HIVE基本操作
1、启动远程服务端:hive --service metastore启动(这里是阻塞式),然后在客户端操作
2、Hive DDL(数据库定义语言)
--展示所有数据库show databases;
--切换数据库use database_name;3、创建语法(建议拷贝到notepad++中,查看类型时比较方便有高亮)
/*创建表的操作基本语法:CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)[(col_name data_type [COMMENT col_comment], ... [constraint_specification])][COMMENT table_comment][PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)][CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)[STORED AS DIRECTORIES][[ROW FORMAT row_format] [STORED AS file_format]| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)][LOCATION hdfs_path][TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_nameLIKE existing_table_or_view_name[LOCATION hdfs_path];复杂数据类型data_type: primitive_type| array_type| map_type| struct_type| union_type -- (Note: Available in Hive 0.7.0 and later)基本数据类型primitive_type: TINYINT| SMALLINT| INT| BIGINT| BOOLEAN| FLOAT| DOUBLE| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)| STRING| BINARY -- (Note: Available in Hive 0.8.0 and later)| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)| DECIMAL -- (Note: Available in Hive 0.11.0 and later)| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)| DATE -- (Note: Available in Hive 0.12.0 and later)| VARCHAR -- (Note: Available in Hive 0.12.0 and later)| CHAR -- (Note: Available in Hive 0.13.0 and later)array_type: ARRAY < data_type >map_type: MAP < primitive_type, data_type >struct_type: STRUCT < col_name : data_type [COMMENT col_comment], ...>union_type: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)行格式规范row_format: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char][NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]文件基本类型file_format:: SEQUENCEFILE| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)| RCFILE -- (Note: Available in Hive 0.6.0 and later)| ORC -- (Note: Available in Hive 0.11.0 and later)| PARQUET -- (Note: Available in Hive 0.13.0 and later)| AVRO -- (Note: Available in Hive 0.14.0 and later)| JSONFILE -- (Note: Available in Hive 4.0.0 and later)| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname表约束constraint_specification:: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ][, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
*/--创建普通hive表(不包含行定义格式)create table psn(id int,name string,likes array<string>,address map<string,string>)--创建自定义行格式的hive表create table psn2(id int,name string,likes array<string>,address map<string,string>)row format delimitedfields terminated by ','collection items terminated by '-'map keys terminated by ':';--创建hive的外部表(需要添加external和location的关键字)
create external table psn4(id int,name string,likes array<string>,address map<string,string>)row format delimitedfields terminated by ','collection items terminated by '-'map keys terminated by ':'location '/data';-- 在之前创建的表都属于hive的内部表(psn,psn2,psn3),而psn4属于hive的外部表,内部表跟外部表的区别:1、hive内部表创建的时候数据存储在hive的默认存储目录中,外部表在创建的时候需要制定额外的目录2、hive内部表删除的时候,会将元数据和数据都删除,而外部表只会删除元数据,不会删除数据
--应用场景:内部表:需要先创建表,然后向表中添加数据,适合做中间表的存储外部表:可以先创建表,再添加数据,也可以先有数据,再创建表,本质上是将hdfs的某一个目录的数据跟,hive的表关联映射起来,因此适合原始数据的存储,不会因为误操作将数据给删除掉--创建多分区表create table psn6(id int,name string,likes array<string>,address map<string,string>)partitioned by(gender string,age int)row format delimitedfields terminated by ','collection items terminated by '-'map keys terminated by ':'; 注意:1、当创建完分区表之后,在保存数据的时候,会在hdfs目录中看到分区列会成为一个目录,以多级目录的形式 存在2、当创建多分区表之后,插入数据的时候不可以只添加一个分区列,需要将所有的分区列都添加值3、多分区表在添加分区列的值得时候,与顺序无关,与分区表的分区列的名称相关,按照名称就行匹配加载数据文件到某一张表中
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
加载本地数据到hive表
load data local inpath '/root/data/data' into table psn;--(/root/data/data指的是本地linux目录)
加载hdfs数据文件到hive表
load data inpath '/data/data' into table psn;--(/data/data指的是hdfs的目录)
注意:
1、load操作不会对数据做任何的转换和修改操作
2、从本地linux load local数据文件是复制文件到对应表目录下
3、从hdfs load数据文件是移动文件到对应表目录下
4、load操作也支持向分区表中load数据,只不过需要添加分区列的值
相关文章:

