Node.js入门指南(三)
目录
Node.js 模块化
介绍
模块暴露数据
导入模块
导入模块的基本流程
CommonJS 规范
包管理工具
介绍
npm
cnpm
yarn
nvm的使用
我们上一篇文章介绍了Node.js中的http模块,这篇文章主要介绍Node.js的模块化,包管理工具以及nvm的使用。
Node.js 模块化
介绍
在Node.js中模块化的概念是非常重要的,我们将一个复杂的程序文件拆分成多个文件的过程就是模块化,拆出来的每一个文件就是一个模块。模块的特点是它内部的数据是私有的,但是它可以通过向外面暴露数据来让其他的模块使用。一个项目在编码的过程中如果使用这种方式来进行那这个项目就是模块化项目。
模块化的好处可以让我们减少命名冲突的问题,当我们的程序都写在同一个文件中时,声明变量很容易造成命名冲突的问题,因此使用模块化可以在一定的程度上减少这种问题。其次是模块化具有高复用性,假设我们设计一个功能,然后在多个地方需要使用到它,我们就可以让该功能模块单独地放在一个文件中,直接进行调用即可,而不需要重复地编写相应的功能。最后就是高维护性,模块化也让后期的维护更加的容易轻松。
模块暴露数据
模块暴露数据的方式有两种:第一种是:module.exports = value 。第二种是使用:exports.name = value的方式。module.exports 可以暴露任意数据,比如对象,字符串或者数字等。
//me.js
function study(){console.log('今天学习Node.js');
}
function play(){console.log('今天摆烂');
}
//暴露数据方式一
module.exports={study,play
};//暴露数据方式二
exports.study=study;
exports.play=play;//index.js
//导入模块
const plan=require('./me.js');plan.study();
plan.play();
以上为两个方式的暴露形式,需要注意的是不能使用 exports = value 的形式暴露数据。因为 exports = module.exports = {} ,require 返回的是目标模块中 module.exports 的值。因此假设我们直接编写exports=study,那么module.exports的值还是{},因此requir返回的值就是{}。若我们使用exports.study=study的方式进行暴露,此时,就会向{}中添加一个为study的属性,而module.exports与exports是执行的同一个地址,因此module.exports中就存在study,因此就可以成功进行暴露数据。
导入模块
在模块中我们使用 require 传入文件路径即可引入文件。上面的代码我们也有进行导入的编写了。但是导入需要注意以下的一些事项:
1️⃣对于自己创建的模块,导入时路径建议写相对路径,且不能省略./和../。
2️⃣js和json文件导入时可以不写后缀,c/c++编写的node扩展文件也可以不写后缀,但是一般用不到。
3️⃣如果导入其他类型的文件,会以js文件进行处理。
4️⃣如果导入的路径是个文件夹,则会首先检测该文件夹下package.json文件中main属性对应的文件,如果存在则导入,反之如果文件不存在会报错。如果main属性不存在,或者package.json不存在,则会尝试导入文件夹下的index.js和index.json,如果还是没有找到,就会报错。
//创建一个path文件夹,文件夹里面创建一个package.json以及main.js文件。//package.json
{"main":"./main.js"
}//main.js
module.exports='我是main文件';//index.js
//导入模块
const plan=require('./page');console.log(plan);//我是main文件5️⃣导入node.js内置模块时,直接require模块的名字即可,无需加./和../。
导入模块的基本流程
Node.js导入模块的基本流程如下:首先它会对我们传入的文件路径转为绝对路径,定位目标文件。接着会进行缓存的检测,它会检测导入的文件是否之前有导入过,若该模块有相应的缓存,那它会直接返回对应的文件数据。若在缓存中检测不到对应的文件,它会对目标文件进行读取。接着执行一个函数,获取module.exports 的值。最后缓存模块,并将module.exports 的值返回。
