SpectralGPT: Spectral Foundation Model 论文翻译2
遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
实验
在本节中,我们将严格评估我们的SpectralGPT模型的性能,并对其进行基准测试SOTA基础模型:ResNet50 [36]、SeCo [37]、ViT[22]和SatMAE[30]。此外,我们评估了其在四个下游EO任务中的能力,包括单标签场景分类、多标签场景分类、语义分割和变化检测,以及广泛的消融研究。
我们定量评估了预训练基础模型在4个下游任务中的性能,包括单标签RS场景分类任务的识别精度、多标签RS场景分类任务的宏观和微观平均精度(mAP),即宏观mAP (micro-mAP)、语义分割任务的总体精度(OA)和平均交联(mIoU),以及变化检测的精度、召回率和F1分数。此外,我们还进行了有见地的消融研究,探索了掩蔽比、解码器深度、模型大小、补丁大小和训练时代等关键因素。利用4个NVIDIA GeForce RTX 4090 gpu的计算能力,我们精心微调下游任务和消融研究的预训练基础模型,从而提供对SpectralGPT在RS域中的能力和适应性的全面见解。
A. EuroSAT上的单标签RS场景分类
对于下游单标签RS场景分类任务,我们使用EuroSAT数据集[38]。这个数据集包括从34个欧洲国家收集的27000张哨兵2号卫星图像。这些图像被分为10个土地使用类别,每个类别包含2000到3000个标记图像。该数据集中的每张图像分辨率为64 × 64像素,包含13个光谱带。值得注意的是,为了与之前的数据处理保持一致,所有图像都排除了B10波段。此外,我们遵循[39]中建议的训练/验证分割。在EuroSAT数据集上,这些预训练的模型经过微调,跨越150个epoch,批量大小为512。这一微调过程采用了基本学习率为2 × 1 0 − 4 10^{-4} 10−4的AdamW优化器,并结合了与先前工作[24]一致的数据增强,包括权重衰减(0.05)、drop path(0.1)、repb(0.25)、mixup(0.8)和cutmix(1.0)。利用预训练模型的基础编码器,将其输出通过平均池化层进行预测。训练目标是最小化交叉熵损失。图4给出了下游单标签场景分类任务的网络架构。
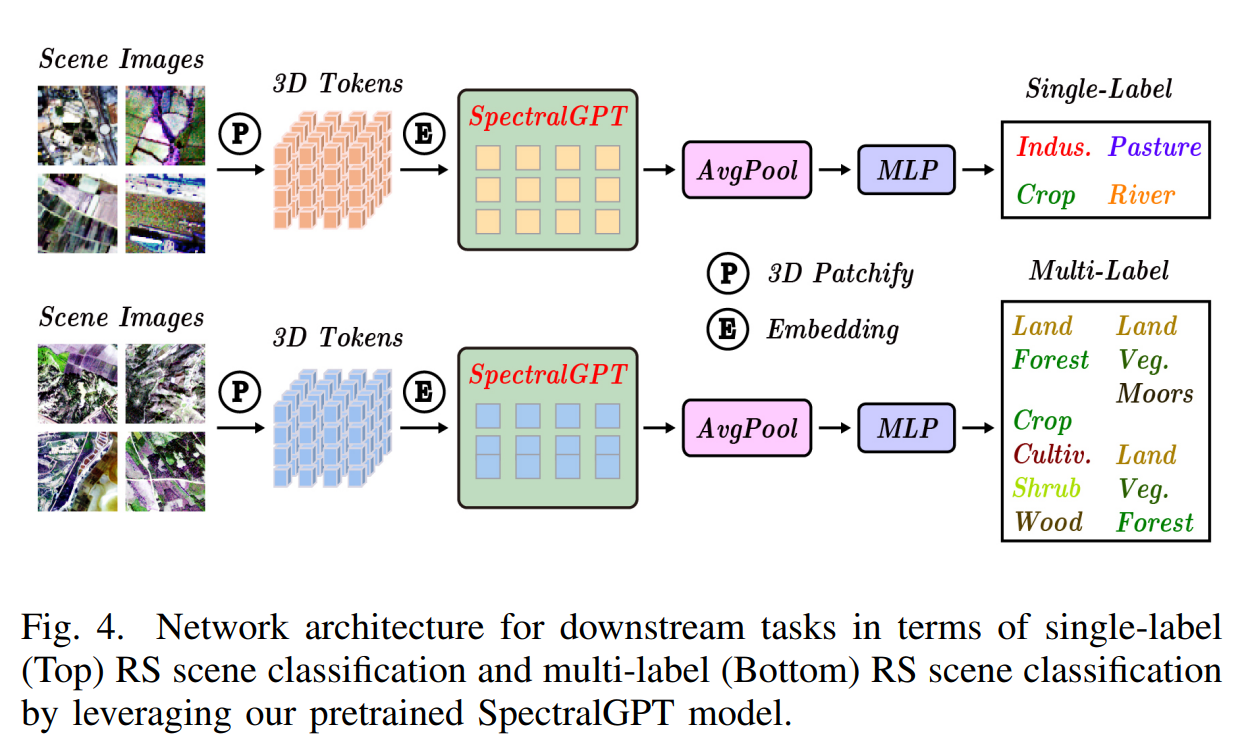
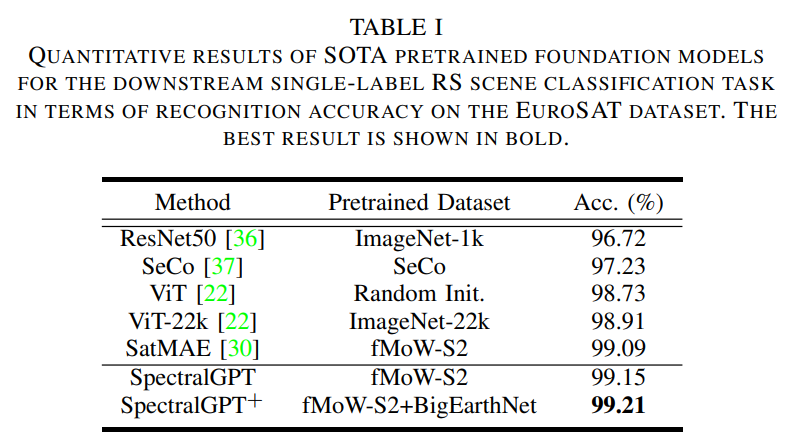
预训练模型的编码器作为基础骨干,其输出服从于平均池化层以生成预测。训练目标包括最小化交叉熵损失。在表1中,我们对我们提出的方法与其他预训练模型进行了比较分析,报告了验证集上最高的Top 1 精度。获得的结果突出了所提出方法的有效性,实现了令人印象深刻的精度99.15%。此外,当模型在fMoW-S2和BigEarthNet数据集上进行预训练时,可以观察到显著的性能提升,最终达到99.21%的显着准确率。这强调了利用不同数据源来改进模型性能的优势。
B. BigEarthNet上的多标签遥感场景分类
对于多标签RS场景分类任务,我们使用bigearth - s2数据集[34]。这个广泛的数据集由125个Sentinel-2 tiles组成,包括590,326张12波段图像,跨越19个类别,用于多标签分类。这些图像的分辨率从10米到60米不等,12%的低质量图像被排除在外。训练和验证集与先前的研究[39]一致,有354,196个训练样本和118,065个验证样本。为了准备模型训练,使用双线性插值将不同分辨率的图像标准化为128 × 128像素的统一尺寸。
在bigearth - s2数据集上,这些基础模型使用10%的训练数据子集进行微调,遵循与EuroSAT微调实验中应用的设置相似的设置,除了学习率提高了2× 1 0 − 4 10^{-4} 10−4,这与先前的研究结果一致[30],[37]。大多数现有方法,包括那些使用预训练基础模型的方法,通常使用bigearth - s2数据集中的所有可用图像进行训练。相比之下,我们提出的SpectralGPT即使只利用10%的训练样本,也能实现更高的分类性能。考虑到这个的多标签分类性质任务中,我们的训练目标涉及多标签软边际损失,性能评估基于mAP度量。值得注意的是,我们使用macro和micro mAP测量来计算mAP。这种方法特别适用于bigearth - s2数据集,它显示了类的不平衡。多标签分类框架如图4所示。
