大模型系列:OpenAI使用技巧_使用OpenAI进行K-means聚类
文章目录
- 1. 使用K-means算法找到聚类
- 2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。
我们使用一个简单的k-means算法来演示如何进行聚类。聚类可以帮助发现数据中有价值的隐藏分组。数据集是在 Get_embeddings_from_dataset Notebook中创建的。
# 导入必要的库
import numpy as np
import pandas as pd
from ast import literal_eval# 数据文件路径
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"# 读取csv文件为DataFrame格式
df = pd.read_csv(datafile_path)# 将embedding列中的字符串转换为numpy数组
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)# 将所有的embedding数组按行堆叠成一个矩阵
matrix = np.vstack(df.embedding.values)# 输出矩阵的形状
matrix.shape
(1000, 1536)
1. 使用K-means算法找到聚类
我们展示了K-means的最简单用法。您可以选择最适合您用例的聚类数量。
# 导入KMeans聚类算法
from sklearn.cluster import KMeans# 设置聚类数目
n_clusters = 4# 初始化KMeans算法,设置聚类数目、初始化方法和随机种子
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)# 使用KMeans算法对数据进行聚类
kmeans.fit(matrix)# 获取聚类标签
labels = kmeans.labels_# 将聚类标签添加到数据框中
df["Cluster"] = labels# 按照聚类标签对数据框进行分组,计算每个聚类的平均分数,并按照平均分数排序
df.groupby("Cluster").Score.mean().sort_values()
/Users/ted/.virtualenvs/openai/lib/python3.9/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warningwarnings.warn(Cluster
0 4.105691
1 4.191176
2 4.215613
3 4.306590
Name: Score, dtype: float64
# 导入必要的库
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt# 初始化t-SNE模型,设置参数
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)# 使用t-SNE模型对数据进行降维
vis_dims2 = tsne.fit_transform(matrix)# 提取降维后的数据的x和y坐标
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]# 针对每个类别,绘制散点图,并标记类别的平均值
for category, color in enumerate(["purple", "green", "red", "blue"]):# 提取属于当前类别的数据的x和y坐标xs = np.array(x)[df.Cluster == category]ys = np.array(y)[df.Cluster == category]# 绘制散点图plt.scatter(xs, ys, color=color, alpha=0.3)# 计算当前类别的平均值avg_x = xs.mean()avg_y = ys.mean()# 标记平均值plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)# 设置图表标题
plt.title("Clusters identified visualized in language 2d using t-SNE")
Text(0.5, 1.0, 'Clusters identified visualized in language 2d using t-SNE')
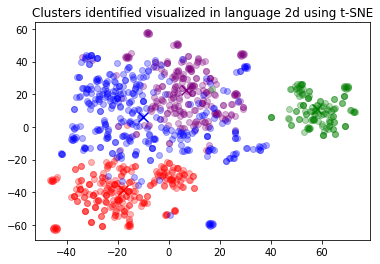
在二维投影中对聚类进行可视化。在这次运行中,绿色聚类(#1)似乎与其他聚类非常不同。让我们看一下每个聚类的几个样本。
2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。
我们将使用text-davinci-003来为聚类命名,基于从该聚类中随机抽取的5个评论样本。
# 导入openai模块import openai# 每个聚类组中的评论数量
rev_per_cluster = 5# 遍历每个聚类组
for i in range(n_clusters):# 输出聚类组的主题print(f"Cluster {i} Theme:", end=" ")# 选取属于该聚类组的评论,并将它们合并成一个字符串reviews = "\n".join(df[df.Cluster == i].combined.str.replace("Title: ", "").str.replace("\n\nContent: ", ": ").sample(rev_per_cluster, random_state=42).values)# 使用openai模块对选取的评论进行主题分析response = openai.Completion.create(engine="text-davinci-003",prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',temperature=0,max_tokens=64,top_p=1,frequency_penalty=0,presence_penalty=0,)# 输出主题分析结果print(response["choices"][0]["text"].replace("\n", ""))# 选取属于该聚类组的样本行,并输出它们的得分、摘要和文本内容sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)for j in range(rev_per_cluster):print(sample_cluster_rows.Score.values[j], end=", ")print(sample_cluster_rows.Summary.values[j], end=": ")print(sample_cluster_rows.Text.str[:70].values[j])# 输出分隔符print("-" * 100)
