【PyTorch】softmax回归
文章目录
- 1.理论介绍
- 2. 代码实现
- 2.1. 主要代码
- 2.2. 完整代码
- 2.3. 输出结果
- 3. Q&A
- 3.1. 运行过程中出现以下警告:
- 3.2. 定义的神经网络中的nn.Flatten()的作用是什么?
- 3.3. num_workers有什么作用?它的值怎么确定?
1.理论介绍
- 背景
在分类问题中,模型的输出层是全连接层,每个类别对应一个输出。我们希望模型的输出 y ^ j \hat{y}_j y^j可以视为属于类 j j j的概率,然后选择具有最大输出值的类别作为我们的预测。
softmax函数能够将未规范化的输出变换为非负数并且总和为1,同时让模型保持可导的性质,而且不会改变未规范化的输出之间的大小次序。 - softmax函数
y ^ = s o f t m a x ( o ) \mathbf{\hat{y}}=\mathrm{softmax}(\mathbf{o}) y^=softmax(o)其中 y ^ j = e x p ( o j ) ∑ k e x p ( o k ) \hat{y}_j=\frac{\mathrm{exp}({o_j})}{\sum_{k}\mathrm{exp}({o_k})} y^j=∑kexp(ok)exp(oj) - softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定,因此,softmax回归是一个线性模型。
- 为了避免将softmax的输出直接送入交叉熵损失造成的数值稳定性问题,需要将softmax和交叉熵损失结合在一起,具体做法是:不将softmax概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的输出,并同时计算softmax及其对数。因此定义交叉熵损失函数时也进行了softmax运算。
2. 代码实现
2.1. 主要代码
criterion = nn.CrossEntropyLoss(reduction='none')
2.2. 完整代码
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from tensorboardX import SummaryWriterdef load_dataset(batch_size, num_workers):"""加载数据集"""root = "./dataset"transform = transforms.Compose([transforms.ToTensor()])mnist_train = FashionMNIST(root=root, train=True, transform=transform, download=True)mnist_test = FashionMNIST(root=root, train=False, transform=transform, download=True)dataloader_train = DataLoader(mnist_train, batch_size, shuffle=True, num_workers=num_workers)dataloader_test = DataLoader(mnist_test, batch_size, shuffle=False,num_workers=num_workers)return dataloader_train, dataloader_testdef init_network(net):"""初始化模型参数"""def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.constant_(m.bias, val=0)if isinstance(net, nn.Module):net.apply(init_weights)class Accumulator:"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]def accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())def train(net, dataloader_train, criterion, optimizer, device):"""训练模型"""if isinstance(net, nn.Module):net.train()train_metrics = Accumulator(3) # 训练损失总和、训练准确度总和、样本数for X, y in dataloader_train:X, y = X.to(device), y.to(device)y_hat = net(X)loss = criterion(y_hat, y)optimizer.zero_grad()loss.mean().backward()optimizer.step()train_metrics.add(float(loss.sum()), accuracy(y_hat, y), y.numel())train_loss = train_metrics[0] / train_metrics[2]train_acc = train_metrics[1] / train_metrics[2]return train_loss, train_accdef