如何使用Spring Cloud搭建高可用的Elasticsearch集群?详解Elasticsearch的安装与配置及Spring Boot集成的实现
Spring Cloud 是一个基于 Spring Boot 的微服务框架,它提供了一系列组件和工具,方便开发人员快速搭建和管理分布式系统。Elasticsearch 是一个开源的全文搜索引擎,也是一个分布式、高可用的 NoSQL 数据库。本篇博客将详细讲解如何使用 Spring Cloud 搭建 Elasticsearch,并介绍如何在 Spring Cloud 微服务中使用 Elasticsearch 进行数据存储和检索。
目录
一、Elasticsearch 简介
二、Spring Cloud 简介
三、Spring Cloud 搭建 Elasticsearch
3.1安装 Elasticsearch
3.2 使用 Spring Boot 集成 Elasticsearch
4.使用 Spring Cloud 搭建 Elasticsearch
4.1 搭建微服务架构
4.2 集成 Elasticsearch
4.2.1 添加 Elasticsearch 依赖
4.2.2 添加 Elasticsearch 配置
4.2.3 使用 Elasticsearch
总结
一、Elasticsearch 简介
Elasticsearch 是一个基于 Lucene 的分布式搜索引擎,它提供了实时分析、搜索、建议和聚合功能。它能够快速地存储、搜索和分析大量结构化和非结构化数据,并且具有高可用性和可伸缩性。Elasticsearch 提供了一个 RESTful API,可以通过 HTTP 协议进行访问和操作。
二、Spring Cloud 简介
Spring Cloud 是基于 Spring Boot 的微服务框架,它提供了一系列组件和工具,包括服务注册与发现、配置管理、负载均衡、熔断器、分布式追踪等,可以快速搭建和管理分布式系统。Spring Cloud 支持多种开源组件,包括 Netflix OSS、Consul、Zookeeper、Eureka 等。
三、Spring Cloud 搭建 Elasticsearch
在 Spring Cloud 微服务中使用 Elasticsearch,需要先进行 Elasticsearch 的安装和配置。下面将介绍如何在 Windows 环境下安装 Elasticsearch。
3.1安装 Elasticsearch
首先需要从 Elasticsearch 官网下载 Elasticsearch 的安装包,下载地址为:https://www.elastic.co/downloads/elasticsearch。选择对应的操作系统版本进行下载,本文以 Windows 10 为例。
下载完成后,解压缩安装包,进入解压后的文件夹,找到 bin 目录下的 elasticsearch.bat 文件,双击运行该文件。在启动 Elasticsearch 之前,需要先修改一些配置。打开 config 目录下的 elasticsearch.yml 文件,修改以下几个配置:
cluster.name: my-application
node.name: node-1
path.data: D:\elasticsearch\data
path.logs: D:\elasticsearch\logs其中,cluster.name 表示集群的名称,可以自定义;node.name 表示节点的名称,也可以自定义;path.data 和 path.logs 分别表示 Elasticsearch 数据和日志的存储路径。
修改完成后,保存并关闭 elasticsearch.yml 文件。然后再次双击运行 elasticsearch.bat 文件,等待 Elasticsearch 启动完成。启动成功后,在浏览器中输入 http://localhost:9200/,可以看到 Elasticsearch 的基本信息。
3.2 使用 Spring Boot 集成 Elasticsearch
使用 Spring Boot 集成 Elasticsearch,需要添加 Elasticsearch 的依赖。在 pom.xml 文件中添加以下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
添加依赖后,需要在 application.yml 文件中配置 Elasticsearch 的连接信息,如下所示:
spring:data:elasticsearch:cluster-name: my-applicationcluster-nodes: localhost:9300
其中,cluster-name 和上面在 Elasticsearch 中配置的 cluster.name 相对应,cluster-nodes 表示 Elasticsearch 的节点地址和端口号。
使用 Spring Data Elasticsearch,可以很方便地进行数据的增删改查操作。只需要定义一个实体类,并继承 ElasticsearchRepository 接口即可。例如,定义一个 Book 实体类:
@Document(indexName = "book")
public class Book {@Idprivate String id;private String title;private String author;// getter 和 setter 方法省略
}其中,@Document 注解用于指定 Elasticsearch 中的索引名称,@Id 注解用于指定实体类中的 ID 属性。
定义完实体类后,可以在其对应的 Repository 接口中定义增删改查方法,例如:
public interface BookRepository extends ElasticsearchRepository<Book, String> {List<Book> findByTitle(String title);List<Book> findByAuthor(String author);
