分布式全局ID之雪花算法
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
雪花算法
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、什么是雪花算法?
- 二、雪花算法的特点
- 三、雪花算法生成的ID和UUID生成的ID区别
- 四、雪花算法实现
- 雪花算法的简单实现
- 雪花算法实现之Mybatis Plus
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
在当今的数据驱动世界中,对于许多应用程序来说,生成唯一的标识符是至关重要的。这些标识符可以用于标识数据记录、跟踪事务或管理资源。而雪花算法就是一种流行且高效的生成唯一标识符的方法。
雪花算法的核心思想是通过结合多个字段来生成一个全局唯一的标识符。它通常由多个部分组成,包括时间戳、机器标识符和序列号。通过这种方式,雪花算法可以确保在分布式系统中生成的标识符是唯一的,并且在时间和空间上具有良好的扩展性。
在这篇博客中,我将深入探讨雪花算法的原理、实现以及其在实际应用中的优势。我将介绍如何使用雪花算法生成唯一的标识符,以及如何将其集成到你的应用程序中。此外,我还将探讨一些常见的问题和注意事项,以帮助你更好地理解和应用雪花算法。
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是雪花算法?
雪花算法是一种分布式唯一ID生成算法,由Twitter公司开发并开源。它的核心思想是,利用64位的二进制数字,将这个数字划分为不同的位段,每个位段表示不同的含义,如时间戳、机器ID、序列号等,然后对每个位段进行相应的位移和运算,最后生成一个全局唯一的ID。具体来说,雪花算法将64位ID分成以下几个部分:
- 时间戳:41位,记录当前时间戳与起始时间戳的差值(精确到毫秒级别),可以使用69.7年。
- 机器ID:10位,用于标识不同的机器,可以支持1024台机器。
- 序列号:12位,表示同一毫秒内生成的不同ID,支持每台机器每毫秒产生4096个ID。
二、雪花算法的特点
- 生成的所有的id都是随着时间递增
- 生成的ID是唯一且有序的,可以用于分布式系统中的分布式锁、分布式数据库等场景。
- 支持分布式部署,每台机器都可以独立生成ID,不会产生冲突。
- 可以根据需求灵活调整位数分配,以满足不同规模系统的需求。
三、雪花算法生成的ID和UUID生成的ID区别
- 长度:雪花算法生成的 ID 通常是 64 位,而 UUID 生成的 ID 是 128 位。
- 组成部分:雪花算法生成的 ID 由时间戳、机器 ID 和序列号组成,而 UUID 生成的 ID 包含多个部分,如时间、计数器和硬件标识等。
- 生成方式:雪花算法生成的 ID 是通过位运算和算术运算生成的,而 UUID 生成的 ID 是通过随机数生成器或者哈希函数等方式生成的。
- 性能:雪花算法生成的 ID 性能较好,生成速度较快,适用于高并发场景,而 UUID 生成的 ID 性能相对较差,生成速度较慢。
- 可读性:雪花算法生成的 ID 可读性较差,不容易理解其含义,而 UUID 生成的 ID 可读性较好,可以通过其组成部分了解其生成的时间、机器等信息。
- 唯一性:雪花算法生成的 ID 在同一台机器上、同一毫秒内是唯一的,而 UUID 生成的 ID 在全球范围内是唯一的。
- ID自增:雪花算法生成的ID是自增的,索引效率高,而UUID生成的不是自增的,效率低。
四、雪花算法实现
雪花算法的简单实现
1.引入相关依赖,hutool工具包已经提供雪花算法ID生成的工具类。
<!-- https://mvnrepository.com/artifact/cn.hutool/hutool-all -->
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.13</version>
</dependency>2.实现代码
//参数1为机器标识
//参数2为数据标识
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
long id = snowflake.nextId();//Snowflake生成Long类型id//简单使用
long id = IdUtil.getSnowflakeNextId();//IdUtil生成long类型id
String id = snowflake.getSnowflakeNextIdStr();//Snowflake生成String类型id雪花算法实现之Mybatis Plus
1.导入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies>2.编写相关配置,在 application.yml 配置文件中添加 MySQL 数据库的相关配置:
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.66.100:3306/test?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
3.开启MapperScan扫描,在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹
@SpringBootApplication
@MapperScan("com.itbaizhan.sonwflake.mapper")
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}
4.实现雪花算法,在实体类id属性上加上 @TableId(type = IdType.ASSIGN_ID)注解
@Data
public class User {@TableId(type = IdType.ASSIGN_ID)// 雪花算法private Long id;private String name;private Integer age;private String email;
}5.编写Mapper
public interface UserMapper extends BaseMapper<User> {
}总结
提示:这里对文章进行总结:
雪花算法 - 为每一片雪花赋予独一无二的标识符
相关文章:

