Java核心知识点整理大全18-笔记
Java核心知识点整理大全-笔记_希斯奎的博客-CSDN博客
Java核心知识点整理大全2-笔记_希斯奎的博客-CSDN博客
Java核心知识点整理大全3-笔记_希斯奎的博客-CSDN博客
Java核心知识点整理大全4-笔记-CSDN博客
Java核心知识点整理大全5-笔记-CSDN博客
Java核心知识点整理大全6-笔记-CSDN博客
Java核心知识点整理大全7-笔记-CSDN博客
Java核心知识点整理大全8-笔记-CSDN博客
Java核心知识点整理大全9-笔记-CSDN博客
Java核心知识点整理大全10-笔记-CSDN博客
Java核心知识点整理大全11-笔记-CSDN博客
Java核心知识点整理大全12-笔记-CSDN博客
Java核心知识点整理大全13-笔记-CSDN博客
Java核心知识点整理大全14-笔记-CSDN博客
Java核心知识点整理大全15-笔记-CSDN博客
Java核心知识点整理大全16-笔记-CSDN博客
Java核心知识点整理大全17-笔记-CSDN博客
往期快速传送门👆:
目录
12. Kafka
12.1.1. Kafka 概念
12.1.2. Kafka 数据存储设计
12.1.2.1. partition 的数据文件(offset,MessageSize,data)
12.1.2.2. 数据文件分段 segment(顺序读写、分段命令、二分查找)
12.1.2.3. 数据文件索引(分段索引、稀疏存储)
12.1.3. 生产者设计
12.1.3.1. 负载均衡(partition 会均衡分布到不同 broker 上)
12.1.3.2. 批量发送
12.1.3.3. 压缩(GZIP 或 Snappy)
12.1.1. 消费者设计
12.1.1.1. Consumer Group
13. RabbitMQ
13.1.1. 概念
13.1.2. RabbitMQ 架构
13.1.2.1. Message
13.1.2.2. Publisher
13.1.2.3. Exchange(将消息路由给队列 )
13.1.2.4. Binding(消息队列和交换器之间的关联)
13.1.2.5. Queue
13.1.2.6. Connection
13.1.2.7. Channel
13.1.2.8. Consumer
13.1.2.9. Virtual Host
13.1.2.10.Broker
13.1.3. Exchange 类型
13.1.3.1. Direct 键(routing key)分布:
13.1.3.2. Fanout(广播分发)
13.1.3.3. topic 交换器(模式匹配)
14. Hbase
14.1.1. 概念
14.1.2. 列式存储
14.1.3. Hbase 核心概念
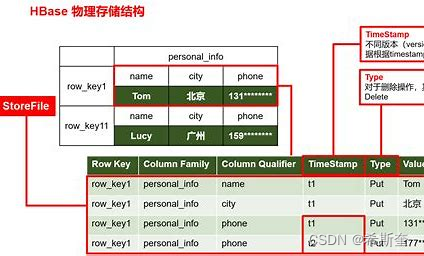
14.1.3.1. Column Family 列族
14.1.3.2. Rowkey(Rowkey 查询,Rowkey 范围扫描,全表扫描)
14.1.3.3. Region 分区
14.1.3.4. TimeStamp 多版本
14.1.4. Hbase 核心架构
14.1.4.1. Client:
14.1.4.2. Zookeeper:
14.1.4.3. Hmaster
14.1.4.4. HregionServer
14.1.4.5. Region 寻址方式(通过 zookeeper .META)
14.1.4.6. HDFS
14.1.5. Hbase 的写逻辑

12. Kafka
12.1.1. Kafka 概念
Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用 Scala 语言编写,目前是 Apache 的开源项目。
1. broker:Kafka 服务器,负责消息存储和转发
2. topic:消息类别,Kafka 按照 topic 来分类消息
3. partition:topic 的分区,一个 topic 可以包含多个 partition,topic 消息保存在各个 partition 上
4. offset:消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表该消息的 唯一序号
5. Producer:消息生产者
6. Consumer:消息消费者
7. Consumer Group:消费者分组,每个 Consumer 必须属于一个 group
8. Zookeeper:保存着集群 broker、topic、partition 等 meta 数据;另外,还负责 broker 故 障发现,partition leader 选举,负载均衡等功能