HIVE基本操作
1、启动远程服务端:hive --service metastore启动(这里是阻塞式),然后在客户端操作 2、Hive DDL(数据库定义语言) --展示所有数据库show databases; --切换数据库use database_name; 3、创建语法&#x…...
【经典LeetCode算法题目专栏分类】【第5期】贪心算法:分发饼干、跳跃游戏、模拟行走机器人
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 分发饼干 class Solutio…...

【大数据面试】MapReduce常见问题与答案
目录 介绍下MapReduce MapReduce优缺点 MapReduce架构 MapReduce工作原理 MapReduce哪个阶段最费时间 ✅MapReduce中的Combine是干嘛的?有什么好出? ✅MapReduce环形缓冲区是什么 ✅MapReduce为什么一定要有环型缓冲区 MapReduce为什么一定要有Shuffle过程 MapRedu…...

数组深入学习感悟
注:本文学习借鉴于《代码随想录》 一.介绍数组 数组是储存在连续内存空间中的相同类型数据的集合 数组名的理解: 数组名就是数组⾸元素(第⼀个元素)的地址是对的,但是有两个例外: sizeof(数组名),sizeof中单独放数…...
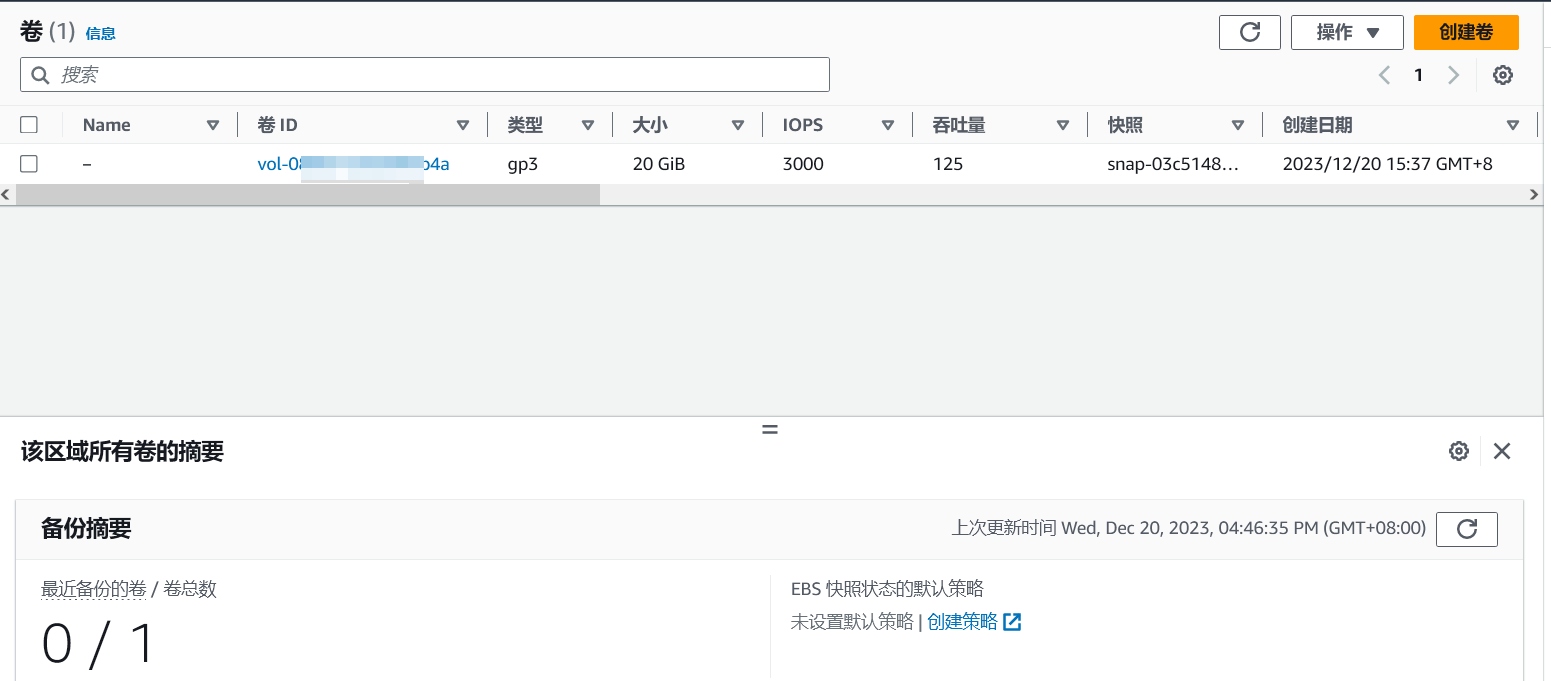
亚马逊云科技-如何缩容/减小您的AWS EC2根卷大小-简明教程
一、背景 Amazon EBS提供了块级存储卷以用于 EC2 实例,EBS具备弹性的特点,可以动态的增加容量、更改卷类型以及修改预配置的IOPS值。但是EBS不能动态的减少容量,在实际使用中,用户也许会存在此类场景: 在创建AWS EC2…...