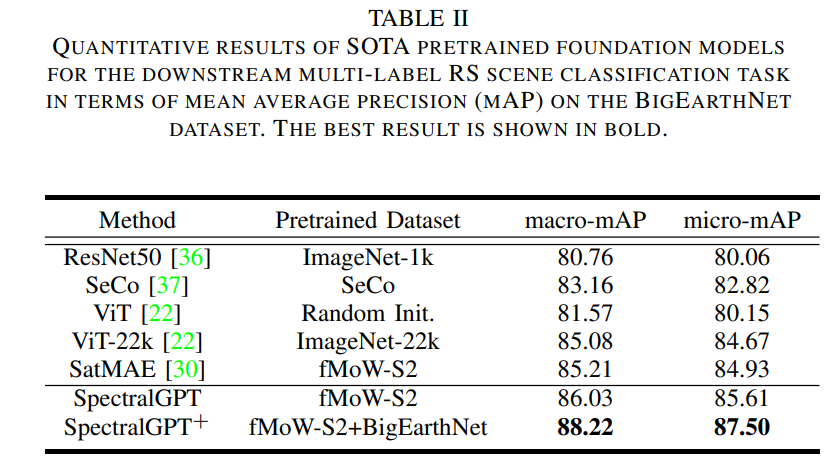
表2给出了我们的预训练模型与其他提出的预训练模型和从零开始训练的模型的比较分析,展示了提出的方法的卓越性能。特别是,与在ImageNet-22k和SatMAE相比,我们的SpectralGPT模型的性能macro-mAP(micro-mAP)比它们高出0.84% (0.82%)和0.71%(0.68%)。值得注意的是,引入了额外的预训练数据(BigEarthNet),即SpectralGPT+,导致了显著的性能提升,模型取得了令人印象深刻的成绩macro-mAP(micro-mAP) 为88.22%(87.50%) ,比仅在fMoW-S2上训练的模型高出2.19%(1.86%)。这种实质性的改善可归因于两个关键因素。首先,模型在BigEarthNet上的初始预训练(即使没有标签)使其对数据集的分布有了很强的掌握,加速了微调过程中的收敛,增强了mAP。其次,采用MIM方法作为预训练 pretext 任务,再加上庞大的数据规模,需要与训练策略保持一致,强调随机掩膜框架和90%掩膜比的重要性,以促进更鲁棒的表示学习。此外,由于我们的评估集中在一个多标签分类任务上,并且只使用了10%的训练数据,结果强调了我们提出的模型在处理具有挑战性的下游任务时的优越泛化和少量学习能力。
C.基于SegMunich的RS语义分割
对于语义分割任务,我们创建了一个新的SegMunich数据集,该数据集来自Sentinel-2光谱卫星[41]。该数据集由10波段最佳像素合成,尺寸为3,847 × 2,958像素,空间分辨率为10米。它在2020年4月之前的三年内捕捉了慕尼黑的城市景观,并包括一个分割掩模,精心描绘了13个土地利用和土地覆盖(LULC)类别。这个掩码的数据来自不同的地方,包括OpenStreetMap的街道网络数据和OSMLULC 平台数据为其余12个类别,均以相同的10米空间分辨率获得。为了创建语义分割的综合特征表示,数据集将10米光谱带(B1、B2、B3和B4)与重采样的20米光谱带(B5、B6、B7、B8A、B11、B12)结合起来,并将其上采样以匹配10米分辨率。这种谱带的融合确保了数据集为语义分割任务提供了丰富和信息丰富的数据。
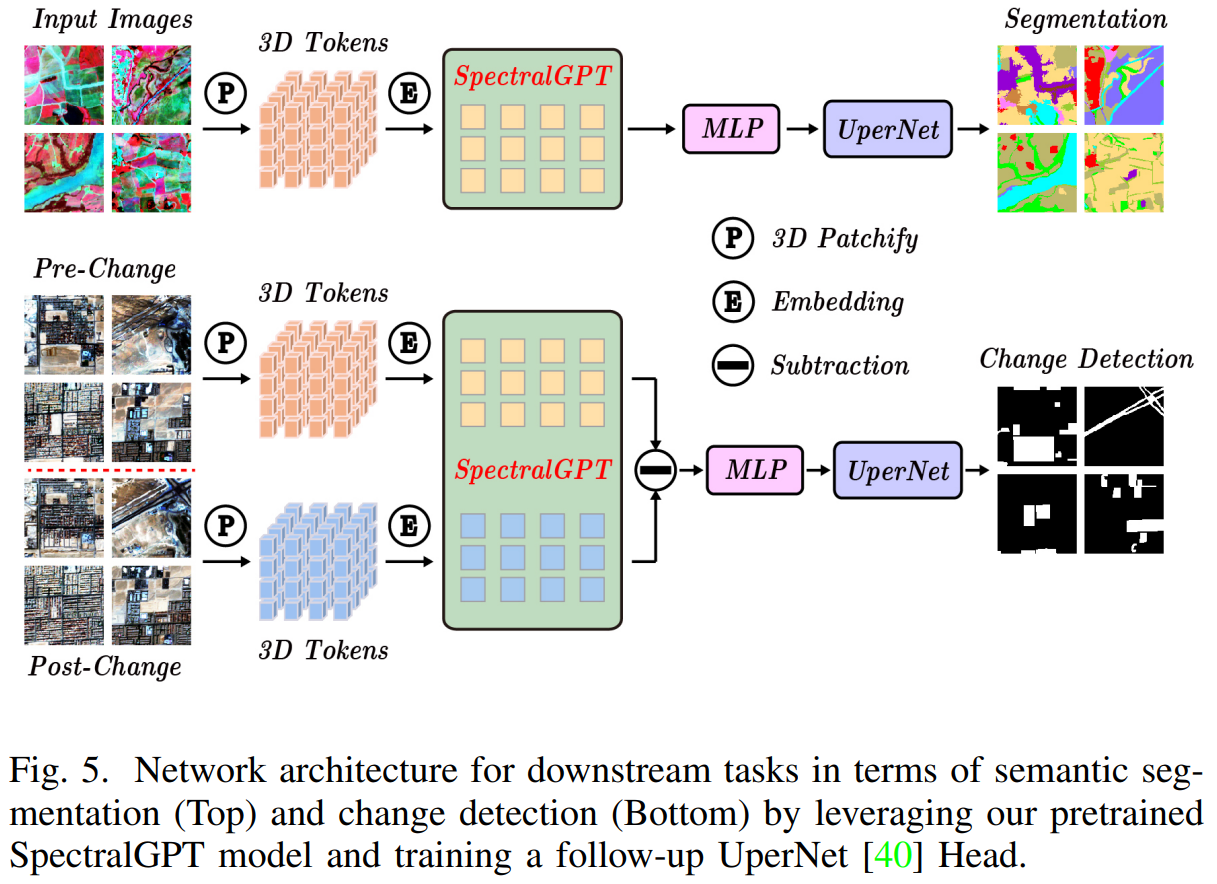
在SegMunich数据集上,我们将UperNet框架[40]与预训练的基础模型结合使用,最初将编码器最后一层的每个像素的四个token合并为一个token。图像数据被分成128 x 128像素的标记,重叠50%。然后将数据集分成8:2的训练验证比,并进行数据增强技术,包括随机翻转和旋转。在对该数据集进行微调期间,我们使用96个批处理大小,并将基本学习率设置为5 x 1 0 − 4 10^{-4} 10−4。优化函数和损失函数与EuroSAT实验中使用的函数保持一致,确保对模型训练和评价采取连贯统一的方法。分割架构如图5所示。
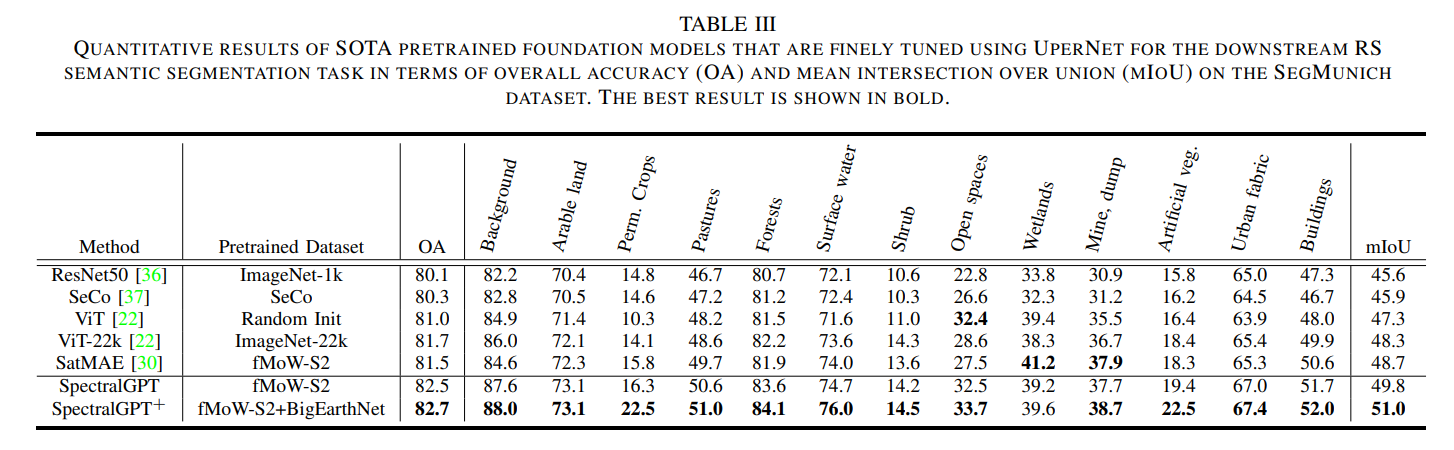
表III列出了语义分割任务的OA和mloU的定量结果。我们的SpectralGPT (SpectralGPT+)表现优于其他所有产品,mIoU比第二名(即SatMAE)高出1.1% (2.3%)。图6(a)提供了分割任务所研究的慕尼黑地区的视觉描述,以及13个类别的比例。如**图6(b)所示,几个roi的定性比较表明,在大多数情况下,与竞争模型相比,我们的模型在识别更广泛的土地利用类别方面具有优越的能力。此外,当考虑将ViT-22k 作为性能比较的基线时,我们的模型在所有分割类别中始终表现出色,如图6©**所示,特别是对于作物、牧场、开放空间、植被等类别。通过将类别统计数据与分类IoU结果相结合,我们的SpectralGPT模型在减轻类别不平衡分类带来的挑战方面表现出色。与其他基础模型相比,这将大大提高性能。

