【Spark入门】基础入门
【大家好,我是爱干饭的猿,本文重点介绍Spark的定义、发展、扩展阅读:Spark VS Hadoop、四大特点、框架模块、运行模式、架构角色。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【YOLOv5入门】目标检测》
1. Spark 框架概述
1.1 Spark 是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。

简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
为什么是统一分析引擎?
Spark是一款分布式内存计算的统一分析引擎。
其特点就是对任意类型的数据进行自定义计算。
Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用
程序计算数据。
Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
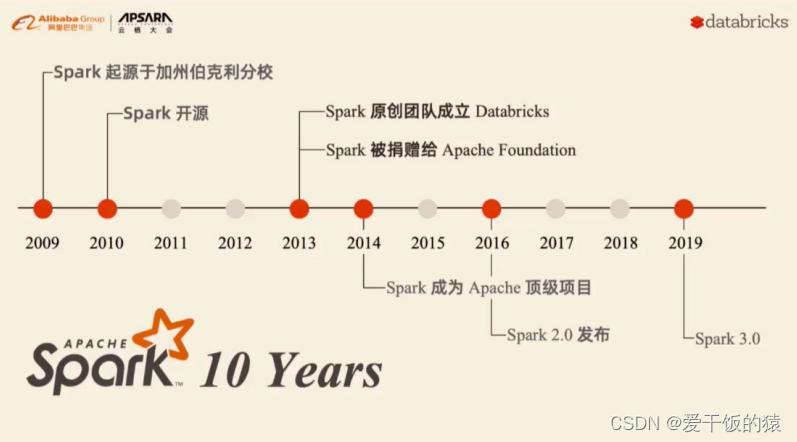
1.2 Spark风雨十年
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据处理框架。
Spark的发展历史,经历过几大重要阶段,如下图所示:
1.3 扩展阅读:Spark VS Hadoop
Spark和前面学习的Hadoop技术栈有何区别呢?

尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
面试题:Hadoop的基于进程的计算和Spark基于线程方式优缺点?
答案:Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加
载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
1.4 Spark 四大特点
1. 速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- 其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
- 其二、Spark 提供了非常丰富的算子(API), 可以做到复杂任务在一个Spark 程序中完成.
2. 易于使用
Spark 的版本已经更新到 Spark 3.2.0(截止日期2021.10.13),支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本。
3. 通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。

