python的pandas数据分析处理基础学习
pandas学习
一、 pandas基础
1. 什么是pandas?
一个开源的python类库:用于数据分析、数据处理、数据可视化
- 高性能
- 容易使用的数据结构
- 容易使用的数据分析工具
很方便和其他类库一起使用:
-
numpy:用于数学计算
-
scikit-learn:用于机器学习
2. pandas 的安装
方法一:
pip3 install pandas
方法二:
下载使用Python类库集成安装包:anaconda link: https://www.anaconda.com
当今最流行的python数据分析发行版
已经安装了数据分析需要的几乎所有的类库0
3. pandas读取数据
pandas 需要先读取表格类型的数据,然后进行分析
| 数据类型 | 说明 | pandas读取方式 |
|---|---|---|
| csv ,tsv,txt | 用逗号,tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx | pd.read_excel |
| mysql | 关系型数据库表 | pd.read_sql |
-
读取csv文件
import os import pandas as pdfpath = "E:\MyProject\DataAnalysis\my_pandas\Datas\cpu_temp.csv" # 读取csv文件的所有数据 datas = pd.read_csv(fpath) # 查看前几行的数据 默认前5行 da = datas.head() print(da) # 查看数据的形状,返回行和列 ds = datas.shape print(ds) # 查看列名列表 df = datas.columns print(df) # 查看索引列 dg = datas.index print(dg) # 查看每列的数据类型 dh = datas.dtypes print(dh)
4. Pandas数据结构
import pandas as pd
import numpy as np
-
DataFrame:二维数据、整个表格、多行多列
创建DataFrame的方法
-
根据多个字典序列创建dataframe
data = {'age':[23,45,32,56,32,54,22],'id': [1,2,3,4,5,6,7]'year': [1991,1992,1993,1994,1995,1996,1997]} d1 = pandas.DataFrame(data) -
df.columns 和df.index
-
-
Series: 一维数据、一行或一列
创建Series的三种方法:
-
仅使用数据列表即可产生最简单的Series
sl = pd.Series([1,'a',5.2,7]) -
创建一个具有标签索引的Series
s2 = pd.Series([1,'a',5.2,7], index=['d','e','f','g']) -
使用python字典创建Series
sdata = {'a':3500,'b'=4566, 'c'=12556,'d'=12435} s3 = pd.Series(sdata)
-
5. Pandas 数据查询
Pandas查询数据的几种方法
-
df.loc 根据行,列的标签值查询
-
使用单个标签值(label)查询数据
-
使用值列表批量查询
-
使用数值区间进行范围查询
-
使用条件表达式查询
df.loc[df["age"]<30,:]df.loc[(df['a']<=30) & (df['d']>=15) & (df[f]=='ssa')& (df['s']==1), :] -
调用函数查询
df.loc[lambda df : (df['a']<30)& (df['d']>=15),:]
-
-
df.iloc 根据行,列的数字位置查询
-
df.where
-
df.query
注意:.loc既能查询,又能覆盖写入,强烈推荐
6. Pandas新增数据列
-
直接赋值 修改列数值
将第b列的含有@符合的值替换掉 df.loc[:,"b"] = df["b"].str.replace("@","").astype('int32')计算差值新增一列插值
df[:,"chazhi"] = df["a"] - df["b"] -
df.apply
index则axis=0 columns则axis=1def get_temp_type(x):if x["CPU0_Temp"]>60:return '高温'elif x["CPU0_Temp"] < 50:return '低温'return '常温' df.loc[:,'temp_type'] = df.apply(get_temp_type,axis=1) df['temp_type'].value_counts() -
df.assign
可以是lambda函数也可以是自定义函数 df.assign(cpu0_huashi = lambda x :x['CPU0_Temp']*9/5 + 32,cpu1_huashi = lambda x: x['CPU1_Temp']*9/5 + 32) -
按条件选择分组分别赋值
先创建空列(这里第一张创建新列的方式 df["cup_type"] = '' df.loc[df['CPU1_Temp']- df['CPU0_Temp']>10,"cpu_type"] = "温差大" df.loc[df['CPU1_Temp']- df['CPU0_Temp']<=10,"cpu_type"] = "温差正常"
7. Pandas的数据统计函数
-
汇总类统计
提取所有数字列统计结果 df.describe() -
唯一去重和按值计算
-
唯一性去重
一般不用于数值列,而是枚举,分类列
df['b'].unique() -
按值计算
df[‘a’].value_counts()
-
-
相关系数和协方差
用途(超级厉害):
-
两只股票,是不是同涨同跌?程度多大?正相关还是负相关?
-
产品销量的波动,跟哪些因素正相关、负相关,程度多大?
对于两个变量X、Y
-
协方差:衡量同向反向程度,如果协方差为正,说明X、Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X、Y反向变化,协方差越小说明反向程度越高
df.cov() -
相关系数:衡量相似程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大
df.corr()df['a'].corr(df['b']) 查看a和b的相关系数 df['a'].corr(df['b']-df['c'])
-
8. Pandas缺失值处理
pandas使用函数处理缺失值
-
isnull和notnull:检测是否为空值,可用于df和series
-
dropna:丢弃、删除缺失值 【下面是参数介绍】
- axis:删除还是列,{0 or ‘index’,1 or ‘columns’},default 0
- how: 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除
- inplace:如果为True则修改当前df,否则返回新的df
-
fillna:填充空值 【下面是参数介绍】
- value:用于填充的值,可以是单个值,或者字典(key为列名,value是值)
- method:等于ffill使用前一个不为空的值填充for word fill;等于bfill使用后一个不为空的值填充back word fill
- axis:按行还是列填充,{0 or ‘index’,1 or ‘columns’}
- inplace:如果为True则修改当前df,否则返回新的df
相关文章:

python的pandas数据分析处理基础学习
pandas学习 一、 pandas基础 1. 什么是pandas? 一个开源的python类库:用于数据分析、数据处理、数据可视化 高性能容易使用的数据结构容易使用的数据分析工具 很方便和其他类库一起使用: numpy:用于数学计算 scikit-learn&a…...

【Qt-容器类】
Qt编程指南 ■ 顺序容器类■ QList■ QVector■ QLinkedList■ QStack■ QQueue ■ 关联容器类■ QSet■ QMap■ QMultiMap■ QHash■ QMultiHash ■ 顺序容器类 ■ QList QList 比较常用的容器类,以数组列表的形式实现,在前、后添加数据非常快。以下为…...

2023-12-27 语音转文字的whisper应用部署
点击 <C 语言编程核心突破> 快速C语言入门 语音转文字的whisper应用部署 前言一、部署whisper二、部署whisper.cpp总结 前言 要解决问题: 需要一款开源的语音转文字应用, 用于视频自动转换字幕. 想到的思路: openai的whisper以及根据这个模型开发的whisper.cppC应用. …...
MAVLINK生成自定义消息
git clone https://github.com/mavlink/mavlink.gitcd mavlinkgit submodule update --init --recursivepython -m mavgenerate出现以下界面 XML填写自定义xml路径,内容可以参考mavlink/message_definitions/v1.0 Out为输出路径 <?xml version"1.0"…...

【MediaPlayerSource】播放器源内部的音视频sender的创建和使用
来看下声网播放中的sender相关组件设计:MediaPlayerSourceDummy 是一个MediaPlayerSourceImpl ,输入音视频帧到 播放器。player_worker_ 线程触发所有操作,由外部传递,与其他组件公用 MediaPlayerSourceDummy(base::IAgoraService* agora_service, utils::worker_type play…...
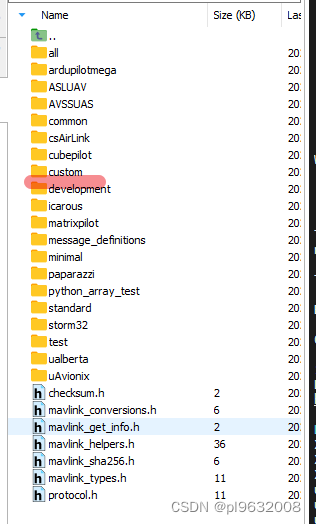
【机器学习】西瓜书第6章支持向量机课后习题6.1参考答案
【机器学习】西瓜书学习心得及课后习题参考答案—第6章支持向量机 1.试证明样本空间中任意点x到超平面(w,b)的距离为式(6.2)。 首先,直观解释二维空间内点到直线的距离: 由平面向量的有关知识,可得: 超平面的法向量为 w w w&am…...