分布式全局ID之雪花算法
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 雪花算法 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、什么是雪花算法?…...

拿到服务器该做的事和升级docker engine
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-pluginsudo -i # 切换到 root 用户apt update -y # 升级 packagesapt install wget curl sudo vim git -y # Debian 系统比较干净,安装常用的软件 安装docker …...
【VScode和Leecode的爱恨情仇】command ‘leetcode.signin‘ not found
文章目录 一、关于command ‘leetcode.signin‘ not found的问题二、解决方案第一,没有下载Nodejs;第二,有没有在VScode中配置Nodejs第三,力扣的默认在VScode请求地址中请求头错误首先搞定配置其次搞定登入登入方法一:…...

mangokit:golang web项目管理工具,使用proto定义http路由和错误
文章目录 前言1、mangokit介绍1.1 根据proto文件生成http路由1.2 根据proto文件生成响应码1.3 使用wire来管理依赖注入 2、mangokit实现2.1 protobuf插件开发2.2 mangokit工具 3、使用示例3.1 创建新项目3.2 添加新的proto文件3.3 代码生成 前言 在使用gin框架开发web应用时&a…...

微信小程序实现一个简单的登录功能
微信小程序实现一个简单的登录功能 功能介绍login.wxmllogin.jsuserInfo.wxmluserInfo.js解析 功能介绍 微信小程序实现一个简单的登录功能。包括一个登录页面和一个用户信息展示页面。在登录页面中输入用户名和密码,点击登录按钮进行验证,如果验证成功&…...

whisper深入-语者分离
文章目录 学习目标:如何使用whisper学习内容一:whisper 转文字1.1 使用whisper.load_model()方法下载,加载1.2 使用实例对文件进行转录1.3 实战 学习内容二:语者分离(pyannote.audio)pyannote.audio是huggi…...
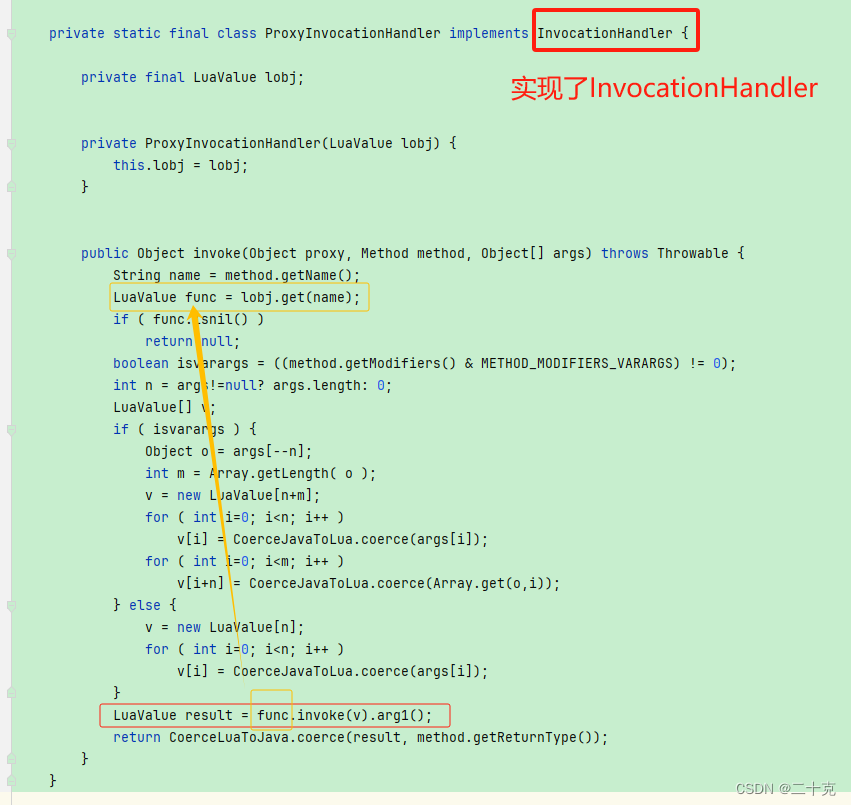
LuaJava操作Java的方法
最近在学习lua,然后顺便看了下luaj,可能用的人比较少,网上关于luaj的文章较少,其中在网上找到这个博主的相关文章,很详细,对于要学习luaj的小伙伴可以两篇一起查看,本文在此基础上进行扩展。 …...

