【Java中序列化的原理是什么(解析)】

🍁序列化的原理是什么?
- 🍁典型-----解析
- 🍁拓展知识仓
- 🍁Serializable 和 Externalizable 接门有何不同?
- 🍁如果序列化后的文件或者原始类被篡改,还能被反序列化吗?
- 🍁serialVersionUID 有何用途? 如果没定义会有什么问题?
- 🍁在Java中,有哪些好的序列化框架,有什么好处?
🍁典型-----解析
序列化是将对象转换为可传输格式的过程。是一种数据的持久化手段。一般广泛应用于网络传输,RMI和RPC等场景中。 几乎所有的商用编程语言都有序列化的能力,不管是数据存储到硬盘,还是通过网络的微服务传输,都需要序列化能力。
在Java的序列化机制中,如果是String,枚举或者实现了Serializable接口的类,均可以通过Java的序列化机制将类序列化为符合编码的数据流,然后通过InputStream和OutputStream将内存中的类持久化到硬盘或者网络中;同时,也可以通过反序列化机制将磁盘中的字节码再转换成内存中的类。
如果一个类想被序列化,需要实现Serializable接口。否则将抛出NotSerializableException异常。Serializable接门没有方法或字段,仅用于标识可序列化的语义。
自定义类通过实现Serializable接口做标识,进而在10中实现序列化和反序列化,具体的执行路径如下:
#write0bject -> #writeobjecto(判断类是否是自定义类) -> writeOrdinary0bject(区分Serializable和Externalizable) -> writeSerialData(序列化fields) -> invokewriteobject(反射调用类自己的序列化策略)
其中,在invokeWriteObject的阶段,系统就会处理自定义类的序列化方案。
这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。
看一段代码,对象的序列化和反序列化:
import java.io.*;
import java.util.*; class Employee implements Serializable { private String name; private int age; private Department department; public Employee(String name, int age, Department department) { this.name = name; this.age = age; this.department = department; } public String toString() { return "Employee [name=" + name + ", age=" + age + ", department=" + department + "]"; }
} class Department implements Serializable { private String name; private List<Employee> employees; public Department(String name) { this.name = name; this.employees = new ArrayList<>(); } public void addEmployee(Employee employee) { employees.add(employee); } public String toString() { return "Department [name=" + name + ", employees=" + employees + "]"; }
} public class ComplexSerializationDemo { public static void main(String[] args) throws IOException, ClassNotFoundException { // 创建对象关系图 Department department1 = new Department("HR"); Department department2 = new Department("IT"); Employee employee1 = new Employee("Alice", 25, department1); Employee employee2 = new Employee("Bob", 30, department2); Employee employee3 = new Employee("Charlie", 35, department1); department1.addEmployee(employee1); department1.addEmployee(employee3); department2.addEmployee(employee2); // 序列化对象关系图到文件 FileOutputStream fileOut = new FileOutputStream("complexObject.ser"); ObjectOutputStream out = new ObjectOutputStream(fileOut); out.writeObject(department1); out.writeObject(department2); out.writeObject(employee1); out.writeObject(employee2); out.writeObject(employee3); out.close(); fileOut.close(); System.out.println("对象关系图已序列化到文件complexObject.ser"); // 从文件中反序列化对象关系图 FileInputStream fileIn = new FileInputStream("complexObject.ser"); ObjectInputStream in = new ObjectInputStream(fileIn); Department department1_ = (Department) in.readObject(); Department department2_ = (Department) in.readObject(); Employee employee1_ = (Employee) in.readObject(); Employee employee2_ = (Employee) in.readObject(); Employee employee3_ = (Employee) in.readObject(); in.close(); fileIn.close(); System.out.println("从文件complexObject.ser反序列化的对象关系图:"); System.out.println("Department 1: " + department1_); System.out.println("Department 2: " + department2_); System.out.println("Employee 1: " + employee1_); System.out.println("Employee 2: " + employee2_); System.out.println("Employee 3: " + employee3_); }
}
🍁拓展知识仓
🍁Serializable 和 Externalizable 接门有何不同?
类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
当试图对一个对象进行序列化的时候,如果遇到不支持 Serializable 接口的对象。在此情况下,将抛出NotSerializableException。
如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该实现Java.io.Serializable接口。
