数据挖掘 决策树
# 编码声明,并不是注释,而是一种特殊的源文件指令,用于指定文件的字符编码格式
# -*- coding: utf-8 -*-import pandas as pd # 提供了DataFrame等数据结构
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树分类器和可视化决策树的模块
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.feature_extraction import DictVectorizer # 将字典形式的特征转换成向量形式# 读入并选择
data = pd.read_csv("lenses.txt", encoding="gbk", sep="\t")
features = data[['age', 'prescript', 'astigmatic', 'tearRate']] # 使用两层括号是为了创建一个包含多个列名的列表
targets = data['eye_types']
# 获取所有属性的同步属性值的名字
feature_name = []
# 遍历 features 数据框的每一列,对每一列的 unique 值进行提取,并将这些 unique 值添加到 feature_name 列表中
features.apply(lambda x: feature_name.extend(x.unique()), axis=0)# 特征提抽取one-hot编码
vect = DictVectorizer() # 将字典数据转换为特征矩阵,如果某个样本缺少某个特征,会用默认值(通常为0)进行填充,形成稀疏矩阵。
# 生成一个列表,其中每个元素是一个字典,字典的键是列名,值是对应行的值。
features = vect.fit_transform((features.to_dict(orient="records")))# 划分数据集
# 训练集特征数据赋值给 X_train,测试集特征数据赋值给 X_test,训练集目标数据赋值给 y_train,测试集目标数据赋值给 y_test
X_train, X_test, y_train, y_test = train_test_split(features, targets, test_size=0.25)# #构建模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(f"决策树模型的分类准确率为{score:.3f}")# 将模型保存至dot文件
with open("tree_model.dot", 'w') as f:f = export_graphviz(clf, out_file=f, feature_names=feature_name, class_names=targets.unique())# #将模型输出至目标文件
# import os
# os.system(f"dot -Tpng {'tree_model.dot'} -o {'tree_model'}.jpg")from sklearn.datasets import load_iris
from sklearn import tree
import graphviz# ----------------数据准备----------------------------
iris = load_iris() # 加载数据# ---------------模型训练----------------------------------
clf = tree.DecisionTreeClassifier() # sk-learn的决策树模型
clf = clf.fit(iris.data, iris.target) # 用数据训练树模型构建()
r = tree.export_text(clf, feature_names=iris['feature_names'])
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=iris.feature_names,class_names=iris.target_names,filled=True, rounded=True,special_characters=True)
graph = graphviz.Source(dot_data) # 将存储在 dot_data 中的图形数据加载到对象中
graph # 显示图形。(如果没显示,则需要独立运行这一句)
# graph.render("iris") #将图形保存为iris.pdf文件。
# graph.view() # 直接打开pdf文件展示# 关于使用的文件编码:
# GBK编码主要用于简化汉字编码,通常在中国大陆被使用。如果你确定你的文本数据是中文并且使用了GBK编码,那么使用GBK编码是合适的。
# 但是如果你不确定数据的编码方式,或者数据中包含多种语言的字符,那么使用UTF-8编码会更加安全,因为它是一种通用的、兼容性很好的编码方式,能够支持几乎所有的字符和符号,并且在全球范围内被广泛应用。# 每次运行准确度差距较大,主要是因为数据量太小# 熵(entropy)是用来衡量一个随机变量的不确定性的度量,如果计算出的熵值较高,表示该数据集的不确定性也较高;而熵值较低则表示数据集的不确定性较低,即包含的信息量较少。# "tearRate"特征是指眼泪流失率(tear rate),用于描述眼睛的泪液排出速度或眼泪的分泌量。
# "soft"通常指代软性隐形眼镜或软性眼镜镜片,而"hard"可能指代硬性隐形眼镜或硬性眼镜镜片。
如果不能生成决策树图片,可以参考这篇文章
相关文章:

