Hdoop学习笔记(HDP)-Part.15 安装HIVE
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十五、安装HIVE
1.配置MetaStore
利用ambari创建的MySQL作为MetaStore,创建用户hive及数据库hive
mysql -uroot -p
CREATE DATABASE hive;
CREATE USER 'hive'@'%' IDENTIFIED BY 'lnyd@LNsy115';
GRANT ALL ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
2.安装
在服务中添加Hive
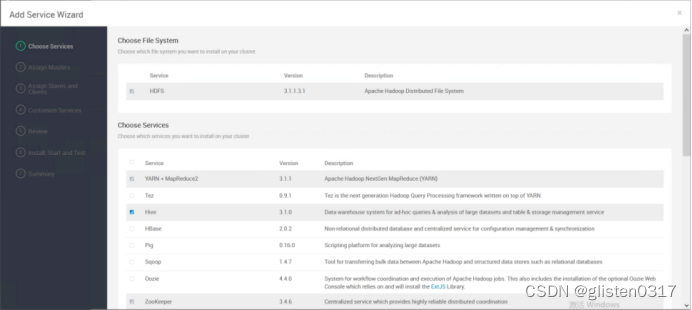
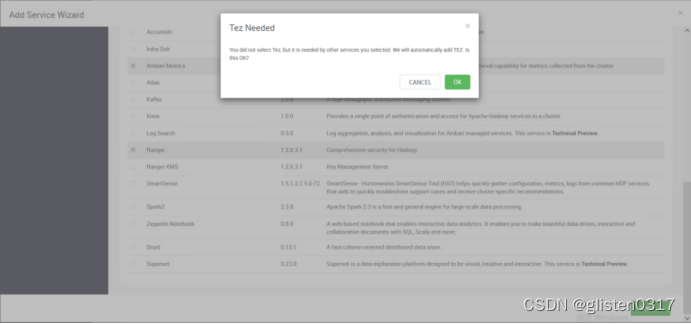
安装hive时需要同步安装Tez
DATABASE
Hive Database:Existing MySQL / MariaDB
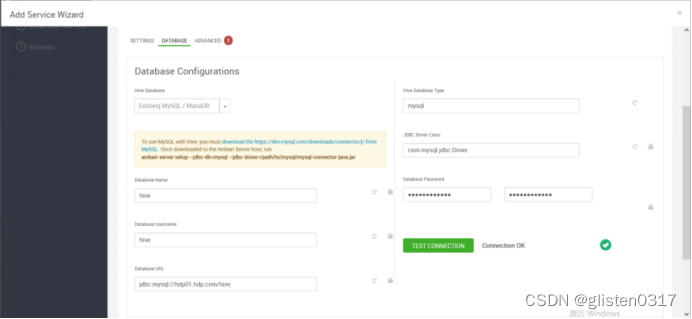

