Python 使用XlsxWriter操作Excel
在数据处理和报告生成的领域中,Excel 文件一直是广泛使用的标准格式。为了让 Python 开发者能够轻松创建和修改 Excel 文件,XlsxWriter 库应运而生。XlsxWriter 是一个功能强大的 Python 模块,专门用于生成 Microsoft Excel 2007及以上版本(.xlsx 格式)的电子表格文件。本文将对XlsxWriter进行概述,探讨其主要特点、用法和一些实际应用,并实现绘制各类图例(条形图,柱状图,饼状图)等。
主要特点
- .xlsx 格式支持: XlsxWriter 专注于创建 Microsoft Excel 2007 及以上版本的文件,这是一种基于 XML 的格式,允许存储大量数据、样式和图表。
- 格式和样式: XlsxWriter 允许开发者以编程方式设置单元格的格式和样式,包括字体、颜色、对齐方式等。这使得生成的 Excel 文件能够呈现出精美的外观。
- 图表和图形: XlsxWriter 支持创建各种类型的图表,如折线图、柱状图、饼图等,使用户能够直观地呈现数据。同时,它还支持插入图片、形状和注释等图形元素。
- 公式和函数: XlsxWriter 允许在单元格中使用 Excel 公式和函数,这对于进行复杂的计算和数据分析非常有用。
- 大数据量处理: XlsxWriter 被设计为高性能的库,能够处理大规模的数据集,同时保持生成的 Excel 文件的高质量。
- 图表和条件格式: 除了基本的单元格样式,XlsxWriter 支持添加条件格式,以及在工作表中插入图表,提供更直观的数据可视化。
安装模块
要开始使用 XlsxWriter,首先需要安装该库。可以通过以下命令使用 pip 安装:
pip install XlsxWriter
XlsxWriter 提供了一个强大而灵活的工具,使得使用 Python 生成 Excel 文件变得简单而高效。无论是用于数据分析、报告生成还是其他领域,XlsxWriter 都为开发者提供了一种简单而可靠的方法,使他们能够充分利用 Excel 的强大功能。在掌握了基本用法后,开发者可以深入研究 XlsxWriter 的高级特性,以满足更复杂的需求。
单行输出函数
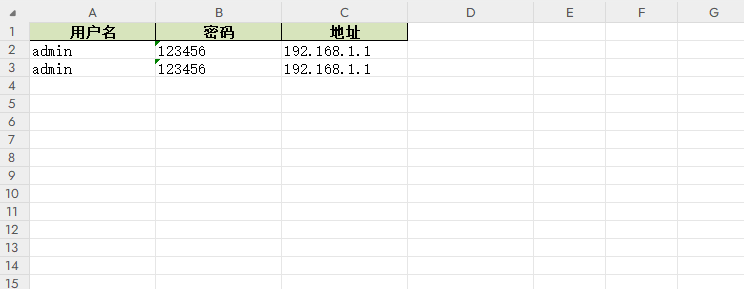
函数WriteSingleArticle()调用时传入文档名称,以及传入表头和数据,写出简单的单行记录。
import xlsxwriter# 写出数据
def WriteSingleArticle(xls_name,header,data):workbook = xlsxwriter.Workbook(xls_name)worksheet = workbook.add_worksheet()# 定义表格样式head_style = workbook.add_format({"bold": True, "align": "center", "border": 1, "fg_color": "#D7E4BC"})worksheet.set_column("A1:D1", 15)# 写出表头worksheet.write_row("A1", header, head_style)for index in range(0, len(data)):worksheet.write_row("A{}".format(index + 2), data[index])workbook.close()return Trueif __name__ == "__main__":headings = ["用户名", "密码", "地址"]data = [["admin","123456","192.168.1.1"],["admin","123456","192.168.1.1"]]ref = WriteSingleArticle("lyshark.xlsx",headings,data)print("写出状态: {}".format(ref))
输出效果如下所示;
多行表格输出函数
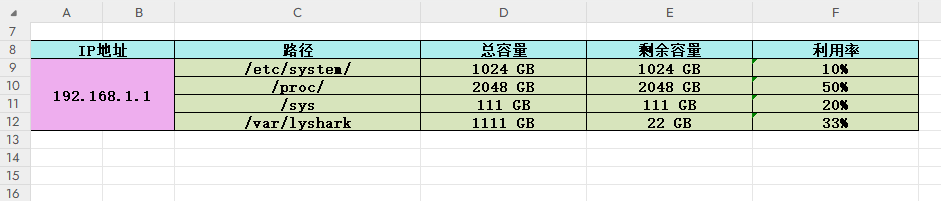
函数CreateTable(address,data,section)实现了输出一个列表格式的Table,只需传入列表序列即可。
先找到表格生成坐标与大小之间的比值关系,这是第一步,如下是简单的实现固定位置生成表格。
import xlsxwriter# 设置表格sheet名称
workbook = xlsxwriter.Workbook('lyshark.xlsx')
worksheet = workbook.add_worksheet("系统磁盘统计")# 设置头部标题IP地址列
merge_format = workbook.add_format({'bold': True,'border': 1,'align': 'center','valign': 'vcenter','fg_color': '#EEAEEE'})
worksheet.merge_range('A9:B12', '192.168.1.1', merge_format)# 设置表格头部提示,并将前两个表头合并为1个
header = ["IP地址","IP地址","路径","总容量","剩余容量","利用率"]
merge_format1 = workbook.add_format({'bold': True,'border': 1,'align': 'center','valign': 'vcenter','fg_color': '#AEEEEE'})
worksheet.write_row("A8:B12",header,merge_format1) # 显示表头
worksheet.merge_range('A8:B8',"IP地址",merge_format1) # 合并表头(合并第一个元素)# 写出路径列表
data1 = ["/etc/system/","/proc/","/sys","/var/lyshark"]
merge_format2 = workbook.add_format({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet.write_column("C9",data1,merge_format2)
worksheet.set_column("C9:C9",30)# 写出总容量
data2 = ["1024 GB","2048 GB","111 GB","1111 GB"]
merge_format3 = workbook.add_format({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet.write_column("D9",data2,merge_format3)
worksheet.set_column("D9:D9",20)# 写出剩余容量
data3 = ["1024 GB","2048 GB","111 GB","22 GB"]
merge_format4 = workbook.add_format({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet.write_column("E9",data3,merge_format4)
worksheet.set_column("E9:E9",20)# 写出利用率
data4= ["10%","50%","20%","33%"]
merge_format5 = workbook.add_format({'bold': True,'border': 1,'valign': 'vcenter','fg_color': '#D7E4BC','align': 'center'})
worksheet.write_column("F9",data4,merge_format5)
worksheet.set_column("F9:F9",20)workbook.close()
输出效果如下所示;
继续封装如上代码,将其封装为CreateTable(address,data,section)函数,用户传入表头地址,数据集,以及从第几行开始写数据,则自动生成表单。
import xlsxwriterworkbook = xlsxwriter.Workbook('lyshark.xlsx')
worksheet = workbook.add_worksheet("统计表")# 创建表结构
def CreateTable(address,data,section):# --------------------------------------------------------------------# 计算表头列表长度header_count = len(data[1])print("不带表头的列表长度: {}".format(header_count))merge_format1 = workbook.add_format({'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#AEEEEE'})# 根据表格列长度 计算出表格大小header_range = f"A{section}:B{section+header_count}"print("表头总长度 header_range = {}".format(header_range))# 写出表头到文件worksheet.write_row(header_range, data[0], merge_format1)# --------------------------------------------------------------------# 计算合并表头偏移,并合并header_merge_range = f"A{section}:B{section}"print("合并表头偏移 header_merge_range = {}".format(header_merge_range))# 合并表头(合并第一个元素)header_table = data[0][0]worksheet.merge_range(header_merge_range, header_table, merge_format1)# worksheet.merge_range(header_merge_range, "IP地址", merge_format1)# --------------------------------------------------------------------# 计算出表头 所占总单元格大小remove_header_count = len(data) - 1print("除去表头的列表长度: {}".format(remove_header_count))# 此处自己调整列长度address_merge_range = f"A{section+1}:B{section + len(data[0][1])}"print("所占总单元格大小 address_merge_range = {} => {}".format(len(data[0][1]),address_merge_range))merge_format = workbook.add_format({'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#EEAEEE'})# 写出单元格合并大小worksheet.merge_range(address_merge_range, address , merge_format)# --------------------------------------------------------------------# 循环填充数据merge_format_index = workbook.add_format({'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})letter_list = ['C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O','P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']# 循环填充数据 最大字段长度为24for index in range(0, remove_header_count):index_range = f"{letter_list[index]}{section+1}"worksheet.write_column(index_range, data[index+1], merge_format_index)index_range = f"{letter_list[index]}{section+1}:{letter_list[index]}{section+1}"worksheet.set_column(index_range, 30)"""# 不使用循环逐条填充merge_format2 = workbook.add_format( {'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})index_range = "C{}".format(section+1)worksheet.write_column(index_range, data[1], merge_format2)index_range = "C{}:C{}".format(section+1,section+1)worksheet.set_column(index_range, 30)index_range = "D{}".format(section+1)worksheet.write_column(index_range, data[2], merge_format2)index_range = "D{}:D{}".format(section+1,section+1)worksheet.set_column(index_range, 30)index_range = "E{}".format(section+1)worksheet.write_column(index_range, data[2], merge_format2)index_range = "E{}:E{}".format(section+1,section+1)worksheet.set_column(index_range, 30)"""# 返回计算后的表格的下两个单元的实际偏移位置return section + remove_header_count + 3# 测试恒矩阵
def Test():val = \[["测试地址", "测试地址","磁盘路径", "总容量", "剩余容量"],["/etc/system/", "/proc/", "/sys", "/user"],["1024 GB", "2048 GB", "12 GB","98 GB"],["1345 GB", "1124 GB", "341 GB", "55 GB"]]ref = CreateTable("192.168.1.1",val,1)print("返回下一个表格索引: {}".format(ref))ref = CreateTable("192.168.1.1",val,ref)print("返回下一个表格索引: {}".format(ref))workbook.close()# 测试竖矩阵
def Test2():header = ["测试地址", "测试地址","磁盘路径", "总容量", "剩余容量"]val = \[["/etc/system/", "1024 GB", "256 GB"],["/etc/passwd/", "104 GB", "345GB"],["/etc/username/", "12 GB", "56 GB"],["/etc/lyshark/", "12 GB", "56 GB"]]# 横向矩阵转竖向矩阵ref_xor = list ( map(list,zip(*val)) )# 追加头部ref_xor.insert(0, header)print(ref_xor)ref = CreateTable("192.168.1.1",ref_xor,1)print("返回下一个表格索引: {}".format(ref))workbook.close()if __name__ == "__main__":Test2()
输出效果如下所示;