Externalizable继承了Serializable,该接口中定义了两个抽象方法: writeExternal()与readExternal()。当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法,如果没有在这两个方法中定义序列化实现细节,那么序列化之后,对象内容为空。实现Externalizable接口的类必须要提供一个public的无参的构造器。
所以,实现Externalizable,并实现writeExternal0和readExternal()方法可以指定序列化哪些属性。
🍁如果序列化后的文件或者原始类被篡改,还能被反序列化吗?
🍁serialVersionUID 有何用途? 如果没定义会有什么问题?
序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。
把Java对象序列化成可存诸或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这人对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
但是,虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化ID 是否 致,即serialVersionUID要求 一致。
在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。这样做是为了保证安全,因为文件存储中的内容可能被篡改。
当实现iava.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件没有发生变化,就算重偏译多次,serialVersionUID也不会变化的。但是,如果发生了变化,那么这个文件对应的serialVersionUID也就会发生变化。
基于以上原理,如果我们一个类实现了Serializable接口,但是没有定义serialVersionUID,然后序列化,在序列化之后,由于某些原因,我们对该类做了变更,重新启动应用后,我们相对之前序列化过的对象进行反序列化的话就会报错。
看一段代码,如何使用自定义的序列化方法,以及如何处理序列化过程中的异常:
import java.io.*;
import java.util.*; class Employee implements Serializable { private static final long serialVersionUID = 1L; private String name; private int age; private Set<String> skills; public Employee(String name, int age, Set<String> skills) { this.name = name; this.age = age; this.skills = skills; } public void displayInfo() { System.out.println("Name: " + name); System.out.println("Age: " + age); System.out.println("Skills: " + skills); } // 自定义的序列化方法 private void writeObject(ObjectOutputStream out) throws IOException { out.writeUTF(name); out.writeInt(age); out.writeObject(skills); } // 自定义的反序列化方法 private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException { name = in.readUTF(); age = in.readInt(); skills = (Set<String>) in.readObject(); }
} public class SerializationDemo { public static void main(String[] args) { try { // 创建一个 Employee 对象并序列化 Set<String> skills = new HashSet<>(); skills.add("Java"); skills.add("Python"); Employee employee = new Employee("John", 25, skills); ByteArrayOutputStream baos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(baos); employee.writeObject(oos); // 使用自定义的序列化方法 oos.close(); // 反序列化 Employee 对象(确保使用相同的 serialVersionUID) ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bais); Employee deserializedEmployee = new Employee("", 0, new HashSet<>()); // 创建一个新的 Employee 对象用于反序列化 deserializedEmployee.readObject(ois); // 使用自定义的反序列化方法 ois.close(); deserializedEmployee.displayInfo(); // 输出员工的详细信息 } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } }
}
在上面的示例中,为 Employee 类实现了 writeObject 和 readObject 方法,以自定义序列化和反序列化的过程。我们在 writeObject 方法中使用了 ObjectOutputStream 的 writeUTF、writeInt 和 writeObject 方法来写入员工的姓名、年龄和技能集合。在 readObject 方法中,我们使用 ObjectInputStream 的 readUTF、readInt 和 readObject 方法来读取这些值。我们还创建了一个新的 Employee 对象用于反序列化,并调用了自定义的反序列化方法。这个示例展示了如何处理序列化和反序列化过程中的异常,并展示了如何使用自定义的序列化方法来控制对象的序列化和反序列化过程。
🍁在Java中,有哪些好的序列化框架,有什么好处?
Java中常用的序列化框架:
java、 kryo、hessian、 protostuff、 gson、fastjson等。
Kryo: 速度快,序列化后体积小: 跨语言支持较复杂
Hessian: 默认支持跨语言: 效率不高
Protostuff: 速度快,基于protobuf; 需静态编译
Protostuff-Runtime: 无需静态编译,但序列化前需预先传入schema; 不支持无默认构造函数的类,反序列化时需用户自己初始化序列化后的对象,其只负责将该对象进行赋值
Java: 使用方便,可序列化所有类;速度慢,占空间
相关文章:
【Java中序列化的原理是什么(解析)】
🍁序列化的原理是什么? 🍁典型-----解析🍁拓展知识仓🍁Serializable 和 Externalizable 接门有何不同? 🍁如果序列化后的文件或者原始类被篡改,还能被反序列化吗?🍁serialVersionU…...
冠赢互娱基于 OpenKrusieGame 实现游戏云原生架构升级
作者:力铭 关于冠赢互娱 冠赢互娱是一家集手游、网游、VR 游戏等研发、发行于一体的游戏公司,旗下官方正版授权的传奇类手游——《仙境传奇》系列深受广大玩家们的喜爱。基于多年 MMORPG 类型游戏的自研与运营经验,冠赢互娱正式推出了 2D M…...