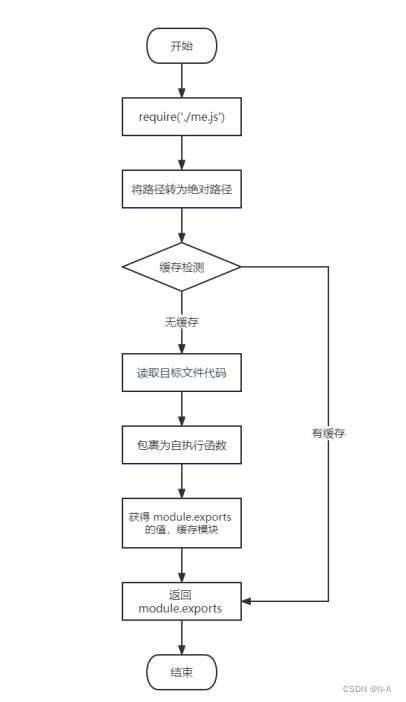
function require(file){//1.将相对路径转为绝对路径,定位目标文件let absolutePath=path.resolve(__dirname,file);//2.缓存检测if(caches[absolutePath]){return caches[absolutePath];}//3.读取文件的代码let code=fs.readFileSync(absolutePath).toString();//4.包裹为一个函数,然后执行let module={};let exports=module.exports={};(function(exports,require,module,__filename,__dirname){const test={name:'N-A'}module.exports=test;//输出console.log(arguments.callee.toString());})(exports,require,module,__filename,__dirname)//5.缓存结果caches[absolutePath]=module.exports;
}const m=require('./me.js');至于上面中间执行的函数如果查看呢?我们可以使用arguments.callee.toString() 查看自执行函数。
//show.js
const test={name:'N-A'
}
module.exports=test;
console.log(arguments.callee.toString())//输出结果
function (exports, require, module, __filename, __dirname) {
const test={name:'N-A'
}
module.exports=test;
console.log(arguments.callee.toString())
}CommonJS 规范
最后介绍一下CommonJS规范,我们只需要知道:module.exports 、 exports 以及 require 这些都是 CommonJS 模块化规范中的内容。而 Node.js 是实现了 CommonJS 模块化规范,二者关系有点像 JavaScript 与 ECMAScript。
包管理工具
介绍
在介绍包管理工具之前,我们需要知道什么是包,包是代表一组特定功能的源码集合。简单理解就是包有很多的功能,我们如果需要实现什么功能我们可以使用对应的包。当我们使用包时,我们就需要使用到包管理工具,比如:npm、cnpm或者yarn。这些包管理工具可以对包进行下载安装、更新、删除以及上传等操作。它能够提高我们的开发效率。
npm
npm 全称 Node Package Manager,它是 node.js 官方内置的包管理工具。在我们安装Node.js时,npm已经自动安装了npm,我们只需要在命令窗口通过npm -v查看相应的版本号即可,若有显示版本号即表示npm已经安装。
使用npm首先我们需要在将文件夹初始化为一个包,后续才能够正常地安装以及下载包。有两种方式可以进行初始化,第一种是直接输入npm init,然后进行交互式地进行创建。它会一步一步地引导你进行输入,若直接按回车它会使用默认的值。每个配置项的具体含义如下:
{
"name": "1-npm", #包的名字
"version": "1.0.0", #包的版本
"description": "", #包的描述
"main": "index.js", #包的入口文件
"scripts": { #脚本配置
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "", #作者
"license": "ISC" #开源证书
}当我们完成操作时,文件夹下面会出现一个package.json文件,该文件为包的配置文件,每个包都必须要有package.json。第二种方式可以使用 npm init -y 或者 npm init --yes 极速创建 package.json。就不需要一步一步地按里面的问题来创建了。
但是在初始化的过程中还需要注意以下的一些事项:
1️⃣package name ( 包名 ) 不能使用中文、大写,默认值是 文件夹的名称 ,所以文件夹名称也不能使用中文和大写。
2️⃣version ( 版本号 )要求 x.x.x 的形式定义, x 必须是数字,默认值是 1.0.0。