安装完成后,需要按照提示将hdfs、yarn等服务进行重启。
Ambari安装后,Hive使用了Tez作为计算引擎,也可以修改为MR或Spark,在配置文件中调整,/usr/hdp/3.1.5.0-152/hive/conf/hive-site.xml
<property><name>hive.execution.engine</name><value>tez</value></property>
3.高可用
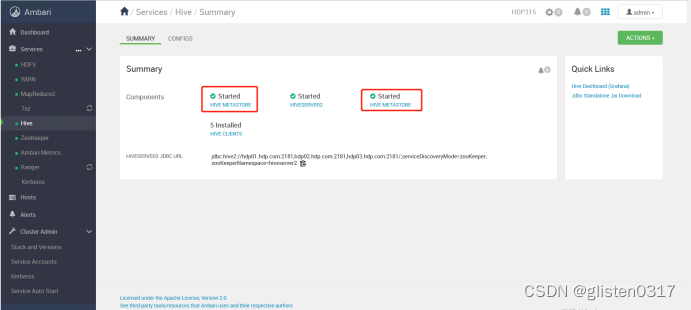
(1)MetaSore HA
ACTIONS->Add Hive Metastore
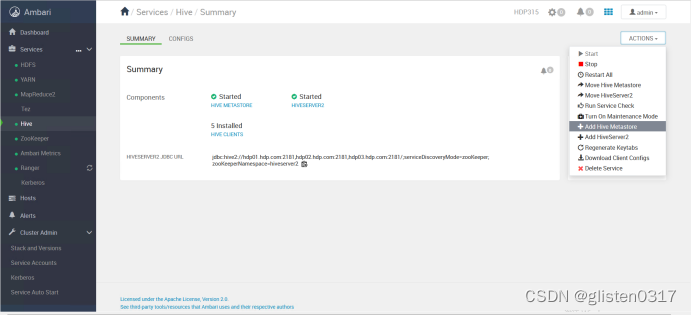
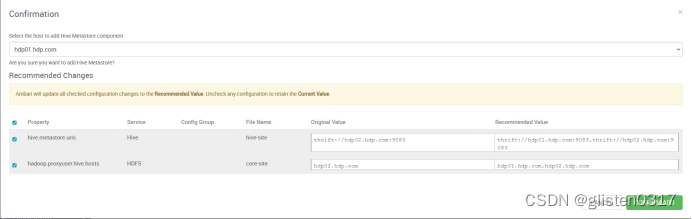
重启相关服务后完成HA启用。
(2)HiveServer2 HA
ACTIONS->Add HiveServer2
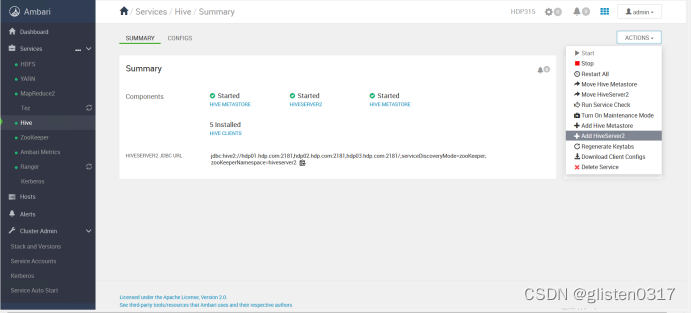
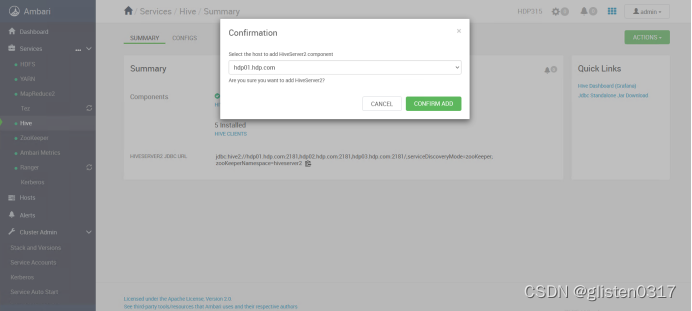
重启HIVE和Tez服务后完成HA启用。
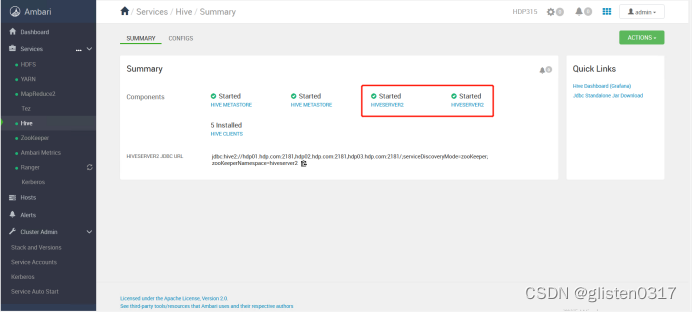
4.Ranger授权
在Ranger上新建策略完成对租户的授权
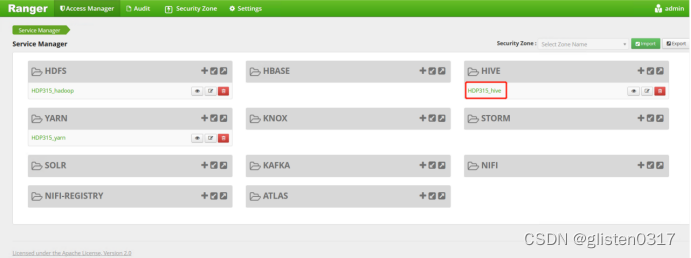

权限策略可以精细到列
5.常用指令
(1)CLI连接
类似于mysql的命令行工具,但是只能操作本地的Hive服务,无法通过JDBC连接远程服务,且sql执行结果没有格式化,看起来不是很直观。
先用keytab登录,使用hive客户端进入
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
hive

