Spring 多数据源搭建
目录
前言
正文
1.Druid 介绍和使用
2.其他多数据源解决方案
总结
前言
对于复杂的业务和项目,可能在一个单体项目中存在需要连接多个数据库的情况。这时,就会使用到多数据源,实际中遇到的可能性比较大。
正文
如果一个项目中需要连接 db1 ,同时一部分业务需要获取 db2 中的数据,则需要连接第二个数据源。这里一个数据源对应一个数据库,这两个数据库可能是部署在同一台服务器上,也可能不在同一台服务器上,通过配置 jdbc-url 来区别。
在配置上需要配置不同的 datasource 才能实现不同的数据源连接。
1.Druid 介绍和使用
Druid 是阿里旗下开源的数据库连接池,提供强大的监控和扩展功能,包括数据库性能健康,获取 SQL 日志的能力。除此之外,也可以和 MyBaties 配合用于多数据源搭建。
pom.xml依赖如下
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.23</version></dependency>为了测试多数据源,创建一个主库 test_spring_master,一个从库 test_spring_slave,创建 SQL 如下:
create database test_spring_master default character set utf8;
create database test_spring_slave default character set utf8;配置文件内容如下:
spring:datasource:master: #主数据元username: masterpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/test_spring_master?useTimezone=true&serverTimezone=UTCinitialSize: 5minIdle: 5maxActive: 20slave: #第二个数据源username: slavepassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/test_spring_slave?useTimezone=true&serverTimezone=UTCinitialSize: 5minIdle: 5maxActive: 20
针对两个数据源配置,需要编写两个配置类,一个是主数据源配置类,另一个是从数据源配置类,分别命名为 MasterDataSourceConfig 和 SlaveDataSourceConfig,代码如下:
package org.example.config;import com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.context.annotation.Scope;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;import javax.sql.DataSource;@Configuration
@MapperScan(basePackages = MasterDataSourceConfig.PACKAGE_NAME, sqlSessionFactoryRef = "masterSqlSessionFactory")
public class MasterDataSourceConfig {//定位到包类路径static final String PACKAGE_NAME = "org.example.mapper.master";//设置 mapper.xml位置。//不存在 *.xml 这种模糊匹配,必须准确的名称static final String MAPPER_LOCATION="classpath:org/example/mapper/master/MySinger.xml";@Value("${spring.datasource.master.jdbc-url}")private String url;@Value("${spring.datasource.master.username}")private String user;@Value("${spring.datasource.master.password}")private String password;@Value("${spring.datasource.master.driver-class-name}")private String driverClass;/*** 获得主数据源* @return*/@Bean(name = "masterDataSource")public DataSource masterDataSource(){DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName(driverClass);//设置驱动dataSource.setUrl(url);dataSource.setUsername(user);dataSource.setPassword(password);return dataSource;}/*** 将 masterDataSource 注入到 masterTransactionManger* @return 管理数据库实物*/@Bean(name = "masterTransactionManger")public DataSourceTransactionManager masterTransactionManger(){//使用了 @Bean,则可以直接依赖注入进去return new DataSourceTransactionManager(masterDataSource());}@Bean(name = "masterSqlSessionFactory")@Primary //如果有多个相同类型的Bean 优先使用本Beanpublic SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource){final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();sessionFactory.setDataSource(masterDataSource);sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResource(MasterDataSourceConfig.MAPPER_LOCATION));try {return sessionFactory.getObject();} catch (Exception e) {e.printStackTrace();}return null;}}
补充:
@MapperScan注解用于指定需要扫描的 Mapper 接口所在的包名,它通常与@Configuration注解一起使用,表示该注解所标注的类是一个配置类。basePackages属性用于指定需要扫描的包名,多个包名可以用逗号隔开。例如,@MapperScan(basePackages = "com.example.mapper")表示需要扫描com.example.mapper包以及其子包中的 Mapper 接口。- 此外,
@MapperScan注解还有一个sqlSessionFactoryRef属性,用于指定使用的 SqlSessionFactory 的名称,即在 Spring IoC 容器中定义的 SqlSessionFactory Bean 的名称。在多个数据源的情况下,可以通过该属性为不同的 Mapper 接口指定不同的 SqlSessionFactory,以使用不同的数据源。- 也就是说,
@MapperScan注解将指定包下的 MyBatis Mapper 接口与SqlSessionFactory关联起来。为了让@MapperScan注解知道要关联哪个SqlSessionFactory实例,需要通过sqlSessionFactoryRef属性指定SqlSessionFactory的 Bean 名称。
可以看到 masterSqlSessionFactory 方法上有 @Primary 注解,说明这时主库。而从数据源配置类和主数据源配置类比较类似,唯一不同就是一些参数和注解不同。
package org.example.config;import com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;import javax.sql.DataSource;@Configuration
@MapperScan(basePackages = SlaveDataSourceConfig.PACKAGE_NAME, sqlSessionFactoryRef = "slaveSqlSessionFactory")
public class SlaveDataSourceConfig {//定位到包类路径static final String PACKAGE_NAME = "org.example.mapper.slave";//设置 mapper.xml位置。static final String MAPPER_LOCATION="classpath:org/example/mapper/slave/MyStore.xml";@Value("${spring.datasource.slave.jdbc-url}")private String url;@Value("${spring.datasource.slave.username}")private String user;@Value("${spring.datasource.slave.password}")private String password;@Value("${spring.datasource.slave.driver-class-name}")private String driverClass;/*** 获得主数据源* @return*/@Bean(name = "slaveDataSource")public DataSource slaveDataSource(){DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName(driverClass);//设置驱动dataSource.setUrl(url);dataSource.setUsername(user);dataSource.setPassword(password);return dataSource;}/*** 将 masterDataSource 注入到 masterTransactionManger* @return 管理数据库实物*/@Bean(name = "slaveTransactionManager")public DataSourceTransactionManager slaveTransactionManager(){//使用了 @Bean,则可以直接依赖注入进去return new DataSourceTransactionManager(slaveDataSource());}@Bean(name = "slaveSqlSessionFactory")public SqlSessionFactory slaveSqlSessionFactory(@Qualifier("slaveDataSource") DataSource slaveDataSource) throws Exception {final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();sessionFactory.setDataSource(slaveDataSource);sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResource(SlaveDataSourceConfig.MAPPER_LOCATION));return sessionFactory.getObject();}}
为了进一步实验,需要在两个库中分别创建表,于是主库创建 m_singers 歌手表,在从数据库中创建 m_stores 商店表。
use test_spring_master;
create table `m_singers`(`id` int(11) unsigned not null auto_increment comment '歌手主键',`name` varchar(80) not null comment '歌手名',`age` int(3) default null comment '年龄',primary key (`id`)
)engine InnoDB default character set=utf8;
use test_spring_slave;
create table `m_stores`(`id` int(11) unsigned not null auto_increment comment '主键',`name` varchar(100) NOT NULL comment '店名',`space` int(6) not null comment '单位平方米',`description` varchar(300) not null comment '简介',primary key (`id`)
)engine InnoDB DEFAULT character set=utf8;创建用户并授予权限
create user 'master'@'localhost' identified by'123456';
show grants for 'master'@'localhost';
create user 'slave'@'localhost' identified by'123456';
GRANT ALL PRIVILEGES ON test_spring_slave.m_stores TO 'slave'@'localhost';
GRANT ALL PRIVILEGES ON test_spring_master.m_singers TO 'master'@'localhost';继续分别创建对应的实体类
MyStore.java
package org.example.entity;import lombok.Data;import java.io.Serializable;@Data
public class MyStore implements Serializable {// 主键private Integer id;// 名称private String name;// 地区private int space;// 描述private String description;
}
MySinger.java
package org.example.entity;import lombok.Data;import java.io.Serializable;@Data
public class MySinger implements Serializable {private Integer id;private String name;private int age;
}
对应的 Dao 文件:
MyStore。
package org.example.mapper.slave;import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.example.entity.MyStore;@Mapper
public interface MyStoreDao {int insert(MyStore record);int updateByPrimaryKey(MyStore record);MyStore findByName(@Param("name") String name);
}
MySinger。
package org.example.mapper.master;import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.example.entity.MySinger;@Mapper
public interface MySingerDao {int deleteByPrimaryKey(Integer id);int insert(MySinger record);int insertSelective(MySinger record);MySinger selectByPrimaryKey(Integer id);int updateByPrimaryKeySelective(MySinger record);int updateByPrimaryKey(MySinger record);MySinger findByName(@Param("name") String name);
}
剩下的 controller,service 部分基本就是一般流程了,就不继续向下写了。 最后自己进行测试:

完成 。
2.其他多数据源解决方案
其他解决方案也很多,如使用多个 Bean、自实现动态 DataSource 等,其中有一种方法非常简单高效 ,就是使用第三方的依赖包,动态加载不同的数据源,推荐使用 dynamic-datasource-spring-boot-starter。
dynamic-datasource-spring-boot-starter 是国内开发者维护的多数据源解决方案插件被作者称为一个基于 springboot 的快速继承多数据源的启动器。它的优点主要有支持数据源分组,适用于多种场景,纯粹多库、读写分离、一主多从混合模式。
POM.xml依赖
<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.1</version></dependency>数据源配置
spring:datasource:dynamic:primary: master #设置默认的数据源或者数据数组,默认只即为 masterstrict: false #设置严格模式,默认false不启动。启动后在未匹配到指定数据源时会抛出异常,不启动则使用默认数据源。datasource:master:url: jdbc:mysql://xx.xx.xx.xx:3306/dynamicusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driver #3.2.0开始支持 SPI 可省略此配置slave_1:url: jdbc:mysql://xx.xx.xx.xx:3307/dynamicusername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driverslave_2:url: ENC(xxxxx) #内置加密,使用详情请看文档。username: ENC(xxxxx)password: ENC(xxxxx)driver-class-name: com.mysql.cj.jdbc.Driverscherma: db/schema.sql #配置生效,自动初始化表格data: db/data.sql #配置生效,自动初始化数据continue-on-error: true #默认true ,初始化失败是否separator: "," #sql 默认分隔符#这些配置会配置一个默认库 master, 一个组 slave 下有两个子库 slave_1, slave_2配置解释:
在这段配置中:
spring.datasource.dynamic是dynamic-datasource-spring-boot-starter的配置前缀。
primary: master设置主数据源为 “master”。
strict: false为非严格模式。如果请求的数据源不存在,系统会自动回退到主数据源,而不是抛出异常。
datasource:下面列出了所有的数据源,每一个数据源都有一个名字(在这个例子中是 master, slave_1, slave_2),和对应的数据源详情(url, username, password, driver-class-name)。每个具体的数据源(比如 “master”)下:
url:数据库的 JDBC URL。
username:数据库用户名。
password:数据库密码。ENC(xxx) 是一个加密格式,能够保护你的敏感信息不被明文展示。
driver-class-name:JDBC 驱动类型。如果你依赖的版本在3.2.0以上,驱动可以被自动识别,这个配置也可以省略。
scherma: db/schema.sql和data: db/data.sql是你自定义的SQL语句文件。在 Spring Boot 中可以通过这种方式定义 SQL 文件的路径,然后在应用启动的时候自动执行这些 SQL 文件。强调一下,这只是个示例,你需要根据具体的数据库信息(如类型、地址、端口、用户名、密码等)去做相应的调整和修改。例如,替换
xx.xx.xx.xx为实际的数据库服务器地址,并且替换username和password为正确的数据库访问凭证等。
最后使用 @DS 注解,采取就近原则,方法上的注解优先于类上的注解,代码如下 :
package org.example.service;import com.baomidou.dynamic.datasource.annotation.DS;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;import java.util.List;@Service
@DS("slave")
public class UserServiceImpl implements UserService{@Autowiredprivate JdbcTemplate jdbcTemplate;public List selectAll(){return jdbcTemplate.queryForList("select * from user");}@Override@DS("slave_1")public List selectByCondition(){return jdbcTemplate.queryForList("select * from user where age > 10");}}
总结
多数据源搭建提供了灵活性、性能优化、隔离性和安全性方面的优势。它使应用程序能够更好地适应不同的需求,并在处理数据时提供更好的性能和可扩展性。
相关文章:
Spring 多数据源搭建
目录 前言 正文 1.Druid 介绍和使用 2.其他多数据源解决方案 总结 前言 对于复杂的业务和项目,可能在一个单体项目中存在需要连接多个数据库的情况。这时,就会使用到多数据源,实际中遇到的可能性比较大。 正文 如果一个项目中需要连…...