Mybatis 动态 SQL - trim, where, set
之前的例子都巧妙地避开了一个臭名昭著的动态SQL挑战。考虑一下如果我们回到之前的“if”例子,但这次我们将“ACTIVE 1”也作为一个动态条件。 <select id"findActiveBlogLike"resultType"Blog">SELECT * FROM BLOGWHERE<if test&qu…...
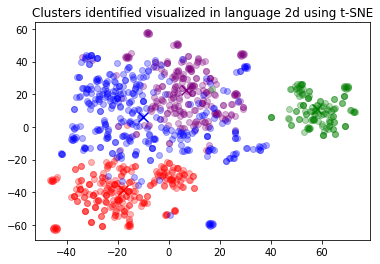
大模型系列:OpenAI使用技巧_使用OpenAI进行K-means聚类
文章目录 1. 使用K-means算法找到聚类2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。 我们使用一个简单的k-means算法来演示如何进行聚类。聚类可以帮助发现数据中有价值的隐藏分组。数据集是在 Get_embeddings_from_dataset Notebook中创建的。 # 导入必要…...
共享单车之数据分析
文章目录 第1关:统计共享单车每天的平均使用时间第2关:统计共享单车在指定地点的每天平均次数第3关:统计共享单车指定车辆每次使用的空闲平均时间第4关:统计指定时间共享单车使用次数第5关:统计共享单车线路流量 第1关…...

Spring的Bean你了解吗
Bean的配置 Spring容器支持XML(常用)和Properties两种格式的配置文件 Spring中XML配置文件的根元素是,中包含了多个子元素,每个子元素定义了一个Bean,并描述了该Bean如何装配到Spring容器中 元素包含了多个属性以及子元素,常用属性及子元素如下所示 i…...
)
MongoDB聚合:$merge 阶段(1)
$merge的用途是把聚合管道产生的结果写入指定的集合,有时候可以用$merge来做物化视图。需要注意,$meger操作必须是聚合管道的最后一个阶段。具体功能有: 能够输出到当前或不同的数据库能够输出到正在聚合的集合(慎重:…...

