【星海随笔】redis 解析
redis
非关系型数据库
支持事务,操作都是原子性
所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。
redis-server:顾名思义,redis服务
redis-cli:redis client,提供一个redis客户端,以供连接到redis服务,进行增删改查等操作
redis-sentinel:redis实例的监控管理、通知和实例失效备援服务
redis-benchmark:redis的性能测试工具
redis-check-aof:若以AOF方式的持久化,当意外发生时用来快速修复
redis-check-rdb:若以RDB方式的持久化,当意外发生时用来快速修复
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API1。6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字。当Antirez为Redis选择一个数字作为默认端口号时,Antirez把"MERZ"在手机键盘上对应的数字6379拿来用了。
基础数据类型
五种类型
string(字符串) 基本形式:key value
hash(哈希)
list (列表)
set (集合)
zset (sorted set:有序集合)
基础类型可以配合watch进行操作
WATCH 机制:使用 WATCH 监视一个或多个 key , 跟踪 key 的 value 修改情况,如果有key 的 value 值在事务 EXEC 执行之前被修改了,整个事务被取消。EXEC 返回提示信息,表示事务已经失败。
设置过期时间
expire <key> <num> #设置key的有限期
ttl <key> #获取剩余多长时间
配置文件中hz设置定期删除时间
string
最大存储为512MB。
String类型除了可以存字符串也可以是int 和 float。
方法:
get <key> #根据key获取volume
set <key> <volume> #设置key对应的volume
setnx <key> <value> #当key不存在时才设置
setex <key> <seconds> <value> # 设置key的值并设置过期时间(单位:秒)
psetex <key> <milliseconds> <value> #设置key的值并设置过期时间(单位:毫秒)
del #删除
append <key> <value> #将value追加到key的值的后面,即将该值与原来的值合并。
#mget //多个同时获取
#mset //多个同时设置
strlen <key> #获取字符串的长度
getrange <key> <start> <end> #获取key值对应的volume一段区间的值。volume 0 位开始计数。
incr <key> #使int自增一个数字。
incrby <key> <num> #使key增长指定的数字。
decr <key>
decrby <key> <num>
redis访问速度块、支持的数据类型比较丰富,所以redis很适合用来存储热点数据
设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
数据库查询注意事项:
不推荐使用keys 命令去模糊匹配
Redis从2.8.0版本开始提供scan命令,这个命令可以以渐进的方式,分多次遍历整个数据库,并返回匹配给定模式的键。scan家族相关命令有scan,sscan,hscan和zscan,
HASH
每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表
形式如: value=[{field1,value1},…{fieldN,valueN}]。
Hash 是一个键值对(key - value)集合
如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置)
所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构
# 删除哈希表key中的field键值
HDEL key field [field ...] # 返回哈希表key中field的数量
HLEN key
# 返回哈希表key中所有的键值
HGETALL key # 为哈希表key中field键的值加上增量n
HINCRBY key field n 设置hash值
HSET <hash_key> <dict_key> <dict_val> [field value ...]
将哈希表key的域field的值设置为value,返回值为新创建的field域的个数,对于已经存在的域进行了value的覆写,是不计算在返回值中的。获取hash值
HGET <hash_key> <dict_key>
