Python----Pandas
目录
Series属性
DataFrame的属性
Pandas的CSV文件
Pandas数据处理
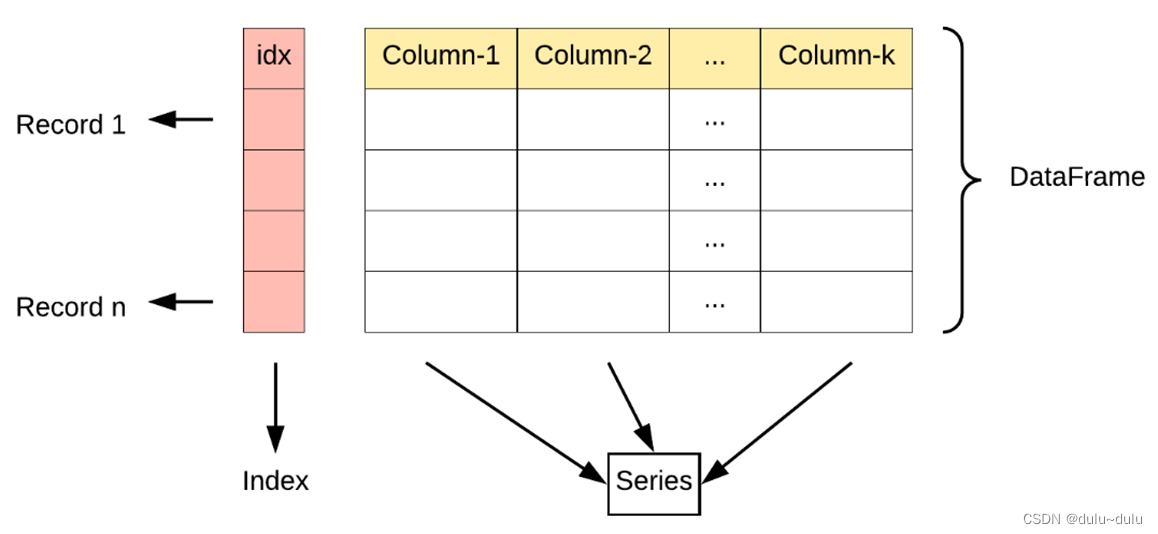
Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据)
Series属性
Series的属性如下:
| 属性 | 描述 |
| pandas.Series(data,index,dtype,name,copy) | Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。 |
| data: 一组数据(ndarray 类型) | |
| index: 数据索引标签,如果不指定,默认从 0 开始。 | |
| dtype: 数据类型,默认会自己判断。 | |
| name: 设置名称。 | |
| copy: 拷贝数据,默认为 False。 |
示例1:
>>> import pandas as pd
>>> a = [1,2,3]
>>> sa = pd.Series(a)
>>> print(sa)
0 1
1 2
2 3
dtype: int64
>>> sa[1]
2
>>> a = ['Google','baidu','wiki']
>>> sa = pd.Series(a,index=['x','y','z'])
>>> print(sa)
x Google
y baidu
z wiki
dtype: object
示例2:
Pandas数据类型包括
•object字符串或混合类型
•int 整型
•float浮点型
•datetime时间类型
•bool布尔型
>>> import numpy as np
>>> import pandas as pd
>>> s = pd.Series(np.random.randn(4),index=['a','b','c','d'])
>>> print(sa)
a -1.226694
b 0.157971
c 0.022525
d 2.606825
dtype: float64
>>> s[:2] #选取前两条数据
a -1.226694
b 0.157971
dtype: float64
>>> s[[1,3]] # 选取第2和第4条数据
b 0.157971
d 2.606825
dtype: float64
>>> s[s<s.mean()] #x小于平均值
a -1.226694
b 0.157971
c 0.022525
dtype: float64
>>> s['a'] #通过索引值选取元素-1.2266936531191652
>>> s[['c','d']] # 多个索引值,注意括号
c 0.022525
d 2.606825
dtype: float64
>>> s = pd.Series(data=['1.2','1.5','2.7','2.3'])
>>> b = s.astype('float32') # 转换类型
>>> print(b)
0 1.2
1 1.5
2 2.7
3 2.3
dtype: float32DataFrame的属性
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
示例:
# 使用列表创建
>>> import pandas as pd
>>> data = [['Google',10],['Baidu',12],['Wiki',13]] #二维列表
>>> df = pd.DataFrame(data, columns=['site','Age'])
>>> print(df)site Age
0 Google 10
1 Baidu 12
2 Wiki 13
# 使用字典创建,其中字典的key为列名
>>> data = {'Site':['Google', 'Baidu','Wiki'],'Age':[10,12,13]}
>>> pf = pd.DataFrame(data)
>>> print(pd)Site Age
0 Google 10
1 Baidu 12
2 Wiki 13
•Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[0]) # 返回第一行
calories 420
duration 50
Name: 0, dtype: int64
注意:返回结果其实就是一个 Pandas Series数据。
•可以返回多行数据,使用[[...]]格式,其中...为各行的索引,逗号隔开:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[[0,1]]) # 返回第一行和第二行calories duration
0 420 50
1 380 40
注意:返回结果其实就是一个 Pandas DataFrame 数据。
# 查看指定列
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df['calories']) #一列访问
0 420
1 380
2 390
Name: calories, dtype: int64
>>> print(df[['calories','duration']]) # 多列访问calories duration
0 420 50
1 380 40
2 390 45
# 查看指定行和列
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[0,'calories']) #第0行,calories数值
420
# 可以指定索引值index:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data, index=['day1','day2','day3'])
>>> print(df)calories duration
day1 420 50
day2 380 40
day3 390 45
# 可以使用loc属性返回指定索引对应到的某一行
>>> print(df.loc['day1'])
calories 420
duration 50
Name: day1, dtype: int64
Pandas的CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
# to_string()用于返回DataFrame类型的数据,如果不使用该函数,则输出结果
# 为数据的前面5行和末尾5行,中间部分以...代替
将DataFrame存储为CSV文件
to_csv()方法
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Baidu", "Taobao", "Wiki"]
st = ["www.google.com", "www.baidu.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