D.对OSCD的RS变化检测
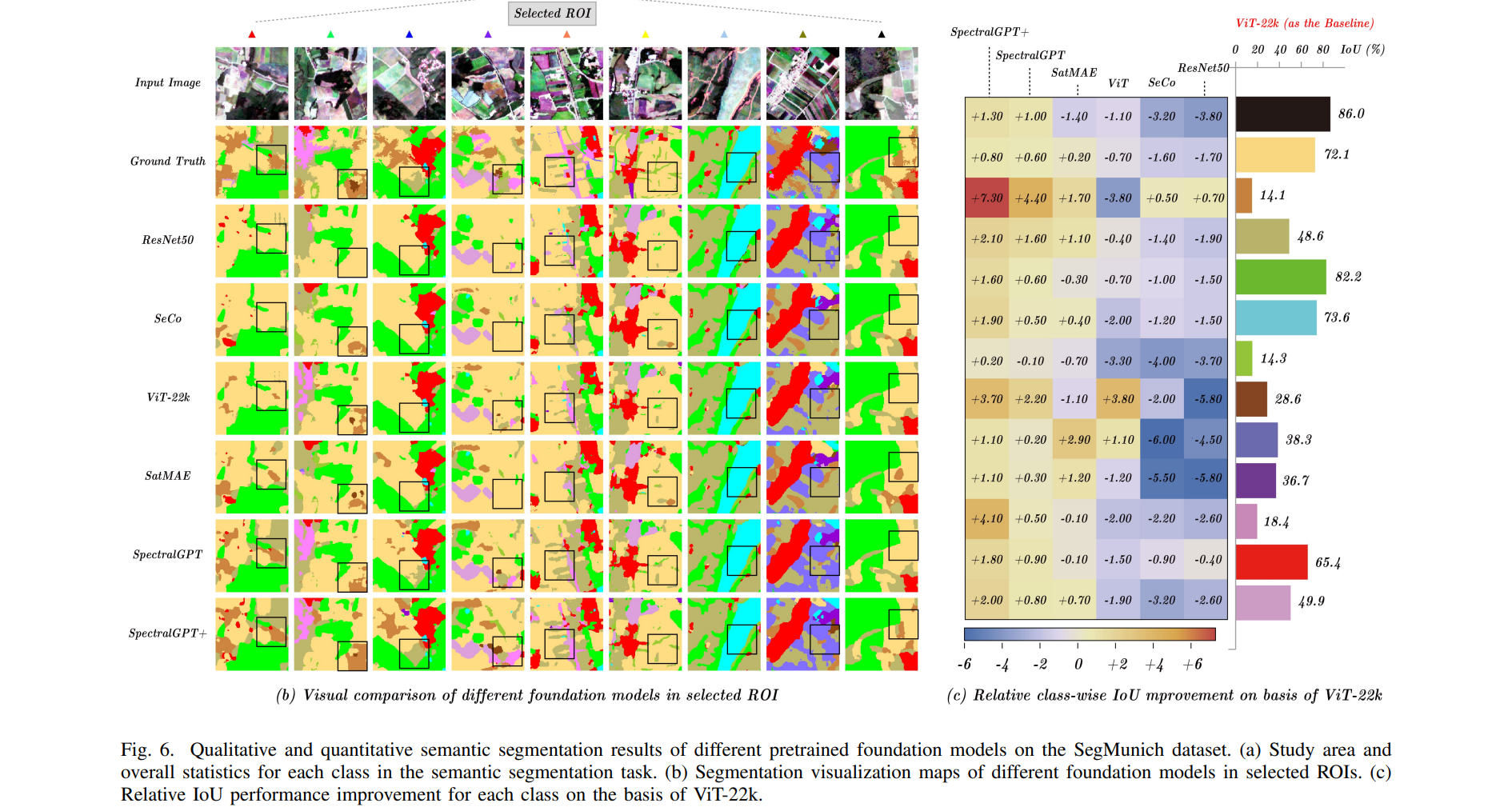
对于变化检测任务,我们使用OSCD数据集[42]。图7(a)显示了几个城市规模的例子。该数据集包括24个城市的Sentinel-2图像,其中14张用于训练,10张用于评估。这些图像拍摄于2015年至2018年之间,包含13个光谱波段,分辨率分别为10米、20米和60米。该数据集在像素级进行了注释,以表明变化,特别是关注城市发展。在OSCD数据集上,我们执行图像裁剪以创建大小为128 × 128像素的斑块,重叠率为50%,并且我们应用随机翻转和旋转作为数据增强技术。对于每一对图像,两者都通过共享编码器同时处理,并计算其特征之间的差异,然后传递给UperNet。每个特征像素由4个标记组成,类似于分割方法,我们使用线性层将这4个标记合并为1个标记。该模型以负对数似然损失为训练目标,以批大小为64个,学习率设置为1× 1 0 − 3 10^{-3} 10−3,训练60个epoch。在变更检测任务中利用预训练的SpectralGPT模型的整个框架如图5所示。
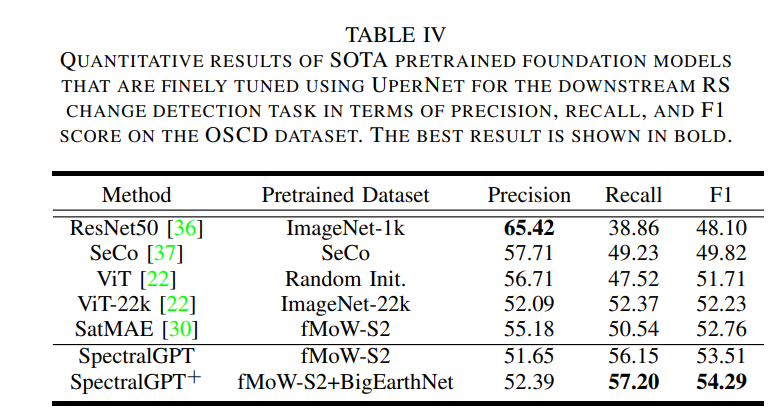
模型性能通过精度、召回率和F1分数来评估,其定量结果如表4所示,在OSCD数据集上,我们提出的模型获得了最高的F1分数,超过了第二好的模型(即SatMAE) 0.75%(1.53%)。然而,值得注意的是,我们的模型在F1得分和召回率方面表现出色,但与其他模型相比,精度相对较低。这种现象可以归因于两个主要因素。首先,变化检测任务内固有数据的极度不平衡(见图7(b)),其中阳性和阴性样本的数量差异显著,可能导致模型将阴性案例分类为阳性,以牺牲精度为代价提高召回率。其次,ViT架构的复杂性需要大量的数据来缓解过拟合。模型可能会与过拟合作斗争,并且对域外数据的适应性变差。解决这一挑战可能需要提供额外的微调数据或者降低模型的等级。在定性结果方面,我们的模型在**图7(d)**的选定roi中预测变化像素方面表现出色,假阴性较少。值得注意的是,**图7©**强调了SpectralGPT的卓越性能,其中我们的模型在一半的测试城市中取得了最好的结果。此外,被比较的模型在10个不同的的城市表现趋势一致,Lasvegas 和 Montpellier分别在F1中获得了最高和第二高的分数