test(net, dataloader_test, device):"""测试模型"""if isinstance(net, nn.Module):net.eval()with torch.no_grad(): test_metrics = Accumulator(2) # 测试准确度总和、样本数for X, y in dataloader_test:X, y = X.to(device), y.to(device)y_hat = net(X)test_metrics.add(accuracy(y_hat, y), y.numel())test_acc = test_metrics[0] / test_metrics[1]return test_accif __name__ == "__main__":# 全局参数设置batch_size = 256num_workers = 3num_epochs = 20learning_rate = 0.1device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 创建记录器writer = SummaryWriter()# 加载数据集dataloader_train, dataloader_test = load_dataset(batch_size, num_workers)# 定义神经网络net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)).to(device)# 初始化神经网络init_network(net)# 定义损失函数criterion = nn.CrossEntropyLoss(reduction='none')# 定义优化器optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate)for epoch in range(num_epochs):train_loss, train_acc = train(net, dataloader_train, criterion, optimizer, device)test_acc = test(net, dataloader_test, device)writer.add_scalars("metrics", {'train_loss': train_loss, 'train_acc': train_acc, 'test_acc': test_acc}, epoch)writer.close()
2.3. 输出结果
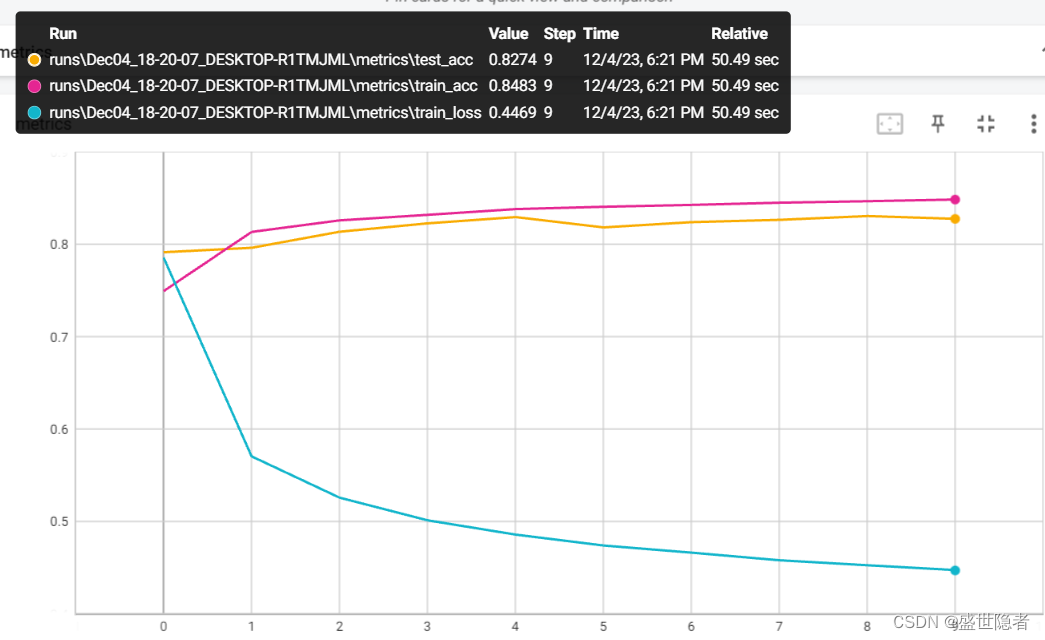
3. Q&A
3.1. 运行过程中出现以下警告:
UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at …\torch\csrc\utils\tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
该警告的大致意思是给定的NumPy数组不可写,并且PyTorch不支持不可写的张量。这意味着你可以使用张量写入底层(假定不可写)NumPy数组。在将数组转换为张量之前,可能需要复制数组以保护其数据或使其可写。在本程序的其余部分,此类警告将被抑制。因此需要修改C:\Users\%UserName%\anaconda3\envs\%conda_env_name%\lib\site-packages\torchvision\datasets\mnist.py的第498行,将return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)中的False改成True。
3.2. 定义的神经网络中的nn.Flatten()的作用是什么?
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)).to(device)
nn.Flatten()的作用是将图像数据张量展成一维,方便输入后续的全连接层。
3.3. num_workers有什么作用?它的值怎么确定?
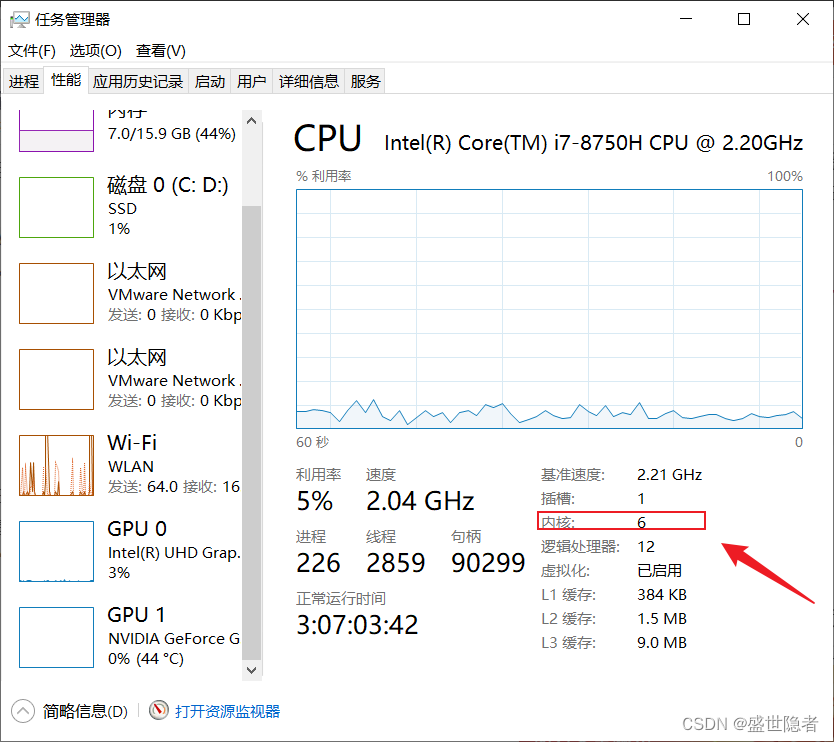
num_workers表示加载batch数据的进程数,num_workers=0时只有主进程去加载batch数据。要实现多进程加载数据,加载函数一定要位于if __name__ == "__main__"下。一般开始是将num_workers设置为等于计算机上的CPU内核数量,在此基础上,尝试减少num_workers的值,选择训练速度高时的值。查看CPU内核数量的方法:“任务管理器 > 性能 > CPU”。
相关文章:
【PyTorch】softmax回归
文章目录 1.理论介绍2. 代码实现2.1. 主要代码2.2. 完整代码2.3. 输出结果 3. Q&A3.1. 运行过程中出现以下警告:3.2. 定义的神经网络中的nn.Flatten()的作用是什么?3.3. num_workers有什么作用?它的值怎么确定? 1.理论介绍 背…...
12.8 作业 C++
使用手动连接,将登录框中的取消按钮使用qt4版本的连接到自定义的槽函数中,在自定义的槽函数中调用关闭函数 将登录按钮使用qt5版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin",密码是否为…...