可以设置一些基本参数,让hive使用起来更便捷:
让提示符显示当前库
set hive.cli.print.current.db=true;
显示查询结果时显示字段名称
set hive.cli.print.header=true;
设置只对当前会话有效,重启hive会话后就失效。
创建测试数据库test_hive_db
create database test_hive_db;

查看数据库的信息
desc database test_hive_db;
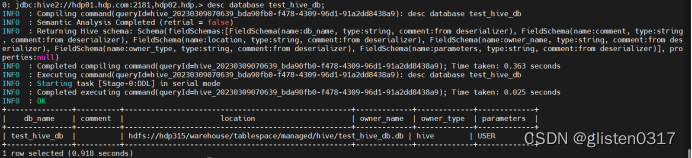
从输出结果看,测试数据库test_hive_db存储在hdfs上,位置为hdfs://hdp315/warehouse/tablespace/managed/hive/test_hive_db.db
(2)Beeline连接
HiveServer2支持一个新的命令行Shell,称为:Beeline,后续将会使用Beeline替代Hive CLI。Beeline基于SQLLine CLI的JDBC客户端。Hive CLI和Beeline都属于命令行操作模式,主要区别是Hive CLI只能操作本地的Hive服务,而Beeline可以通过JDBC连接远程服务。
开启了kerberos认证的hadoop集群,hive默认使用kerberos认证。先以hive/hdp01.hdp.com@HDP315.COM身份登录,创建数据库hive_db_tenant1和tenant2、表hive_table_tenant1和hive_table_tenant2,在ranger上分别将两个租户赋权到对应的数据库上,然后以tenant1身份连接,分别尝试连接两个数据库,看是否有权限访问
kinit -kt /etc/security/keytabs/hive.service.keytab hive/hdp01.hdp.com@HDP315.COM
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
create database hive_db_tenant1;
create database hive_db_tenant2;
create table hive_db_tenant1.hive_table_tenant1 (id int,name string,address string,phone string);
create table hive_db_tenant2.hive_table_tenant2 (id int,name string,address string,phone string);
kdestroy
kinit -kt /root/keytab/tenant1.keytab tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
describe hive_db_tenant1.hive_table_tenant1;
describe hive_db_tenant2.hive_table_tenant2;
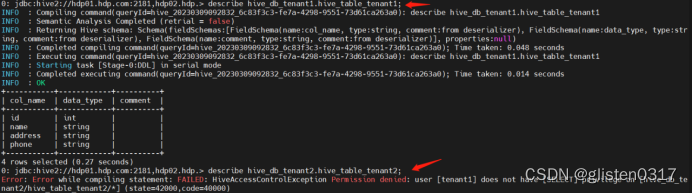
从结果看,无法访问hive_table_tenant2的表。
(3)导入数据等测试
生成6GB大小的文件
#!/bin/bash
cat /dev/null > /root/bigFile.txt
for((i=1;i<=100000000;i++));
doecho "$i,testname$i,testaddress$i,testphonenumber$i" >> /root/bigFile.txt;
done
本次测试使用tenant1
kinit -kt /root/keytab/tenant1.keytab tenant1
hdfs dfs -put /root/bigFile.txt /testhdfs/tenant1
beeline -u 'jdbc:hive2://hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;principal=hive/hdp01.hdp.com@HDP315.COM'
set tez.queue.name=tenant1;
① 导入测试
测试一次性导入和切分导入的性能
新建表,用于一次性导入
CREATE TABLE `test_tenant1_one`(
`id` int,
`name` string,
`address` string,
`phone` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_one.db';
执行导入
LOAD DATA INPATH 'hdfs://hdp315/testhdfs/tenant1/bigFile.txt' INTO TABLE hive_db_tenant1.test_tenant1_one;