柱状图输出函数
简单实现CreateChart(headings,data)柱状图生成函数,通过传入头部标题和数据集列表即可完成表单生成。
import xlsxwriterworkbook = xlsxwriter.Workbook('lyshark.xlsx')
worksheet = workbook.add_worksheet("统计表")def CreateChart(headings,data):# 定义表格样式head_style = workbook.add_format({"bold": True, "align": "center", "font": 13})# 逐条写入数据worksheet.write_row("A1", headings, head_style)for i in range(0, len(data)):worksheet.write_row("A{}".format(i + 2), data[i])# 添加柱状图chart = workbook.add_chart({"type": "column"})chart.add_series({"name": "=统计表!$B$1", # 图例项"categories": "=统计表!$A$2:$A$10", # X轴Item名称"values": "=统计表!$B$2:$B$10" # X轴Item值})chart.add_series({"name": "=统计表!$C$1","categories": "=统计表!$A$2:$A$10","values": "=统计表!$C$2:$C$10"})chart.add_series({"name": "=统计表!$D$1","categories": "=统计表!$A$2:$A$10","values": "=统计表!$D$2:$D$10"})# 添加柱状图标题chart.set_title({"name": "性能统计柱状图"})chart.set_style(12)# 在G2处绘制worksheet.insert_chart("G2", chart)workbook.close()if __name__ == "__main__":headings = ["主机地址", "CPU利用率", "内存利用率", "交换分区"]data = [["192.168.1.100", 88, 36, 66], ["192.168.1.200", 98, 89, 66], ["192.168.1.220", 88, 100, 32]]# 循环添加模拟数据for i in range(1, 100):s = ["192.168.1.{}".format(i), i, i, i]data.append(s)CreateChart(headings,data)
输出效果如下所示;