Cluster 0 Theme: All of the reviews are positive and the customers are satisfied with the product they purchased.
5, Loved these gluten free healthy bars, saved $$ ordering on Amazon: These Kind Bars are so good and healthy & gluten free. My daughter ca
1, Should advertise coconut as an ingredient more prominently: First, these should be called Mac - Coconut bars, as Coconut is the #2
5, very good!!: just like the runts<br />great flavor, def worth getting<br />I even o
5, Excellent product: After scouring every store in town for orange peels and not finding an
5, delicious: Gummi Frogs have been my favourite candy that I have ever tried. of co
----------------------------------------------------------------------------------------------------
Cluster 1 Theme: All of the reviews are about pet food.
2, Messy and apparently undelicious: My cat is not a huge fan. Sure, she'll lap up the gravy, but leaves th
4, The cats like it: My 7 cats like this food but it is a little yucky for the human. Piece
5, cant get enough of it!!!: Our lil shih tzu puppy cannot get enough of it. Everytime she sees the
1, Food Caused Illness: I switched my cats over from the Blue Buffalo Wildnerness Food to this
5, My furbabies LOVE these!: Shake the container and they come running. Even my boy cat, who isn't
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: All of the reviews are positive and express satisfaction with the product.
5, Fog Chaser Coffee: This coffee has a full body and a rich taste. The price is far below t
5, Excellent taste: This is to me a great coffee, once you try it you will enjoy it, this
4, Good, but not Wolfgang Puck good: Honestly, I have to admit that I expected a little better. That's not
5, Just My Kind of Coffee: Coffee Masters Hazelnut coffee used to be carried in a local coffee/pa
5, Rodeo Drive is Crazy Good Coffee!: Rodeo Drive is my absolute favorite and I'm ready to order more! That
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: All of the reviews are about food or drink products.
5, Wonderful alternative to soda pop: This is a wonderful alternative to soda pop. It's carbonated for thos
5, So convenient, for so little!: I needed two vanilla beans for the Love Goddess cake that my husbands
2, bot very cheesy: Got this about a month ago.first of all it smells horrible...it tastes
5, Delicious!: I am not a huge beer lover. I do enjoy an occasional Blue Moon (all o
3, Just ok: I bought this brand because it was all they had at Ranch 99 near us. I
----------------------------------------------------------------------------------------------------
重要的是要注意,聚类不一定与您打算使用它们的目的完全匹配。更多的聚类将关注更具体的模式,而较少的聚类通常会关注数据中最大的差异。
相关文章:
大模型系列:OpenAI使用技巧_使用OpenAI进行K-means聚类
文章目录 1. 使用K-means算法找到聚类2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。 我们使用一个简单的k-means算法来演示如何进行聚类。聚类可以帮助发现数据中有价值的隐藏分组。数据集是在 Get_embeddings_from_dataset Notebook中创建的。 # 导入必要…...
共享单车之数据分析
文章目录 第1关:统计共享单车每天的平均使用时间第2关:统计共享单车在指定地点的每天平均次数第3关:统计共享单车指定车辆每次使用的空闲平均时间第4关:统计指定时间共享单车使用次数第5关:统计共享单车线路流量 第1关…...