新建表,用于分桶导入,分桶的实质就是对分桶的字段做了hash,然后存放到对应文件中,所以说如果原有数据没有按key hash,需要在插入分桶的时候hash,也就是说向分桶表中插入数据的时候必然要执行一次MAPREDUCE,这也就是分桶表的数据基本只能通过从结果集查询插入的方式进行导入
CREATE TABLE `test_tenant1_bucket`(
`id` int,
`name` string,
`address` string,
`phone` string
)
CLUSTERED BY(id) INTO 16 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 'hdfs://hdp315/testhdfs/tenant1/test_tenant1_bucket.db';
执行导入
INSERT OVERWRITE TABLE test_tenant1_bucket SELECT * FROM test_tenant1_one;
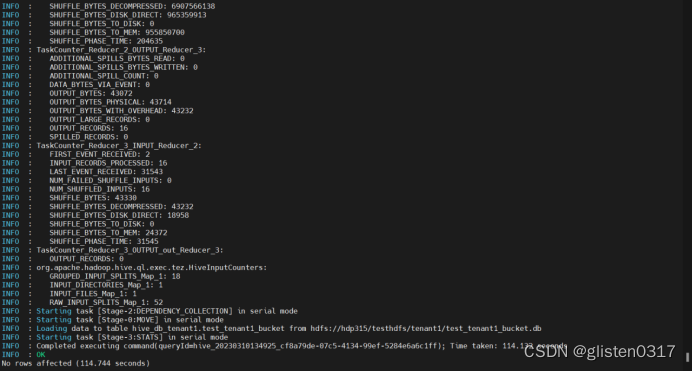
此时,分桶后的文件会分成16个分片
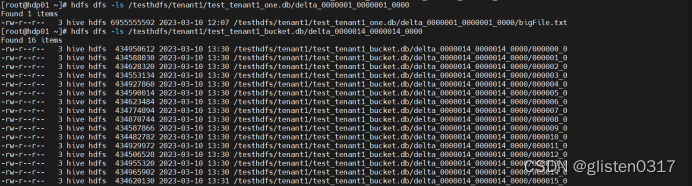
② 查询测试
对测试的数据库进行查询操作
SELECT SUM(id) FROM hive_db_tenant1.test_tenant1_bucket;
6.常见报错
(1)提示没有权限调用default队列
Select查询不报错,但count、insert、load等操作需要调用tez引擎时会报错
报错信息:
ERROR : Job Submission failed with exception 'java.io.IOException(org.apache.hadoop.yarn.exceptions.YarnException: org.apache.hadoop.security.AccessControlException: User hive does not have permission to submit application_1678378182198_0002 to queue default
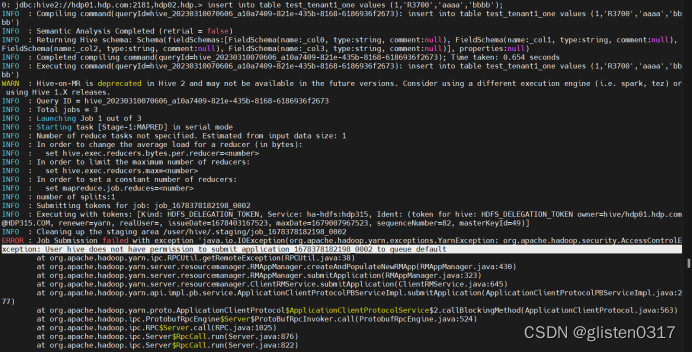
默认调用的是default队列,需要手工指定使用的队列
mr指定队列:
set mapreduce.job.queuename=tenant1;
tez指定队列:
set tez.queue.name=tenant1;
相关文章:
Hdoop学习笔记(HDP)-Part.15 安装HIVE
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

vue3+element-plus之el-date-picker日期选择器清空无回调的解决方案
MENU 前言解决htmlJavaScrip 前言 在一个任务列表的搜索栏,添加一个日期区间搜索。使用到element-plus中的日期选择器el-date-picker;el-date-picker本身方法中有change事件,但是清空按钮没有对应回调方法。在任务列表的搜索需求中࿰…...
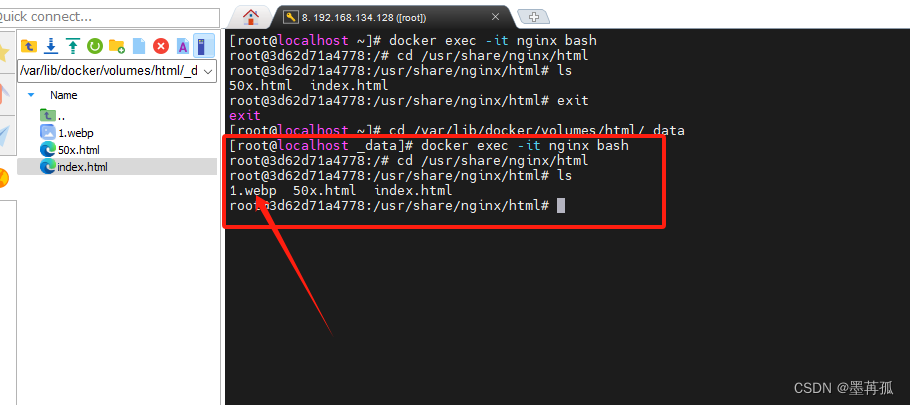
【虚拟机】Docker基础 【二】
2.2.数据卷 容器是隔离环境,容器内程序的文件、配置、运行时产生的容器都在容器内部,我们要读写容器内的文件非常不方便。大家思考几个问题: 如果要升级MySQL版本,需要销毁旧容器,那么数据岂不是跟着被销毁了&#x…...