Pandas数据处理
•使用 head(n) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
输出:Name Team Number ... Weight College Salary
0 Avery Bradley Boston Celtics 0.0 ... 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 ... 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 ... 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 ... 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 ... 231.0 NaN 5000000.0
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
输出:Name Team Number ... Weight College Salary
0 Avery Bradley Boston Celtics 0.0 ... 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 ... 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 ... 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 ... 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 ... 231.0 NaN 5000000.0
5 Amir Johnson Boston Celtics 90.0 ... 240.0 NaN 12000000.0
6 Jordan Mickey Boston Celtics 55.0 ... 235.0 LSU 1170960.0
7 Kelly Olynyk Boston Celtics 41.0 ... 238.0 Gonzaga 2165160.0
8 Terry Rozier Boston Celtics 12.0 ... 190.0 Louisville 1824360.0
9 Marcus Smart Boston Celtics 36.0 ... 220.0 Oklahoma State 3431040.0
•使用 tail(n) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
输出:Name Team Number Position ... Height Weight College Salary
453 Shelvin Mack Utah Jazz 8.0 PG ... 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG ... 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C ... 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C ... 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN ... NaN NaN NaN NaN
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
输出:Name Team Number ... Weight College Salary
448 Gordon Hayward Utah Jazz 20.0 ... 226.0 Butler 15409570.0
449 Rodney Hood Utah Jazz 5.0 ... 206.0 Duke 1348440.0
450 Joe Ingles Utah Jazz 2.0 ... 226.0 NaN 2050000.0
451 Chris Johnson Utah Jazz 23.0 ... 206.0 Dayton 981348.0
452 Trey Lyles Utah Jazz 41.0 ... 234.0 Kentucky 2239800.0
453 Shelvin Mack Utah Jazz 8.0 ... 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 ... 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 ... 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 ... 231.0 Kansas 947276.0
457 NaN NaN NaN ... NaN NaN NaN
•info() 方法返回表格的一些基本信息(索引、数据类型和内存信息)
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458 entries, 0 to 457 #行数,458,行,第一行编号为0
Data columns (total 9 columns): #列数,9列
# Column Non-Null Count Dtype #各列的数据类型
--- ------ -------------- -----
0 Name 457 non-null object #non-null,意思是非空的数
1 Team 457 non-null object
2 Number 457 non-null float64
3 Position 457 non-null object
4 Age 457 non-null float64
5 Height 457 non-null object
6 Weight 457 non-null float64
7 College 373 non-null object #college的空值最多
8 Salary 446 non-null float64
dtypes: float64(4), object(5)
memory usage: 32.3+ KB
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
a = df.sort_values(by='Weight') # 按Weight列数据升序排列
print(a.head().to_string())
输出:Name Team Number Position Age Height Weight College Salary
152 Aaron Brooks Chicago Bulls 0.0 PG 31.0 6-0 161.0 Oregon 2250000.0
