【JaveWeb教程】(18) MySQL数据库开发之 MySQL数据库设计-DDL 如何查询、创建、使用、删除数据库数据表 详细代码示例讲解
目录
- 2. 数据库设计-DDL
- 2.1 项目开发流程
- 2.2 数据库操作
- 2.2.1 查询数据库
- 2.2.2 创建数据库
- 2.2.3 使用数据库
- 2.2.4 删除数据库
- 2.3 图形化工具
- 2.3.1 介绍
- 2.3.2 安装
- 2.3.3 使用
- 2.2.3.1 连接数据库
- 2.2.3.2 操作数据库
- 2.3 表操作
- 2.3.1 创建
- 2.3.1.1 语法
- 2.3.1.2 约束
- 2.3.1.3 数据类型
- 2.3.1.4 案例
- 2.3.1.5 设计表流程
- 2.3.2 查询
- 2.3.3 修改
- 2.3.4 删除

2. 数据库设计-DDL
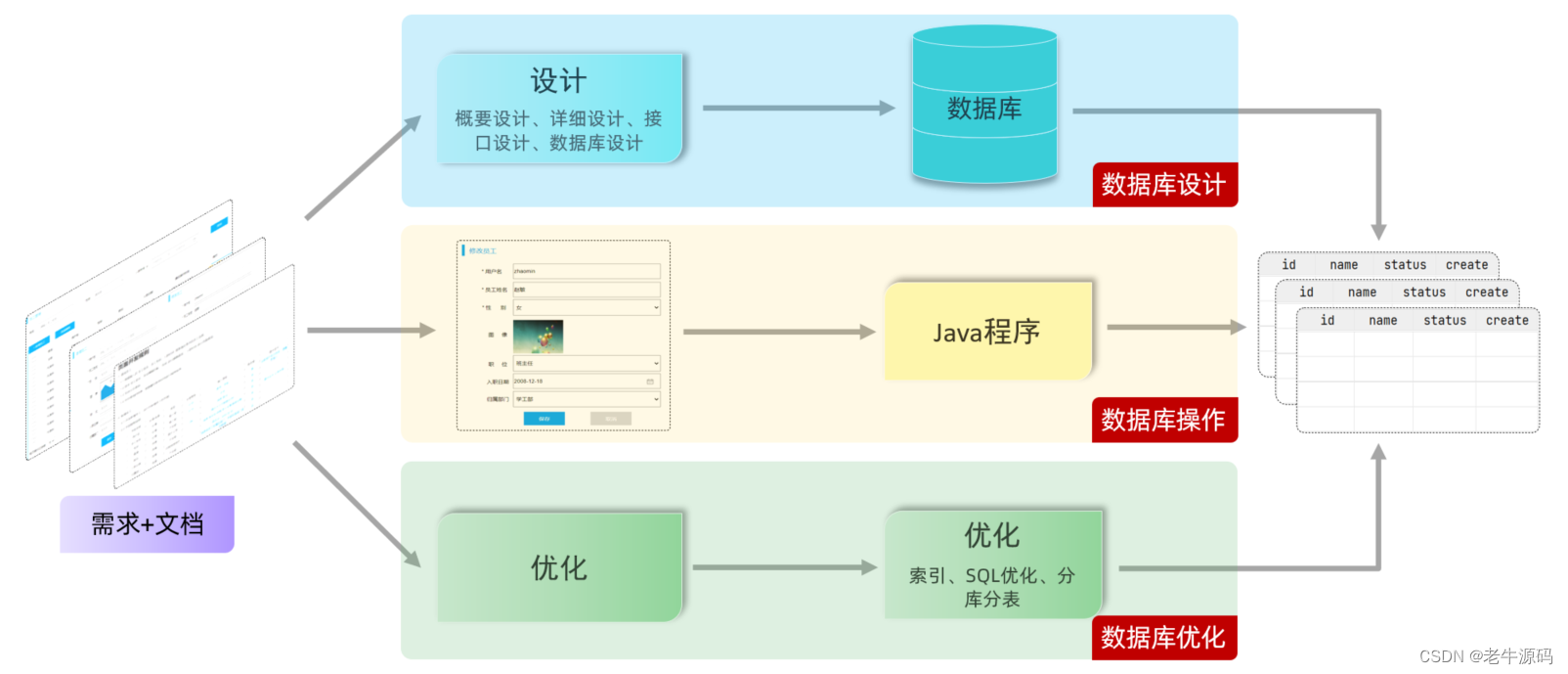
下面我们就正式的进入到SQL语句的学习,在学习之前先给大家介绍一下我们要开发一个项目,整个开发流程是什么样的,以及在流程当中哪些环节会涉及到数据库。
2.1 项目开发流程
需求文档:
- 在我们开发一个项目或者项目当中的某个模块之前,会先会拿到产品经理给我们提供的页面原型及需求文档。
设计:
- 拿到产品原型和需求文档之后,我们首先要做的不是编码,而是要先进行项目的设计,其中就包括概要设计、详细设计、接口设计、数据库设计等等。
- 数据库设计根据产品原型以及需求文档,要分析各个模块涉及到的表结构以及表结构之间的关系,以及表结构的详细信息。最终我们需要将数据库以及数据库当中的表结构设计创建出来。
开发/测试:
- 参照页面原型和需求进行编码,实现业务功能。在这个过程当中,我们就需要来操作设计出来的数据库表结构,来完成业务的增删改查操作等。
部署上线:
- 在项目的功能开发测试完成之后,项目就可以上线运行了,后期如果项目遇到性能瓶颈,还需要对项目进行优化。优化很重要的一个部分就是数据库的优化,包括数据库当中索引的建立、SQL 的优化、分库分表等操作。
在上述的流程当中,针对于数据库来说,主要包括三个阶段:
- 数据库设计阶段
- 参照页面原型以及需求文档设计数据库表结构
- 数据库操作阶段
- 根据业务功能的实现,编写SQL语句对数据表中的数据进行增删改查操作
- 数据库优化阶段
- 通过数据库的优化来提高数据库的访问性能。优化手段:索引、SQL优化、分库分表等
接下来我们就先来学习第一部分数据库的设计,而数据库的设计就是来定义数据库,定义表结构以及表中的字段。
2.2 数据库操作
我们在进行数据库设计,需要使用到刚才所介绍SQL分类中的DDL语句。
DDL英文全称是Data Definition Language(数据定义语言),用来定义数据库对象(数据库、表)。
DDL中数据库的常见操作:查询、创建、使用、删除。
2.2.1 查询数据库
查询所有数据库:
show databases;
命令行中执行效果如下:

查询当前数据库:
select database();
命令行中执行效果如果:

我们要操作某一个数据库,必须要切换到对应的数据库中。
通过指令:select database() ,就可以查询到当前所处的数据库
2.2.2 创建数据库
语法:
create database [ if not exists ] 数据库名;
案例: 创建一个itcast数据库。
create database itcast;
命令行执行效果如下:

注意:在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错。

- 可以使用if not exists来避免这个问题
-- 数据库不存在,则创建该数据库;如果存在则不创建
create database if not extists itcast;
命令行执行效果如下: 
2.2.3 使用数据库
语法:
use 数据库名 ;
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则不能操作。
案例:切换到itcast数据
use itcast;
命令执行效果如下:

2.2.4 删除数据库
语法:
drop database [ if exists ] 数据库名 ;
如果删除一个不存在的数据库,将会报错。
可以加上参数 if exists ,如果数据库存在,再执行删除,否则不执行删除。
案例:删除itcast数据库
drop database if exists itcast; -- itcast数据库存在时删除
命令执行效果如下:

说明:上述语法中的database,也可以替换成 schema
- 如:create schema db01;
- 如:show schemas;