【OpenAI Q* 超越人类的自主系统】DQN :Q-Learning + 深度神经网络
深度 Q 网络:用深度神经网络,来近似Q函数 强化学习介绍离散场景,使用行为价值方法连续场景,使用概率分布方法实时反馈连续场景:使用概率分布 行为价值方法 DQN(深度 Q 网络) 深度神经网络 Q-L…...

Vue axios Post请求 403 解决之道
前言: 刚开始请求的时候报 CORS 错误,通过前端项目配置后算是解决了,然后,又开始了新的报错 403 ERR_BAD_REQUEST。但是 GET 请求是正常的。 后端的 Controller 接口代码如下: PostMapping(value "/login2&qu…...
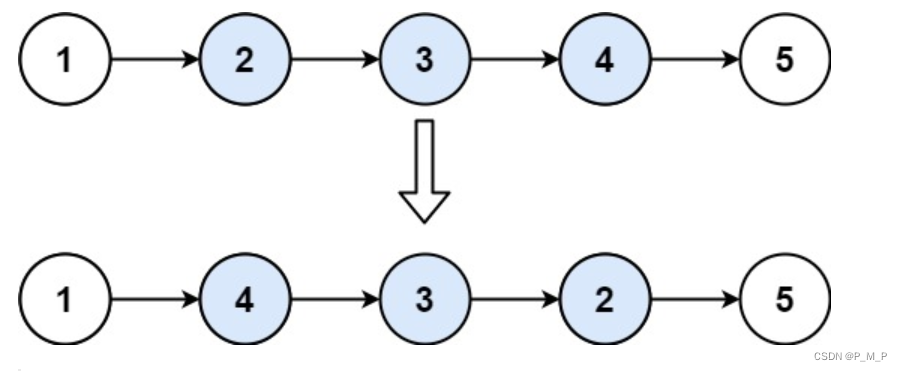
【Leetcode】重排链表、旋转链表、反转链表||
目录 💡重排链表 题目描述 方法一: 方法二: 💡旋转链表 题目描述 方法: 💡反转链表|| 题目描述 方法: 💡总结 💡重排链表 题目描述 给定一个单链表 L 的头节…...
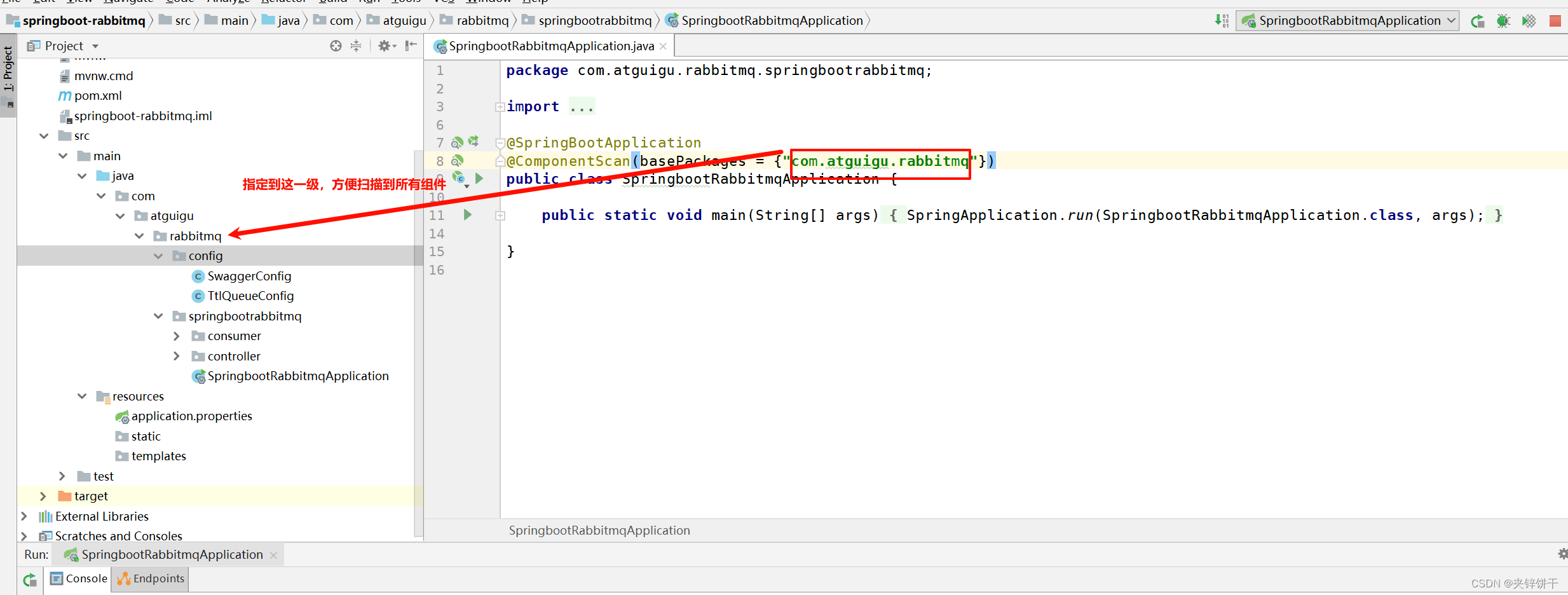
RabbitMQ 报错:Failed to declare queue(s):[QD, QA, QB]
实在没想到会犯这种低级错误。 回顾整理一下吧: 原因:SpringBoot主配置类默认只会扫描自己所在的包及其子包下面的组件。其他位置的配置不会被扫描。 如果非要使用其他位置,就需要在启动类上面指定新的扫描位置。注意新的扫描位置会覆盖默…...
Neo4j 5建库
Neo4j 只有企业版可以运行多个库,社区版无法创建多个库,一个实例只能运行一个库; 如果业务需要使用多个库怎么办呢? 就是在一个机器上部署多个实例,每个实例单独一个库名 这个库的名字我们可以自己定义; …...