获取指定的hash fieldHMGET <hash_key> <dict_key> [field ...]
获取全部指定的hash filedHMSET key field value [field value ...]
同时设置hash的多个field递增某一个域的值
HINCRBY key field increment
将指定的hash filed 加上给定值, 如果filed不是integer则报错判断某一个域是否存在
HEXISTS key field
测试指定field是否存在删除域
HDEL key field [field ...]
删除指定的hash field获取域的数量
HLEN key
返回指定hash的field数量获取所有的域名
HKEYS key
返回hash的所有field获取所有域的值
HVALS key
返回hash的所有value获取所有域名和值
HGETALL key
list
List在在内存中按照一个name对应一个List来存储
在key对应的list添加字符串元素,L:代表左Push,R:代表右Push,成功返回list的长度,失败返回0。
由于redis类库中没有提供对列表元素的增量迭代,如果想要循环<key>对应的列表的所有元素,那么就需要:
获取name对应的所有列表、循环列表
添加 rpush、lpush、linsert
修改 lset
删除 lpop、rpop、lrem、ltrim
查询 lrange、lindex、llen
阻塞操作 blpop、brpop
弹出/ rpoplpush
r.lpush(<key>, 11,22,33)
# 保存顺序为: 33,22,11
lpushx(<key>,<value>) #添加到列表的最左边
lpop <key> [count] #删除某个元素
r.lset(<key>, <index>, <value>) #对某个值重新赋值
llen(<key>) #获取长度
print(re.lrange( <name>,<start>,<end> )) #列表分片获取数据
lindex(<key>, index) #根据索引查找元素
如果列表非常大,那么就有可能在第一步时就将程序的内存撑爆,所有有必要自定义一个增量迭代的功能:
迭代遍历列表
import redis
conn=redis.Redis(host='127.0.0.1',port=6379)
# conn.lpush('test',*[1,2,3,4,45,5,6,7,7,8,43,5,6,768,89,9,65,4,23,54,6757,8,68])
# conn.flushall()
def scan_list(name,count=2):index=0while True:data_list=conn.lrange(name,index,count+index-1)if not data_list:returnindex+=countfor item in data_list:yield item
print(conn.lrange('test',0,100))
for item in scan_list('test',5):print('---')print(item)
集合set
Set命令用于存储一个或多个字符串值到一个键中。如果该键不存在,则会创建一个新键。
Set数据结构是dict字典,字典是用哈希表实现的。
SET <key> <value>
sadd <key> <value1> <value2>.. 添加一个或多个元素到集合中
smembers <key> 取出该集合的所有值
simembers <key> <value> 判断集合中是否含有该<value>值
scard <key> 返回该集合的元素个数
srem <key><value1><value> 删除集合中和某几个元素
spop <key> 随机从该集合吐出一个元素
srandmember <key> <n> 随机从该集合中取出n个值,不会从集合中删除
smove <source> <destination> <value> 把集合中一个值从一个集合移动到另一个集合
sinter <key1> <key2> 返回两个集合的交集元素
sunion <key1> <key2> 返回两个集合并集元素
sdiff <key1> <key2> 返回两个集合中的差集元素 (key1中的,不包含key2中的)
Redis的Set命令是一种强大的数据存储和操作工具,可以用于存储、查询和更新不重复的元素。通过合理的使用Set命令,可以实现高效、可靠和灵活的数据存储和操作,满足不同业务需求的要求。
排序集合是唯一元素(比如:用户id)的集合,每个元素按分数排序,这样可以快速的按分数来检索元素
有序集合zset
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