oracle怎样才算开启了内存大页?
oracle怎样才算开启了内存大页? 关键核查下面三点: 1./etc/sysctl.conf vm.nr_hugepages16384这是给了32G,计划sga给30G,一般需多分配2-4G sysctl -p生效 看cat /proc/meminfo|grep Huge啥结果? 这种明显是配了…...
【halcon深度学习之那些封装好的库函数】determine_dl_model_detection_param
determine_dl_model_detection_param 目标检测的数据准备过程中的有一个库函数determine_dl_model_detection_param “determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议…...
跟着我学Python进阶篇:01.试用Python完成一些简单问题
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...

neo4j-Py2neo使用
neo4j-Py2neo(一):基本库介绍使用 py2neo的文档地址:https://neo4j-contrib.github.io/py2neo/ py2neo的本质是可以采用两种方式进行操作,一种是利用cypher语句,一种是使用库提供的DataTypes,Data类的实例需要和远程…...
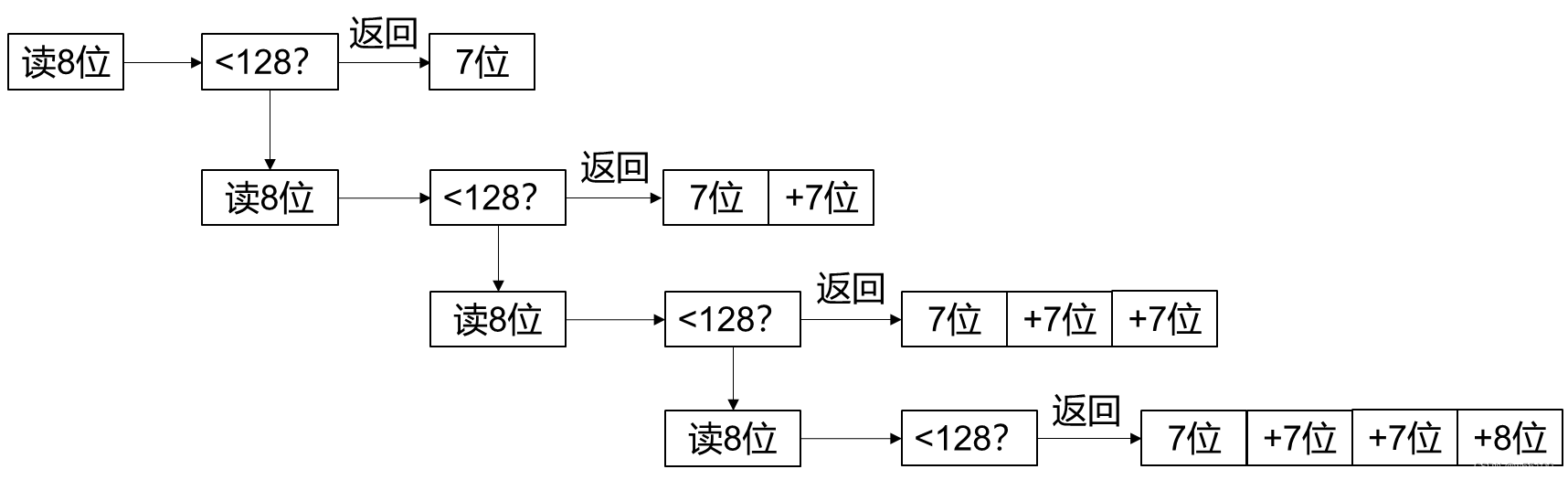
