pyspark 使用udf 进行预测,发现只起了一个计算节点
PySpark UDF 只使用一个计算节点的问题
原因分析
-
默认的并行度设置
PySpark在执行UDF(用户定义函数)时,默认可能不会利用所有可用的计算节点。这是因为UDF通常在单个节点上执行,并且如果没有正确设置分区,可能会导致数据倾斜或不平衡的分布。
-
数据分区不足
如果你的数据没有被平均分配到多个分区中,那么处理这些数据的任务就可能只在一个节点上执行,导致其他节点闲置。
-
资源限制
集群配置或资源管理器(如YARN、Mesos或Kubernetes)的资源限制可能导致只有一个节点被分配用于任务。
解决方法
-
增加分区
通过
repartition()方法增加数据的分区数,可以更好地利用集群的多个节点。df = df.repartition("your_partition_column") # 或者指定分区数量 df = df.repartition(10) -
调整并行度
在Spark中,你可以通过设置
spark.sql.shuffle.partitions或spark.default.parallelism来调整任务的并行度。spark.conf.set("spark.sql.shuffle.partitions", "200") spark.conf.set("spark.default.parallelism", "200") -
优化UDF
如果可能,尝试使用Spark的内置函数代替UDF,因为内置函数通常会更好地利用Spark的并行处理功能。
-
检查资源配置
确保你的集群资源管理器配置允许使用多个节点。如果你使用的是YARN,检查
yarn-site.xml文件中的资源分配设置。 -
监控和调试
使用Spark UI来监控任务执行情况,检查是否有数据倾斜或其他性能瓶颈。
通过以上方法,你可以尝试解决PySpark UDF只使用一个计算节点的问题,从而更有效地利用集群资源进行分布式计算。
Spark中设置任务并行度的两种方式
Spark中设置任务并行度的两个配置参数spark.sql.shuffle.partitions和spark.default.parallelism都可以用来调整并行处理任务的数量,但它们在应用的范围和作用上存在差异。
1. spark.sql.shuffle.partitions
-
作用范围: 这个参数专门用于调整Spark SQL操作中的shuffle操作的并行度。Shuffle操作发生在宽依赖的阶段,例如在groupBy或者repartition操作之后。
-
默认值: 默认情况下,
spark.sql.shuffle.partitions的值为200。 -
影响: 当执行有shuffle操作的Spark SQL查询时,这个参数决定了shuffle过程中输出的分区数量。设置得过高会导致许多小分区,可能会增加调度开销;设置得过低可能会导致单个分区过大,影响并行处理的效率。
2. spark.default.parallelism
-
作用范围: 这个参数是Spark核心的全局默认并行度设置,影响所有RDD操作的默认分区数,包括没有指定分区数的transformations和actions。
-
默认值: 对于分布式shuffle操作,如
reduceByKey和join,spark.default.parallelism的默认值取决于集群的配置。如果是运行在本地模式,它默认等于机器的CPU核心数;如果是运行在集群模式,它通常等于Spark应用的所有executor的核心总数。 -
影响: 这个参数通常用于控制RDD的默认分区数和并行任务数。它会影响到RDD的repartition操作和默认的shuffle操作。
区别总结
-
应用范围:
spark.sql.shuffle.partitions专门针对Spark SQL中的shuffle操作;而spark.default.parallelism适用于所有RDD的默认分区数。 -
默认值: 两者的默认值不同,且取决于不同的条件。
-
调整时机: 对
spark.sql.shuffle.partitions的调整通常是为了优化特定的Spark SQL查询性能;而调整spark.default.parallelism则是为了影响整个Spark应用中的并行度。 -
影响范围:
spark.sql.shuffle.partitions只影响SQL查询中的shuffle阶段;spark.default.parallelism则影响所有RDD的默认分区和并行任务。
在实际应用中,这两个参数可以根据需要分别调整,以达到最佳的资源利用率和性能。通常,对于Spark SQL任务,优先考虑调整spark.sql.shuffle.partitions;而对于基于RDD的操作,则关注spark.default.parallelism。
相关文章:

pyspark 使用udf 进行预测,发现只起了一个计算节点
PySpark UDF 只使用一个计算节点的问题 原因分析 默认的并行度设置 PySpark在执行UDF(用户定义函数)时,默认可能不会利用所有可用的计算节点。这是因为UDF通常在单个节点上执行,并且如果没有正确设置分区,可能会导致数…...

mysql触发器的简单使用
mysql触发器 触发器是一个特殊的存储过程,在事件delete、insert、update发生时自动执行一条或多条SQL语句(执行多条SQL语句需要用begin、end 包裹起来) 创建触发器 创建触发器的四大必要条件 唯一的触发器名称触发器关联的表触发器响应的…...