3️⃣ISC 证书与 MIT 证书功能上是相同的,关于开源证书扩展阅读http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html
4️⃣package.json 可以手动创建与修改。
那我们如果去寻找这些包呢?我们可以访问对应的网站去查找我们需要的包,并通过它的介绍去安装以及使用对应的包。
下载包我们可以通过 npm install 和 npm i 命令安装包。假设我们需要安装uniq(数组去重)这个包,我们就可以使用npm i uniq来进行安装。安装成功之后我们可以在文件夹下看到新增的两个资源,node_modules 文件夹:主要用于存放下载的包,以及package-lock.json为包的锁文件,用于锁定包的版本。
安装 uniq 之后, uniq 就是当前这个包的一个 依赖包 ,有时会简称为依赖。比如我们创建一个包名字为 A,A 中安装了包名字是 B,我们就说 B 是 A 的一个依赖包 ,也会说 A 依赖 B。
//我们编写一个index.js文件用于导入uniq包进行使用:
//导入包
const req=require('uniq');
let arr=[1,2,34,2,1,2,1]
console.log(req(arr));//[1,2,34]require 导入 npm 包基本流程主要是:在当前文件夹下 node_modules 中寻找同名的文件夹。若找不到则在上级目录中下的node_modules中寻找同名的文件夹,直至找到磁盘根目录。
同时,在npm安装包时我们可以设置相应的依赖类型,主要有两个选项:生产依赖以及开发依赖。主要的命令形式如下表。当我们没有特意设置时都会默认地安装生产依赖。
| 类型 | 命令 | 补充 |
| 生产依赖 | npm i -S uniq npm i --save uniq | -S 等效于 --save , -S 是默认选项 包信息保存在 package.json 中 dependencies 属性 |
| 开发依赖 | npm i -D less npm i --save-dev less | -D 等效于 --save-dev 包信息保存在 package.json 中 devDependencies 属性 |
那我们如何判断安装的包应该属于生产依赖还是开发依赖呢?我们可以到相应的包安装文档里面进行查找,会有对应提示。或者自己进行判断,生产依赖是开发阶段以及后续的上线运行阶段都需要使用到的依赖包。而开发依赖只在开发阶段使用的依赖包。可以通过自己的需求来进行相应地设置。
同时在安装包的时候我们可以指定包相应的版本号,通过npm i <包名@版本号>。来选择相应的包版本号。当我们安装的包不需要时,我们可以使用npm r 包名或者npm remove 包名来进行包的删除。
上述我们提到的包安装都是局部的安装,除了局部安装我们还可以进行全局安装,使用npm i -g 包名即可进行全局地安装。进行全局安装的包可以在任意的位置进行访问运行,它不受工作目录的影响。我们以npm i -g nodemon为例,但我们全局安装了nodemon之后,我们就可以使用它来自动重启node应用程序了。在原本我们使用node index.js来运行文件当文件有修改的时候,需要重启,但是若使用nodemon index.js则可以自动地帮助我们重启服务。
但是我们直接输入会报错,我们需要修改一些配置。有两种方式:第一是是将我们终端的默认配置文件修改为Command Prompt。第二种是以管理员的身份打开powershell命令行,输入命令set-ExecutionPolicy remoteSigned并输入A,回车同样能够生效。
当我们在项目开发的阶段,我们需要将代码发送给队友时,我们不可能直接将我们整个项目给队友,因为我们下载了包,因此node_modules文件夹会特别地大。一般发送给队友之前我们都会将node_modules删除。之后队友拿到我们的代码时,它可以通过npm i这个命令来进行安装包依赖的下载。该命令会根据package.json以及package-lock.json的依赖声明安装依赖。
我们还可以配置 package.json 中的 scripts 属性来配置命令别名,让我们可以更简单的执行命令。配置完成之后,可以使用别名执行命令。例如:
{
.
.
.
"scripts": {
"server": "node server.js",
"start": "node index.js",
},
.
.
}配置完成之后,可以使用别名执行命令。直接使用npm run server以及npm (run) start来进行运行。npm start一般用来启动项目。npm run 有自动向上级目录查找的特性,跟 require 函数也一样对于陌生的项目,我们可以通过查看 scripts 属性来参考项目的一些操作 。
