CSDN每日一题学习训练——Java版(二叉搜索树迭代器、二叉树中的最大路径和、按要求补齐数组)
版本说明
当前版本号[20231115]。
| 版本 | 修改说明 |
|---|---|
| 20231115 | 初版 |
目录
文章目录
- 版本说明
- 目录
- 二叉搜索树迭代器
- 题目
- 解题思路
- 代码思路
- 参考代码
- 二叉树中的最大路径和
- 题目
- 解题思路
- 代码思路
- 参考代码
- 按要求补齐数组
- 题目
- 解题思路
- 代码思路
- 参考代码
二叉搜索树迭代器
题目
实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
BSTIterator(TreeNode root) 初始化 BSTIterator 类的一个对象。BST 的根节点 root 会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。
boolean hasNext() 如果向指针右侧遍历存在数字,则返回 true ;否则返回 false 。
int next()将指针向右移动,然后返回指针处的数字。
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
示例:
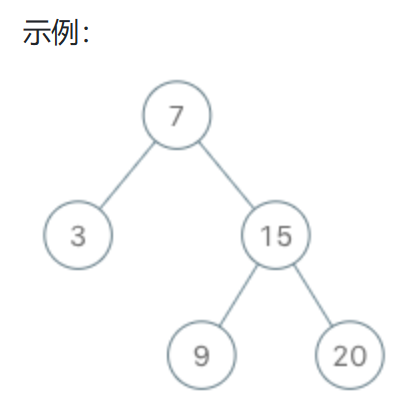
输入
[“BSTIterator”, “next”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”, “next”, “hasNext”]
[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []]
输出
[null, 3, 7, true, 9, true, 15, true, 20, false]
解释
BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]);
bSTIterator.next(); // 返回 3
bSTIterator.next(); // 返回 7
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 9
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 15
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 20
bSTIterator.hasNext(); // 返回 False
提示:
树中节点的数目在范围 [1, 105] 内
0 <= Node.val <= 106
最多调用 105 次 hasNext 和 next 操作
进阶:
你可以设计一个满足下述条件的解决方案吗?next() 和 hasNext() 操作均摊时间复杂度为 O(1) ,并使用 O(h) 内存。其中 h 是树的高度。
解题思路
- 初始化一个空栈,用于存储中序遍历过程中的节点。
- 从根节点开始,将所有左子节点依次入栈,直到遇到没有左子节点的节点。
- 当栈不为空时,弹出栈顶元素,将其值返回,并将其右子节点依次入栈,直到遇到没有右子节点的节点。
- 重复步骤2和3,直到栈为空。
代码思路
-
这段代码实现了一个二叉搜索树的迭代器。
-
首先定义了一个TreeNode类,表示二叉树的节点,包含一个整数值val和左右子节点left、right。
// 定义一个二叉树节点类 public class TreeNode {int val; // 节点值TreeNode left; // 左子节点TreeNode right; // 右子节点// 构造函数,初始化节点值TreeNode(int x) {val = x;} } -
然后定义了一个BSTIterator类,用于实现二叉搜索树的迭代器。这个迭代器使用了一个LinkedList来存储遍历过程中的节点。
// 定义一个二叉搜索树迭代器类 class BSTIterator {LinkedList<TreeNode> stack = new LinkedList<>(); // 使用链表存储遍历过程中的节点 -
在构造函数中,将根节点root及其左子树的所有节点依次入栈。这样,栈顶元素就是当前最小的节点。
