BikeDNA(八)外在分析:OSM 与参考数据的比较2
BikeDNA(八)外在分析:OSM 与参考数据的比较2
1.数据完整性
见链接
2.网络拓扑结构
见链接
3.网络组件
本节仔细研究两个数据集的网络组件特征。
断开连接的组件不共享任何元素(节点/边)。 换句话说,不存在可以从一个断开连接的组件通向另一组件的网络路径。 如上所述,大多数现实世界的自行车基础设施网络确实由许多断开连接的组件组成(Natera Orozco et al., 2020) 。 然而,当两个断开的组件彼此非常接近时,这可能是边缘缺失或另一个数字化错误的迹象。
方法
为了比较 OSM 和参考数据中断开组件的数量和模式,将内在分析的所有组件结果并置,并生成两个新图,分别显示 OSM 和参考数据的组件间隙以及组件连接性的差异。
解释
许多自行车网络的分散性使得很难评估断开的组件是否是由于缺乏数据质量或缺乏正确连接的自行车基础设施而导致的问题。 比较两个数据集中的断开组件可以更准确地评估断开组件是数据问题还是规划问题。
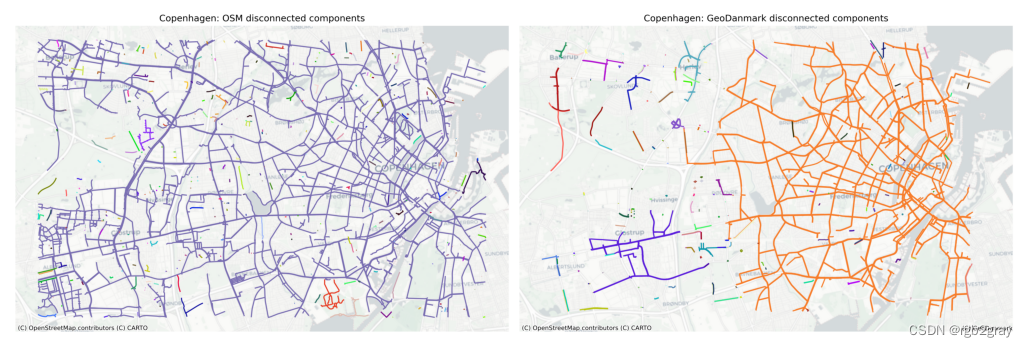
3.1 断开的组件
print(f"The OSM network in the study area consists of {osm_intrinsic_results['component_analysis']['component_count']} disconnected components."
)
print(f"The {reference_name} network in the study area consists of {ref_intrinsic_results['component_analysis']['component_count']} disconnected components."
)
The OSM network in the study area consists of 356 disconnected components.
The GeoDanmark network in the study area consists of 204 disconnected components.
plot_func.plot_saved_maps([osm_results_static_maps_fp + "all_components_osm",ref_results_static_maps_fp + "all_components_reference",]
)
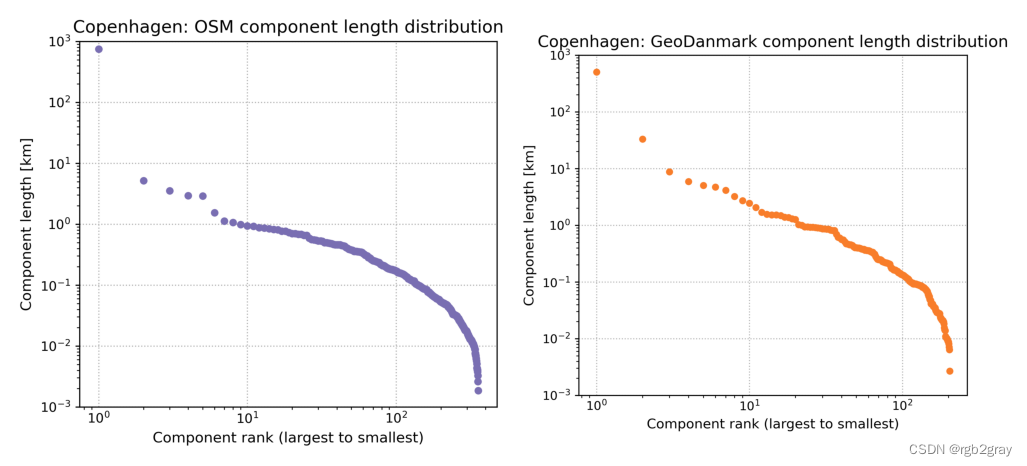
3.2 组件长度分布
所有网络组件长度的分布可以在所谓的 Zipf 图 中可视化,该图按等级对每个组件的长度进行排序,在左侧显示最大组件的长度,然后是第二大组件的长度,依此类推,直到 右侧最小组件的长度。 当 Zipf 图遵循 双对数比例 中的直线时,这意味着找到小的不连续组件的机会比传统分布的预期要高得多 (Clauset et al., 2009)。 这可能意味着网络没有合并,只有分段或随机添加 (Szell et al., 2022),或者数据本身存在许多间隙和拓扑错误,导致小的断开组件。
但是,也可能发生最大的连通分量(图中最左边的标记,等级为 1 0 0 10^0 100)是明显的异常值,而图的其余部分则遵循不同的形状。 这可能意味着在基础设施层面,大部分基础设施已连接到一个大型组件,并且数据反映了这一点 - 即数据在很大程度上没有受到间隙和缺失链接的影响。 自行车网络也可能介于两者之间,有几个大型组件作为异常值。
在对同一区域进行比较时,如下所示,如果一个数据集在其最大连通分量中显示出明显的异常值,而另一个数据集则没有,并且如果它也至少同样大,则通常可以解释为 更加完整。
plot_func.plot_saved_maps([osm_results_plots_fp + "component_length_distribution_osm",ref_results_plots_fp + "component_length_distribution_reference",],figsize=pdict["fsmap"]
)
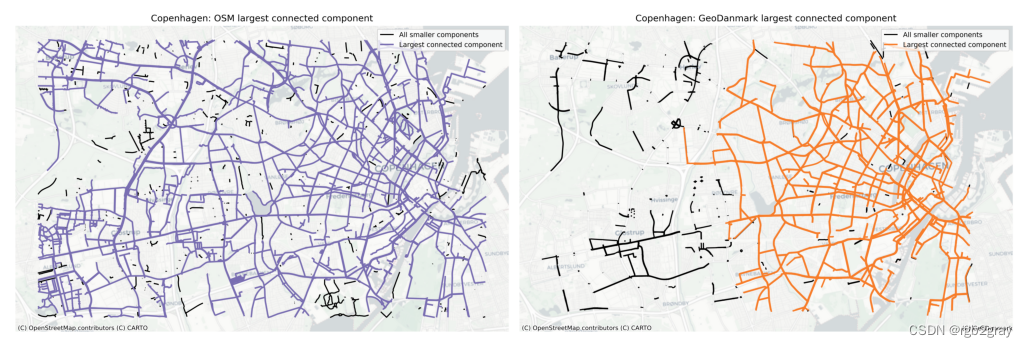
3.3 最大连通分量
# Read largest cc
osm_largest_cc = gpd.read_file(osm_results_data_fp + "largest_connected_component.gpkg")
ref_largest_cc = gpd.read_file(ref_results_data_fp + "largest_connected_component.gpkg")print(f"The largest connected component in the OSM network contains {osm_intrinsic_results['component_analysis']['largest_cc_pct_size']:.2f}% of the network length."
)
print(f"The largest connected component in the {reference_name} network contains {ref_intrinsic_results['component_analysis']['largest_cc_pct_size']:.2f}% of the network length."
)
The largest connected component in the OSM network contains 91.47% of the network length.
The largest connected component in the GeoDanmark network contains 80.04% of the network length.
plot_func.plot_saved_maps([osm_results_static_maps_fp + "largest_conn_comp_osm",ref_results_static_maps_fp + "largest_conn_comp_reference",]
)
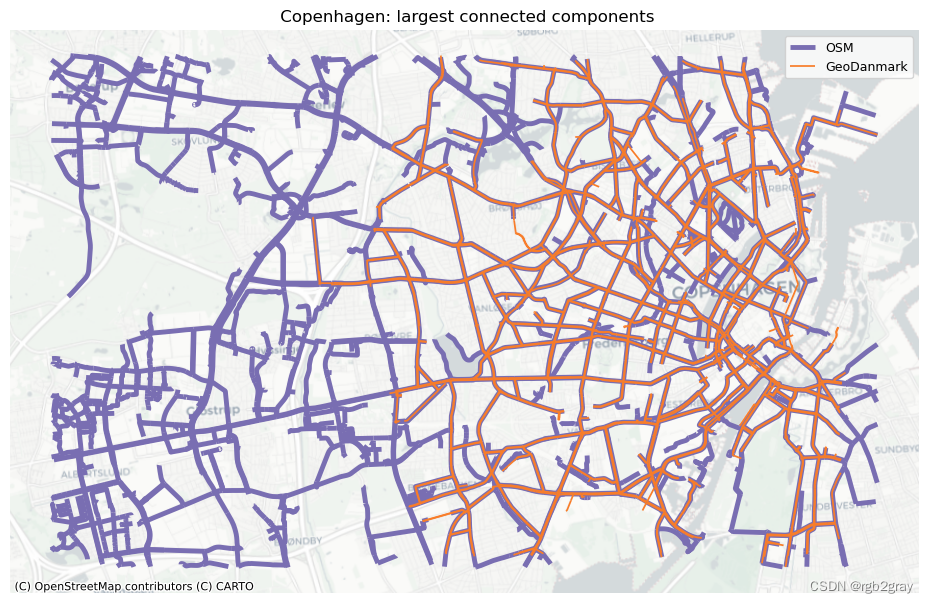
OSM 和参考网络中最大连接组件的叠加
# Plotset_renderer(renderer_map)
fig, ax = plt.subplots(1, figsize=pdict["fsmap"])osm_largest_cc.plot(ax=ax, linewidth=3.5, color=pdict["osm_base"], label="OSM")
ref_largest_cc.plot(ax=ax, linewidth=1.25, color=pdict["ref_base"], label=reference_name)ax.set_title(f" {area_name}: largest connected components")
ax.set_axis_off()
ax.legend()
cx.add_basemap(ax=ax, crs=study_crs, source=cx_tile_2)plot_func.save_fig(fig, compare_results_static_maps_fp + "largest_cc_overlay_compare")
# Plot again for potential report titlepageset_renderer(renderer_map)
fig, ax = plt.subplots(1, figsize=pdict["fsmap"])osm_largest_cc.plot(ax=ax, linewidth=3, color=pdict["osm_base"], label="OSM")
ref_largest_cc.plot(ax=ax, linewidth=1, color=pdict["ref_base"], label=reference_name)
ax.set_axis_off()plot_func.save_fig(fig, compare_results_static_maps_fp + "titleimage",plot_res="high")