相关文章:
SpectralGPT: Spectral Foundation Model 论文翻译2
遥感领域的通用大模型 2023.11.13在CVPR发表 原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org) 实验 在本节中,我们将严格评估我们的SpectralGPT模型的性能,并对其进行基准测试SOTA基础模型:ResN…...

Java编译过程中的JVM
流程 源代码编写: 首先,开发者使用Java编程语言编写源代码。这些源代码通常保存在扩展名为.java的文件中。 编译源代码: 使用Java编译器(例如javac),这些.java文件被编译成Java字节码。字节码是一种中间形…...
Python BDD 框架比较之 pytest-bdd vs behave
pytest-bdd和behave是 Python 的两个流行的 BDD 测试框架,两者都可以用来编写用户故事和可执行的测试用例, 具体选择哪一个则需要根据实际的项目状况来看。 先简单看一下两者的功能: pytest-bdd 基于pytest测试框架,可以与pytest…...
)
【面经八股】搜广推方向:常见面试题(一)
【面经&八股】搜广推方向:常见面试题(一) 文章目录 【面经&八股】搜广推方向:常见面试题(一)1. 线下效果提升、线上效果不好。2. XGBoost 和 GBDT是什么?有什么区别?3. 偏差与方差。延伸知识(集成学习的三种方式: Bagging、Boosting、Stacking)。4. 随机森林…...
斐讯K2结合Padavan实现锐捷认证破解方法
前言 众所周知,校园网在传统模式下是不能直接插路由使用的,但苦于校园网只能连接一台设备的烦恼,不得不“另辟蹊径”来寻求新的解决路径,这不,它来了,它来了,它带着希望走来了。 本文基于斐讯…...
SpringBoot : ch06 整合 web (一)
前言 SpringBoot作为一款优秀的框架,不仅提供了快速开发的能力,同时也提供了丰富的文档和示例,让开发者更加容易上手。在本博客中,我们将介绍如何使用SpringBoot来整合Web应用程序的相关技术,并通过实例代码来演示如何…...