2.3 图形化工具
2.3.1 介绍
前面我们讲解了DDL中关于数据库操作的SQL语句,在我们编写这些SQL时,都是在命令行当中完成的。大家在练习的时候应该也感受到了,在命令行当中来敲这些SQL语句很不方便,主要的原因有以下 3 点:
- 没有任何代码提示。(全靠记忆,容易敲错字母造成执行报错)
- 操作繁琐,影响开发效率。(所有的功能操作都是通过SQL语句来完成的)
- 编写过的SQL代码无法保存。
在项目开发当中,通常为了提高开发效率,都会借助于现成的图形化管理工具来操作数据库。
目前MySQL主流的图形化界面工具有以下几种:
DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
官网: https://www.jetbrains.com/zh-cn/datagrip/
2.3.2 安装
安装: 参考资料中提供的《DataGrip安装手册》
说明:DataGrip这款工具可以不用安装,因为Jetbrains公司已经将DataGrip这款工具的功能已经集成到了 IDEA当中,所以我们就可以使用IDEA来作为一款图形化界面工具来操作Mysql数据库。
2.3.3 使用
2.2.3.1 连接数据库
1、打开IDEA自带的Database
2、配置MySQL
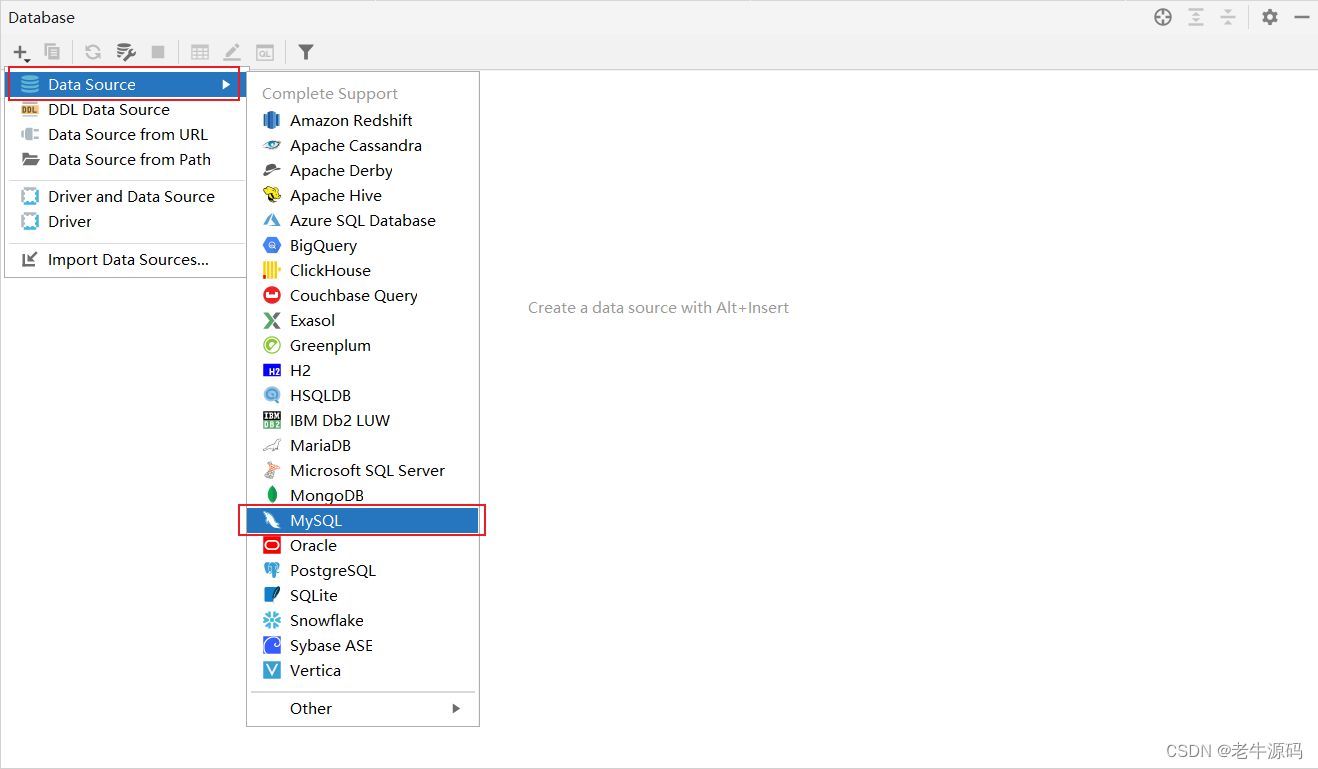
3、输入相关信息
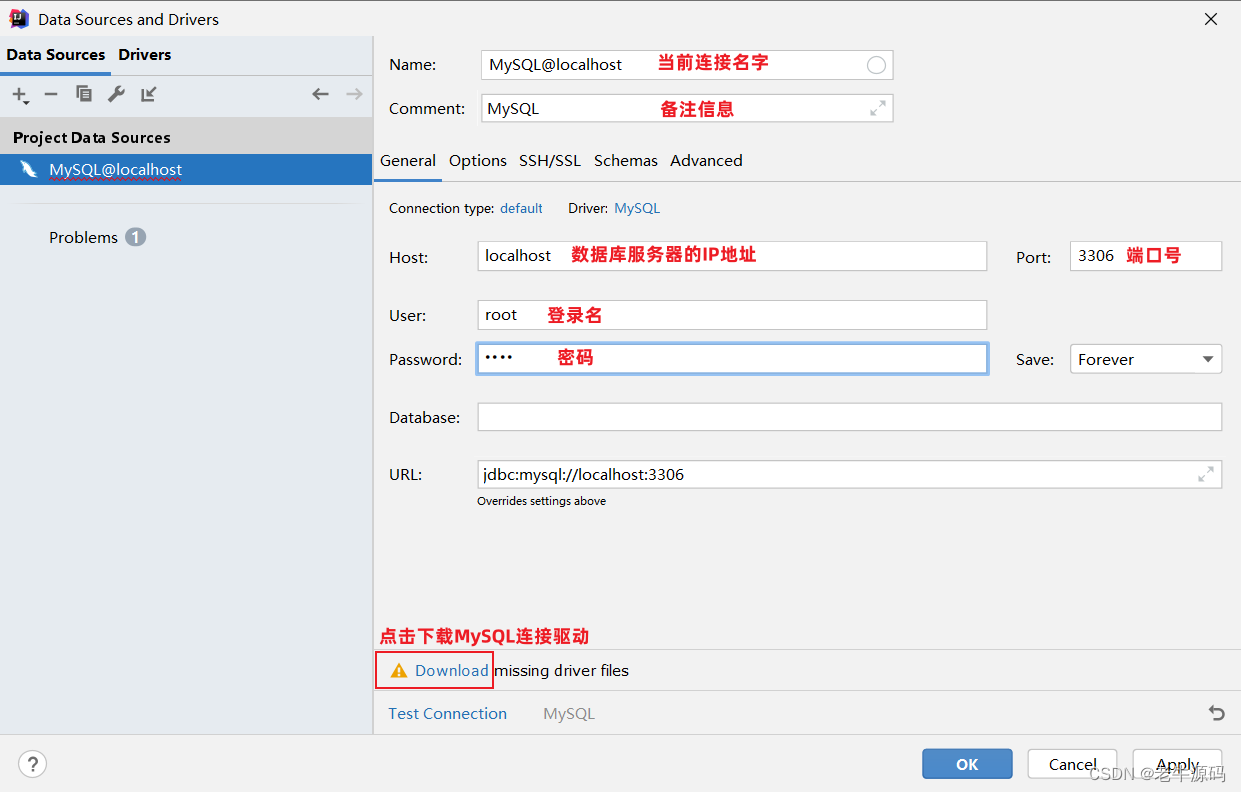
4、下载MySQL连接驱动
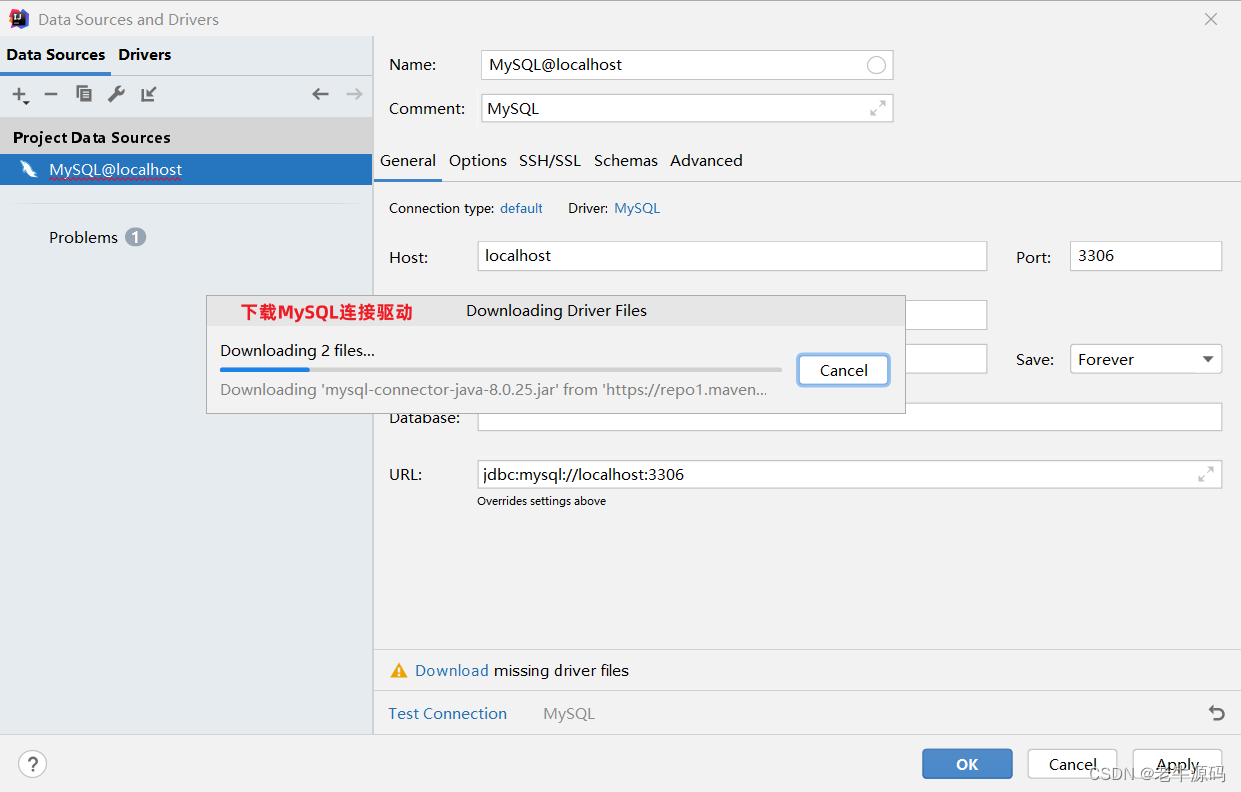
5、测试数据库连接
6、保存配置
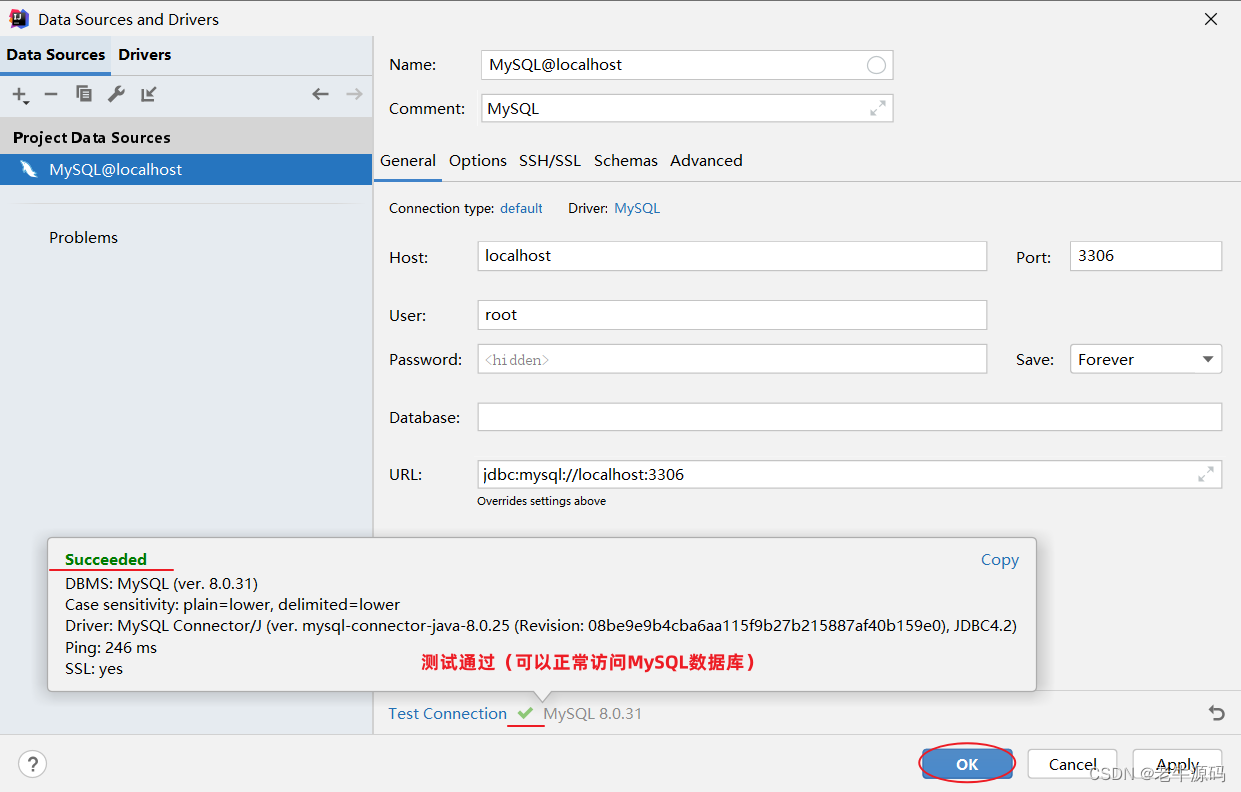
默认情况下,连接上了MySQL数据库之后, 数据库并没有全部展示出来。 需要选择要展示哪些数据库。具体操作如下:
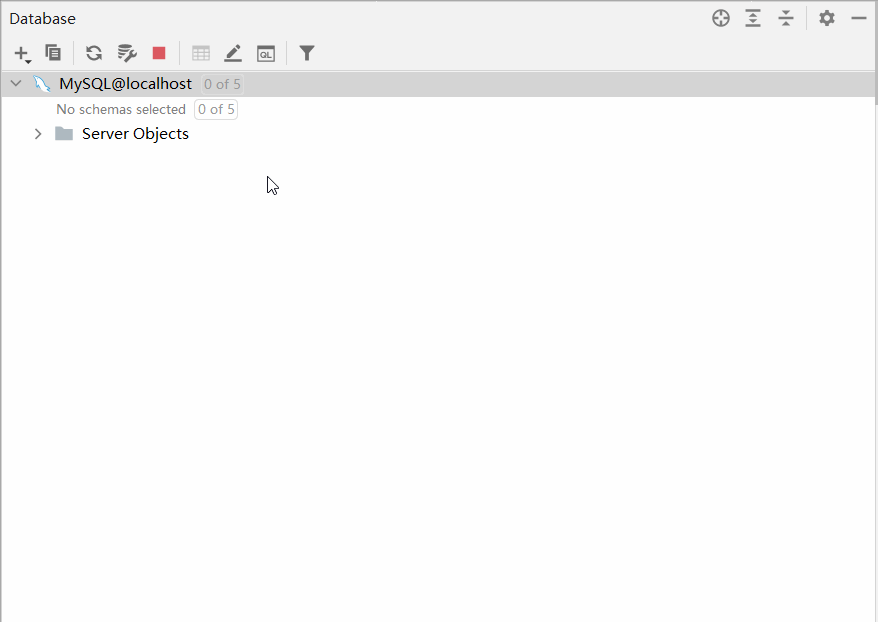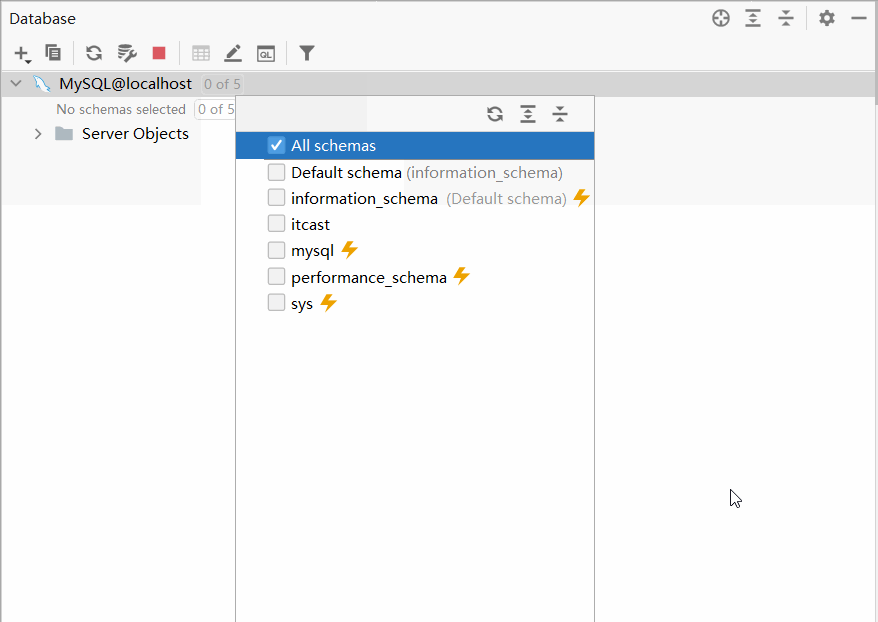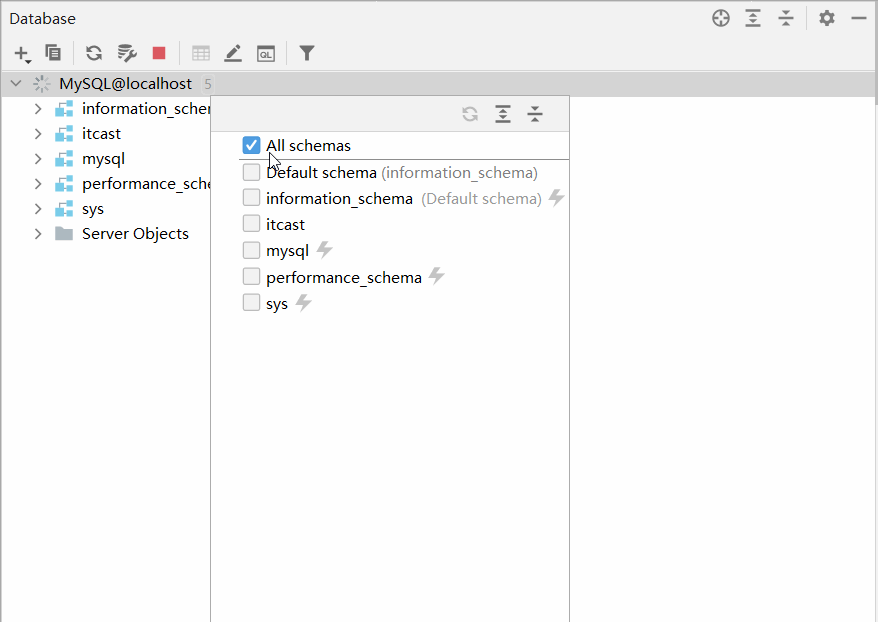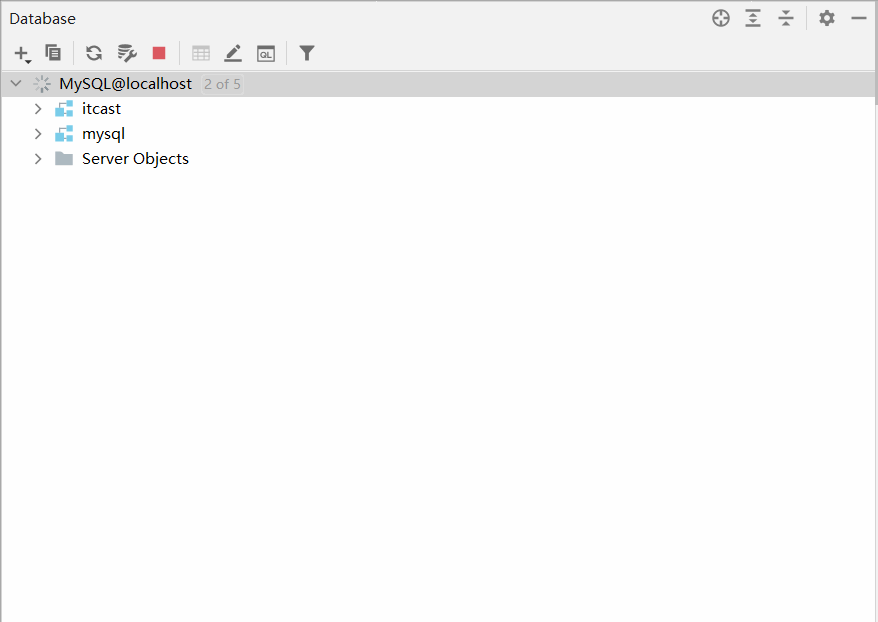
2.2.3.2 操作数据库
创建数据库:
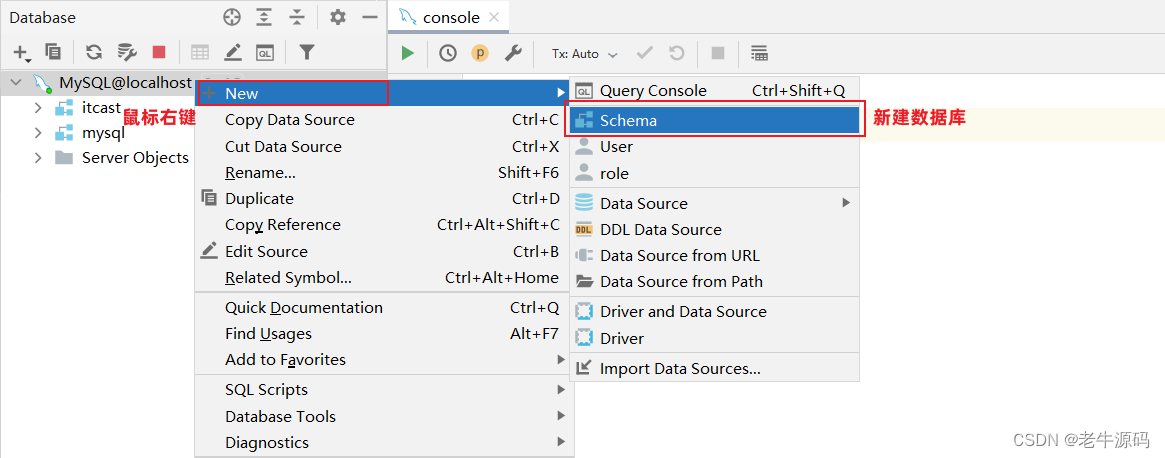
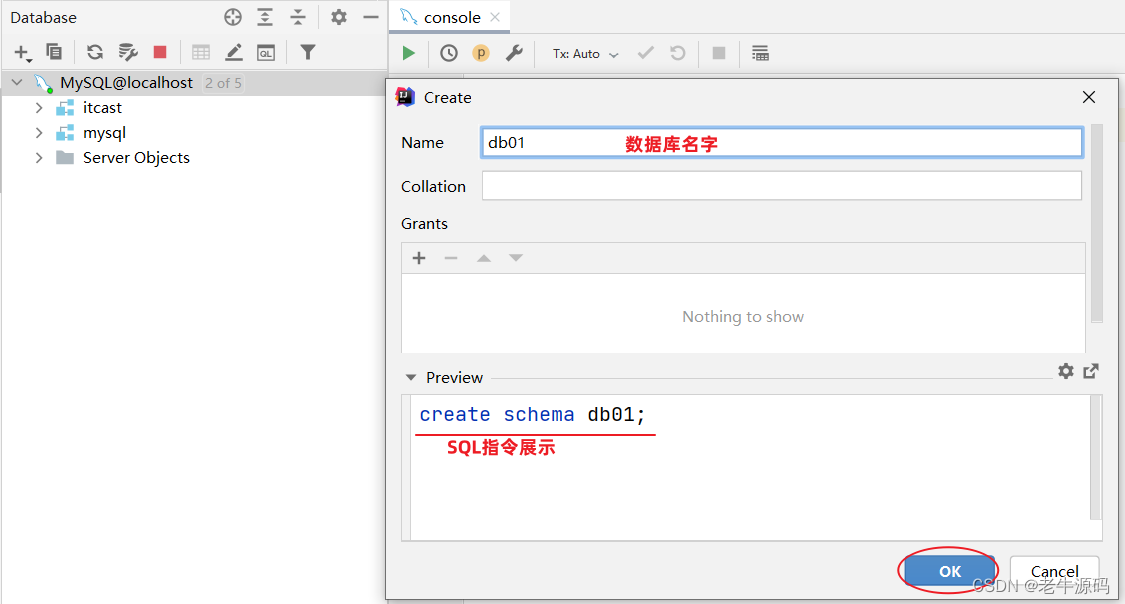
有了图形化界面工具后,就可以方便的使用图形化工具:创建数据库,创建表、修改表等DDL操作。
其实工具底层也是通过DDL语句操作的数据库,只不过这些SQL语句是图形化界面工具帮我们自动完成的。
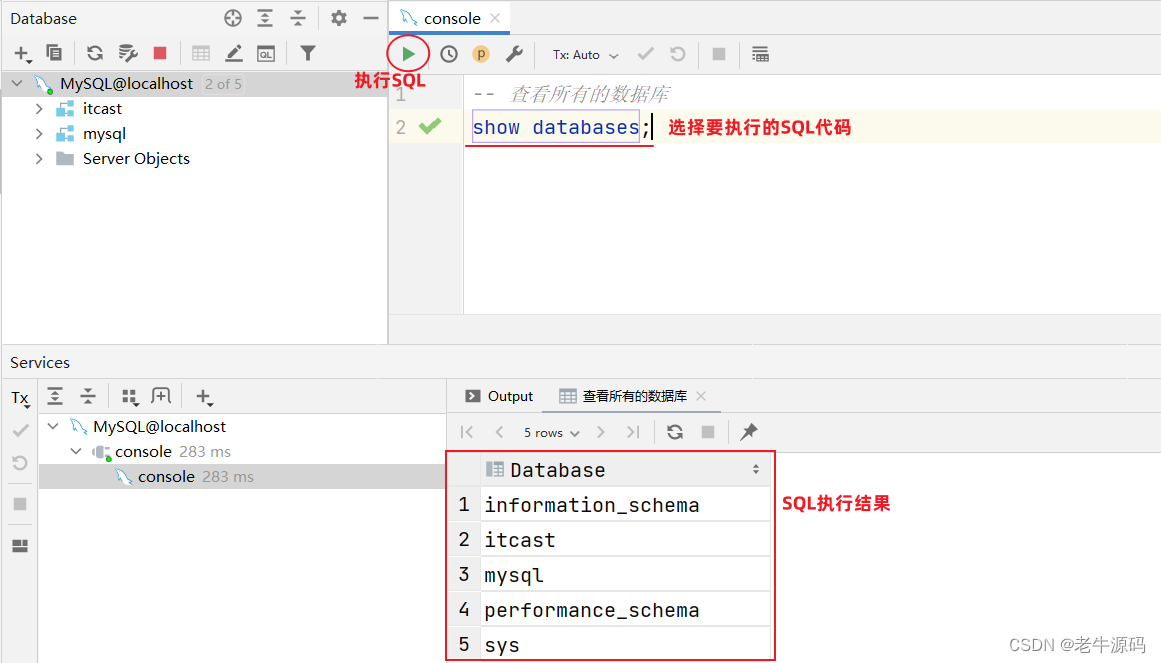
查看所有数据库:

2.3 表操作
学习完了DDL语句当中关于数据库的操作之后,接下来我们继续学习DDL语句当中关于表结构的操作。
关于表结构的操作也是包含四个部分:创建表、查询表、修改表、删除表。
2.3.1 创建
2.3.1.1 语法
create table 表名(字段1 字段1类型 [约束] [comment 字段1注释 ],字段2 字段2类型 [约束] [comment 字段2注释 ],......字段n 字段n类型 [约束] [comment 字段n注释 ]
) [ comment 表注释 ] ;
注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号
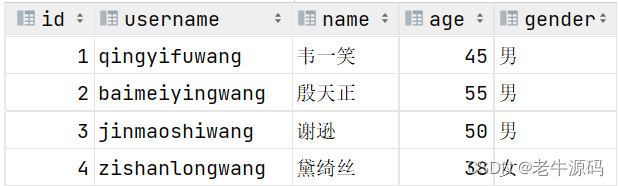
案例:创建tb_user表
- 对应的结构如下:
- 建表语句:
create table tb_user (id int comment 'ID,唯一标识', # id是一行数据的唯一标识(不能重复)username varchar(20) comment '用户名',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '性别'
) comment '用户表';
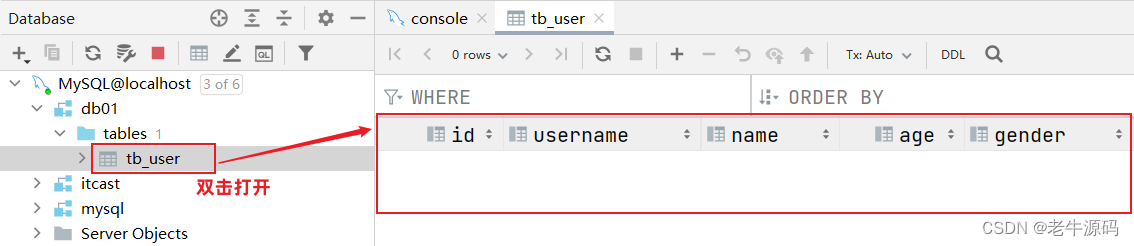
数据表创建完成,接下来我们还需要测试一下是否可以往这张表结构当中来存储数据。
双击打开tb_user表结构,大家会发现里面没有数据:
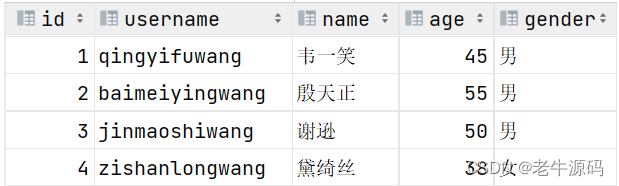
添加数据:

此时我们再插入一条数据:
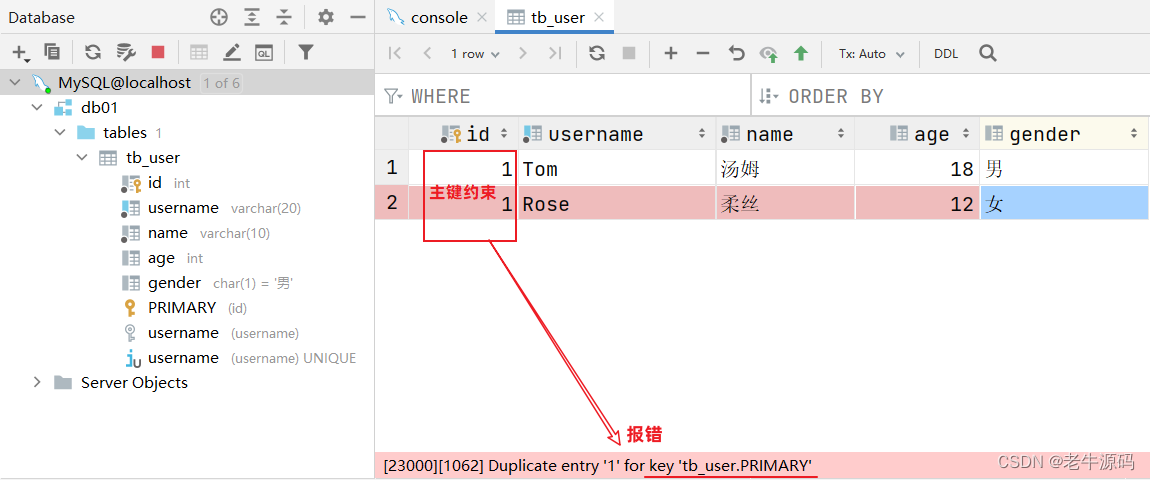
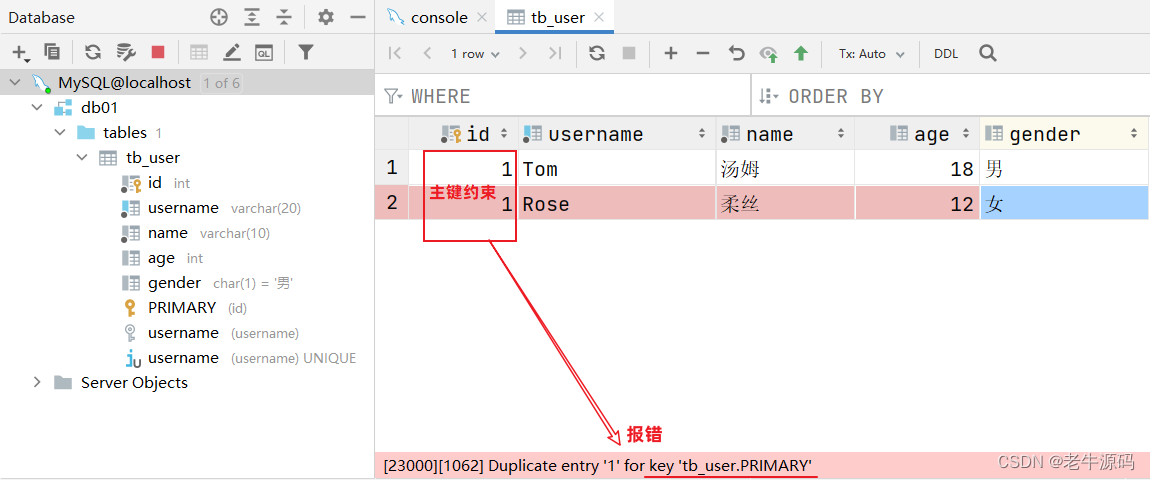
我们之前提到过:id字段是一行数据的唯一标识,不能有重复值。但是现在数据表中有两个相同的id值,这是为什么呢?
- 其实我们现在创建表结构的时候, id这个字段我们只加了一个备注信息说明它是一个唯一标识,但是在数据库层面呢,并没有去限制字段存储的数据。所以id这个字段没有起到唯一标识的作用。
想要限制字段所存储的数据,就需要用到数据库中的约束。
2.3.1.2 约束
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。
作用:就是来保证数据库当中数据的正确性、有效性和完整性。(后面的学习会验证这些)
在MySQL数据库当中,提供了以下5种约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
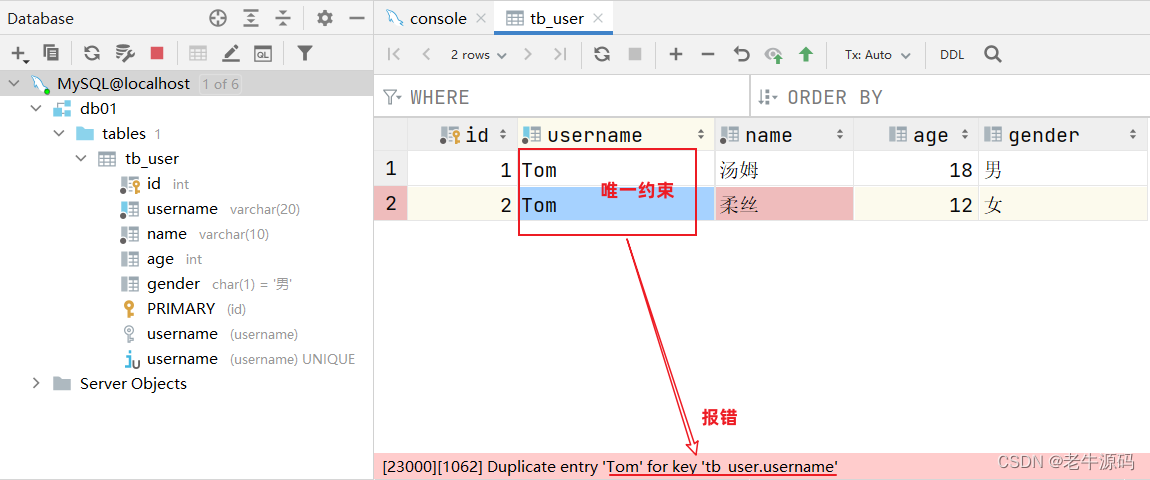
案例:创建tb_user表
- 对应的结构如下:
在上述的表结构中:
id 是一行数据的唯一标识
username 用户名字段是非空且唯一的
name 姓名字段是不允许存储空值的
gender 性别字段是有默认值,默认为男
- 建表语句:
create table tb_user (id int primary key comment 'ID,唯一标识', username varchar(20) not null unique comment '用户名',name varchar(10) not null comment '姓名',age int comment '年龄',gender char(1) default '男' comment '性别'
) comment '用户表';
数据表创建完成,接下来测试一下表中字段上的约束是否生效
大家有没有发现一个问题:id字段下存储的值,如果由我们自己来维护会比较麻烦(必须保证值的唯一性)。MySQL数据库为了解决这个问题,给我们提供了一个关键字:auto_increment(自动增长)
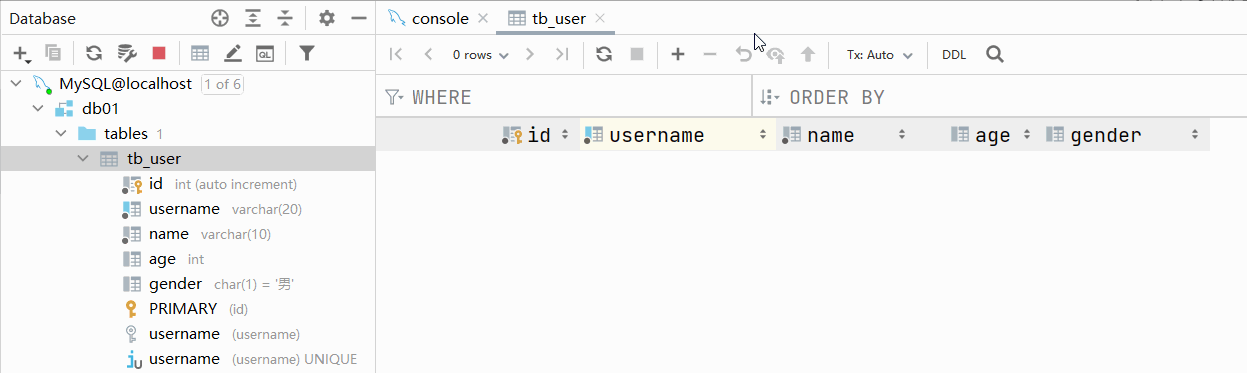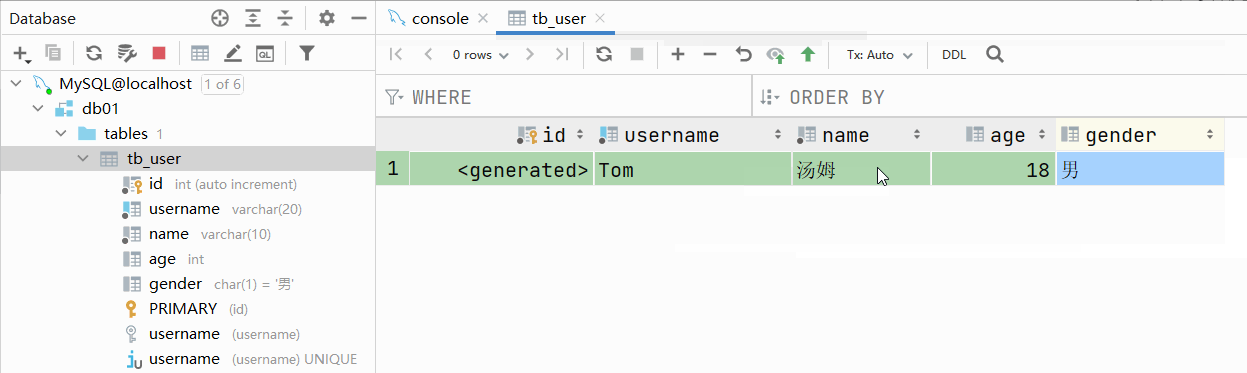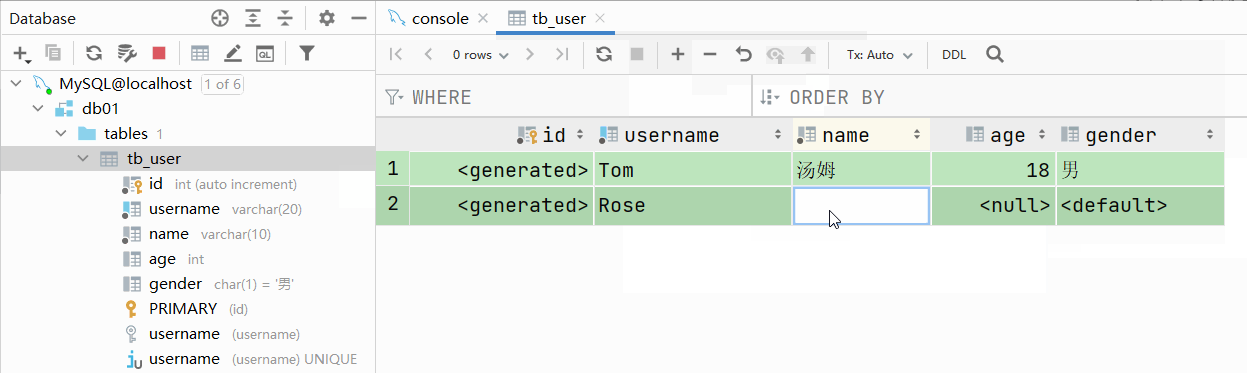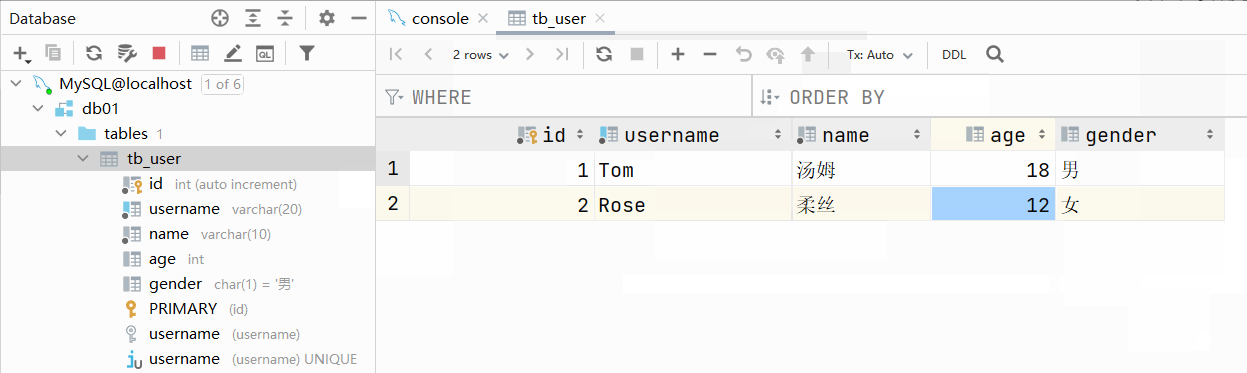
主键自增:auto_increment
- 每次插入新的行记录时,数据库自动生成id字段(主键)下的值
- 具有auto_increment的数据列是一个正数序列开始增长(从1开始自增)
create table tb_user (id int primary key auto_increment comment 'ID,唯一标识', #主键自动增长username varchar(20) not null unique comment '用户名',name varchar(10) not null comment '姓名',age int comment '年龄',gender char(1) default '男' comment '性别'
) comment '用户表';
测试:主键自增
2.3.1.3 数据类型
在上面建表语句中,我们在指定字段的数据类型时,用到了int 、varchar、char,那么在MySQL中除了以上的数据类型,还有哪些常见的数据类型呢? 接下来,我们就来详细介绍一下MySQL的数据类型。
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
| 类型 | 大小 | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-263,263-1) | (0,2^64-1) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
示例: 年龄字段 ---不会出现负数, 而且人的年龄不会太大age tinyint unsigned分数 ---总分100分, 最多出现一位小数score double(4,1)
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
示例: 用户名 username ---长度不定, 最长不会超过50username varchar(50)手机号 phone ---固定长度为11phone char(11)
日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
示例: 生日字段 birthday ---生日只需要年月日 birthday date创建时间 createtime --- 需要精确到时分秒createtime datetime
2.3.1.4 案例
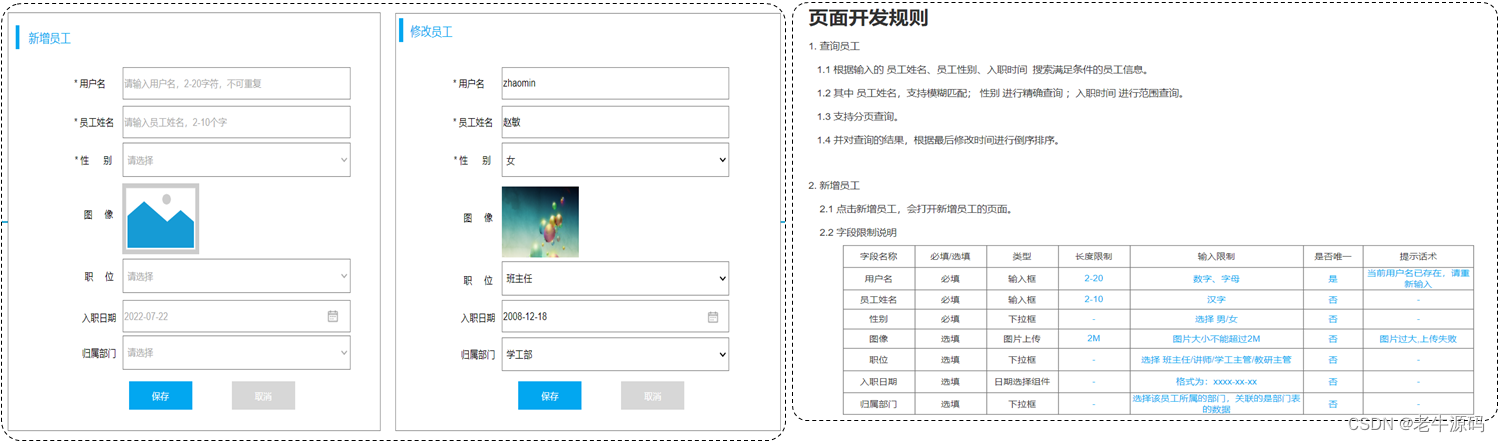
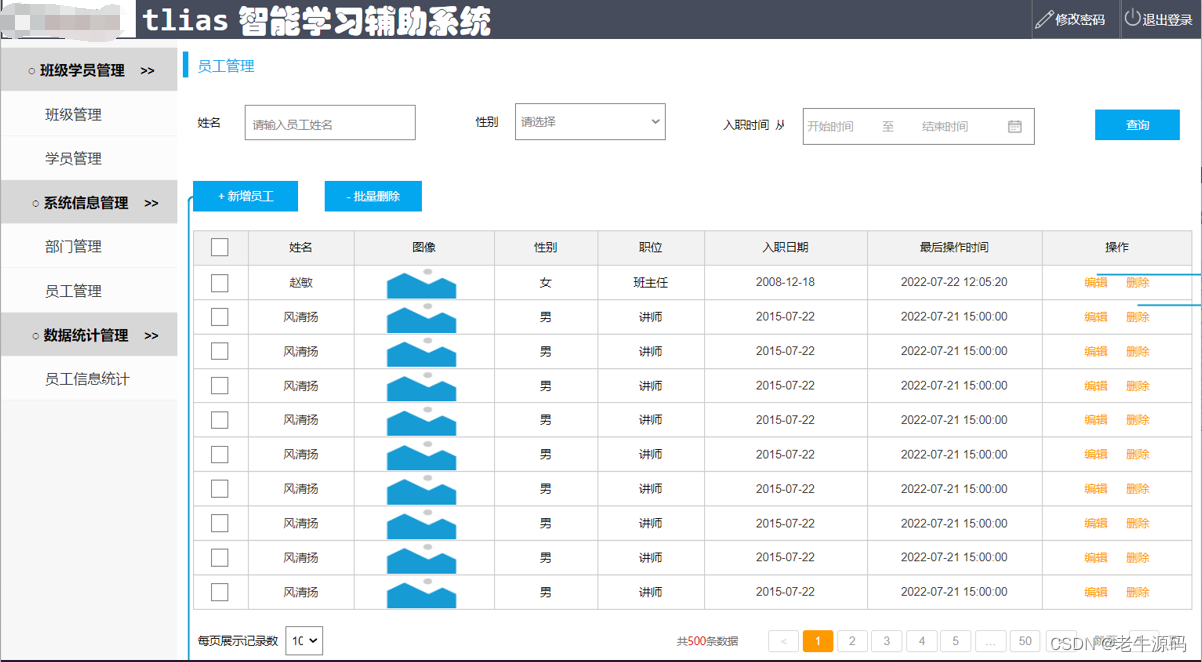
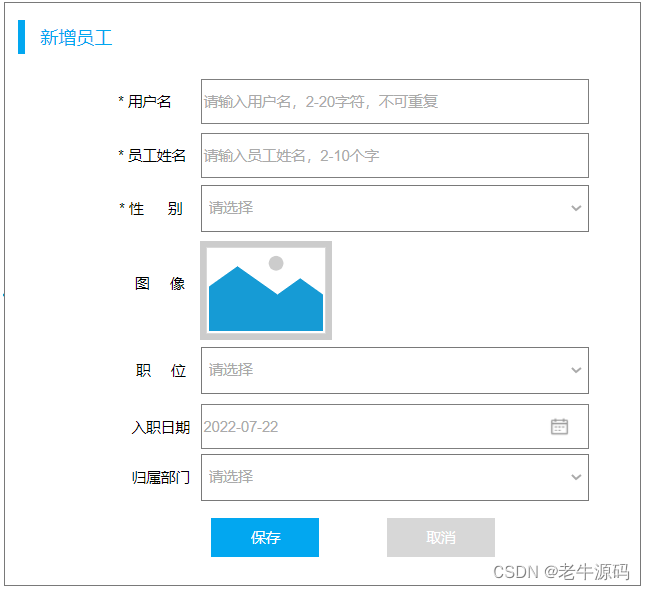
需求:根据产品原型/需求创建表((设计合理的数据类型、长度、约束)
参考资料中提供的《黑马-tlias智能学习辅助系统》页面原型,设计员工管理模块的表结构
暂不考虑所属部门字段
产品原型及需求如下:
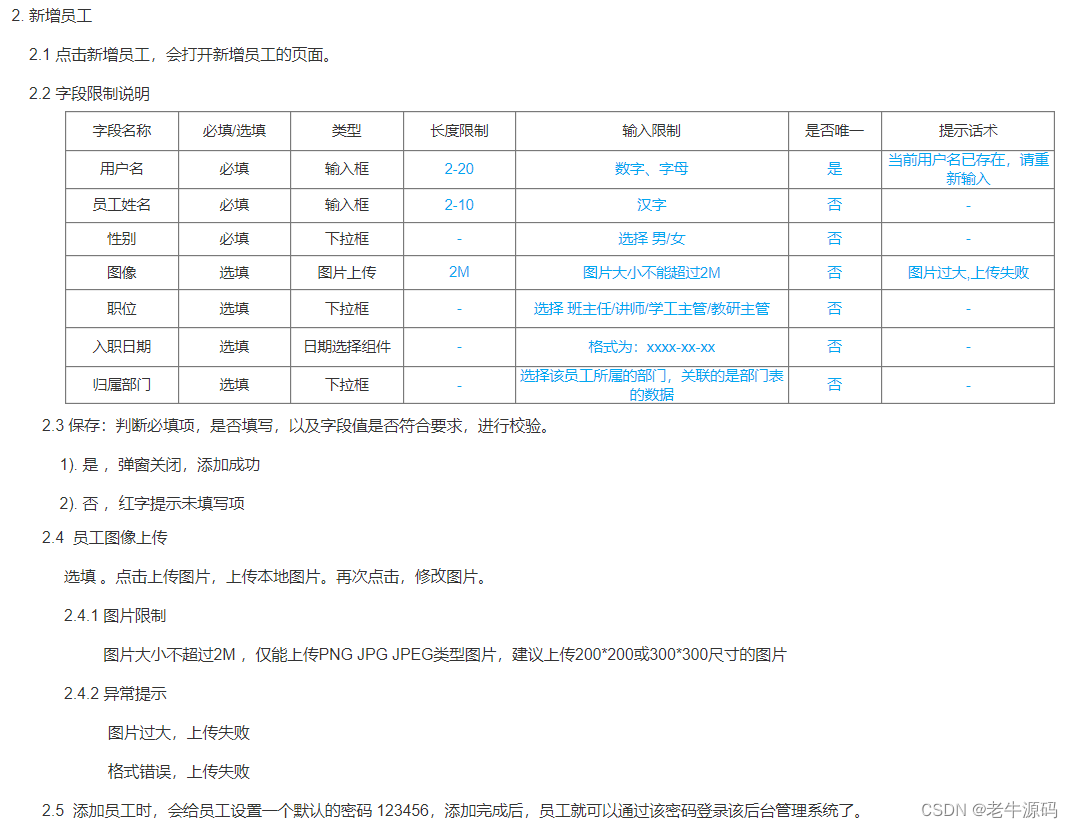
步骤:
-
阅读产品原型及需求文档,看看里面涉及到哪些字段。
-
查看需求文档说明,确认各个字段的类型以及字段存储数据的长度限制。
-
在页面原型中描述的基础字段的基础上,再增加额外的基础字段。
使用SQL创建表:
create table emp (id int unsigned primary key auto_increment comment 'ID',username varchar(20) not null unique comment '用户名',password varchar(32) default '123456' comment '密码',name varchar(10) not null comment '姓名',gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',image varchar(300) comment '图像',job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',entrydate date comment '入职时间',create_time datetime not null comment '创建时间',update_time datetime not null comment '修改时间'
) comment '员工表';
除了使用SQL语句创建表外,我们还可以借助于图形化界面来创建表结构,这种创建方式会更加直观、更加方便。
操作步骤如下:
- 在指定操作的数据库上,右键New ==> Table
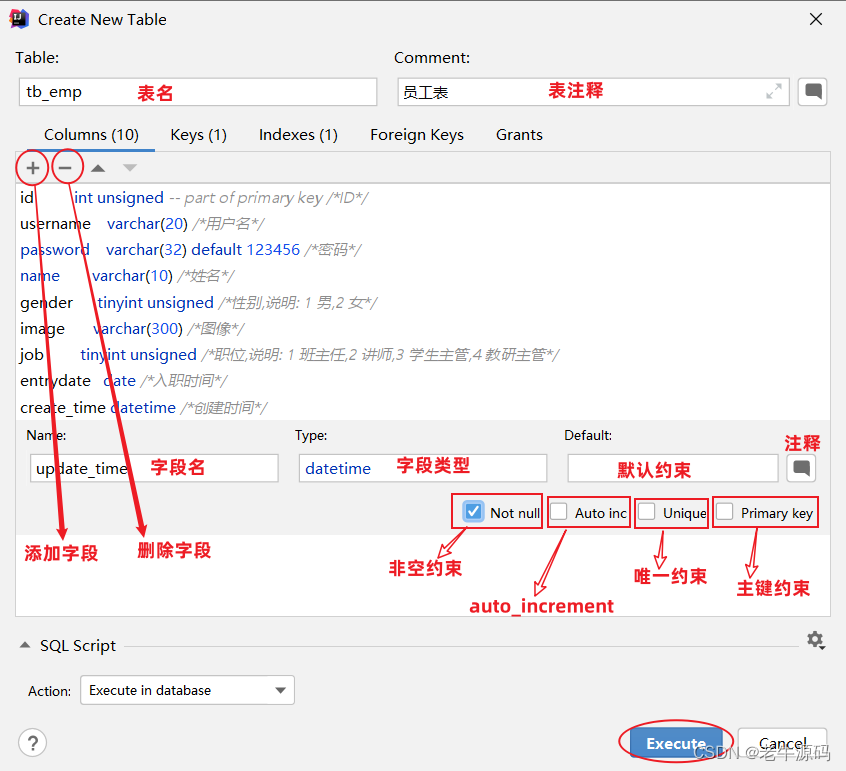
- 编辑表结构的相关信息
2.3.1.5 设计表流程
通过上面的案例,我们明白了,设计一张表,基本的流程如下:
-
阅读页面原型及需求文档
-
基于页面原则和需求文档,确定原型字段(类型、长度限制、约束)
-
再增加表设计所需要的业务基础字段(id主键、插入时间、修改时间)
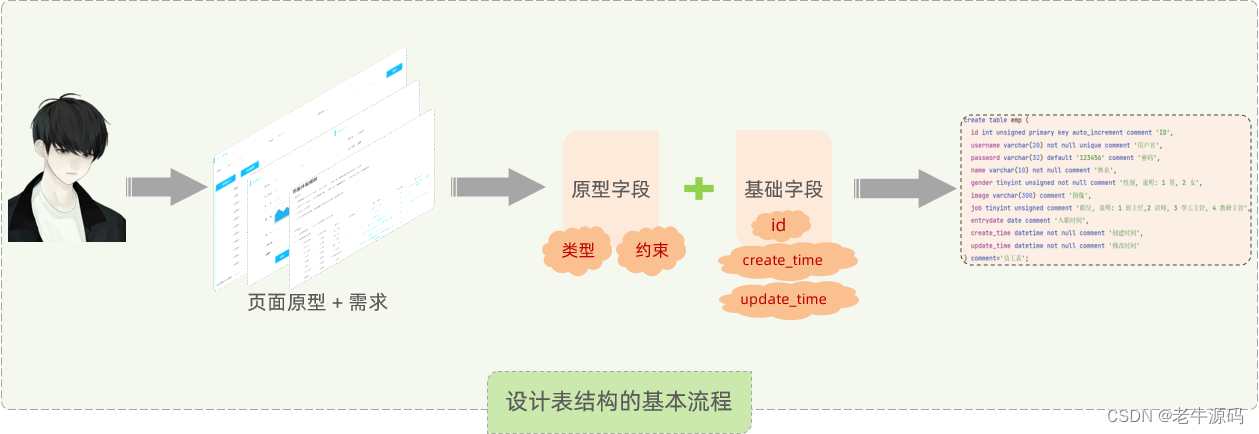
说明:
create_time:记录的是当前这条数据插入的时间。
update_time:记录当前这条数据最后更新的时间。
2.3.2 查询
关于表结构的查询操作,工作中一般都是直接基于图形化界面操作。
查询当前数据库所有表
show tables;