Spring的Bean你了解吗
Bean的配置 Spring容器支持XML(常用)和Properties两种格式的配置文件 Spring中XML配置文件的根元素是,中包含了多个子元素,每个子元素定义了一个Bean,并描述了该Bean如何装配到Spring容器中 元素包含了多个属性以及子元素,常用属性及子元素如下所示 i…...
)
MongoDB聚合:$merge 阶段(1)
$merge的用途是把聚合管道产生的结果写入指定的集合,有时候可以用$merge来做物化视图。需要注意,$meger操作必须是聚合管道的最后一个阶段。具体功能有: 能够输出到当前或不同的数据库能够输出到正在聚合的集合(慎重:…...

2. 云原生实战之kubesphere搭建
文章目录 机器介绍centos基本配置安装 VMware Tools设置静态ip关闭防火墙关闭SELinux开启时间同步配置host和hostname 安装kubesphere依赖项安装配置文件准备执行安装命令 机器介绍 在ESXI中准备虚拟机,部署参考官网:https://kubesphere.io/zh/ CentOs…...
main参数传递、反汇编、汇编混合编程
week03 一、main参数传递二、反汇编三、汇编混合编程 一、main参数传递 参考 http://www.cnblogs.com/rocedu/p/6766748.html#SECCLA 在Linux下完成“求命令行传入整数参数的和” 注意C中main: int main(int argc, char *argv[]), 字符串“12” 转为12,可以调用atoi…...
前后端分离nodejs+vue医院预约挂号系统6nrhh
医院预约挂号系统主要有管理员、用户和医生三个功能模块。以下将对这三个功能的作用进行详细的剖析。 运行软件:vscode 前端nodejsvueElementUi 语言 node.js 框架:Express/koa 前端:Vue.js 数据库:mysql 开发软件:VScode/webstorm/hbuiderx均…...
 的几种常用方法)
在pytorch中,读取GPU上张量的数值 (数据从GPU到CPU) 的几种常用方法
1、.cpu() 方法: 使用 .cpu() 方法可以将张量从 GPU 移动到 CPU。这是一种简便的方法,常用于在进行 CPU 上的操作之前将数据从 GPU 取回 import torch# 在 GPU 上创建一个张量 gpu_tensor torch.tensor([1, 2, 3], devicecuda)# 将 GPU 上的张…...
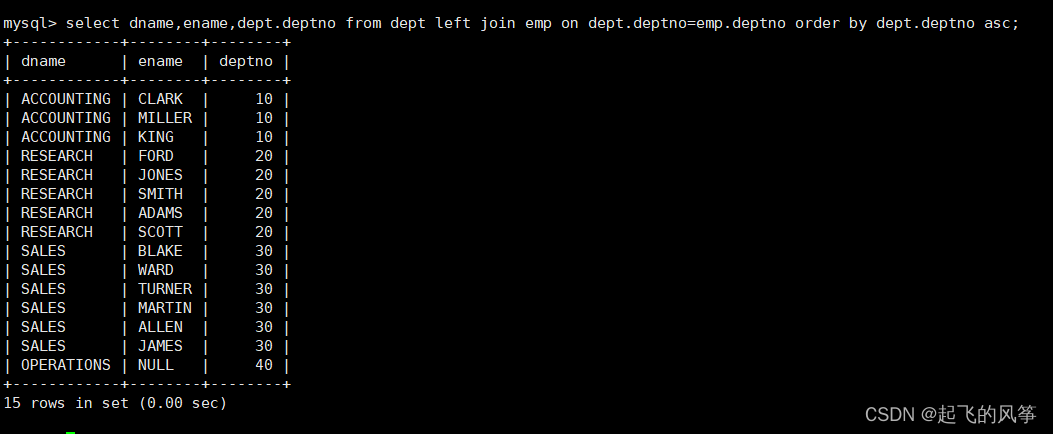
【mysql】—— 表的内连和外连
在MySQL中,内连(INNER JOIN)和外连(OUTER JOIN)是用于联接多个表的操作。接下来,我分别给大家介绍下二者。 目录 (一)内连接 1、什么叫内连接 2、语法格式 3、案例:显…...

VSCode远程开发配置
目录 概要远程开发插件安装开始连接SSH无密码登录开发环境配置 概要 现在很多公司都是直接远程到服务器上写代码,使用远程开发,可以在与生产环境相同的环境中开发、测试和部署代码,减少因环境不同而导致的问题。当下VSCode远程开发是支持的比…...