// 构造函数,接收根节点作为参数,将根节点及其左子树的所有节点依次入栈public BSTIterator(TreeNode root) {TreeNode cur = root;while (cur != null) {stack.push(cur);cur = cur.left;}} -
next()方法用于获取下一个节点的值。首先弹出栈顶元素,然后将该节点的右子树及其左子树的所有节点依次入栈。这样,下一次调用next()方法时,栈顶元素就是当前最小的节点。
// next() 方法,返回下一个节点的值public int next() {TreeNode n = stack.pop(); // 弹出栈顶元素TreeNode cur = n.right; // 获取弹出节点的右子节点while (cur != null) {stack.push(cur); // 将右子节点及其左子树的所有节点依次入栈cur = cur.left;}return n.val; // 返回弹出节点的值} -
hasNext()方法用于判断是否还有下一个节点。只要栈不为空,就说明还有下一个节点。
// hasNext() 方法,判断是否还有下一个节点public boolean hasNext() {return !stack.isEmpty(); // 如果栈不为空,则说明还有下一个节点}
参考代码
public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) {val = x;}
}
class BSTIterator {LinkedList<TreeNode> stack = new LinkedList<>();public BSTIterator(TreeNode root) {TreeNode cur = root;while (cur != null) {stack.push(cur);cur = cur.left;}}public int next() {TreeNode n = stack.pop();TreeNode cur = n.right;while (cur != null) {stack.push(cur);cur = cur.left;}return n.val;}public boolean hasNext() {return !stack.isEmpty();}
}
/*** Your BSTIterator object will be instantiated and called as such:* BSTIterator obj = new BSTIterator(root);* int param_1 = obj.next();* boolean param_2 = obj.hasNext();*/
二叉树中的最大路径和
题目
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
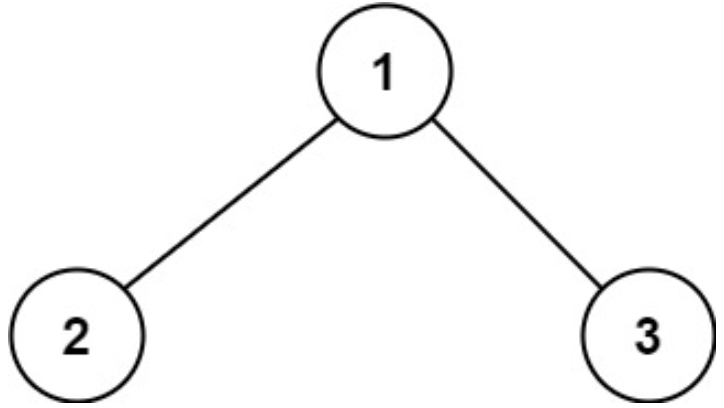
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:
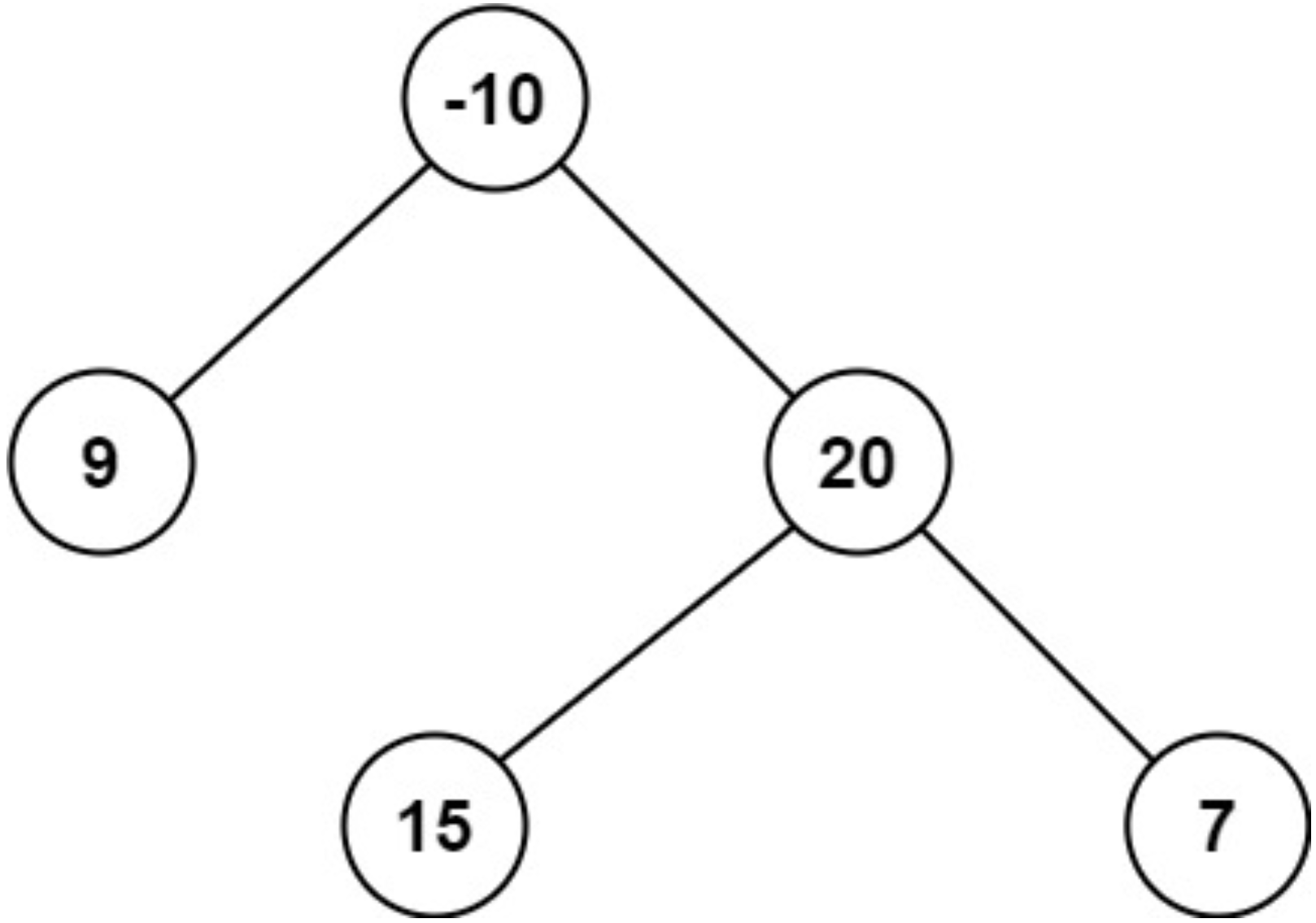
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
提示:
树中节点数目范围是 [1, 3 * 104]
-1000 <= Node.val <= 1000
解题思路
- 初始化一个全局变量 maxSum,用于存储最大路径和,初始值为 Integer.MIN_VALUE。
- 定义一个递归函数 maxGain,输入参数为 TreeNode 类型的节点 node。
- 如果节点为空,返回 0。
- 计算左子树的最大增益 leftGain,如果小于等于 0,则取 0。
- 计算右子树的最大增益 rightGain,如果小于等于 0,则取 0。
- 计算新路径的价格 priceNewpath,即当前节点的值加上左右子树的最大增益。
- 更新 maxSum,将其设置为 maxSum 和 priceNewpath 中的较大值。
- 返回当前节点的值加上左右子树中增益较大的那个值。
- 在 maxPathSum 函数中调用 maxGain 函数,并返回 maxSum。