CSS 绝对定位问题和粘性定位介绍
目录 1,绝对定位问题1,绝对定位元素的特性2,初始包含块问题 2,粘性定位注意点: 1,绝对定位问题 1,绝对定位元素的特性 display 默认为 block。所以行内元素设置绝对定位后可直接设置宽高。脱离…...

matlab 计算两点云之间的放缩倍数
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 1、原理概述 放缩倍数即尺度参数,尺度参数可由2个公共点在不同坐标系下的距离之…...

MySQL-数据库设计与实现
目录 第1关:从概念模型到MySQL实现 第2关:从需求分析到逻辑模型 第3关:建模工具的使用 第1关:从概念模型到MySQL实现 任务描述 将已建好的概念模型,变成MySQL物理实现。 # 请将你实现flight_booking数据库的语句写…...

后端返回图片流前端展示图片
根据后端返回的图片流格式,选用合适方法转换 下面以base64为例 if(res.status 200) {res.data.data.forEach((item,index) > {let Array data:image/png;base64, itemlet blob this.base64toBlob(Array)let url URL.createObjectURL(blob)this.imageList.p…...

解决 from . import _imaging as core ImportError: DLL load failed: 找不到指定的模块。
升级pillow版本就完事了 卸载掉之前的旧版本 conda uninstall pillow升级到新的版本就解决了 pip uninstall pillow 那个错误就解决了...

springBoot3.2 + jdk21 + GraalVM上手体验
springBoot3.2 jdk21 GraalVM上手体验 SpringBoot2.x官方已经停止维护了,jdk8这次真的得换了🤣 可以参考官方文章进行体验:https://spring.io/blog/2023/09/09/all-together-now-spring-boot-3-2-graalvm-native-images-java-21-and-virt…...
)的用法,web中的应用)
Python float(input())的用法,web中的应用
float(input()) 要理解Python中的float(input()),可以分两部分。第一,input()用于获取键盘上的输入,该函数的返回值是一个Python字符串str类型的数据——不过输入的是什么;第二,float()函数用于将传递的参数——这里就…...
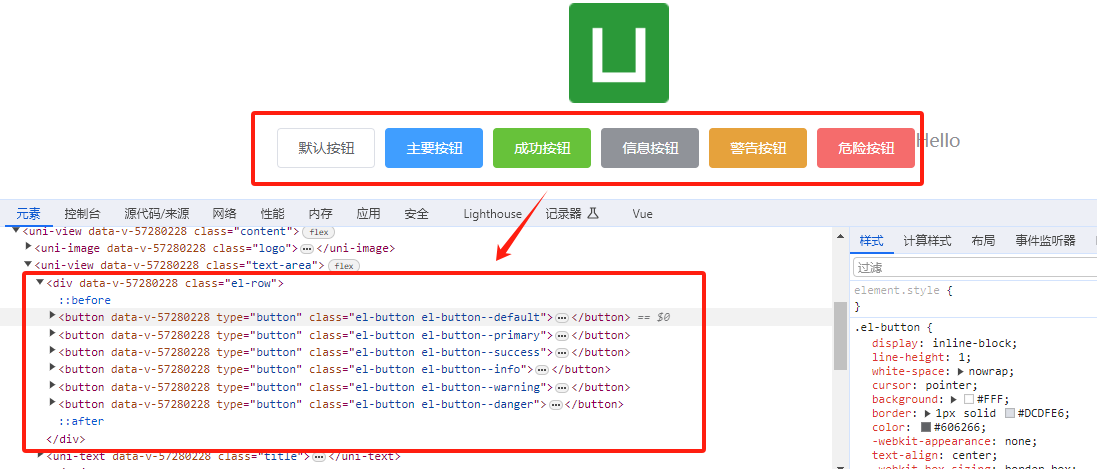
uniapp是否可以用elementUI等前端UI库、使用步骤以及需要注意的问题
文章目录 uniapp是否可以用elementUI等前端UI库使用方法和步骤问题如何解决 uniapp是否可以用elementUI等前端UI库 在PC端开发uniapp,可以用elementUI,因为elementUI就是PC端的。 在使用uniapp,选择vue2.0时,实测可以用nodejs16的…...