复数值神经网络可能是深度学习的未来
一、说明 复数这种东西,在人的头脑中似乎抽象、似乎复杂,然而,对于计算机来说,一点也不抽象,不复杂,那么,将复数概念推广到神经网络会是什么结果呢?本篇介绍国外的一些同行的尝试实践,请我们注意观察他们的进展。...
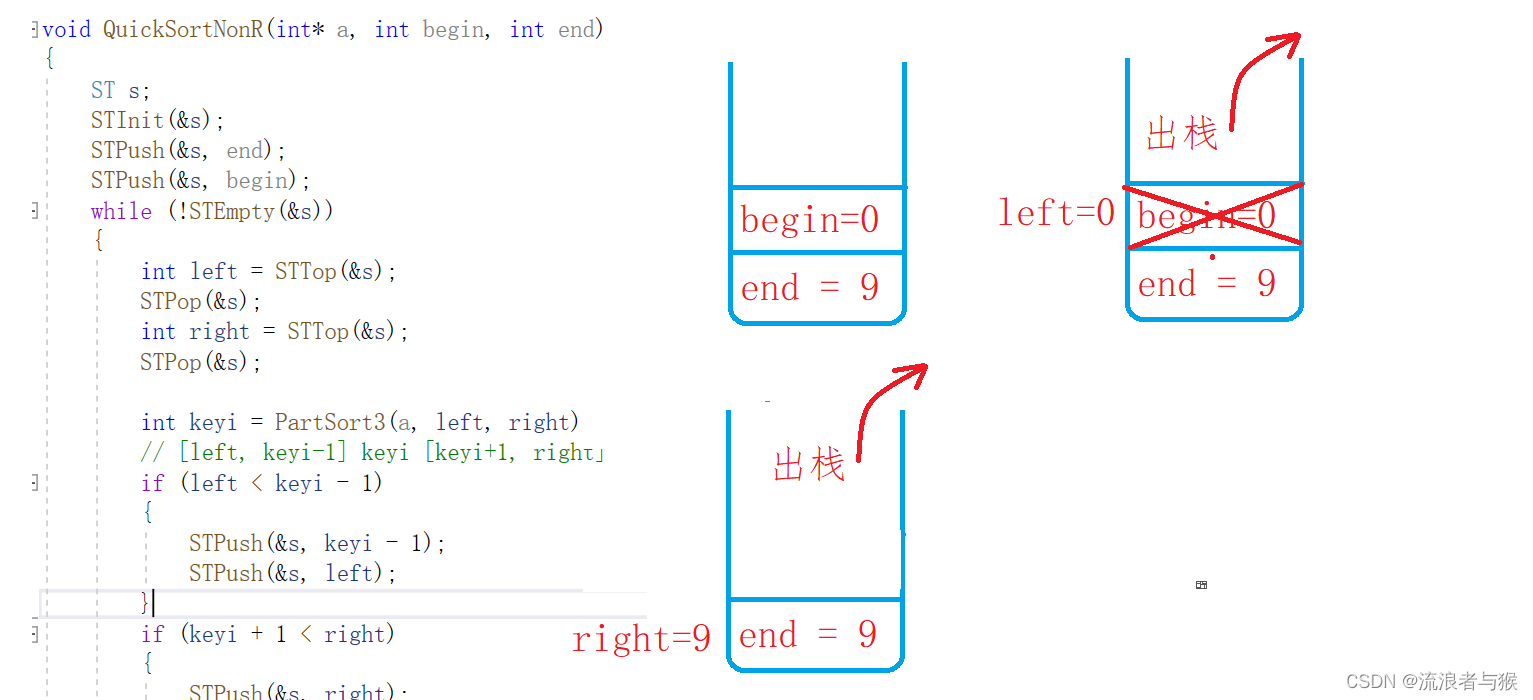
【C语言】数据结构——排序二(快排)
💗个人主页💗 ⭐个人专栏——数据结构学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:数组打印与交换1. 交换排序1.1 基本思想:1.2 冒泡与快排的异同 2. 冒泡排序2.1 基本思想2.2 …...
企业私有云容器化架构
