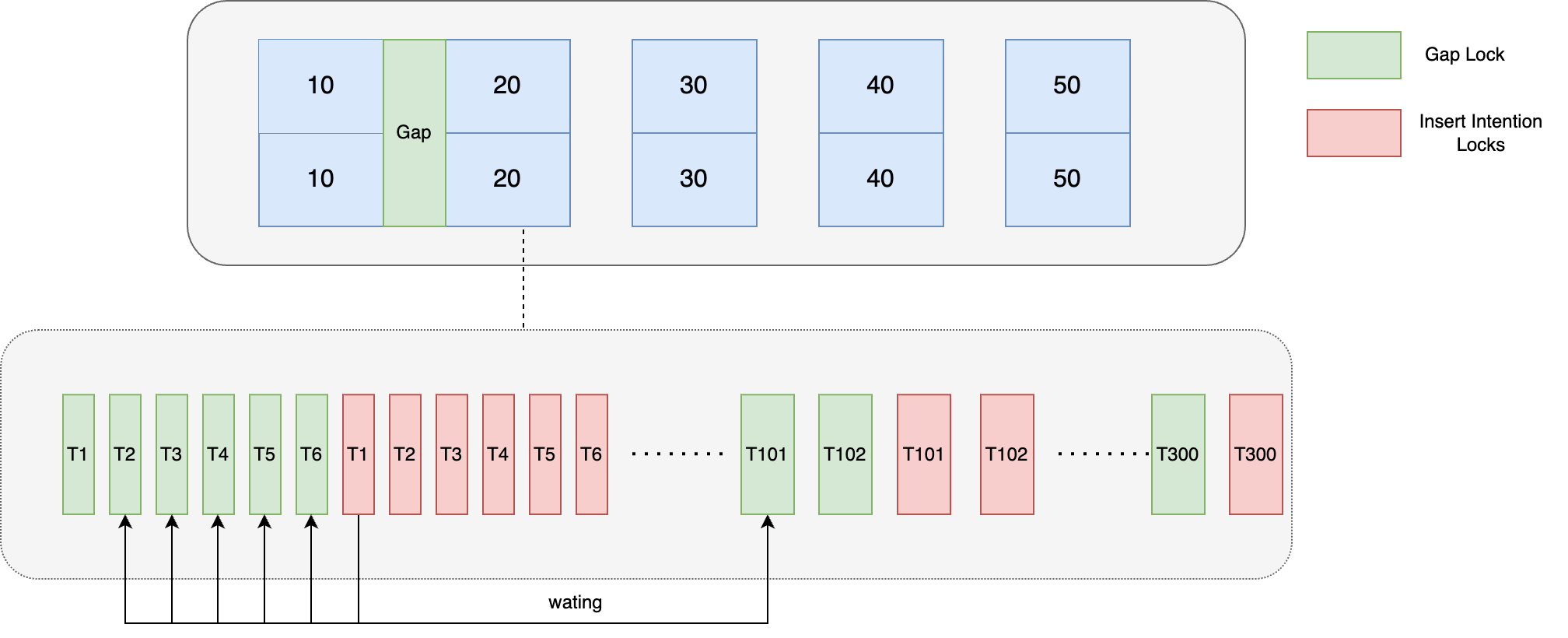
记一次线上问题引发的对 Mysql 锁机制分析
背景 最近双十一开门红期间组内出现了一次因 Mysql 死锁导致的线上问题,当时从监控可以看到数据库活跃连接数飙升,导致应用层数据库连接池被打满,后续所有请求都因获取不到连接而失败 整体业务代码精简逻辑如下: Transaction p…...

Android 工厂模式距离传感器逻辑优化
Android 工厂模式距离传感器逻辑优化 接到客户反馈提到距离传感器校准完毕之后,每次测试完成界面都会弹出“请点击校准按钮进行校准!”Toast弹窗,需要对弹窗的显示逻辑进行优化,即只让其在首次进入距离传感器测试界面时弹出&#…...

Dell笔记本电脑 启动时提示解决
https://www.dell.com/support/kbdoc/en-us/000139731/what-the-headless-operation-mode-active-post-message-means-and-how-to-stop-it-appearing-during-start-up dell官方解释: 提示来自于BIOS/UEFI固件中POST Behaviar,只要打开了忽略警告、错误…...

【人工智能Ⅰ】7-KNN 决策树
【人工智能Ⅰ】7-KNN & 决策树 7-1 KNN(K near neighbour) 思想:一个样本与数据集中的k个样本最相似,若这k个样本大多数属于某类别,则该个样本也属于这类别 距离度量 样本相似性用欧氏距离定义 L p ( x i , x…...

【LeetCode】26. 删除有序数组中的重复项
26. 删除有序数组中的重复项 难度:简单 题目 给你一个 非严格递增排列 的数组 nums ,请你原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素…...

K8S知识点(八)
(1)实战入门-Label 通过标签实现Pod的区分,说白了就是一种标签选择机制 可以使用命令是否加了标签: 打标签: 更新标签: 筛选标签: 修改配置文件,重新创建一个pod 筛选࿱…...