条形图输出函数
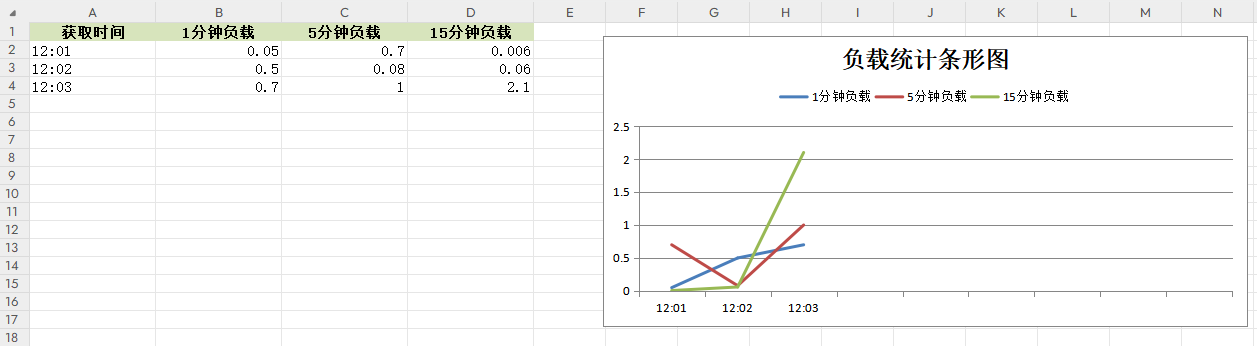
封装CreateChart(headings,data)函数实现输出条形图,并将前十的数据绘成图展示在右侧。
import xlsxwriterworkbook = xlsxwriter.Workbook('lyshark.xlsx')
worksheet = workbook.add_worksheet("统计表")def CreateChart(headings,data):# 定义表格样式head_style = workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.set_column("A1:D1", 15)# 逐条写入数据worksheet.write_row("A1", headings, head_style)for i in range(0, len(data)):worksheet.write_row("A{}".format(i + 2), data[i])# 添加条形图,显示前十个元素chart = workbook.add_chart({"type": "line"})chart.add_series({"name": "=统计表!$B$1", # 图例项"categories": "=统计表!$A$2:$A$10", # X轴Item名称"values": "=统计表!$B$2:$B$10" # X轴Item值})chart.add_series({"name": "=统计表!$C$1","categories": "=统计表!$A$2:$A$10","values": "=统计表!$C$2:$C$10"})chart.add_series({"name": "=统计表!$D$1","categories": "=统计表!$A$2:$A$10","values": "=统计表!$D$2:$D$10"})# 添加柱状图标题chart.set_title({"name": "负载统计条形图"})# chart.set_style(8)chart.set_size({'width': 1000, 'height': 500})chart.set_legend({'position': 'top'})# 在F2处绘制worksheet.insert_chart("F2", chart)workbook.close()if __name__ == "__main__":headings = ["获取时间", "1分钟负载", "5分钟负载", "15分钟负载"]data = [["12:01", 0.05, 0.7, 0.006], ["12:02", 0.5, 0.08, 0.06], ["12:03", 0.7, 1, 2.1]]CreateChart(headings,data)
输出效果如下所示;
饼状图输出函数
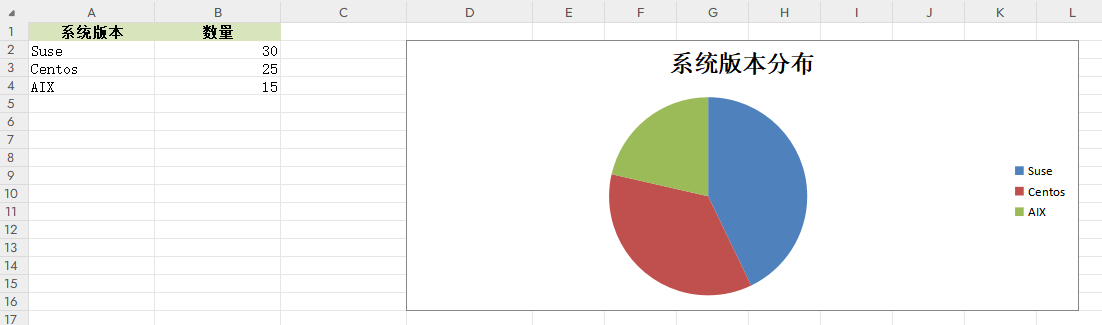
函数CreateChart(headings,data)用于生成饼状图,实现对主机以及主机数量的图形化展示。
import xlsxwriterworkbook = xlsxwriter.Workbook('lyshark.xlsx')
worksheet = workbook.add_worksheet("统计表")def CreateChart(headings,data):# 定义表格样式head_style = workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.set_column("A1:D1", 15)# 逐条写入数据worksheet.write_row("A1", headings, head_style)for i in range(0, len(data)):worksheet.write_row("A{}".format(i + 2), data[i])# 添加条形图,显示前十个元素chart = workbook.add_chart({"type": "pie"})chart.add_series({"name": "=统计表!$B$1", # 图例项"categories": "=统计表!$A$2:$A$4", # X轴 Item名称"values": "=统计表!$B$2:$B$4" # X轴Item值})# 添加饼状图chart.set_title({"name": "系统版本分布"})chart.set_size({'width': 600, 'height': 300})chart.set_legend({'position': 'right'})# 在D2处绘制worksheet.insert_chart("D2", chart)workbook.close()if __name__ == "__main__":headings = ["系统版本", "数量"]data = [["Suse", 30], ["Centos", 25], ["AIX", 15]]CreateChart(headings,data)
输出效果如下所示;
实现绘图类
通过调用xlsxwriter第三方库,实现绘制各类通用图形,并保存为XLS文档格式.
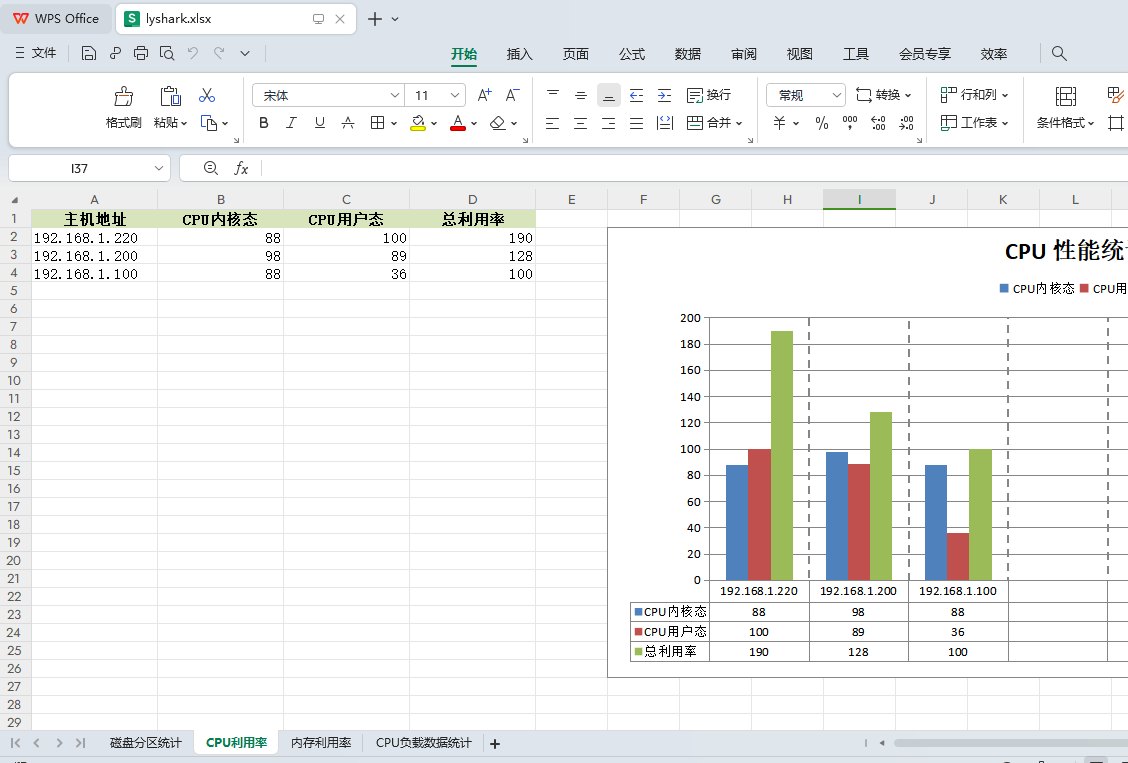
import xlsxwriterclass DrawChart():def __init__(self,workbook):self.workbook = xlsxwriter.Workbook(workbook)# 排序函数,以第三列为条件排列def cpu_takeSecond(self,elem):return int(elem[3])def mem_taskSecond(self,elem):return int(elem[1])# 封装统计主机磁盘使用情况def CreateDiskTable(self,worksheet,address,data,section):# 添加统计名称 例如: 磁盘统计worksheet = self.workbook.add_worksheet(worksheet)merge_format = self.workbook.add_format({'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#EEAEEE'})header_count = len(data[1])merge_format1 = self.workbook.add_format({'bold': True, 'border': 1, 'align': 'center', 'valign': 'vcenter', 'fg_color': '#AEEEEE'})# 根据磁盘路径计算出表格大小header_range = "A{}:B{}".format(section,section+header_count)worksheet.write_row(header_range, data[0], merge_format1) # 显示表头# 计算合并表头偏移header_merge_range = "A{}:B{}".format(section,section)worksheet.merge_range(header_merge_range, "巡检IP地址", merge_format1) # 合并表头(合并第一个元素)# 计算出地址所占总单元格大小address_merge_range = "A{}:B{}".format(section+1,section+header_count)worksheet.merge_range(address_merge_range, address , merge_format) #需要计算出来,根据传入分区数量# 通过计算得到磁盘路径所对应到表中的位置merge_format2 = self.workbook.add_format({'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC'})index_range = "C{}".format(section+1)worksheet.write_column(index_range, data[1], merge_format2)index_range = "C{}:C{}".format(section+1,section+1)worksheet.set_column(index_range, 30)# 计算出总容量对应到表中的位置merge_format3 = self.workbook.add_format({'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})index_range = "D{}".format(section + 1)worksheet.write_column(index_range, data[2], merge_format3)index_range = "D{}:D{}".format(section + 1, section + 1)worksheet.set_column(index_range, 20)# 计算出剩余容量对应到表中的位置merge_format4 = self.workbook.add_format({'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})index_range = "E{}".format(section + 1)worksheet.write_column(index_range, data[3], merge_format4)index_range = "E{}:E{}".format(section + 1, section + 1)worksheet.set_column(index_range, 20)# 计算出利用率对应到表中的位置merge_format5 = self.workbook.add_format({'bold': True, 'border': 1, 'valign': 'vcenter', 'fg_color': '#D7E4BC', 'align': 'center'})index_range = "F{}".format(section + 1)worksheet.write_column(index_range, data[4], merge_format5)index_range = "F{}:F{}".format(section + 1, section + 1)worksheet.set_column(index_range, 20)# 返回计算后的表格的下两个单元的实际偏移位置return section + header_count + 3# 创建CPU利用率百分比,并统计前十def CreateCpuUsedTable(self,worksheet,header,data):worksheet = self.workbook.add_worksheet(worksheet)# 设置头部颜色,并写入头部数据head_style = self.workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.write_row("A1", header, head_style)# 设置头部列宽worksheet.set_column("A1:D1", 15)# 排序,统计第三列数据,将最大的放在最前面,以此向下data.sort(key=self.cpu_takeSecond, reverse=True)# 将数据批量添加到表格中for x in range(0,len(data)):worksheet.write_row("A{}".format(x + 2), data[x])# --------------------------------------------------------------# 添加柱状图(开始绘图)chart = self.workbook.add_chart({"type": "column"})chart.add_series({"name": "=CPU利用率!$B$1", # 图例项(也就是CPU内核态)"categories": "=CPU利用率!$A$2:$A$10", # X轴 Item名称"values": "=CPU利用率!$B$2:$B$10" # X轴Item值})chart.add_series({"name": "=CPU利用率!$C$1","categories": "=CPU利用率!$A$2:$A$10","values": "=CPU利用率!$C$2:$C$10"})chart.add_series({"name": "=CPU利用率!$D$1","categories": "=CPU利用率!$A$2:$A$10","values": "=CPU利用率!$D$2:$D$10"})# 添加柱状图标题chart.set_title({"name": "CPU 性能统计柱状图"})# chart.set_style(8)chart.set_x_axis({'major_gridlines': {'visible': True,'line': {'width': 1.25, 'dash_type': 'dash'}},})chart.set_size({'width': 900, 'height': 500})chart.set_legend({'position': 'top'})chart.set_table({'show_keys': True})# 在F2处绘制worksheet.insert_chart("F2", chart)# 内存利用率统计def CreateMemoryTable(self, worksheet, header, data):worksheet = self.workbook.add_worksheet(worksheet)# 设置头部颜色,并写入头部数据head_style = self.workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.write_row("A1", header, head_style)# 设置头部列宽worksheet.set_column("A1:D1", 15)# 排序,统计第三列数据,将最大的放在最前面,以此向下data.sort(key=self.mem_taskSecond, reverse=True)# 将数据批量添加到表格中for x in range(0,len(data)):worksheet.write_row("A{}".format(x + 2), data[x])# --------------------------------------------------------------# 添加柱状图(横向图)chart = self.workbook.add_chart({"type": "bar"})chart.add_series({"name": "=内存利用率!$B$1","categories": "=内存利用率!$A$2:$A$10","values": "=内存利用率!$B$2:$B$10"})chart.add_series({"name": "=内存利用率!