10.机器人系统仿真(urdf集成gazebo、rviz)
目录 1 机器人系统仿真的必要性与本篇学习目的 1.1 机器人系统仿真的必要性 1.2 一些概念 URDF是 Unified Robot Description Format 的首字母缩写,直译为统一(标准化)机器人描述格式,可以以一种 XML 的方式描述机器人的部分结构,比如底盘…...

城市基础设施智慧路灯改造的特点
智慧城市建设稳步有序推进。作为智慧城市的基础设施,智能照明是智慧城市的重要组成部分,而叁仟智慧路灯是智慧城市理念下的新产品。随着物联网和智能控制技术的飞速发展,路灯被赋予了新的任务和角色。除了使道路照明智能化和节能化外…...
配置BFD多跳检测示例
BFD简介 定义 双向转发检测BFD(Bidirectional Forwarding Detection)是一种全网统一的检测机制,用于快速检测、监控网络中链路或者IP路由的转发连通状况。 目的 为了减小设备故障对业务的影响,提高网络的可靠性,网…...
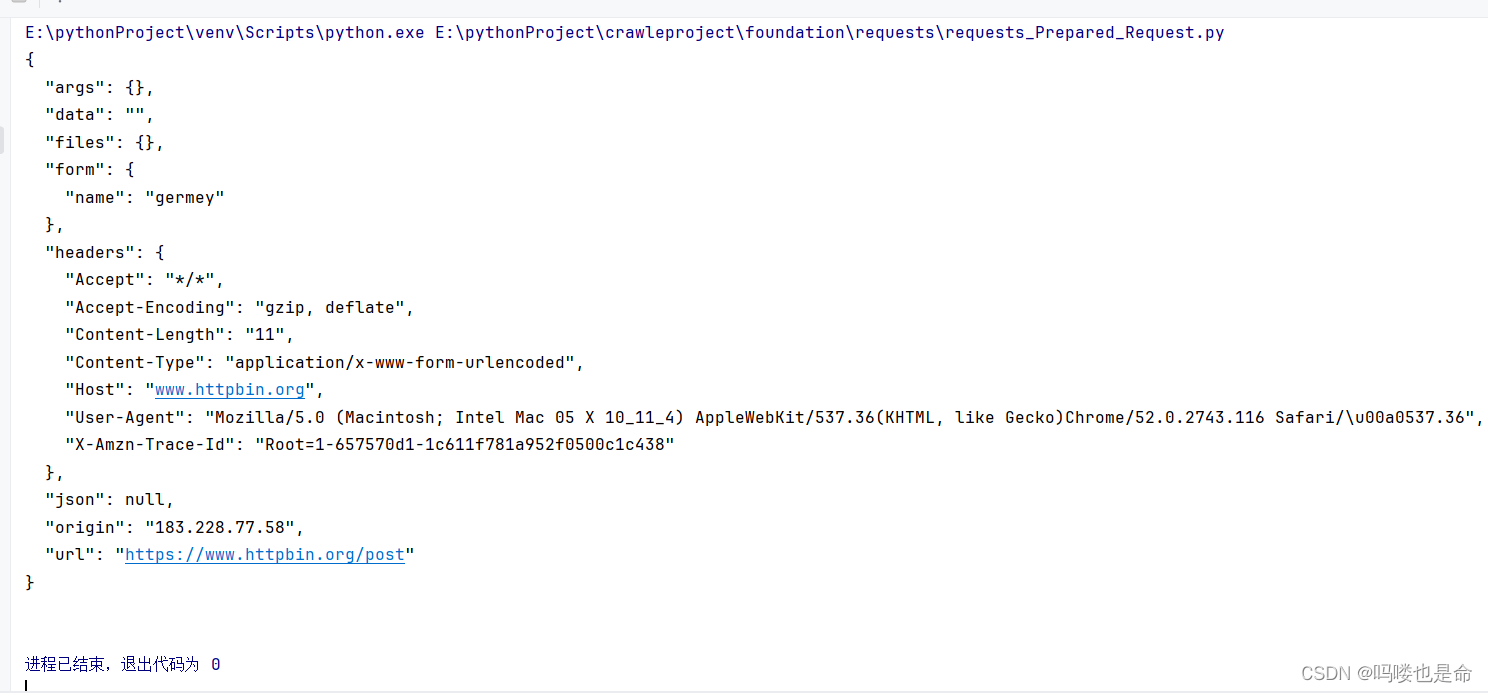
爬虫学习-基础库的使用(requests)
目录 一、安装以及实例引入 (1)requests库下载 (2)实例测试 二、GET请求 (1)基本实例 (2)抓取网页 (3)抓取二进制数据 (4)添…...
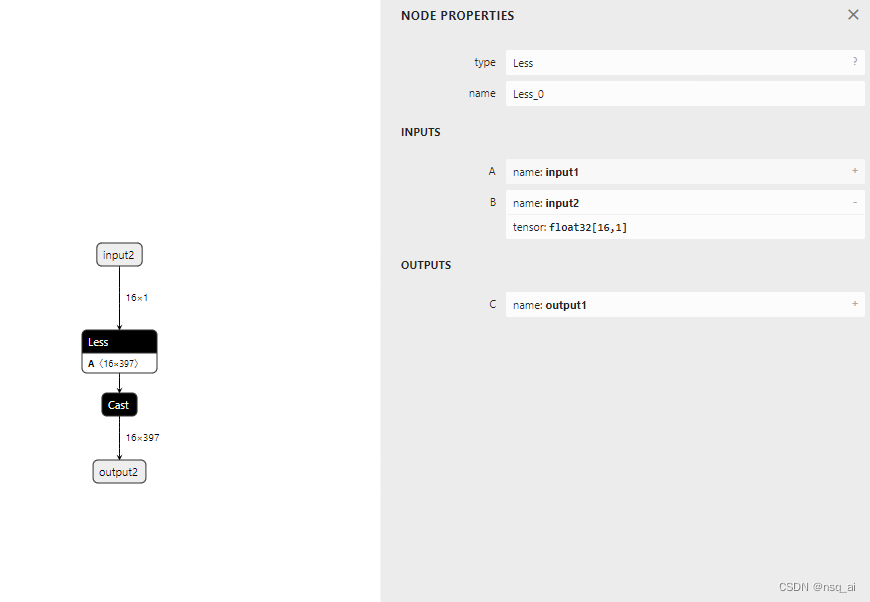
4.8 构建onnx结构模型-Less
前言 构建onnx方式通常有两种: 1、通过代码转换成onnx结构,比如pytorch —> onnx 2、通过onnx 自定义结点,图,生成onnx结构 本文主要是简单学习和使用两种不同onnx结构, 下面以 Less 结点进行分析 方式 方法一&a…...

