ELK简单介绍二
学习目标
- 能够部署kibana并连接elasticsearch集群
- 能够通过kibana查看elasticsearch索引信息
- 知道用filebeat收集日志相对于logstash的优点
- 能够安装filebeat
- 能够使用filebeat收集日志并传输给logstash
kibana
kibana介绍
Kibana是一个开源的可视化平台,可以为ElasticSearch集群的管理提供友好的Web界面,帮助汇总,分析和搜索重要的日志数据。
文档路径: Set up | Kibana Guide [8.11] | Elastic
kibana部署
第1步: 在kibana服务器(我这里是VM1)上安装kibana
[root@vm1 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.5.2-x86_64.rpm [root@vm1 ~]# rpm -ivh kibana-6.5.2-x86_64.rpm
第2步: 配置kibana
[root@vm1 ~]# cat /etc/kibana/kibana.yml |grep -v '#' |grep -v '^$' server.port: 5601 端口 server.host: "0.0.0.0" 监听所有,允许所有人能访问 elasticsearch.url: "http://10.1.1.12:9200" ES集群的路径 logging.dest: /var/log/kibana.log 我这里加了kibana日志,方便排错与调试 日志要自己建立,并修改owner和group属性 [root@vm1 ~]# touch /var/log/kibana.log [root@vm1 ~]# chown kibana.kibana /var/log/kibana.log
第3步: 启动kibana服务
[root@vm1 ~]# systemctl start kibana [root@vm1 ~]# systemctl enable kibana [root@vm1 ~]# lsof -i:5601 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME node 10420 kibana 11u IPv4 111974 0t0 TCP *:esmagent (LISTEN)
第4步: 通过浏览器访问 http://kibana服务器IP:5601
kibana汉化
https://github.com/anbai-inc/Kibana_Hanization/
[root@vm1 ~]# wget https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip [root@vm1 ~]# unzip Kibana_Hanization-master.zip -d /usr/local [root@vm1 ~]# cd /usr/local/Kibana_Hanization-master/ 这里要注意:1,要安装python; 2,rpm版的kibana安装目录为/usr/share/kibana/ [root@vm1 Kibana_Hanization-master]# python main.py /usr/share/kibana/ 汉化完后需要重启 [root@vm1 Kibana_Hanization-master]# systemctl stop kibana [root@vm1 Kibana_Hanization-master]# systemctl start kibana
再次通过浏览器访问 http://kibana服务器IP:5601
通过kibana查看集群信息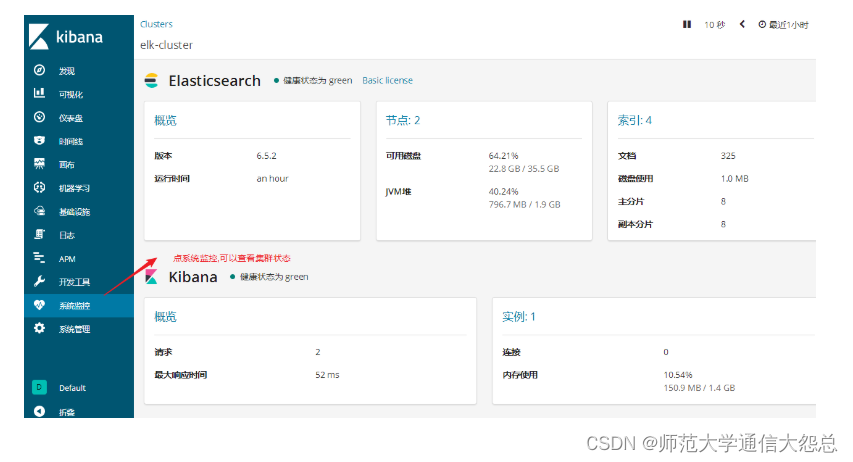
通过kibana查看logstash收集的日志索引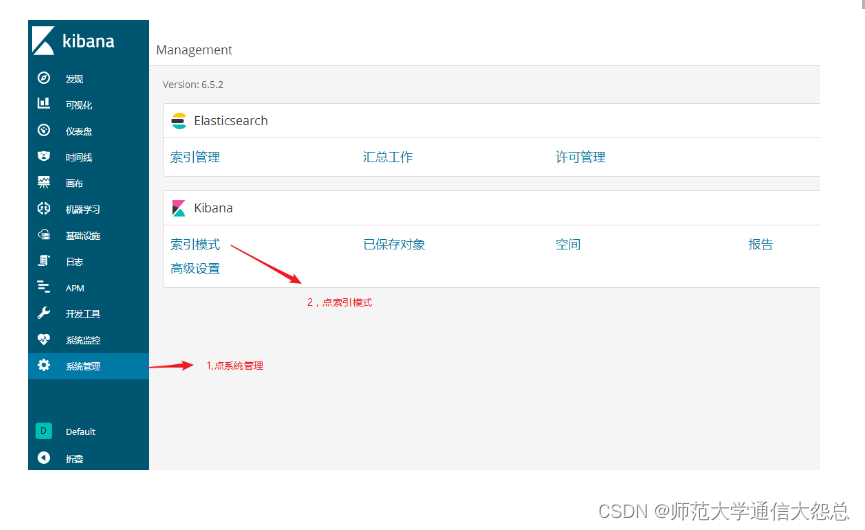