2. 云原生实战之kubesphere搭建
文章目录 机器介绍centos基本配置安装 VMware Tools设置静态ip关闭防火墙关闭SELinux开启时间同步配置host和hostname 安装kubesphere依赖项安装配置文件准备执行安装命令 机器介绍 在ESXI中准备虚拟机,部署参考官网:https://kubesphere.io/zh/ CentOs…...
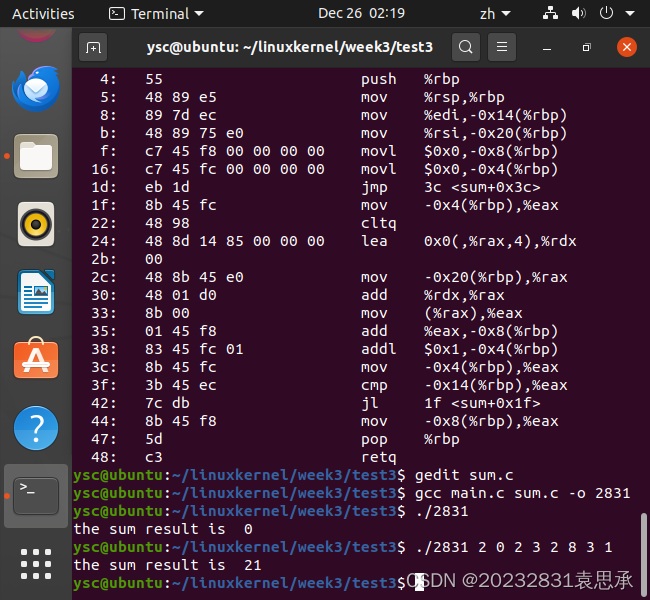
main参数传递、反汇编、汇编混合编程
week03 一、main参数传递二、反汇编三、汇编混合编程 一、main参数传递 参考 http://www.cnblogs.com/rocedu/p/6766748.html#SECCLA 在Linux下完成“求命令行传入整数参数的和” 注意C中main: int main(int argc, char *argv[]), 字符串“12” 转为12,可以调用atoi…...
前后端分离nodejs+vue医院预约挂号系统6nrhh
医院预约挂号系统主要有管理员、用户和医生三个功能模块。以下将对这三个功能的作用进行详细的剖析。 运行软件:vscode 前端nodejsvueElementUi 语言 node.js 框架:Express/koa 前端:Vue.js 数据库:mysql 开发软件:VScode/webstorm/hbuiderx均…...
 的几种常用方法)
在pytorch中,读取GPU上张量的数值 (数据从GPU到CPU) 的几种常用方法
1、.cpu() 方法: 使用 .cpu() 方法可以将张量从 GPU 移动到 CPU。这是一种简便的方法,常用于在进行 CPU 上的操作之前将数据从 GPU 取回 import torch# 在 GPU 上创建一个张量 gpu_tensor torch.tensor([1, 2, 3], devicecuda)# 将 GPU 上的张…...
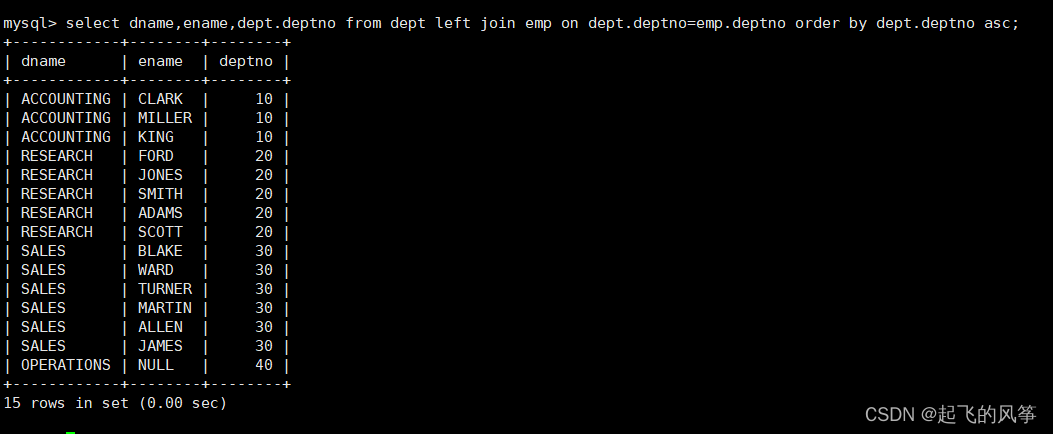
【mysql】—— 表的内连和外连
在MySQL中,内连(INNER JOIN)和外连(OUTER JOIN)是用于联接多个表的操作。接下来,我分别给大家介绍下二者。 目录 (一)内连接 1、什么叫内连接 2、语法格式 3、案例:显…...

VSCode远程开发配置
目录 概要远程开发插件安装开始连接SSH无密码登录开发环境配置 概要 现在很多公司都是直接远程到服务器上写代码,使用远程开发,可以在与生产环境相同的环境中开发、测试和部署代码,减少因环境不同而导致的问题。当下VSCode远程开发是支持的比…...