[Java 基础] Java Stream
Java Stream 是 Java 8 引入的新特性之一,它提供了一种新的处理数据集合的方式。Stream 可以使我们更加方便地对集合进行处理和操作,同时还能提高代码的简洁性和可读性。 文章目录 什么是 Stream常见用法创建 Stream中间操作终端操作 总结 什么是 Stream…...
达芬奇18.6DaVinci ResolveStudio(Win/Mac)激活版
DaVinci Resolve Studio 18是一款业界领先的视频后期制作软件,它集成了剪辑、调色、视觉特效、动态图形和音频后期制作等功能,为用户提供了完整的创作解决方案。该软件不仅适用于电影、电视和网页内容的制作,还广泛应用于广告、纪录片和独立电…...
16. 最接近的三数之和)
力扣题目学习笔记(OC + Swift)16. 最接近的三数之和
16. 最接近的三数之和 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解。 排序 双指针 思路同15. 三数之和 简单地使用三重循环枚举所有的三…...

基于STM32的DHT11温湿度传感器与LCD显示器的集成设计
在本文中,我们将详细介绍如何基于STM32微控制器实现DHT11温湿度传感器与LCD显示器的集成设计。我们将包括硬件连接、软件编程以及涉及的STM32库函数和相关知识。这个项目旨在帮助您理解如何使用STM32来读取DHT11温湿度传感器的数据,并将数据显示在LCD显示…...

解决浏览器自动将http跳转至https导致无法访问的问题
以下只针对Chrome浏览器 方法一: 1.地址栏中输入chrome://net-internals/#hsts。 2.在Delete domain中输入项目的域名,并Delete(删除)。 3.可以在Query domain测试是否删除成功。 HSTS全称:HTTP Strict Transport Se…...

小程序面试题 | 07.精选小程序面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

深度学习的推理部分
深度学习的推理部分指的是已经训练好的深度学习模型应用于新数据(通常是测试或实际应用数据)以进行预测、分类、分割等任务的过程。在深度学习中,训练和推理是两个阶段: 训练阶段: 在这个阶段,深度学习模型…...
如何用 CleanMyMac 来保护 Mac 隐私
大家早上好,中午好,下午好,晚上好。 在我们使用MacBook上的自带浏览器-Safari(或者一些其他浏览器)进行网页浏览的时候,往往会留下一些痕迹。如果这些痕迹涉及一些敏感数据信息的话,那么我们肯…...
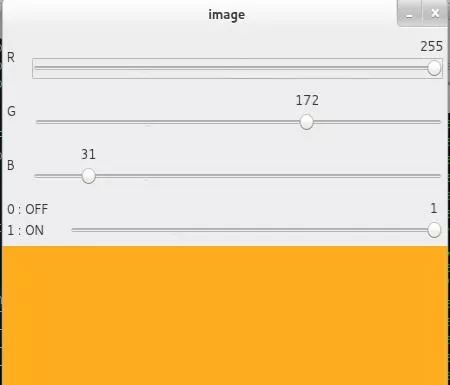
opencv入门到精通——鼠标事件和Trackbar控件的使用
目标 了解如何在OpenCV中处理鼠标事件 您将学习以下功能:cv.setMouseCallback() 了解将轨迹栏固定到OpenCV窗口 您将学习以下功能:cv.getTrackbarPos,cv.createTrackbar等。 简单演示 在这里,我们创建一个简单的应用程序&am…...