数据挖掘 决策树
# 编码声明,并不是注释,而是一种特殊的源文件指令,用于指定文件的字符编码格式 # -*- coding: utf-8 -*-import pandas as pd # 提供了DataFrame等数据结构 from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树分类…...
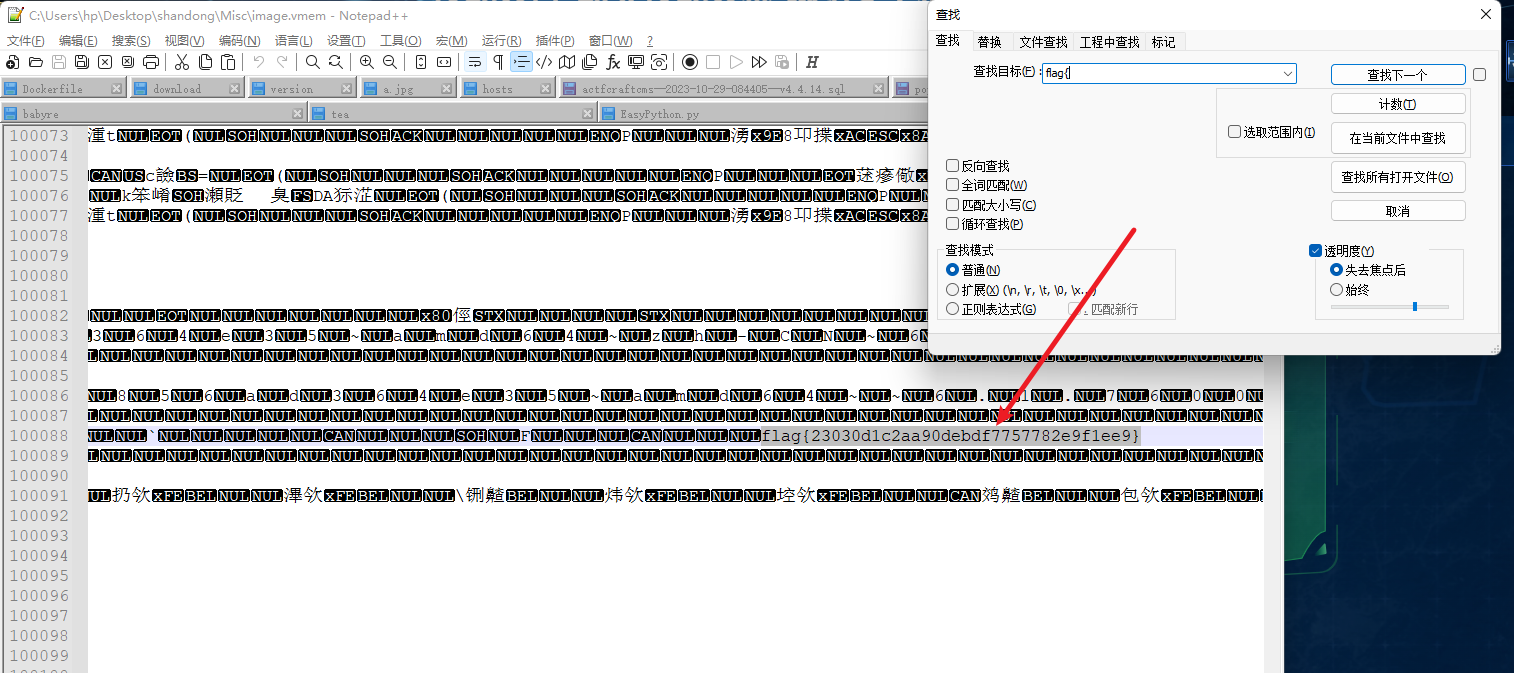
“技能兴鲁”职业技能大赛-网络安全赛项-学生组初赛 WP
Crypto BabyRSA 共模攻击 题目附件: from gmpy2 import * from Crypto.Util.number import *flag flag{I\m not gonna tell you the FLAG} # 这个肯定不是FLAG了,不要交这个咯p getPrime(2048) q getPrime(2048) m1 bytes_to_long(bytes(flag.e…...

[Android]修改应用包名、名称、版本号、Icon以及环境判断和打包
1.修改包名 在Android Studio中更改项目的包名涉及几个步骤: 打开项目结构: 在Android Studio中,确保您处于Android视图模式(在左侧面板顶部有一个下拉菜单可以选择)。 重命名包名: 在项目视图中,找到您的包名&…...

基于风驱动算法优化概率神经网络PNN的分类预测 - 附代码
基于风驱动算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于风驱动算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于风驱动优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神经网络…...
)
安全计算环境(设备和技术注解)
网络安全等级保护相关标准参考《GB/T 22239-2019 网络安全等级保护基本要求》和《GB/T 28448-2019 网络安全等级保护测评要求》 密码应用安全性相关标准参考《GB/T 39786-2021 信息系统密码应用基本要求》和《GM/T 0115-2021 信息系统密码应用测评要求》 1身份鉴别 1.1对登录的…...