Java调试技巧之垃圾回收机制解析
Java作为一种高级编程语言,以其跨平台、面向对象、自动内存管理等特性而广受开发者的喜爱。其中,自动内存管理是Java的一大亮点,通过垃圾回收机制实现对内存的自动分配和释放,极大地简化了开发者的工作。本文将深入探讨Java的垃圾…...
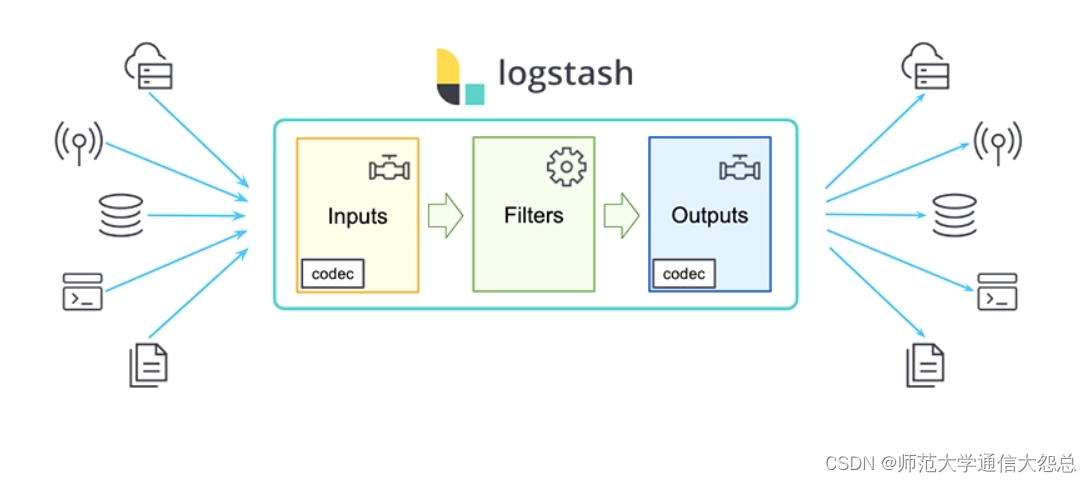
logstash插件简单介绍
logstash插件 输入插件(input) Input:输入插件。 Input plugins | Logstash Reference [8.11] | Elastic 所有输入插件都支持的配置选项 SettingInput typeRequiredDefaultDescriptionadd_fieldhashNo{}添加一个字段到一个事件codeccodecNoplain用于输入数据的…...
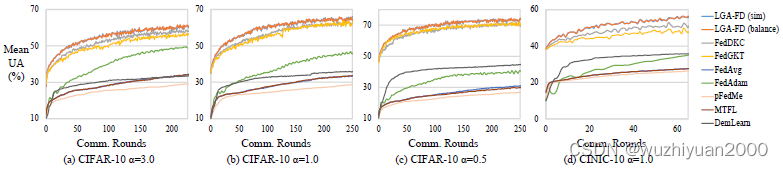
联邦多任务蒸馏助力多接入边缘计算下的个性化服务 | TPDS 2023
联邦多任务蒸馏助力多接入边缘计算下的个性化服务 | TPDS 2023 随着移动智能设备的普及和人工智能技术的发展,越来越多的分布式数据在终端被产生与收集,并以多接入边缘计算(MEC)的形式进行处理和分析。但是由于用户的行为模式与服务需求的多样,不同设备上的数据分布…...