plt.close()
3.4 缺少链接
在组件之间潜在缺失链接的图中,将绘制与另一个组件上的边的指定距离内的所有边。 断开的边缘之间的间隙用标记突出显示。 因此,该地图突出显示了边缘,尽管这些边缘彼此非常接近,但它们是断开连接的,因此不可能在边缘之间的自行车基础设施上骑自行车。
# DEFINE MAX BUFFER DISTANCE BETWEEN COMPONENTS CONSIDERED A GAP/MISSING LINK
component_min_distance = 10assert isinstance(component_min_distance, int) or isinstance(component_min_distance, float
), print("Setting must be integer or float value!")
# Read results with component gapsosm_cg_edge_ids = pd.read_csv(osm_results_data_fp + f"component_gaps_edges_{component_min_distance}.csv"
)["edge_id"].to_list()
osm_component_gaps_edges = osm_edges_simplified.loc[osm_edges_simplified.edge_id.isin(osm_cg_edge_ids)
]ref_cg_edge_ids = pd.read_csv(ref_results_data_fp + f"component_gaps_edges_{component_min_distance}.csv"
)["edge_id"].to_list()
ref_component_gaps_edges = ref_edges_simplified.loc[ref_edges_simplified.edge_id.isin(ref_cg_edge_ids)
]osm_component_gaps = gpd.read_file(osm_results_data_fp + f"component_gaps_centroids_{component_min_distance}.gpkg"
)
ref_component_gaps = gpd.read_file(ref_results_data_fp + f"component_gaps_centroids_{component_min_distance}.gpkg"
)
# Interactive plot of adjacent componentsfeature_groups = []if len(osm_component_gaps_edges) > 0:# Feature groups for OSMosm_edges_simplified_folium = plot_func.make_edgefeaturegroup(gdf=osm_edges_simplified,mycolor=pdict["osm_base"],myweight=pdict["line_base"],nametag="OSM network",show_edges=True,)osm_component_gaps_edges_folium = plot_func.make_edgefeaturegroup(gdf=osm_component_gaps_edges,mycolor=pdict["osm_emp"],myweight=pdict["line_emp"],nametag="OSM: Adjacent disconnected edges",show_edges=True,)osm_component_gaps_folium = plot_func.make_markerfeaturegroup(gdf=osm_component_gaps, nametag="OSM: Component gaps", show_markers=True)feature_groups.extend([osm_edges_simplified_folium,osm_component_gaps_edges_folium,osm_component_gaps_folium,])# Feature groups for reference
if len(ref_component_gaps_edges) > 0:ref_edges_simplified_folium = plot_func.make_edgefeaturegroup(gdf=ref_edges_simplified,mycolor=pdict["ref_base"],myweight=pdict["line_base"],nametag=f"{reference_name} network",show_edges=True,)ref_component_gaps_edges_folium = plot_func.make_edgefeaturegroup(gdf=ref_component_gaps_edges,mycolor=pdict["ref_emp"],myweight=pdict["line_emp"],nametag=f"{reference_name}: Adjacent disconnected edges",show_edges=True,)ref_component_gaps_folium = plot_func.make_markerfeaturegroup(gdf=ref_component_gaps, nametag=f"{reference_name}: Component gaps", show_markers=True)feature_groups.extend([ref_edges_simplified_folium,ref_component_gaps_edges_folium,ref_component_gaps_folium,])m = plot_func.make_foliumplot(feature_groups=feature_groups,layers_dict=folium_layers,center_gdf=osm_nodes_simplified,center_crs=osm_nodes_simplified.crs,
)bounds = plot_func.compute_folium_bounds(osm_nodes_simplified)
m.fit_bounds(bounds)
m.save(compare_results_inter_maps_fp + "component_gaps_compare.html")display(m)
print("Interactive map saved at " + compare_results_inter_maps_fp.lstrip("../") + "component_gaps_compare.html")
Interactive map saved at results/COMPARE/cph_geodk/maps_interactive/component_gaps_compare.html
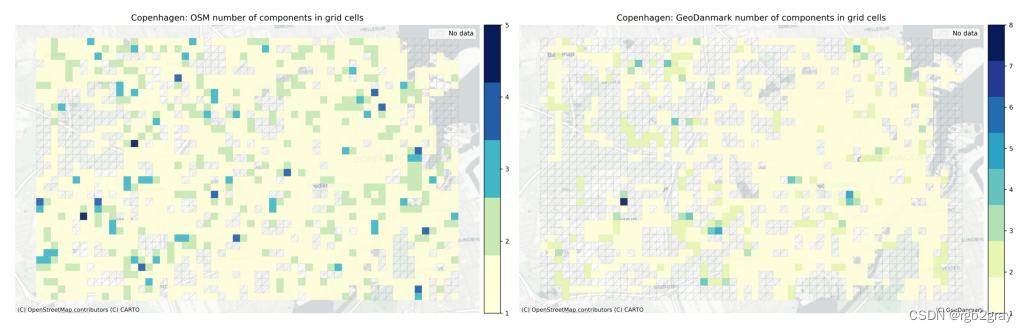
3.5 每个网格单元的组件
下图显示了与网格单元相交的组件数量。 网格单元中的组件数量过多通常表明网络连接较差 - 要么是由于基础设施分散,要么是因为数据质量问题。
plot_func.plot_saved_maps([osm_results_static_maps_fp + "number_of_components_in_grid_cells_osm",ref_results_static_maps_fp + "number_of_components_in_grid_cells_reference",]
)
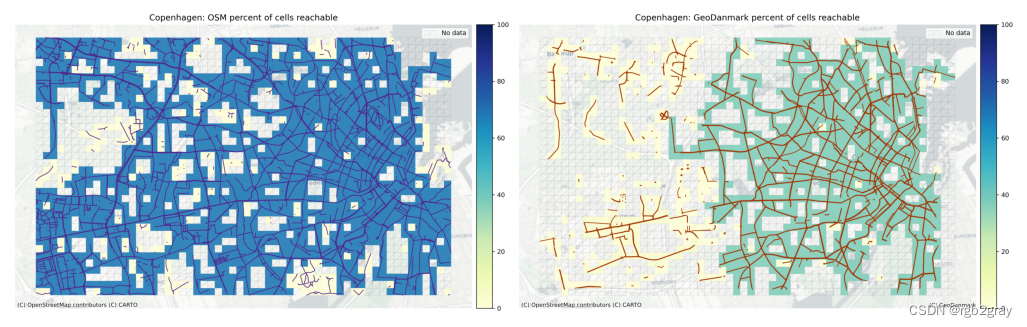
3.6 组件连接
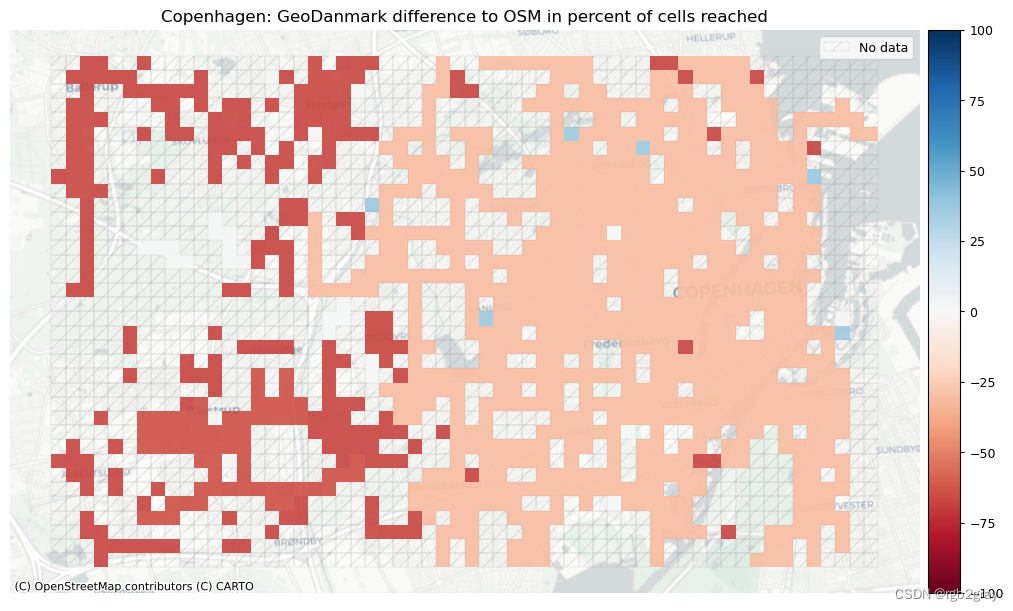
在这里,我们可视化每个单元格可以到达的单元格数量之间的差异。 该指标是网络连接性的粗略衡量标准,但具有计算成本低的优点,因此能够快速突出网络连接性的明显差异。
在显示到达的细胞百分比差异的图中,正值表示使用参考数据集的连接性较高,而负值表示可以从 OSM 数据中的特定细胞到达更多的细胞。