鲁棒最小二乘法 拟合圆
圆拟合算法_基于huber加权的拟合圆算法-CSDN博客 首次拟合圆得到采用的上述blog中的 Ksa Fit 方法。 该方法存在干扰点时,拟合得到的结果会被干扰。 首次拟合圆的方法 因此需要针对外点增加权重因子,经过多次迭代后&…...

LeetCode——动态规划
动态规划 一、一维数组:斐波那契数列 爬楼梯70简单 dp定义: dp[i]表示爬到第i阶有多少种不同的方式 状态转移方程: dp[i] dp[i-1] dp[i-1] (每次可以爬1或2个台阶) 边界条件: dp[0] 1; dp[1] 1;&#…...

opencv和gdal的读写图片波段顺序问题
最近处理遥感影像总是不时听到 图片的波段错了,一开始不明就里,都是图片怎么就判断错了。 1、图像RGB波段顺序判断 后面和大家交流,基本上知道了一个判断标准。 一般来说,进入人眼的自然画面在计算机视觉中一般是rgb波段顺序表示…...

PyQt 打包成exe文件
参考链接 Python程序打包成.exe(史上最全面讲解)-CSDN博客 手把手教你将pyqt程序打包成exe(1)_pyqt exe-CSDN博客 PyInstaller 将DLL文件打包进exe_怎么把dll文件加到exe里-CSDN博客 自己的问题 按照教程走的话,会出现找不到“mmdeploy_ort_net.dll”文件的报错…...
)
【Web2D/3D】SVG(第二篇)
1. 前言 SVG(Scalable Vector Graphics,可缩放矢量图形)是一种使用XML描述2D图形的语言,由于SVG是基于XML(HTML也是基于XML的),因为SVG DOM中每个元素都是可以操作的,包含修改元素属…...