350 Briante Weber Miami Heat 12.0 PG 23.0 6-2 165.0 Virginia Commonwealth NaN
263 Bryce Cotton Memphis Grizzlies 8.0 PG 23.0 6-1 165.0 Providence 700902.0
359 Brandon Jennings Orlando Magic 55.0 PG 26.0 6-1 169.0 NaN 8344497.0
286 Tim Frazier New Orleans Pelicans 2.0 PG 25.0 6-1 170.0 Penn State 845059.0print(a[a.Weight > 200].head().to_string()) # Weight列大于200的
输出:Name Team Number Position Age Height Weight College Salary
47 Isaiah Canaan Philadelphia 76ers 0.0 PG 25.0 6-0 201.0 Murray State 947276.0
309 Kent Bazemore Atlanta Hawks 24.0 SF 26.0 6-5 201.0 Old Dominion 2000000.0
226 Rashad Vaughn Milwaukee Bucks 20.0 SG 19.0 6-6 202.0 UNLV 1733040.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
282 Bryce Dejean-Jones New Orleans Pelicans 31.0 SG 23.0 6-6 203.0 Iowa State 169883.0
示例3:
import pandas as pd
df = pd.read_csv('nba.csv')
df['one'] = 1 #增加一个固定值的列
print(df.head().to_string())
输出:Name Team Number Position Age Height Weight College Salary one
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0 1
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0 1
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN 1
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0 1
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0 1print(a[a.Weight > 200].head().to_string()) # Weight列大于200的
输出:Name Team Number Position Age Height Weight College Salary
47 Isaiah Canaan Philadelphia 76ers 0.0 PG 25.0 6-0 201.0 Murray State 947276.0
309 Kent Bazemore Atlanta Hawks 24.0 SF 26.0 6-5 201.0 Old Dominion 2000000.0
226 Rashad Vaughn Milwaukee Bucks 20.0 SG 19.0 6-6 202.0 UNLV 1733040.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
282 Bryce Dejean-Jones New Orleans Pelicans 31.0 SG 23.0 6-6 203.0 Iowa State 169883.0
•drop()方法:通过指定标签名称和响应的轴,或者直接指定索引或列名称,删除行或列
| 属性 | 描述 |
| pandas.DataFrame.drop(labels=None, axis=0,index=None,columns=None, level=None,inplace=False,errors=’raise’) | 通过指定标签名称和相应的轴,或直接指定索引或列名称,删除行或列。 |
| labels 单个标签或者标签列表 | |
| axis=0 默认 删除index; axis=1 指定删除列 | |
| inplace=True 修改原数据 | |
| level 针对多重索引 指定级别 | |
| index 指定索引 | |
| columns 指定列名 |
示例:
>>>import pandas as pd
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
输出:a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
#删除行
>>> df.drop(2)a b c d
0 0 1 2 3
1 4 5 6 7
>>> df.drop([0,1])a b c d
2 8 9 10 11>>>import pandas as pd
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
输出:
# 删除列
>>> df.drop('a', axis=1)b c d
0 1 2 3
1 5 6 7
2 9 10 11
>>> df.drop(['b','c'], axis=1)a d
0 0 3
1 4 7
2 8 11
>>> df.drop(columns=['b','c']) # 同上a d
0 0 3
1 4 7
2 8 11
相关文章:
Python----Pandas
目录 Series属性 DataFrame的属性 Pandas的CSV文件 Pandas数据处理 Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据) Series属性 Series的属性如下: 属性描述pandas.Series(data,index,dtype,nam…...
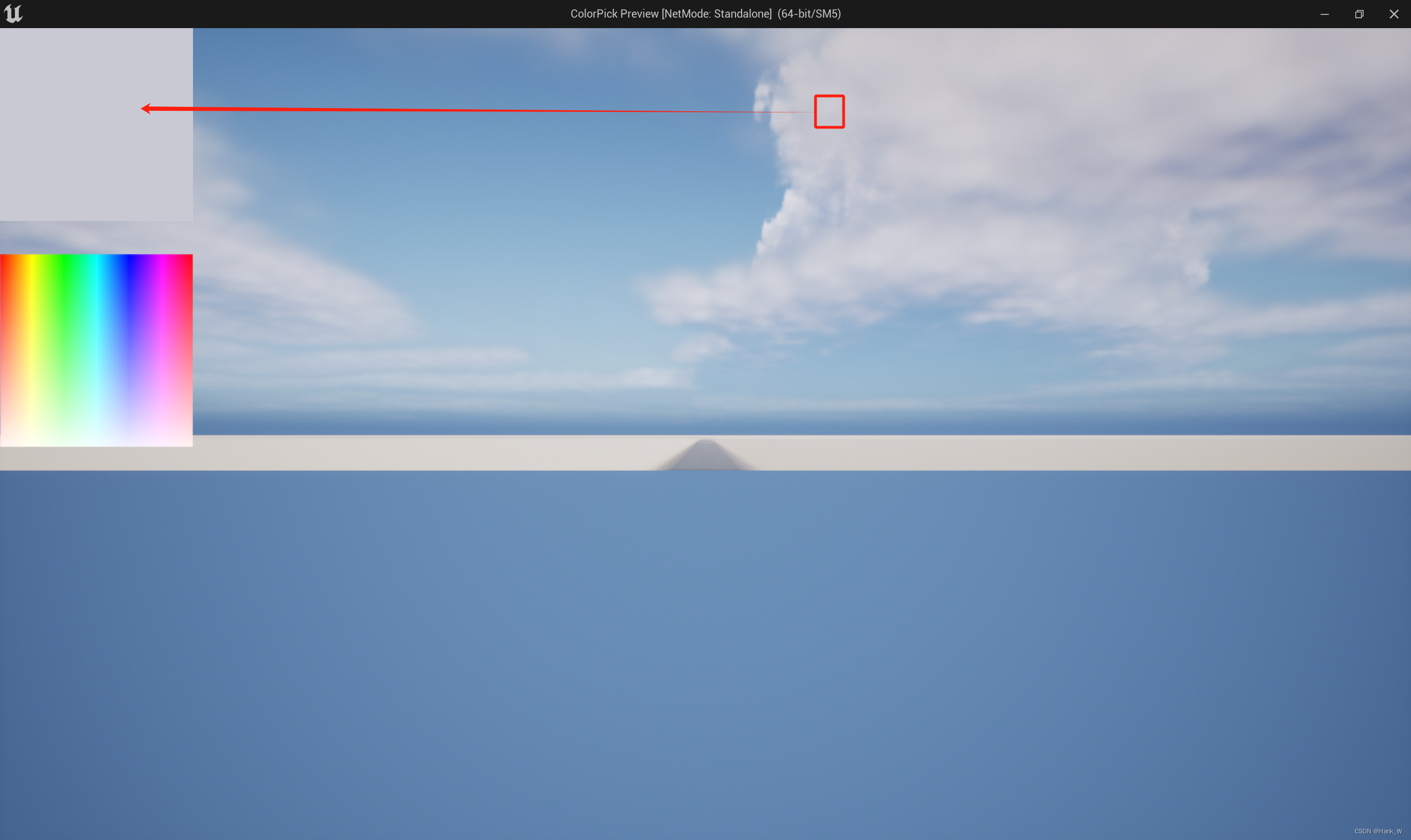
【UE】UEC++获取屏幕颜色GetPixelFromCursorPosition()
目录 【UE】UE C 获取屏幕颜色GetPixelFromCursorPosition() 一、函数声明与定义 二、函数的调用 三、运行结果 【UE】UE C 获取屏幕颜色GetPixelFromCursorPosition() 一、函数声明与定义 创建一个蓝图方法库方法 GetPixelFromCursorPosition(),并给他指定UF…...