$C$1","categories": "=内存利用率!$A$2:$A$10","values": "=内存利用率!$C$2:$C$10"})# 添加柱状图标题chart.set_title({"name": "内存利用率统计图"})chart.set_x_axis({'major_gridlines': {'visible': True,'line': {'width': 1.25, 'dash_type': 'dash'}},})chart.set_size({'width': 900, 'height': 400})chart.set_legend({'position': 'top'})# 在F2处绘制worksheet.insert_chart("F2", chart)# --------------------------------------------------------------# 统计CPU Load 负载情况 注意: 只能指定单独的主机def CreateCpuLoadAvgTable(self, address,worksheet, header, data):worksheet = self.workbook.add_worksheet(worksheet)# 设置头部颜色,并写入头部数据head_style = self.workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.write_row("A1", header, head_style)# 设置头部列宽worksheet.set_column("A1:D1", 15)# 将数据批量添加到表格中for x in range(0,len(data)):worksheet.write_row("A{}".format(x + 2), data[x])# 定义表格样式head_style = self.workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})worksheet.set_column("A1:D1", 15)# 逐条写入数据worksheet.write_row("A1", header, head_style)for i in range(0, len(data)):worksheet.write_row("A{}".format(i + 2), data[i])# 添加条形图,显示前十个元素chart = self.workbook.add_chart({"type": "line"})chart.add_series({"name": "=CPU负载数据统计!$B$1", # 图例项"categories": "=CPU负载数据统计!$A$2:$A$10", # X轴 Item名称"values": "=CPU负载数据统计!$B$2:$B$10" # X轴Item值})chart.add_series({"name": "=CPU负载数据统计!$C$1", # 第一个线条(图例)"categories": "=CPU负载数据统计!$A$2:$A$10","values": "=CPU负载数据统计!$C$2:$C$10"})chart.add_series({"name": "=CPU负载数据统计!$D$1", # 第二个线条(图例)"categories": "=CPU负载数据统计!$A$2:$A$10","values": "=CPU负载数据统计!$D$2:$D$10"})# 添加柱状图标题chart.set_title({"name": "统计地址: {}".format(address)})chart.set_size({'width': 900, 'height': 500})chart.set_legend({'position': 'top'})# 在F2处绘制worksheet.insert_chart("F2", chart)# 关闭并保存绘制结果def Save(self):self.workbook.close()if __name__ == "__main__":work = DrawChart("lyshark.xlsx")# ------------------------------------------------------------------# 统计系统磁盘容量disk_val = [["IP地址", "IP地址", "磁盘路径", "总容量", "剩余容量", "利用率"],["/etc/system/", "/proc/", "/sys", "/abc/lyshark"],["1024GG", "2048GB", "111GB", "1111GB"],["1024GG", "2048GB", "111GB", "22GB"],["10%", "50%", "20%", "33%"]]ref = work.CreateDiskTable("磁盘分区统计","127.0.0.1",disk_val,3)print("下个表格开头位置: {}".format(ref))print("[+] 磁盘数据统计完成")# -------------------------------------------------------------------# 统计系统CPU负载情况header = ["主机地址", "CPU内核态", "CPU用户态", "总利用率"]cpu_val = [["192.168.1.100", 88, 36, 100],["192.168.1.200", 98, 89, 128],["192.168.1.220", 88, 100, 190]]ref = work.CreateCpuUsedTable("CPU利用率",header,cpu_val)print("[+] CPU利用率统计已完成")# -------------------------------------------------------------------# 统计系统内存利用率数据header = ["主机地址", "通用内存利用率", "交换内存利用率"]mem_val = [["192.168.1.100", 25, 35],["192.168.1.200", 44, 57],["192.168.1.200", 24, 21],["192.168.1.200", 78, 89]]ref = work.CreateMemoryTable("内存利用率",header,mem_val)print("[+] 内存利用率统计已完成")# -------------------------------------------------------------------# 获取CPU LoadAvg负载情况header = ["拉取日期","1分钟负载","5分钟负载","15分钟负载"]cpu_avg_val = [["12:11",0.1,0.2,1.3],["12:12",1.4,3.3,6.9],["12:13",2.6,3.2,6.9]]ref = work.CreateCpuLoadAvgTable("127.0.0.1","CPU负载数据统计",header,cpu_avg_val)print("[+] CPU负载统计完成")work.Save()
输出效果如下所示;
相关文章:
Python 使用XlsxWriter操作Excel
在数据处理和报告生成的领域中,Excel 文件一直是广泛使用的标准格式。为了让 Python 开发者能够轻松创建和修改 Excel 文件,XlsxWriter 库应运而生。XlsxWriter 是一个功能强大的 Python 模块,专门用于生成 Microsoft Excel 2007及以上版本&a…...