plot_func.plot_saved_maps([osm_results_static_maps_fp + "percent_cells_reachable_grid_osm",ref_results_static_maps_fp + "percent_cells_reachable_grid_reference",]
)
# Compute difference in cell reach percentage (where data for both OSM and REF is available)grid["cell_reach_pct_diff"] = (grid["cells_reached_ref_pct"] - grid["cells_reached_osm_pct"]
)
# Plotset_renderer(renderer_map)# norm color bar
cbnorm_diff = colors.Normalize(vmin=-100, vmax=100)fig, ax = plt.subplots(1, figsize=pdict["fsmap"])
from mpl_toolkits.axes_grid1 import make_axes_locatable
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="3.5%", pad="1%")grid.plot(cax=cax,ax=ax,alpha=pdict["alpha_grid"],column="cell_reach_pct_diff",cmap=pdict["diff"],legend=True,norm=cbnorm_diff,
)# Add no data patches
grid[grid["cell_reach_pct_diff"].isnull()].plot(cax=cax,ax=ax,facecolor=pdict["nodata_face"],edgecolor=pdict["nodata_edge"],linewidth= pdict["line_nodata"],hatch=pdict["nodata_hatch"],alpha=pdict["alpha_nodata"],
)# osm_edges_simplified.plot(ax=ax, color=pdict["osm_base"], alpha=1,linewidth=2)
# ref_edges_simplified.plot(ax=ax, color=pdict["ref_base"], alpha=1,linewidth=1)ax.legend(handles=[nodata_patch], loc="upper right")ax.set_title(f"{area_name}: {reference_name} difference to OSM in percent of cells reached"
)
ax.set_axis_off()
cx.add_basemap(ax=ax, crs=study_crs, source=cx_tile_2)plot_func.save_fig(fig, compare_results_static_maps_fp + "percent_cell_reached_diff_compare")
4.概括
# Load results from intrinsic
osm_intrinsic_df = pd.read_csv(osm_results_data_fp + "intrinsic_summary_results.csv",index_col=0,names=["OSM"],header=0,
)ref_intrinsic_df = pd.read_csv(ref_results_data_fp + "intrinsic_summary_results.csv",index_col=0,names=[reference_name],header=0,
)# Drop rows from OSM results not available for reference
osm_intrinsic_df.drop(["Incompatible tag combinations", "Missing intersection nodes"],axis=0,inplace=True,
)# Save new results
osm_intrinsic_df.at["Alpha", "OSM"] = osm_alpha
osm_intrinsic_df.at["Beta", "OSM"] = osm_beta
osm_intrinsic_df.at["Gamma", "OSM"] = osm_gammaref_intrinsic_df.at["Alpha", reference_name] = ref_alpha
ref_intrinsic_df.at["Beta", reference_name] = ref_beta
ref_intrinsic_df.at["Gamma", reference_name] = ref_gamma# Combine
extrinsic_df = osm_intrinsic_df.join(ref_intrinsic_df)
assert len(extrinsic_df) == len(osm_intrinsic_df) == len(ref_intrinsic_df)
extrinsic_df.style.pipe(format_extrinsic_style)
| OSM | GeoDanmark | |
|---|---|---|
| Total infrastructure length (km) | 1,056 | 626 |
| Protected bicycle infrastructure density (m/km2) | 5,342 | 2,999 |
| Unprotected bicycle infrastructure density (m/km2) | 427 | 455 |
| Mixed protection bicycle infrastructure density (m/km2) | 55 | 0 |
| Bicycle infrastructure density (m/km2) | 5,825 | 3,454 |
| Nodes | 5,016 | 4,125 |
| Dangling nodes | 1,828 | 870 |
| Nodes per km2 | 28 | 23 |
| Dangling nodes per km2 | 10 | 5 |
| Overshoots | 8 | 21 |
| Undershoots | 18 | 11 |
| Components | 356 | 204 |
| Length of largest component (km) | 747 | 501 |
| Largest component's share of network length | 91% | 80% |
| Component gaps | 78 | 52 |
| Alpha | 0.11 | 0.10 |
| Beta | 1.15 | 1.14 |
| Gamma | 0.38 | 0.38 |
5.保存结果
extrinsic_df.to_csv(compare_results_data_fp + "extrinsic_summary_results.csv", index=True
)with open(compare_results_data_fp + f"grid_results_extrinsic.pickle", "wb"
) as f:pickle.dump(grid, f)
from time import strftime
print("Time of analysis: " + strftime("%a, %d %b %Y %H:%M:%S"))
Time of analysis: Mon, 18 Dec 2023 20:25:24
相关文章:
BikeDNA(八)外在分析:OSM 与参考数据的比较2
BikeDNA(八)外在分析:OSM 与参考数据的比较2 1.数据完整性 见链接 2.网络拓扑结构 见链接 3.网络组件 本节仔细研究两个数据集的网络组件特征。 断开连接的组件不共享任何元素(节点/边)。 换句话说,…...