在vue中如何书写 SSR 友好的代码
文章目录 前言服务端的响应性组件生命周期钩子访问平台特有 API跨请求状态污染激活不匹配自定义指令teleports后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:vue.js 🐱👓博主在前端领域还有很多…...

开源与闭源:数字时代大模型之辩
欢迎大家到我的博客浏览更多文章。YinKais Blog | YinKais Blog 大模型的未来:开源与闭源的博弈 在大模型的发展中,开源和闭源两种截然不同的开发模式发挥着重要的作用。开源以其技术共享的特性,吸引了大量人才参与,推动了大模型的…...

卷积神经网络(VGG-16)猫狗识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、数据预处理1. 加载数据2. 再次检查数据3. 配置数据集4. 可视化数据 三、构建VG-16网络四、编译五、训练模型六、模型评估七、保存and加载模型八、预测…...
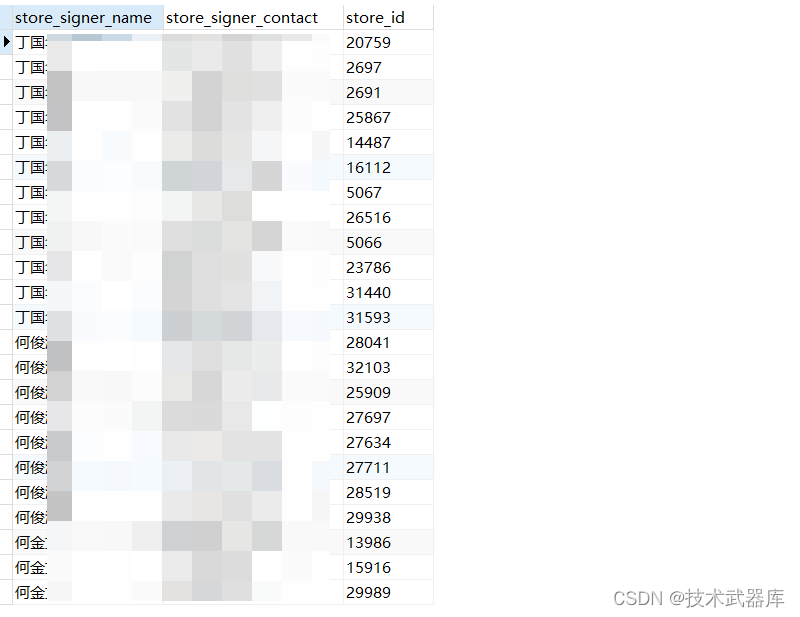
Mysql 行转列,把逗号分隔的字段拆分成多行