25.4 MySQL 函数
1. 函数的介绍 1.1 函数简介 在编程中, 函数是一种组织代码的方式, 用于执行特定任务. 它是一段可以被重复使用的代码块, 通常接受一些输入(参数)然后返回一个输出. 函数可以帮助开发者将大型程序分解为更小的, 更易于管理的部分, 提高代码的可读性和可维护性.函数在编程语言…...

Unity 下载Zip压缩文件并且解压缩
1、Unity下载Zip压缩文件主要使用UnityWebRequest类。 可以参考以下方法: webRequest UnityWebRequest.Get(Path1); //压缩文件路径webRequest.timeout 60;webRequest.downloadHandler new DownloadHandlerBuffer();long fileSize GetLocalFileSize(Path2); …...

c++11新特性篇-委托构造函数和继承构造函数
C11引入了委托构造函数(Delegating Constructor)和C11及后续标准引入了继承构造函数(Inheriting Constructor)两个特性。 1.委托构造函数 委托构造函数是C11引入的一个特性,它允许一个构造函数调用同一类的另一个构造…...
案例)
Flink SQL处理回撤流(Retract Stream)案例
Flink SQL支持处理回撤流(Retract Stream),下面是一个使用Flink SQL消费回撤流的案例: 假设有一个数据流,包含用户的姓名和年龄,希望计算每个姓名的年龄总和。 以下是示例代码: // 创建流执行…...
)
6.5.事件图层(MapEventsOverlay)
愿你出走半生,归来仍是少年! 简单来说就是一个不参与绘制但是可进行交互的图层,它具备了单击和长按的交互功能。 booleanonSingleTapConfirmed(MotionEvent e, MapView mapView)booleanonLongPress(MotionEvent e, MapView mapView) 通过继承它重写上方…...
供暖系统如何实现数据远程采集?贝锐蒲公英高效实现智慧运维
山西某企业专注于暖通领域,坚持为城市集中供热行业和楼宇中央空调行业提供全面、专业的“智慧冷暖”解决方案。基于我国供热行业的管理现状,企业成功研发并推出了可将能源供应、管理与信息化、自动化相融合的ICS-DH供热节能管理系统。 但是,由…...
Flutter笔记:关于Flutter中的大文件上传(上)
Flutter笔记 关于Flutter中的大文件上传(上) 大文件上传背景与 Flutter 端实现文件分片传输 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址&#…...
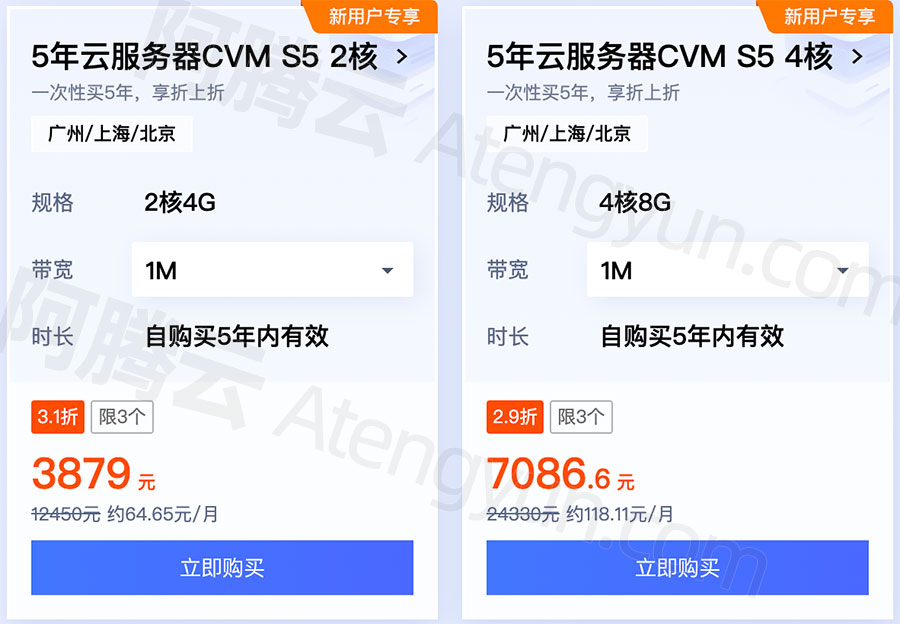
腾讯云CVM服务器5年可选2核4G和4核8G配置
腾讯云服务器网整理五年云服务器优惠活动 txyfwq.com/go/txy 配置可选2核4G和4核8G,公网带宽可选1M、3M或5M,系统盘为50G高性能云硬盘,标准型S5实例CPU采用主频2.5GHz的Intel Xeon Cascade Lake或者Intel Xeon Cooper Lake处理器,…...
数据结构:反射
基本概念 反射中的四个类 Class类 Java文件在被编译之后,生成了.class文件,JVM此时解读.class文件,将其解析为java.lang.Class 对象,在程序运行时每个java文件就最终变成了Class类对象的一个实例。通过反射机制应用这个 实例就…...

45 深度学习(九):transformer
文章目录 transformer原理代码的基础准备位置编码Encoder blockmulti-head attentionFeed Forward自定义encoder block Deconder blockEncoderDecodertransformer自定义loss 和 学习率mask生成函数训练翻译 transformer 这边讲一下这几年如日中天的新的seq2seq模式的transform…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析
LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 功能模块架构与核心技…...