28 星际旋转
效果演示 实现了一个太阳系动画,其中包括了地球、火星、金星、土星、水星、天王星、海王星以及火卫二号等行星的动画效果。太阳系的行星都被放在一个固定的容器中,并使用CSS动画来实现旋转和移动的效果。当太阳系的行星绕着太阳运行时,它们会…...
)
测试人员必备基本功(3)
容易被忽视的bug 第三章 查询列表容易被忽视的bug 文章目录 容易被忽视的bug第三章 查询列表容易被忽视的bug 前言1.查询角色2.接口设计 三、测试设计1.测试点2.容易发现bug的测试点如下: 总结 前言 一个WEB系统的所有功能模块,其实都是围绕“增、删、…...

记一次数据修复,需要生成十万条sql进行数据回滚
一、背景 数据回滚 二、难点 2.1 需要处理的数据涉及多达数万个用户,每个用户涉及的表达到10个 2.2 时间紧急,需要快速回滚,数据需要完整 2.3 数据存在重复或空缺问题 三、解决方案 3.1 数据多,使用分批处理,把大任务分割成若…...

[paddle]paddlehub部署paddleocr的hubserving服务
步骤如下: 第一步:首先需要安装好paddleocr环境已经paddlehub环境 第二步:下载paddleocr源码: git clone https://github.com/PaddlePaddle/PaddleOCR.git 然后切换到paddocr目录执行 新建个文件夹叫Inference把paddleocr模型…...