PostgreSQL中所的锁
为了确保复杂的事务可以安全地同时运行,PostgreSQL提供了各种级别的锁来控制对各种数据对象的并发访问,使得对数据库关键部分的更改序列化。事务并发运行,直到它们尝试获取互相冲突的锁为止(比如两个事务更新同一行时)。当多个事务同时在数据…...
学习MySQL先有全局观,细说其发展历程及特点
学习MySQL先有全局观,细说其发展历程及特点 一、枝繁叶茂的MySQL家族1. 发展历程2. 分支版本 二、特点分析1. 常用数据库2. 选型角度及场景 三、三大组成部分四、总结 相信很多同学在接触编程之初,就接触过数据库,而对于其中关系型数据库中的…...

Linux安装与配置Maven
案例中Linux版本为CentOS7.9,安装目录为 /root/software/ 1、使用 wget 命令从官网下载安装包(https://maven.apache.org/download.cgi) wget https://dlcdn.apache.org/maven/maven-3/3.9.5/binaries/apache-maven-3.9.5-bin.tar.gz2、解压…...

Java面向对象第一天
什么是类?什么是对象? 现实生活是由很多很多对象组成的,基于对象抽出了类 对象:软件中真实存在的单个的个体/东西 类:类型/类别,代表一类个体 类是对象的模板/模子,对象是类的具体的实例 类中…...

什么是mvc原理是什么
MVC是一种设计模式,它将应用程序分为三个部分:模型(Model)、视图(View)和控制器(Controller)。 模型(Model)表示应用程序的数据结构,包括与数据相…...

json_to_mask
修改后的json_to_dataset文件,直接复制替换你自己原始的json_to_dataset,建议保存一下原版import argparse import base64 import json import os import os.path as ospimport imgviz import PIL.Imagefrom labelme.logger import logger from labelme …...
Camtasia2024免费版mac电脑录屏软件
作为一个互联网人,没少在录屏软件这个坑里摸爬滚打。培训、学习、游戏、影视解说……都得用它。这时候没个拿得出手的私藏软件,还怎么混?说实话,录屏软件这两年也用了不少,基本功能是有但总觉得缺点什么,直…...