12.1.2. Kafka 数据存储设计
12.1.2.1. partition 的数据文件(offset,MessageSize,data)
partition 中的每条 Message 包含了以下三个属性:offset,MessageSize,data,其中 offset 表 示 Message 在这个 partition 中的偏移量,offset 不是该 Message 在 partition 数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了 partition 中的一条 Message,可以认为 offset 是 partition 中 Message 的 id;MessageSize 表示消息内容 data 的大小;data 为 Message 的具 体内容。
12.1.2.2. 数据文件分段 segment(顺序读写、分段命令、二分查找)
partition 物理上由多个 segment 文件组成,每个 segment 大小相等,顺序读写。每个 segment 数据文件以该段中最小的 offset 命名,文件扩展名为.log。这样在查找指定 offset 的 Message 的 时候,用二分查找就可以定位到该 Message 在哪个 segment 数据文件中。
12.1.2.3. 数据文件索引(分段索引、稀疏存储)
Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩 展名为.index。index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存 储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以 将索引文件保留在内存中。

12.1.3. 生产者设计
12.1.3.1. 负载均衡(partition 会均衡分布到不同 broker 上)
由于消息 topic 由多个 partition 组成,且 partition 会均衡分布到不同 broker 上,因此,为了有 效利用 broker 集群的性能,提高消息的吞吐量,producer 可以通过随机或者 hash 等方式,将消息平均发送到多个 partition 上,以实现负载均衡。
12.1.3.2. 批量发送
是提高消息吞吐量重要的方式,Producer 端可以在内存中合并多条消息后,以一次请求的方式发 送了批量的消息给 broker,从而大大减少 broker 存储消息的 IO 操作次数。但也一定程度上影响 了消息的实时性,相当于以时延代价,换取更好的吞吐量。
12.1.3.3. 压缩(GZIP 或 Snappy)
Producer 端可以通过 GZIP 或 Snappy 格式对消息集合进行压缩。Producer 端进行压缩之后,在 Consumer 端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力,在对大 数据处理上,瓶颈往往体现在网络上而不是 CPU(压缩和解压会耗掉部分 CPU 资源)。
12.1.1. 消费者设计

12.1.1.1. Consumer Group
同一 Consumer Group 中的多个 Consumer 实例,不同时消费同一个 partition,等效于队列模 式。partition 内消息是有序的,Consumer 通过 pull 方式消费消息。Kafka 不删除已消费的消息 对于 partition,顺序读写磁盘数据,以时间复杂度 O(1)方式提供消息持久化能力。
13. RabbitMQ
13.1.1. 概念
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为 面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言 等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可 用性等方面表现不俗。具体特点包括:
1. 可靠性(Reliability):RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布 确认。
2. 灵活的路由(Flexible Routing):在消息进入队列之前,通过 Exchange 来路由消息的。对 于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路 由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。
3. 消息集群(Clustering):多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。
4. 高可用(Highly Available Queues):队列可以在集群中的机器上进行镜像,使得在部分节 点出问题的情况下队列仍然可用。
5. 多种协议(Multi-protocol):RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。
6. 多语言客户端(Many Clients):RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、 Ruby 等等。
7. 管理界面(Management UI):RabbitMQ 提供了一个易用的用户界面,使得用户可以监控 和管理消息 Broker 的许多方面。
8. 跟踪机制(Tracing):如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生 了什么。
9. 插件机制(Plugin System):RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编 写自己的插件
13.1.2. RabbitMQ 架构
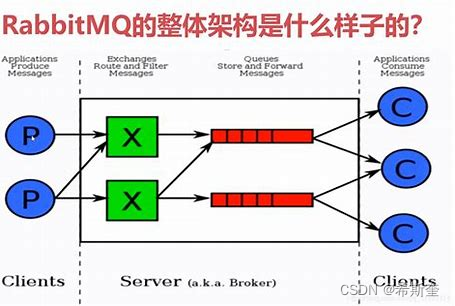
13.1.2.1. Message
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系 列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优 先权)、delivery-mode(指出该消息可能需要持久性存储)等。
13.1.2.2. Publisher
1. 消息的生产者,也是一个向交换器发布消息的客户端应用程序。
13.1.2.3. Exchange(将消息路由给队列 )
2. 交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
13.1.2.4. Binding(消息队列和交换器之间的关联)
3. 绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连 接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
13.1.2.5. Queue
4. 消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息 可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
13.1.2.6. Connection
5. 网络连接,比如一个 TCP 连接。
13.1.2.7. Channel
6. 信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的 TCP 连接内地虚 拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这 些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所 以引入了信道的概念,以复用一条 TCP 连接。
13.1.2.8. Consumer
7. 消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
13.1.2.9. Virtual Host
8. 虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密 环境的独立服务器域。
13.1.2.10.Broker
9. 表示消息队列服务器实体。
13.1.3. Exchange 类型
Exchange 分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、 topic、headers 。headers 匹配 AMQP 消息的 header 而不是路由键,此外 headers 交换器和 direct 交换器完全一致,但性能差很多,目前几乎用不到了,所以直接看另外三种类型:
13.1.3.1. Direct 键(routing key)分布:
1. Direct:消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。它是完全匹配、单播的模式.
13.1.3.2. Fanout(广播分发)
2. Fanout:每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。很像子 网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快 的。

