【性能调优】local模式下flink处理离线任务能力分析
文章目录
- 一. flink的内存管理
- 1.Jobmanager的内存模型
- 2.TaskManager的内存模型
- 2.1. 模型说明
- 2.2. 通讯、数据传输方面
- 2.3. 框架、任务堆外内存
- 2.4. 托管内存
- 3.任务分析
- 二. 单个节点的带宽瓶颈
- 1. 带宽相关理论
- 2. 使用speedtest-cli 测试带宽
- 3. 任务分析
- 3. 其他工具使用介绍
本文相关讨论
- flink内存对任务性能的影响:通过了解内存模型,了解这些模型都负责那些工作,比如用户代码使用堆,数据通讯使用直接内存等,以便能够根据任务特点针对性调整任务内存;
- 并发与带宽之间的关系,local模式下怎么根据带宽,设置最佳线程数;
- 内存监控相关命令。
任务说明:
使用local模式运行flink sql任务,任务为:从hdfs解析数据到hdfs中的离线任务,其中数据量有4亿,文件数有13个,初始运行参数为:堆内存设为3g、并发设为13,其中运行命令如下:
java -XX:NativeMemoryTracking=summary -Xms3096m -Xmx3096m -cp $FLINK_HOME/lib/chunjun-core.jar:$FLINKX_HOME/bin/:$FLINK_HOME/lib/*:$HADOOP_CLASSPATH \$CLASS_NAME -job hdfs-hdfs.sql -mode local -jobType sql \-flinkConfDir $FLINK_HOME/conf \-flinkLibDir $FLINK_HOME/lib \-hadoopConfDir $HADOOP_CONF_DIR \-confProp "{ \"taskmanager.numberOfTaskSlots\":13}"
本例子使用chunjun提交flink任务。
一. flink的内存管理
了解flink内存模型,可以让我们针对任务特点,合理设置内存,在不造成内存浪费的同时,分析出任务性能瓶颈。
1.Jobmanager的内存模型
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。框架内存、特殊批处理source、cp、akka通讯(java api实现)。 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的_堆外内存(直接内存或本地内存)_。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
Flink 需要多少 JVM 堆内存,很大程度上取决于运行的作业数量、作业的结构及上述用户代码的需求。
jobManager的内存管理相关调优不用关注太多,因为jobmanager的任务相对固定。
2.TaskManager的内存模型
2.1. 模型说明
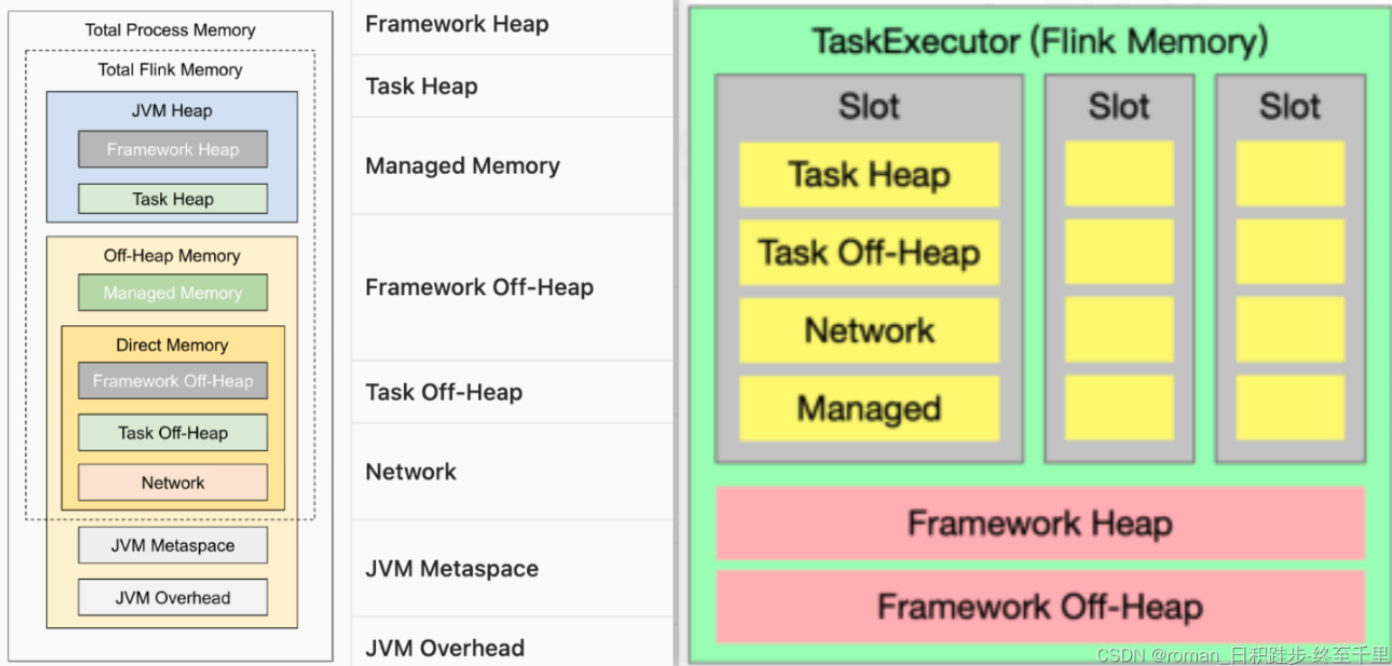
| 内存分类 | 解释 |
|---|---|
| 一. 堆内存 | |
| 1. 框架堆内存 | 启动TM所需内存 |
| 2. Task堆内存 | 存放、执行Flink算子及用户代码 |
| 二.堆外内存 | |
| 3. 框架堆外内存* | 用于 Flink 框架的堆外内存(直接内存或本地内存) |
| 4. 任务堆外内存* | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)(比如用户代码使用netty进行数据传输)。 |
| 5. 网络内存* | 用户任务之间数据传输的直接内存 |
| 6. 托管内存 | 用于存放Flink的中间结果和RocksDB State Backend 的本地内存 |
| 7. JVM Metaspace和Overhead内存 | 用于JVM存储类元数据;JVM的例如栈空间、垃圾回收空间等开销 |
*代表直接内存。
2.2. 通讯、数据传输方面
TaskManager和JobManager之间的通讯
主要依赖JVM堆内存,网络缓冲器内存在数据传输方面也起到了一定的作用。具体来说:
- TaskManager和JobManager之间的所有通信(例如任务提交,状态更新等)都是通过Akka消息进行的。