【Hello Go】Go语言函数
Go语言函数 定义格式自定义函数无参数无返回值有参数无返回值不定参数列表有返回值有多个返回值 函数类型匿名函数和闭包延迟调用deferdefer和匿名函数结合使用 获取命令行参数 定义格式 函数是构成代码执行的逻辑结构 在Go语言中 函数的基本组成为 func关键字函数名参数列表…...
)
docker小技能:容器IP和宿主机IP一致( Nacos服务注册ip为内网ip,导致Fegin无法根据服务名访问 )
文章目录 I 预备知识1.1 Docker组成1.2 命名空间 (进程隔离)1.3 Docker的网络模式1.4 容器IP和宿主机IP一致1.5 容器时间和服务器时间的一致性II 常用命令2.1 案例:流水线docker 部署2.2 删除没有使用的镜像2.3 shell 不打印错误输出2.4 阿里云流水线/jenkins忽略shell步骤中…...

Android笔记:震动实现
Android震动可以通过Vibrator类实现。以下是一个简单的代码示例: 注:需要注意,震动需要在子线程中执行,所以应该在一个异步任务中执行上述代码,或者使用Handler等机制将其发送到主线程中进行执行。 1、在AndroidMani…...

CSDN每日一题学习训练——Java版(二叉搜索树迭代器、二叉树中的最大路径和、按要求补齐数组)
版本说明 当前版本号[20231115]。 版本修改说明20231115初版 目录 文章目录 版本说明目录二叉搜索树迭代器题目解题思路代码思路参考代码 二叉树中的最大路径和题目解题思路代码思路参考代码 按要求补齐数组题目解题思路代码思路参考代码 二叉搜索树迭代器 题目 实现一个二…...