【python爬虫】设计自己的爬虫 3. 文件数据保存封装
考虑到爬取的多媒体文件要保存到本地,因此封装了一个类来专门处理这样的问题,下面看代码: class FileStore:def __init__(self, file_path, read_file_moder,write_file_modewb):"""初始化 FileStore 实例Parameters:- file_…...
pta模拟题——7-34 刮刮彩票
“刮刮彩票”是一款网络游戏里面的一个小游戏。如图所示: 每次游戏玩家会拿到一张彩票,上面会有 9 个数字,分别为数字 1 到数字 9,数字各不重复,并以 33 的“九宫格”形式排布在彩票上。 在游戏开始时能看见一个位置上…...

【补题】 1
蓝桥杯小白赛 3.小蓝的金牌梦【算法赛】 - 蓝桥云课 (lanqiao.cn) 数组长度为质数,最大的子数组和 素数 前缀和 #include "bits/stdc.h" using namespace std; #define int long long #define N 100010 int ans[N];int s[N];vector&l…...

IP地址定位技术为网络安全建设提供全新方案
随着互联网的普及和数字化进程的加速,网络安全问题日益引人关注。网络攻击、数据泄露、欺诈行为等安全威胁层出不穷,对个人隐私、企业机密和社会稳定构成严重威胁。在这样的背景下,IP地址定位技术应运而生,为网络安全建设提供了一…...
Redis中HyperLogLog的使用
目录 前言 HyperLogLog 前言 在学习HyperLogLog之前,我们需要先学习两个概念 UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。PV&am…...

新版Spring Security6.2架构 (一)
Spring Security 新版springboot 3.2已经集成Spring Security 6.2,和以前会有一些变化,本文主要针对官网的文档进行一些个人翻译和个人理解,不对地方请指正。 整体架构 Spring Security的Servlet 支持是基于Servelet过滤器,如下…...

名字的漂亮度
给出一个字符串,该字符串仅由小写字母组成,定义这个字符串的“漂亮度”是其所有字母“漂亮度”的总和。 每个字母都有一个“漂亮度”,范围在1到26之间。没有任何两个不同字母拥有相同的“漂亮度”。字母忽略大小写。给出多个字符串࿰…...

机器学习基本概念2
资料来源: https://www.youtube.com/watch?vYe018rCVvOo&listPLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index1 https://www.youtube.com/watch?vbHcJCp2Fyxs&listPLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index2 分三步 1、 定义function b和w是需要透…...
—— Spring Cloud Alibaba 之 Nacos 2.3.0 史上最大更新版本发布)
Spring Cloud 与微服务学习总结(19)—— Spring Cloud Alibaba 之 Nacos 2.3.0 史上最大更新版本发布
Nacos 一个用于构建云原生应用的动态服务发现、配置管理和服务管理平台,由阿里巴巴开源,致力于发现、配置和管理微服务。说白了,Nacos 就是充当微服务中的的注册中心和配置中心。 Nacos 2.3.0 新特性 1. 反脆弱插件 Nacos 2.2.0 版本开始加入反脆弱插件,从 2.3.0 版本开…...