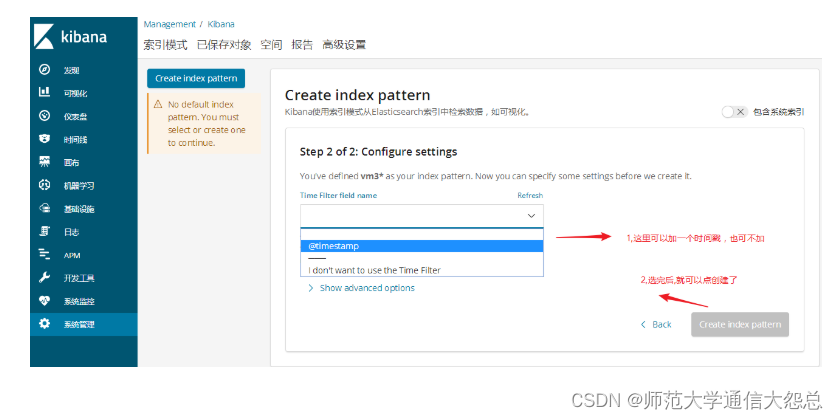
最后点发现查看
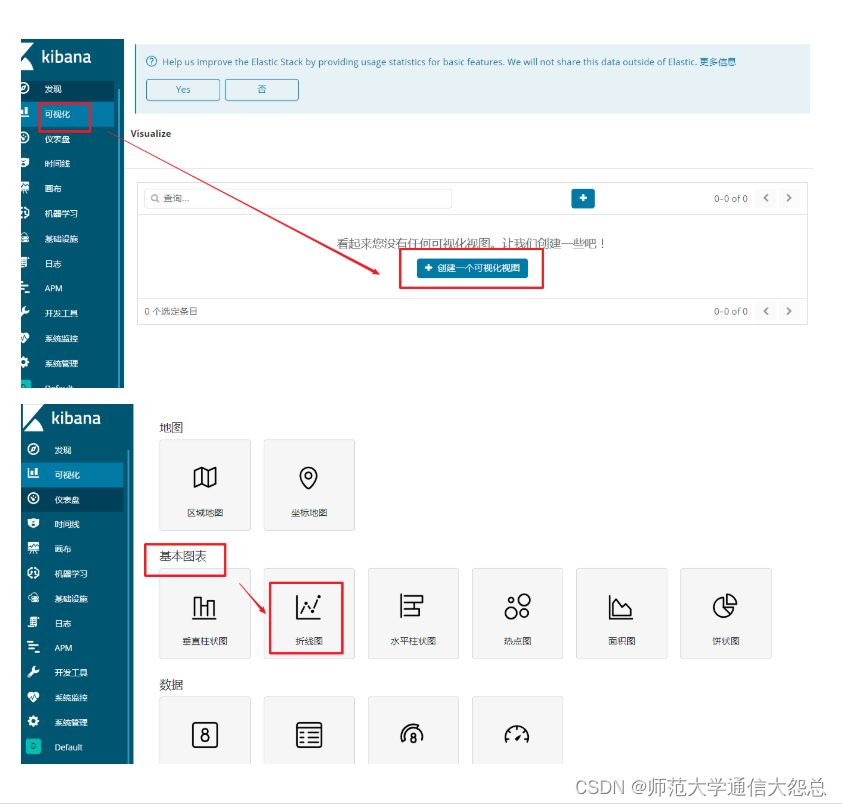
通过kibana做可视化图形