WPF中有哪些布局方式和对齐方法
在WPF (Windows Presentation Foundation) 中,你可以使用多种方式来进行元素的对齐,这主要取决于你使用的布局容器类型。以下是一些最常用的对齐方式: HorizontalAlignment 和 VerticalAlignment 在大多数WPF元素上,你可以使用 Ho…...
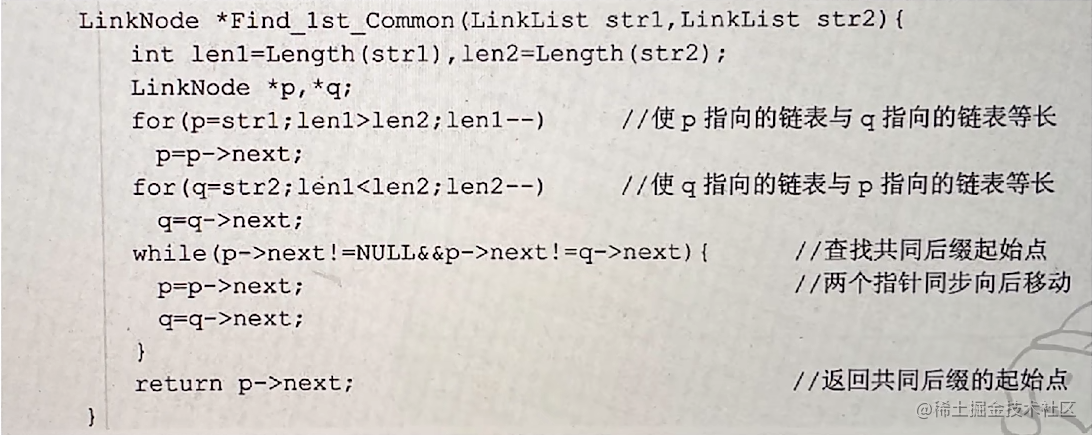
【2012年数据结构真题】
41题 (1) 最坏情况下比较的总次数 对于长度分别为 m,n 的两个有序表的合并过程,最坏情况下需要一直比较到两个表的表尾元素,比较次数为 mn-1 次。已知需要 5 次两两合并,故设总比较次数为 X-5, X 就是以 N…...
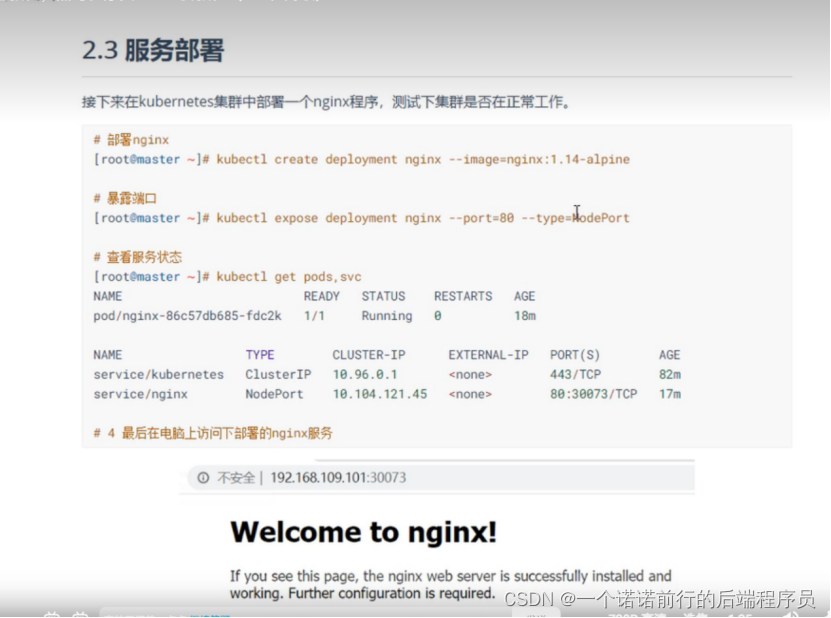
k8s_base
应用程序在服务器上部署方式的演变,互联网发展到现在为止 应用程序在服务器上部署方式 历经了3个时代1. 传统部署 优点简单 缺点就是操作系统的资源是有限制的,比如说操作系统的磁盘,内存 比如说我8G,部署了3个应用程序,当有一天…...
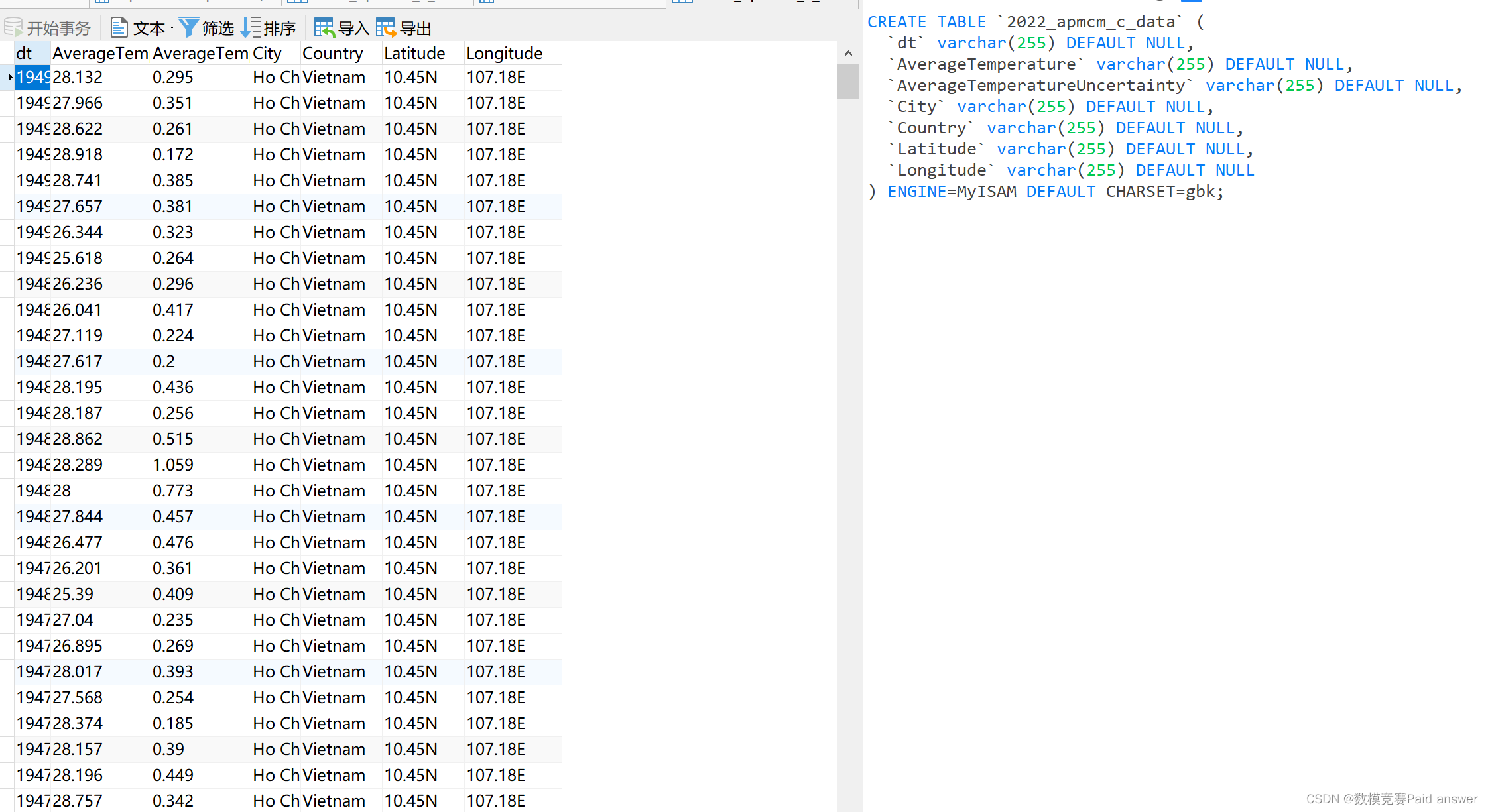
2023年亚太杯APMCM数学建模大赛数据分析题MySQL的使用
2023年亚太杯APMCM数学建模大赛 以2022年C题全球变暖数据为例 数据分析: 以2022年亚太杯数学建模C题为例,首先在navicat建数据库然后右键“表”,单击“导入向导”,选择对应的数据格式及字符集进行数据导入 导入之后,…...