【二分查找】LeetCode1970:你能穿过矩阵的最后一天
本文涉及的基础知识点 二分查找算法合集 作者推荐 动态规划LeetCode2552:优化了6版的1324模式 题目 给你一个下标从 1 开始的二进制矩阵,其中 0 表示陆地,1 表示水域。同时给你 row 和 col 分别表示矩阵中行和列的数目。 一开始在第 0 …...
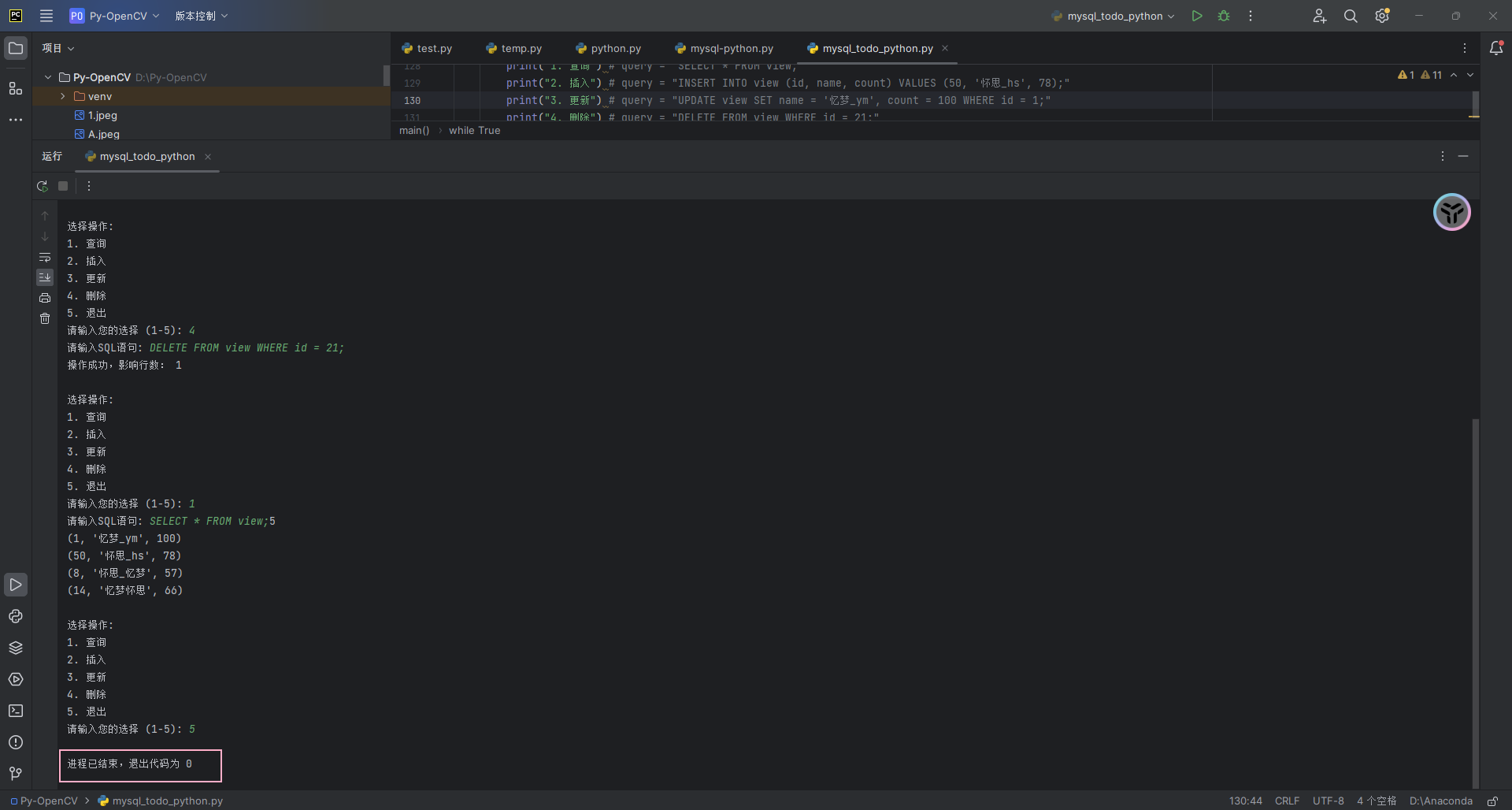
利用python连接MySQL数据库并执行相关sql操作
一、新建MySQL数据库 1.启动MySQL服务 打开phpstudy,开启MySQL服务。如果开启失败的话,可以打开任务管理器,把正在运行的mysqld服务的进程进行关闭,再次打开MySQL服务即可启动。 2.新建MySQL数据库 选择数据库,点击…...

jenkins配置
branch: "dev" 切换分支 $WORKSPACE: /var/lib/jenkins/workspace/jenkins任务名 dest_passwd服务器密码 变量 sudo sshpass -p $dest_passwd ssh root192.168.211.319 -tt rm -rf /data/patent/*:删除文件/data/patent/* sudo sshpa…...
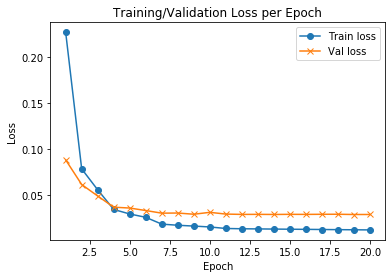
LeNet对MNIST 数据集中的图像进行分类--keras实现
我们将训练一个卷积神经网络来对 MNIST 数据库中的图像进行分类,可以与前面所提到的CNN实现对比CNN对 MNIST 数据库中的图像进行分类-CSDN博客 加载 MNIST 数据库 MNIST 是机器学习领域最著名的数据集之一。 它有 70,000 张手写数字图像 - 下载非常简单 - 图像尺…...