八、C#笔记
/// <summary> /// 第十三章:创建接口和定义抽象类 /// </summary> namespace Chapter13 { class Program { static void Main(string[] args) { //13.1理解接口 ///13.1.1定义接口 ///…...

OpCore Simplify:一键生成OpenCore EFI的终极解决方案
OpCore Simplify:一键生成OpenCore EFI的终极解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置的复杂流程头疼吗&…...

体验 Taotoken 官方价折扣与活动价带来的实际成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验 Taotoken 官方价折扣与活动价带来的实际成本优势 对于需要频繁调用大模型 API 的开发者和团队而言,成本控制是一个…...

面部美化 API 集成指南
面部美化 API 集成指南 在本教程中,我们将介绍如何集成面部美化 API。该 API 能够准确识别面部特征,并通过用户上传的面部图像实现皮肤平滑、皮肤美白和去痘等美化功能(每张图像最多可处理五张面孔)。 环境准备 在使用 API 之前…...

内网离线部署RPA:打包EXE+本地激活+数据零上云方案
领导给了一周,我前三天全耗在这个报错上:无法连接到 activation.xxx.com 请检查网络连接后重试2024年5月,我用的蓝印RPA物理隔离内网部,处理核心业务数据,要求"数据不出本机,流程不外传,审…...

Microsoft Defender双零日在野利用全解析:从BlueHammer到RedSun的终端沦陷之路
前言 2026年5月20日,微软安全响应中心(MSRC)发布紧急安全公告,承认旗下Microsoft Defender存在两个已被野外利用超过一个月的零日漏洞——CVE-2026-41091与CVE-2026-45498。同日,美国国土安全部下属的网络安全与基础设施安全局(CISA)将这两个…...
 )
Navicat Premium16 免费安装配置教程(附安装包)
一、下载安装包 官网下载:https://www.navicat.com.cn/products#navicat 可直接网盘下载 链接:https://pan.baidu.com/s/1t3Tx0c8gEaMEifGow_05aQ?pwd8888 二、安装过程 1. 双击安装包 2. 选中“我同意”,点击“下一步”。 3.…...

AI科技日报-2026年5月22日
AI科技日报 日期:2026年5月22日人工智能正在从“会生成”向“会规划、会行动”进化,2026年成为全球AI发展的关键之年。以下为今日重要资讯。 一、大模型竞赛持续升级 OpenAI、谷歌、深度求索等顶尖AI企业正在发布规模更大或效率更高的最新版本大模型。斯…...

COMET:基于深度学习的机器翻译质量评估框架
COMET:基于深度学习的机器翻译质量评估框架 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET 在机器翻译技术日益成熟的今天,如何客观、准确、可解释地评估翻译质量成为了学术…...

渗透测试小白上手指南:系统化故障排查能力迁移手册
1. 别被“渗透测试”四个字吓住:它本质是系统化的故障排查能力很多人第一次听说“渗透测试”,脑子里立刻浮现出黑客电影里飞速滚动的代码、黑底绿字的终端、几秒钟攻破银行防火墙的炫酷场面。结果一搜学习资料,满屏都是“Kali Linux”“Metas…...

ABAP系统实现OAuth 2.0最小权限控制的原生方案
1. 这不是一次“配个Token就完事”的集成——为什么ABAP系统里OAuth 2.0落地总卡在“权限过宽”这道坎上你有没有遇到过这样的场景:前端调用SAP Fiori应用,后端ABAP系统需要校验用户身份和操作权限;团队决定上OAuth 2.0,理由很充分…...