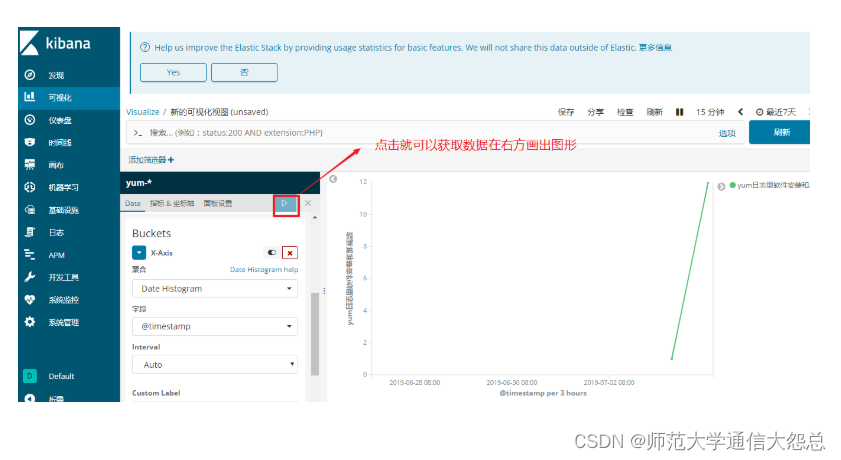
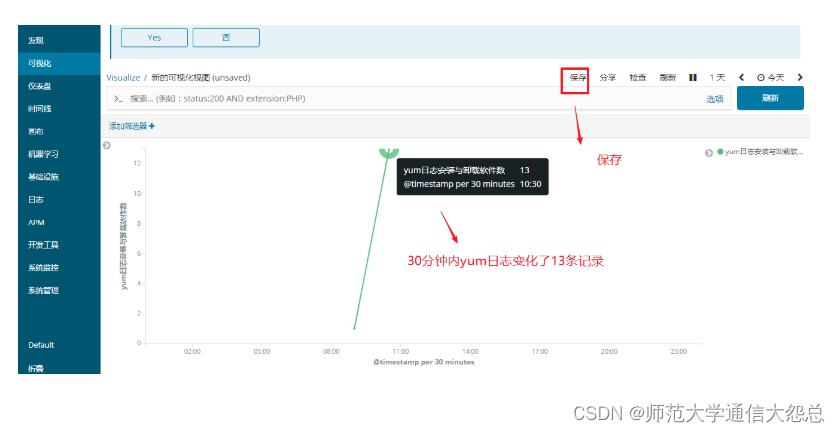
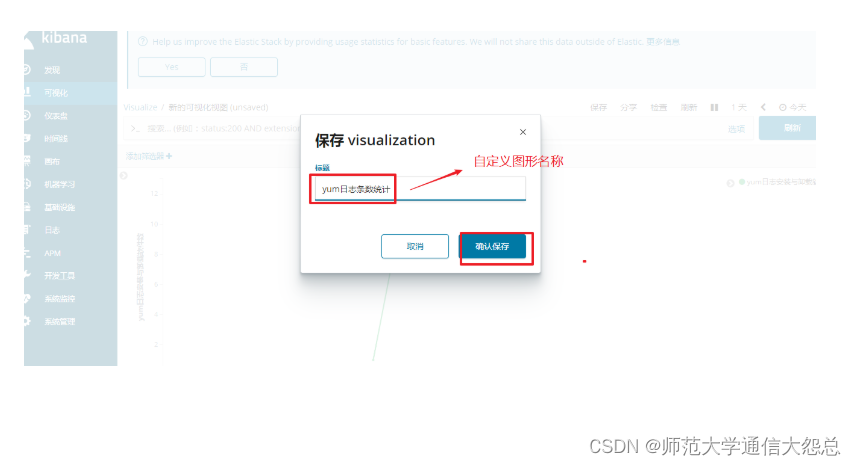
filebeat
因为logstash消耗内存等资源太高,如果在要采集的服务上都安装logstash,这样对应用服务器的压力增加。所以我们要用轻量级的采集工具才更高效,更省资源。
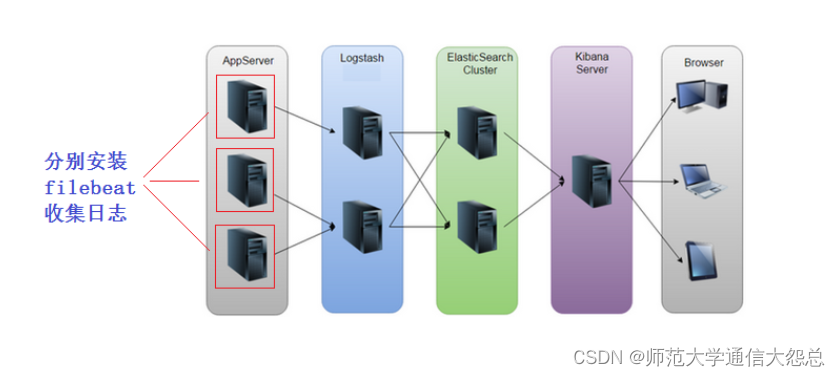
beats是轻量级的日志收集处理工具,Beats占用资源少
-
Packetbeat: 网络数据(收集网络流量数据)
-
Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
-
Filebeat: 文件(收集日志文件数据)
-
Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
-
Auditbeat:审计数据 (收集审计日志)
-
Heartbeat:运行时间监控 (收集系统运行时的数据)
我们这里主要是收集日志信息, 所以只讨论filebeat。
filebeat可以直接将采集的日志数据传输给ES集群(EFK), 也可以给logstash(==5044==端口接收)。
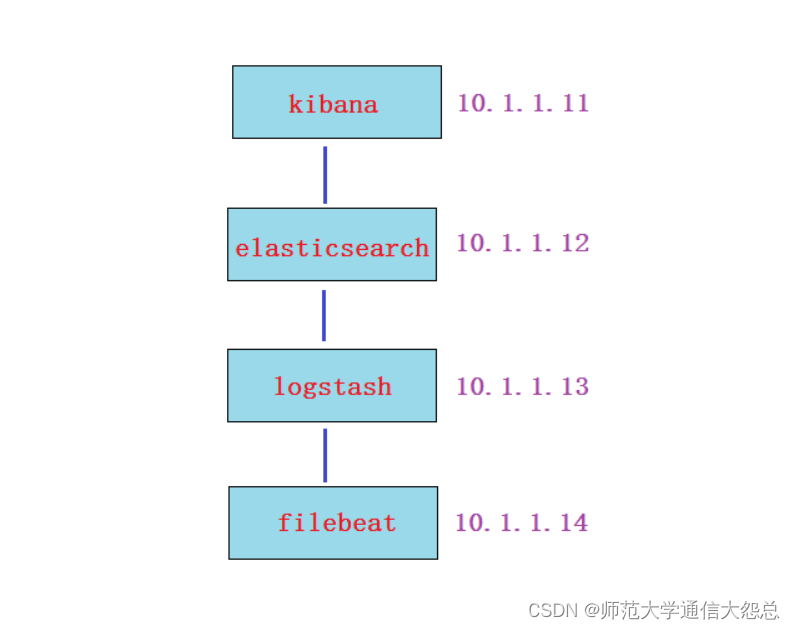
filebeat收集日志直接传输给ES集群
第1步: 下载并安装filebeat(再开一台虚拟机vm4模拟filebeat, 内存1G就够了, 安装filebeat)
[root@vm4 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.2-x86_64.rpm [root@vm4 ~]# rpm -ivh filebeat-6.5.2-x86_64.rpm
第2步: 配置filebeat收集日志
[root@vm4 ~]# cat /etc/filebeat/filebeat.yml |grep -v '#' |grep -v '^$'
filebeat.inputs:
- type: logenabled: true 改为truepaths:- /var/log/*.log 收集的日志路径
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 3
setup.kibana:
output.elasticsearch: 输出给es集群hosts: ["10.1.1.12:9200"] es集群节点ip
processors:- add_host_metadata: ~- add_cloud_metadata: ~
第3步: 启动服务
[root@vm4 ~]# systemctl start filebeat [root@vm4 ~]# systemctl enable filebeat
第4步: 验证
在es-head和kibana上验证(验证过程省略, 参考前面的笔记)
练习:可以尝试使用两台filebeat收集日志,然后在kibana用筛选器进行筛选过滤查看。(可先把logstash那台关闭logstash进行安装filebeat测试)
filebeat传输给logstash