Django的回顾的第4天
1.模型层 1.1简介 你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python代码之中。 def current_datetime(request):now datetime.datetime.now()html "<html><body>It is now %s.</body><…...
)
点云从入门到精通技术详解100篇-基于三维点云的工件曲面轮廓检测与机器人打磨轨迹规划(中)
目录 2.2.2 散乱点云滤波去噪 2.2.3 海量点云数据压缩 2.3 点云采集与预处理实验...
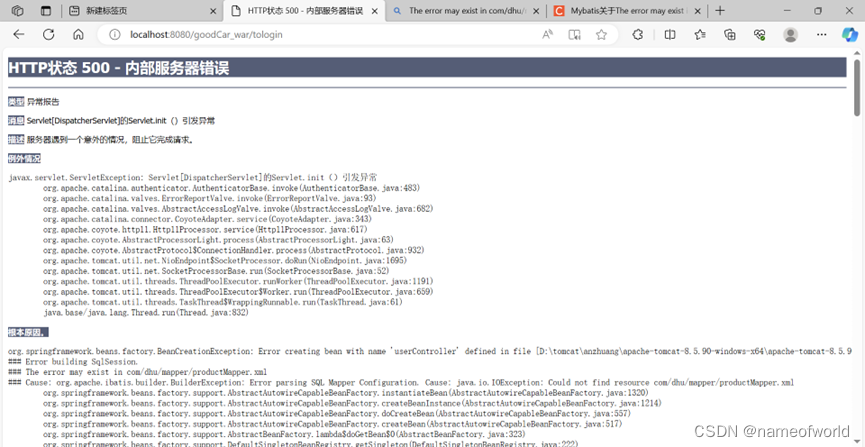
Mapper文件夹在resource目录下但是网页报错找不到productMapper.xml文件的解决
报错如下: 我的Mapper文件夹在resourse目录下但是网页报错找不到productMapper.xml。 结构如下:代码如下:<mappers><mapper resource"com/dhu/mapper/productMapper.xml" /> </mappers> 这段代码是在mybatis-co…...

22.Oracle中的临时表空间
Oracle中的临时表空间 一、临时表空间概述1、什么是临时表空间2、临时表空间的作用 二、临时表空间相关语法三、具体使用案例1、具体使用场景示例2、具体使用场景代码示例 点击此处跳转下一节:23.Oracle11g的UNDO表空间点击此处跳转上一节:21.Oracle的程…...
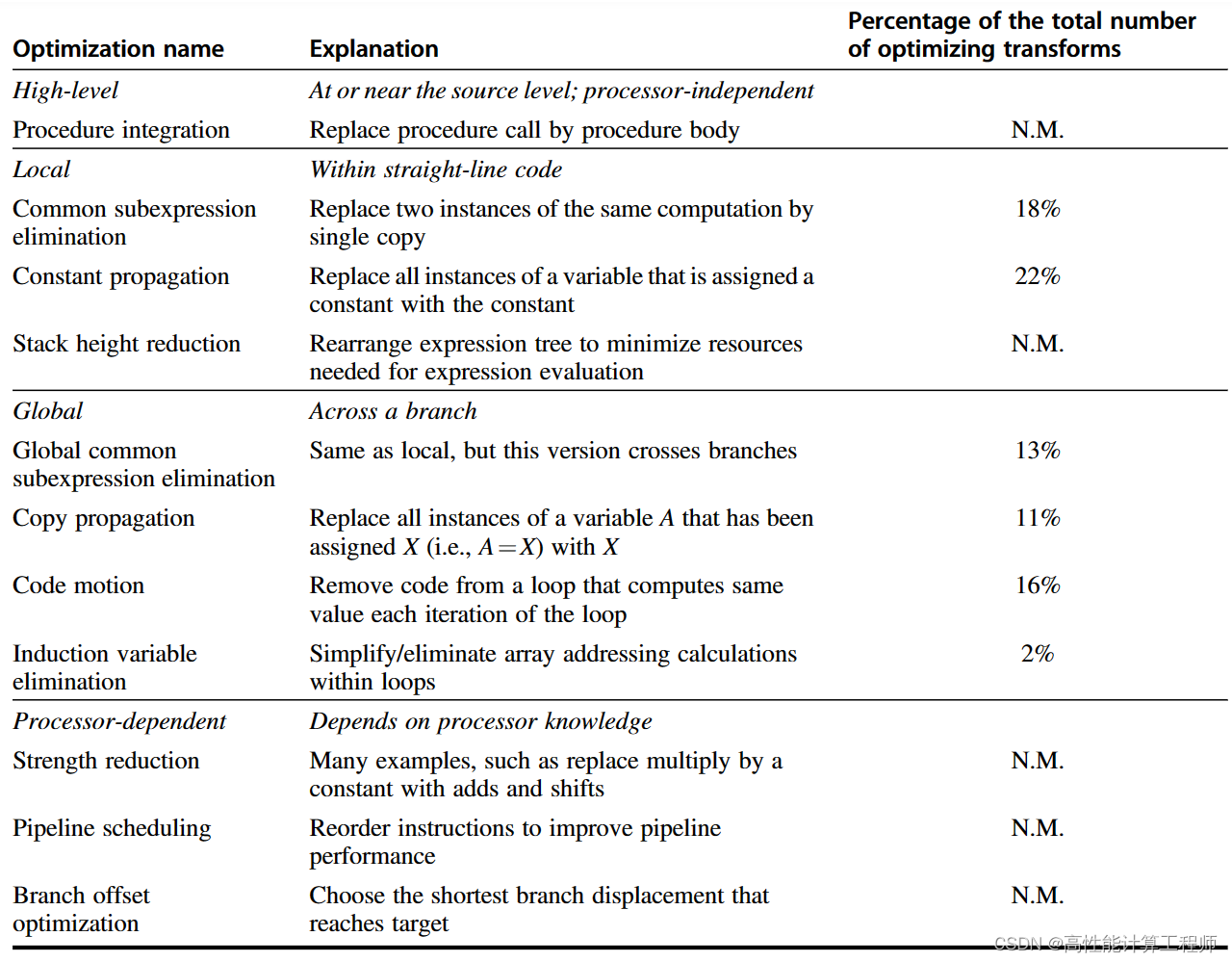
附录A 指令集基本原理
1. 引言 本书主要关注指令集体系结构4个主题: 1. 提出对指令集进行分类的方法,并对各种方法的优缺点进行定性评估; 2. 提出并分析一些在很大程度上独立于特定指令集的指令集评估数据。 3. 讨论语言与编译器议题以及…...