uint29传输格式
前言 不知道谁想出来的。 反正我是想不到。 我看网上也没人讲这个。 写篇博客帮一下素未谋面的网友。 uint29 本质上是网络传输的时候,借用至多4字节Bytes,表达29位的无符号整数。 读8位数字,判断小于128? 是的话,返回末7位…...
Linux:终端定时自动注销
这样防止了,当我们临时离开电脑这个空隙,被坏蛋给趁虚而入 定几十秒或者分钟,如果这个时间段没有输入东西那么就会自动退出 全局生效 这个系统中的所有用户生效 vim /etc/profile在末尾加入TMOUT10 TMOUT10 这个就是10 秒,按…...
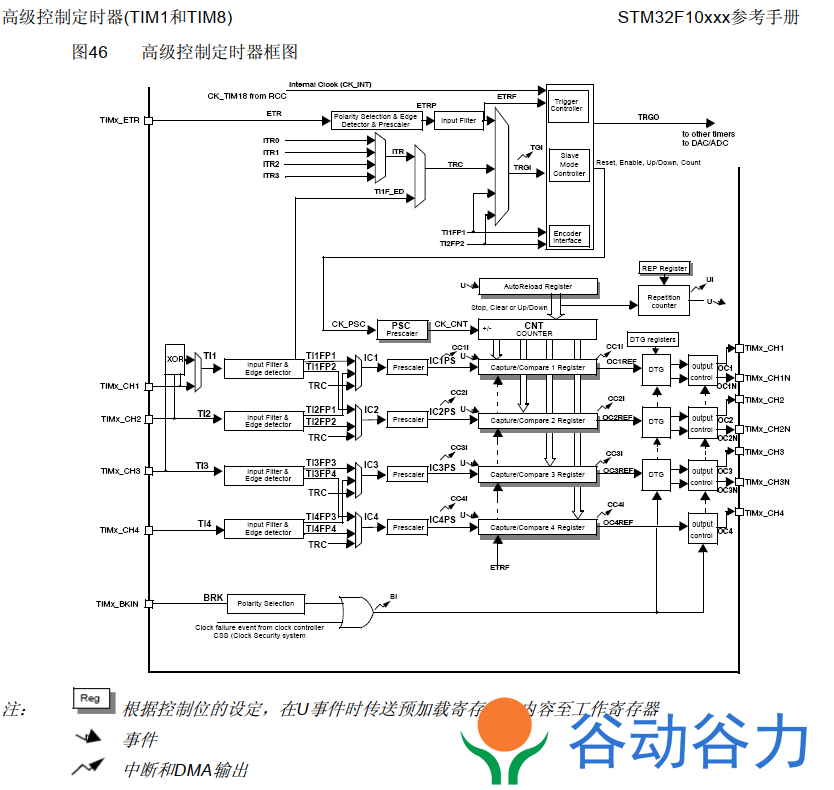
STM32F103RCT6开发板M3单片机教程06--定时器中断
前言 除非特别说明,本章节描述的模块应用于整个STM32F103xx微控制器系列,因为我们使用是STM32F103RCT6开发板是mini最小系统板。本教程使用是(光明谷SUN_STM32mini开发板) STM32F10X定时器(Timer)基础 首先了解一下是STM32F10X…...
数据库故障Waiting for table metadata lock
场景:早上来发现一个程序,链接mysql数据库有点问题,随后排查,因为容器在k8s里面。所以尝试重启了pod没有效果 一、重启pod: 这里是几种在Kubernetes中重启Pod的方法: 删除Pod,利用Deployment重建 kubectl delete pod mypodDepl…...