复数值神经网络可能是深度学习的未来
一、说明 复数这种东西,在人的头脑中似乎抽象、似乎复杂,然而,对于计算机来说,一点也不抽象,不复杂,那么,将复数概念推广到神经网络会是什么结果呢?本篇介绍国外的一些同行的尝试实践,请我们注意观察他们的进展。...
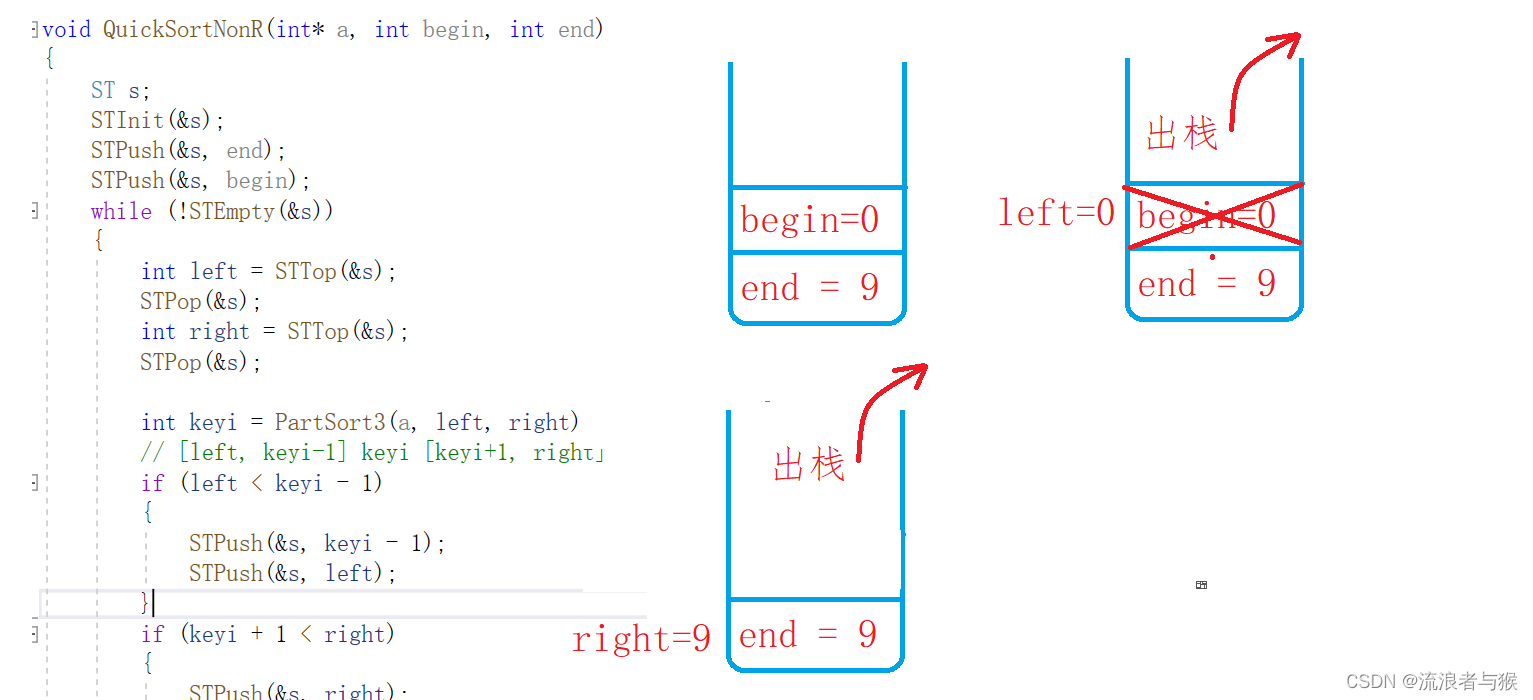
【C语言】数据结构——排序二(快排)
💗个人主页💗 ⭐个人专栏——数据结构学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:数组打印与交换1. 交换排序1.1 基本思想:1.2 冒泡与快排的异同 2. 冒泡排序2.1 基本思想2.2 …...
企业私有云容器化架构
什么是虚拟化: 虚拟化(Virtualization)技术最早出现在 20 世纪 60 年代的 IBM 大型机系统,在70年代的 System 370 系列中逐渐流行起来,这些机器通过一种叫虚拟机监控器(Virtual Machine Monitor,VMM&#x…...
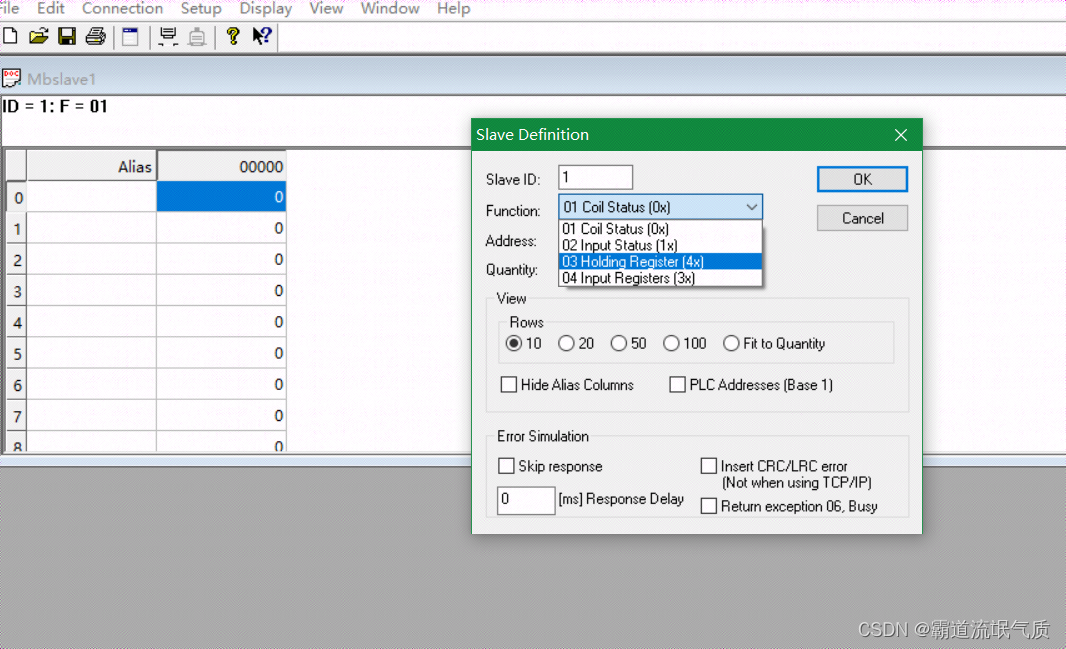
SpringBoot+modbus4j实现ModebusTCP通讯读取数据
场景 Windows上ModbusTCP模拟Master与Slave工具的使用: Windows上ModbusTCP模拟Master与Slave工具的使用-CSDN博客 Modebus TCP Modbus由MODICON公司于1979年开发,是一种工业现场总线协议标准。 1996年施耐德公司推出基于以太网TCP/IP的Modbus协议&…...