zrangebyscore key minmax [withscores] [limit offset count]返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。 zrevrangebyscore key maxmin [withscores] [limit offset count] 同上,改为从大到小排列。 zincrby <key> <increment> <value>为元素的score加上增量zcount <key> <min> <max>统计该集合,分数区间内的元素个数 zrank <key> <value>返回该值在集合中的排名,从0开始。
redis 淘汰策略
- 设置redis最大内存配置-maxmemory
移除规则可以通过maxmemory-policy来指定。
设置达到最大内存时的移除策略-maxmemory-policy
volatile-lru :使用LRU算法移除key,只对设置了过期时间的Key进行淘汰。(最近最少使用策略)
allkeys-lru: 在所有集合key中,使用LRU算法移除key。
volatile-lfu :使用LFU算法移除key,只对设置了过期时间的Key进行淘汰。。
allkeys-lfu :在所有集合key中,使用LFU算法移除key。
volatile-random :只对设置了过期时间的Key进行淘汰,淘汰算法为随机淘汰。
allkeys-random: 在所有集合key中,移除随机的key。
volatile-ttl: 移除那些TTL值最小的key,即那些最近要过期的key。
noeviction: 永不删除key,针对写操作,达到最大内存再进行数据装入时会返回错误。
设置样本数量-maxmemory-samples
持久化
AOF 持久化
Redis默认情况是不开启AOF的
重启时再重新执行AOF文件中的命令来恢复数据。它主要解决数据持久化的实时性问题。
AOF是执行完命令后才记录日志的。为什么不先记录日志再执行命令呢?
这是因为Redis在向AOF记录日志时,不会先对这些命令进行语法检查,如果先记录日志再执行命令,日志中可能记录了错误的命令,Redis使用日志回复数据时,可能会出错。正是因为执行完命令后才记录日志,所以不会阻塞当前的写操作。但是会存在两个风险:
- 更执行完命令还没记录日志时,宕机了会导致数据丢失
- AOF不会阻塞当前命令,但是可能会阻塞下一个操作。
这两个风险最好的解决方案是折中妙用AOF机制的三种写回策略 appendfsync:
always,同步写回,每个子命令执行完,都立即将日志写回磁盘。
everysec,每个命令执行完,只是先把日志写到AOF内存缓冲区,每隔一秒同步到磁盘。
no:只是先把日志写到AOF内存缓冲区,有操作系统去决定何时写入磁盘。
AOF优点:
数据保证:我们可以设置fsync策略,一般默认是everysec,也可以设置每次写入追加,所以即使服务死掉了,也最多丢失一秒数据
自动缩小:当aof文件大小到达一定程度的时候,后台会自动的去执行aof重写,此过程不会影响主进程,重写完成后,新的写入将会写到新的aof中,旧的就会被删除掉。但是此条如果拿出来对比rdb的话还是没有必要算成优点,只是官网显示成优点而已。
RDB持久化
RDB,就是把内存数据以快照的形式保存到磁盘上。和AOF相比,它记录的是某一时刻的数据,并不是操作。
RDB持久化,是指在指定的时间间隔内,执行指定次数的写操作,将内存中的数据集快照写入磁盘中,它是Redis默认的持久化方式。执行完操作后,在指定目录下会生成一个dump.rdb文件,Redis 重启的时候,通过加载dump.rdb文件来恢复数据。
rdb的优点:
体积更小:相同的数据量rdb数据比aof的小,因为rdb是紧凑型文件。
恢复更快:因为rdb是数据的快照,基本上就是数据的复制,不用重新读取再写入内存。
性能更高:父进程在保存rdb时候只需要fork一个子进程,无需父进程的进行其他io操作,也保证了服务器的性能。
rdb的缺点:
故障丢失:因为rdb是全量的,我们一般是使用shell脚本实现30分钟或者1小时或者每天对redis进行rdb备份,(注,也可以是用自带的策略),但是最少也要5分钟进行一次的备份,所以当服务死掉后,最少也要丢失5分钟的数据。
耐久性差:相对aof的异步策略来说,因为rdb的复制是全量的,即使是fork的子进程来进行备份,当数据量很大的时候对磁盘的消耗也是不可忽视的,尤其在访问量很高的时候,fork的时间也会延长,导致cpu吃紧,耐久性相对较差。
如何选择RDB和AOF
如果数据不能丢失,RDB和AOF混用
如果只作为缓存使用,可以承受几分钟的数据丢失的话,可以只使用RDB。
如果只使用AOF,优先使用everysec的写回策略。
AOF数据的恢复