13.1.3.3. topic 交换器(模式匹配)
3. topic 交换器:topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模 式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成 单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号 “”。#匹配 0 个或多个单词,匹配不多不少一个单词。

14. Hbase
14.1.1. 概念
base 是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS 为 Hbase 提供可靠的 底层数据存储服务,MapReduce 为 Hbase 提供高性能的计算能力,Zookeeper 为 Hbase 提供 稳定服务和 Failover 机制,因此我们说 Hbase 是一个通过大量廉价的机器解决海量数据的高速存 储和读取的分布式数据库解决方案。
14.1.2. 列式存储
列方式所带来的重要好处之一就是,由于查询中的选择规则是通过列来定义的,因此整个数据库 是自动索引化的。

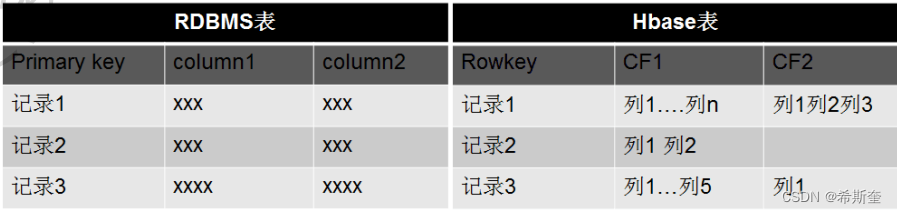
这里的列式存储其实说的是列族存储,Hbase 是根据列族来存储数据的。列族下面可以有非常多 的列,列族在创建表的时候就必须指定。为了加深对 Hbase 列族的理解,下面是一个简单的关系 型数据库的表和 Hbase 数据库的表:
14.1.3. Hbase 核心概念
14.1.3.1. Column Family 列族
Column Family 又叫列族,Hbase 通过列族划分数据的存储,列族下面可以包含任意多的列,实 现灵活的数据存取。Hbase 表的创建的时候就必须指定列族。就像关系型数据库创建的时候必须 指定具体的列是一样的。Hbase 的列族不是越多越好,官方推荐的是列族最好小于或者等于 3。我 们使用的场景一般是 1 个列族。
14.1.3.2. Rowkey(Rowkey 查询,Rowkey 范围扫描,全表扫描)
Rowkey 的概念和 mysql 中的主键是完全一样的,Hbase 使用 Rowkey 来唯一的区分某一行的数 据。Hbase 只支持 3 中查询方式:基于 Rowkey 的单行查询,基于 Rowkey 的范围扫描,全表扫 描。
14.1.3.3. Region 分区
Region:Region 的概念和关系型数据库的分区或者分片差不多。Hbase 会将一个大表的数 据基于 Rowkey 的不同范围分配到不通的 Region 中,每个 Region 负责一定范围的数据访问 和存储。这样即使是一张巨大的表,由于被切割到不通的 region,访问起来的时延也很低。
14.1.3.4. TimeStamp 多版本
TimeStamp 是实现 Hbase 多版本的关键。在 Hbase 中使用不同的 timestame 来标识相同 rowkey 行对应的不通版本的数据。在写入数据的时候,如果用户没有指定对应的 timestamp,Hbase 会自动添加一个 timestamp,timestamp 和服务器时间保持一致。在 Hbase 中,相同 rowkey 的数据按照 timestamp 倒序排列。默认查询的是最新的版本,用户 可同指定 timestamp 的值来读取旧版本的数据。
14.1.4. Hbase 核心架构
Hbase 是由 Client、Zookeeper、Master、HRegionServer、HDFS 等几个组建组成。