leetcode18. 四数之和
题目描述 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复): …...
(十八)Flask之threaing.local()对象
0、引子: 如下是一段很基础的多线程代码: from threading import Threaddemo 0def task(arg):global demodemo argprint(demo)for i in range(10):t Thread(targettask, args(i, ))t. start()当程序运行时,可能会看到输出的顺序是混乱的…...
ffmpeg 硬件解码零拷贝unity 播放
ffmpeg硬件解码问题 ffmpeg 在硬件解码,一般来说,我们解码使用cuda方式,当然,最好的方式是不要确定一定是cuda,客户的显卡不一定有cuda,windows 下,和linux 下要做一些适配工作,最麻…...
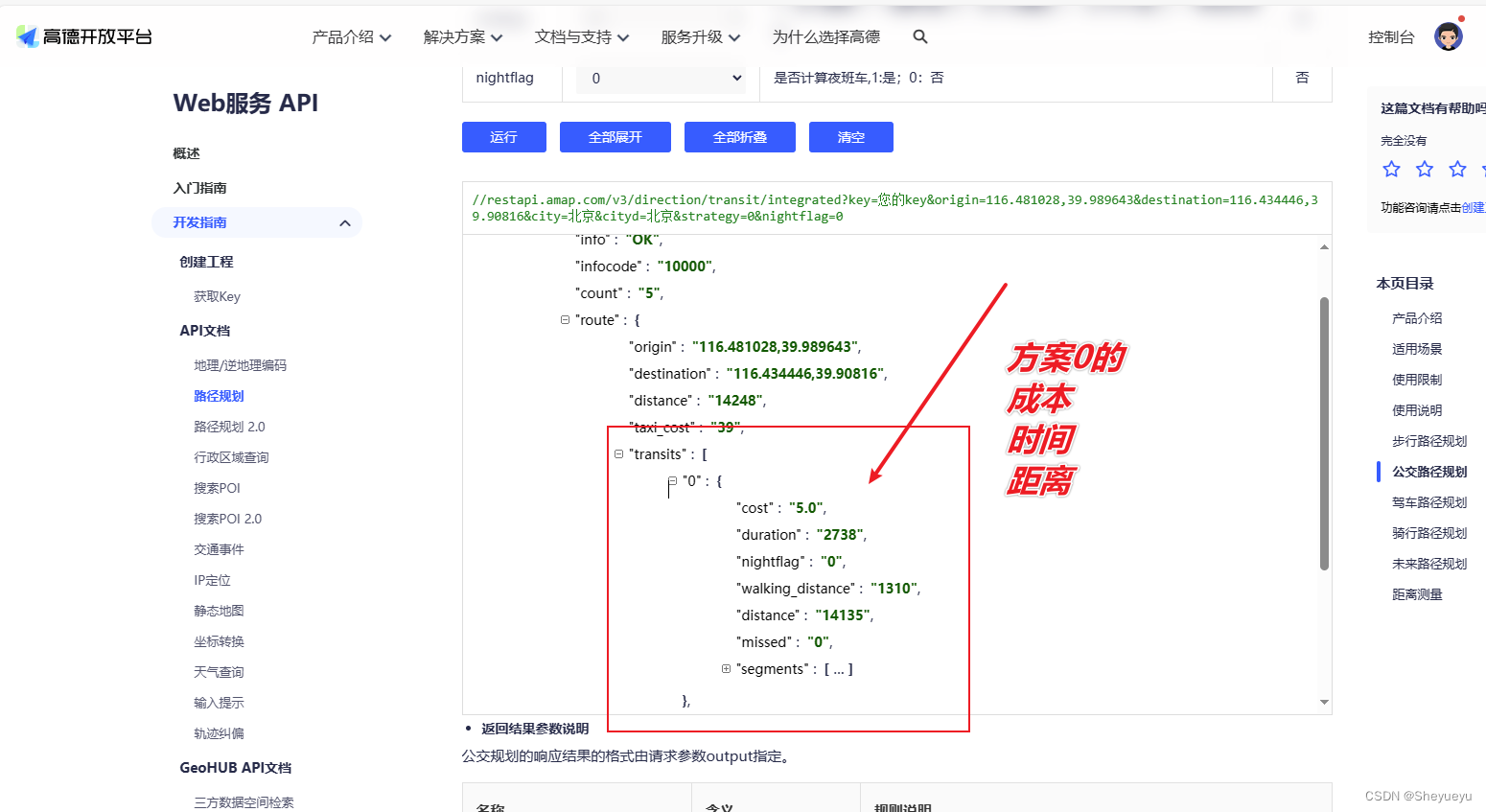
高德地图_公共交通路径规划API,获取两地点之间的驾车里程和时间
import pandas as pd import requests import jsondef get_dis_tm(origin, destination,city,cityd):url https://restapi.amap.com/v3/direction/transit/integrated?key xxx #这里就是需要去高德开放平台去申请key,请在xxxx位置填写,web服务APIlink {}origin{}&desti…...