当我们在使用npm下载包时,一般速度都会很慢,此时我们可以配置淘宝镜像来提高其下载的速度。可以直接使用npm config set registry https://registry.npmmirror.com/进行配置。或者使用nrm工具来进行配置,使用nrm来进行配置主要是可以更加简便地进行配置,不需要记住对应的配置地址,同时还可以进行切换。首先需要npm i -g nrm进行安装nrm,然后修改镜像nrm use taobao。最后通过npm config list命令来检查配置即可,若出现为https://registry.npmmirror.com/则表示配置成功。若想要切换为官网,直接使用nrm use npm即可。
我们还可以将自己开发的工具包发布到 npm 服务上,方便自己和其他开发者使用,操作步骤如下:1. 创建文件夹,并创建文件index.js, 在文件中声明函数,使用 module.exports 暴露。2. npm 初始化工具包,package.json 填写包的信息 。3. 注册账号 https://www.npmjs.com/signup 并 登录账号 。4. 若此时你的npm使用的是淘宝的镜像,需要修改为官方的官方镜像 (命令行中运行 nrm use npm ) 5. 命令行下 npm login 填写相关用户信息 。6. 命令行下 npm publish 提交包。包的下载以及使用步骤与其他的包一样。发布之后若想要对包进行更新,需要修改package.json文件中的版本号,使用npm publish发布更新。若你想要删除包我们可以使用:npm unpublish --foce来进行删除。
cnpm
cnpm也是一个包管理工具,它的操作步骤与npm大体相同。cnpm 服务部署在国内阿里云服务器上, 因此相比于npm,cnpm包的下载速度更快。我们通过npm install -g cnpm --registry=https://registry.npmmirror.com来进行安装cnpm。它的操作命令都与npm相似,只是npm变成cnpm,其他的保持不变。
yarn
yarn 是由 Facebook 在 2016 年推出的新的 Javascript 包管理工具,官方网址。yarn的特点是速度快,安全性高以及可靠。但是在安装全局的依赖时,需要设置对应的path环境变量才能够进行使用。我们使用npm i -g yarn来进行安装yarn。它相应的命令如下表:
| 功能 | 命令 |
| 初始化 | yarn init / yarn init -y |
| 安装包 | yarn add uniq 生产依赖 yarn add less --dev 开发依赖 yarn global add nodemon 全局安装 |
| 删除包 | yarn remove uniq 删除项目依赖包 yarn global remove nodemon 全局删除包 |
| 安装项目依赖 | yarn |
| 运行命令别名 | yarn <别名> 不需要添加 run |
nvm的使用
但是我们想要改变node.js的版本时,原本我们会先将自己安装的版本先卸载掉,然后再下载对应自己想要的版本。但是如果使用nvm,我们可以轻松地进行版本的安装、卸载以及切换。首先先下载 nvm 。找到 nvm-setup.exe 下载即可。此时需要确保先将电脑原本的Node.js先卸载掉,在安装nvm,不然后续无法进行版本的切换。
| 命令 | 说明 |
| nvm list available | 显示所有可以下载的 Node.js 版本 |
| nvm list | 显示已安装的版本 |
| nvm install x.x.x | 安装 x.x.x 版本的 Node.js |
| nvm install latest | 安装最新版的 Node.js |
| nvm uninstall x.x.x | 删除某个版本的 Node.js |
| nvm use x.x.x | 切换到 x.x.x 的 Node.js |
好啦,本文就这里结束了!
相关文章:
Node.js入门指南(三)
目录 Node.js 模块化 介绍 模块暴露数据 导入模块 导入模块的基本流程 CommonJS 规范 包管理工具 介绍 npm cnpm yarn nvm的使用 我们上一篇文章介绍了Node.js中的http模块,这篇文章主要介绍Node.js的模块化,包管理工具以及nvm的使用。 Node…...