14.1.4.1. Client:
Client 包含了访问 Hbase 的接口,另外 Client 还维护了对应的 cache 来加速 Hbase 的 访问,比如 cache 的.META.元数据的信息。
14.1.4.2. Zookeeper:
Hbase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口 以及集群配置的维护等工作。具体工作如下:
1. 通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异 常,会通过竞争机制产生新的 master 提供服务
2. 通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的 时候,通过回调的形式通知 Master RegionServer 上下限的信息
3. 通过 Zoopkeeper 存储元数据的统一入口地址。
14.1.4.3. Hmaster
master 节点的主要职责如下:
1. 为 RegionServer 分配 Region
2. 维护整个集群的负载均衡
3. 维护集群的元数据信息发现失效的 Region,并将失效的 Region 分配到正常 RegionServer 上当 RegionSever 失效的时候,协调对应 Hlog 的拆分
14.1.4.4. HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如 下:
1. 管理 master 为其分配的 Region
2. 处理来自客户端的读写请求
3. 负责和底层 HDFS 的交互,存储数据到 HDFS
4. 负责 Region 变大以后的拆分
5. 负责 Storefile 的合并工作
14.1.4.5. Region 寻址方式(通过 zookeeper .META)
第 1 步:Client 请求 ZK 获取.META.所在的 RegionServer 的地址。
第 2 步:Client 请求.META.所在的 RegionServer 获取访问数据所在的 RegionServer 地 址,client 会将.META.的相关信息 cache 下来,以便下一次快速访问。
第 3 步:Client 请求数据所在的 RegionServer,获取所需要的数据。
14.1.4.6. HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 Hbase 提供高可用(Hlog 存储在 HDFS)的支持
14.1.5. Hbase 的写逻辑
获取 RegionServer
第 1 步:Client 获取数据写入的 Region 所在的 RegionServer
请求写 Hlog
第 2 步:请求写 Hlog, Hlog 存储在 HDFS,当 RegionServer 出现异常,需要使用 Hlog 来 恢复数据。
请求写 MemStore
第 3 步:请求写 MemStore,只有当写 Hlog 和写 MemStore 都成功了才算请求写入完成。 MemStore 后续会逐渐刷到 HDFS 中。
相关文章:
Java核心知识点整理大全18-笔记
Java核心知识点整理大全-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全2-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全3-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全4-笔记-CSDN博客 Java核心知识点整理大全5-笔记-CSDN博客 Java核心知识点整理大全6…...

vue 富文本编辑器多图上传
首先我使用的富文本编辑器是vue-quill-editor 使用npm进行下载 npm install vue-quill-editor --save当然也可以按照官方的方法下载,到官方 因为我是在原有老项目上开发的使用的组件库是ant-design-vue 1x版,当然使用其他组件库也可以 然后还有重要的一…...
)
简易地铁自动机售票系统实现(C++)
该程序具有以下功能 (1) 一个地铁路线类 Router,包含路线编号,途中的各个站点。可以新增、删除、查询路线,可以根据线路名称,显示线路图片。 (2) 一个地图类 Map,可以显示所有可以乘坐的地铁站名,以及线路…...
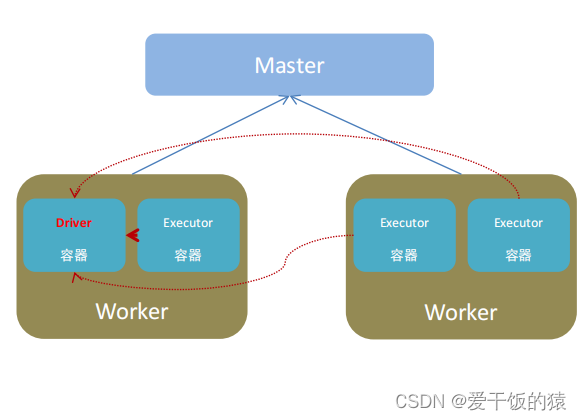
【Spark入门】基础入门
【大家好,我是爱干饭的猿,本文重点介绍Spark的定义、发展、扩展阅读:Spark VS Hadoop、四大特点、框架模块、运行模式、架构角色。 后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍ÿ…...

【自制开源】实时调参,手写字生成神器!大学生福音,告别繁琐的手写报告。
HandwritingGenerator HandwritingGenerator 是一个使用 PyQt6 制作的手写文本图片生成器。 该工具允许用户自定义多种效果,通过在左边配置效果参数,右边实时预览,并在调整好后输出图片。 效果预览 软件界面预览:一封情书&#x…...

Python 进阶(十一):高精度计算(decimal 模块)
《Python入门核心技术》专栏总目录・点这里 文章目录 1. 导入decimal模块2. 设置精度3. 创建Decimal对象4. 基本运算5. 比较运算6. 其他常用函数7. 注意事项8. 总结 大家好,我是水滴~~ 在进行数值计算时,浮点数的精度问题可能会导致结果的不准确性。为了…...

MCU常用文件格式
1. asm文件 asm是汇编语言源程序的扩展名,.asm文件是以asm作为扩展名的文件,是汇编语言的源程序文件。汇编语言(Assembly Language)是面向机器的程序设计语言,是利用计算机所有硬件特性并能直接控制硬件的语言。在汇编语言中,用助…...
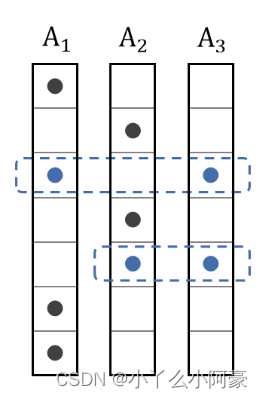
【机器学习】On the Identifiability of Nonlinear ICA: Sparsity and Beyond
前言 本文是对On the Identifiability of Nonlinear ICA: Sparsity and Beyond (NIPS 2022)中两个结构稀疏假设的总结。原文链接在Reference中。 什么是ICA(Independent component analysis)? 独立成分分析简单来说,就是给定很多的样本X,通…...
)
RBAC(Role-Based Access Control,基于角色的访问控制)
1. RBAC核心概念 RBAC(Role-Based Access Control,基于角色的访问控制)是一种广泛应用于软件和系统中的权限管理模型。它通过将用户与角色关联,再将角色与访问权限关联,来管理用户对系统资源的访问。RBAC模型的主要特…...

C++const指针的两种用法
const int *p &a; 指向const变量的指针 指向const变量的指针const修饰的变量,只能由指向const变量的指针去指向 p &a1;const的位置,必须在*的左边指向const变量的指针,可以被改变,可以指向别的变量可以指向普通变量&am…...

【Proteus仿真】【51单片机】智能垃圾桶设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用报警模块、LCD1602液晶模块、按键模块、人体红外传感器、HCSR04超声波、有害气体传感器、SG90舵机等。 主要功能: 系统运行后…...

【Windows】执行tasklist/taskkill提示“错误:找不到”或者“ERROR: not found”的解决方案
原因 由于WinMgmt异常导致起不来,而WinMgmt是SVCHOST进程中的WMI服务,解决这个问题需要停止之后再重新启动。 WinMgmt是Windows 2000客户端管理的核心组件,当客户端应用程序连接或当管理程序需要它本身的服务时,这个进程就会初始…...

MS2630——Sub-1 GHz、低噪声放大器芯片
产品简述 MS2630 是一款 Sub-1 GHz 低功耗、低噪声放大器 (LNA) 芯 片。芯片采用先进制造工艺,采用 SOT23-6 的封装形式。 主要特点 ◼ 典型噪声系数: 1.57dB ◼ 典型功率增益: 16.3dB ◼ 典型输出 P1dB : -9.2dBm…...

车载以太网-数据链路层-MAC
文章目录 车载以太网MAC(Media Access Control)车载以太网MAC帧格式以太网MAC帧报文示例车载以太网MAC层测试内容车载以太网MAC(Media Access Control) 车载以太网MAC(Media Access Control)是一种用于车载通信系统的以太网硬件地址,用于在物理层上识别和管理数据包的传…...

