Kafka系列(四)
本文接kafka三,代码实践kafkaStream的应用,用来完成流式计算。
kafkastream
关于流式计算也就是实时处理,无时间概念边界的处理一些数据。想要更有性价比地和java程序进行结合,因此了解了kafka。但是本人阅读了kafka地官网,觉得可阅读性并不是很高,当然是个人认为,就是界面做的就不是很舒服。
简介
简介一下kafkaStream
Kafka Stream的特点
-
Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
-
除了Kafka外,无任何外部依赖
-
充分利用Kafka分区机制实现水平扩展和顺序性保证(想要保证消息有序性就要设置一个分区)
-
通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
-
支持正好一次处理语义
-
提供记录级的处理能力,从而实现毫秒级的低延迟
-
支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
-
同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
关键概念
-
源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
-
Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
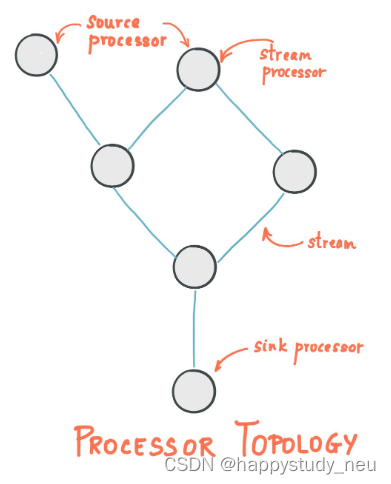
Kstream
(1)数据结构类似于map,key-value键值对
KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。 数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
为了说明这一点,让我们想象一下以下两个数据记录正在发送到流中:
(“ alice”,1)->(“” alice“,3)
如果流处理应用是要总结每个用户的价值,它将返回alice,4。因为第二条数据记录不会覆盖第一条,而是做了一个insert,累加。
代码实现
依赖
<!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency>
kafkaStream配置类
需要在nacos的配置里面配置hosts属性和group,本地等怎么配置都可以,只要能读取到就行。
/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);}
}这里生产者和消费者我就不再举例子了,直接举中间这个stream怎么写。
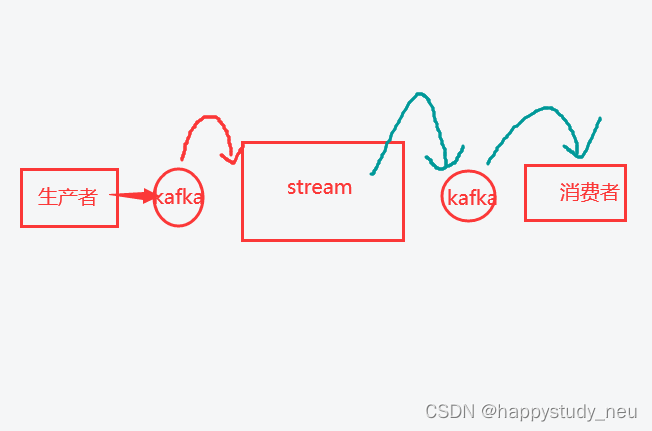
stream需要知道是谁发的,所以生产者和stream需要绑定一个相同的主题,而stream需要知道要给谁发送过去,消费者知道是谁发的,所以stream和消费者又有一个相同的主题。
streamhandler代码
具体的每一行代码的含义结合个人理解都在注释里面。
package com.neu.article.stream;import com.alibaba.fastjson.JSON;import com.neu.base.constants.HotArticleConstants;
import com.neu.base.model.mess.ArticleVisitStreamMess;
import com.neu.base.model.mess.UpdateArticleMess;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;@Configuration
@Slf4j
public class HotArticleStreamHandler {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//接收消息KStream<String,String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);//聚合流式处理stream.map((key,value)->{UpdateArticleMess mess = JSON.parseObject(value, UpdateArticleMess.class);//重置消息的key:1234343434(文章id) 和 value: likes:1 当前文章点赞一次//mess.getType().name():用于区分是点赞还是阅读 mess.getAdd():用于区分是加1还是减1return new KeyValue<>(mess.getArticleId().toString(),mess.getType().name()+":"+mess.getAdd());})//按照文章id进行聚合.groupBy((key,value)->key)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))/*** 自行的完成聚合的计算*/.aggregate(new Initializer<String>() {/*** 初始方法,返回值是消息的value->aggValue,聚合之后的value* @return*/@Overridepublic String apply() {return "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";}/*** 真正的聚合操作,返回值是消息的value*/}, new Aggregator<String, String, String>() {/**** @param key 消息的key :mess.getArticleId().toString()* @param value 消息的value likes:1* @param aggValue 初始化消息聚合后的一个值 COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0* @return*/@Overridepublic String apply(String key, String value, String