【基础架构】part-2 可扩展性
文章目录
- 可扩展性(Scalability)
- 2.1 水平扩展
- 2.2 垂直扩展
- 2.3 弹性扩展
- 三、可靠性(Reliability)
- 3.1 容错机制
- 3.2 错误处理和恢复策略
- 3.3 监控和自动化运维
- 四、 安全性(Security)
- 4.1 身份验证和授权
- 4.2 加密和数据保护
- 4.3 安全审计和监控
- 五、可维护性(Maintainability)
- 5.1 模块化设计
- 5.2 清晰的代码结构
- 5.3 文档化
- 5.4 自动化测试和部署
- 六、性能(Performance)
- 6.1 性能调优
- 6.2 缓存策略
- 6.3 异步处理
- 6.4 负载均衡
- 七、可管理性(Manageability)
- 7.1 日志和监控系统
- 7.2 自动化运维和部署
- 7.3 可视化管理界面
- 八、可伸缩性(Elasticity)
- 8.1 云计算和弹性扩展
- 8.2 容器化
- 8.3 容器编排
- 8.4 弹性存储
- 8.5 自动化监测和扩展
可扩展性(Scalability)
可扩展性是指系统能够有效地处理增加的负载和流量,而不影响性能和用户体验。
2.1 水平扩展
通过添加更多的服务器节点来增加系统的处理能力,以平衡负载和提高性能。
以下是常用的水平扩展的策略:
- 负载均衡:
- 使用负载均衡器将用户请求分发到多个服务器,确保每个服务器都能够处理适当份额的请求。
- 常见的负载均衡算法包括轮询、最小连接数、最小响应时间等。
- 弹性扩展:
- 设置弹性扩展策略,根据系统负载动态地增加或减少服务器实例的数量。
- 云服务提供商通常提供自动扩展组件,可以根据规则自动调整实例数量。
- 分布式架构:
- 将应用程序拆分为独立的服务,每个服务都可以独立部署和水平扩展。
- 这种微服务架构使得系统更加灵活,可以根据需要独立地扩展特定的服务。
- 数据库水平分片:
- 当数据库成为瓶颈时,采用水平分片将数据分散存储在多个节点上。
- 水平分片可以按照数据范围、哈希函数或其他策略进行,以确保数据分布均匀。
- 缓存优化:
- 使用缓存来降低对后端系统的负载,减少响应时间。
- 分布式缓存系统(如Redis)可以存储频繁访问的数据,减轻数据库负担。
- 容器化和容器编排:
- 使用容器技术(如Docker)将应用程序和其依赖项打包到容器中,提高环境一致性。
- 利用容器编排工具(如Kubernetes)自动化容器的部署、扩展和管理。
- 多数据中心部署:
- 将系统部署到多个数据中心,以提高系统的容错性和可用性。
- 可以通过DNS负载均衡或全局负载均衡来实现流量在不同数据中心之间的分发。
- 容错设计:
- 采用容错设计,使系统在组件或节点故障时仍能正常运行。
- 冗余组件、自动故障转移和备份系统是实现容错的关键。
- 自动化监控和报警:
- 部署监控系统,实时监测系统性能和健康状况。
- 设置报警规则,当系统达到某个预定阈值时触发报警,通知运维人员或自动采取措施。
- 灾备和备份:
- 设计灾备方案,确保在主要数据中心或服务器出现故障时能够迅速切换到备用系统。
- 定期进行数据备份,并确保备份的可靠性和可恢复性。
2.2 垂直扩展
通过增加单个节点的资源能力,如CPU、内存或存储容量,来增加系统的处理能力。
以下是垂直扩展可用的方法:
- 升级硬件组件:
- 提升服务器的硬件性能,例如更快的CPU、更大的内存、更快的存储设备等。
- 这可以通过替换硬件组件或添加附加硬件来实现。
- 垂直分区:
- 将应用程序划分为不同的垂直分区,每个分区运行在独立的硬件上。
- 这使得不同部分的应用程序可以利用不同规格的硬件,从而更好地适应其需求。
- 数据库垂直分割:
- 将数据库表拆分为较小的、相关的表,使得查询和操作只涉及到必要的数据。
- 这有助于提高查询性能,并允许每个表根据需要垂直扩展。
- 缓存和优化算法:
- 使用缓存技术来存储频繁访问的数据,减轻对数据库的负载。
- 通过优化算法和查询,减少对数据库和其他资源的消耗,提高单个服务器的效率。
- 超线程技术:
- 如果硬件支持,启用超线程技术来允许单个CPU核心执行多个线程。