2024校招,网易互娱游戏测试工程师一面
前言 大家好,今天回顾一下,我前段时间参加的游戏测试工程师技术面试 两个面试官,一个提问,另一个负责记录 过程 自我介绍比赛经历介绍一下使用的博弈算法穷举算法对性能有什么影响怎么评估局面好坏出现的bug怎么解决的&#x…...
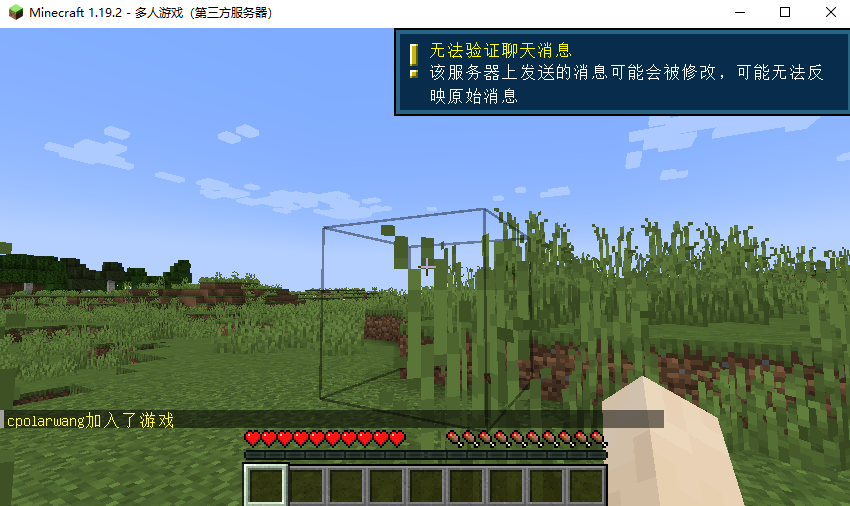
Linux Ubuntu搭建我的世界Minecraft服务器实现好友远程联机MC游戏
文章目录 前言1. 安装JAVA2. MCSManager安装3.局域网访问MCSM4.创建我的世界服务器5.局域网联机测试6.安装cpolar内网穿透7. 配置公网访问地址8.远程联机测试9. 配置固定远程联机端口地址9.1 保留一个固定tcp地址9.2 配置固定公网TCP地址9.3 使用固定公网地址远程联机 前言 Li…...