数学建模-基于BL回归模型和决策树模型对早产危险因素的探究和预测
整体求解过程概述(摘要) 近年来,全球早产率总体呈上升趋势,在我国,早产儿以每年 20 万的数目逐年递增,目前早产已经成为重大的公共卫生问题之一。据研究,早产是威胁胎儿及新生儿健康的重要因素,可能会造成死亡或智力体…...

接口测试 —— 接口测试的意义
1、接口测试的意义(优势) (1)更早的发现问题: 不少的测试资料中强调,测试应该更早的介入到项目开发中,因为越早的发现bug,修复的成本越低。 然而功能测试必须要等到系统提供可测试…...

一些常见的爬虫库
一些常见的爬虫库,并按功能和用途进行分类: 通用爬虫库: Beautiful Soup:用于解析HTML和XML文档,方便地提取数据。Requests:用于HTTP请求,获取网页内容。Scrapy:一个强大的爬虫框架…...
2023.12.2 做一个后台管理网页(左侧边栏实现手风琴和隐藏/出现效果)
2023.12.2 做一个后台管理网页(左侧边栏实现手风琴和隐藏/出现效果) 网页源码见附件,比较简单,之前用很多种方法实现过该效果,这次的效果相对更好。 实现功能: (1)实现左侧边栏的手…...