iOS 收集 SDK 内部 log
为 SDK 设置 log 等级,设置 RCIMClient 的 logLevel 为您期望的,可以在 SDK initWithAppkey 之后设置,比如希望只收集错误 log,那么可以设置为 RC_Log_Level_Error,如果想一般信息、警告信息,错误信息都收集…...
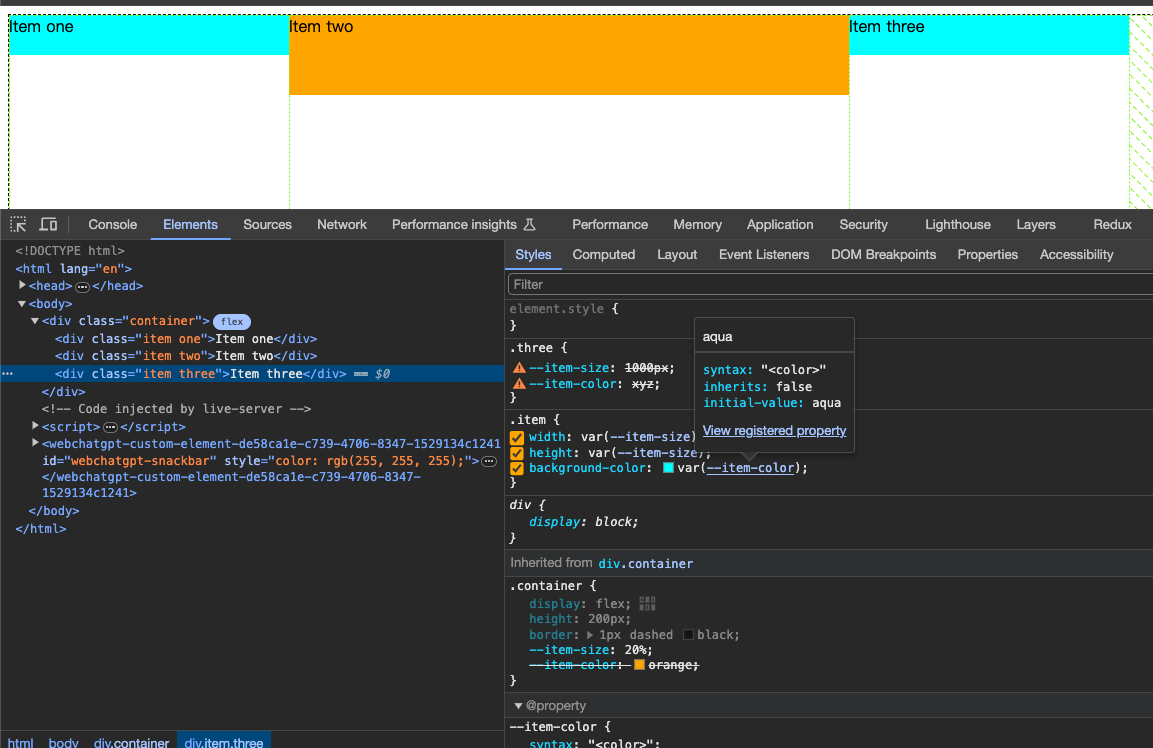
【CSS @property】CSS自定义属性说明与demo
CSS property property - CSS: Cascading Style Sheets | MDN At 规则 - CSS:层叠样式表 | MDN Custom properties (–*): CSS variables - CSS: Cascading Style Sheets | MDN CSS Houdini - Developer guides | MDN 📚 什么是property? property CSS…...