aggValue) {System.out.println(value);if(StringUtils.isBlank(value)){return aggValue;}String[] aggAry = aggValue.split(",");int col = 0,com=0,lik=0,vie=0;for (String agg : aggAry) {//agg遍历第一次的时候最开始为 COLLECTION:0String[] split = agg.split(":");//split[0] = COLLECTION split[1] = 0/*** 获得初始值,也是时间窗口内计算之后的值*/switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:col = Integer.parseInt(split[1]);break;case COMMENT:com = Integer.parseInt(split[1]);break;case LIKES:lik = Integer.parseInt(split[1]);break;case VIEWS:vie = Integer.parseInt(split[1]);break;}}/*** 累加操作 likes:1*/String[] valAry = value.split(":");//valAry[0] = likes valAry[1] = 1switch (UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){case COLLECTION:col += Integer.parseInt(valAry[1]);break;case COMMENT:com += Integer.parseInt(valAry[1]);break;case LIKES:lik += Integer.parseInt(valAry[1]);break;case VIEWS:vie += Integer.parseInt(valAry[1]);break;}//返回值是有要求的,必须与初始化apply方法的返回值形式一致String formatStr = String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);System.out.println("文章的id:"+key);System.out.println("当前时间窗口内的消息处理结果:"+formatStr);return formatStr;}//Materialized.as("hot-atricle-stream-count-001"):用于指定六十处理的状态,字符串可以随便给,多个流处理的话不重复就行}, Materialized.as("hot-atricle-stream-count-001")).toStream().map((key,value)->{//key.key().toString():文章id,value:COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0return new KeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));})//发送消息.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);return stream;}/*** 格式化消息的value数据* @param articleId* @param value* @return*/public String formatObj(String articleId,String value){ArticleVisitStreamMess mess = new ArticleVisitStreamMess();mess.setArticleId(Long.valueOf(articleId));//COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0String[] valAry = value.split(",");for (String val : valAry) {String[] split = val.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:mess.setCollect(Integer.parseInt(split[1]));break;case COMMENT:mess.setComment(Integer.parseInt(split[1]));break;case LIKES:mess.setLike(Integer.parseInt(split[1]));break;case VIEWS:mess.setView(Integer.parseInt(split[1]));break;}}log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));return JSON.toJSONString(mess);}
}
相关文章:
Kafka系列(四)
本文接kafka三,代码实践kafkaStream的应用,用来完成流式计算。 kafkastream 关于流式计算也就是实时处理,无时间概念边界的处理一些数据。想要更有性价比地和java程序进行结合,因此了解了kafka。但是本人阅读了kafka地官网&#…...
【Linux学习】进程信号
目录 十七.进程信号 导言 17.1 linux中的信号列表 17.2 标准信号与实时信号 17.3 信号的产生 17.3.1 通过终端按键产生信号 17.3.2 调用系统函数产生信号 17.3.3 软件条件产生信号 17.3.4 硬件异常产生信号 17.3.5 【补充】核心转储 Core Dump 17.4 信号的阻塞 17.4.1 信号相关…...
机器学习没那么难,Azure AutoML帮你简单3步实现自动化模型训练
在Machine Learning 这个领域,通常训练一个业务模型的难点并不在于算法的选择,而在于前期的数据清理和特征工程这些纷繁复杂的工作,训练过程中的问题在于参数的反复迭代优化。 AutoML 是 Azure Databricks 的一项功能,它自动的对…...