Unittest单元测试之unittest用例执行顺序
unittest用例执行顺序 当在一个测试类或多个测试模块下,用例数量较多时,unittest在执行用例 (test_xxx)时,并不是按从上到下的顺序执行,有特定的顺序。 unittest框架默认根据ACSII码的顺序加载测试用例&a…...

海云安谢朝海:开发安全领域大模型新实践 人工智能助力高效安全左移
2023年11月29日,2023中国(深圳)金融科技大会成功举行,该会议是深圳连续举办的第七届金融科技主题年度会议,也是2023深圳国际金融科技节重要活动之一。做好金融工作,需要兼顾创新与安全,当智能体…...

Postman接口测试工具完整教程
前言 作为软件开发过程中一个非常重要的环节,软件测试越来越成为软件开发商和用户关注的焦点。完善的测试是软件质量的保证,因此软件测试就成了一项重要而艰巨的工作。要做好这项工作当然也绝非易事。 第一部分:基础篇 postman:4.5.1 1.安…...

Android 滑动按钮(开关) SwitchCompat 自定义风格
原生的SwitchCompat控件如下图,不说不堪入目,也算是不敢恭维了。开个玩笑... 所以我们就需要对SwitchCompat进行自定义风格,效果如下图 代码如下 <androidx.appcompat.widget.SwitchCompatandroid:id"id/switch_compat"android:…...
)
前端面试灵魂提问-计网(2)
1、websocket 为什么全双工? 1.1 WebSocket是什么 WebSocket 是一种通信协议,它在客户端和服务器之间建立持久的全双工连接。全双工意味着数据可以双向流动,即客户端可以向服务器发送消息,服务器也可以向客户端发送消息,而无需…...