- 这可以提高CPU的利用率,尽可能地利用服务器的处理能力。
- 垂直缩减:
- 移除不必要的服务或功能,使得应用程序的资源需求更为合理。
- 这可以降低系统的整体资源消耗,延缓对硬件升级的需求。
- 高效编程和算法优化:
- 通过高效的编程实践和算法优化,减少应用程序对资源的需求。
- 优化代码,使得应用程序在相同硬件上能够处理更多的请求。
- 动态资源调整:
- 利用虚拟化技术和云服务提供商的资源调整功能,动态地调整服务器的规模和配置。
- 这可以在需要时提高或降低服务器的性能和能力。
2.3 弹性扩展
利用云计算平台的弹性能力,根据负载需求自动调整资源的规模,以满足变化的需求。
- 自动化扩展:
- 利用自动化工具和云服务提供商的功能,根据预定的规则动态地增加或减少系统的资源。
- 通过设置自动扩展组件,可以基于 CPU 使用率、网络流量等指标来触发自动扩展。
- 负载均衡:
- 使用负载均衡器将流量分发到多个服务器,确保每个服务器都能够处理适当份额的请求。
- 在负载均衡算法中考虑实时系统负载和服务器的性能指标,以实现动态负载分配。
- 微服务架构:
- 将系统拆分为小的、独立的微服务,每个微服务都可以独立部署和水平扩展。
- 这允许对系统的特定部分进行精确的扩展,而不必扩展整个应用程序。
- 容器化和容器编排:
- 使用容器技术(如Docker)将应用程序和其依赖项打包到容器中,提高环境一致性。
- 利用容器编排工具(如Kubernetes)自动化容器的部署、扩展和管理,实现更快速的弹性扩展。
- 数据库水平分片:
- 当数据库成为瓶颈时,采用水平分片将数据分散存储在多个节点上。
- 水平分片可以按照数据范围、哈希函数或其他策略进行,以确保数据分布均匀。
- 缓存策略:
- 使用缓存来降低对后端系统的负载,减少响应时间。
- 分布式缓存系统(如Redis、Memcached)可以存储频繁访问的数据,减轻数据库负担。
- 多地域和多数据中心部署:
- 将系统部署到多个地理位置或数据中心,以提高系统的容错性和可用性。
- 利用全局负载均衡和DNS服务来将流量分发到不同的地域或数据中心。
- 容错设计:
- 采用容错设计,使系统在组件或节点故障时仍能正常运行。
- 使用冗余组件、自动故障转移和备份系统来提高系统的可用性。
- 监控和自愈:
- 部署监控系统,实时监测系统性能、负载和健康状况。
- 实现自愈机制,当检测到故障或异常时,自动进行故障转移或重启受影响的组件。
- 灰度发布和蓝绿部署:
- 通过灰度发布和蓝绿部署策略,逐步引入新版本或变更,降低发布风险。
- 这允许在生产环境中进行有控制的变更,同时监测系统的性能和稳定性。
附加:灰度发布的方法
- 分阶段发布:
- 将新版本分为多个阶段,逐步将其发布到不同的用户群体。
- 可以按照用户数量、地理位置、用户角色等因素来定义不同的阶段。
- 百分比分配:
- 初始阶段将新版本只分配给一小部分用户,逐渐增加分配的百分比。
- 例如,开始时只让1%的用户使用新版本,然后逐步增加到10%、25%,最终全部用户。
- 时间窗口发布:
- 将新版本在一定时间窗口内逐步引入,而不考虑用户数量。
- 例如,在一个小时内将新版本发布到不同的用户群体,以确保问题能够及时发现和解决。
- 用户群体发布:
- 根据用户群体的特征,将新版本发布给特定的用户群体。
- 这可以根据用户行为、偏好、历史数据等来定义。
- A/B 测试:
- 将新版本与旧版本进行对比,通过在用户群体中随机分配不同版本来收集比较数据。
- A/B测试可用于评估新功能的性能、用户体验等方面。
- 金丝雀发布(Canary Release):
- 将新版本先部署到小部分生产环境中,通常是一组具有相似特征的服务器。
- 监测新版本的性能和稳定性,如果没有问题,则逐步扩大到整个系统。
- 特征开关:
- 在代码中加入特征开关,通过控制开关状态来启用或禁用特定功能。
- 这样可以在不重新部署的情况下控制新功能的开启与关闭。
- 回滚计划:
- 制定明确的回滚计划,以防在灰度发布过程中出现严重问题。
- 确保能够快速、可靠地回滚到之前的稳定版本。
- 实时监控和报警:
- 部署实时监控系统,监测新版本的性能指标、错误率等。
- 设置报警规则,及时发现潜在问题并采取相应措施。
- 用户参与:
- 在一些情况下,可以让用户自愿参与新版本的试用,并鼓励他们提供反馈。
- 用户参与可以增加测试覆盖率,同时提供实际用户的体验反馈。
三、可靠性(Reliability)
可靠性是指系统在面对故障或错误时能够保持稳定运行的能力。
3.1 容错机制
采用冗余设计和容错技术,如使用主备模式、复制和故障切换,以确保系统在部分故障情况下仍然可用。
3.2 错误处理和恢复策略
实施有效的错误处理机制,包括错误检测、错误报告、错误日志记录和错误恢复策略,以减少系统故障对用户的影响。
3.3 监控和自动化运维
建立监控系统来实时监测系统的状态和性能,并采取自动化运维措施,如自动报警、自动扩展和自动修复,以提高故障检测和响应的效率。
四、 安全性(Security)
安全性是指系统能够保护数据和资源免受未经授权的访问、恶意攻击和数据泄露等威胁。
4.1 身份验证和授权
实施强大的身份验证和授权机制,确保只有经过身份验证且授权的用户能够访问系统的敏感资源。
4.2 加密和数据保护
使用加密算法对敏感数据进行加密,保护数据的机密性和完整性。同时,采取数据备份和灾难恢复措施,以保护数据免受丢失或损坏的风险。
4.3 安全审计和监控
建立安全审计机制,记录用户的操作、系统事件和安全事件,以便进行安全审计和监控。此外,采用实时监控系统来检测潜在的安全漏洞和异常活动,并及时采取措施进行响应和应对。
五、可维护性(Maintainability)
可维护性是指系统易于维护和管理,以降低变更和修复的成本。以下是提高系统可维护性的一些实践:
5.1 模块化设计
将系统划分为模块化的组件,使每个组件都具有清晰的职责和接口,便于理解、修改和测试。
5.2 清晰的代码结构
采用良好的编码规范和设计模式,使代码结构清晰易读,降低代码的复杂性和耦合度。
5.3 文档化
编写清晰、详细的文档,包括系统架构、设计原理、接口说明和操作手册,以便开发人员和运维人员理解和管理系统。
5.4 自动化测试和部署
建立自动化测试框架,包括单元测试、集成测试和端到端测试,以确保系统的正确性和稳定性。同时,采用自动化部署工具,简化部署过程,提高发布的效率和一致性。
六、性能(Performance)
性能是指系统的响应时间和吞吐量,以满足用户的需求。以下是一些提高系统性能的关键策略:
6.1 性能调优
通过对系统进行性能分析和优化,找出性能瓶颈并进行相应的调整,以提高系统的响应时间和吞吐量。
6.2 缓存策略
利用缓存技术,将频繁访问的数据缓存起来,减少对后端资源的访问,提高系统的响应速度。
6.3 异步处理
将一些耗时的操作设计为异步任务,以避免阻塞主线程或请求处理流程,提高系统的并发能力和响应性能。
6.4 负载均衡
通过负载均衡技术,将流量分发到多个服务器上,以平衡负载,提高系统的吞吐量和容量。
七、可管理性(Manageability)
可管理性是指系统易于管理和监控,以便及时发现和解决问题。
7.1 日志和监控系统
建立强大的日志和监控系统,记录系统的运行状态、性能指标和异常事件,以便及时发现问题并进行分析和修复。
7.2 自动化运维和部署
采用自动化工具和脚本,简化运维任务和部署过程,减少人工操作的错误和时间成本。
7.3 可视化管理界面
设计直观和易用的管理界面,使管理员能够方便地监控系统状态、配置参数和执行管理操作。
八、可伸缩性(Elasticity)
可伸缩性是指系统能够根据负载需求的变化自动调整资源的规模。
8.1 云计算和弹性扩展
利用云计算平台提供的弹性扩展能力,根据负载需求自动调整资源的规模,以满足变化的需求,避免资源浪费和性能瓶颈。
8.2 容器化
采用容器化技术,如Docker。
8.3 容器编排
使用容器编排工具,如Kubernetes,对容器进行自动化部署、管理和伸缩,以实现高度可伸缩的系统架构。
8.4 弹性存储
采用可伸缩的存储解决方案,如对象存储或分布式文件系统,以满足不断增长的数据存储需求。
8.5 自动化监测和扩展
建立自动化监测系统,实时监测系统的负载和性能指标,并根据预设的阈值自动进行资源扩展,以保持系统的高可伸缩性。
相关文章:

【基础架构】part-2 可扩展性
文章目录 可扩展性(Scalability)2.1 水平扩展2.2 垂直扩展2.3 弹性扩展 三、可靠性(Reliability)3.1 容错机制3.2 错误处理和恢复策略3.3 监控和自动化运维 四、 安全性(Security)4.1 身份验证和授权4.2 加…...

[SWPUCTF 2021 新生赛]no_wakeup
直接赋值即可 $a ->admin admin; $a ->passwd wllm; 发现没有绕过,改成大于2的绕过__wakeup 这是因为PHP在反序列化时会检查序列化字符串的长度,如果长度小于等于2,则不会调用__wakeup()方法。...
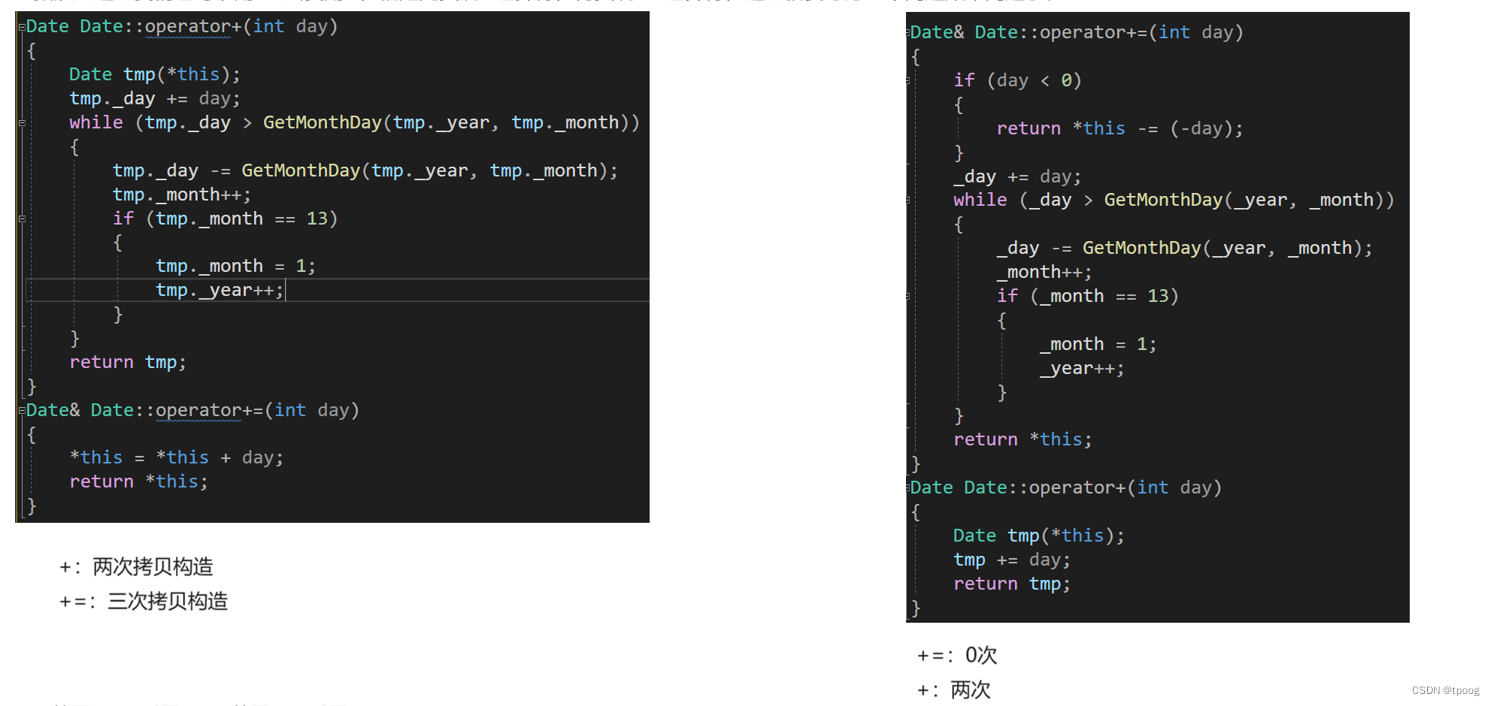
类和对象(3)日期类的实现
日期类的实现 一,声明二,函数成员定义2.1构造函数2.2获取月份天数2.3比较运算符2.3.1等于和大于2.3.2其他 2.4计算运算符2.4.1 &&2.4.2-&&- 2.5日期-日期 一,声明 class Date { public:Date(int year 1, int month 1, int…...