通过AOF文件恢复数据1. 使用redis的bgsave命令先备份一份当前的Redis服务端状态redis> BGSAVE2. 用redis-cli命令指定AOF文件并将其还原到Redis数据库中redis-cli -p 6379 –aof-rewrite rewrite.aof上面命令中,port指定Redis服务端口,aof-rewrite指定AOF文件,rewrite.aof指定需要恢复的AOF文件名。3. 使用redis-cli命令进行AOF文件重写redis-cli -p 6379 –aof-rewrite-incremental rewrite.aof上面命令中,port指定Redis服务端口,aof-rewrite-incremental指定AOF文件,rewrite.aof指定需要恢复的AOF文件名。4. 重新启动Redis服务使用redis-cli 重新启动Redis服务:redis-cli -p 6379 –aof-load loader.aof最后,通过Redis服务重启指令 loader.aof 重新加载AOF文件。通过以上步骤,可以快速实现Redis AOF文件的恢复。在Redis数据丢失的情况下,恢复AOF文件是很有效的手段,能够快速恢复丢失的数据。
恢复RDB的数据
redis-cli --rdb rdbfile
redis分布式
redis不同的节点保存不同的数据
redis有四种模式
单机模式、主从模式、哨兵模式、集群模式
在配置主从复制之前,我们需要确保两个Redis主服务器的配置文件(redis.conf)中的以下参数正确设置:
bind: 设置Redis服务器绑定的IP地址;
port: 设置Redis服务器监听的端口号;
daemonize: 将Redis服务器以守护进程方式运行;
pidfile: 设置Redis服务器守护进程的PID文件的路径;
logfile: 设置Redis服务器日志文件的路径;
dbfilename: 设置Redis服务器持久化数据文件的名称。
双主设置
在配置文件中,我们需要将其中一个Redis主服务器设置为另一个Redis主服务器的从服务器。具体操作如下:打开第一个Redis主服务器的配置文件(redis.conf),将以下参数的值修改如下:
slaveof 192.168.0.2 6380
该配置将第一个Redis主服务器设置为第二个Redis主服务器的从服务器。打开第二个Redis主服务器的配置文件(redis.conf),将以下参数的值修改如下:
slaveof 192.168.0.1 6379
该配置将第二个Redis主服务器设置为第一个Redis主服务器的从服务器。
配置主从复制后,我们需要在两个Redis主服务器上分别执行以下命令以启用双向同步:在第一个Redis主服务器上执行以下命令:
redis-cli -h 192.168.0.1 -p 6379
这将连接到第一个Redis主服务器。slaveof no one
这将将第一个Redis主服务器从从服务器转变为主服务器。在第二个Redis主服务器上执行以下命令:
redis-cli -h 192.168.0.2 -p 6380
这将连接到第二个Redis主服务器。slaveof no one
这将将第二个Redis主服务器从从服务器转变为主服务器。
哨兵模式(哨兵要奇数个,建议3节点起步)
Redis_S1 Master 192.168.205.1
Redis_S2 slaves 192.168.205.2
Redis_S3 slaves 192.168.205.3
vim /etc/redis-sentinel.confsentinel monitor mymaster 192.168.205.1 6379 2
# 配置监控主节点的IP、端口号、2代表多少个Sentinel实例认为主服务器不可用,才会触发自动故障转移。sentinel auth-pass mymaster pass123
# 主节点的密码sentinel down-after-milliseconds mymaster 10000
# 指定Sentinel在多长时间内未收到来自主服务器的回复后,将主服务器标记为主观下线。
# 单位为毫秒sentinel parallel-syncs mymaster 1
# 用于指定在自动故障转移期间,最多可以有多少个从服务器同时对新的主服务器进行同步。
# 为1即可
集群管理
https://blog.csdn.net/weixin_47824895/article/details/129891957
cluster nodes
redis-cli --cluster add-node 192.168.136.172:6392 \
192.168.136.172:6389 --cluster-master-id 74d466622c60f66710da4c3d1cc1e2a0d478add3#添加从节点
redis-cli --cluster add-node new_host:new_port \existing_host:existing_port --cluster-slave --cluster-master-id node_id相关文章:

【星海随笔】redis 解析
redis 非关系型数据库 支持事务,操作都是原子性 所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。 redis-server:顾名思义,redis服务 redis-cli:redis client,提供一个redis客户端,…...
鸿蒙:实现两个Page页面跳转
效果展示 这篇博文在《鸿蒙:从0到“Hello Harmony”》基础上实现两个Page页面跳转 1.构建第一个页面 第一个页面就是“Hello Harmony”,把文件名和显示内容都改一下,改成“FirstPage”,再添加一个“Next”按钮。 Entry Compone…...

C#有关里氏替换原则的经典问题答疑
目录 理解创建类型与变量类型很关键 先来理解变量类型。 再来理解创建类型。 有了正确的理解再来看疑问 里氏替换原则是面向对象七大原则中最重要的原则。 语法表现:父类容器装子类对象。 namespace 里氏替换原则 {class GameObject { } class Player : GameO…...
【每日一题】689. 三个无重叠子数组的最大和-2023.11.19
题目: 689. 三个无重叠子数组的最大和 给你一个整数数组 nums 和一个整数 k ,找出三个长度为 k 、互不重叠、且全部数字和(3 * k 项)最大的子数组,并返回这三个子数组。 以下标的数组形式返回结果,数组中…...

“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向
文章目录 每日一句正能量前言什么是大模型的开源与闭源开源与闭源的定义和特点开源的意义开源和闭源的优劣势比较不同的大模型企业,开源、闭源的策略不尽相同。企业在开发垂类模型时选择开源还是闭源大模型开源vs 闭源:两者并非选择题后记 每日一句正能量…...