Tomcat源码分析
Tomcat源码分析与实例 Tomcat是一个开源的Java Web服务器,它提供了一种简单的方式来部署和运行Java Web应用程序。本文将详细介绍Tomcat的源码分析和实例。 1. Tomcat源码分析 1.1 目录结构 Tomcat的源码目录结构如下: tomcat-x.y.z/ ├── bin/ ├…...
计算机视觉面试题-02
图像处理和计算机视觉基础 什么是图像滤波?有哪些常见的图像滤波器? 图像滤波是一种通过在图像上应用滤波器(卷积核)来改变图像外观或提取图像特征的图像处理技术。滤波器通常是一个小的矩阵,通过在图像上进行卷积…...
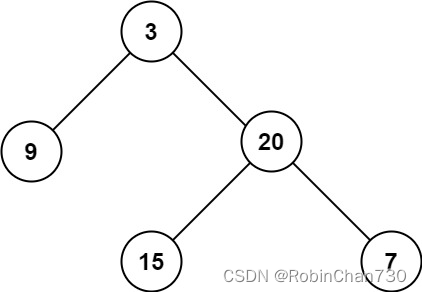
力扣日记11.27-【二叉树篇】二叉树的最大深度
力扣日记:【二叉树篇】二叉树的最大深度 日期:2023.11.27 参考:代码随想录、力扣 104. 二叉树的最大深度 题目描述 难度: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最…...
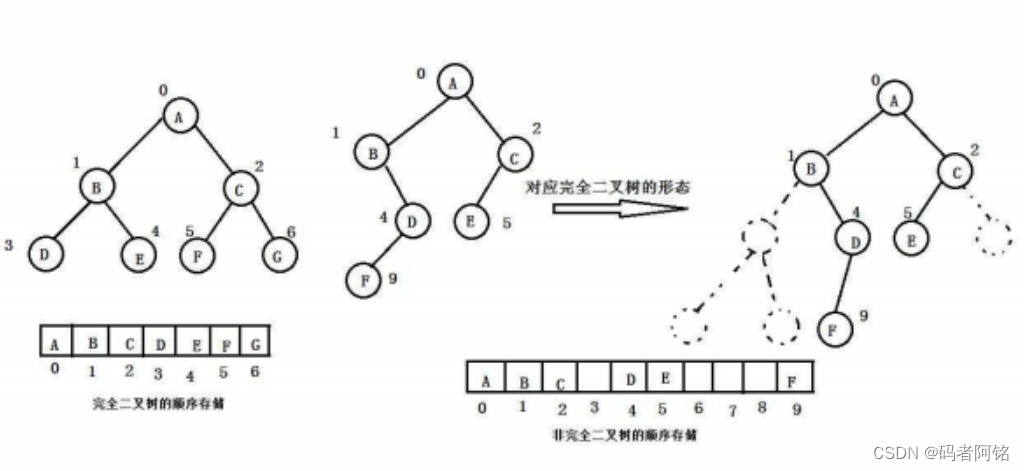
【数据结构】树的概念以及二叉树
目录 1 树概念及结构 1.1 树的概念 1.3 树的存储 2 二叉树的概念及结构 2.1 概念 2.2 特殊的二叉树 2.3 二叉树的性质 2.4 二叉树的存储结构 1 树概念及结构 1.1 树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组…...
软件测试职业规划导图
公司开发的产品专业性较强,软件测试人员需要有很强的专业知识,现在软件测试人员发展出现了一种测试管理者不愿意看到的景象: 1、开发技术较强的软件测试人员转向了软件开发(非测试工具开发); 2、业务能力较强的测试人员转向了软件…...
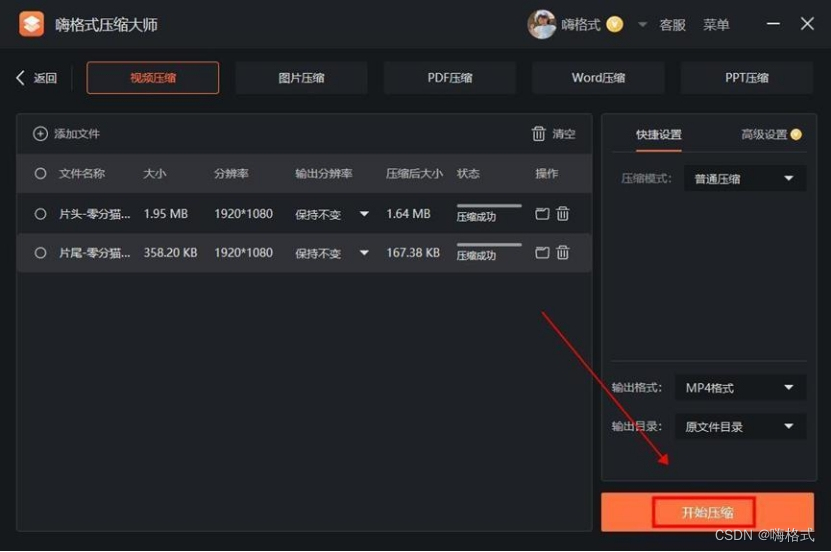
360压缩安装一半不动了?一分钟解决!
360压缩软件是我们常用的压缩软件,但是常常会遇到压缩安装到一半停止的情况,下面提供了一些可能的原因和解决办法,大家可以进行尝试~ 方法一:关闭防火墙和杀毒软件 有时候,防火墙和杀毒软件可能会阻止360压缩的安装过…...
:微动信号模型的构建与验证)
信号建模-从雷达回波到生命体征分离(三):微动信号模型的构建与验证
1. 雷达回波中的生命体征信号解码 第一次接触生物雷达信号时,我和大多数工程师一样被复杂的数学公式劝退。直到在智慧医疗项目中亲手调试设备才发现,那些看似深奥的相位变化曲线,其实就像医生听诊器里的呼吸节奏——只要找对方法,…...