Git修改远程仓库名称
1、先直接在远程点仓库名,然后左侧菜单栏找settings-general,然后直接修改工程名,保存即可。 2、还是在settings-general下,下拉找到Advanced点击Expand展开,然后下拉到最底部 在Change path里填入新的项目名称&#x…...
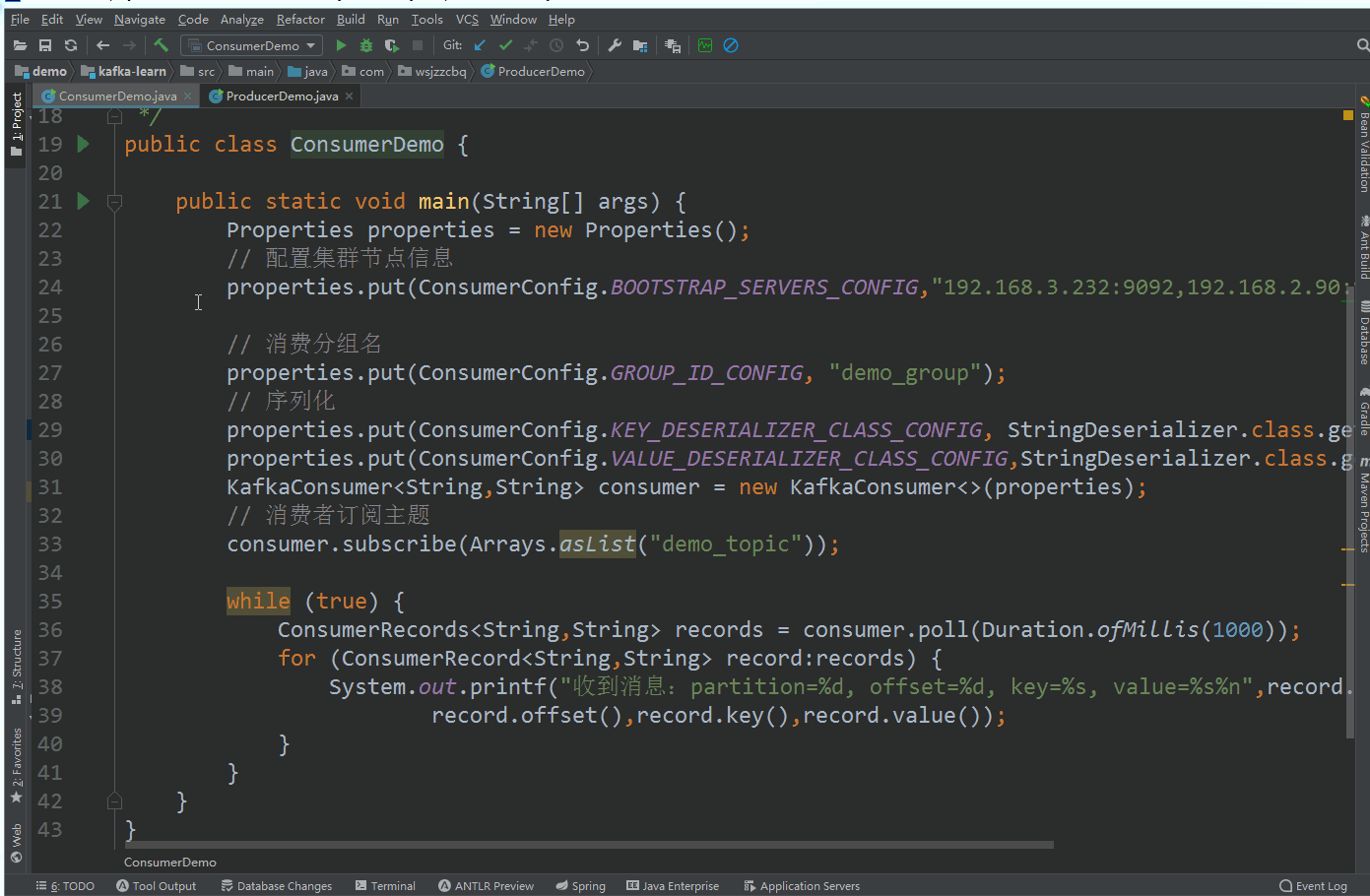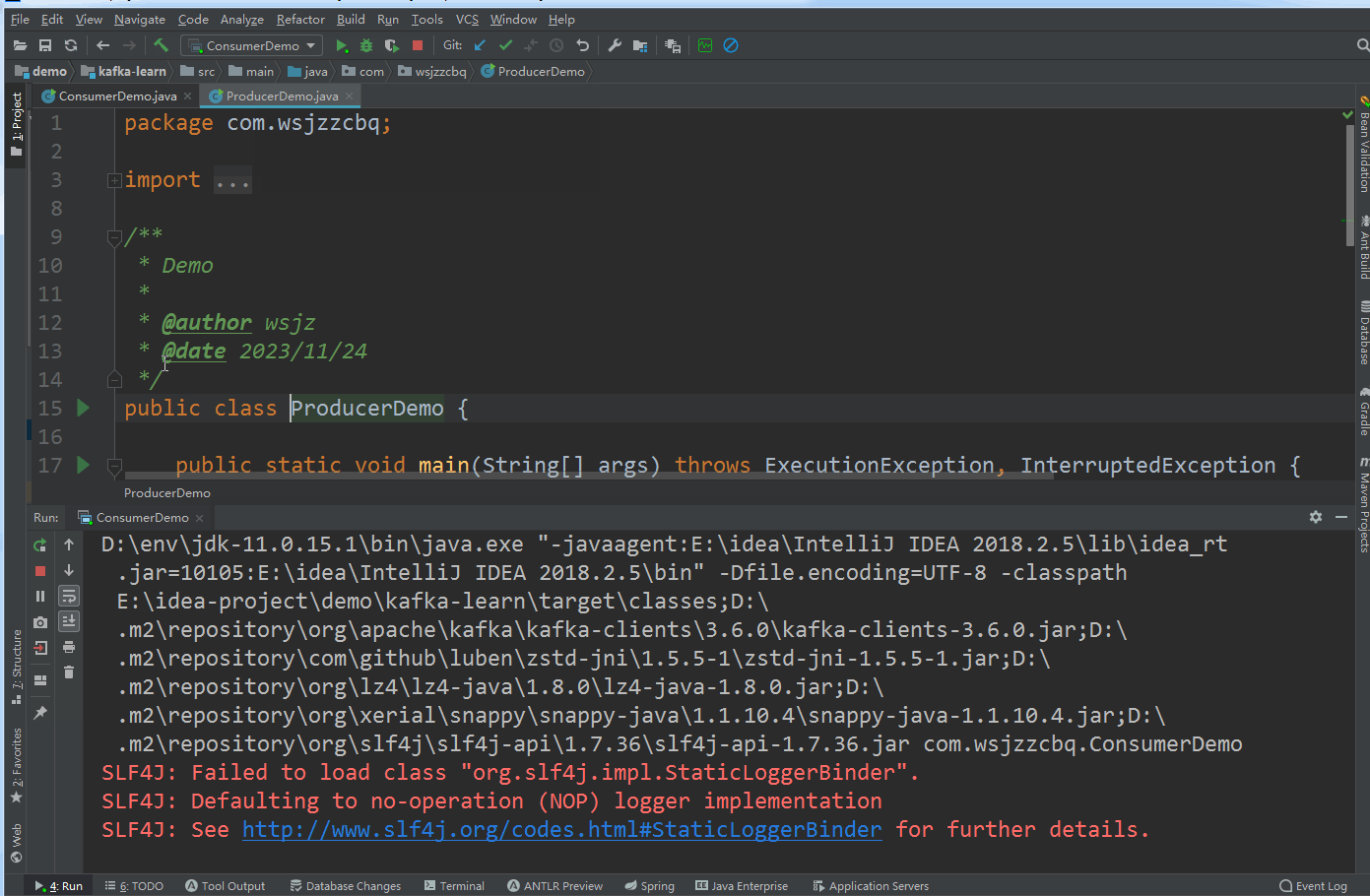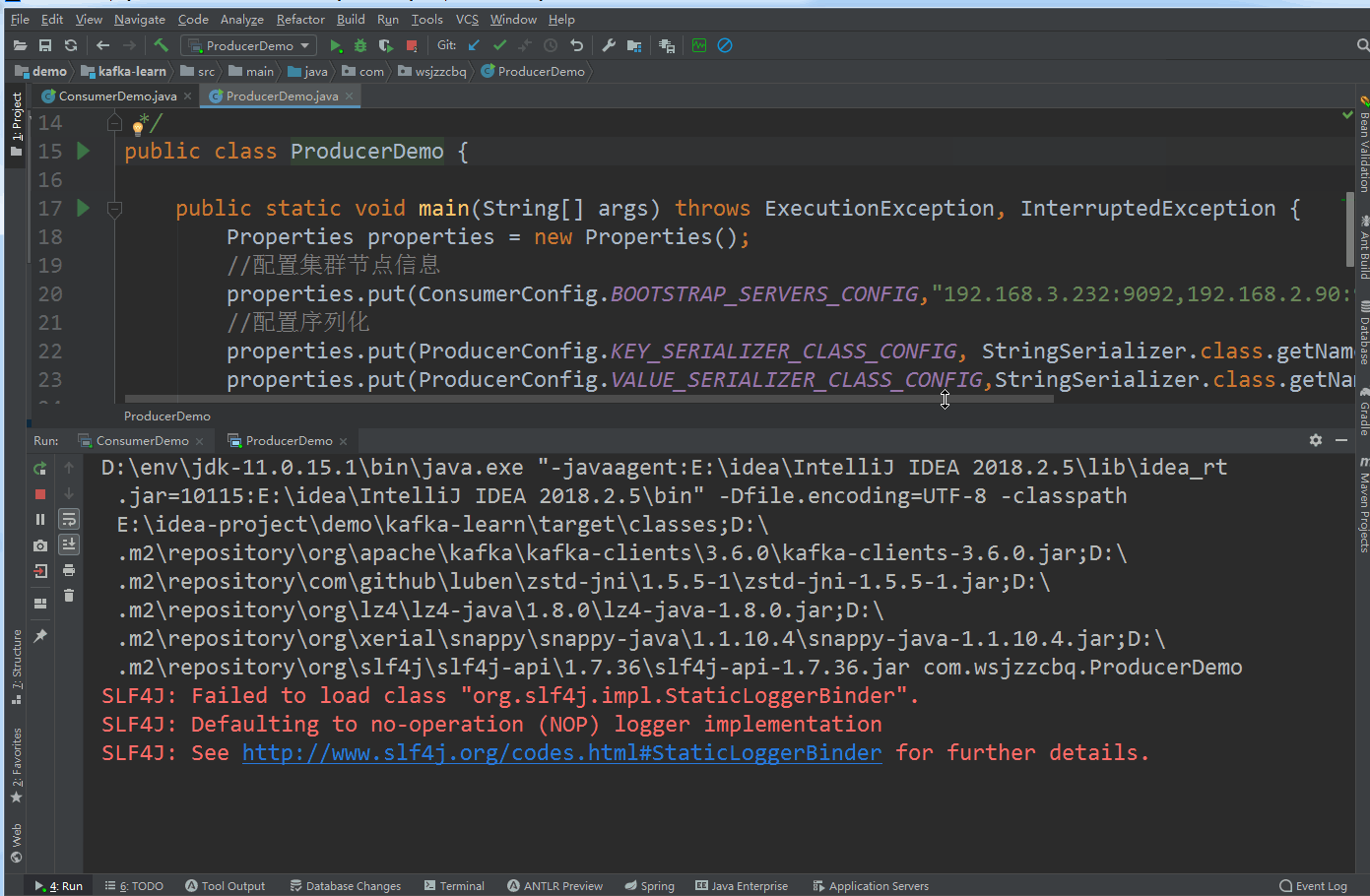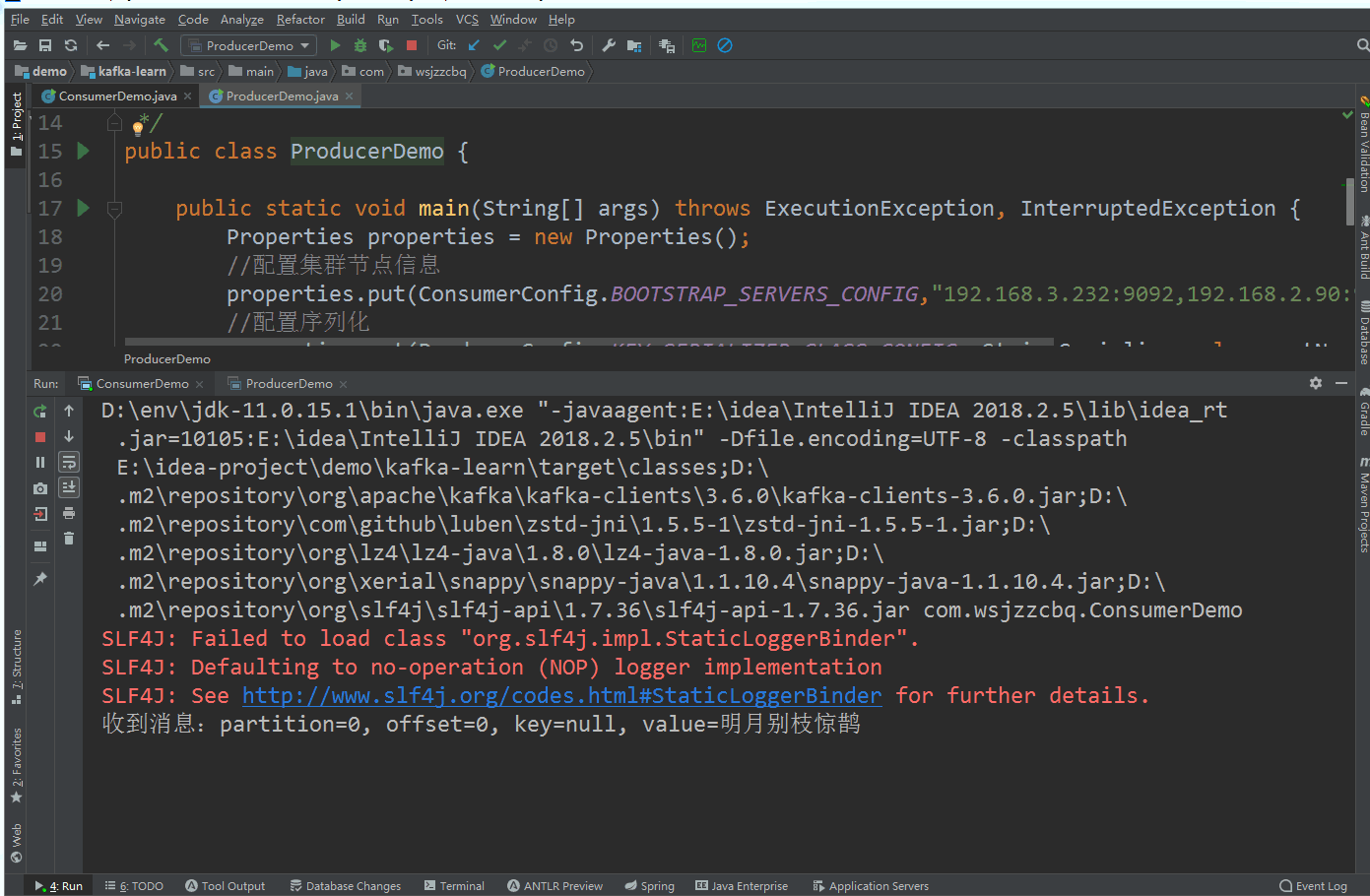
kafka 集群 ZooKeeper 模式搭建
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序 Kafka 官网:Apache Kafka 关于ZooKeeper的弃用 根据 Kafka官网信息,随着Apache Kafka 3.5版本的发布,Zookeeper现…...
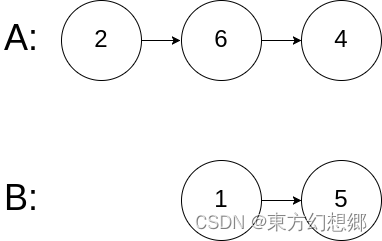
【LeetCode】 160. 相交链表
相交链表 题目题解 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意&am…...