代码思路
-
首先定义了一个名为Solution的类,其中包含一个名为maxSum的整数变量,用于存储最大路径和。
// 定义一个名为Solution的类 class Solution {// 初始化最大路径和为整数最小值int maxSum = Integer.MIN_VALUE;// 定义一个名为maxPathSum的方法,接收一个TreeNode类型的参数root,返回一个整数值 -
maxPathSum(TreeNode root):这是主方法,它接受一个二叉树的根节点作为参数,并返回最大路径和。在这个方法中,首先调用maxGain方法来计算最大路径和,然后返回maxSum变量的值。
public int maxPathSum(TreeNode root) {// 调用maxGain方法计算最大路径和maxGain(root);// 返回最大路径和return maxSum;} -
maxGain(TreeNode node):这是一个辅助方法,用于递归地计算以给定节点为起点的最大路径和。它首先检查节点是否为空,如果为空则返回0。
// 定义一个名为maxGain的方法,接收一个TreeNode类型的参数node,返回一个整数值public int maxGain(TreeNode node) {// 如果节点为空,返回0if (node == null) {return 0;} -
然后,它分别计算左子树和右子树的最大增益(即不选择该子树的情况下的最大路径和),并将它们与当前节点的值相加得到新路径的价格。
// 计算左子树的最大增益,如果小于0则取0int leftGain = Math.max(maxGain(node.left), 0);// 计算右子树的最大增益,如果小于0则取0int rightGain = Math.max(maxGain(node.right), 0);// 计算新路径的价格int priceNewpath = node.val + leftGain + rightGain; -
接着,它将新路径的价格与当前的最大路径和进行比较,更新maxSum变量的值。最后,它返回当前节点的值加上左右子树中增益较大的那个值,作为以当前节点为起点的最大路径和。
// 更新最大路径和maxSum = Math.max(maxSum, priceNewpath); -
通过递归地遍历整个二叉树,该方法可以找到从根节点到任意叶子节点的最大路径和,并将其存储在maxSum变量中。最终,maxPathSum方法将返回这个最大路径和。
// 返回当前节点的值加上左右子树中增益较大的那个值return node.val + Math.max(leftGain, rightGain);
参考代码
这段代码是二叉树路径和的最大值问题。
class Solution {int maxSum = Integer.MIN_VALUE;public int maxPathSum(TreeNode root) {maxGain(root);return maxSum;}public int maxGain(TreeNode node) {if (node == null) {return 0;}int leftGain = Math.max(maxGain(node.left), 0);int rightGain = Math.max(maxGain(node.right), 0);int priceNewpath = node.val + leftGain + rightGain;maxSum = Math.max(maxSum, priceNewpath);return node.val + Math.max(leftGain, rightGain);}
}
按要求补齐数组
题目
给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
输入: nums =
[1,3]
, n =
6
输出: 1
解释:
根据 nums 里现有的组合
[1], [3], [1,3]
,可以得出
1, 3, 4
。
现在如果我们将
2
添加到 nums 中, 组合变为:
[1], [2], [3], [1,3], [2,3], [1,2,3]
。
其和可以表示数字
1, 2, 3, 4, 5, 6
,能够覆盖
[1, 6]
区间里所有的数。
所以我们最少需要添加一个数字。