目录 效果如下源数据变更后的数据 方法第一种示例SQL和业务结合在一起使用 第二种示例SQL和业务结合在一起使用 结论 效果如下 源数据 变更后的数据 方法 第一种 先执行下面的SQL,看不看能不能执行,如果有结果,代表数据库版本是可以的&…...
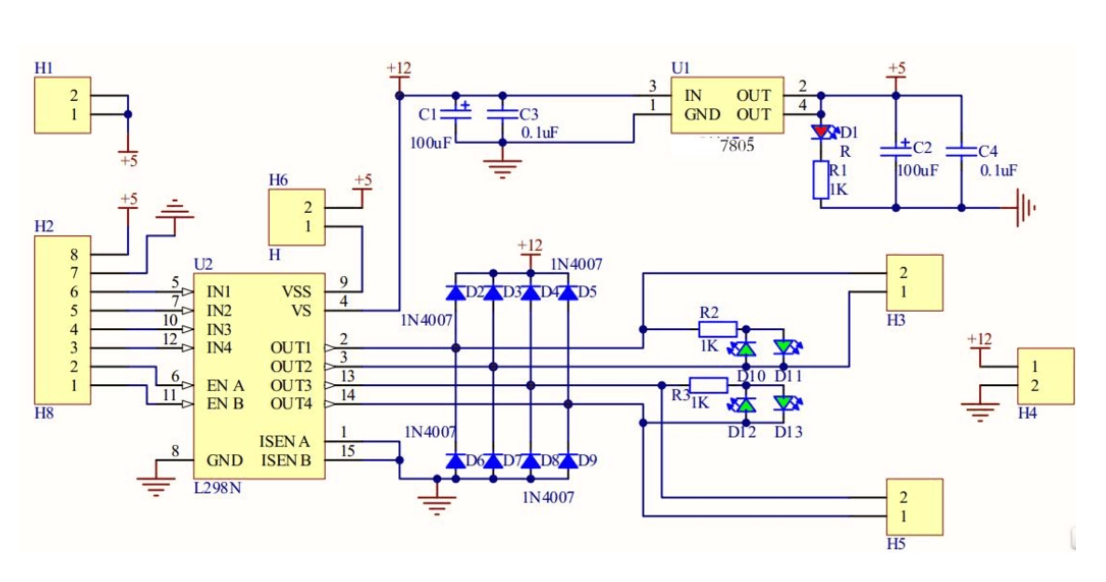
基于单片机设计的智能水泵控制器
一、前言 在一些场景中,如水池、水箱等水体容器的管理中,保持水位的稳定是至关重要的。传统上,人们通常需要手动监测水位并进行水泵的启停控制,这种方式不仅效率低下,还可能导致水位过高或过低,从而对水体…...
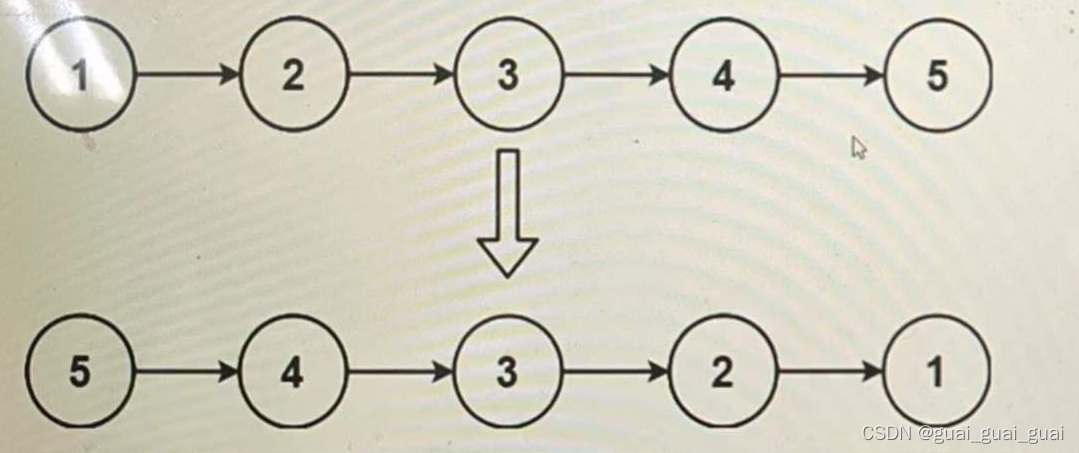
反转链表的实现
题目描述: 给出一个链表的头节点,将其反转,并返回新的头节点 思路1:反转地址 将每个节点里的地址由指向下一个节点变为指向前一个节点 定义三个结构体指针n1,n2,n3,n1表示改后指针的地址,n2表示要修改结构体里next的…...
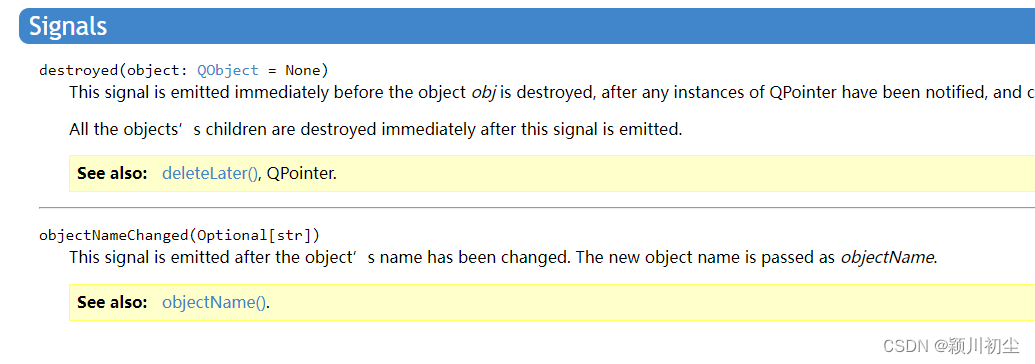
python之pyqt专栏6-信号与槽2
上一篇python之pyqt专栏5-信号与槽1-CSDN博客,我们通过信号与槽实现了点击Button,改变Label的文本内容。可以知道 信号是在类中定义的,是类的属性 槽函数是信号通过connect连接的任意成员函数,当信号发生时,执行与信号…...