计算机网络——物理层-信道的极限容量(奈奎斯特公式、香农公式)
目录 介绍 奈氏准则 香农公式 介绍 信号在传输过程中,会受到各种因素的影响。 如图所示,这是一个数字信号。 当它通过实际的信道后,波形会产生失真;当失真不严重时,在输出端还可根据已失真的波形还原出发送的码元…...

【算法挨揍日记】day31——673. 最长递增子序列的个数、646. 最长数对链
673. 最长递增子序列的个数 673. 最长递增子序列的个数 题目解析: 给定一个未排序的整数数组 nums , 返回最长递增子序列的个数 。 注意 这个数列必须是 严格 递增的。 解题思路: 算法思路: 1. 状态表⽰: 先尝试…...
Jmeter做接口测试
1.Jmeter的安装以及环境变量的配置 Jmeter是基于java语法开发的接口测试以及性能测试的工具。 jdk:17 (最新的Jeknins,只能支持到17) jmeter:5.6 官网:http://jmeter.apache.org/download_jmeter.cgi 认识JMeter的目录࿱…...

第14届蓝桥杯青少组python试题解析:23年5月省赛
选择题 T1. 执行以下代码,输出结果是()。 lst "abc" print(lstlst)abcabc abc lstlst abcabc T2. 执行以下代码,输出的结果是()。 age {16,18,17} print(type(sorted(age)))<class set&…...
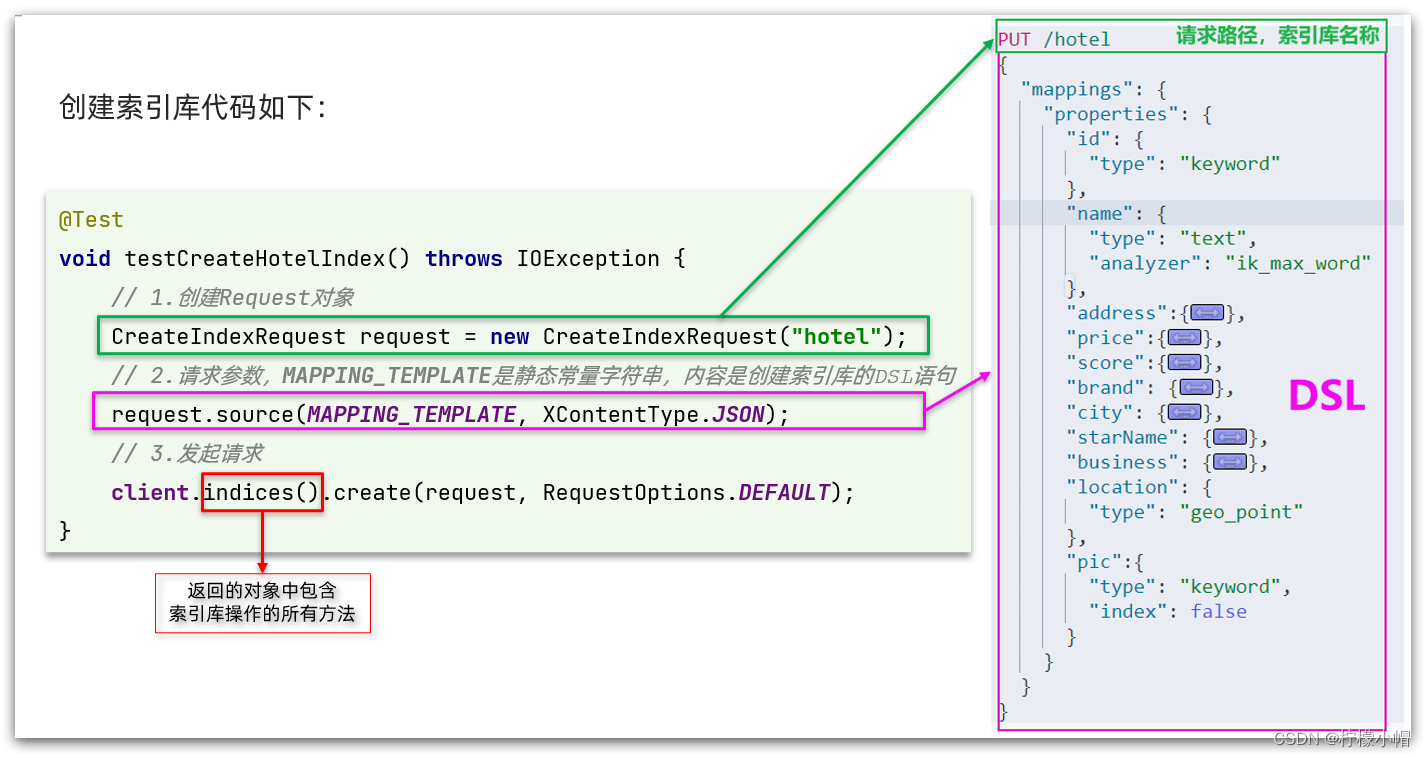
SpringCloud 微服务全栈体系(十四)
第十一章 分布式搜索引擎 elasticsearch 四、RestAPI ES 官方提供了各种不同语言的客户端,用来操作 ES。这些客户端的本质就是组装 DSL 语句,通过 http 请求发送给 ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/…...