示例 2:
输入: nums =
[1,5,10]
, n =
20
输出: 2
解释: 我们需要添加
[2, 4]
。
示例 3:
输入: nums =
[1,2,2]
, n =
5
输出: 0

解题思路
- 初始化 patches 为 0,表示需要补充的数字个数;i 为 0,表示当前处理的 nums 数组中的索引;miss 为 1,表示当前未覆盖的数字范围的最小值。
- 当 miss <= n 时,执行循环: a. 如果 i < nums.length 且 nums[i] <= miss,说明可以用 nums[i] 来表示 miss,将 miss 加上 nums[i],并将 i 向右移动一位。 b. 否则,说明需要补充一个数字,使得 miss 可以表示为两个数的和,即 miss = miss + miss。将 miss 加上 miss,并将 patches 加 1。
- 返回 patches。
代码思路
-
初始化变量
patches为0,表示已经使用的补丁数量;变量i为0,表示当前处理的nums数组中的索引;变量miss为1,表示当前未覆盖的数字范围的最小值。// 初始化变量patches为0,i为0,miss为1int patches = 0, i = 0;long miss = 1; -
当
miss小于等于n时,执行循环。这是因为我们需要确保覆盖从1到n的所有数字。 -
在循环中,首先检查
i是否小于nums的长度且nums[i]小于等于miss。如果是,则说明我们可以使用nums[i]来扩展当前的覆盖范围,因此将miss加上nums[i]并将i加1。// 当miss小于等于n时,执行循环while (miss <= n) {// 如果i小于nums的长度且nums[i]小于等于miss,则将miss加上nums[i]并将i加1if (i < nums.length && nums[i] <= miss)miss += nums[i++]; -
如果上述条件不满足,说明我们需要增加一个新的补丁来扩展当前的覆盖范围。此时,将
miss加上miss(即当前未覆盖的数字范围的最小值),并将patches加1。// 否则,将miss加上miss,并将patches加1else {miss += miss;patches++;} -
循环结束后,返回
patches的值,即所需的最少补丁数量。
// 返回patches的值return patches;
参考代码
这段代码是计算将1到n之间的所有数字都覆盖所需要的最少的补丁数量。
class Solution {public int minPatches(int[] nums, int n) {int patches = 0, i = 0;long miss = 1;while (miss <= n) {if (i < nums.length && nums[i] <= miss)miss += nums[i++];else {miss += miss;patches++;}}return patches;}
}
相关文章:
CSDN每日一题学习训练——Java版(二叉搜索树迭代器、二叉树中的最大路径和、按要求补齐数组)
版本说明 当前版本号[20231115]。 版本修改说明20231115初版 目录 文章目录 版本说明目录二叉搜索树迭代器题目解题思路代码思路参考代码 二叉树中的最大路径和题目解题思路代码思路参考代码 按要求补齐数组题目解题思路代码思路参考代码 二叉搜索树迭代器 题目 实现一个二…...