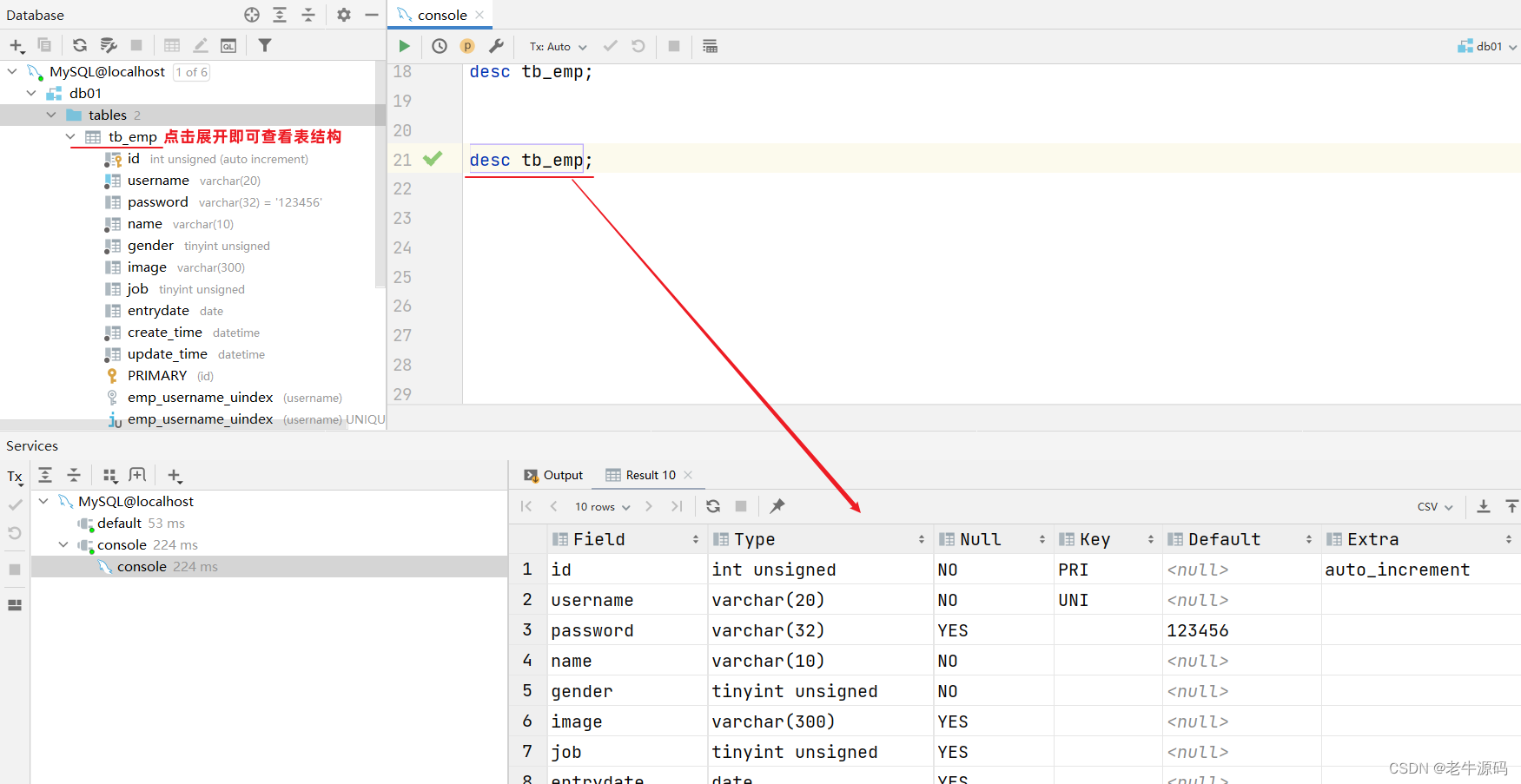
查看指定表结构
desc 表名 ;#可以查看指定表的字段、字段的类型、是否可以为NULL、是否存在默认值等信息
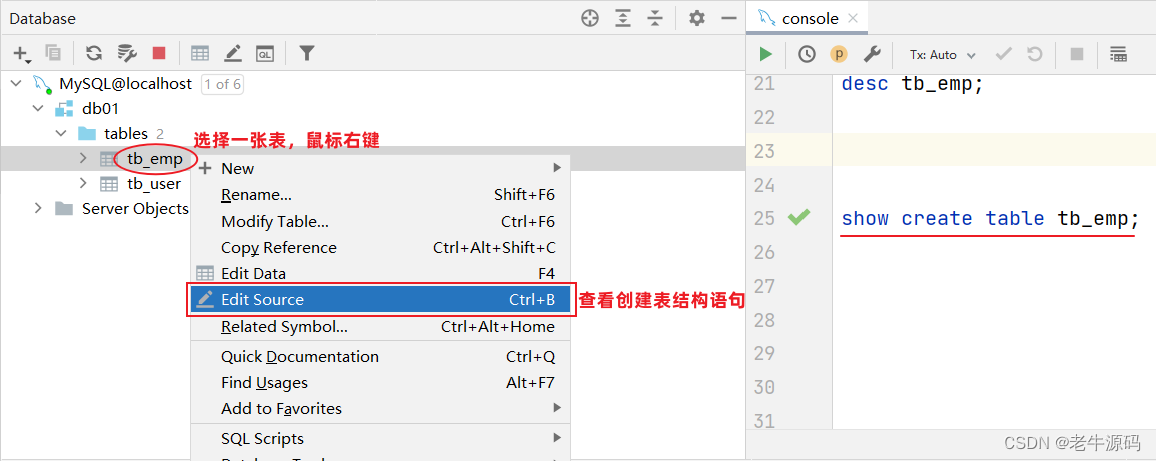
查询指定表的建表语句
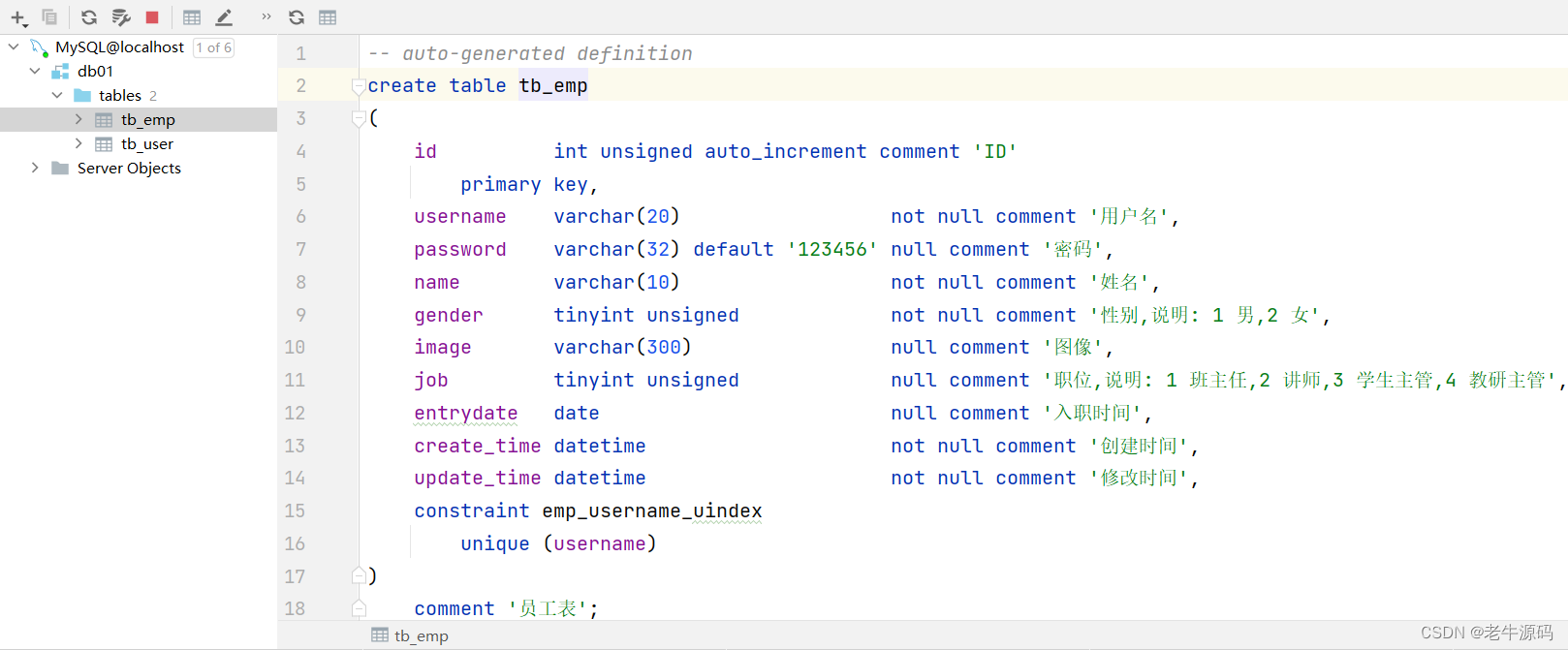
show create table 表名 ;
2.3.3 修改
关于表结构的修改操作,工作中一般都是直接基于图形化界面操作。
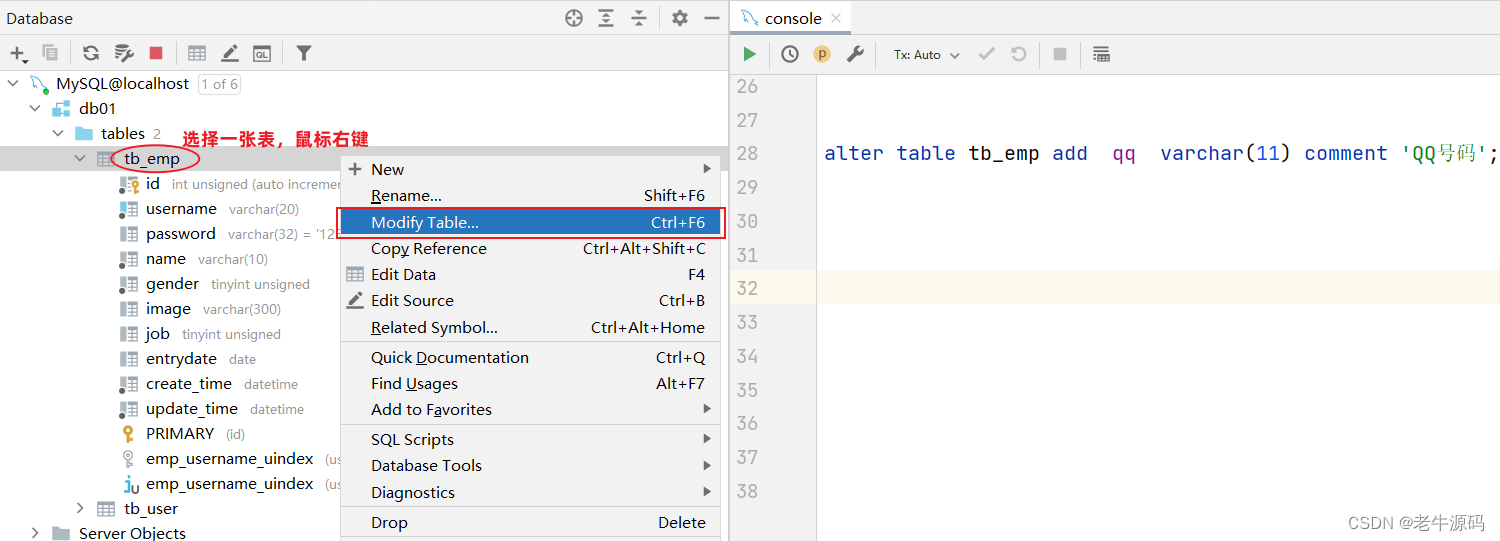
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
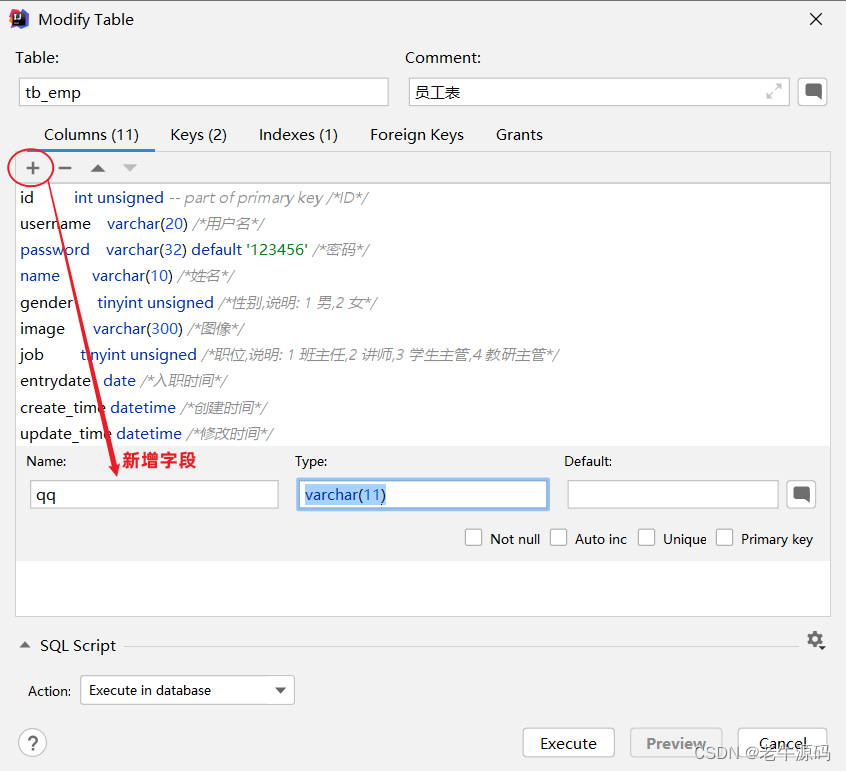
案例: 为tb_emp表添加字段qq,字段类型为 varchar(11)
alter table tb_emp add qq varchar(11) comment 'QQ号码';
图形化操作:添加字段
修改数据类型
alter table 表名 modify 字段名 新数据类型(长度);
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
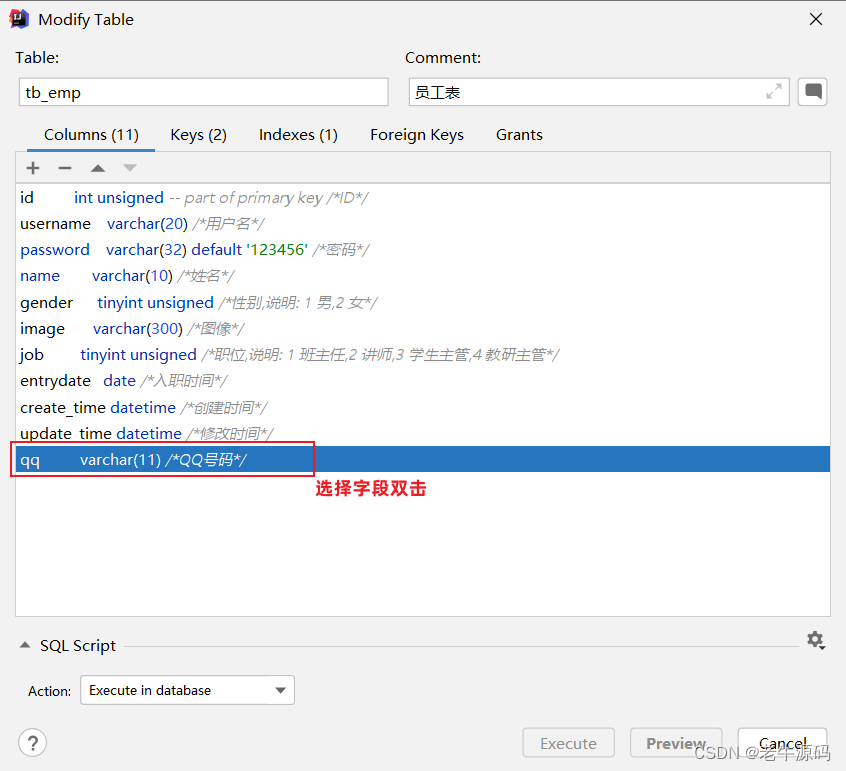
案例:修改qq字段的字段类型,将其长度由11修改为13
alter table tb_emp modify qq varchar(13) comment 'QQ号码';
案例:修改qq字段名为 qq_num,字段类型varchar(13)
alter table tb_emp change qq qq_num varchar(13) comment 'QQ号码';
图形化操作:修改数据类型和字段名