Leetcode—2824.统计和小于目标的下标对数目【简单】
2023每日刷题(三十九) Leetcode—2824.统计和小于目标的下标对数目 实现代码 class Solution { public:int countPairs(vector<int>& nums, int target) {int n nums.size();sort(nums.begin(), nums.end());int left 0, right left 1;i…...

【基础架构】part-2 可扩展性
文章目录 可扩展性(Scalability)2.1 水平扩展2.2 垂直扩展2.3 弹性扩展 三、可靠性(Reliability)3.1 容错机制3.2 错误处理和恢复策略3.3 监控和自动化运维 四、 安全性(Security)4.1 身份验证和授权4.2 加…...

[SWPUCTF 2021 新生赛]no_wakeup
直接赋值即可 $a ->admin admin; $a ->passwd wllm; 发现没有绕过,改成大于2的绕过__wakeup 这是因为PHP在反序列化时会检查序列化字符串的长度,如果长度小于等于2,则不会调用__wakeup()方法。...
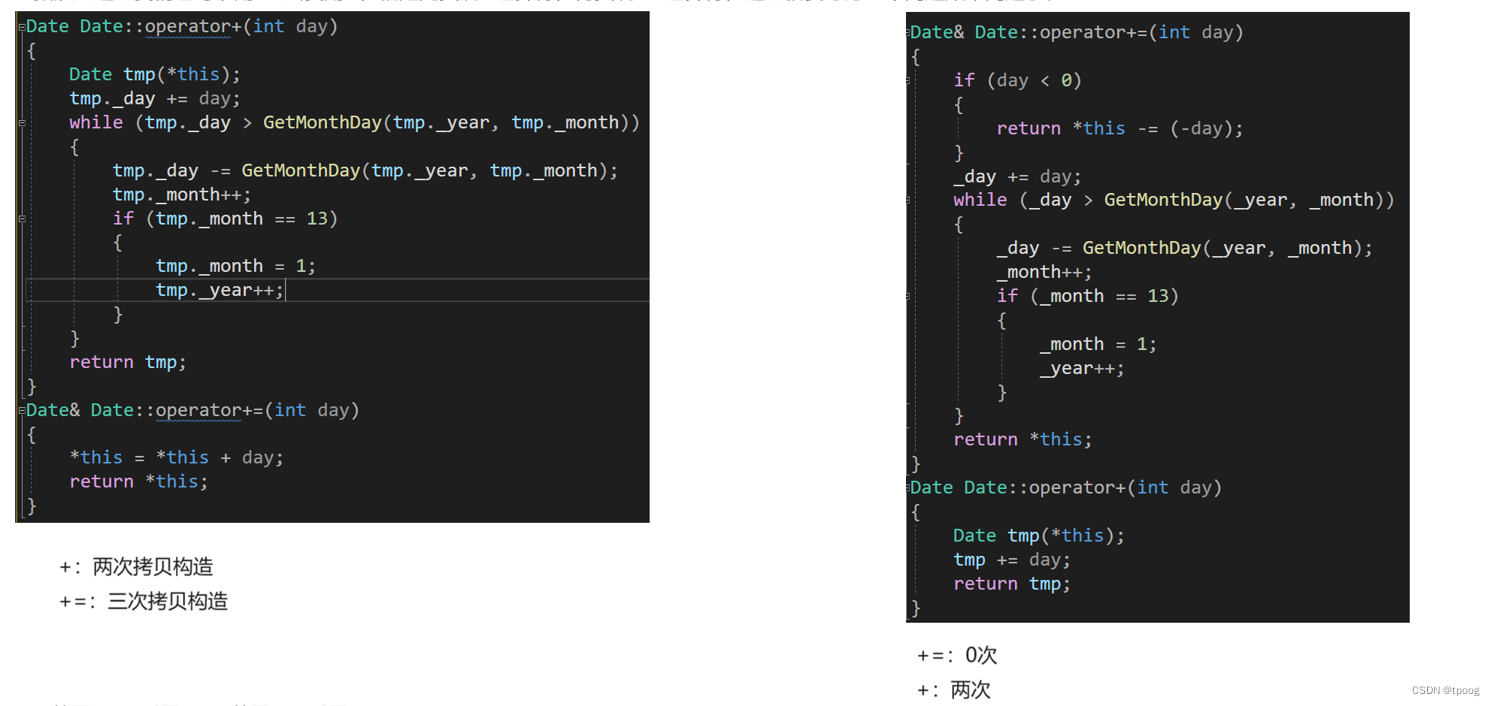
类和对象(3)日期类的实现
日期类的实现 一,声明二,函数成员定义2.1构造函数2.2获取月份天数2.3比较运算符2.3.1等于和大于2.3.2其他 2.4计算运算符2.4.1 &&2.4.2-&&- 2.5日期-日期 一,声明 class Date { public:Date(int year 1, int month 1, int…...