拦截器的使用
拦截器(Interceptor)是一种在应用程序中用于干预、修改或拦截请求和响应的组件,是AOP 编程的一种实践,和过滤器一样都是一种具体的AOP实现。它可以在请求被发送到目标处理程序之前或之后,对请求进行预处理或对响应进行…...
)
R语言——taxize(第四部分)
taxize(第四部分) 3.39. get_wiki(获取维基分类群的页面名称)3.40. get_wormsid(获取分类群名称的Worms ID)3.41. gni_details(使用Global Names Index搜索分类学名称详情)3.42. gni…...

C++学习 --list
目录 1, 什么是list 2, 创建 2-1, 标准数据类型 2-2, 自定义数据类型 2-3, 其他创建方式 3, 操作list 3-1, 赋值 3-2, 添加元素 3-2-1, 添加元素(assign) 3-2-…...
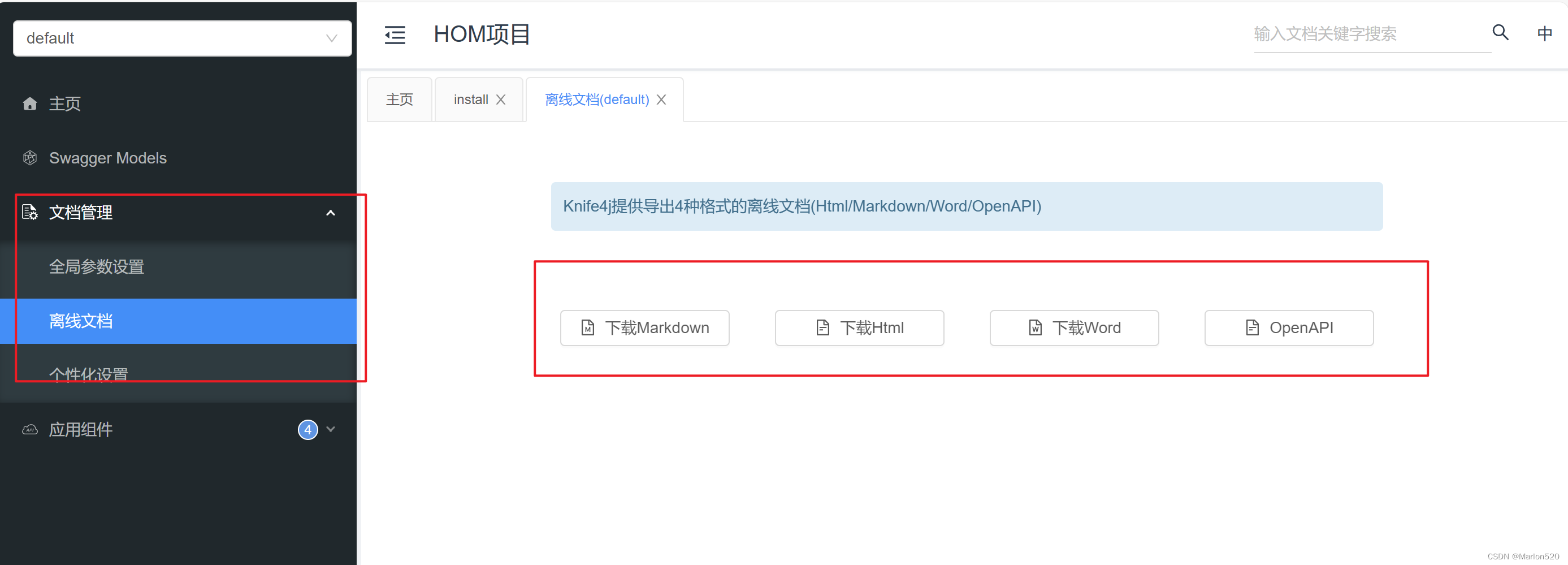
Springboot集成swagger之knife4j
knife4j的最终效果: 支持直观的入参介绍、在线调试及离线各种API文档下载。 1 引入pom <dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId><version>3.0.2</ver…...

多线程 02
1.线程的常见构造方法 方法说明Thread()创建线程对象Thread(Runnable target)使用 Runnable 对象创建线程对象Thread(String name)创建线程对象,并命名Thread(Runnable target, String name)使用 Runnable 对象创建线程对象,并命名【了解】Thread(Threa…...
车辆管控大数据可视化平台案例源码分析【可视化项目案例-10】
🎉🎊🎉 你的技术旅程将在这里启航! 🚀🚀 本专栏包括但不限于大屏可视化、图表可视化等等。订阅专栏用户在文章底部可下载对应案例源码以供大家深入的学习研究。 🎓 每一个案例都会提供完整代码和详细的讲解,不论你是初学者还是资深开发者,这里都有适合你的内容。…...
链表的回文结构
题目描述 题目链接:链表的回文结构_牛客题霸_牛客网 (nowcoder.com) 题目分析 我们的思路是: 找到中间结点逆置后半段比对 我们可以简单画个图来表示一下: ‘ 奇数和偶数都是可以的 找中间结点 我们可以用快慢指针来找中:l…...