C语言中一些特殊字符的输出
目录 %的介绍 斜杠与反斜杠 转义字符 %的介绍 int a1; 1、printf(’’%d’’,a);//输出1 2、printf(’’%%d’’,a);//输出%d 3、printf(’’%%%d ‘’,a)//输出%1 C语言中,%也是转义符,%%相当于% 斜杠与反斜杠 首先需要明白…...

Opencv制作电子签名(涉及知识点:像素过滤,图片通用resize函数,像素大于某个阈值则赋值为其它的像素值)
import cv2def resize_by_ratio(image, widthNone, heightNone, intercv2.INTER_AREA):img_new_size None(h, w) image.shape[:2] # 获得高度和宽度if width is None and height is None: # 如果输入的宽度和高度都为空return image # 直接返回原图if width is None:h_ratio …...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...

OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 [特殊字符]
OpenPose编辑器:解锁AI绘画中人体姿态的精准控制秘诀 🎨 【免费下载链接】openpose-editor Openpose Editor for AUTOMATIC1111s stable-diffusion-webui 项目地址: https://gitcode.com/gh_mirrors/op/openpose-editor 在AI绘画创作的世界里&…...

AI应用哪家性价比高
在当前数字化转型浪潮中,企业纷纷寻求AI应用来降本增效,但面对市场上琳琅满目的产品,“AI应用哪家性价比高”成为决策者最纠结的问题。性价比并非单纯的价格对比,而是功能、效率、易用性与实际价值的综合考量。本文将从行业痛点出…...

互联网大厂Java面试实录:严肃面试官 vs. 搞笑程序员谢飞机
互联网大厂Java面试实录:严肃面试官 vs. 搞笑程序员谢飞机第一轮:基础问题 面试官:你好,谢飞机。既然你是来应聘Java开发岗位的,那我先问一些简单的问题。第一个问题,Java中的HashMap是线程安全的吗&#x…...

如何快速上手UndertaleModTool:游戏修改的完整指南
如何快速上手UndertaleModTool:游戏修改的完整指南 【免费下载链接】UndertaleModTool The most complete tool for modding, decompiling and unpacking Undertale (and other GameMaker games!) 项目地址: https://gitcode.com/gh_mirrors/un/UndertaleModTool …...

计算机专业生打 CTF 全指南:从新手小白到赛事拿分,附实战避坑手册_ctf比赛自己带电脑吗
作为计算机专业毕业的过来人,我始终觉得:CTF 比赛是大学生把课本知识落地成硬技能的最佳载体。 刚上大二时,我还是个只会敲基础代码、对 网络安全停留在课本概念的小白,靠着 3 次参赛经历,不仅吃透了操作系统、计算机…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

yolo11红外光伏板图像识别 光伏板缺陷检测系统
YOLOv11光伏板热缺陷检测系统是一种利用先进的YOLOv11算法进行太阳能光伏板缺陷识别的解决方案。这种系统通常会包含以下几个关键部分: 安装教程 1.安装minconda 2.pycharm 3.安装cuda(11.0)(下载链接:https://develop…...
)
从‘看不见’到‘毁不掉’:深入聊聊数字水印的鲁棒性到底怎么测(附常见攻击模拟方法)
数字水印鲁棒性测试实战指南:从理论到攻击模拟 数字水印技术已经从单纯的学术研究走向了广泛的商业应用,成为版权保护领域不可或缺的一环。但真正决定一个水印系统实用价值的,是其抵抗各种攻击的鲁棒性——这项指标直接关系到水印能否在现实…...

CANN/asc-devkit SIMT fmodf函数
fmodf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...