【EMFace】《EMface: Detecting Hard Faces by Exploring Receptive Field Pyramids》
arXiv-2021 文章目录 1 Background and Motivation2 Related Work3 Advantages / Contributions4 Method5 Experiments5.1 Datasets and Metrics5.2 Ablation Study5.3 Comparison with State-of-the-Arts 6 Conclusion(own) 1 Background and Motivatio…...
)
详细学习Pyqt5的20种输入控件(Input Widgets)
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...
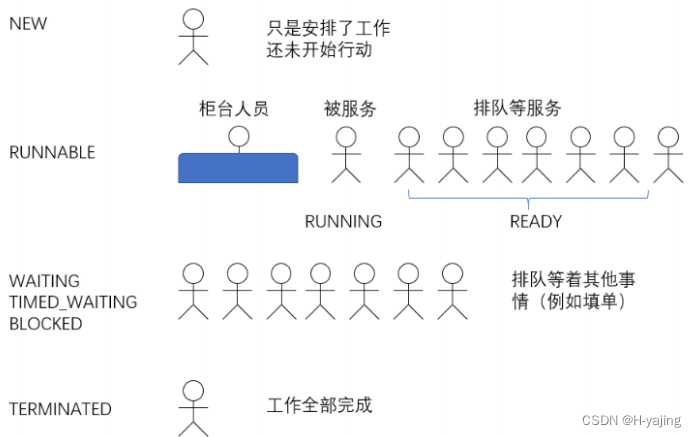
【JavaEE初阶】Thread 类及常见方法、线程的状态
目录 1、Thread 类及常见方法 1.1 Thread 的常见构造方法 1.2 Thread 的几个常见属性 1.3 启动⼀个线程 - start() 1.4 中断⼀个线程 1.5 等待⼀个线程 - join() 1.6 获取当前线程引用 1.7 休眠当前线程 2、线程的状态 2.1 观察线程的所有状态 2.2 线程状态和状…...
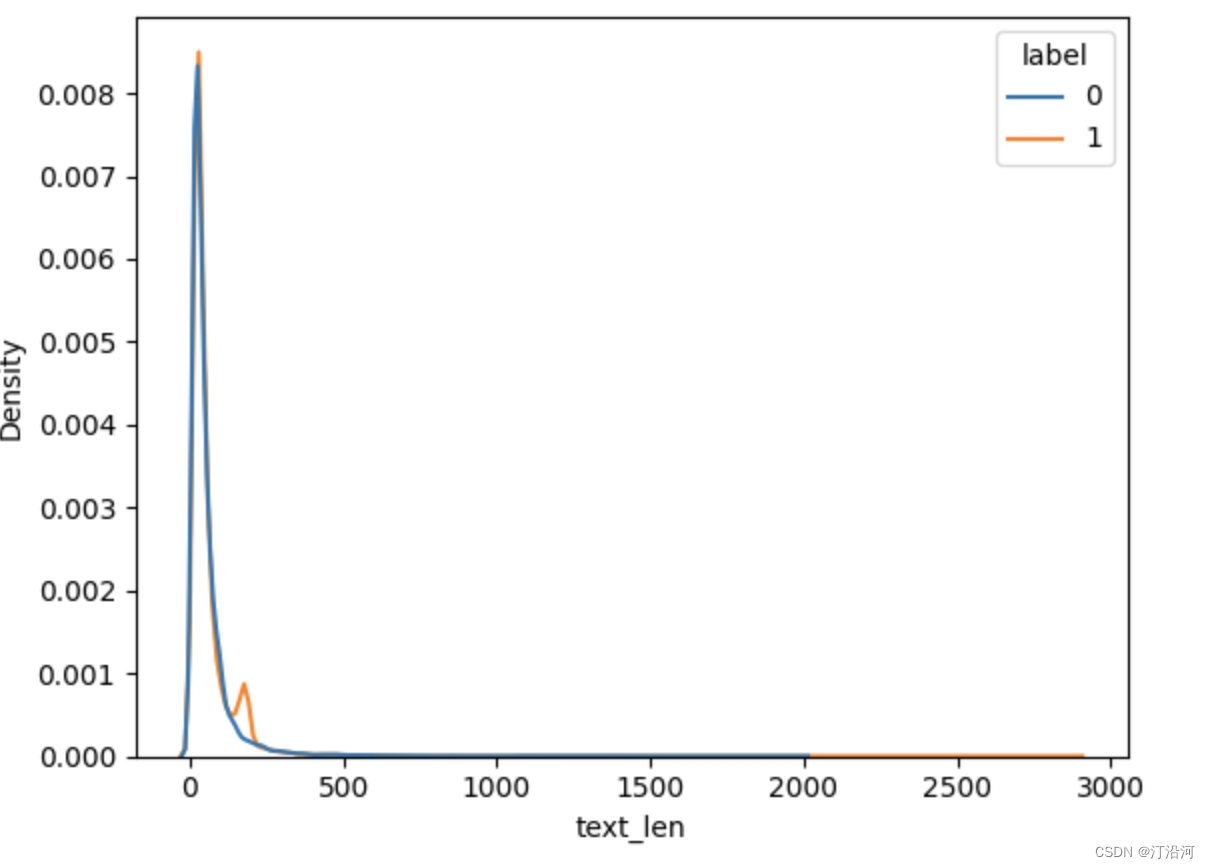
0 NLP: 数据获取与EDA
0数据准备与分析 二分类任务,正负样本共计6W; 数据集下载 https://github.com/SophonPlus/ChineseNlpCorpus/raw/master/datasets/online_shopping_10_cats/online_shopping_10_cats.zip 样本的分布 正负样本中评论字段的长度 ,超过500的都…...