自学SLAM(8)《第四讲:相机模型与非线性优化》作业
前言 小编研究生的研究方向是视觉SLAM,目前在自学,本篇文章为初学高翔老师课的第四次作业。 文章目录 前言1.图像去畸变2.双目视差的使用3.矩阵微分4.高斯牛顿法的曲线拟合实验 1.图像去畸变 现实⽣活中的图像总存在畸变。原则上来说,针孔透…...

STL—next_permutation函数
目录 1.next_permutation函数的定义 2.简单使用 2.1普通数组全排列 2.2结构体全排列 2.3string 3.补充 1.next_permutation函数的定义 next_permutation函数会按照字母表顺序生成给定序列的下一个较大的排列,直到整个序列为降序为止。与其相对的还有一个函数—…...

Mysql 三种不使用索引的情况
目录 1. 查询语句中使用LIKE关键字 例 1 2. 查询语句中使用多列索引 例 2 3. 查询语句中使用OR关键字 例 3 总结 索引可以提高查询的速度,但并不是使用带有索引的字段查询时,索引都会起作用。使用索引有几种特殊情况,在这些情况下&…...

Ladybug 全景相机, 360°球形成像,带来全方位的视觉体验
360无死角全景照片总能给人带来强烈的视觉震撼,有着大片的既视感。那怎么才能拍出360球形照片呢?它的拍摄原理是通过图片某个点位为中心将图片其他部位螺旋式、旋转式处理,从而达到沉浸式体验的效果。俗话说“工欲善其事,必先利其…...

centos 6.10 安装swig 4.0.2
下载地址 解压文件。 执行下面命令 cd swig-4.0.2 ./configure --prefix/usr/local/swig-4.0.2 make && make install...

mask: rle, polygon
RLE 编码 RLE(Run-Length Encoding)是一种简单而有效的无损数据压缩和编码方法。它的基本思想是将连续相同的数据值序列用一个值和其连续出现的次数来表示,从而减少数据的存储或传输量。 在图像分割领域(如 COCO 数据集中&#…...

【JMeter】JMeter压测过程中遇到Non HTTP response code错误解决方案
压测过程中并发逐步加大后遇到60%的错误率,查看错误是JMeter网页版聚合报告中显示 Non HTTP response code: java.net.NoRouteToHostException/Non HTTP response message: Cannot assign requested address (Address not available) 这是第二次遇到,故…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...