WPF中有哪些布局方式和对齐方法
在WPF (Windows Presentation Foundation) 中,你可以使用多种方式来进行元素的对齐,这主要取决于你使用的布局容器类型。以下是一些最常用的对齐方式: HorizontalAlignment 和 VerticalAlignment 在大多数WPF元素上,你可以使用 Ho…...
【2012年数据结构真题】
41题 (1) 最坏情况下比较的总次数 对于长度分别为 m,n 的两个有序表的合并过程,最坏情况下需要一直比较到两个表的表尾元素,比较次数为 mn-1 次。已知需要 5 次两两合并,故设总比较次数为 X-5, X 就是以 N…...
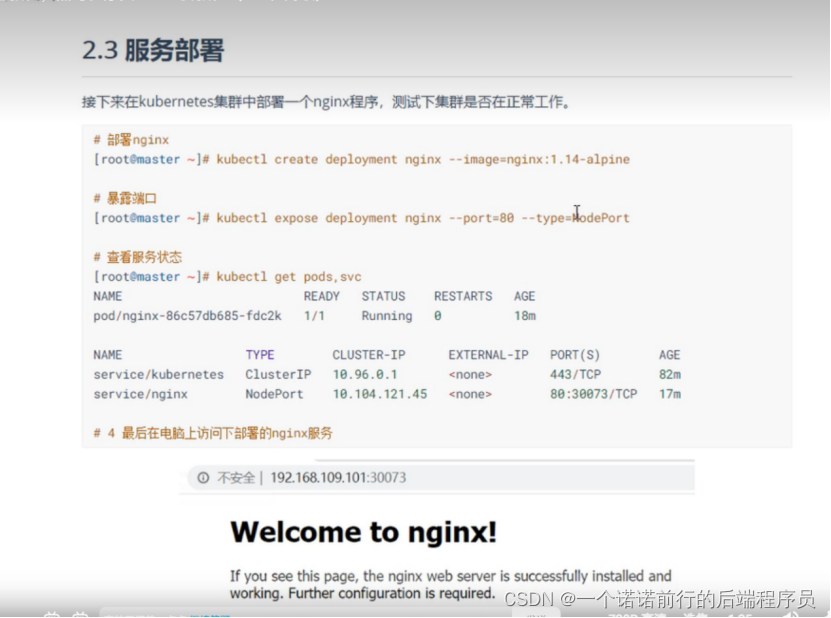