新手开发者首次在Taotoken模型广场选型与试用的全过程记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手开发者首次在Taotoken模型广场选型与试用的全过程记录 作为一名刚开始接触大模型应用的开发者,我最近尝试了Taotok…...

Java 面试高频题:通知平台整体架构一般怎么拆?
消息实时通知平台架构总览怎么搭?一次讲清渠道、模板、推送、回执、偏好与治理闭环 大家好,我是一名有 4 年工作经验的 Java 后端开发。 从第129天开始,我连续围绕消息实时通知系统写了整体设计、渠道抽象、模板中心、实时推送、异步投递、偏…...
)
别再死记硬背公式了!用VHDL和Quartus II手把手教你玩转一位全加器(附完整源码与仿真)
从零实现数字逻辑:用VHDL在Quartus II中构建全加器的完整指南 当第一次接触数字逻辑设计时,那些抽象的真值表和逻辑表达式常常让人望而生畏。作为一名曾经同样困惑的工程师,我深刻理解初学者面对理论知识与实际工程实现之间的鸿沟。本文将带你…...
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而烦恼吗?XUnity Auto Translator为你提供了…...

电池级硫酸锂粉碎工艺与设备选型全解析
一、硫酸锂粉碎核心需求与特性 1. 硫酸锂基础物性(决定粉碎工艺边界) 形态与硬度:白色结晶 / 颗粒(无水 / 一水),莫氏硬度约 2–3,质地脆、易结块、吸湿性强。 纯度要求:工业级≥99.…...

OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南
OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南 在部署OPNsense防火墙时,文件系统选择往往被忽视,却直接影响系统性能、数据安全和运维效率。UFS和ZFS的抉择不仅关乎安装时的选项勾选,更关系到长期运行的稳定性…...

[实战剖析] 从零构建CSRF攻击:GET与POST请求的攻防博弈
1. CSRF攻击的本质与危害 跨站请求伪造(CSRF)就像有人偷偷用你的手机给朋友发消息。想象你登录了社交网站没有退出,这时访问了恶意网页,它就能冒充你执行加好友、改资料等操作。这种攻击不需要窃取密码,只要浏览器保持…...

STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战
STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战 嵌入式开发中,SPI接口的Flash存储器因其高速、稳定和易用性而广受欢迎。W25Q128作为一款128Mbit容量的SPI Flash芯片,在数据存储、固件升级等场景中扮演着重要角色。然而&#…...

三步完成微信好友关系一键检测:发现谁偷偷删除了你
三步完成微信好友关系一键检测:发现谁偷偷删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你…...

为什么你的Perplexity搜索总返回噪音结果?7步精准提示工程诊断流程
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索结果噪音现象的本质剖析 Perplexity 作为基于大语言模型的语义搜索引擎,其结果页中高频出现的“噪音”并非传统关键词匹配失准所致,而是源于其底层推理机制与用户…...