C++:OJ练习(每日练习系列)
编程题: 题一:把字符串转换成整数 把字符串转换成整数_牛客题霸_牛客网 示例1 输入: "2147483647" 返回值: 2147483647思路一: 第一步:it从str的第一个字符开始遍历,定义一个最后输…...
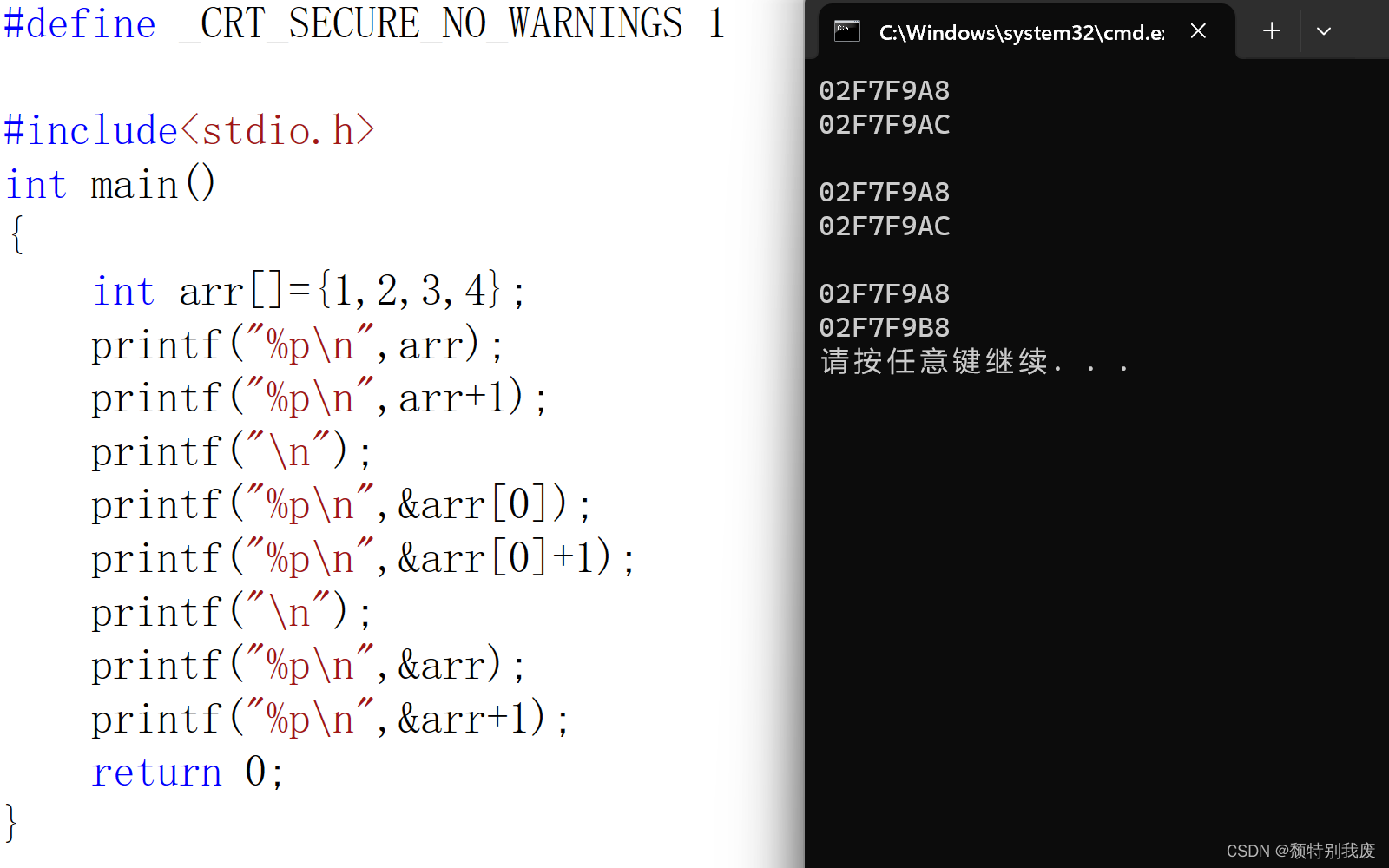
C语言—什么是数组名
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> int main() {int arr[]{1,2,3,4};printf("%p\n",arr);printf("%p\n",&arr);printf("%p\n",*arr);return 0; } 结论:数组名是数组首元素地址(下标为0的元素…...