全志T113开发板Qt远程调试
1引言 通常情况下工程师在调试Qt程序时,需要频繁制作镜像烧录到核心板来测试Qt程序是否完善,这样的操作既费时又费力。这时我们可以通过QtCreator设备功能,定义设备后,在x86_64虚拟机上交叉编译qt程序,将程序远程部署到…...

学习使用php、js脚本关闭当前页面窗口的方法
学习使用php、js脚本关闭当前页面窗口的方法 前言方法一:使用JavaScript代码方法二:通过http头文件来实现方法三:使用服务器端脚本来实现 前言 在开发web应用程序时,我们通常需要在不同的网页之间进行导航。通常情况下࿰…...

python 人脸检测与人脸识别
安装库文件: pip install dlib face_recognition import dlib import face_recognition import cv2 from PIL import Image, ImageDraw# 判断运行环境 cpu or gpu def check_env():print(dlib.DLIB_USE_CUDA)print(dlib.cuda.get_num_devices())# 判断人脸在图片当中的位置 def…...

RT-Thread: ulog 日志 讲解和使用
说明:记录 RT-Thread: ulog 日志功能和使用流程。 官网资料链接: https://docs.rt-thread.org/#/rt-thread-version/rt-thread-standard/programming-manual/ulog/ulog 1.ulog 简介 日志的定义:日志是将软件运行的状态、过程等信息&#x…...
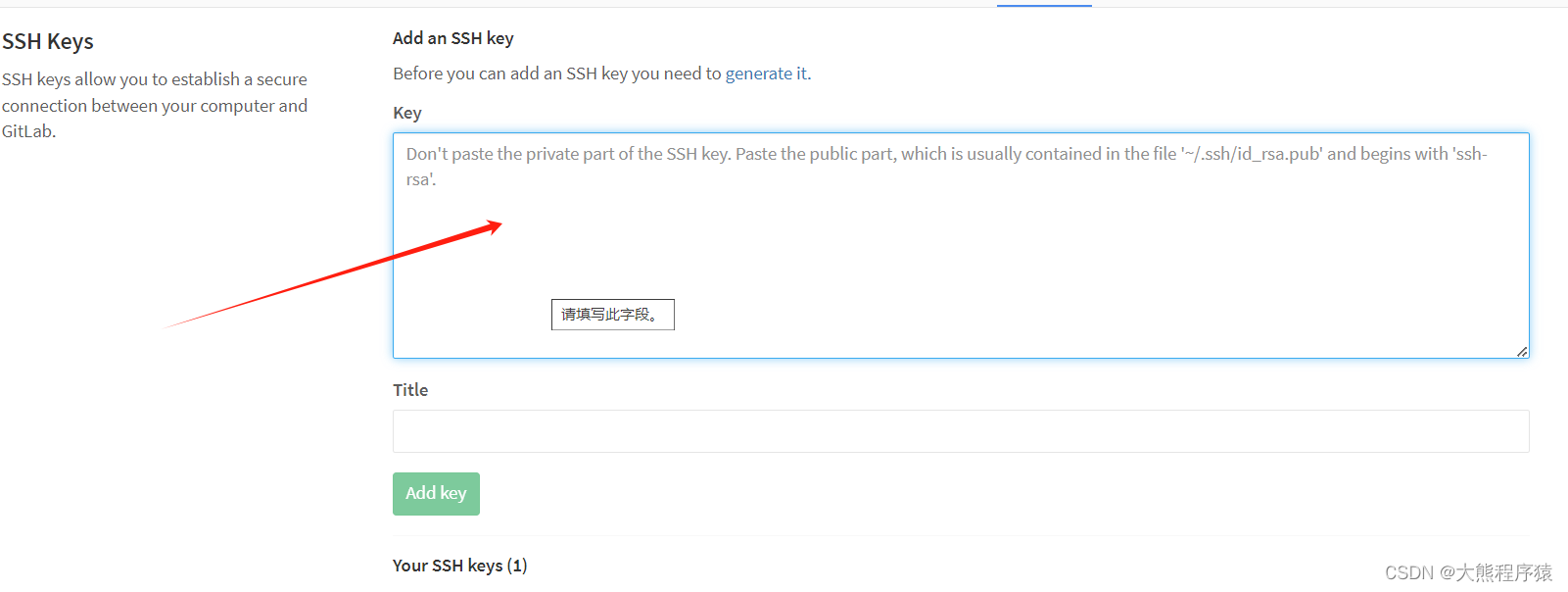
git ssh key 配置
一、Profile Settings-->SSH Keys 我们点击这里会有详情的文档介绍生成sshkey。 ssh-keygen -t rsa -b 2048 -C "邮箱" --回车... 将生成的id_rsa.pub粘贴到如下保存 git config --global user.name "用户名" git config --global user.email "邮…...