Linux性能优化全景指南
Part1 Linux性能优化 1、性能优化性能指标 高并发和响应快对应着性能优化的两个核心指标:吞吐和延时 应用负载角度:直接影响了产品终端的用户体验系统资源角度:资源使用率、饱和度等 性能问题的本质就是系统资源已经到达瓶颈,但…...
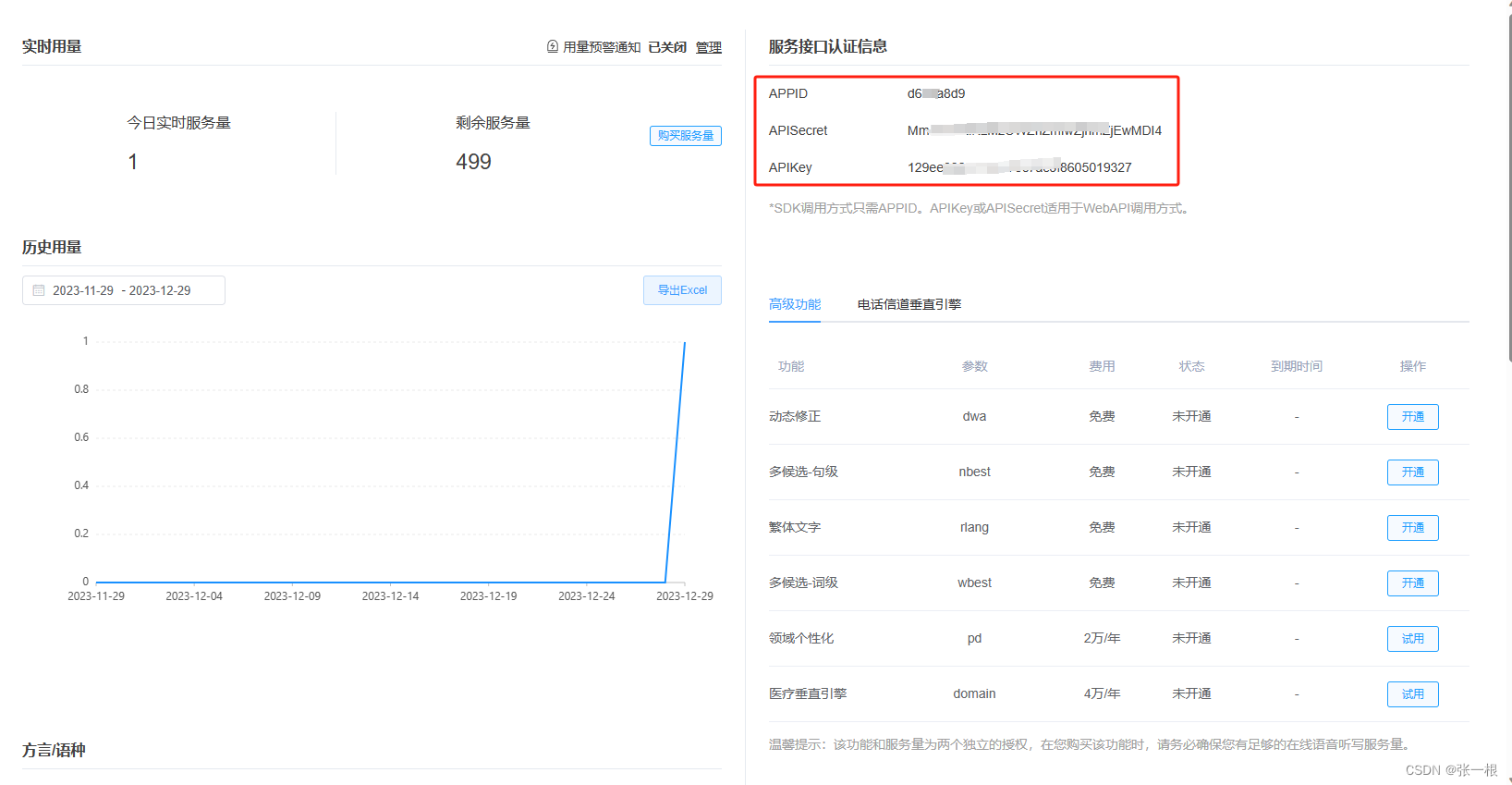
树莓派 ubuntu20.04下 python调讯飞的语音API,语音识别和语音合成
目录 1.环境搭建2.去讯飞官网申请密钥3.语音识别(sst)4.语音合成(tts)5.USB声卡可能报错 1.环境搭建 #环境说明:(尽量在ubuntu下使用, 本次代码均在该环境下实现) sudo apt-get install sox # 安装语音播放软件 pip …...
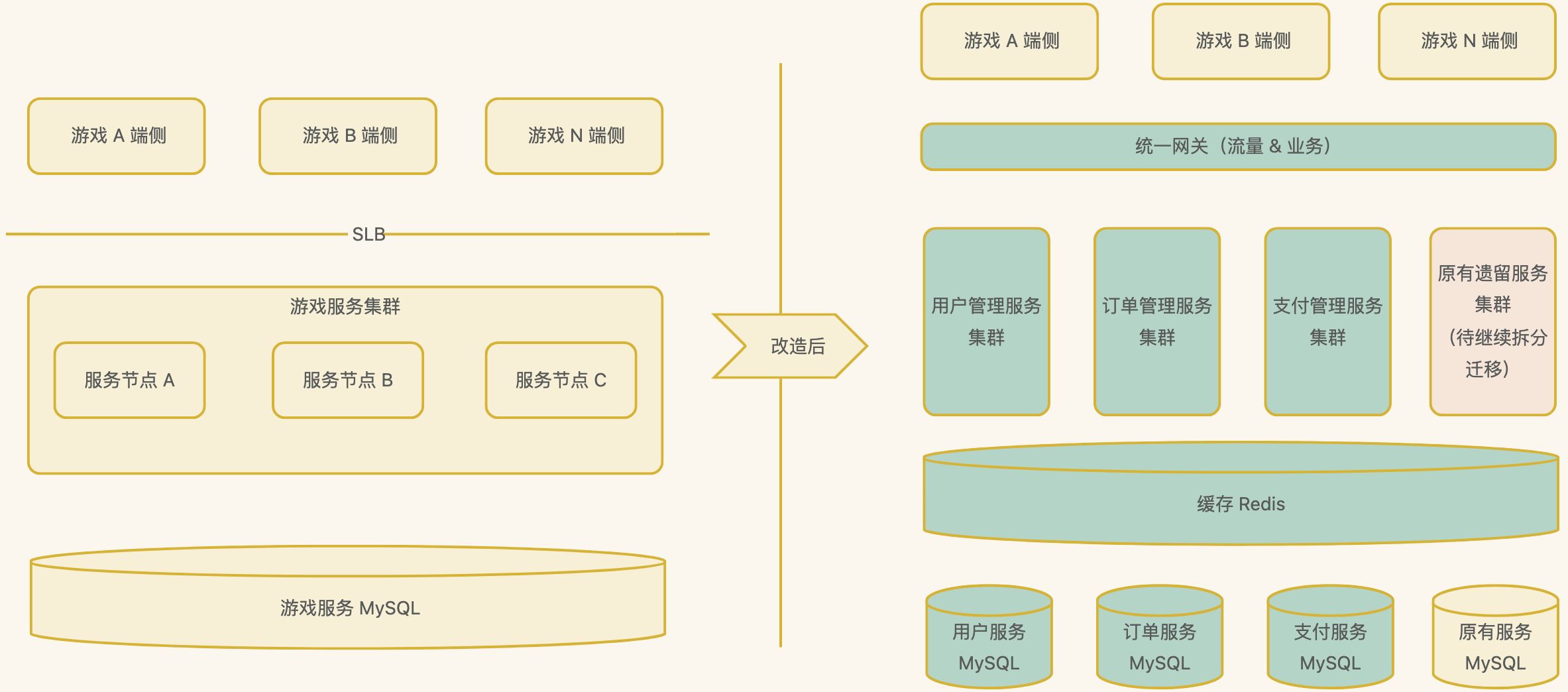
分布式系统架构设计之分布式系统实践案例和未来展望
分布式系统在过去的几十年里经历了长足的发展,从最初的简单分布式架构到今天的微服务、云原生等先进架构,取得了丰硕的成果。本文将通过实际案例分享分布式系统的架构实践,并展望未来可能的发展方向。 一、实践案例 1、微服务化实践 背景 …...
)
别再乱装JDK了!Win11下用Eclipse Temurin OpenJDK 17的正确姿势(附路径避坑指南)
Win11开发者必看:Eclipse Temurin OpenJDK 17终极配置指南 刚接触Java开发的工程师小张最近遇到件怪事——明明按照教程安装了JDK,运行项目时却总是报错"找不到主类"。折腾两天后才发现,问题出在安装路径里的一个中文字符。这种看…...
)
CnDataSeed 发布:中国城市公共服务空间匹配数据库(CUSMD)
一、数据简介透视城市公共服务供需格局,量化空间公平与发展质量!在城市高质量发展与共同富裕持续推进的背景下,公共服务体系的评价标准正在从“资源供给规模”逐步转向“居民真实可达体验”。教育、医疗、文化体育、交通与公共安全等公共服务…...