- 在数据传输过程中,TaskManager使用的网络缓冲器内存也在一定程度上参与了和JobManager的通信。比如说,TaskManager需要向JobManager发送一些统计信息,或者在写入或读取远程状态数据时,都需要使用网络缓冲器内存。
TaskManager之间的通信
TaskManager之间的通信主要使用的是网络缓冲器内存(Network Memory)。当两个TaskManager之间需要交换数据时,会使用网络缓冲器内存来存储待发送的数据以及接收到的数据。
Flink的网络通信基于Netty,Netty默认使用堆外(off-heap)内存进行数据的读写操作。在数据发送方,Flink会先将数据序列化后存放到网络缓冲器中,然后通过网络发送到接收方。在接收方,Flink会从网络缓冲器中读取数据,然后进行反序列化,恢复成原始的数据格式。 网络缓冲器内存的大小会影响Flink job的性能,如果设置得过小可能会导致数据传输的瓶颈,过大则可能会浪费内存资源。
2.3. 框架、任务堆外内存
- 框架堆外内存:主要用于网络缓冲和一些需要大数据计算的操作,如排序或哈希操作。Flink使用堆外内存以存储中间结果,防止大数据操作时耗尽所有的Java堆内存。
- 任务堆外内存:主要用于用户代码和操作,以及用户代码依赖的库和插件的内存需求。它使得用户代码和框架操作能在任务中并行运行而不会互相干扰。
在实际操作中,你可以根据具体工作负载的需求来调整这三部分内存的配置。
2.4. 托管内存
托管内存(Managed Memory)主要用于数据处理和中间结果的存储,被用于以下几个主要的用途:
- 状态后端:如果你使用RockDB这样的内存稀疏状态后端,那么托管内存可以用作写缓冲区或者读缓冲区,用来优化读写的性能。
- 网络缓冲:在数据发送和接收过程中,Flink使用托管内存作为网络缓冲区。
- 批处理算子:在进行批处理的计算时,如排序和哈希操作,Flink会使用到托管内存。
状态后端存储
- Flink 任务处理中的状态(例如键控状态)通常需要持久化,以确保容错性和恢复能力。
托管内存是Flink特地为状态后端和网络缓冲等用途分配的内存段。 托管内存被用于存储状态后端的数据,这样可以避免将大量状态数据存储在 JVM 堆内存中,从而提高任务的稳定性和性能。- 当你启用RockDB状态后端时,Flink将把数据写入磁盘,而不仅仅是维持在内存中,这样可以支持更大的状态大小和更长的保留周期。
3.任务分析
任务为local模式,任务为从hdfs读到hdfs写,hdfs的源数据有13个文件,总共有4亿的数据,每条数据98byte。下面从flink内存模型的角度分析下任务对各内存的使用情况
local模式代表,在机器上启动一个minicluster,这包含一个jobmanager、一个taskmanager。
- 任务启动时会使用框架堆内存(Framework Heap Memory)创建启动jobmanager和taskmanager。
- 因为只有一个taskmanager,也就是不会涉及到taskmanager之间的数据传输,所以不会用到网络缓存(Network Memory)。
- 从用户代码层面看,这里使用的是flink sql ,其中hdfs-connector用于读写数据,这算是用户代码,而相关读写实现使用的是hdfs
client相关api实现,api中没有涉及到使用直接内存的方法,所以读写数据的操作是在堆内存中(.任务堆内存(Task Heap Memory))。- 此离线任务来一条数据处理一条,即任务无状态、或中间结果,也就是说任务不需要托管内存(Managed memory)
所以总体分析下来,local模式下我们需要调控的是堆内存,因为数据传输主要存在于用户代码中。
二. 单个节点的带宽瓶颈
根据拿到的带宽,与任务消费数据速度,我们大概可以测试出任务的并发度。
1. 带宽相关理论
网络带宽是指在一个固定的时间内(1秒),能通过的最大位数据,是个峰值数据, 单位是Mbps。
上行带宽/下行带宽
带宽的上行和下行分别指的是网络传输中数据的上传和下载方向。
- 对于服务器来说对外提供服务用的是自己的
上行带宽和用户的下行带宽, 而用户上传东西则用的自己的上行带宽和服务器的下行带宽- 对于用户来说访问服务器用的是用户的
下行带宽和服务器的上行带宽, 而上传文件则用的用户的上行带宽和服务器的下行带宽
流量单位/存储单位