第1步: 在logstash上要重新配置,开放5044端口给filebeat连接,并重启logstash服务
[root@vm3 ~]# vim /etc/logstash/conf.d/test.conf
input {beats {port => 5044}
}
output {elasticsearch {hosts => ["10.1.1.12:9200"]index => "filebeat2-%{+YYYY.MM.dd}"}stdout { 再加一个标准输出到屏幕,方便实验环境调试}
}
[root@vm3 ~]# cd /usr/share/logstash/bin/
如果前面有使用后台跑过logstash实例的请kill掉先
[root@vm3 bin]# pkill java
[root@vm3 bin]# ./logstash --path.settings /etc/logstash/ -r -f /etc/logstash/conf.d/test.conf
第2步: 配置filebeat收集日志
[root@vm4 ~]# cat /etc/filebeat/filebeat.yml |grep -v '#' |grep -v '^$'
filebeat.inputs:
- type: logenabled: true 改为truepaths:- /var/log/*.log 收集的日志路径
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 3
setup.kibana:
output.logstash: 这两句非常重要,表示日志输出给logstashhosts: ["10.1.1.13:5044"] IP为logstash服务器的IP;端口5044对应logstash上的配置
processors:- add_host_metadata: ~- add_cloud_metadata: ~
第3步: 启动服务
[root@vm4 ~]# systemctl stop filebeat [root@vm4 ~]# systemctl start filebeat
第5步: 去ES-head上验证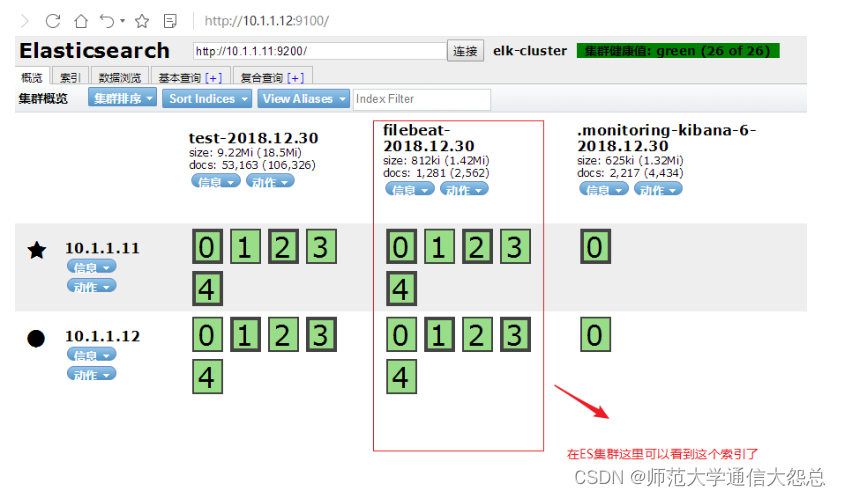
第6步:在kibana创建索引模式(过程省略,参考上面的笔记操作),然后点发现验证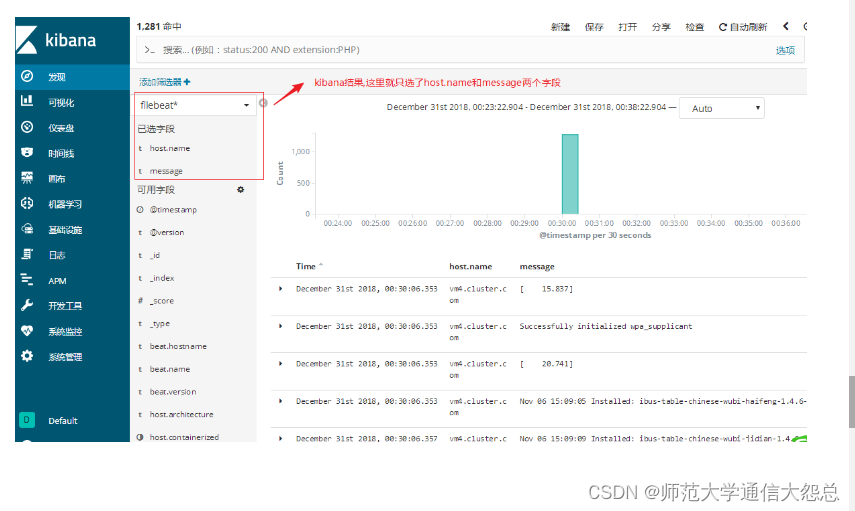
filebeat收集nginx日志
1, 在filebeat这台服务器上安装nginx,启动服务。并使用浏览器访问刷新一下,模拟产生一些相应的日志(==强调==: 我们在这里是模拟的实验环境,一定要搞清楚实际情况下是把filebeat安装到nginx服务器上去收集日志)
[root@vm4 ~]# yum install epel-release -y [root@vm4 ~]# yum install nginx -y [root@vm4 ~]# systemctl restart nginx [root@vm4 ~]# systemctl enable nginx
2, 修改filebeat配置文件,并重启服务
[root@vm4 ~]# cat /etc/filebeat/filebeat.yml |grep -v '#' |grep -v '^$'