如何与死锁斗争!!!
其他系列文章导航 Java基础合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、死锁场景现场 二、死锁是如何产生的 三、死锁排查思路 四、sql模拟死锁复现 五、死锁的解决方案 前言 为避免影响业务,应尽可能避…...
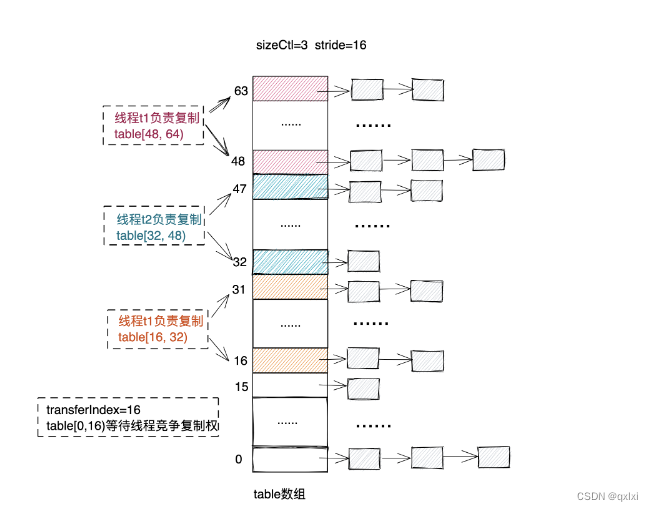
【Java并发】聊聊不安全的HashMap以及ConcurrentHashMap
在实际的开发中,hashmap是比较常用的数据结构,如果所开发的系统并发量不高,那么没有问题,但是一旦系统的并发量增加一倍,那么就可能出现不可控的系统问题,所以在平时的开发中,我们除了需要考虑正…...
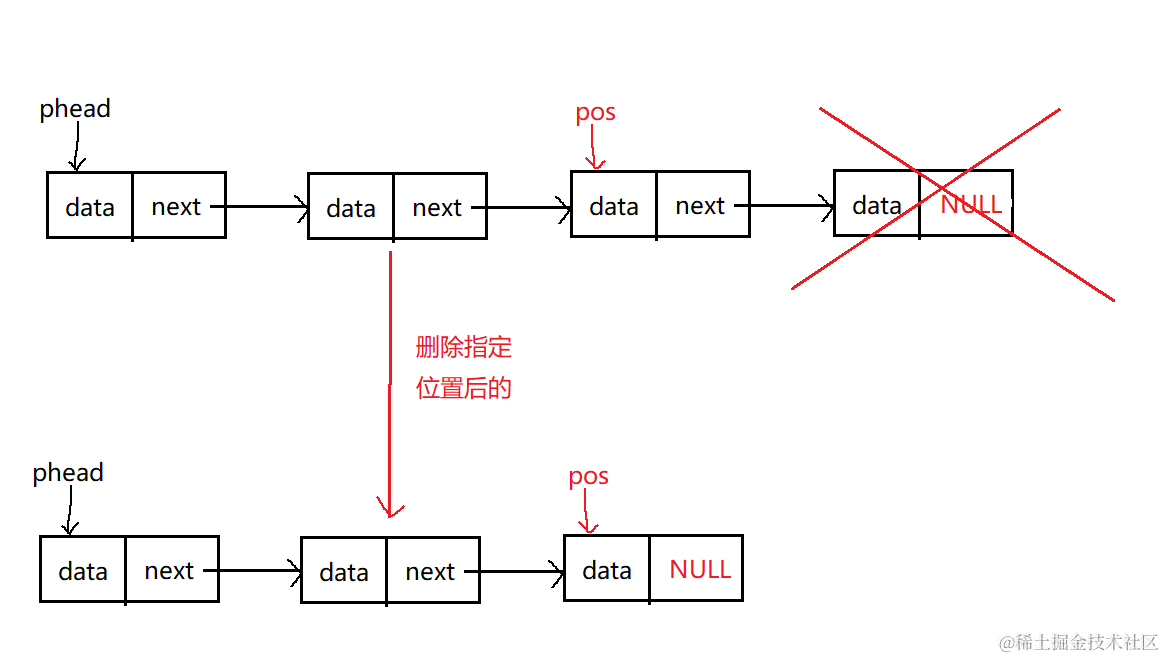
数据结构--->单链表
文章目录 链表链表的分类 单链表单链表的存储结构单链表主要实现的接口函数单链表尾插动态申请新节点单链表头插单链表的尾删单链表的头删在指定位置之前插入单链表查找插入 在指定位置之后插删除指定位置元素删除指定位置之后的元素顺序输出链表销毁单链表 顺序表和单链表的区…...