分布式篇---第五篇
系列文章目录 文章目录 系列文章目录前言一、你知道哪些限流算法?二、说说什么是计数器(固定窗口)算法三、说说什么是滑动窗口算法前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去…...
)
SpringMVC(二)
八、HttpMessageConverter HttpMessageConverter,报文信息转换器,将请求报文转换为Java对象,或将Java对象转换为响应报文 HttpMessageConverter提供了两个注解和两个类型:RequestBody,ResponseBody,Reque…...

kafka操作的一些坑
1.如果Offset Explorer能够检测到kafka中的数据,但是自己的kafka无法读取到 这个问题主要是由于kafka中的信息已经被消费掉了造成的 consumer.commitAsync();这里如果已经消费掉了kafka的信息,那么已经被消费掉的kafka数据就不会被再读取掉,…...

转录组学习第5弹-比对参考基因组
比对参考基因组 在构建文库的过程中需要将DNA片段化,因此测序得到的序列只是基因组的部分序列。为了确定测序reads在基因组上的位置,需要将reads比对回参考基因组上,这个步骤叫做比对,即文献中所提到的alignment或mapping。包括基…...
部署系列六基于nndeploy的深度学习 图像降噪unet部署
文章目录 1.直接在源代码demo中修改2. 如何修改呢?3. 修改 graph4. 总结 https://github.com/DeployAI/nndeploy https://nndeploy-zh.readthedocs.io/zh/latest/introduction/index.html 通过以上2个官方链接对nndeploy基本的使用方法应该有所了解了。 下面就是利用…...