k8s_base
应用程序在服务器上部署方式的演变,互联网发展到现在为止 应用程序在服务器上部署方式 历经了3个时代1. 传统部署 优点简单 缺点就是操作系统的资源是有限制的,比如说操作系统的磁盘,内存 比如说我8G,部署了3个应用程序,当有一天…...
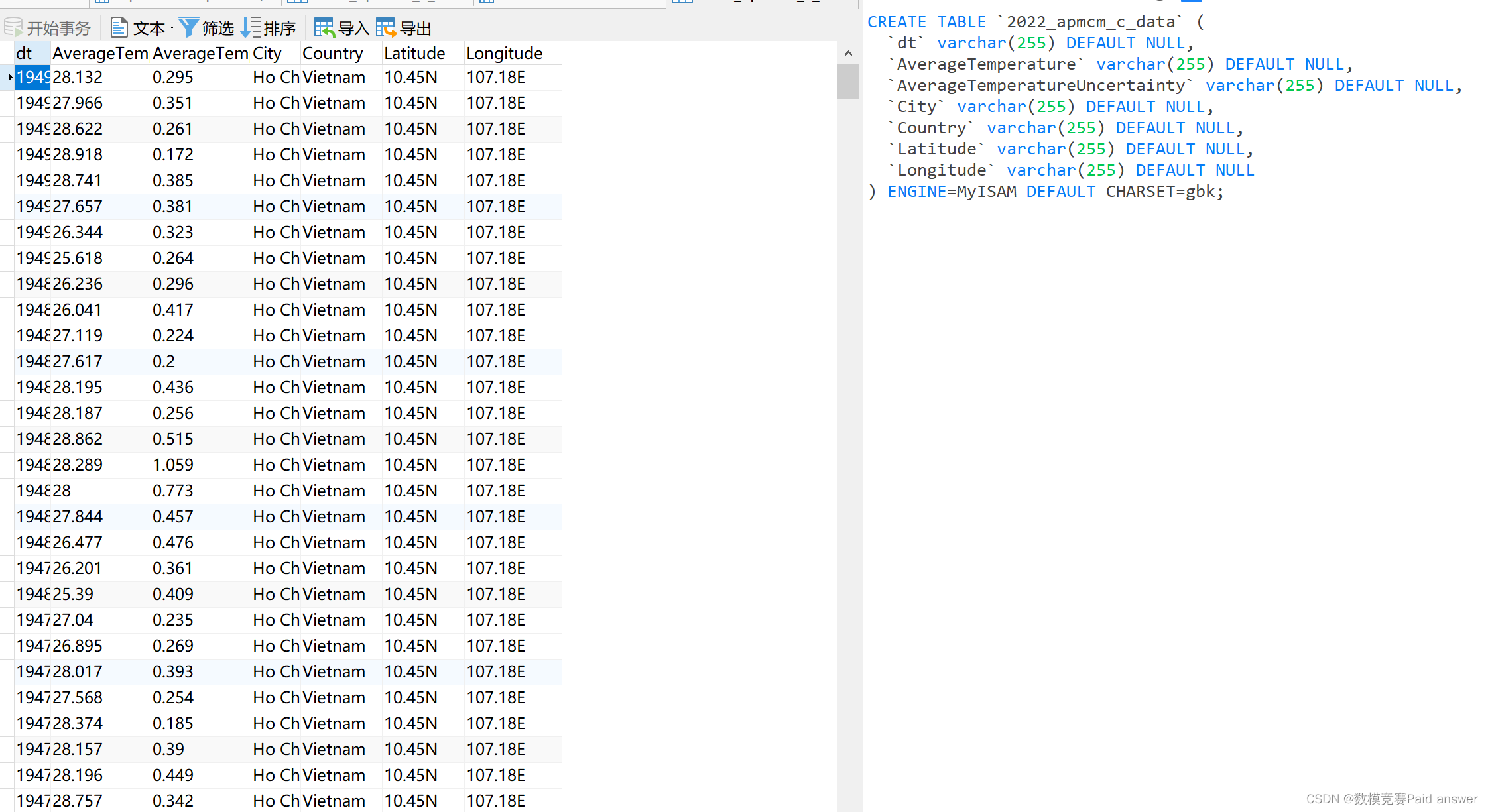
2023年亚太杯APMCM数学建模大赛数据分析题MySQL的使用
2023年亚太杯APMCM数学建模大赛 以2022年C题全球变暖数据为例 数据分析: 以2022年亚太杯数学建模C题为例,首先在navicat建数据库然后右键“表”,单击“导入向导”,选择对应的数据格式及字符集进行数据导入 导入之后,…...