【开题报告】基于微信小程序的个人健康管理系统的设计与实现
1.选题背景与意义 在现代社会,人们对健康的关注日益增加。随着生活方式的变化和工作压力的增加,许多人意识到保持良好的身体健康对于提高生活质量和幸福感的重要性。 然而,许多人在日常生活中缺乏对自身健康状况的了解和管理。他们可能没有…...

Swagger笔记
一、导包 <!--引入swagger--> <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version> </dependency> <!--前端的UI界面--> <dependency><…...
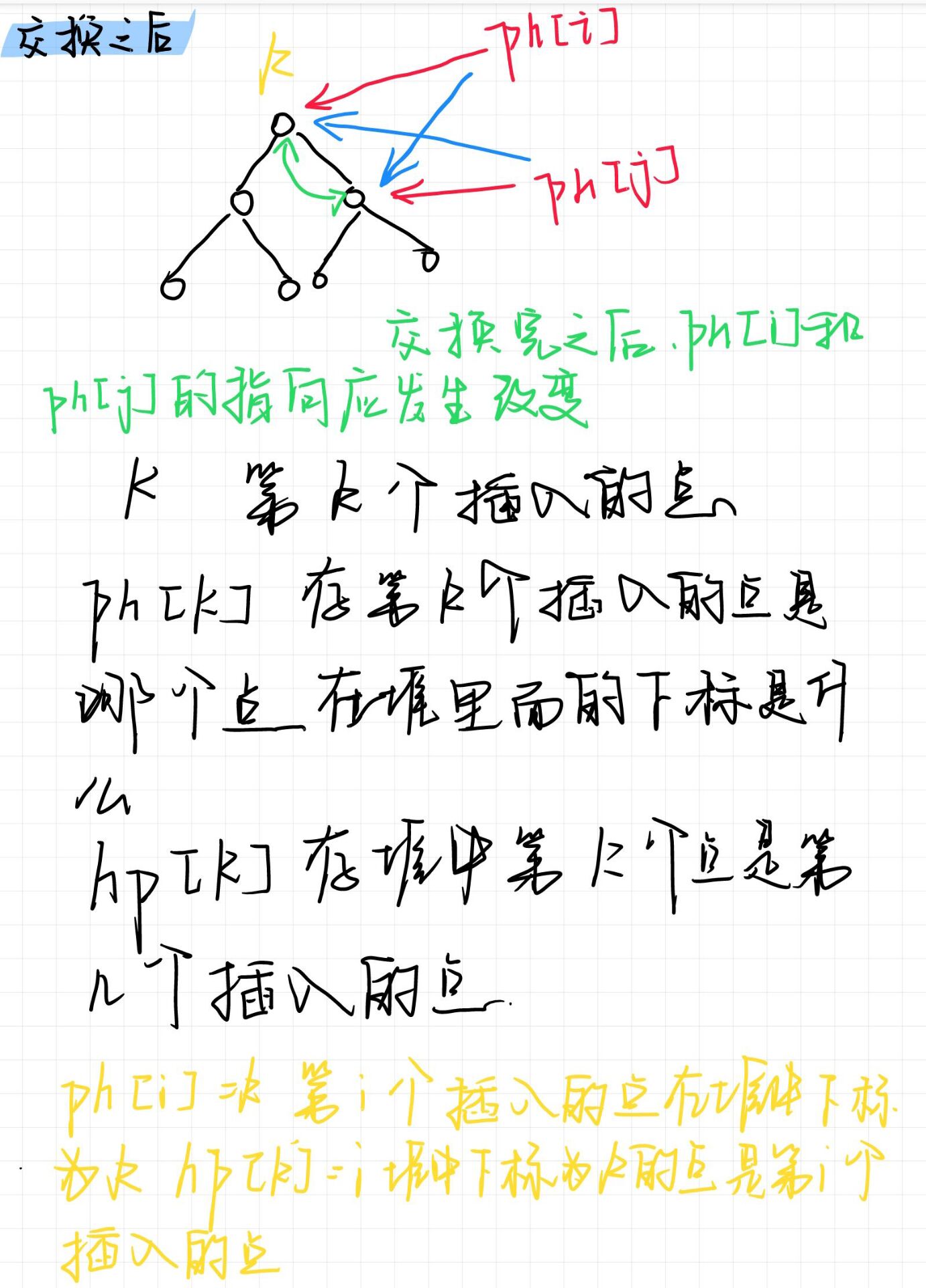
数据结构 堆
手写堆,而非stl中的堆 如何手写一个堆? //将数组建成堆 <O(n) for (int i n / 2;i;i--) //从n/2开始down down(i); 从n/2元素开始down,最下面一层元素的个数是n/2,其余上面的元素的个数是n/2,从最下面一层到最高层…...
将 ONLYOFFICE 文档编辑器与 Node.js 应用集成
我们来了解下,如何将 ONLYOFFICE 文档编辑器与您的 Web 应用集成。 许多 Web 应用都可以从文档编辑功能中获益。但是要从头开始创建这个功能,需要花费大量时间和精力。幸运的是,您可以使用 ONLYOFFICE——这是一款开源办公套件,可…...
CentOS 7搭建Gitlab流程
目录 1、查询docker镜像gitlab-ce 2、拉取镜像 3、查询已下载的镜像 4、新建gitlab文件夹 5、在gitlab文件夹下新建相关文件夹 6、创建运行gitlab的容器 7、查看docker容器 8、根据Linux地址访问gitlab 9、进入docker容器,设置用户名的和密码 10、登录git…...
Idea安装完成配置
目录: 环境配置Java配置Maven配置Git配置 基础设置编码级设置File Header自动生成序列化编号配置 插件安装MyBtisPlusRestfulTooklkit-fix 环境配置 Java配置 Idea右上方,找到Project Settings. 有些版本直接有,有些是在设置下的二级菜单下…...

超详细~25考研规划~感恩现在努力的你!!!
25考研规划 俄语,翻译过来叫我爱你 考试时间 第一天 8.30-11.30政治——100分 2.00-5.00英语——100分 第二天 8.30-11.30数学——150分 2.00-5.00专业课——150分 1.什么是25考研 将在2024年12月参加考研,2025年本科毕业,9月读研究…...

智慧城市安全监控的新利器
在传统的城市管理中,井盖的监控一直是一个难题,而井盖异动传感器的出现为这一问题提供了有效的解决方案。它具有体积小、重量轻、安装方便等特点,可以灵活地应用于各种类型的井盖,实现对城市基础设施的全方位监控。 智能井盖监测终…...
)
【算法】石子合并(区间dp)
题目 设有 N 堆石子排成一排,其编号为 1,2,3,…,N。 每堆石子有一定的质量,可以用一个整数来描述,现在要将这 N 堆石子合并成为一堆。 每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子…...