}这样就可以通过调用 BookRepository 中的方法进行数据的增删改查操作了。
4.使用 Spring Cloud 搭建 Elasticsearch
在 Spring Cloud 微服务中使用 Elasticsearch,需要先搭建一个基于 Spring Cloud 的微服务架构。本文将以 Spring Cloud Eureka 作为服务注册中心,Spring Cloud Config 作为配置中心,Spring Cloud Gateway 作为网关,Spring Cloud Feign 作为服务调用客户端,演示如何搭建一个微服务架构,并在其中使用 Elasticsearch 进行数据存储和检索。
4.1 搭建微服务架构
首先需要创建一个 Spring Boot 项目,作为微服务架构的父项目,命名为 spring-cloud-demo。在该项目的 pom.xml 文件中添加以下依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>这些依赖分别是 Spring Cloud Eureka、Spring Cloud Config、Spring Cloud Gateway 和 Spring Cloud Feign。
在项目的 application.yml 文件中配置 Eureka、Config 和 Gateway 的相关信息,如下所示:
spring:application:name: spring-cloud-demo
eureka:client:service-url:defaultZone: http://localhost:8761/eureka/instance:instance-id: ${spring.application.name}:${random.value}prefer-ip-address: true
server:port: 8000
---
spring:profiles4.2 集成 Elasticsearch
在 Spring Cloud 微服务架构中集成 Elasticsearch,需要分别在每个微服务中添加 Elasticsearch 的相关依赖和配置。
4.2.1 添加 Elasticsearch 依赖
在微服务的 pom.xml 文件中添加 Elasticsearch 的相关依赖,如下所示:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.7.0</version>
</dependency>其中,spring-boot-starter-data-elasticsearch 依赖用于集成 Spring Data Elasticsearch,elasticsearch-rest-high-level-client 依赖用于连接 Elasticsearch 服务器。
4.2.2 添加 Elasticsearch 配置
在微服务的 application.yml 文件中添加 Elasticsearch 的连接配置,如下所示:
spring:data:elasticsearch:cluster-name: my-applicationcluster-nodes: localhost:9300其中,cluster-name 和 Elasticsearch 中配置的 cluster.name 相对应,cluster-nodes 表示 Elasticsearch 的节点地址和端口号。
4.2.3 使用 Elasticsearch
使用 Spring Data Elasticsearch 进行数据的增删改查操作和使用普通的 Spring Data JPA 操作类似,只需要定义一个实体类,并继承 ElasticsearchRepository 接口即可。例如,在一个微服务中定义一个 Book 实体类和对应的 Repository 接口,如下所示:
@Document(indexName = "book")
public class Book {@Idprivate String id;private String title;private String author;// getter 和 setter 方法省略
}public interface BookRepository extends ElasticsearchRepository<Book, String> {List<Book> findByTitle(String title);List<Book> findByAuthor(String author);
}其中,@Document 注解用于指定 Elasticsearch 中的索引名称,@Id 注解用于指定实体类中的 ID 属性。
定义完实体类和 Repository 接口后,就可以在服务中使用 BookRepository 中的方法进行数据的增删改查操作了。
总结
本文介绍了如何使用 Spring Cloud 搭建一个微服务架构,并在其中使用 Elasticsearch 进行数据存储和检索。具体来说,主要分为以下几个步骤:
- 在 Elasticsearch 中创建索引和文档类型;
- 在 Spring Boot 项目中添加 Elasticsearch 的相关依赖,并配置连接信息;
- 使用 Spring Data Elasticsearch 进行数据的增删改查操作;
- 在 Spring Cloud 微服务架构中添加 Elasticsearch 的相关依赖和配置;
- 在微服务中使用 Spring Data Elasticsearch 进行数据的增删改查操作。
通过本文的介绍,相信读者已经掌握了如何在 Spring Boot 和 Spring Cloud 微服务架构中使用 Elasticsearch 进行数据存储和检索的方法。在实际开发中,还需要根据具体的需求和业务场景进行相应的调整和优化,以实现更好的效果
相关文章:

如何使用Spring Cloud搭建高可用的Elasticsearch集群?详解Elasticsearch的安装与配置及Spring Boot集成的实现
Spring Cloud 是一个基于 Spring Boot 的微服务框架,它提供了一系列组件和工具,方便开发人员快速搭建和管理分布式系统。Elasticsearch 是一个开源的全文搜索引擎,也是一个分布式、高可用的 NoSQL 数据库。本篇博客将详细讲解如何使用 Spring…...
phpinfo包含临时文件Getshell全过程及源码
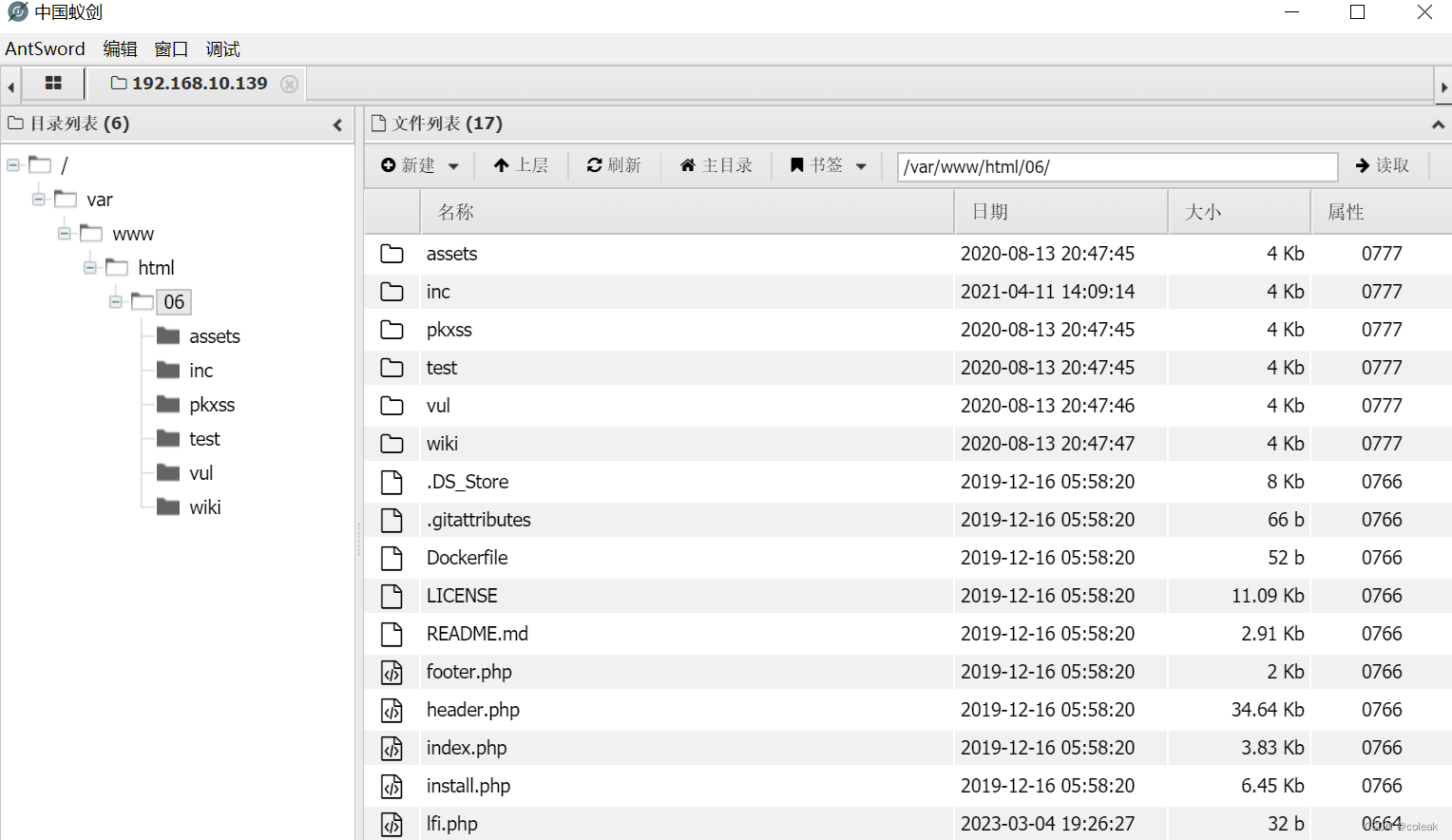
目录 前言 原理 漏洞复现 靶场环境 源码 复现过程 前言 PHP LFI本地文件包含漏洞主要是包含本地服务器上存储的一些文件,例如session文件、日志文件、临时文件等。但是,只有我们能够控制包含的文件存储我们的恶意代码才能拿到服务器权限。假如在服…...