分布式篇---第五篇
系列文章目录 文章目录 系列文章目录前言一、你知道哪些限流算法?二、说说什么是计数器(固定窗口)算法三、说说什么是滑动窗口算法前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去…...
)
SpringMVC(二)
八、HttpMessageConverter HttpMessageConverter,报文信息转换器,将请求报文转换为Java对象,或将Java对象转换为响应报文 HttpMessageConverter提供了两个注解和两个类型:RequestBody,ResponseBody,Reque…...

kafka操作的一些坑
1.如果Offset Explorer能够检测到kafka中的数据,但是自己的kafka无法读取到 这个问题主要是由于kafka中的信息已经被消费掉了造成的 consumer.commitAsync();这里如果已经消费掉了kafka的信息,那么已经被消费掉的kafka数据就不会被再读取掉,…...

转录组学习第5弹-比对参考基因组
比对参考基因组 在构建文库的过程中需要将DNA片段化,因此测序得到的序列只是基因组的部分序列。为了确定测序reads在基因组上的位置,需要将reads比对回参考基因组上,这个步骤叫做比对,即文献中所提到的alignment或mapping。包括基…...
部署系列六基于nndeploy的深度学习 图像降噪unet部署
文章目录 1.直接在源代码demo中修改2. 如何修改呢?3. 修改 graph4. 总结 https://github.com/DeployAI/nndeploy https://nndeploy-zh.readthedocs.io/zh/latest/introduction/index.html 通过以上2个官方链接对nndeploy基本的使用方法应该有所了解了。 下面就是利用…...

使用 ClickHouse 做日志分析
原作:Monika Singh & Pradeep Chhetri 这是我们在 Monitorama 2022 上发表的演讲的改编稿。您可以在此处找到包含演讲者笔记的幻灯片和此处的视频。 当 Cloudflare 的请求抛出错误时,信息会记录在我们的 requests_error 管道中。错误日志用于帮助解…...
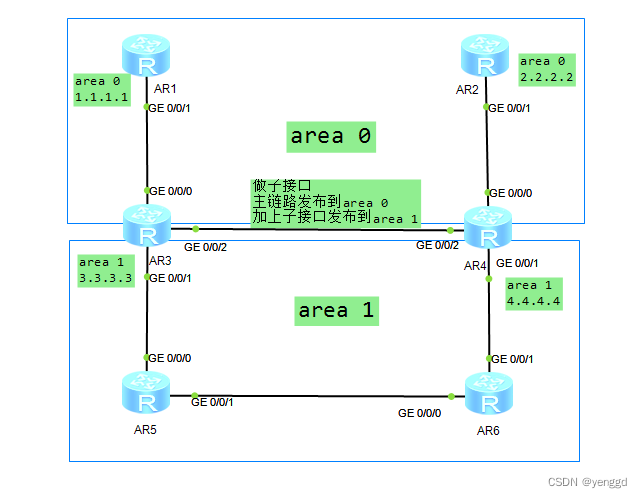
华为ospf路由协议防环和次优路径中一些难点问题分析
第一种情况是ar3的/0/0/2口和ar4的0/0/2口发布在区域1时,当ar1连接ar2的线断了以后,骨干区域就断了,1.1.1.1到2.2.2.2就断了,ping不通了。但ar5和ar6可以ping通2.2.2.2和1.1.1.1,ar3和ar4不可以ping通2.2.2.2和1.1.1.1…...
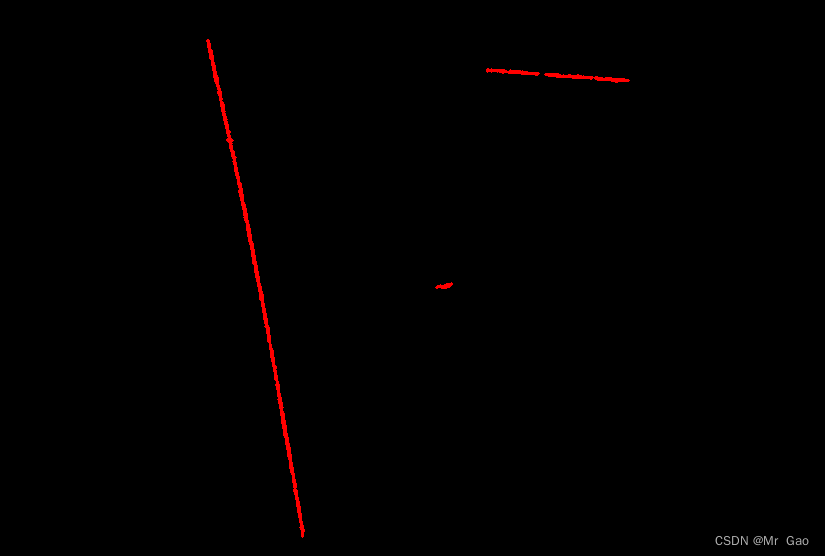
python-opencv划痕检测-续
python-opencv划痕检测-续 这次划痕检测,是上一次划痕检测的续集。 处理的图像如下: 这次划痕检测,我们经过如下几步: 第一步:读取灰度图像 第二步:进行均值滤波 第三步:进行图像差分 第四步࿱…...