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/*.log- /var/log/nginx/access.log 只在这里加了一句nginx日志路径(按需求自定义即可)
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 3
setup.kibana:
output.logstash:hosts: ["10.1.1.13:5044"]
processors:- add_host_metadata: ~- add_cloud_metadata: ~[root@vm4 ~]# systemctl stop filebeat
[root@vm4 ~]# systemctl start filebeat
3, 验证(在kibana或es-head上查询)
练习: 尝试收集httpd,mysql日志
实验中易产生的问题总结:
-
filebeat配置里没有把output.elasticsearch改成output.logstash
-
filebeat在收集/var/log/*.log日志时,需要对日志进行数据的改变或增加,才会传。当/var/log/yum.log增加了日志数据会传输,但不会触发配置里的其它日志传输。(每个日志的传输是独立的)
-
filebeat收集的日志没有定义索引名称, 我这个实验是在logstash里定义的。(此例我定义的索引名叫filebeat2-%{+YYYY.MM.dd})
-
es-head受资源限制可能会关闭了,你在浏览器上验证可能因为缓存问题,看不到变化的结果。
-
区分索引名和索引模式(index pattern)名
filebeat日志简单过滤
[root@vm4 ~]# grep -Ev '#|^$' /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/yum.log- /var/log/nginx/access.loginclude_lines: ['Installed'] 表示收集的日志里有Installed关键字才会收集
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 3
setup.kibana:
output.logstash:hosts: ["10.1.1.13:5044"]
processors:- add_host_metadata: ~- add_cloud_metadata: ~[root@vm4 ~]# systemctl restart filebeat
测试方法:
通过yum install和yum remove 产生日志,检验结果
结果为: yum install安装可以收集,yum remove卸载的不能收集
其它参数可以自行测试
-
exclude_lines
-
exclude_files
相关文章:
ELK简单介绍二
学习目标 能够部署kibana并连接elasticsearch集群能够通过kibana查看elasticsearch索引信息知道用filebeat收集日志相对于logstash的优点能够安装filebeat能够使用filebeat收集日志并传输给logstash kibana kibana介绍 Kibana是一个开源的可视化平台,可以为ElasticSearch集群…...