下载速度的单位为KB/s,而带宽所使用的计量单位为Kb/s,两者相差8倍:8 bit = 1 B 一字节 (1Byte)
带宽速度计算:
1M带宽下载速度125KB/s;
2M带宽下载速度125KB/s*2;
10M带宽下载速度125KB/s*10=1.25M/s;
20M带宽下载速度125KB/s*20=2.5M/s;
100M带宽下载速度125KB/s*100=12.5M/s
实际带宽速率的损失
理论上,2Mbps带宽,宽带理论速率是 256KB/s。实际速率大约为103–200kB/s。4M,即4Mb/s宽带理论速率是 512KB/s 实际速率大约为200—440kB/s。
其原因是受用户计算机性能、网络设备质量、资源使用情况、网络高峰期、网站服务能力、线路衰耗、信号衰减等多因素的影响而造成的)。
吞吐量
吞吐量是指在没有帧丢失的情况下,设备能够接收并转发的最大数据速率实际带宽,单位Mbps, 通常用来描述一个系统的性能。
与带宽的关系:吞吐量即在规定时间、空间及数据在网络中所走的路径(网络路径)的前提下,下载文件时实际获得的带宽值。由于多方面的原因,实际上吞吐量往往比传输介质所标称的最大带宽小得多
例如: 带宽为10Mbps的链路连接的一对节点可能只达到2Mbps的吞吐量。这样就意味着,一个主机上的应用能够以2Mbps的速度向另外的一个主机发送数据。
2. 使用speedtest-cli 测试带宽
# 安装
$ sudo yum install -y speedtest-cli # 测试
$ speedtest-cli
Retrieving speedtest.net configuration...
Testing from China Unicom (111.206.170.119)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by China Telecom TianJin-5G (TianJin) [123.83 km]: 65.213 ms
Testing download speed................................................................................
Download: 143.51 Mbit/s
Testing upload speed......................................................................................................
Upload: 456.74 Mbit/s
3. 任务分析
Speedtest-cli测量出的是你的网络连接的最大理论带宽。实际上,你的实际网络带宽可能因为很多因素(例如网络拥堵,服务器性能,距离测试服务器的远近,你本地网络的设置等)而低于这个理论值。对于代码中处理数据,还要考虑代码处理数据的效率。
实际在测试过程中,有如下瓶颈:
- 使用3G内存启动flink任务,对于每条数据为98Byte,单线程每次处理4万条数据,13个线程(数据源共有13个文件)同时消费,花费20s,大概算下来每秒处理2.43MB/s数据。
- 当增大堆内存时效率并未提升,也就是到了带宽瓶颈。且当我将内存降低到2G时,消费速度并未明显减小。
也就是说每秒处理2.43MB/s数据是机器带宽瓶颈,目前最佳内存为2G,并发减小时处理时间会比例减小,当并发减小到4时,处理速度达到快,3秒处理完,但总体算下来小于每秒处理2.43MB/s数据,也就是说并发根据文件数设置可以达到最佳性能。
3. 其他工具使用介绍
测试任务占用内存: jps + top
# 1. 找到指定进程
jps -l
2900 com.dtstack.chunjun.Main
3645 sun.tools.jps.Jps# 2. 查看一个进程占用内存
top -p <pid>
按e会转换内存为byte->m->g等单位,较为人性化的展示。
相关文章:
【性能调优】local模式下flink处理离线任务能力分析
文章目录 一. flink的内存管理1.Jobmanager的内存模型2.TaskManager的内存模型2.1. 模型说明2.2. 通讯、数据传输方面2.3. 框架、任务堆外内存2.4. 托管内存 3.任务分析 二. 单个节点的带宽瓶颈1. 带宽相关理论2. 使用speedtest-cli 测试带宽3. 任务分析3. 其他工具使用介绍 本…...