159.库存管理(TOPk问题!)
思路:也是tok的问题,与上篇博客思路一样,只不过是求前k个小的元素! 基于快排分块思路的代码如下: class Solution { public:int getkey(vector<int>&nums,int left,int right){int rrand();return nums[r%…...
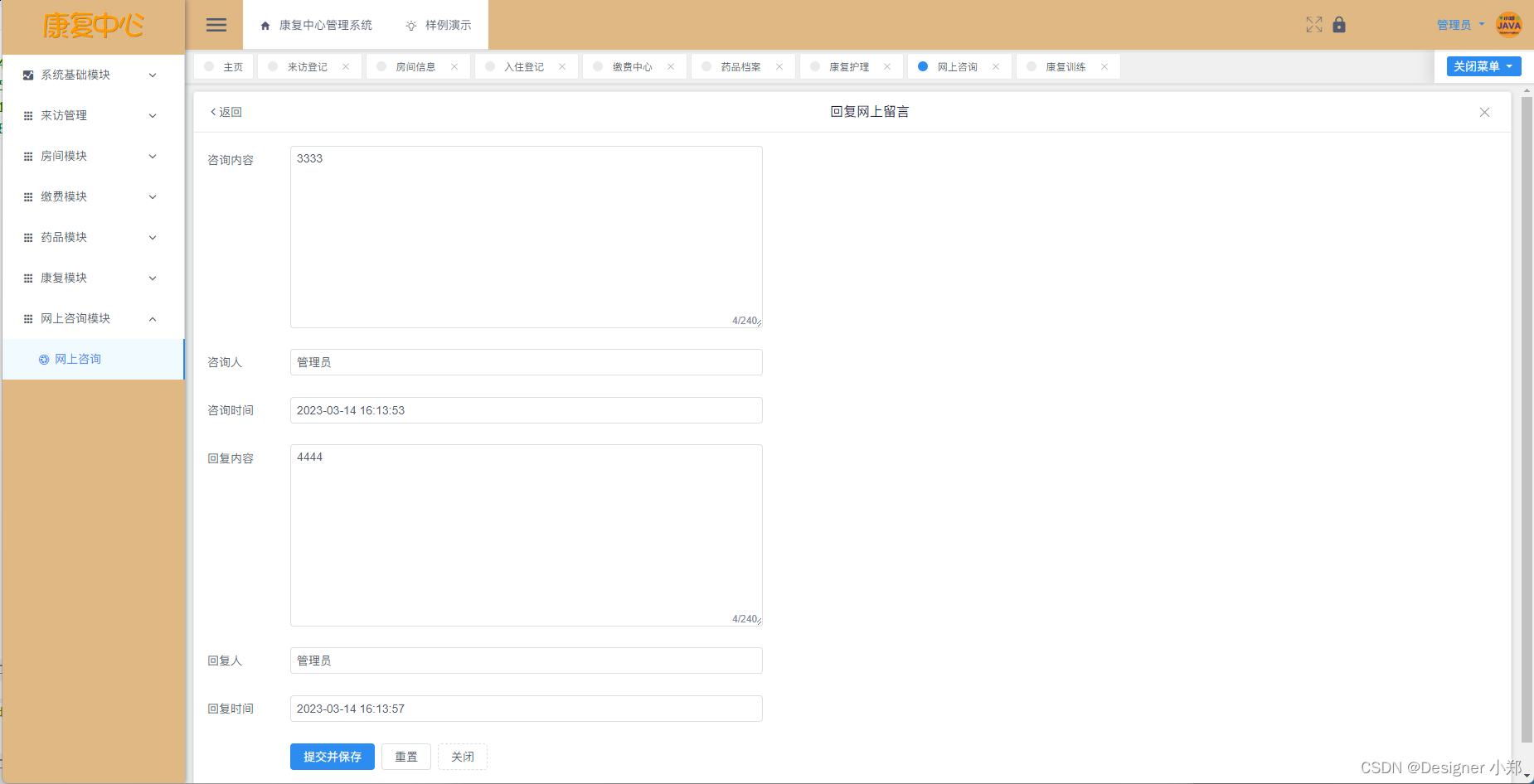
【开源】基于Vue+SpringBoot的康复中心管理系统
项目编号: S 056 ,文末获取源码。 \color{red}{项目编号:S056,文末获取源码。} 项目编号:S056,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 普通用户模块2.2 护工模块2.3 管理员…...