使用 ClickHouse 做日志分析
原作:Monika Singh & Pradeep Chhetri 这是我们在 Monitorama 2022 上发表的演讲的改编稿。您可以在此处找到包含演讲者笔记的幻灯片和此处的视频。 当 Cloudflare 的请求抛出错误时,信息会记录在我们的 requests_error 管道中。错误日志用于帮助解…...
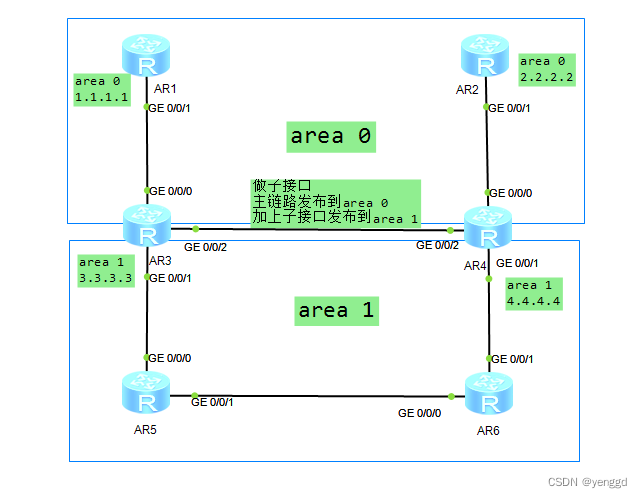
华为ospf路由协议防环和次优路径中一些难点问题分析
第一种情况是ar3的/0/0/2口和ar4的0/0/2口发布在区域1时,当ar1连接ar2的线断了以后,骨干区域就断了,1.1.1.1到2.2.2.2就断了,ping不通了。但ar5和ar6可以ping通2.2.2.2和1.1.1.1,ar3和ar4不可以ping通2.2.2.2和1.1.1.1…...
python-opencv划痕检测-续
python-opencv划痕检测-续 这次划痕检测,是上一次划痕检测的续集。 处理的图像如下: 这次划痕检测,我们经过如下几步: 第一步:读取灰度图像 第二步:进行均值滤波 第三步:进行图像差分 第四步࿱…...

c++[string实现、反思]
我的码云 我的string码云 分析总结 1.项目结构 所有的类和函数需要在namespace中实现,要和string高度对应 private:char* _str;//字符串size_t _size;//有效长度size_t _capacity;//总空间,包括\0const static size_t npos-1;2.定义变量 <1> 所…...

c++版本opencv计算灰度图像的轮廓点
代码 #include<iostream> #include<opencv.hpp>int main() {std::string imgPath("D:\\prostate_run\\result_US_20230804_141531\\mask\\us\\104.bmp");cv::Mat imgGray cv::imread(imgPath, 0);cv::Mat kernel cv::getStructuringElement(cv::MORPH…...

【05】ES6:函数的扩展
一、函数参数的默认值 ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面。 1、基本用法 默认值的生效条件 不传参数,或者明确的传递 undefined 作为参数,只有这两种情况下,默认值才会生效。 注意:null 就…...
Ubuntu20.04安装搜狗输入法
1、安装包下载 搜狗输入法linux-首页搜狗输入法for linux—支持全拼、简拼、模糊音、云输入、皮肤、中英混输https://shurufa.sogou.com/linux点击立即下载,根据自己的硬件选择deb安装包。 2、输入法安装 当第一步完成以后,页面会自动跳转至搜狗的安装…...

linux的基础命令
文章目录 linux的基础命令一、linux的目录结构(一)Linux路径的描述方式 二、Linux命令入门(一)Linux命令基础格式 三、ls命令(一)HOME目录和工作目录(二)ls命令的参数1.ls命令的-a选…...