video 标签 各种属性及所有事件监听
网页中的video 属性和事件,用于计算观看视频的时长,其他用法备存。 <!-- video 不支持 IE8及以下版本浏览器,支持三种视频格式:MP4,WebM 和 Ogg --><video src"test.mp4" controls width"400…...

TS中断言、转换的应用
1.TS 类型断言定义 把两种能有重叠关系的数据类型进行相互转换的一种 TS 语法,把其中的一种数据类型转换成另外一种数据类型。类型断言和类型转换产生的效果一样,但语法格式不同。 2.TS 类型断言语法格式 A 数据类型的变量 as B 数据类型 。 A 数据类…...

【代码随想录算法训练营-第四天】【链表】24,19, 面试题 02.07,142
24. 两两交换链表中的节点 第一遍-递归-小看了一下题解 思路: 读了两遍题目才理解…相邻节点的交换,这个操作很容易实现,但需要一个tmpNode因为是链表的题目,没开始思考之前先加了dummyNode,还真管用把dummyNode作为…...

代理设计模式
1. 代理模式 1.1 代理模式的原理分析 代理设计模式(Proxy Design Pattern)是一种结构型设计模式,它为其他对象提供一个代理对象,以控制对这个对象的访问。代理模式可以用于实现懒加载、安全访问控制、日志记录等功能。 代理模式…...
ubuntu安装docker及docker常用命令
docker里有三个部分 daemon 镜像 和 容器 我们需要了解的概念 容器 镜像 数据卷 文章目录 docker命令docker镜像相关命令docker容器相关命令数据卷ubuntu安装docker docker命令 #启动,停止,重启docker systemctl start docker systemctl stop docker s…...
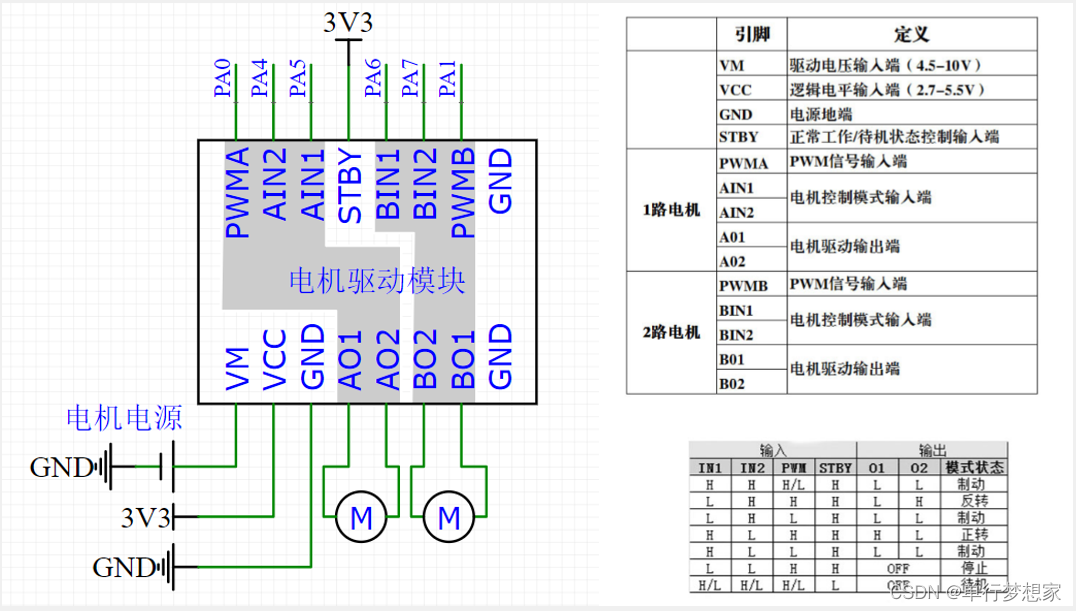
STM32-TIM定时器输出比较
目录 一、输出比较简介 二、PWM简介 三、输出比较通道(通用) 四、输出比较通道(高级) 五、输出比较模式 六、PWM基本结构 七、PWM参数计算 八、外设介绍 8.1 舵机 8.2 直流电机及驱动 九、开发步骤 十、输出比较库函数…...