CSS特效017:球体涨水的效果
CSS常用示例100专栏目录 本专栏记录的是经常使用的CSS示例与技巧,主要包含CSS布局,CSS特效,CSS花边信息三部分内容。其中CSS布局主要是列出一些常用的CSS布局信息点,CSS特效主要是一些动画示例,CSS花边是描述了一些CSS…...
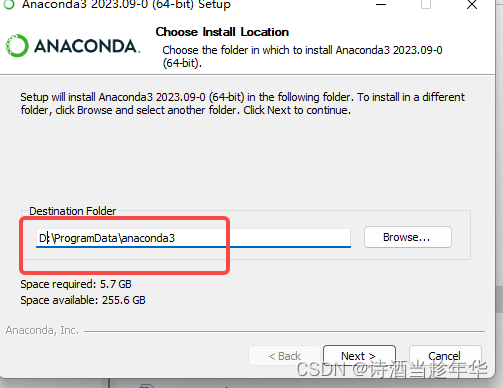
Windows下安装Anaconda3并使用JupyterNoteBook
下载安装包 Anaconda官网 进官网,点击下载 自动根据当前系统下载对应的包了,安装包大约1G,喝杯Java耐心等待。 安装 很多人安装C盘,我这里放D盘。 注意:你的文件夹目录一定要不能有空格 然后其他的直接默认install即…...

什么年代了,还不会 CI/CD 么?
目录 什么是 CI/CD? CI/CD 对业务有哪些好处? 一:确保卓越的代码质量 二:更快的发布速度 → 更快的交付 三:自动化降低成本 四:故障隔离 五:简化回滚 六:持续反馈 七&#…...

centos 7.7 安装Python-3.7.4
一、安装PYTHON 编译依赖包 1.1 首先安装gcc编译器,gcc有些系统版本已经默认安装,通过 gcc --version 查看,没安装的先安装gcc, yum -y install gcc glibc make1.2 安装其它依赖包,(注:不要缺…...
git的用法
目录 一、为什么需要git 二、git基本操作 2.1、初始化git仓库 2.2、配置本地仓库的name和email 2.3、认识工作区、暂存区、版本库 三、git的实际操作 3.1 提交文件 3.2 查看git状态以及具体的修改 3.3 git版本回退 git reset 3.1 撤销修改 四、git分支管理 4.…...
)
【网络协议-17】LWIP学习浅谈:从入门到实战,嵌入式网络开发进阶指南(续)
前言 在嵌入式开发领域,网络功能已经成为越来越多产品的标配。从智能家居设备到工业控制器,从物联网网关到车载电子,几乎都离不开 TCP/IP 网络通信。而在资源受限的嵌入式系统中,LWIP(Lightweight Internet Protocol&…...

猫抓浏览器扩展:一站式解决网页视频音频资源下载难题
猫抓浏览器扩展:一站式解决网页视频音频资源下载难题 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到这样的困扰&#x…...

嵌入式开发环境搭建第一步:在VMware中为Ubuntu 22.04.3 LTS做这些关键初始配置
嵌入式开发环境搭建第一步:VMware中Ubuntu 22.04.3 LTS的10项关键配置 当你刚完成Ubuntu 22.04.3 LTS的基础安装,系统就像毛坯房——有基本框架但远未达到"拎包入住"的开发标准。作为嵌入式开发者,我们需要将这个"裸系统&quo…...

办公用品领用程序,领用归还记录上链,减少浪费,丢失,虚报领用。
办公用品领用上链管理系统设计方案 一、实际应用场景描述 某中型互联网公司(约200人)行政部门管理着包含笔记本电脑、投影仪、绘图板等高价值设备,以及硒鼓、墨盒、A4纸等高频消耗品。当前采用纸质登记表Excel台账的方式管理,每月…...

《用若依框架开发多门店SaaS系统的完整实战指南——两个大学生如何从零到交付》
作者:一个踩过坑的开发者 前言:如果你正在开发一套多门店管理系统(推拿、美容、餐饮等),并且还在纠结“从零造轮子还是用开源框架”,这篇文章值得你花10分钟读完。 一、为什么要写这篇文章? 三…...
)
【仅限首批200名开发者】Docker WASM边缘部署Checklist v3.1(含Intel TDX/AMD SEV-SNP安全启动验证项)
更多请点击: https://intelliparadigm.com 第一章:Docker WASM边缘部署Checklist v3.1概览 Docker WASM边缘部署Checklist v3.1 是面向轻量级、高安全性边缘场景的标准化验证清单,专为在资源受限设备(如树莓派、智能网关、车载终…...

JCSprout字符串优化终极指南:StringBuilder与StringBuffer性能对比
JCSprout字符串优化终极指南:StringBuilder与StringBuffer性能对比 【免费下载链接】JCSprout 👨🎓 Java Core Sprout : basic, concurrent, algorithm 项目地址: https://gitcode.com/gh_mirrors/jc/JCSprout 在Java开发中&#x…...

5分钟快速上手3dsconv:解决3DS游戏安装难题的完整指南
5分钟快速上手3dsconv:解决3DS游戏安装难题的完整指南 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 你是否遇…...

终极Windows界面美化指南:用ExplorerPatcher打造个性化工作环境
终极Windows界面美化指南:用ExplorerPatcher打造个性化工作环境 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 厌倦了Windows 11千…...

国产回路电阻测试仪:康高特白驹Pro与技术前瞻
引言电力系统作为现代社会运行的基石,其稳定性和安全性至关重要。电气设备中的连接点,特别是高压断路器、隔离开关等关键设备的触头,其接触电阻的微小变化都可能引发局部过热,导致设备故障,甚至造成系统性风险。因此&a…...