Zabbix监控(2)
目录 一.自动发现 配置自动发现:(被动模式) 修改三台服务器的hosts文件: 修改agent02的配置文件: 访问页面,删除客服端主机配置: 在配置的自动发现中添加规则: 我们重启的zab…...
uni-app中代理的两种配置方式
方式一: 在项目的 manifest.json 文件中点击 源码视图 在最底部的vue版本下编写代理代码 方式二: 在项目中创建 vue.config.js 文件然后进行配置 在页面中发起请求 完整的url:http://c.m.163.com/recommend/getChanListNews?channelT1457068979049&size10 …...
循环异步调取接口使用数组promiseList保存,Promise.all(promiseList)获取不到数组内容,then()返回空数组
在使用 vue vant2.13.2 技术栈的项目中,因为上传文件的接口是单文件上传,当使用批量上传时,只能循环调取接口;然后有校验内容:需要所有文件上传成功后才能保存,在文件上传不成功时点击保存按钮,…...

C++轮子 · STL 序列容器
STL中大家最耳熟能详的可能就是容器,容器大致可以分为两类,序列型容器(SequenceContainer)和关联型容器(AssociativeContainer)这篇文章中将会重点介绍STL中的各种序列型容器和相关的容器适配器。主要内容包括 std::vectorstd::arraystd::dequestd::queuestd::stackstd::…...
浅谈智慧路灯安全智能供电方案设计
摘要: 智慧路灯,作为智慧城市、新基建、城市更新的主要组成部分,近些年在各大城市已得到很好的落地和 应用,但其与传统路灯相比集成大量异元异构电子设备,这些设备的供电电压、接口形式、权属单位各不相同, 如何设计一…...
:工厂方法模式)
C#设计模式教程(2):工厂方法模式
工厂方法模式是一种创建型设计模式,它定义了一个用于创建对象的接口,但让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。 C# 代码实现 以下是C#中实现工厂方法模式的一个简单示例: 首先,定义一个抽象产品(Product)类,它是所有具体产品的基类。 pu…...