删除字段
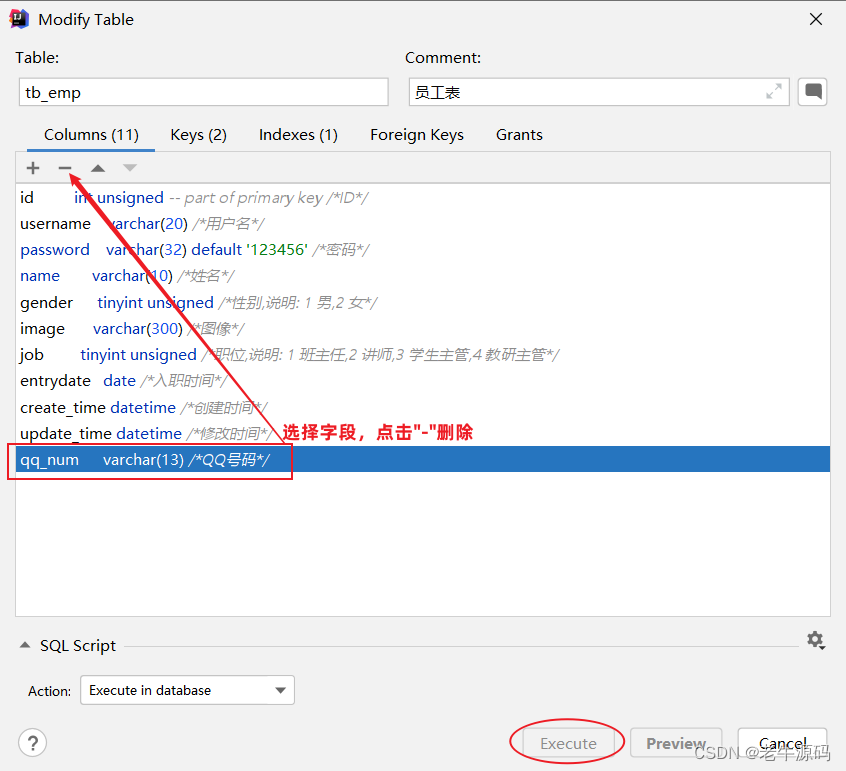
alter table 表名 drop 字段名;
案例:删除tb_emp表中的qq_num字段
alter table tb_emp drop qq_num;
图形化操作:删除字段
修改表名
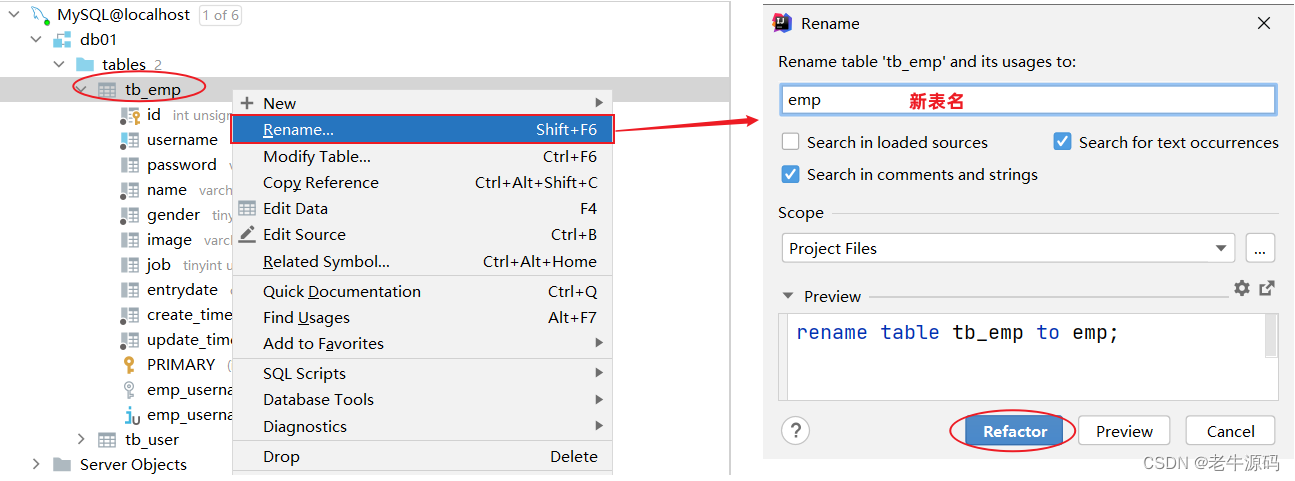
rename table 表名 to 新表名;
案例:将当前的tb_emp表的表名修改为emp
rename table tb_emp to emp;
图形化操作:修改表名
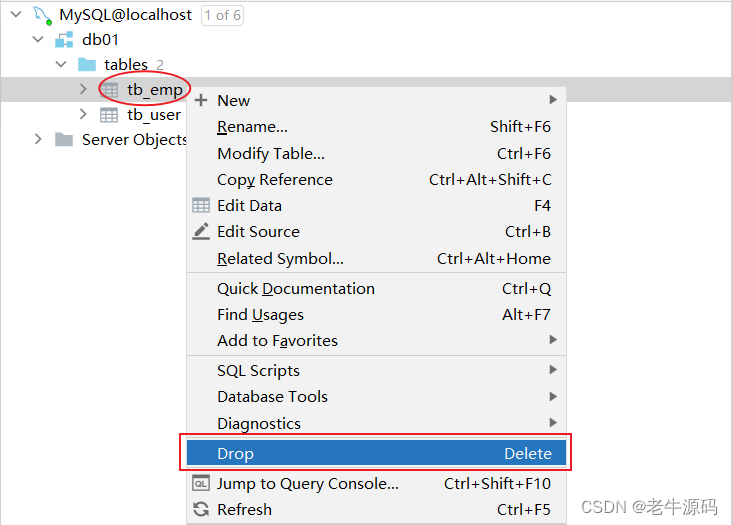
2.3.4 删除
关于表结构的删除操作,工作中一般都是直接基于图形化界面操作。
删除表语法:
drop table [ if exists ] 表名;
if exists :只有表名存在时才会删除该表,表名不存在,则不执行删除操作(如果不加该参数项,删除一张不存在的表,执行将会报错)。
案例:如果tb_emp表存在,则删除tb_emp表
drop table if exists tb_emp; -- 在删除表时,表中的全部数据也会被删除。
图形化操作:删除表
相关文章:
【JaveWeb教程】(18) MySQL数据库开发之 MySQL数据库设计-DDL 如何查询、创建、使用、删除数据库数据表 详细代码示例讲解
目录 2. 数据库设计-DDL2.1 项目开发流程2.2 数据库操作2.2.1 查询数据库2.2.2 创建数据库2.2.3 使用数据库2.2.4 删除数据库 2.3 图形化工具2.3.1 介绍2.3.2 安装2.3.3 使用2.2.3.1 连接数据库2.2.3.2 操作数据库 2.3 表操作2.3.1 创建2.3.1.1 语法2.3.1.2 约束2.3.1.3 数据类…...