4. 运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。
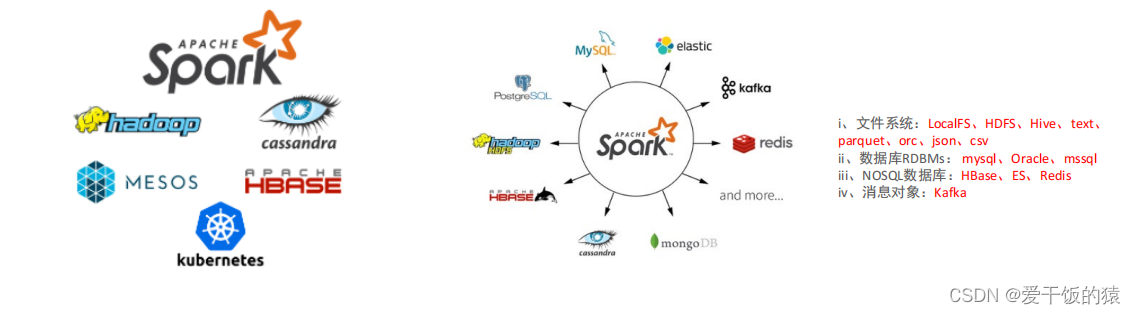
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
1.5 Spark 框架模块-了解
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上
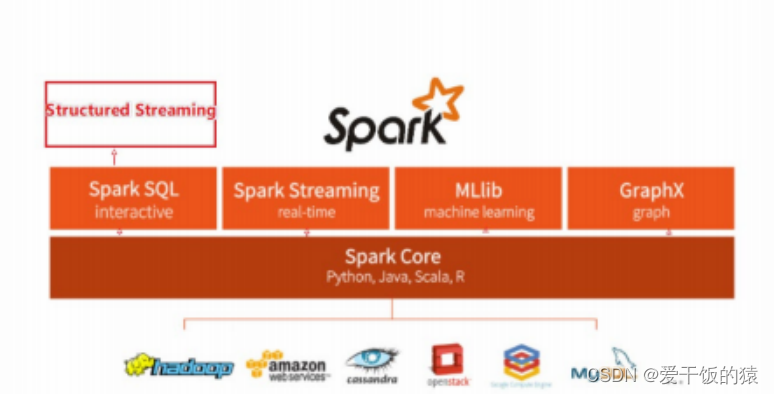
- Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
- SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
- SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
- MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
1.6 Spark 运行模式
Spark提供多种运行模式,包括:
- 本地模式(单机)
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境 - Standalone模式(集群)
Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境 - Hadoop YARN模式(集群)
Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境 - Kubernetes模式(容器集群)
Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境 - 云服务模式(运行在云平台上)
1.7 Spark 架构角色
1. YARN角色回顾
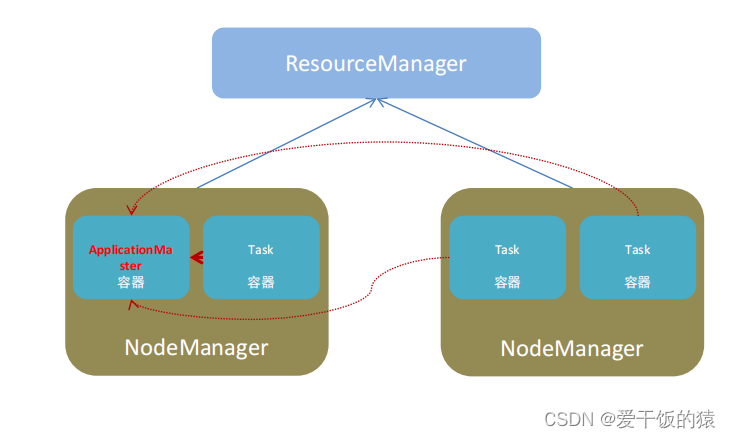
YARN主要有4类角色,从2个层面去看:
- 资源管理层面
- 集群资源管理者(Master):ResourceManager
- 单机资源管理者(Worker):NodeManager
- 任务计算层面
- 单任务管理者(Master):ApplicationMaster
- 单任务执行者(Worker):Task(容器内计算框
架的工作角色)
2. Spark运行角色
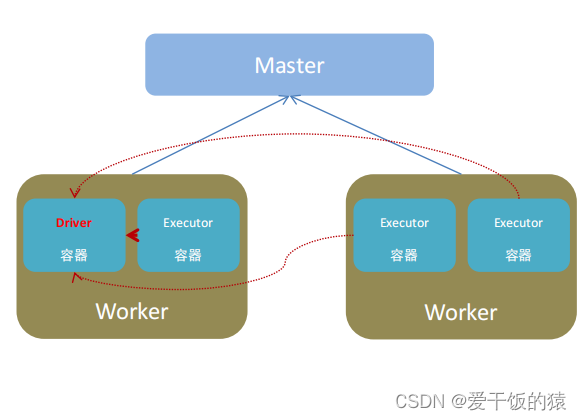
Spark中由4类角色组成整个Spark的运行时环境
- Master角色,管理整个集群的资源 - 类比与YARN的ResouceManager
- Worker角色,管理单个服务器的资源 - 类比于YARN的NodeManager
- Driver角色,管理单个Spark任务在运行的时候的工作 - 类比于YARN的ApplicationMaster
- Executor角色,单个任务运行的时候的一堆工作者,干活的 - 类比于YARN的容器内运行的TASK
从2个层面划分:
- 资源管理层面:
- 管理者: Spark是Master角色,YARN是ResourceManager
- 工作中: Spark是Worker角色,YARN是NodeManager
- 从任务执行层面:
- 某任务管理者: Spark是Driver角色,YARN是ApplicationMaster
- 某任务执行者: Spark是Executor角色,YARN是容器中运行的具体工作进程。
本篇文章内容摘自-黑马程序员
相关文章:
【Spark入门】基础入门
【大家好,我是爱干饭的猿,本文重点介绍Spark的定义、发展、扩展阅读:Spark VS Hadoop、四大特点、框架模块、运行模式、架构角色。 后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍ÿ…...

【自制开源】实时调参,手写字生成神器!大学生福音,告别繁琐的手写报告。
HandwritingGenerator HandwritingGenerator 是一个使用 PyQt6 制作的手写文本图片生成器。 该工具允许用户自定义多种效果,通过在左边配置效果参数,右边实时预览,并在调整好后输出图片。 效果预览 软件界面预览:一封情书&#x…...

Python 进阶(十一):高精度计算(decimal 模块)
《Python入门核心技术》专栏总目录・点这里 文章目录 1. 导入decimal模块2. 设置精度3. 创建Decimal对象4. 基本运算5. 比较运算6. 其他常用函数7. 注意事项8. 总结 大家好,我是水滴~~ 在进行数值计算时,浮点数的精度问题可能会导致结果的不准确性。为了…...

MCU常用文件格式
1. asm文件 asm是汇编语言源程序的扩展名,.asm文件是以asm作为扩展名的文件,是汇编语言的源程序文件。汇编语言(Assembly Language)是面向机器的程序设计语言,是利用计算机所有硬件特性并能直接控制硬件的语言。在汇编语言中,用助…...
【机器学习】On the Identifiability of Nonlinear ICA: Sparsity and Beyond
前言 本文是对On the Identifiability of Nonlinear ICA: Sparsity and Beyond (NIPS 2022)中两个结构稀疏假设的总结。原文链接在Reference中。 什么是ICA(Independent component analysis)? 独立成分分析简单来说,就是给定很多的样本X,通…...
)
RBAC(Role-Based Access Control,基于角色的访问控制)
1. RBAC核心概念 RBAC(Role-Based Access Control,基于角色的访问控制)是一种广泛应用于软件和系统中的权限管理模型。它通过将用户与角色关联,再将角色与访问权限关联,来管理用户对系统资源的访问。RBAC模型的主要特…...

C++const指针的两种用法
const int *p &a; 指向const变量的指针 指向const变量的指针const修饰的变量,只能由指向const变量的指针去指向 p &a1;const的位置,必须在*的左边指向const变量的指针,可以被改变,可以指向别的变量可以指向普通变量&am…...

【Proteus仿真】【51单片机】智能垃圾桶设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用报警模块、LCD1602液晶模块、按键模块、人体红外传感器、HCSR04超声波、有害气体传感器、SG90舵机等。 主要功能: 系统运行后…...

【Windows】执行tasklist/taskkill提示“错误:找不到”或者“ERROR: not found”的解决方案
原因 由于WinMgmt异常导致起不来,而WinMgmt是SVCHOST进程中的WMI服务,解决这个问题需要停止之后再重新启动。 WinMgmt是Windows 2000客户端管理的核心组件,当客户端应用程序连接或当管理程序需要它本身的服务时,这个进程就会初始…...

MS2630——Sub-1 GHz、低噪声放大器芯片
产品简述 MS2630 是一款 Sub-1 GHz 低功耗、低噪声放大器 (LNA) 芯 片。芯片采用先进制造工艺,采用 SOT23-6 的封装形式。 主要特点 ◼ 典型噪声系数: 1.57dB ◼ 典型功率增益: 16.3dB ◼ 典型输出 P1dB : -9.2dBm…...

车载以太网-数据链路层-MAC
文章目录 车载以太网MAC(Media Access Control)车载以太网MAC帧格式以太网MAC帧报文示例车载以太网MAC层测试内容车载以太网MAC(Media Access Control) 车载以太网MAC(Media Access Control)是一种用于车载通信系统的以太网硬件地址,用于在物理层上识别和管理数据包的传…...