C++-特殊类和单例模式
1.请设计一个类,不能被拷贝 拷贝构造函数以及赋值运算符重载,因此想要让一个类禁止拷贝,只需让该类不能调用拷贝构造函数以及赋值运算符重载即可。 //该类不能发生拷贝class NonCopy{public:NonCopy(const NonCopy& Nc) delete;NonCopy&…...

终极教程:如何用免费Chrome插件一键保存完整网页内容
终极教程:如何用免费Chrome插件一键保存完整网页内容 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture-chrome-extens…...
,第7名99%人从未试过)
【独家实测】12种火焰风格生成成功率排行榜(含燃烧强度/流体轨迹/余烬衰减量化评分),第7名99%人从未试过
更多请点击: https://codechina.net 第一章:火焰风格生成效果的评估体系与实测方法论 火焰风格图像生成质量评估需兼顾视觉感知一致性、物理合理性与算法可复现性。单一指标(如PSNR或LPIPS)无法全面刻画火焰特有的动态纹理、亮度…...

DVWA靶场实战避坑指南:Docker环境搭建与四层安全等级解析
1. 这不是“又一个DVWA教程”,而是一份能让你在真实渗透测试中少走三周弯路的靶场操作手册很多人第一次接触渗透测试,打开浏览器输入http://192.168.1.10/dvwa,看到那个灰扑扑的登录页,就以为自己已经站在了红队门口。结果刚点开S…...

C#中协变逆变的实现
1. 协变与逆变的概念协变(Covariance)允许将子类(派生类)类型作为父类(基类)类型使用。例如:IEnumerable<string> 可以被视为 IEnumerable<object>,因为 string 是 obje…...

机器学习势函数与反向蒙特卡洛在GeO2玻璃中程有序结构解析中的对比研究
1. 项目概述:当机器学习势函数遇上反向蒙特卡洛在材料模拟的世界里,我们常常面临一个两难选择:是相信基于物理化学原理构建的“经验”模型,还是完全服从实验数据的“拟合”结果?这个问题在网络形成玻璃,比如…...
)
Linux 用户与用户组核心概念详解(零基础必懂)
前言Linux 是典型的多用户、多任务操作系统,支持多人同时登录、各司其职、权限隔离。所有文件、进程、权限都依托用户与用户组实现管控,是Linux权限体系的基石。彻底弄懂用户、用户组概念,是掌握服务器权限管控、账号运维的前提,本…...

融合FIWARE与TinyML:构建工业级边缘智能的MLOps系统工程实践
1. 项目概述:当边缘智能遇见工业级平台在物联网项目里摸爬滚打十几年,我见过太多这样的场景:传感器数据源源不断地上传到云端,一个简单的“开”或“关”的决策,需要经过网络传输、云端服务器处理、再传回指令ÿ…...

大型语言模型推理加速:Lyanna架构与推测解码优化
1. 大型语言模型推理加速的技术挑战在自然语言处理领域,大型语言模型(LLM)的推理速度一直是制约其实际应用的关键瓶颈。传统自回归解码方式需要逐个生成token,这种序列化特性使得计算资源无法得到充分利用。以LLaMA-2-7B模型为例,在NVIDIA A1…...

Frida安卓逆向实战:SELinux适配与Hook可靠性保障
1. 这不是“装个 Frida 就能 Hook”的幻觉,而是安卓逆向真实的第一道门槛很多人点开“Frida 教程”时,心里想的是:“装个 frida-server,跑个 js 脚本,改个登录态,不就完事了?”——我试过三次&a…...

你的Linux启动慢?可能是UEFI这七个阶段在“摸鱼”!性能调优实战指南
Linux启动慢?UEFI七阶段性能调优实战指南当你的Linux系统启动速度像蜗牛爬行时,问题可能隐藏在UEFI启动的七个关键阶段中。本文将带你深入UEFI启动流程的每个环节,揭示可能导致延迟的"摸鱼"行为,并提供针对性的优化方案…...