linux查询某个进程使用的内存量
linux查询某个进程使用的内存量 查进程用的内存,查看进程占用的内存量,centos查询内存使用 查某个进程id使用的内存量 ps -p 24450 -o rss | awk {print int($1/1024)"MB"} 该命令的含义是: ps -p 24450: 查找进程ID为24450的进…...

list的总结
目录 1.什么是list 1.1list 的优势和劣势 优势: 劣势: 2.构造函数 2.1 default (1) 2.2 fill (2) 2.3 range (3) 2.4 copy (4) 3.list iterator的使用 3.1. begin() 3.2. end() 3.3迭代器遍历 4. list容量函数 4.1. empty() 4.2. siz…...
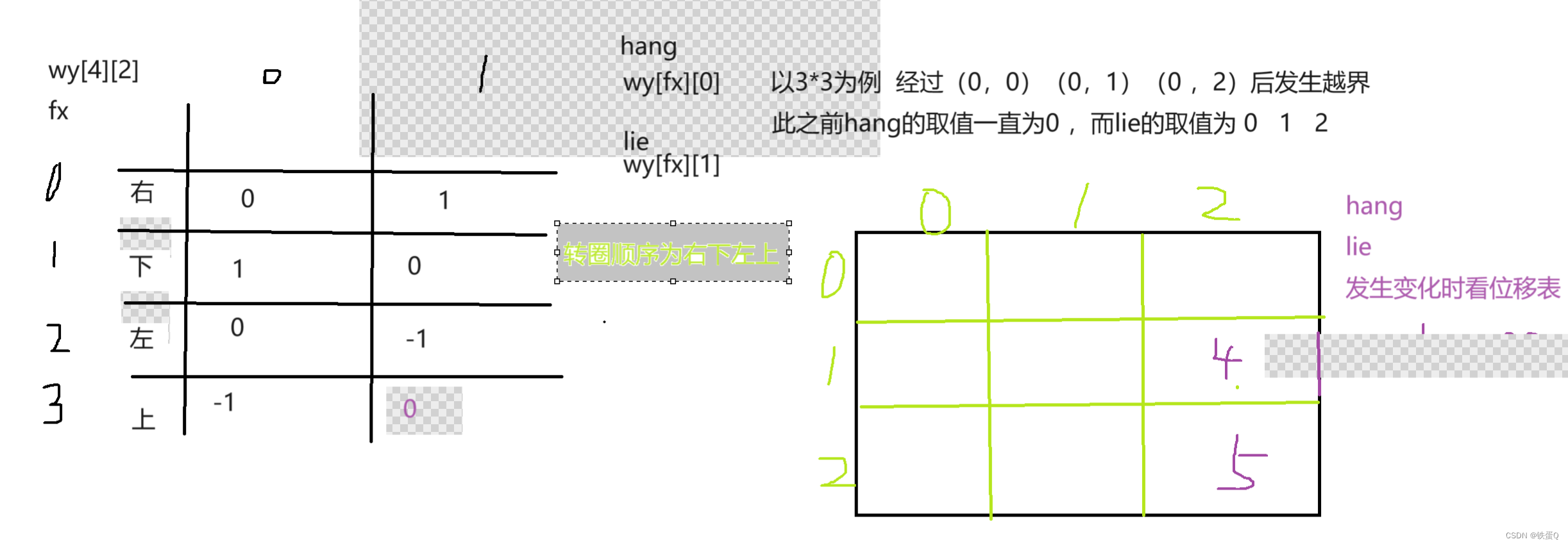
c语言数字转圈
数字转圈 题干输入整数 N(1≤N≤9),输出如下 N 阶方阵。 若输入5显示如下方阵: * 1** 2** 3** 4** 5* *16**17**18**19** 6* *15**24**25**20** 7* *14**23**22**21** 8* *13**12**11**10** 9*输入样例3输出样例* 1*…...
Apache Superset数据分析平台如何实现公网实时远程访问数据【内网穿透】
文章目录 前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网穿透,实现公网访问3. 设置固定连接公网地址 前言 Superset是一款由中国知名科技公司开源的“现代化的…...