MongoDB聚合:$documents
$documents阶段可以根据输入值返回字面意义的文档。 语法 { $documents: <表达式> }$documents接受可解析为对象数组的任何有效表达式,包括: 系统变量,如 $$NOW 或 $$SEARCH_META $let 表达式 $lookup 表达式作用域中的变量 没有…...

程序员英语 - 英文会议常用句型
相信大部分程序员都会有如下经历: 产品经理(BA)们在和外系统聊集成方案时或者给用户解决某个问题时发现搞不定了,这个时候就会拉上程序员一起上会参与讨论或者排查问题,但程序员们英文又不好,上了会又听不懂…...
UV贴图和展开初学者指南
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 介绍 这正是本文的主题——UV贴图——登上舞台的时候。大多数 3D 建…...

解密Path环境变量
解密Path环境变量 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,让我们一起深入探讨程序开发中不可或缺的一项关键技术——“path环境变量”。无论…...
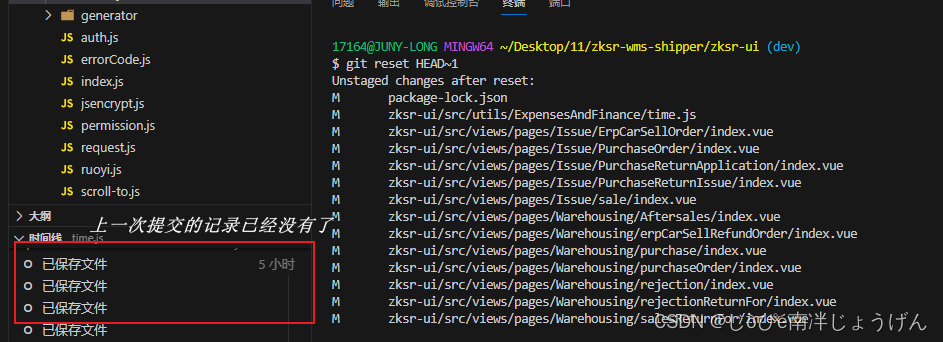
git撤销提交到本地的commit
有些时候,当我们提交代码到本地后,突然发现因为某些原因需要撤销提交本地的代码。 就比如我,因为代码写错了分支,已经提交到本地了,而我需要取消,并且还要把代码搞得另外的分支上。 提交前: …...
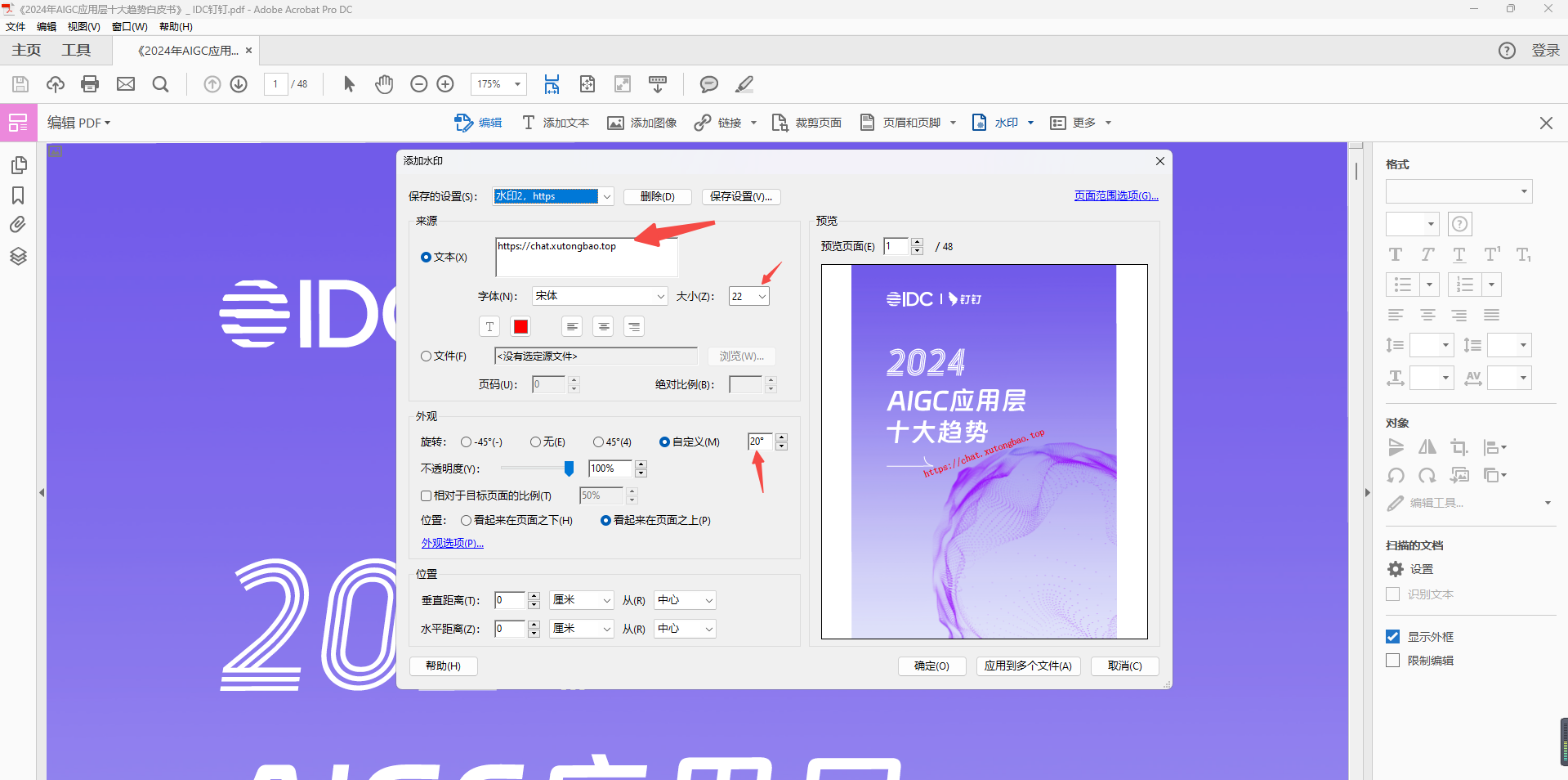