c++[string实现、反思]
我的码云 我的string码云 分析总结 1.项目结构 所有的类和函数需要在namespace中实现,要和string高度对应 private:char* _str;//字符串size_t _size;//有效长度size_t _capacity;//总空间,包括\0const static size_t npos-1;2.定义变量 <1> 所…...

c++版本opencv计算灰度图像的轮廓点
代码 #include<iostream> #include<opencv.hpp>int main() {std::string imgPath("D:\\prostate_run\\result_US_20230804_141531\\mask\\us\\104.bmp");cv::Mat imgGray cv::imread(imgPath, 0);cv::Mat kernel cv::getStructuringElement(cv::MORPH…...

【05】ES6:函数的扩展
一、函数参数的默认值 ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面。 1、基本用法 默认值的生效条件 不传参数,或者明确的传递 undefined 作为参数,只有这两种情况下,默认值才会生效。 注意:null 就…...
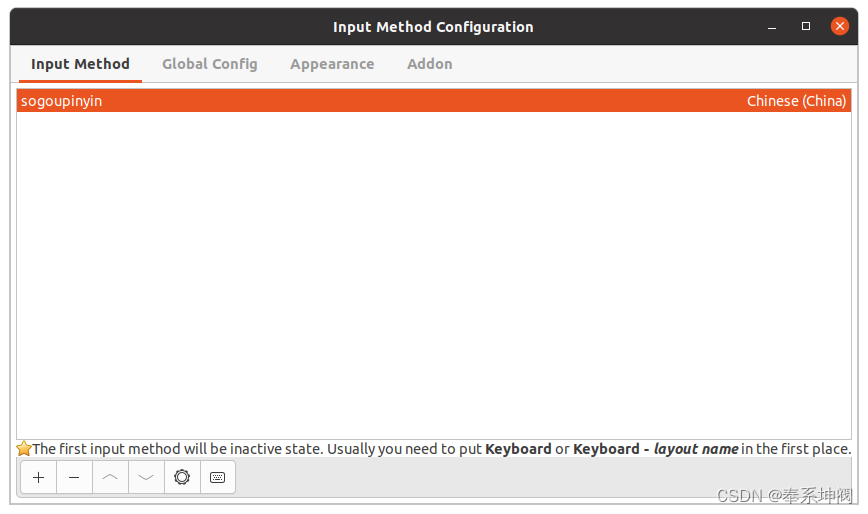
Ubuntu20.04安装搜狗输入法
1、安装包下载 搜狗输入法linux-首页搜狗输入法for linux—支持全拼、简拼、模糊音、云输入、皮肤、中英混输https://shurufa.sogou.com/linux点击立即下载,根据自己的硬件选择deb安装包。 2、输入法安装 当第一步完成以后,页面会自动跳转至搜狗的安装…...

linux的基础命令
文章目录 linux的基础命令一、linux的目录结构(一)Linux路径的描述方式 二、Linux命令入门(一)Linux命令基础格式 三、ls命令(一)HOME目录和工作目录(二)ls命令的参数1.ls命令的-a选…...