程序员的能力-如何成为不会过时的“码农”
码农是指从事编程工作的人,也被称为程序员或开发者。他们使用计算机语言和工具来编写、测试和维护软件程序或网站。码农通常需要具备扎实的计算机科学知识、编程技能和问题解决能力,以及良好的逻辑思维和团队合作能力。他们可以在软件开发公司、科技企业…...
【OpenAI】自定义GPTs应用(GPT助手应用)及外部API接口请求
11月10日,OpenAI正式宣布向所有ChatGPT Plus用户开放GPTs功能 简而言之:GPT应用市场(简称GPTs, 全称GPT Store) Ps: 上图为首次进入时的页面,第一部分是自己创建的GPTs应用,下面是公开可以使用的GPTs应用 一、创建GPTs…...

canvas绘制不同样式的五角星(图文示例)
查看专栏目录 canvas实例应用100专栏,提供canvas的基础知识,高级动画,相关应用扩展等信息。canvas作为html的一部分,是图像图标地图可视化的一个重要的基础,学好了canvas,在其他的一些应用上将会起到非常重…...

C#: BitConverter 字节数组byte[ ] 转各种数据类型用法列举
说明:C# BitConverter 字节数组byte[ ] 转各种数据类型用法示例 1.ToBoolean(byte[] value, int startIndex):将指定字节数组中从指定索引开始的两个字节转换为布尔值。 byte[] bytes { 1, 0 }; bool result BitConverter.ToBoolean(bytes, 0); // 输…...

【开发实践】前端jQuery+gif图片实现载入界面
一、需求分析 载入界面(Loading screen)是指在计算机程序或电子游戏中,当用户启动应用程序或切换到新的场景时,显示在屏幕上的过渡界面。它的主要作用是向用户传达程序正在加载或准备就绪的信息,以及提供一种视觉上的反…...

解析消费全返:谈谈那些关于商业的小妙招
每天五分钟讲解商业模式,大家好我是模式策划啊浩。 在数字化时代,商业模式正在经历前所未有的变革。其中,消费全返的概念正在逐渐崭露头角,引领着商业创新的新潮流。消费全返,顾名思义,是指消费者在购买商…...
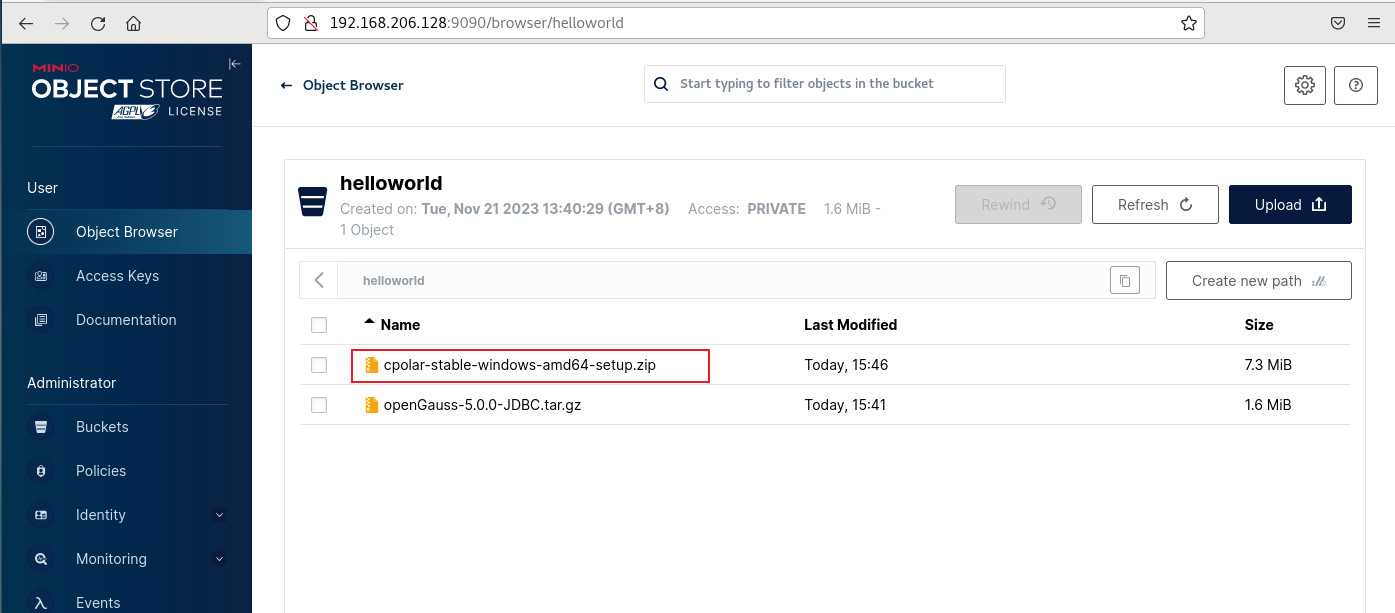
如何在MinIO存储服务中通过Buckets实现远程访问管理界面上传文件
文章目录 前言1. 创建Buckets和Access Keys2. Linux 安装Cpolar3. 创建连接MinIO服务公网地址4. 远程调用MinIO服务小结5. 固定连接TCP公网地址6. 固定地址连接测试 前言 MinIO是一款高性能、分布式的对象存储系统,它可以100%的运行在标准硬件上,即X86等…...