什么是虚拟化: 虚拟化(Virtualization)技术最早出现在 20 世纪 60 年代的 IBM 大型机系统,在70年代的 System 370 系列中逐渐流行起来,这些机器通过一种叫虚拟机监控器(Virtual Machine Monitor,VMM&#x…...
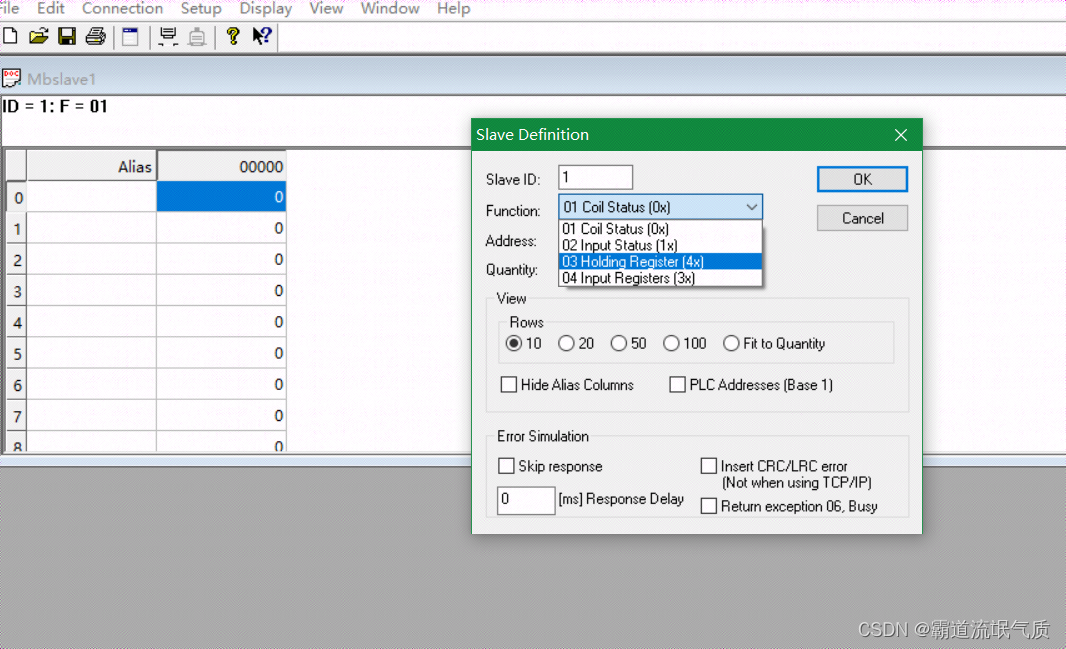
SpringBoot+modbus4j实现ModebusTCP通讯读取数据
场景 Windows上ModbusTCP模拟Master与Slave工具的使用: Windows上ModbusTCP模拟Master与Slave工具的使用-CSDN博客 Modebus TCP Modbus由MODICON公司于1979年开发,是一种工业现场总线协议标准。 1996年施耐德公司推出基于以太网TCP/IP的Modbus协议&…...