自学SLAM(8)《第四讲:相机模型与非线性优化》作业
前言 小编研究生的研究方向是视觉SLAM,目前在自学,本篇文章为初学高翔老师课的第四次作业。 文章目录 前言1.图像去畸变2.双目视差的使用3.矩阵微分4.高斯牛顿法的曲线拟合实验 1.图像去畸变 现实⽣活中的图像总存在畸变。原则上来说,针孔透…...

STL—next_permutation函数
目录 1.next_permutation函数的定义 2.简单使用 2.1普通数组全排列 2.2结构体全排列 2.3string 3.补充 1.next_permutation函数的定义 next_permutation函数会按照字母表顺序生成给定序列的下一个较大的排列,直到整个序列为降序为止。与其相对的还有一个函数—…...

Mysql 三种不使用索引的情况
目录 1. 查询语句中使用LIKE关键字 例 1 2. 查询语句中使用多列索引 例 2 3. 查询语句中使用OR关键字 例 3 总结 索引可以提高查询的速度,但并不是使用带有索引的字段查询时,索引都会起作用。使用索引有几种特殊情况,在这些情况下&…...

Ladybug 全景相机, 360°球形成像,带来全方位的视觉体验
360无死角全景照片总能给人带来强烈的视觉震撼,有着大片的既视感。那怎么才能拍出360球形照片呢?它的拍摄原理是通过图片某个点位为中心将图片其他部位螺旋式、旋转式处理,从而达到沉浸式体验的效果。俗话说“工欲善其事,必先利其…...

centos 6.10 安装swig 4.0.2
下载地址 解压文件。 执行下面命令 cd swig-4.0.2 ./configure --prefix/usr/local/swig-4.0.2 make && make install...

mask: rle, polygon
RLE 编码 RLE(Run-Length Encoding)是一种简单而有效的无损数据压缩和编码方法。它的基本思想是将连续相同的数据值序列用一个值和其连续出现的次数来表示,从而减少数据的存储或传输量。 在图像分割领域(如 COCO 数据集中&#…...

【JMeter】JMeter压测过程中遇到Non HTTP response code错误解决方案
压测过程中并发逐步加大后遇到60%的错误率,查看错误是JMeter网页版聚合报告中显示 Non HTTP response code: java.net.NoRouteToHostException/Non HTTP response message: Cannot assign requested address (Address not available) 这是第二次遇到,故…...

【Kingbase FlySync】评估工具安装及使用
【Kingbase FlySync】评估工具使用 概述准备环境目标资源1.测试虚拟机下载地址包含node1,node22.评估工具下载地址3.exam.sql下载地址 评估工具安装1.上传并解压评估工具安装包2.安装数据库驱动包3.设置环境变量4.node1载入样例信息 收集并阅读node1信息1.收集报告2.阅读报告 收…...

pandas教程:Data Aggregation 数据聚合
文章目录 10.2 Data Aggregation(数据聚合)1 Column-Wise and Multiple Function Application(列对列和多函数应用)2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据) 10.2 Data…...

开启创造力之门:掌握Vue中Slot插槽的使用技巧与灵感
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、s…...