设计模式总览
一、设计模式 介绍 种一棵树最好的时间是十年前,其次是现在 《援助的死亡》-- 比萨莫约 The best time to plant a tree was 10 years ago。 The second best time is now。 《dead aid》-- Dambisa Moyo 1、创建型模式 1.1、单例模式 确保一个类最多只有一个实…...

数据链路层之VLAN基本概念和基本原理
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某技术知识点… 一个人摸索学习很难坚持,想组团高效学习… 想写博客但无从下手,急需…...
UVA11729 Commando War
UVA11729 Commando War 题面翻译 突击战 你有n个部下,每个部下需要完成一项任务。第i个部下需要你花Bj分钟交代任务,然后他就会立刻独立地、无间断地执行Ji分钟后完成任务。你需要选择交代任务的顺序,使得所有任务尽早执行完毕(…...

【数据库】数据库基于封锁机制的调度器,使冲突可串行化,保障事务和调度一致性
封锁使可串行化 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更…...
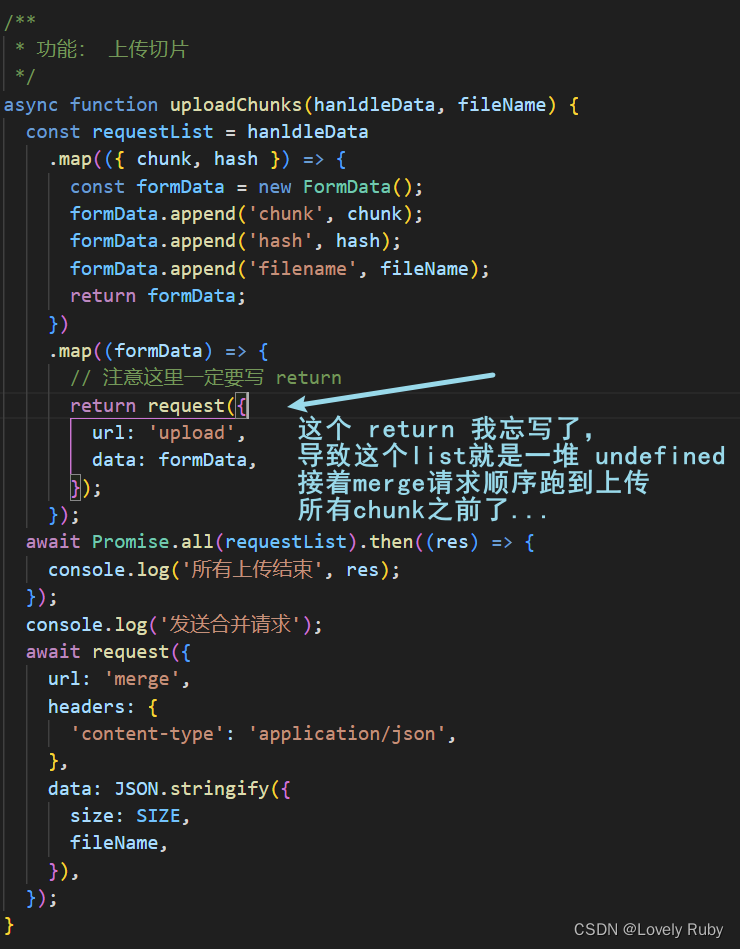
大文件分片上传、分片进度以及整体进度、断点续传(一)
大文件分片上传 效果展示 前端 思路 前端的思路:将大文件切分成多个小文件,然后并发给后端。 页面构建 先在页面上写几个组件用来获取文件。 <body><input type"file" id"file" /><button id"uploadButton…...