Linux性能优化全景指南
Part1 Linux性能优化 1、性能优化性能指标 高并发和响应快对应着性能优化的两个核心指标:吞吐和延时 应用负载角度:直接影响了产品终端的用户体验系统资源角度:资源使用率、饱和度等 性能问题的本质就是系统资源已经到达瓶颈,但…...
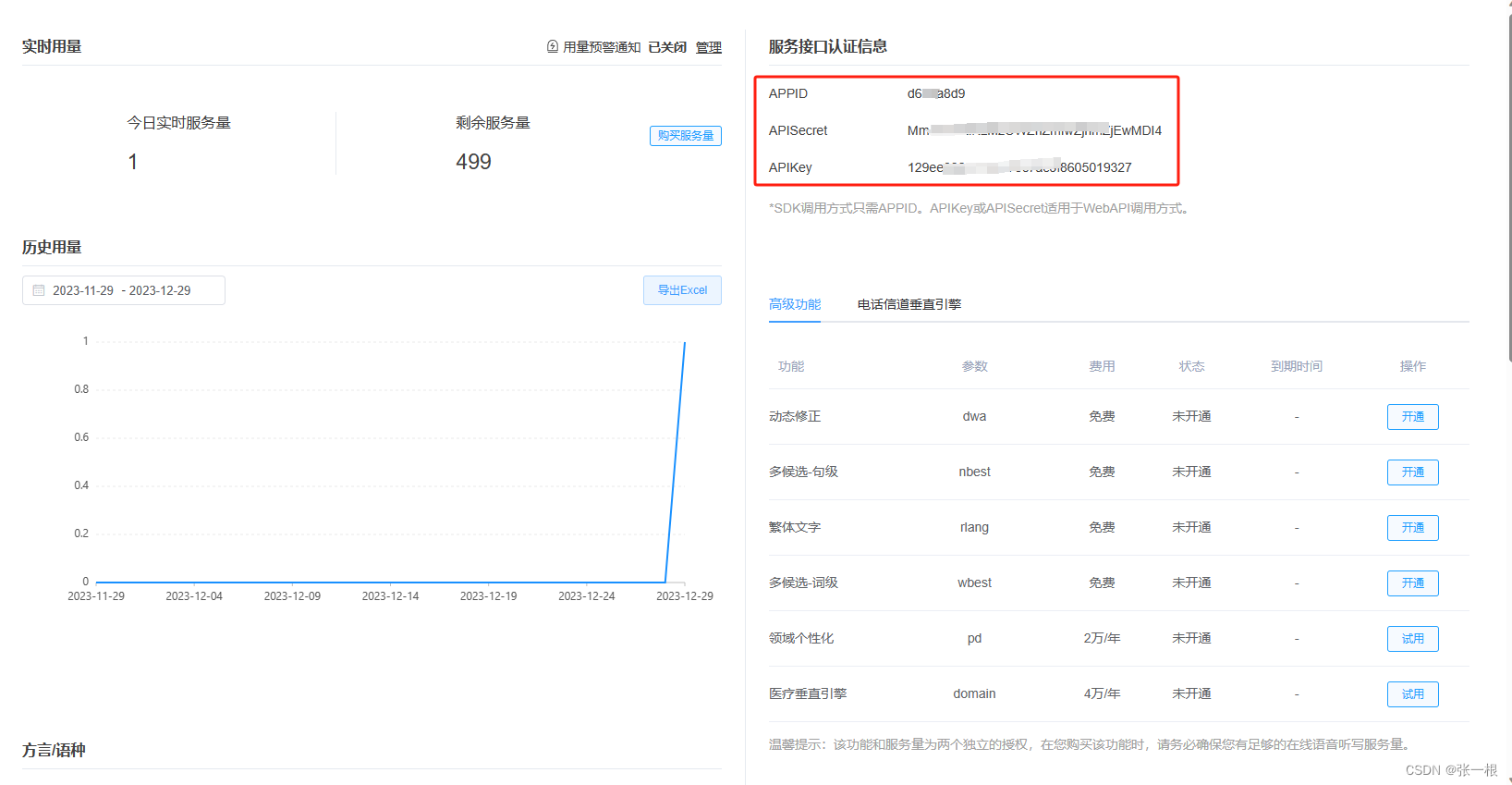
树莓派 ubuntu20.04下 python调讯飞的语音API,语音识别和语音合成
目录 1.环境搭建2.去讯飞官网申请密钥3.语音识别(sst)4.语音合成(tts)5.USB声卡可能报错 1.环境搭建 #环境说明:(尽量在ubuntu下使用, 本次代码均在该环境下实现) sudo apt-get install sox # 安装语音播放软件 pip …...