【华为数据之道学习笔记】6-3数据服务分类与建设规范
数据服务是为了更好地满足用户的数据消费需求而产生的,因此数据消费方的差异是数据服务分类的最关键因素。具体包括两大类:数据集服务和数据API服务。 1. 数据集服务 (1)数据集服务定义 比较常见的数据消费者有两类:一…...

Vue的脚手架
脚手架配置 脚手架文档:Vue CLI npm config set registry https://registry.npm.taobao.org vue.config.js配置选项: 配置参考 | Vue CLI ref选项 ref和id类似,给标签打标识。 document.getElementById(btn); this.$ref.btn; 父子组…...

Java实现Word中插入上标和下标
Java实现Word中插入上标和下标 Java不能直接在Word中插入上标和下标,但是可以通过POI库来实现。 下面提供一个Java代码示例,使用POI库向Word中插入带有上标和下标的文字: import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.…...

Java和Python中的目标堆栈规划实现
目标堆栈规划是一种简单高效的人工智能规划算法,用于解决复合目标问题。它的工作原理是**将总体目标分解为更小的子目标,然后以向后的顺序逐一解决它们。 让我们考虑一个简单的例子来说明目标堆栈规划。想象一下你想要烤一个蛋糕,目标是准备…...

别再混淆了!结构方程模型SEM中的反映型vs构成型指标,用PLS-PM一次讲清
结构方程模型中的反映型与构成型指标:理论辨析与PLS-PM实战指南 在数据分析的复杂世界里,结构方程模型(SEM)就像是一把瑞士军刀,能够同时处理测量模型和结构模型。但许多研究者在使用这把"军刀"时,常常忽略了一个关键细…...

AI智能体记忆系统设计:分层架构与向量化检索实战
1. 项目概述:一个为AI智能体设计的记忆系统最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的痛点:如何让这些智能体拥有“记忆”?不是那种简单的对话历史记录,而是更接近人类工作记忆和…...

别再到处找DEM了!手把手教你用ArcGIS Pro + Python脚本,从NASA官网免费下载并拼接出完整的中国90米高程数据
从NASA获取中国90米高程数据的自动化解决方案 在GIS和遥感研究领域,获取高质量的数字高程模型(DEM)数据是许多项目的基础工作。然而,对于中国区域的完整覆盖、高精度且免费可用的DEM数据,研究者们常常面临获取困难。本文将介绍如何利用ArcGI…...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...

上网行为怎么监控?教你五个简单实用的上网行为监控方法,建议收藏
在数字化办公时代,企业管理面临着新的挑战:一方面需要网络提供资讯和工具,另一方面,无节制的非工作上网行为正在侵蚀企业的生产力。如何科学、合理地监控上网行为?以下为您介绍五个监控方法,涵盖了从硬件到…...

别再只点保存了!QGIS工程文件.QGZ和.QGS到底怎么选?附XML结构详解
QGIS工程文件格式深度解析:.QGZ与.QGS的选择策略与XML实战指南 当你在QGIS中完成一幅精心设计的地图,点击保存按钮时,系统弹出的格式选择对话框可能让你陷入短暂的犹豫——该选择.QGZ还是.QGS?这个看似简单的选择背后,…...

C++ 知识点22 函数模板
C 函数模板一、为什么要有函数模板?先看痛点:你要写两个交换函数,int 版、double 版:// int 交换 void swapInt(int &a, int &b) {int t a; a b; b t; } // double 交换 void swapDouble(double &a, double &b…...

Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程
Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 还在为穿越机飞行不稳定而烦恼吗?🤔 想体验…...

WarcraftHelper:魔兽争霸3兼容性修复终极解决方案
WarcraftHelper:魔兽争霸3兼容性修复终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现代Windows系…...

【技术解析】方差分析:从统计表解读到业务决策的实战指南
1. 方差分析:从统计表到业务决策的实战指南 第一次接触方差分析时,我也被那些统计术语和公式搞得晕头转向。直到有一次,产品经理拿着A/B测试数据问我:"新版页面真的比旧版好吗?好多少?"我才意识到…...