Springboot数据校验与异常篇
一、异常处理 1.1Http状态码 HTTP状态码是指在HTTP通信过程中,服务器向客户端返回的响应状态。它通过3位数字构成,第一个数字定义了响应的类别,后两位数字没有具体分类作用。以下是常见的HTTP状态码及其含义: - 1xx(信…...

第三十六章 XML 模式的高级选项 - 创建子类型的替换组
文章目录 第三十六章 XML 模式的高级选项 - 创建子类型的替换组创建子类型的替换组将子类限制在替换组中 第三十六章 XML 模式的高级选项 - 创建子类型的替换组 创建子类型的替换组 XML 模式规范还允许定义替换组,这可以是创建选择的替代方法。语法有些不同。无需…...
堆与二叉树(上)
本篇主要讲的是一些概念,推论和堆的实现(核心在堆的实现这一块) 涉及到的一些结论,证明放到最后,可以选择跳过,知识点过多,当复习一用差不多,如果是刚学这一块的,建议打…...

HBase查询的一些限制与解决方案
Apache HBase 是一个开源的、非关系型、分布式数据库,它是 Hadoop 生态系统的一部分,用于存储和处理大量的稀疏数据。HBase 在设计上是为了提供快速的随机读写能力,但与此同时,它也带来了一些查询上的限制: 没有SQL支持…...

软件开发 VS Web开发
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 目录 介绍: 角色和职责: 软件开发人员: Web开发人员: 技能: 软件开发人员: Web开发人…...

三维扫描平民化实战:从手机APP到高精度重建全流程指南
1. 项目概述:当三维扫描走下神坛几年前,如果你想获取一个真实物体的三维数字模型,那通常意味着你需要联系一家专业的三维扫描服务公司,支付一笔不菲的费用,然后等待专业人士用一台价格堪比一辆豪华轿车的设备ÿ…...

终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案
终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirrors/ed/edgedb …...

从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型
从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from t…...

从单场到多场并发:知识竞赛平台的弹性扩展能力
🚀 从单场到多场并发:知识竞赛平台的弹性扩展能力动态调度 平滑扩容 稳定支撑📌 演进中的需求:从单一活动到复杂场景传统的知识竞赛活动往往以单场、线下或小规模在线形式进行,对技术平台的压力相对有限。然而&#…...

音频AI DSP:低功耗边缘智能的硬件架构与实现
1. 项目概述:当音频AI遇见边缘DSP几年前,如果有人告诉我,一个比指甲盖还小的芯片,能在不到1毫瓦的功耗下,持续监听环境声音、识别特定关键词,甚至能分辨出你是在嘈杂的餐厅还是在安静的办公室,我…...
)
华为eNSP模拟器实战:用VRRP+MSTP给公司网络做个高可用冗余(附完整配置命令)
华为eNSP企业级网络高可用架构实战:VRRP与MSTP深度协同设计 当一家中型企业的终端规模突破500台时,网络架构的脆弱性往往会突然暴露——某个交换机的意外宕机可能导致整个部门断网,核心链路的拥塞会让关键业务卡顿不已。这时仅靠基础的STP和…...

企业安全运维:轻量级OpenClaw检测脚本的设计、部署与MDM集成实战
1. 项目概述:为什么我们需要一个轻量级的OpenClaw检测脚本?在当今的企业IT环境中,开发工具和AI辅助编程代理的普及带来了前所未有的效率提升,但同时也引入了新的安全与合规盲区。想象一下,一个未经批准的开发工具&…...

3分钟上手:Windows上直接安装Android应用的最佳工具APK Installer
3分钟上手:Windows上直接安装Android应用的最佳工具APK Installer 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为复杂的Android模拟器配置而烦恼吗&…...
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注 【免费下载链接】PixelAnnotationTool Annotate quickly images. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelAnnotationTool 你是否曾经为图像标注工作感到头疼ÿ…...
)
MathType 快捷键实战指南——数学建模效率飙升的秘诀(从入门到精通)
1. 为什么你需要掌握MathType快捷键? 如果你经常需要处理数学公式,肯定遇到过这样的场景:为了输入一个简单的积分符号,不得不从工具栏里翻找半天;调整公式对齐时反复用鼠标拖动;修改矩阵维度时逐个单元格调…...