RT-Thread 线程间同步【信号量、互斥量、事件集】
线程间同步 一、信号量1. 创建信号量2. 获取信号量3. 释放信号量4. 删除信号量5. 代码示例 二、互斥量1. 创建互斥量2. 获取互斥量3. 释放互斥量4. 删除互斥量5. 代码示例 三、事件集1. 创建事件集2. 发送事件3. 接收事件4. 删除事件集5. 代码示例 简单来说,同步就是…...
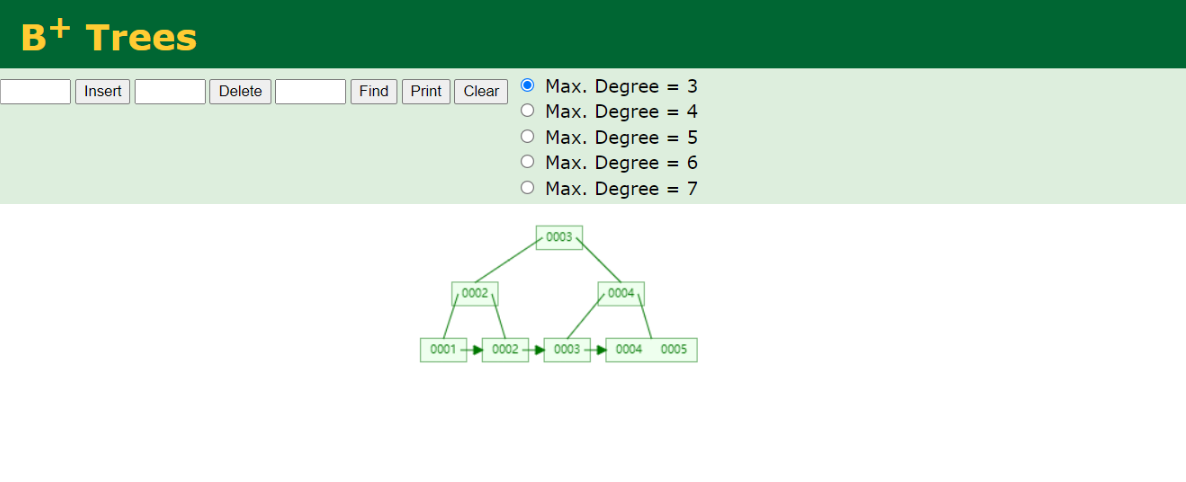
B 树和 B+树 的区别
文章目录 B 树和 B树 的区别 B 树和 B树 的区别 了解二叉树、AVL 树、B 树的概念 B 树和 B树的应用场景 B 树是一种多路平衡查找树,为了更形象的理解。 二叉树,每个节点支持两个分支的树结构,相比于单向链表,多了一个分支。 …...