算法 - 二分法 / 双指针 / 三指针 / 滑动窗口
文章目录 🍺 二分法🍻 旋转数组🥂 33. 搜索旋转排序数组 [旋转数组] [目标值] (二分法) 🍻 元素边界🥂 34. 在排序数组中查找元素的第一个和最后一个位置 [有序数组] > [元素边界] > (二分法)🥂 81. …...

ChatGPT3.5、GPT4.0、DALL·E 3和Midjourney对话与绘画智能体验
MidTool(https://www.aimidtool.com/)是一个集成了多种先进人工智能技术的助手,它融合了ChatGPT3.5、GPT4.0、DALLE 3和Midjourney等不同的智能服务,提供了一个多功能的体验。下面是这些技术的简要介绍: ChatGPT3.5&am…...

MySQL中锁的概述
按照锁的粒度来分可分为:全局锁(锁住当前数据库的所有数据表),表级锁(锁住对应的数据表),行级锁(每次锁住对应的行数据) 加全局锁:flush tables with read lo…...

5396. 棋盘
5396. 棋盘 - AcWing题库 二维差分数组 #include <iostream> #include <vector> using namespace std;int main() {int n, m;cin >> n >> m;vector<vector<int>> v(n 2, vector<int>(n 2));while (m--) {int x1, x2, y1, y2;cin…...
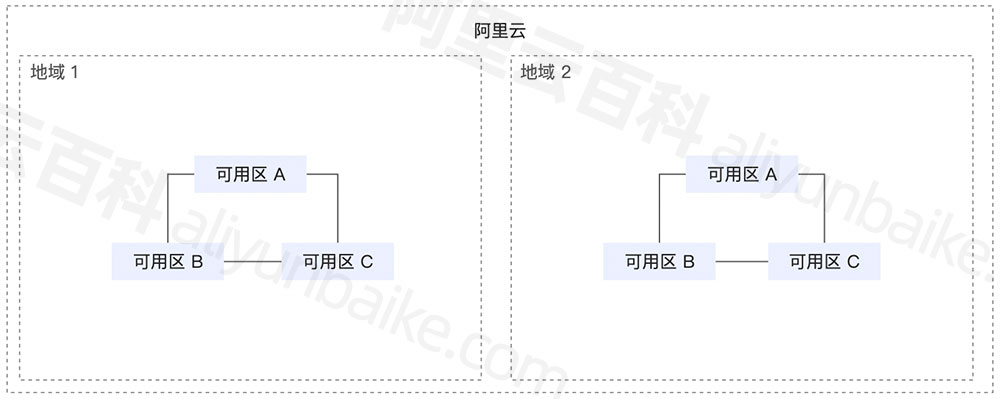
阿里云地域和可用区分布表,2024更新
2024年阿里云服务器地域分布表,地域指数据中心所在的地理区域,通常按照数据中心所在的城市划分,例如华北2(北京)地域表示数据中心所在的城市是北京。阿里云地域分为四部分即中国、亚太其他国家、欧洲与美洲和中东&…...