ubuntu22.04 Desktop 服务器安装
操作系统 使用的是Uubntu22.04 Desktop的版本,系统安装后,默认开启了53端口和631端口 关闭udp 5353、53791端口(avahi-daemon服务) sudo systemctl stop avahi-daemon.socket avahi-daemon.service sudo systemctl disable ava…...

Halcon——关于halcon中的一些语法
Halcon——关于halcon中的一些语法前言一、变量的创建与赋值二、if语句三、for语句四、while语句五、中断语句六、switch语句总结前言 在HDevelep环境下编程时,所用的一些语法与C#有些差异,在此做下记录。 一、变量的创建与赋值 Hdevelep中调用函数时&…...

Java 循环语句
Java 循环语句 循环语句就是在满足一定条件的情况下反复执行某一个操作的语句。Java中提供了3种常用的循环语句,分别是while循环语句、do…while循环语句和for循环语句。 1.while循环语句 while语句也称条件判断语句,它的循环方式为利用一个条件来控制…...

Python 基础语法
文章目录条件判断循环数据类型变量字符编码字符串格式化listtupledictset不可变对象”#“ 开头的是注释每一行是一个语句,当语句以冒号 “:” 结尾时,缩进的语句被视为代码块 好处:强迫代码格式化,强迫少用缩进 坏处:“…...

Kubernetes:通过 kubectl 插件 ketall 查看所有APi对象资源
写在前面 分享一个查看集群所有资源的小工具博文内容涉及: 下载安装常用命令 Demo 理解不足小伙伴帮忙指正 出其东门,有女如云。虽则如云,匪我思存。缟衣綦巾,聊乐我员。——《郑风出其东门》 分享一个查看集群所有资源的小工具&a…...

Zookeeper3.5.7版本——选举机制(非第一次启动)
目录一、ZooKeeper集群中哪些情况会进入Leader选举二、当一台机器进入Leader选举流程时,当前集群的两种状态2.1、集群中本来就已经存在一个Leader2.2、集群中确实不存在Leader三、Zookeeper中的一些概念了解3.1、SID3.2、ZXID3.3、Epoch一、ZooKeeper集群中哪些情况…...
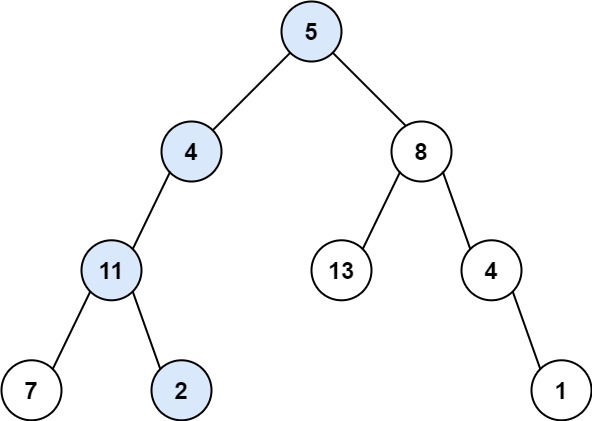
Python | Leetcode刷题日寄Part05
欢迎交流学习~~ LeetCode & Python 系列: 🏆 Python | Leetcode刷题日寄Part01 🔎 Python | Leetcode刷题日寄Part02 💝 Python | Leetcode刷题日寄Part03 ✈️ Python | Leetcode刷题日寄Part04 Python|Leetcode刷题日寄Par…...

SpringCloud学习笔记(一)
单体应用架构 在诞⽣之初,拉勾的⽤户量、数据量规模都⽐较⼩,项目所有的功能模块都放在一个工程中编码、编译、打包并且部署在一个Tomcat容器中的架构模式就是单体应用架构。 优点: 高效开发:项⽬前期开发节奏快,团…...