Go iota简介
当声明枚举类型或定义一组相关常量时,Go语言中的iota关键字可以帮助我们简化代码并自动生成递增的值。本文档将详细介绍iota的用法和行为。 iota关键字 iota是Go语言中的一个预定义标识符,它用于创建自增的无类型整数常量。iota的行为类似于一个计数器…...
PyQt6库和工具库QTDesigner安装与配置
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计12条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话版…...

性能测试:系统架构性能优化思路
今天谈下业务系统性能问题分析诊断和性能优化方面的内容。这篇文章重点还是谈已经上线的业务系统后续出现性能问题后的问题诊断和优化重点。 系统性能问题分析流程 我们首先来分析下如果一个业务系统上线前没有性能问题,而在上线后出现了比较严重的性能问题&#x…...

python字符串格式化
字符串格式化 # 2023年11月16日 星期四 y 2023 m 11 d 16 w 四 s %d年%d月%d日 星期%s%(y,m,d,w) print(s) s {}年{}月{}日 星期{}.format(y,m,d,w) print(s) s f{y}年{m}月{d}日 星期{w} print(s)...
Linux的基本指令(二)
目录 前言 学前补充 touch指令 mkdir指令 rmdir指令 rm指令 通配符* man指令 cp指令 mv指令(重要) 补充内容: 1、如何快速在Linux中写出代码 2、如何看待如此多的Linux指令 cat指令 前言 关于Linux的基本指令我们会分三到四篇文章进行分析,…...
每日一题--寻找重复数
蝶恋花-王国维 阅尽天涯离别苦, 不道归来,零落花如许。 花底相看无一语,绿窗春与天俱莫。 待把相思灯下诉, 一缕新欢,旧恨千千缕。 最是人间留不住,朱颜辞镜花辞树。 目录 题目描述: 思路分析…...
C#,《小白学程序》第二十二课:大数的乘法(BigInteger Multiply)
1 文本格式 using System; using System.Linq; using System.Text; using System.Collections.Generic; /// <summary> /// 大数的(加减乘除)四则运算、阶乘运算 /// 乘法计算包括小学生算法、Karatsuba和Toom-Cook3算法 /// </summary> p…...

2026最权威的十大AI辅助写作助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 现今,人工智能辅助论文写作在学术研究里已渐渐变成常见的手段,当前&a…...

#星光计划4.0#鸿蒙界面设计技术解析与实战案例
鸿蒙界面设计技术解析与实战案例 随着万物互联时代的到来,鸿蒙操作系统(HarmonyOS)以“全场景智慧体验”为核心,构建了一套独特的界面设计体系。不同于传统单设备操作系统的界面逻辑,鸿蒙界面设计围绕“分布式协同、原…...

Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南
Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南 无需复杂配置,无需GPU设备,5分钟拥有自己的AI写作大师 1. 为什么选择这个镜像? 如果你正在寻找一个既强大又容易上手的AI写作助手,这个Qwen3-4B-Instruct镜像…...

性能实测:登临Goldwasser V2加速卡跑YOLOv5s,对比CPU看速度提升多少?
登临Goldwasser V2加速卡YOLOv5s实测:从环境配置到性能对比的全流程拆解 当目标检测任务遇上边缘计算场景,算力与能效的平衡往往成为工程落地的关键瓶颈。上周在部署某工业园区安防系统时,我们尝试用登临科技的Goldwasser V2加速卡运行YOLOv5…...

Windows Defender Remover:系统优化工具与安全组件管理指南
Windows Defender Remover:系统优化工具与安全组件管理指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

AI辅助开发新体验:让快马平台智能解析并生成复杂网站的claw hub爬虫策略
今天想和大家分享一个最近用AI辅助开发爬虫的实践案例。面对一个数据通过多次Ajax请求获取且带有加密参数的复杂网站,传统爬虫开发需要花费大量时间逆向分析,而通过InsCode(快马)平台的AI能力,整个过程变得高效智能多了。 需求分析与目标拆解…...

5分钟部署!《崩坏:星穹铁道》全自动助手终极指南
5分钟部署!《崩坏:星穹铁道》全自动助手终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 你是否每天花费大量时间在《崩坏:…...

甩掉作图焦虑,我把商业级出图压缩到10分钟,设计团队必备AI工具推荐
作为一个在设计行业熬了快十年的工作室主理人,我无数次在甲方的要求下气的想撞墙——不是因为脑子里没有创意,而是因为团队的视觉交付效率根本跟不上客户“朝令夕改”的节奏。你如果是设计师一定懂这种窒息感:早会刚定下的视觉方向࿰…...
—Linkage Mapper与Circuitscape环境部署详解)
生态廊道构建实战指南(1)—Linkage Mapper与Circuitscape环境部署详解
1. 生态廊道构建工具入门指南 第一次接触生态廊道分析的朋友可能会被各种专业术语吓到,其实没那么复杂。简单来说,Linkage Mapper和Circuitscape就是帮我们在数字地图上找出动物迁徙"高速公路"的神器。想象一下,你是一位城市规划师…...

别再只盯着PCA图了!用Seurat做单细胞PCA时,这3个关键结果图你分析对了吗?
单细胞PCA分析进阶指南:超越基础散点图的3个关键洞察维度 当你在Seurat中点击RunPCA()的那一刻,真正的挑战才刚刚开始。大多数单细胞分析教程止步于基础的PCA散点图可视化,却忽略了隐藏在VizDimLoadings、DimHeatmap和JackStrawPlot中的黄金信…...