Tomcat源码分析
Tomcat源码分析与实例 Tomcat是一个开源的Java Web服务器,它提供了一种简单的方式来部署和运行Java Web应用程序。本文将详细介绍Tomcat的源码分析和实例。 1. Tomcat源码分析 1.1 目录结构 Tomcat的源码目录结构如下: tomcat-x.y.z/ ├── bin/ ├…...
计算机视觉面试题-02
图像处理和计算机视觉基础 什么是图像滤波?有哪些常见的图像滤波器? 图像滤波是一种通过在图像上应用滤波器(卷积核)来改变图像外观或提取图像特征的图像处理技术。滤波器通常是一个小的矩阵,通过在图像上进行卷积…...
力扣日记11.27-【二叉树篇】二叉树的最大深度
力扣日记:【二叉树篇】二叉树的最大深度 日期:2023.11.27 参考:代码随想录、力扣 104. 二叉树的最大深度 题目描述 难度: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最…...
【数据结构】树的概念以及二叉树
目录 1 树概念及结构 1.1 树的概念 1.3 树的存储 2 二叉树的概念及结构 2.1 概念 2.2 特殊的二叉树 2.3 二叉树的性质 2.4 二叉树的存储结构 1 树概念及结构 1.1 树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组…...
软件测试职业规划导图
公司开发的产品专业性较强,软件测试人员需要有很强的专业知识,现在软件测试人员发展出现了一种测试管理者不愿意看到的景象: 1、开发技术较强的软件测试人员转向了软件开发(非测试工具开发); 2、业务能力较强的测试人员转向了软件…...
360压缩安装一半不动了?一分钟解决!
360压缩软件是我们常用的压缩软件,但是常常会遇到压缩安装到一半停止的情况,下面提供了一些可能的原因和解决办法,大家可以进行尝试~ 方法一:关闭防火墙和杀毒软件 有时候,防火墙和杀毒软件可能会阻止360压缩的安装过…...
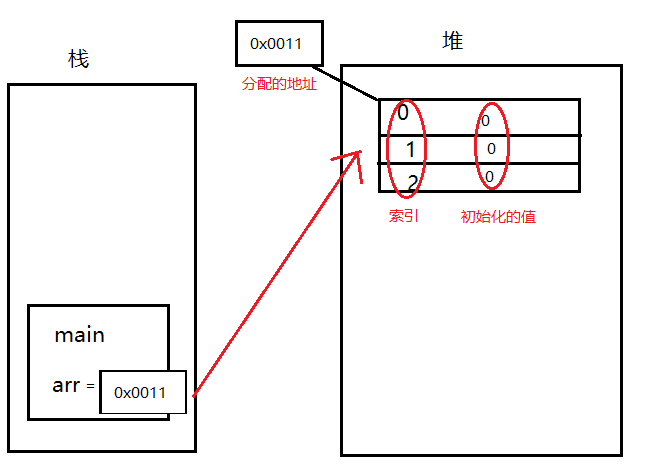
堆和栈的区别 重点来说一下堆和栈;堆与栈之间的联系
文章目录 堆和栈的区别重点来说一下堆和栈:那么堆和栈是怎么联系起来的呢? 堆与栈的区别 很明显: 今天来聊一聊java中的堆和栈,工作当中这两个也是经常遇到的,知识我们没有去注意理论上的这些内容,今天就来分享一下。…...

python 批量将图片存入excel单元格内
python 批量将图片存入excel单元格 示例代码1示例代码2 示例代码1 https://blog.csdn.net/wuyoudeyuer/article/details/128185284 # -*- coding: utf-8 -*- # Time : 2022-12-05 # Author : Carl_DJ 实现功能:在excel中,对应的名称后面,…...