Springboot对接ceph集群以及java利用s3对象网关接口与ceph集群交互
springboot中引入相关依赖 <dependency><groupId>software.amazon.awssdk</groupId><artifactId>regions</artifactId><version>2.22.13</version></dependency><dependency><groupId>software.amazon.awssdk<…...

nrm使用
为了更方便的切换下包的镜像源,我们可以安装 nrm 这个小工具,利用 nrm 提供的终端命令,可以快速查看和切换下 包的镜像源。 //通过 npm 包管理器,将 nrm 安装为全局可用的工具 npm i nrm -g//查看所有可用的镜像源 nrm ls//将下载…...
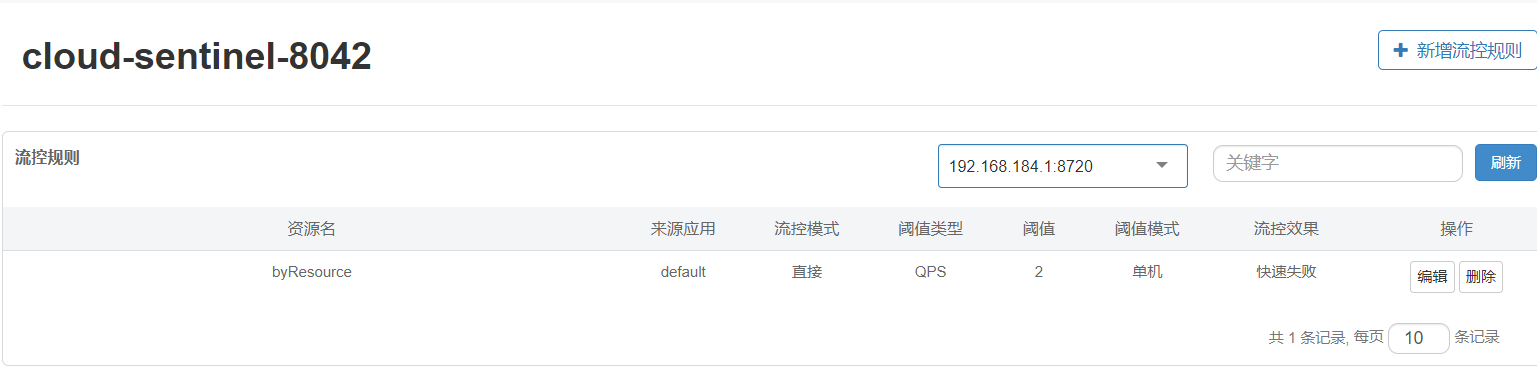
06-微服务OpenFeigh和Sentinel持久化
一、OpenFeign基础应用 1.1 概念 OpenFeign是一种声明式、模板化的HTTP客户端。在Spring Cloud中使用OpenFeign,可以做到使用HTTP请求访问远程服务,就像调用本地方法一样的,开发者完全感知不到这是在调用远程方法,更感知不到在访…...
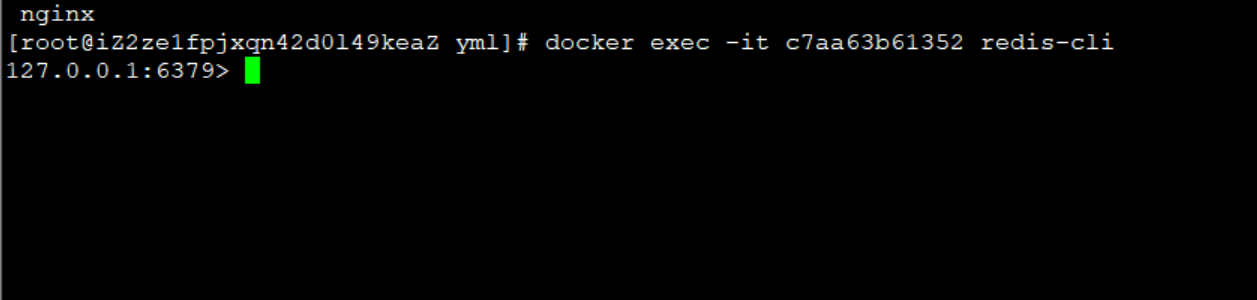
docker 安装redis (亲测有效)
目录 1 安装 1 安装 1 将redis 的 tar 包 上传到服务器 上传之后tar 包,将他变成镜像 输入docker images,发现目前是没有镜像的,现在将tar 包变成镜像 docker load -i redis.tar以上就将tar 包变成镜像了 现在在宿主机找一个地方,存放数据…...
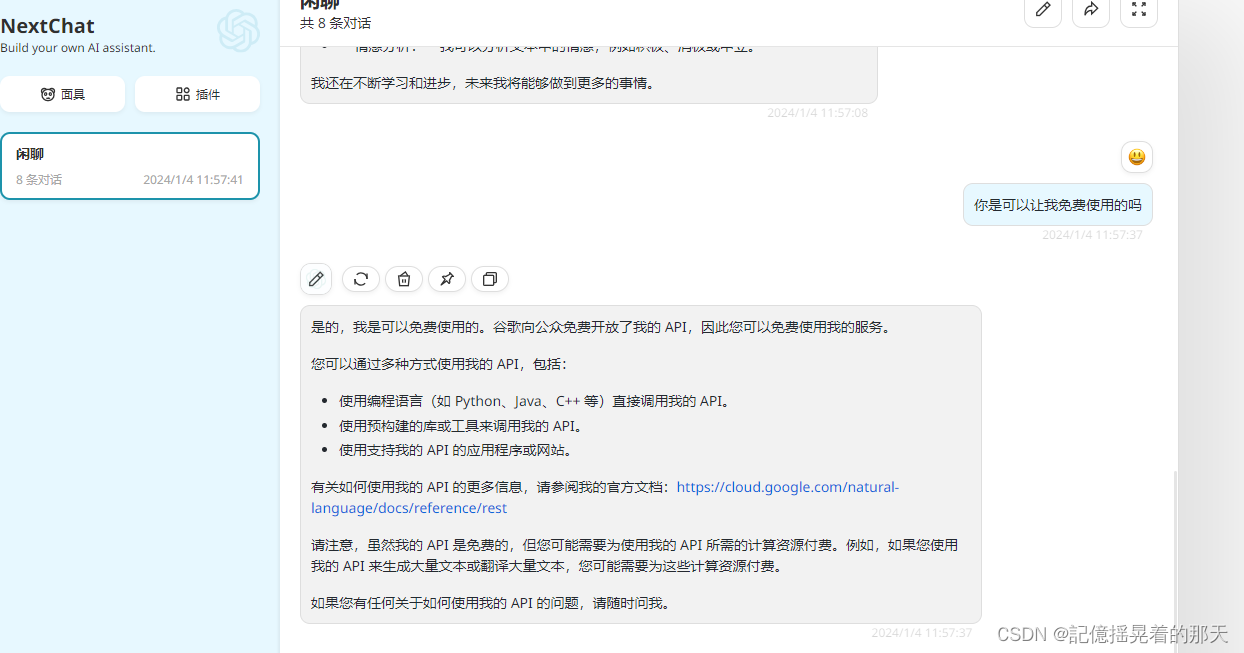
利用GitHub开源项目ChatGPTNextWeb构建属于自己的ChatGPT - Docker
Docker部署ChatGPTNextWeb ChatGPTNextWeb项目github开源地址:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web 根据文档部署ChatGPTNextWeb 文档地址:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/blob/main/README_CN.md 步骤一&#…...