open-vm-tools 与 VMware Tools 对比分析:开源与商业版的5大差异
open-vm-tools 与 VMware Tools 对比分析:开源与商业版的5大差异 【免费下载链接】open-vm-tools Official repository of VMware open-vm-tools project 项目地址: https://gitcode.com/gh_mirrors/op/open-vm-tools open-vm-tools 是一套服务和模块&#x…...

Ai2Psd:告别矢量丢失!Illustrator到PSD无损转换的终极解决方案
Ai2Psd:告别矢量丢失!Illustrator到PSD无损转换的终极解决方案 【免费下载链接】ai-to-psd A script for prepare export of vector objects from Adobe Illustrator to Photoshop 项目地址: https://gitcode.com/gh_mirrors/ai/ai-to-psd 还在为…...

加了领导微信,发现他从不发朋友圈。同事说:他把你屏蔽了。后来才知道,他没屏蔽任何人,只是不发!问他为什么,他说:发什么都不对!
加了领导微信,点开他的朋友圈,映入眼帘的是一条冷酷的横线。此时,旁边的同事幽幽地补了一刀:“不用看了,他肯定把你屏蔽了。”你心里“咯噔”一下,瞬间脑补了一出80集职场宫斗剧:我是不是哪里得…...

ADS DC仿真实战:从零构建电源完整性分析
1. 电源完整性分析为何如此重要? 最近在做一个FPGA板卡项目时,我遇到了一个棘手的问题:板卡在低温环境下频繁出现异常重启。经过排查发现,问题出在核心电源轨的压降上。当环境温度降低时,电源网络的阻抗变化导致供电电…...

Claude道歉!爆火研究漏引华人团队成果
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

安全与对齐:上下文工程在可信AI系统中的关键作用
安全与对齐:上下文工程在可信AI系统中的关键作用 【免费下载链接】Awesome-Context-Engineering 🔥 Comprehensive survey on Context Engineering: from prompt engineering to production-grade AI systems. hundreds of papers, frameworks, and imp…...

ping命令原理及用法
理解 ping 的原理和使用方法,是排查网络故障的基础。下面从原理、命令用法、各种场景下的操作,以及为什么需要 ping 这几个方面来详细解释。一、 ping 的核心原理:借“回声”探测路径ping 命令利用的是一种叫做 ICMP (Internet Control Messa…...
)
告别ST-Link!用CH347+OpenOCD给STM32烧录程序,保姆级配置教程(含常见报错解决)
低成本玩转STM32:用CH347OpenOCD实现高效烧录的完整指南 在嵌入式开发领域,ST-Link调试器一直是STM32系列芯片的标准搭档,但其价格往往让个人开发者、学生群体望而却步。有没有一种既经济实惠又功能完备的替代方案?CH347这款多功…...
——基于阿里云的远程监控与交互控制)
【STM32实战】机械臂快递分拣系统(三)——基于阿里云的远程监控与交互控制
1. 阿里云物联网平台接入实战 第一次接触阿里云物联网平台时,我被它强大的设备管理能力震撼到了。这个平台就像个智能管家,不仅能实时监控设备状态,还能远程下发控制指令。对于我们的机械臂快递分拣系统来说,简直是量身定做的解决…...