ElasticSearch学习笔记-SpringBoot整合Elasticsearch7
项目最近需要接入Elasticsearch7,顺带记录下笔记。 Elasticsearch依赖包版本 <properties><elasticsearch.version>7.9.3</elasticsearch.version><elasticsearch.rest.version>7.9.3</elasticsearch.rest.version> </propertie…...

[足式机器人]Part2 Dr. CAN学习笔记 - Ch02动态系统建模与分析
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记 - Ch02动态系统建模与分析 1. 课程介绍2. 电路系统建模、基尔霍夫定律3. 流体系统建模4. 拉普拉斯变换(Laplace)传递函数、微分方程4.1 Laplace Transform 拉式变换4.2 收…...

【一周年创作总结】人生是远方的无尽旷野呀
那一眼瞥见的伟大的灵魂,却似模糊的你和我 文章目录 📒各个阶段的experience🔎大一寒假🔎大一下学期🔎大一暑假🔎大二上学期(现在) 🍔相遇CSDN🛸自媒体&#…...

金融帝国实验室(Capitalism Lab)V10版本游戏平衡性优化与改进
即将推出的V10版本中的各种游戏平衡性优化与改进: ————————————— 一、当玩家被提议收购一家即将破产的公司时,显示商业秘密。 当一家公司濒临破产,玩家被提议收购该公司时,如果玩家有兴趣评估该公司,则无…...

[SpringBoot]接口的多实现:选择性注入SpringBoot接口的实现类
最近在项目中遇到两种情况,准备写个博客记录一下。 情况说明:Service层一个接口是否可以存在多个具体实现,此时应该如何调用Service(的具体实现)? 其实之前的项目中也遇到过这种情况,只不过我采…...