使用Adobe Acrobat Pro DC给pdf文件填加水印
前言 GPT4的官方售价是每月20美元,很多人并不是天天用GPT,只是偶尔用一下。 如果调用官方的GPT4接口,就可以按使用量付费,用多少付多少,而且没有3个小时内只能提问50条的使用限制。 但是对很多人来说调用接口是比较麻烦…...
解决:Unity : Error while downloading Asset Bundle: Couldn‘t move cache data 问题
目录 问题: 尝试 问题得到解决 我的解释 问题: 最近游戏要上线,发现一个现象,部分机型在启动的时候闪退或者黑屏,概率是5%左右,通过Bugly只有个别机型才有这个现象,其实真实情况比这严重的多…...

SpringBoot默认配置文件
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 循序渐进学SpringBoot ✨特色专栏: MySQL学习 🥭本文内容:SpringBoot默认配置文件 📚个人知识库: Leo知识库,欢迎大家访问 1.前言☕…...

Flink构造宽表实时入库案例介绍
1. 安装包准备 Flink 1.15.4 安装包 Flink cdc的mysql连接器 Flink sql的sdb连接器 MySQL驱动 SDB驱动 Flink jdbc的mysql连接器 2. 入库流程图 3. Flink安装部署 上传Flink压缩包到服务器,并解压 tar -zxvf flink-1.14.5-bin-scala_2.11.tgz -C /opt/ 复…...