【C语言指针练习题】你真的学会指针了吗?
✨✨✨✨如果文章对你有帮助记得点赞收藏关注哦!!✨✨✨✨ 文章目录✨✨✨✨如果文章对你有帮助记得点赞收藏关注哦!!✨✨✨✨一维数组练习题:字符数组练习题:字符指针练习题:二维数组练习题&am…...
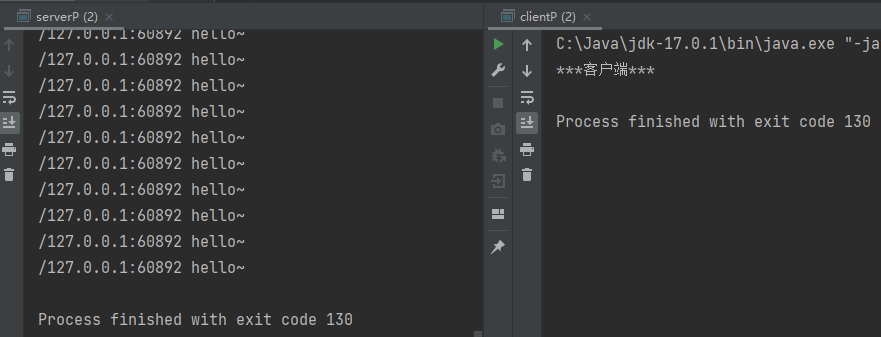
java实现UDP及TCP通信
简介UDP(User Datagram Protocol)用户数据报协议,TCP(Transmission Control Protocol) 传输控制协议,是传输层的两个重要协议。UDP是一种无连接、不可靠传输的协议。其将数据源IP、目的地IP和端口封装成数据包,不需要建立连接,每个…...

深度学习-第T1周——实现mnist手写数字识别
深度学习-第T1周——实现mnist手写数字识别深度学习-第P1周——实现mnist手写数字识别一、前言二、我的环境三、前期工作1、导入依赖项并设置GPU2、导入数据集3、归一化4、可视化图片5、调整图片格式四、构建简单的CNN网络五、编译并训练模型1、设置超参数2、编写训练函数六、预…...
和质量控制(QC))
质量保障(QA)和质量控制(QC)
质量保证和质量控制是比较容易混淆的一组概念。定义实施质量保证是执行过程组的一个过程,而质量控制是监控过程组的一个过程。质量保证的定义:审计质量要求和质量控制测量结果,确保采用合理的质量标准和操作性定义的过程。简单地说࿰…...

你真的会用三元运算符吗?
在我们日常搬砖中,我们经常会看到三元运算符,但是你了解三元运算符到底是怎么用吗?接下来我们就下来详细介绍一下三元运算符大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址&#x…...
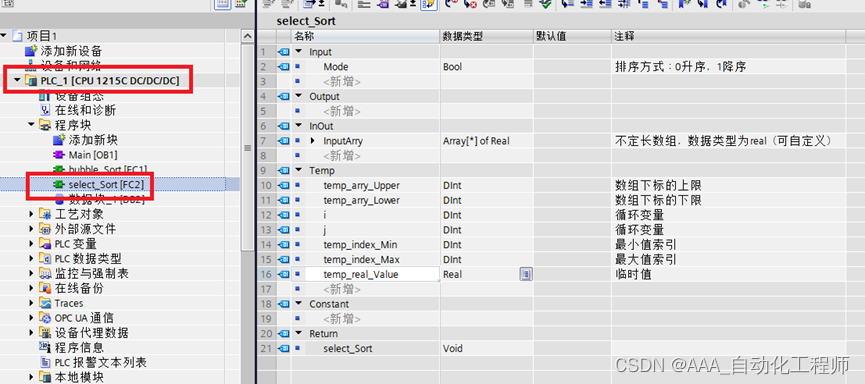
TIA博途中使用SCL语言实现选择排序算法并封装成FC全局库
TIA博途中使用SCL语言实现选择排序算法并封装成FC全局库 选择排序算法包括升序和降序2种: 升序排列: 第一轮从数据源中找到最小值排在第一位,第二轮从剩下的数据中寻找最小值排在第二位,依次类推,直到所有数据完成遍历;降序排列: 第一轮从数据源中找到最大值排在第一位,…...

【C++修炼之路】24.哈希应用--位图
每一个不曾起舞的日子都是对生命的辜负 哈希应用--位图哈希应用:位图一.提出问题二.位图概念三.位图代码四.位图应用五.经典问题哈希应用:位图 一.提出问题 问题: 给40亿个不重复的无符号整数,没排过序。给一个无符号整数&#x…...