Pandas实战100例 | 案例 49: 数值运算
案例 49: 数值运算 知识点讲解 Pandas 提供了进行基本数学运算的简便方法,允许你在 DataFrame 的列之间执行加法、减法、乘法和除法等操作。 数值运算: 直接对 DataFrame 的列应用算术运算符(+, -, *, /)可以执行相应的数值运算。示例代码 # 准备数据和示例代码的运行结果…...

ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性
ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一个开源的Windows内核模式…...

【GEO实战密码】GEO 的真正护城河,是 RAG
《GEO实战密码》节选:GEO 的真正护城河,是 RAG企业做生成式搜索优化,别只盯着外部曝光。AI 愿不愿意引用你,首先取决于你的内容值不值得被信任。最近和不少企业聊 GEO,也就是生成式搜索优化,发现一个非常典…...

人工智能学习之归一化和标准化的区别
归一化与标准化(机器学习核心预处理笔记) 核心前提:机器学习中,特征的量纲(单位)可能差异极大(如:身高cm、体重kg、收入万元),会导致模型(如KNN、…...

从数据手册到实际电路:手把手教你用ADS1120的SPI接口,避开超时和配置的那些‘坑’
ADS1120实战指南:SPI接口深度优化与异常处理全解析 当你在凌晨三点的实验室里盯着示波器上那串诡异的SPI波形时,或许会想起第一次阅读ADS1120数据手册的那个下午。这款16位ΔΣ ADC以其出色的噪声性能和灵活的配置选项,成为精密测量领域的常客…...

一条 SQL 干掉 8 秒卡顿,只因改了一个索引
一条 SQL 干掉 8 秒卡顿,只因改了一个索引 上周五晚上十一点,线上告警突然炸了,用户反馈下单接口卡成 PPT。打开慢查询日志一看,一条最普通的订单查询 SQL 居然跑了 8 秒多。当时我脑子里只有一个念头:这条 SQL 我上周才写的,测试环境明明只要 200 毫秒啊。排查了一整晚,…...

深入解析Keil MDK FLM算法:SRAM运行原理与下载机制
1. 项目概述:FLM算法,Keil MDK下载的“灵魂引擎”如果你用Keil MDK给一块新的APM32或者STM32芯片下载程序,点下那个“Download”或“Load”按钮,几秒钟后“Programming Done”的提示框弹出,这个过程看似简单࿰…...

MCU工程迁移实战:从STM32到MSPM0L1306的完整指南
1. 项目概述:从零理解MCU工程迁移最近在折腾TI的MSPM0系列MCU,特别是MSPM0L1306这颗芯片。很多朋友拿到新的开发板或者从旧项目切换到新平台时,最头疼的就是“迁移工程”这一步。这不仅仅是把代码从一个文件夹复制到另一个文件夹那么简单&…...

整合Taotoken多模型能力为智能客服场景提供备选方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 整合Taotoken多模型能力为智能客服场景提供备选方案 在构建智能客服系统的过程中,产品经理和工程师常常面临一个核心挑…...

7分钟掌握中国行政区划数据:从零到实战的完整指南
7分钟掌握中国行政区划数据:从零到实战的完整指南 【免费下载链接】Administrative-divisions-of-China 中华人民共和国行政区划:省级(省份)、 地级(城市)、 县级(区县)、 乡级&…...

推荐1款全能跨平台下载工具,免费、开源、无广告!
聊一聊下载一直是热话题。特别是遇到自己喜欢的。如电影、电视剧、音乐等等。但并不是所有下载工具都能实现。今天给大家分享一款好用的下载利器。软件介绍全能开源跨平台下载工具Motrix工具只有自己用了才知道好不好用。这是一款无需安装,下载解压即可使用的工具。…...