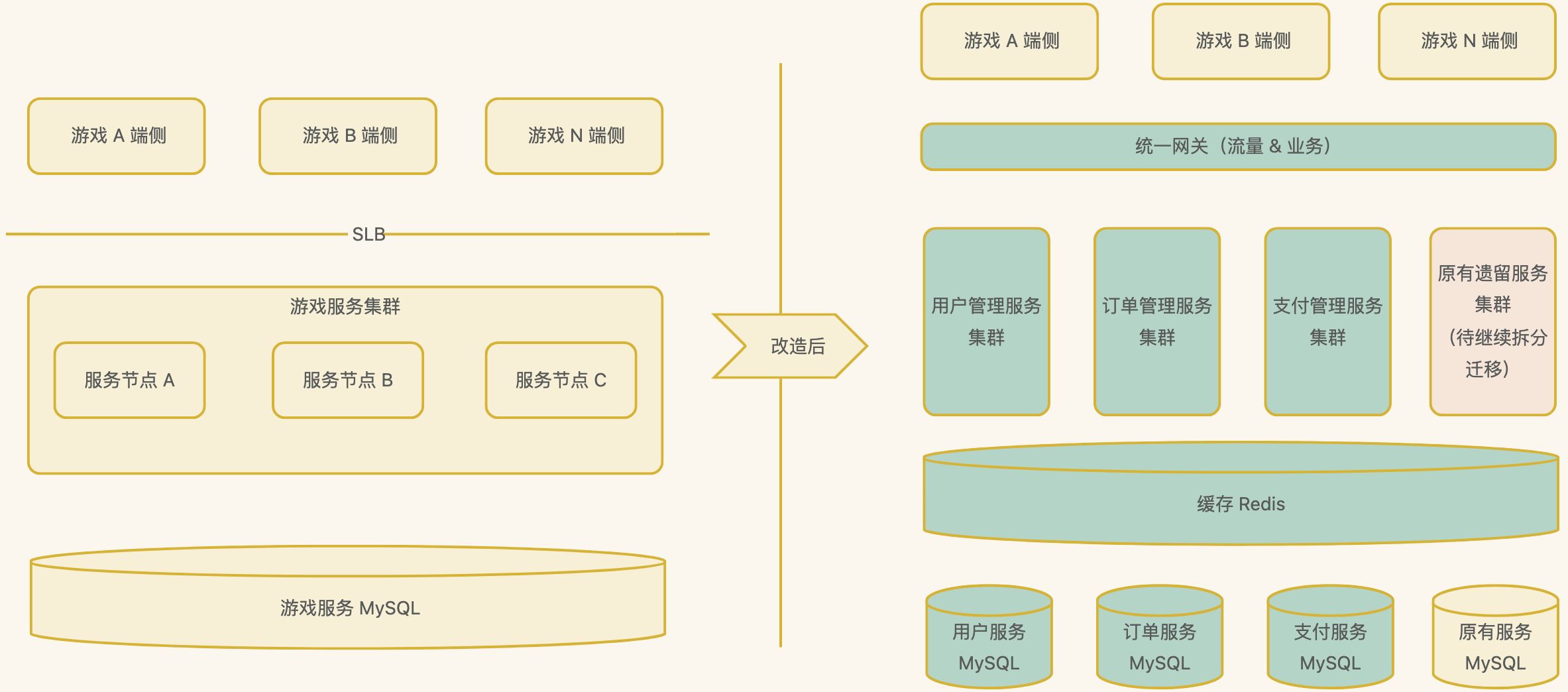
分布式系统架构设计之分布式系统实践案例和未来展望
分布式系统在过去的几十年里经历了长足的发展,从最初的简单分布式架构到今天的微服务、云原生等先进架构,取得了丰硕的成果。本文将通过实际案例分享分布式系统的架构实践,并展望未来可能的发展方向。 一、实践案例 1、微服务化实践 背景 …...
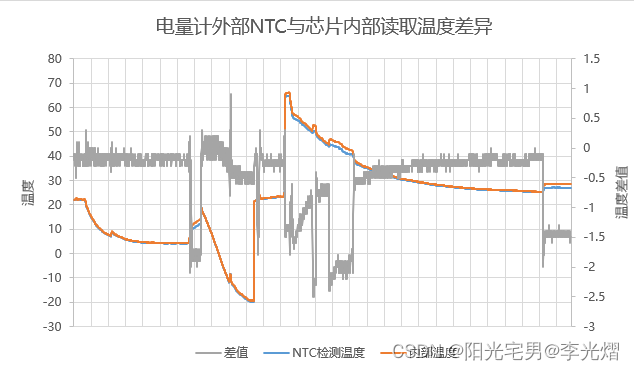
【办公软件】Excel双坐标轴图表
在工作中整理测试数据,往往需要一个图表展示两个差异较大的指标。比如共有三个数据,其中两个是要进行对比的温度值,另一个指标是两个温度的差值,这个差值可能很小。 举个实际的例子:数据如下所示,NTC检测温…...