Pytest 的小例子
一个简单的例子 下面代码保存到test_pytest.py 一个简单的例子 def inc(x):return x 1def test_answer():assert inc(3) 5def test_ask():assert inc(4) 5 pytest 需要安装一下 pip install pytest (Venv) D:\pythonwork>pip install pytest Collecting pytestDown…...
:概率统计基础)
大数据(十一):概率统计基础
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…...

web前端之TypeScript
MENU typescript类型别名、限制值的大小typescript使用class关键字定义一个类、static、readonlytypescript中class的constructor(构造函数)typescript中abstractClass(抽象类)、extends、abstracttypescript中的接口、type、interfacetypescript封装属性、public、private、pr…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...

Cursor与Figma通过MCP协议实现AI辅助设计与开发同步
1. 项目概述:当代码编辑器与设计工具“开口说话”最近在开发者社区里,一个名为“cursor-talk-to-figma-mcp”的项目引起了我的注意。这个由开发者“hamadoun1760”开源的仓库,名字直译过来就是“Cursor与Figma对话的MCP”。乍一看,…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

MCP-Commander:让AI助手操作本地文件与命令行的智能接口
1. 项目概述:一个连接思维与执行的智能接口最近在折腾AI工作流的时候,发现了一个挺有意思的项目,叫nmindz/mcp-commander。乍一看这个名字,可能有点摸不着头脑,但如果你正在尝试让大型语言模型(LLM…...

基于强化学习的机器人抓取:从PPO/SAC算法到仿真部署全解析
1. 项目概述:一个基于强化学习的机器人抓取开源项目最近在机器人控制领域,强化学习(Reinforcement Learning, RL)的应用越来越火,尤其是在需要高精度、高适应性的任务上,比如机器人抓取。传统的抓取规划方法…...

Agent 的记忆也会被投毒:长期记忆安全的六阶段框架
过去,我们更习惯把大模型的风险理解为“这一轮输入有没有问题”“这一轮输出会不会越界”。但有了长期记忆之后,风险结构发生了变化。恶意内容不一定在当场触发,也不一定在同一轮任务里显现出来。它可以先悄悄进入记忆,在几天后、…...

基于CircuitPython与MCP9808的智能恒温控制器DIY指南
1. 项目概述作为一个常年鼓捣嵌入式系统和家庭自动化项目的爱好者,我一直在寻找那些能将技术融入日常生活的有趣点子。几年前开始在家酿造康普茶,立刻就遇到了一个经典难题:发酵温度控制。康普茶这种活菌饮料,其风味和健康度极度依…...

基于CircuitPython的巨型机械键盘:从嵌入式开发到定制输入设备实践
1. 项目概述:当机械键盘遇上“巨无霸”如果你和我一样,对机械键盘那清脆的段落感和扎实的敲击感着迷,同时又是个喜欢动手折腾的硬件爱好者,那么这个项目绝对能让你眼前一亮。我们这次要做的,不是常规的60%或87键键盘&a…...

手工打造柔性LED眼罩:从SMD焊接入门到可穿戴电路实践
1. 项目概述:从零打造你的赛博格之眼如果你和我一样,对《银翼杀手》里那些闪烁着冷光的义眼,或是赛博朋克美学中标志性的发光装饰着迷,那么亲手制作一个属于自己的LED眼罩,绝对是一次令人兴奋的旅程。这不仅仅是一个酷…...