Nginx常见的中间件漏洞
目录 1、Nginx文件名逻辑漏洞 2、Nginx解析漏洞 3、Nginx越权读取缓存漏洞 这里需要的漏洞环境可以看:Nginx 配置错误导致的漏洞-CSDN博客 1、Nginx文件名逻辑漏洞 该漏洞利用条件有两个: Nginx 0.8.41 ~ 1.4.3 / 1.5.0 ~ 1.5.7 php-fpm.conf中的s…...

STM32CubeMX+Keil5+ESP8266:基于HAL库的物联网设备快速联网实战
1. 环境准备与工具链搭建 第一次接触STM32ESP8266组合开发时,我花了整整两天时间才把开发环境理顺。现在回想起来,其实只需要三个核心工具:STM32CubeMX、Keil MDK-ARM和串口调试助手。建议使用Keil5版本,它对HAL库的支持最稳定。我…...

如何实现微信聊天记录的永久保存与智能分析
如何实现微信聊天记录的永久保存与智能分析 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg 在数字时代&…...

LoRA训练助手GPU算力优化:支持FP16/INT4双精度推理,显存占用降低58%
LoRA训练助手GPU算力优化:支持FP16/INT4双精度推理,显存占用降低58% 1. 为什么需要GPU算力优化 如果你尝试过训练自己的AI绘画模型,一定遇到过这样的困扰:生成训练标签时显存爆满、推理速度慢、甚至因为资源不足而中断进程。传统…...

2026本科毕业论文工具 TOP10:从选题到答辩,AI 帮你一键通关
毕业季的论文焦虑,几乎是每个本科生逃不开的 “必修课”。选题卡壳、文献堆砌、格式返工、查重降重反复折腾…… 与其硬熬,不如找对工具。今天就给大家整理了10 款超实用的 AI 毕业论文写作工具,尤其是榜首的 Paperxie,堪称本科生…...

PCD231 B101
ABB PCD231 B101 控制器是 ABB 公司生产的一款高性能励磁控制器模块,专为同步发电机和异步发电机的励磁系统设计,属于 ABB PCD 系列励磁控制器模块的一员。以下是关于该控制器的详细介绍:一、核心功能励磁控制:通过精确控制励磁机…...

【日常运维】Java服务在Windows平台上作为常驻服务的启动方式【winsw.exe】
文章目录[toc]一、下载winsw二、放置jar包三、配置启动信息四、启动服务五、在服务中查看服务是否启动成功六、调用服务是否成功七、指定编码格式八、启动服务一般一、下载winsw 二进制可执行文件下载地址: http://repo.jenkins-ci.org/releases/com/sun/winsw/win…...

【Nginx】Nginx防盗链的配置详解
前情提要:本篇博客详细介绍了防盗链,以及配置盗链盗取网站资源和配置防盗链防止别人盗取两种示例,通过本篇博客你可以学会利用nginx配置盗链和防盗链环境清单真实服务主机:172.25.254.10/24盗链主机:172.25.254.11/24一…...
方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区)
JavaScript WeakSet的has()方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区
JavaScript WeakSet的has()方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区 想象一下,你有一个只认人脸不认名字的侦探朋友。无论你如何描述一个人的特征,他只会摇头说:"除非让我亲眼看到这个人&…...

PSSE与IEEE数据格式互转实战:解决变压器参数异常的避坑指南
PSSE与IEEE数据格式互转实战:变压器参数异常分析与精准修正 电力系统仿真工程师在日常工作中经常面临不同软件平台间数据迁移的挑战。当您手头的IEEE标准潮流数据需要导入PSSE进行分析时,数据格式转换过程中的参数映射问题可能成为影响仿真精度的隐形杀…...
)
避坑指南:部署Qwen3-Embedding-4B常见问题及解决方案(附演示账号)
避坑指南:部署Qwen3-Embedding-4B常见问题及解决方案(附演示账号) 1. 部署前的准备工作 1.1 硬件环境检查 在部署Qwen3-Embedding-4B模型前,需要确认您的硬件配置满足最低要求: GPU要求:至少需要NVIDIA…...