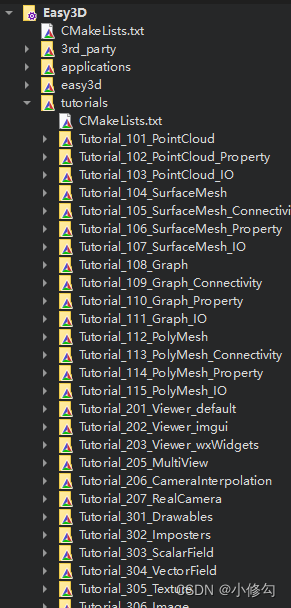
《Easy3d+Qt+VTK》学习
《Easy3dQtVTK》学习-1、编译与配置 一、编译二、配置注 一、编译 1、 资源下载:easy3d giuhub 2、解压缩 3、用qt打开CMakeLists.txt即可 4、点击项目,选择debug或者release,图中3处可自行选择,因为我的qt版本是6,…...
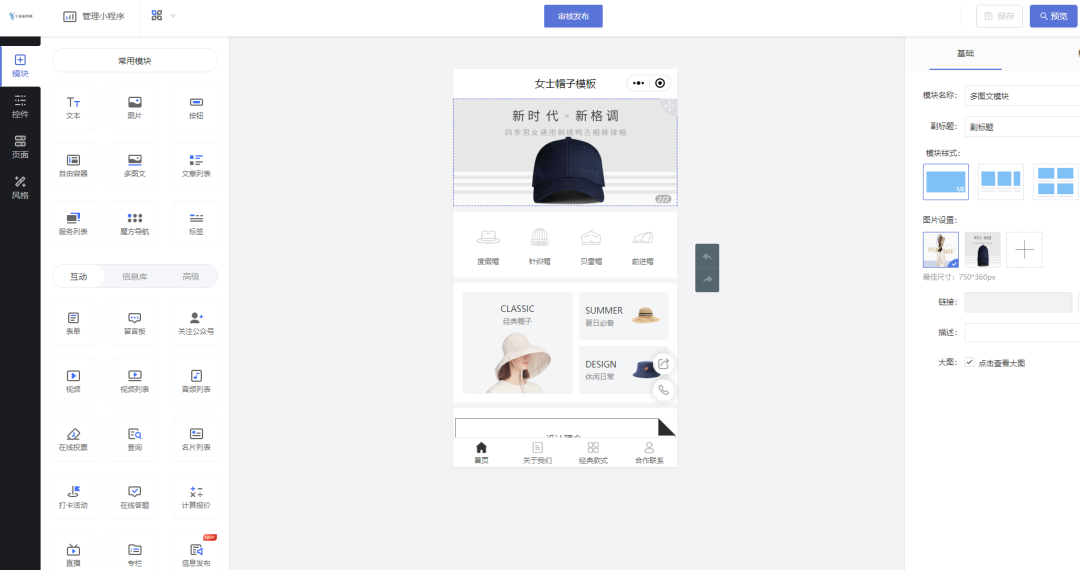
多平台展示预约的服装小程序效果如何
线下实体服装店非常多,主要以同城生意为主,但随着电商经济增长,传统线下自然流量变少,商家们会选择线上入驻平台开店获得更多线上用户,包括自建私域小程序等。 而除了直接卖货外,线上展示预约在服装行业也…...
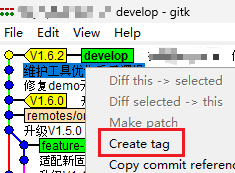
Gti GUI添加标签
通过Git Gui打开项目,通过菜单打开分支历史,我这里是名为"develop"的分支 选中需要打标签的commit,右键-Create tag即可 但貌似无法删除标签,只能通过git bash,本地标签通过git tag -d tagname,…...
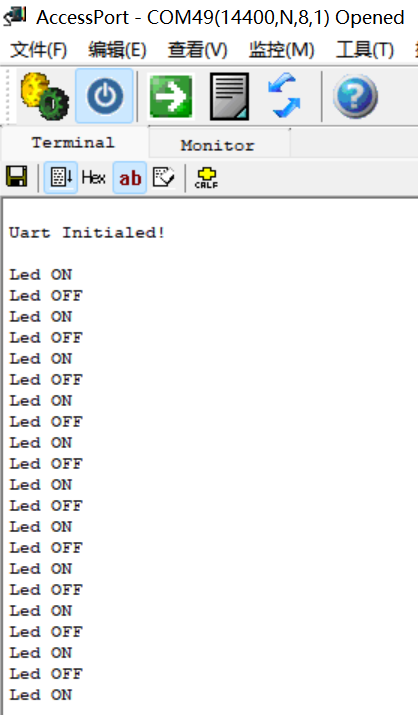
高云GW1NSR-4C开发板M3硬核应用
1.M3硬核IP下载:Embedded M3 Hard Core in GW1NS-4C - 科技 - 广东高云半导体科技股份有限公司 (gowinsemi.com.cn) 特别说明:IDE必须是1.9.9及以后版本,1.9.8会导致编译失败(1.9.8下1.1.3版本IP核可用) 以下根据官方…...
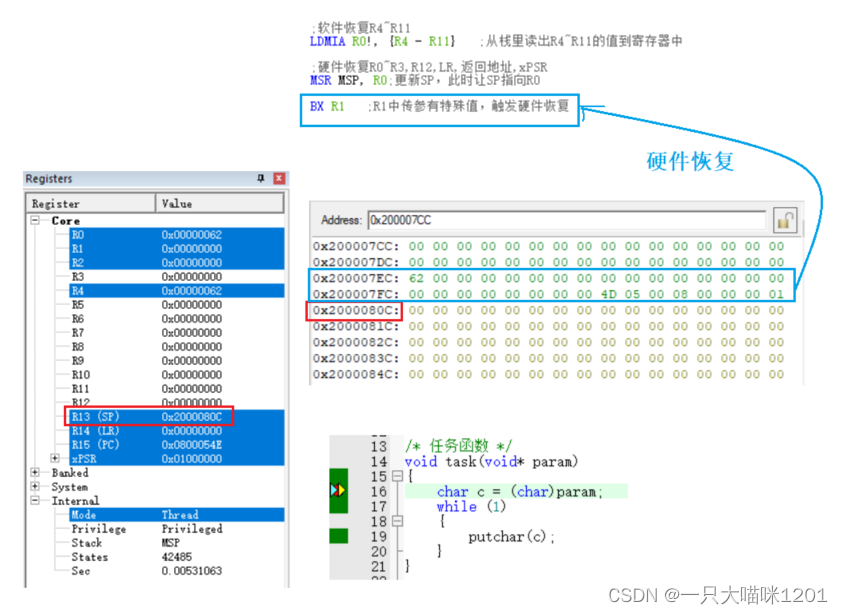
【RTOS学习】模拟实现任务切换 | 寄存器和栈的变化
🐱作者:一只大喵咪1201 🐱专栏:《RTOS学习》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀认识任务切换🏐切换的实质🏐栈中的内容🏐切…...