Vue3使用ElementPlus中的el-upload手动上传并调用上传接口
前端代码 <div class"upload-div"><el-uploadv-model:file-list"form.fileImageList"ref"uploadRef"capture"false"action"#"accept"image/*"list-type"picture-card":on-change"handleC…...

【Github3k+⭐️】《CogAgent: A Visual Language Model for GUI Agents》译读笔记
CogAgent: A Visual Language Model for GUI Agents 摘要 人们通过图形用户界面(Graphical User Interfaces, GUIs)在数字设备上花费大量时间,例如,计算机或智能手机屏幕。ChatGPT 等大型语言模型(Large Language Mo…...

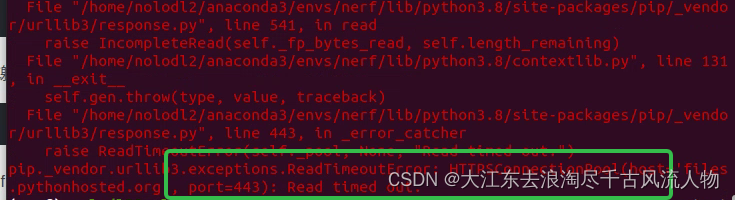
【conda】pip安装报错,网络延时问题解决记录(亲测有效)
【conda】pip安装报错,网络延时问题解决记录 1. pip install 报错如下所示2. 解决方案: 1. pip install 报错如下所示 pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.…...

Spring Boot整理-Spring Boot的优势
Spring Boot 提供了多个显著的优势,特别是对于快速开发和简化 Spring 应用的配置和部署。这些优势包括: 简化配置:Spring Boot 的“约定优于配置”的原则意味着许多 Spring 应用的常见配置项被自动设置,这减少了开发人员需要编写和维护的配置代码量。快速启动和部署:Sprin…...