彻底理解前端安全面试题(1)—— XSS 攻击,3种XSS攻击详解,建议收藏(含源码)
前言 前端关于网络安全看似高深莫测,其实来来回回就那么点东西,我总结一下就是 3 1 4,3个用字母描述的【分别是 XSS、CSRF、CORS】 一个中间人攻击。当然 CORS 同源策略是为了防止攻击的安全策略,其他的都是网络攻击。除了这…...

UE5.1_AI随机漫游
UE5.1_AI随机漫游 目录 UE5.1_AI随机漫游 AI随机漫游方法 方法1:AI角色蓝图直接写方法...

Bifrost三星固件下载器:跨平台技术实现深度解析
Bifrost三星固件下载器:跨平台技术实现深度解析 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 三星设备固件下载与解密过程历来存在技术门槛&#x…...

【ElevenLabs情绪语音实战指南】:3步解锁开心语音API调用、情感强度微调与合规避坑全链路
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs开心情绪语音技术全景概览 核心技术能力 ElevenLabs 的开心情绪语音生成并非简单音调拉升或语速加快,而是基于多任务情感条件建模(Multi-Task Emotional Conditionin…...

安卓手机缓存视频救星:手把手教你将腾讯课堂的.m3u8.sqlite文件转成MP4
安卓手机腾讯课堂缓存视频解密实战:从.m3u8.sqlite到MP4全流程指南 你是否曾在腾讯课堂APP下载了付费课程,却发现缓存文件是一堆无法直接播放的.m3u8.sqlite格式?这些加密文件既不能备份到电脑,也无法在其他设备上观看。本文将彻底…...

二维无金属铁磁半金属AsN2:p轨道自旋电子学的理论突破与计算设计
1. 二维无金属铁磁半金属:一个值得深挖的“潜力股”最近几年,二维材料这个领域真是热闹非凡,从石墨烯一炮而红开始,各种新奇的结构和性质层出不穷。作为一名长期关注计算材料学和自旋电子学的从业者,我一直在寻找那些既…...

Bluetooth 蓝牙协议详解
一、协议简介蓝牙(Bluetooth)短距离无线通信技术,主流分经典蓝牙与BLE 蓝牙 5.0/5.3(低功耗蓝牙),多用于近距离设备配对、数据透传、外设连接,消费电子与便携设备最常用。二、基础参数底层标准&…...

使用Taotoken的Token Plan套餐实现更具成本优势的持续调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken的Token Plan套餐实现更具成本优势的持续调用 对于有稳定大模型调用需求的开发者或团队而言,成本的可预测…...

从实验室到机房:把eNSP里练熟的Telnet AAA配置,无缝迁移到真实华为交换机上
从模拟到实战:华为交换机Telnet AAA配置的迁移指南 当你在eNSP模拟器中反复练习Telnet AAA配置,看着那些绿色指示灯亮起时,是否曾想过:"这些命令在真实设备上真的完全一样吗?"作为一位从实验室走向机房的网络…...

如何5分钟实现Windows系统自动化软件部署:winget-install完整指南
如何5分钟实现Windows系统自动化软件部署:winget-install完整指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_…...

2025最权威的降AI率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 随着人工智能技术迅猛地发展,它在学术研究领域的应用越发深入,对高等…...

3步构建跨平台AI自动化测试:Midscene.js视觉驱动解决方案
3步构建跨平台AI自动化测试:Midscene.js视觉驱动解决方案 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene Midscene.js是一款基于视觉语言模型的跨平台…...