北京大学 wlw机器学习2022春季期末试题分析
北京大学 wlw机器学习2022春季期末试题分析 前言新的开始第一题第二题第三题 前言 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。 新的开始 第…...
)
前端文件下载方法(包含get和post)
export const downloadFileWithIframe (url, name) > {const iframe document.createElement(iframe);iframe.style.display none; // 防止影响页面iframe.style.height 0; // 防止影响页面iframe.name name;iframe.src url;document.body.appendChild(iframe); // 这…...
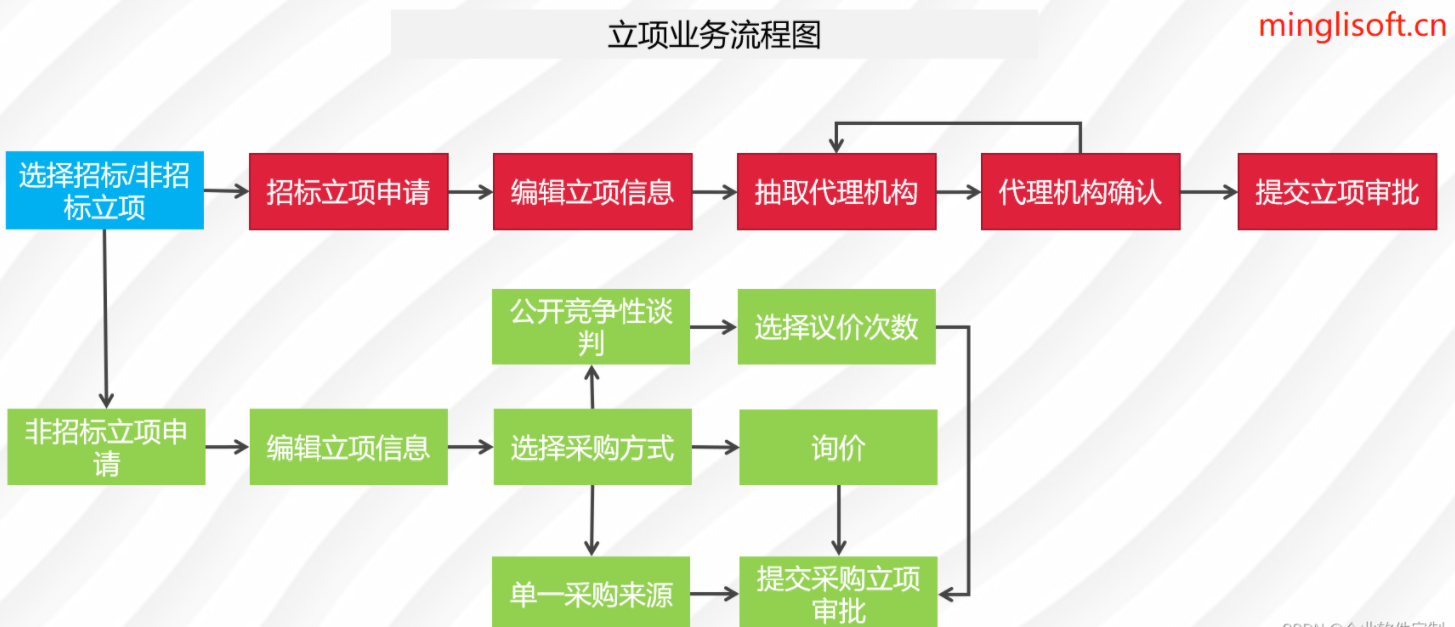
高性能、可扩展、支持二次开发的企业电子招标采购系统源码
在数字化时代,企业需要借助先进的数字化技术来提高工程管理效率和质量。招投标管理系统作为企业内部业务项目管理的重要应用平台,涵盖了门户管理、立项管理、采购项目管理、采购公告管理、考核管理、报表管理、评审管理、企业管理、采购管理和系统管理等…...

2645. 构造有效字符串的最少插入数
Problem: 2645. 构造有效字符串的最少插入数 文章目录 解题思路解决方法复杂度分析代码实现 解题思路 解决此问题需要确定如何以最小的插入次数构造一个有效的字符串。首先,我们需要确定开头的差距,然后决定中间的补足,最后决定末尾的差距。…...
C#,快速排序算法(Quick Sort)的非递归实现与数据可视化
排序算法是编程的基础。 常见的四种排序算法是:简单选择排序、冒泡排序、插入排序和快速排序。其中的快速排序的优势明显,一般使用递归方式实现,但遇到数据量大的情况则无法适用。实际工程中一般使用“非递归”方式实现。 快速排序(Quick Sor…...

【操作系统xv6】学习记录2 -RISC-V Architecture
说明:看完这节,不会让你称为汇编程序员,知识操作系统的前置。 ref:https://binhack.readthedocs.io/zh/latest/assembly/mips.html https://www.bilibili.com/video/BV1w94y1a7i8/?p7 MIPS MIPS的意思是 “无内部互锁流水级的微…...
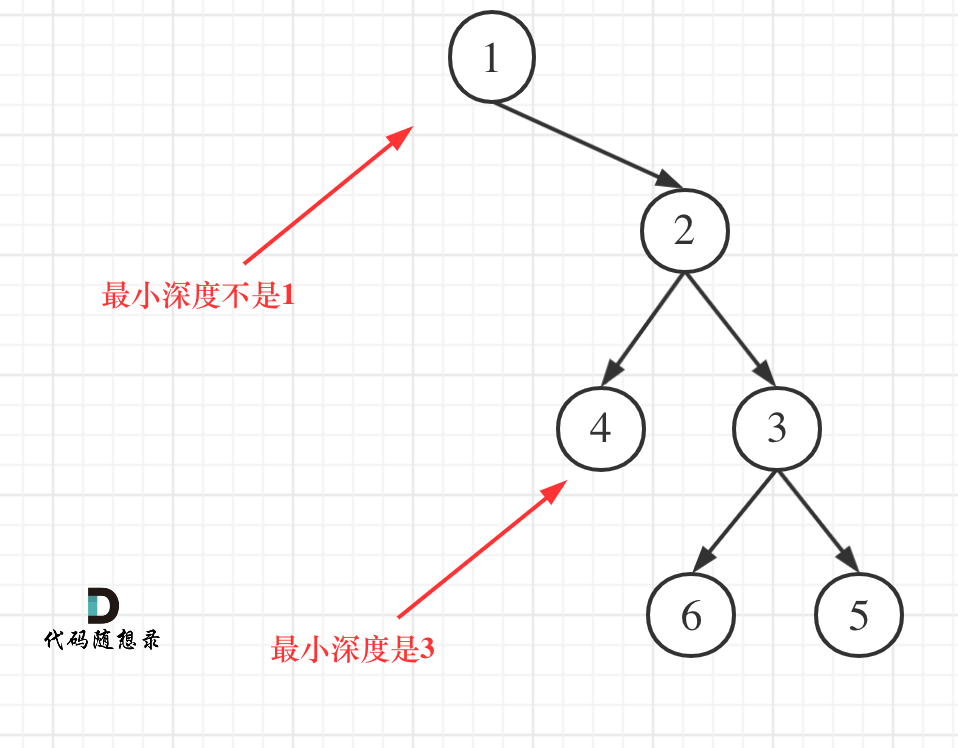
C++力扣题目111--二叉树的最小深度
力扣题目链接(opens new window) 给定一个二叉树,找出其最小深度。 最小深度是从根节点到最近叶子节点的最短路径上的节点数量。 说明: 叶子节点是指没有子节点的节点。 示例: 给定二叉树 [3,9,20,null,null,15,7], 返回它的最小深度 2 思路 看完了这篇104.二…...
)
【图像拼接】源码精读:Adaptive As-Natural-As-Possible Image Stitching(AANAP/ANAP)
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文源码精读】专栏的相关说明,包含专栏内文章结构说明、源码阅读顺序、培养代码能力、如何创新等(不定期更新) 【图像拼接论文源码精读】专栏文章目录 【源码精读】As-Projective-As-Possible Imag…...
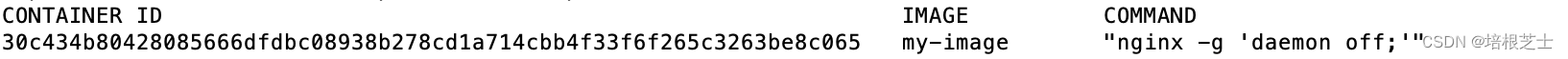
解决docker run报错:Error response from daemon: No command specified.
将docker镜像export/import之后,对新的镜像执行docker run时报错: docker: Error response from daemon: No command specified. 解决方法: 方案1: 查看容器的command: docker ps --no-trunc 在docker run命令上增加…...

算法第十二天-最大整除子集
最大整除子集 题目要求 解题思路 来自[宫水三叶] 根据题意:对于符合要求的[整除子集]中的任意两个值,必然满足[较大数]是[较小数]的倍数 数据范围是 1 0 3 10^3 103,我们不可能采取获取所有子集,再检查子集是否合法的暴力搜解法…...

简单易懂的PyTorch 损失函数:优化机器学习模型的关键
目录 torch.nn子模块Loss Functions详解 nn.L1Loss 用途 用法 使用技巧 注意事项 代码示例 nn.MSELoss 用途 用法 使用技巧 注意事项 代码示例 nn.CrossEntropyLoss 用途 用法 使用技巧 注意事项 代码示例 使用类别索引 使用类别概率 nn.CTCLoss 用途 …...

Kubernetes/k8s的存储卷/数据卷
k8s的存储卷/数据卷 容器内的目录和宿主机的目录挂载 容器在系统上的生命周期是短暂的,delete,k8s用控制创建的pod,delete相当于重启,容器的状态也会回复到初始状态 一旦回到初始状态,所有的后天编辑的文件都会消失…...
【漏洞复现】锐捷RG-UAC统一上网行为管理系统信息泄露漏洞
Nx01 产品简介 锐捷网络成立于2000年1月,原名实达网络,2003年更名,自成立以来,一直扎根行业,深入场景进行解决方案设计和创新,并利用云计算、SDN、移动互联、大数据、物联网、AI等新技术为各行业用户提供场…...
)
Android - 串口通讯(SerialPort)
最早的博客Android 模拟串口通信过程_launch virtual serial port driver pro-CSDN博客里就是用过 Google 提供的 demo,最近想再写个其他的demo发现用起来有点麻烦,还需要导入其他 module,因此在网上找到了Android-SerialPort-API: https://g…...

SAP Smartforms避坑指南:从‘没有输出请求打开’到字体设置,手把手解决5个高频问题
SAP Smartforms实战避坑手册:5个高频问题深度解析与解决方案 在SAP项目实施过程中,Smartforms作为企业级报表输出的核心工具,几乎每个ABAP开发者都会与之打交道。表面上看,它提供了直观的图形化界面,似乎比传统的SAPsc…...
)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪+时序约束实战)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪时序约束实战) 当LED流水灯项目已经无法满足你的FPGA开发需求时,意味着你正站在从入门到进阶的关键转折点。高云FPGA平台提供的云源软件不仅支持基础开发&#…...

AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环Agent 早就跑通了,但有一条横切线一直没单独写过:深度阅读那种动辄一千多字的输出,怎么知道 LLM 是不是在自圆其说。这周回过头来补这一篇,顺便把本周做的几个小改动一并…...

【NotebookLM新闻传播研究权威指南】:20年传媒技术专家亲授AI驱动的新闻生产新范式
更多请点击: https://kaifayun.com 第一章:NotebookLM新闻传播研究导论 NotebookLM 是 Google 推出的基于大型语言模型的实验性研究助手,专为信息整合、溯源验证与知识重构设计。其核心能力在于对用户上传的文档(PDF、TXT、网页…...

终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼
终极窗口置顶解决方案:用AlwaysOnTop告别多任务切换烦恼 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常需要在不同窗口间来回切换?是否觉得频…...

NotebookLM脑机接口部署避坑指南:TensorRT加速失效、电极位移漂移补偿、低信噪比场景下的9种fallback策略
更多请点击: https://codechina.net 第一章:NotebookLM脑机接口研究 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,虽其官方定位并非直接面向脑机接口(BCI)领域,但其底层架构…...

基于MCP协议构建安全AI支付工具:从原理到实践
1. 项目概述与核心价值最近在折腾AI智能体开发,特别是想给Claude Desktop这类工具增加点“超能力”,比如让它能直接帮我处理支付、查询订单状态,甚至自动对账。这想法听起来挺酷,但真动手去实现,发现最大的拦路虎不是写…...

基于Minicursor理念的Node.js后端服务快速搭建与架构解析
1. 项目概述与核心价值最近在折腾一个个人项目,需要快速搭建一个轻量级的、能处理实时数据流的后端服务。在寻找合适的脚手架时,我偶然在 GitHub 上发现了forrestchang/minicursor这个项目。乍一看名字,你可能会联想到数据库的“游标”&#…...

从医院PACS到你的Python脚本:手把手教你用pydicom库读写和修改DICOM文件
从医院PACS到Python脚本:pydicom实战医学影像处理指南 医学影像数据正以每年30%的速度增长,而DICOM作为医疗影像存储与传输的国际标准,承载着CT、MRI等设备产生的海量数据。在临床研究、AI模型训练和医疗信息化建设中,开发者经常需…...

AI智能体开发实战:agent-skills工具库核心技能解析与应用
1. 项目概述与核心价值最近在折腾AI智能体开发,发现一个挺有意思的现象:很多开发者,包括我自己在内,一开始都热衷于去研究那些大型的、功能全面的智能体框架,试图打造一个“全能”的AI助手。但实际落地时,往…...