【算法练习Day48】回文子串最长回文子序列
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 回文子串最长回文子序列总结…...
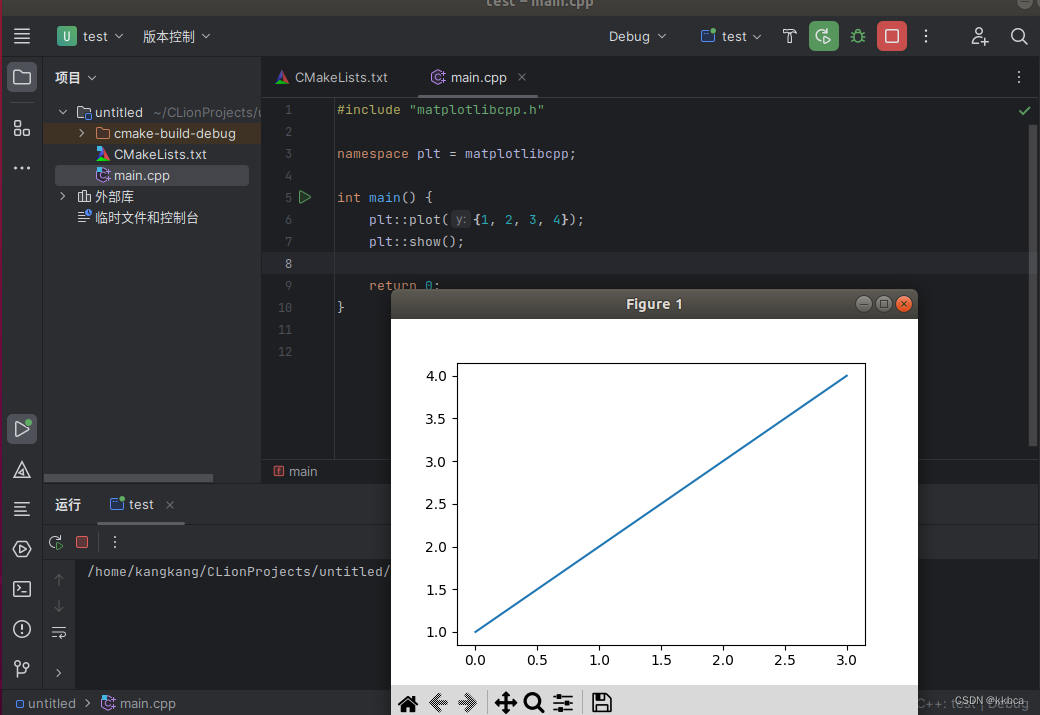
ubuntu下C++调用matplotlibcpp进行画图(超详细)
目录 一、换源 二、安装必要的软件 三、下载matplotlibcpp 四、下载anaconda 1.anaconda下载 2.使用anaconda配置环境 五、下载CLion 1.下载解压CLion 2.替换jbr文件夹 3.安装CLion 4.激活CLion 5.CLion汉化 6.Clion配置 六、使用CLion运行 七、总结 我的环…...

芯科科技推出新的8位MCU系列产品,扩展其强大的MCU平台
新的BB5系列为简单应用提供更多开发选择 中国,北京 - 2023年11月14日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ:SLAB),今日宣布…...

Flink CDC
1、Flink CDC的介绍: 是一种技术,可以帮助我们实时的捕获数据库中数据的变化,并将这些变化的数据以流的形式传输到其他的系统中进行处理和存储。 2、Flink CDC的搭建: 1、开启mysql的binlog功能: # 1、修改mysql配置…...

数据结构-链表的简单操作代码实现3-LinkedList【Java版】
写在前: 本篇博客主要介绍关于双向链表的一些简答操作实现,其中有有部分代码的实现和前两篇博客中的单向链表是相类似的。例如:查找链表中是否包含关键字key、求链表的长度等。 其余的涉及到prev指向的需要特别注意,区分和单向链表之间的差异…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...