3分钟掌握Mermaid:用代码思维绘制专业图表的核心技巧
3分钟掌握Mermaid:用代码思维绘制专业图表的核心技巧 【免费下载链接】mermaid mermaid-js/mermaid: 是一个用于生成图表和流程图的 Markdown 渲染器,支持多种图表类型和丰富的样式。适合对 Markdown、图表和流程图以及想要使用 Markdown 绘制图表和流程…...

OpenClaw自动化写作:用nanobot生成技术文档草稿
OpenClaw自动化写作:用nanobot生成技术文档草稿 1. 为什么需要自动化写作助手 作为一个经常需要撰写技术文档的开发者,我长期被两个问题困扰:一是从大纲到完整内容的填充过程耗时费力,二是反复检查格式和语法错误消耗大量精力。…...

零代码基础也能用:万物识别-中文-通用领域镜像一键部署教程
零代码基础也能用:万物识别-中文-通用领域镜像一键部署教程 1. 开箱即用的图片识别神器 想象一下这样的场景:你刚拍了一张照片,还没来得及细看,AI就已经告诉你画面里有什么——这不是科幻电影,而是"万物识别-中…...

从L298到自举H桥:深入聊聊直流电机驱动方案的演进与选型心得
从L298到自举H桥:直流电机驱动方案的技术演进与工程实践 在机器人底盘、自动化产线和智能硬件开发中,直流电机驱动电路的设计往往决定着整个系统的性能天花板。十年前我们可能还在用L298这类经典驱动芯片,如今工程师们的工具箱里已经出现了IR…...

微信H5页面如何通过wx-open-launch-weapp标签跳转小程序?完整配置指南
微信H5跳转小程序全链路实战:从零配置wx-open-launch-weapp标签 在移动互联网生态中,微信H5与小程序的无缝跳转已成为提升用户体验的关键技术节点。许多开发者首次接触wx-open-launch-weapp标签时,往往会在业务域名验证、HTTPS部署等环节遭遇…...

Vulkan与OpenGL深度解析——现代图形渲染的技术演进
1. 从OpenGL到Vulkan:图形渲染的进化之路 还记得我第一次接触图形编程时,OpenGL就像一位和蔼的老教授,把复杂的GPU操作封装成简单的API调用。但随着项目复杂度提升,我逐渐发现这位"老教授"的教学方式有些过时——它隐藏…...

手把手教你用Dockerfile为Ubuntu 18.04镜像定制Python+OpenCV开发环境
从零构建PythonOpenCV的Docker开发环境:最佳实践指南 在计算机视觉和机器学习项目中,一个标准化、可复现的开发环境至关重要。Docker作为容器化技术的代表,能够完美解决"在我机器上能跑"的经典难题。本文将手把手教你如何基于Ubunt…...

ESLyric歌词源一站式配置:Foobar2000多平台格式转换高效解决方案
ESLyric歌词源一站式配置:Foobar2000多平台格式转换高效解决方案 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource ESLyric歌词源是Foobar2000播…...