C++标准学习--decltype
decltype / auto 是具有类型推导功能的 类型 描述/占位 符 decltype: 获取对象或表达式的类型auto: 类型自动推导 decltype 可以获取变量类型, (并不同于python的type,但python能打印出type获取的名称, C通过typeid实现ÿ…...
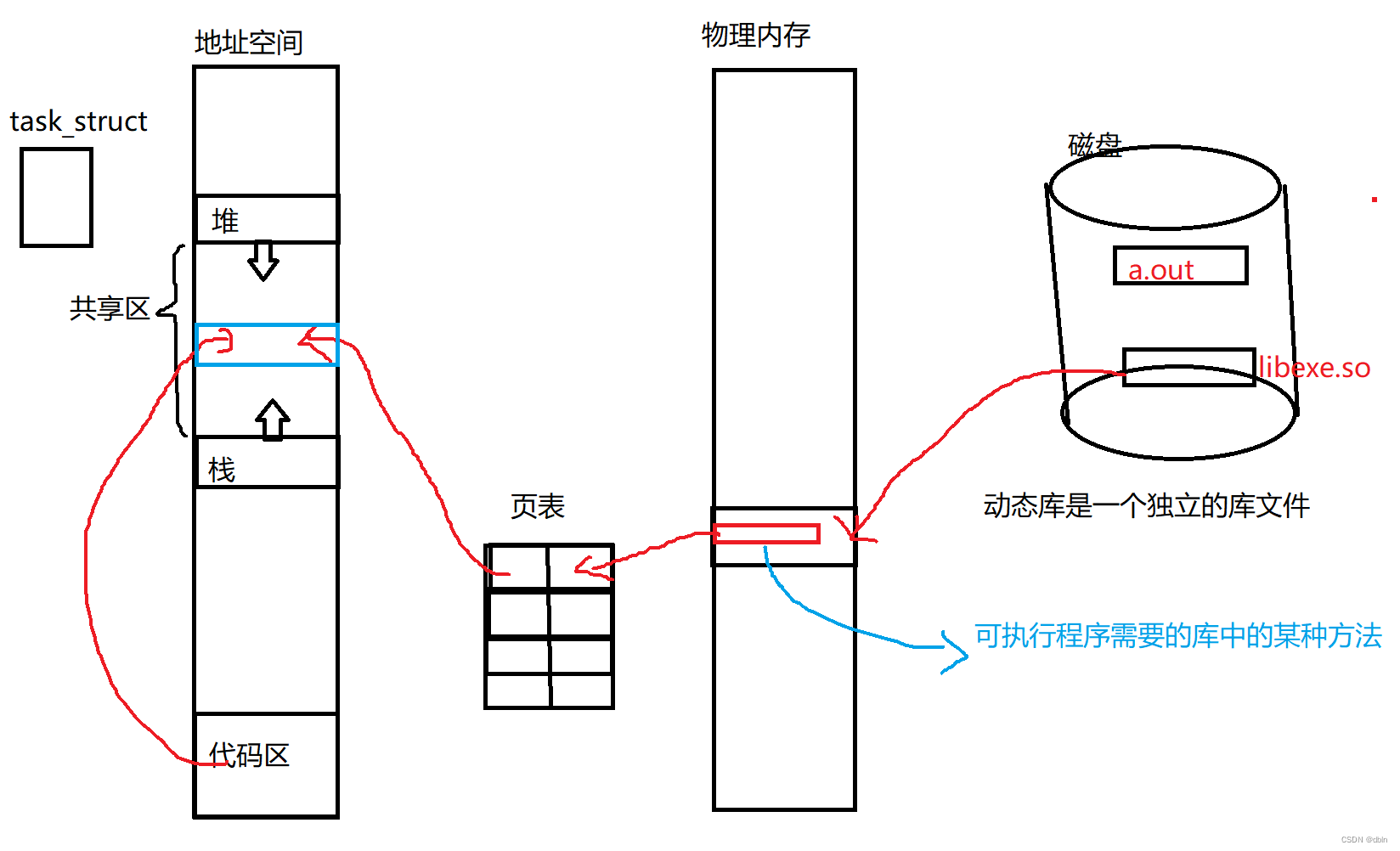
Linux之静态库和动态库
目录 一、前言 二、对于库的理解 三、静态库 四、动态库 五、动静态库的加载 一、前言 在之前,我们讲了静态库和动态库,详情请跳转:静态库和动态库 下面我们将从工程师的角度,去了解静态库和动态库的形成过程,以…...
(三))
erlang/OTP 平台(学习笔记)(三)
分布式 Erlang 借助于语言属性和基于复制的进程通信,Erlang程序天然就可以分布到多台计算机上。要问为什么,且让我们来看两个用Java或C这类语言写成的进程,它们运作良好并以共享内存为通信手段。假设你已经搞定了锁的问题,一切精…...

从Hub到交换机:一个被遗忘的环路案例,带你重新审视STP的实际价值与配置陷阱
从Hub到交换机:一个被遗忘的环路案例,带你重新审视STP的实际价值与配置陷阱 在某个制造业工厂的机房角落,一台老式集线器(HUB)仍然顽强地工作着——它连接着几台关键设备,因为某些历史原因尚未被替换。当网…...
)
Midjourney提示词工程终极护城河:基于CLIP文本嵌入空间的向量对齐技术(附Python可视化调试工具)
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词工程终极护城河:基于CLIP文本嵌入空间的向量对齐技术(附Python可视化调试工具) 在生成式AI实践中,提示词质量差异常导致图像语义漂移——…...

终极指南:用ContextMenuManager彻底解决Windows右键菜单混乱问题
终极指南:用ContextMenuManager彻底解决Windows右键菜单混乱问题 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾因Windows右键菜单过于臃肿…...

SEM轮廓技术在22nm以下OPC建模中的创新应用
1. SEM轮廓技术在OPC建模中的革命性突破在22nm及以下节点的半导体制造工艺中,光学邻近效应校正(OPC)面临着前所未有的挑战。传统基于CD(临界尺寸)测量的建模方法在应对复杂2D结构时显得力不从心,特别是在处…...

GitHub加速实战指南:突破国内访问瓶颈的高效方案
GitHub加速实战指南:突破国内访问瓶颈的高效方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 对于国内开发者而言&a…...

如何利用Deep SORT实现稳定高效的多目标追踪
如何利用Deep SORT实现稳定高效的多目标追踪 【免费下载链接】deep_sort Simple Online Realtime Tracking with a Deep Association Metric 项目地址: https://gitcode.com/gh_mirrors/de/deep_sort 在计算机视觉的实际应用中,多目标追踪一直是一个技术难点…...
Pixel-to-Space 像素到空间 一镜到底·跨镜连续技术解析方案
Pixel-to-Space 像素到空间 一镜到底跨镜连续技术解析方案一、技术总览1.1 核心定义Pixel-to-Space像素到空间,是一套自成体系的二维视频像素向三维物理空间实时反演的全域感知范式,跳出市面传统视频解析与空间重建的通用研发路线,形成专属化…...

Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力
Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

快速学C语言——第19章:C语言常用开发库
第19章:C语言常用开发库 C语言的标准库提供了丰富的函数来帮助开发者完成各种常见任务。掌握这些标准库的使用可以大大提高编程效率。 ⚠️本章只给出日常开发中常用的函数! 19.1 标准输入输出库(stdio.h) stdio.h 是最常用的库&a…...

解决ClaudeCode频繁封号与Token不足问题转向稳定聚合平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决ClaudeCode频繁封号与Token不足问题转向稳定聚合平台 对于依赖Claude Code进行编程辅助的开发者而言,服务中断和资…...