【Kubernetes】K8s 查看 Pod 的状态
K8s 查看 Pod 的状态 [rootk8s-master1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-3 1/1 Running 2 (34m ago) 14hNAME:Pod 的名称。READY:代表 Pod 里面有几个容器,前面是启动的,后面…...
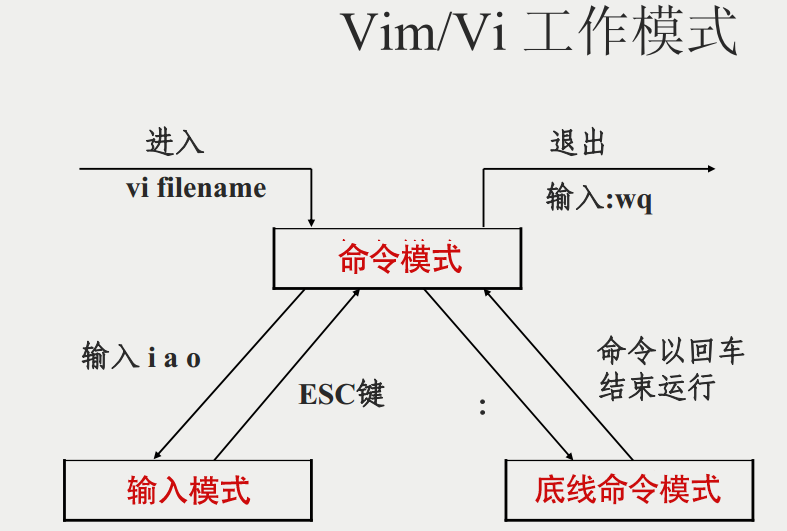
Linux系统操作命令
Linux管理 在线查询Linux命令: https://www.runoob.com/linux/linux-install.htmlhttps://www.linuxcool.com/https://man.linuxde.net/ 1.Linux系统目录结构 Linux系统的目录结构是一个树状结构,每一个文件或目录都从根目录开始,并且根目…...
大模型学习与实践笔记(五)
一、环境配置 1. huggingface 镜像下载 sentence-transformers 开源词向量模型 import os# 设置环境变量 os.environ[HF_ENDPOINT] https://hf-mirror.com# 下载模型 os.system(huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-…...

100个GEO基因表达芯片或转录组数据处理之GSE126848(003)
写在前边 虽然现在是高通量测序的时代,但是GEO、ArrayExpress等数据库储存并公开大量的基因表达芯片数据,还是会有大量的需求去处理芯片数据,并且建模或验证自己所研究基因的表达情况,芯片数据的处理也可能是大部分刚学生信的道友…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...

终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践
终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信作为国内主流的证券…...

如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程
如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本(Onmyoji Auto Script,…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

从零构建Go Web框架:解析the0极简框架的设计原理与实现
1. 项目概述:一个极简主义Web框架的诞生在Web开发的世界里,我们常常面临一个选择:是拥抱功能齐全但略显臃肿的“巨无霸”框架,还是追求极致轻量与灵活的自定义方案?对于许多追求性能、热爱掌控感,或是需要构…...

基于Claude的AI招聘系统:从简历解析到智能评估全流程实践
1. 项目概述:当Claude成为你的招聘官最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。光看名字,你可能会觉得有点玄乎,难道是要让AI来面试和招聘人类?其实,这个项目的核心思路,是…...

PowerInfer:基于稀疏激活的LLM推理引擎,消费级GPU运行百亿大模型
1. 项目概述:当大模型推理遇见“热点激活”最近在折腾本地大模型部署的朋友,可能都绕不开一个核心痛点:显存。动辄几十GB的模型,配上动辄几十GB的推理显存需求,让消费级显卡(比如我们常见的24GB显存的RTX 4…...

ComfyUI ControlNet Aux 终极指南:30+种预处理器让AI图像生成更精准
ComfyUI ControlNet Aux 终极指南:30种预处理器让AI图像生成更精准 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想让您的AI图像生成具备真实…...

树莓派5驱动128x128 LED矩阵:打造复古PICO-8游戏艺术墙
1. 项目概述与核心思路我一直对复古游戏和像素艺术情有独钟,也一直想在家里弄一个既有科技感又能玩的装饰品。最近,我把树莓派5、四块64x64的RGB LED矩阵面板和PICO-8幻想游戏机捣鼓到了一起,成功在墙上挂起了一个128x128像素的“游戏艺术墙”…...