TZOJ 1429 小明A+B
答案: #include <stdio.h> int main() {int T0, A0, B0, sum0;scanf("%d", &T); //输入测试数据的组数while (T--) //循环T次{scanf("%d %d", &A, &B); //输入AB的值sum A B;if (sum > 100) //如果是三位数{…...

制作openeuler的livecd
下载该项目,执行下面的操作gitee openeuler livecd项目 基于openeuler环境 #安装工具,第一次可能报错,可以再执行一次 make installx86 livecd-creator -d -v --config./config/euler_x86_64.ks --fslabeleuler-LiveCD --cachecache --log…...

【大模型12步学习路线 · 第12步 · ②代码篇】Qwen3-VL + ColQwen2.5 + Qdrant 多模态 RAG 全栈实战
【大模型12步学习路线 第12步 ②代码篇】Qwen3-VL + ColQwen2.5 + Qdrant 多模态 RAG 全栈实战 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ②代码篇。 前置阅读:①原理篇 —— VLM 全景 + Multimodal RAG 三大架构。 本篇产出:Qwen3-VL-8B 视觉问答上手…...

毕业设计精选【芳心科技】无人机定点投放控制
实物效果图:实现功能:本次设计的目的是实现无人机在空中投放物品的落点计算,系统的核心是单片机,它控制本系统的各种功能,所以它的选择是非常重要的,在本设计中选用的是GD32F103C8T6单片机,这款…...
就是这么强大!)
哈哈哈哈哈打不过我吧,没有办法我(vllm)就是这么强大!
前文智谱GLM太强了,coding plan还需要限时抢购,咱们自己vllm也咧一个呗!在微信公众号平台爆了 ,接近1w自然阅读,文生文已经满足不了博主的分享欲,今天记录vllm咧一个文生图模型。在文本生成领域,…...

用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战
用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战 黏菌算法(Slime Mould Algorithm, SMA)作为一种新兴的智能优化算法,近年来在工程优化、机器学习参数调优等领域展现出独特优势。本文将带您从生物行为理解到Python实现&a…...

AI写作辅助网站的使用规范:如何让AI生成内容通过严格学术审查
"论文写到一半卡住了,还能不能用AI?""AI生成的内容会被查出来吗?""学校不让用AI,但不靠它我真的写不完!"2026年的毕业季,论文写作的焦虑比往年更甚。面对日益严格的学术审查…...

开发AI应用时如何借助Taotoken模型广场进行选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时如何借助Taotoken模型广场进行选型 当开发者着手构建一个AI应用时,选择合适的模型往往是项目成功的关键起…...

如何为你的Python数据分析脚本注入多模型AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为你的Python数据分析脚本注入多模型AI能力 对于数据分析师和科研工作者而言,Python脚本是处理数据、生成报告的核…...

十大榜单全覆盖,价值兑现引领:联想定义中国AI企业新高度
当前,全球 AI 产业已正式迈入规模化商业落地的关键周期,“技术炫技”让位于“价值兑现”,“算力筑基—技术创新—场景落地”的协同闭环成为高质量发展的核心逻辑。据《全球首席信息官(CIO)报告:企业级 AI 竞…...

ElevenLabs东北话语音效果翻车?92%开发者忽略的3个声调映射参数,立即校准!
更多请点击: https://codechina.net 第一章:ElevenLabs东北话语音效果翻车现象溯源 近期大量中文开发者在使用 ElevenLabs API 生成东北方言语音时,普遍反馈合成结果严重偏离预期——语调生硬、儿化音缺失、语气词(如“嘎哈”“瞅…...

ARM SVE存储指令ST1D与ST1H深度解析与优化
1. ARM SVE存储指令深度解析在ARMv8架构的可扩展向量扩展(SVE)指令集中,ST1D和ST1H指令扮演着关键角色。这些指令专为高效的内存存储操作设计,特别适合处理大规模数据集的场景。与传统的标量存储指令相比,它们能同时处理多个数据元素…...