linux查询某个进程使用的内存量
linux查询某个进程使用的内存量 查进程用的内存,查看进程占用的内存量,centos查询内存使用 查某个进程id使用的内存量 ps -p 24450 -o rss | awk {print int($1/1024)"MB"} 该命令的含义是: ps -p 24450: 查找进程ID为24450的进…...

list的总结
目录 1.什么是list 1.1list 的优势和劣势 优势: 劣势: 2.构造函数 2.1 default (1) 2.2 fill (2) 2.3 range (3) 2.4 copy (4) 3.list iterator的使用 3.1. begin() 3.2. end() 3.3迭代器遍历 4. list容量函数 4.1. empty() 4.2. siz…...

【深度解析】AUTOSAR EcuM:从启动到休眠的ECU状态管理核心
1. AUTOSAR EcuM模块的核心价值与定位 想象一下你正在驾驶一辆现代汽车,当你转动钥匙启动引擎时,仪表盘上的各种指示灯依次亮起,中控屏幕缓缓启动,空调系统开始工作——这一系列看似简单的动作背后,其实隐藏着一个复杂…...
)
从ESP32到HIFI5:一文搞懂Cadence Xtensa处理器家族那些事儿(含DSP指令集差异)
从ESP32到HIFI5:Cadence Xtensa处理器家族全解析 在嵌入式处理器领域,Xtensa架构以其独特的可配置性和扩展能力脱颖而出。作为Cadence旗下的核心产品线,Xtensa处理器家族涵盖了从通用微控制器到专用DSP的广泛解决方案。本文将深入剖析这一技术…...

3大核心优势解析:为什么DeepMosaics是智能马赛克处理的最佳选择?
3大核心优势解析:为什么DeepMosaics是智能马赛克处理的最佳选择? 【免费下载链接】DeepMosaics Automatically remove the mosaics in images and videos, or add mosaics to them. 项目地址: https://gitcode.com/gh_mirrors/de/DeepMosaics 在数…...

VLC for Android跨平台多媒体应用架构设计与大屏优化实现
VLC for Android跨平台多媒体应用架构设计与大屏优化实现 【免费下载链接】vlc-android VLC for Android, Android TV and ChromeOS 项目地址: https://gitcode.com/gh_mirrors/vl/vlc-android VLC for Android作为一款跨平台的多媒体播放解决方案,在Androi…...

告别系统休眠困扰:MouseJiggler鼠标模拟工具全解析
告别系统休眠困扰:MouseJiggler鼠标模拟工具全解析 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. 项目地…...

BetterNCM Installer深度评测:为什么这是最好的网易云插件解决方案
BetterNCM Installer深度评测:为什么这是最好的网易云插件解决方案 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM Installer是一款专为网易云音乐PC客户端打造的…...

Cesium标绘进阶:从静态Entity到动态Primitive的性能优化指南
Cesium标绘进阶:从静态Entity到动态Primitive的性能优化指南 当你的Cesium场景开始加载成千上万的动态标绘对象时,是否遇到过明显的性能下降?帧率骤降、交互卡顿、内存占用飙升——这些常见问题往往源于对Entity API的过度依赖。本文将带你深…...
的axis和keepdims参数在数据清洗与特征工程中的妙用)
NumPy进阶:除了求范数,np.linalg.norm()的axis和keepdims参数在数据清洗与特征工程中的妙用
NumPy工程化实践:用np.linalg.norm()的axis与keepdims重构数据预处理流程 当你面对一个500万行的用户行为特征矩阵时,是否会习惯性写出for循环来计算每行数据的L2范数?我曾用三小时调试一个维度不匹配的报错,最终发现只是忘记设置…...

普通人也能成为音频魔法师?揭秘Audacity的OpenVINO AI插件如何让音频编辑变得智能
普通人也能成为音频魔法师?揭秘Audacity的OpenVINO AI插件如何让音频编辑变得智能 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino…...

SMUDebugTool终极指南:深度解析AMD锐龙系统硬件参数调试开源工具
SMUDebugTool终极指南:深度解析AMD锐龙系统硬件参数调试开源工具 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...