4. 字符设备驱动高级--- 下篇
文章目录一、字符设备驱动高级1.1 注册字符设备驱动新接口1.1.1 新接口与旧接口1.1.2 cdev介绍1.1.3 设备号1.1.4 编程实践1.1.5 alloc_chrdev_region自动分配设备号1.1.6 中途出错的倒影式错误处理方法二、字符设备驱动注册代码分析2.1 旧接口register_chrdev2.2 新接口regist…...

ChatGPT介绍以及一些使用案例
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
)
PCL 点云高斯混合聚类(GMM)
文章目录 一、简介二、算法实现三、实现效果参考资料一、简介 与k均值使用原型向量来刻画聚类结构不同,高斯混合聚类(Mixture-of-Gaussian)采用了概率模型来表达聚类原型。从名字中就可以知晓,该方法将会结合高斯分布来进行聚类过程,该分布的概率密度函数定义如下所示: p (…...

ReAct让AI像人一样“边想边做”,轻松搞定复杂问题!
写在前面 欢迎回到我们的智能体架构系列。上一期我们聊了工具调用,让智能体“长出了手”,能去外部世界获取信息。但很快我们就发现,光有手还不够。面对“谁是《沙丘》制片公司的CEO,以及该公司最近一部电影的预算?”这…...

探索ImageGlass:一个轻量级图像浏览器的多格式支持解决方案
探索ImageGlass:一个轻量级图像浏览器的多格式支持解决方案 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 当你面对数十种不同格式的图像文件时,是…...

VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析
VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析 【免费下载链接】VIBE Official implementation of CVPR2020 paper "VIBE: Video Inference for Human Body Pose and Shape Estimation" 项目地址: https://gitcode.com/gh_mirrors/vi/VIBE …...

3个核心功能解决Windows 11系统问题:Win11Debloat优化工具深度评测
3个核心功能解决Windows 11系统问题:Win11Debloat优化工具深度评测 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更…...

Vivado里SRIO IP核Basic模式配置详解:从链路宽度到Buffer深度,新手避坑指南
Vivado中SRIO IP核Basic模式配置全解析:从参数理解到实战避坑 第一次在Vivado中配置SRIO IP核时,面对密密麻麻的参数选项,大多数工程师都会感到无从下手。作为Xilinx FPGA中实现高速串行通信的关键IP,SRIO(Serial Rap…...

Fun-ASR参数配置攻略:热词列表、目标语言,这样设置准确率最高
Fun-ASR参数配置攻略:热词列表、目标语言,这样设置准确率最高 1. 为什么参数配置如此重要? 语音识别系统的准确率往往取决于两个关键因素:模型本身的性能和使用者的参数配置。Fun-ASR作为钉钉与通义实验室联合推出的企业级语音识别…...

如何快速上手BepInEx:3个高效秘诀解锁Unity游戏插件开发
如何快速上手BepInEx:3个高效秘诀解锁Unity游戏插件开发 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 想象一下,你心爱的Unity游戏缺少某个功能ÿ…...

探索内转子MotorCAD电机模型:面包型永磁体的独特魅力
内转子motorcad电机模型,电机永磁体采用面包型,额定转速3000,可用于后续的优化设计,送motorcad中文手册。最近在研究电机这块,发现了一个超有意思的内转子MotorCAD电机模型,今天来和大家唠唠。这个模型的电…...

别再只盯着find提权了!盘点Linux下5种更隐蔽的权限维持姿势与排查手册
超越find提权:Linux系统下5种高阶权限维持技术与深度排查指南 当攻击者成功获取Linux系统权限后,权限维持(Persistence)往往成为攻防对抗的核心战场。传统安全培训常聚焦于SUID提权等基础手段,但真实APT攻击中…...

Hi-C数据分析进阶:如何用dcHiC精准识别癌症样本中的区室转换事件?
Hi-C技术解密:从染色质区室动态到癌症表观遗传调控 染色质三维结构研究已成为癌症表观遗传学的前沿领域。随着Hi-C技术的普及,科学家们能够以前所未有的分辨率观察基因组在细胞核内的空间组织形式。本文将深入探讨染色质区室(A/B compartment…...