避坑指南:为什么你用自己的数据聚类Anchors后,YOLO模型效果反而变差了?
为什么自定义Anchors聚类后YOLO性能下降?5个关键陷阱与解决方案 当你兴奋地将自定义数据集聚类得到的Anchors应用到YOLO模型时,却发现检测精度不升反降——这种挫败感我深有体会。去年在开发工业缺陷检测系统时,我曾连续三周被困在这个问题里…...

如何快速部署本地AI浏览器助手:Page Assist完整配置指南
如何快速部署本地AI浏览器助手:Page Assist完整配置指南 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist 在数据隐私日益重要的今天&a…...

**ROS机器人系统中基于Python的动态行为树实现与调试实战**在现代机器人开发中,**行为树(Behavior Tree
ROS机器人系统中基于Python的动态行为树实现与调试实战 在现代机器人开发中,行为树(Behavior Tree, BT) 已成为构建复杂、可维护任务逻辑的核心工具之一。尤其是在 ROS(Robot Operating System) 环境下,结…...

LVGL Spinner控件调参避坑指南:从卡顿到丝滑,我只改了这两个参数
LVGL Spinner控件性能调优实战:从参数解析到流畅动画的终极方案 在嵌入式GUI开发中,加载动画的流畅度往往直接关系到用户体验的第一印象。最近在开发智能家居控制面板时,我发现一个有趣的现象:同样的LVGL Spinner控件,…...

别再手动挖洞了!用fscan这款开源神器,5分钟搞定内网资产梳理与高危漏洞初筛
内网渗透效率革命:如何用fscan实现一键式资产发现与漏洞定位 当你在凌晨两点接到紧急渗透测试任务时,是否还在为繁琐的手动信息收集而头疼?传统的内网渗透流程往往需要组合多个工具:先用nmap扫描存活主机,再针对开放端…...

别再只用平均值了!用Python的sklearn QuantileRegressor做分位数回归,预测区间更靠谱
分位数回归实战:用QuantileRegressor构建更可靠的预测区间 当我们在电商平台上预测下个季度的销售额时,传统线性回归给出的"平均预测值"往往让人心里没底——那些突然爆款的商品和滞销的长尾商品会让预测误差大得惊人。这时候,分位…...
)
告别Appium!用Python的uiautomator2+weditor 0.6.4搞定安卓自动化测试(附编码避坑指南)
轻量化安卓自动化测试:Python uiautomator2与weditor实战指南 在移动应用测试领域,Appium曾长期占据主导地位,但其复杂的配置环境让不少开发者望而却步。如今,基于Python的uiautomator2与weditor组合提供了一种更轻量、更高效的替…...

鸣潮自动化终极指南:如何用ok-ww解放双手,轻松管理你的游戏时间
鸣潮自动化终极指南:如何用ok-ww解放双手,轻松管理你的游戏时间 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves …...

Phi-3.5-mini-instruct部署教程:WSL2环境下Windows本地运行vLLM+Chainlit全步骤
Phi-3.5-mini-instruct部署教程:WSL2环境下Windows本地运行vLLMChainlit全步骤 1. 环境准备与快速部署 在开始之前,请确保你的Windows系统已启用WSL2并安装了Ubuntu发行版。本教程将指导你完成从零开始的完整部署流程。 1.1 系统要求 Windows 10/11 …...

Simulink项目复用实战:一个模型适配多个客户需求,全靠可变子系统
Simulink项目复用实战:一个模型适配多个客户需求,全靠可变子系统 在工业自动化、汽车电子和航空航天等领域,系统工程师常常面临一个棘手问题:如何用同一套控制模型满足不同客户的定制化需求?传统做法是为每个客户单独维…...