1.2 轻量级数据交互格式–JSON
对于接口来说,数据交互大部分都是使用的JSON格式,我们这里说的数据,就是我们上一章里讲解HTTP协议的时候,HTTP协议结构里的实体,也就是放在body里。body里存放需要传输的数据,数据是JSON格式,然后通过HTTP协议来传输给接口,接口再以同样的方式给我们返回。理解了这一层…...
 方法)
charCodeAt() 方法
charCodeAt() 是 JavaScript 中用于获取字符串指定位置字符的 Unicode 编码的方法 语法如下: str.charCodeAt(index) str:要获取字符的字符串。index:要获取的字符在字符串中的索引。返回值是一个表示给定索引处字符 Unicode 编码的整数。…...

Flask中redis的配置与使用
注意点: 在__init__.py中需要将redis_store设置成全局变量,这样方便其他文件导入 一、config.py import logging import os from datetime import timedeltafrom redis import StrictRedisclass Config:# 调试信息DEBUG TrueSECRET_KEY os.urandom(3…...

生产者与消费者模型
初识linux之线程同步与生产者消费者模型_生产者线程和消费者线程-CSDN博客 Linux线程(三)—— 多线程(生产者消费者模型、信号量、线程池)-CSDN博客...
透析回溯的模板
关卡名 认识回溯思想 我会了✔️ 内容 1.复习递归和N叉树,理解相关代码是如何实现的 ✔️ 2.理解回溯到底怎么回事 ✔️ 3.掌握如何使用回溯来解决二叉树的路径问题 ✔️ 回溯可以视为递归的拓展,很多思想和解法都与递归密切相关,在很多…...

浅谈web性能测试
什么是性能测试? web性能应该注意些什么? 性能测试,简而言之就是模仿用户对一个系统进行大批量的操作,得出系统各项性能指标和性能瓶颈,并从中发现存在的问题,通过多方协助调优的过程。而web端的性能测试…...
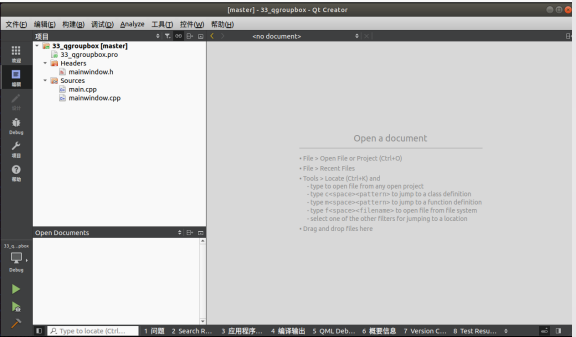
Qt 容器QGroupBox带有标题的组框框架
控件简介 QGroupBox 小部件提供一个带有标题的组框框架。一般与一组或者是同类型的部件一起使用。教你会用,怎么用的强大就靠你了靓仔、靓妹。 用法示例 例 qgroupbox,组框示例(难度:简单),使用 3 个 QRadioButton 单选框按钮,与QVBoxLayout(垂直布局)来展示组框的…...
Linux系统解决“Key was rejected by service”
Linux系统下加载驱动模块出现如上错误提示的原因为:此驱动未经过签名。 方法一、关闭Secure Boot 如果是物理机,需要开机进入BIOS,找到“Secure Boot”的选项,然后关闭。 如果是虚拟机,可以打开虚拟设置,…...

基于MCP协议的AI思维链结构化存储服务器设计与应用
1. 项目概述:一个为AI思维链提供结构化存储的MCP服务器最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)进行复杂推理和规划的项目时,我总被一个问题困扰:如何有效地管理和复用模型在思考过程中产生的…...

Citra 3DS模拟器:在电脑上重温任天堂掌机经典的完整指南 [特殊字符]
Citra 3DS模拟器:在电脑上重温任天堂掌机经典的完整指南 🎮 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/GitHub_Trending/ci/citra 想要在Windows、macOS或Linux电脑上体验《精灵宝可梦XY》、《塞尔达传说&am…...

HoRain云--Skills 基本结构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

Go语言微服务架构设计:从理论到实践
Go语言微服务架构设计:从理论到实践 引言 微服务架构已经成为现代软件架构的主流模式。Go语言凭借其高性能、轻量级和并发能力,成为构建微服务的理想选择。本文将深入探讨微服务架构的核心概念、Go语言实现策略,以及如何构建可扩展、高可用的…...

PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码
PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码 【免费下载链接】pyinstxtractor PyInstaller Extractor 项目地址: https://gitcode.com/gh_mirrors/py/pyinstxtractor 你是否曾经面对一个PyInstaller打包的可执行文件,想要查看其中…...

GIT 切换分支合并分支前一定要先 fetch,一定要选择远程分支进行操作
测试 GIT 切换分支 合并分支 1、切换和合并分支时,要选择远程的分支,确保本地的代码是最新的 2、切换分支前不 fetch3、切换分支前先点 fetch4、合并分支前不 fetch5、合并分支前先 fetch...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...

DETR模型ONNX推理实战:从输出张量到可视化检测框的完整解析
DETR模型ONNX推理实战:从输出张量到可视化检测框的完整解析 在目标检测领域,DETR(Detection Transformer)以其独特的端到端架构和简洁的流程设计,正在改变传统基于锚框(anchor-based)方法的格局…...

Cursor Free VIP:三步破解AI编程助手试用限制的专业解决方案
Cursor Free VIP:三步破解AI编程助手试用限制的专业解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...
动态加载)
PyQt5开发避坑:别再手动编译.ui文件了,试试uic.loadUi()动态加载
PyQt5高效开发:uic.loadUi()动态加载技术深度解析 在快速迭代的GUI开发过程中,PyQt5开发者常陷入一个效率陷阱——每次修改界面后都需要手动执行pyuic编译命令。这种重复性操作不仅打断开发流状态,还会在频繁调整阶段浪费大量时间。本文将揭示…...