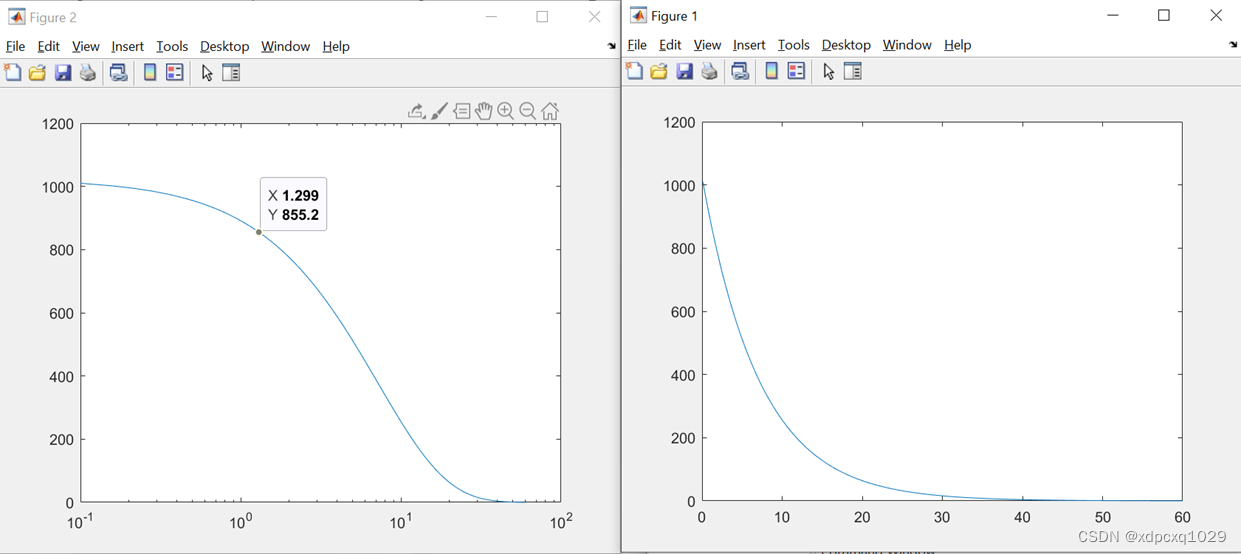
数学建模实战Matlab绘图
二维曲线、散点图 绘图命令:plot(x,y,’line specifiers’,’PropertyName’,PropertyValue) 例子:绘图表示年收入与年份的关系 ‘--r*’:--设置线型;r:设置颜色为红色;*节点型号 ‘linewidth’:设置线宽࿱…...

TypeError the JSON object must be str, bytes or bytearray, not ‘list‘
在使用python的jason库时,偶然碰到以下问题 TypeError: the JSON object must be str, bytes or bytearray, not ‘list’ 通过如下代码可复现问题 >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> import json >>> ra json.loads(a) Trac…...
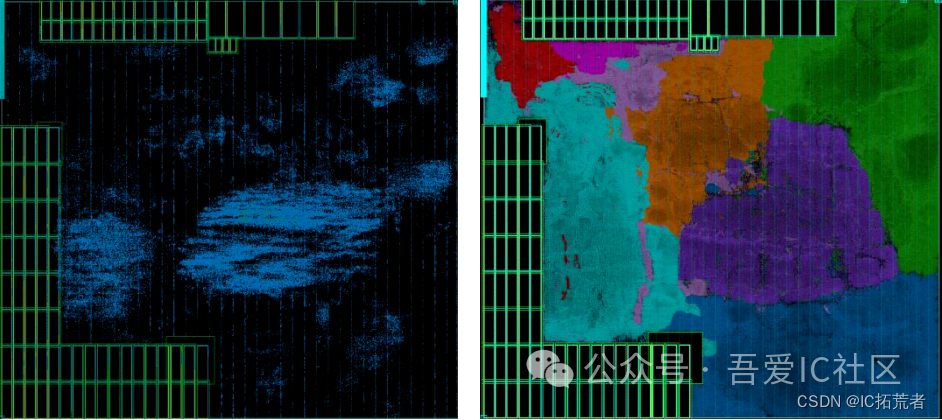
数字IC后端设计实现 | PR工具中到底应该如何控制density和congestion?(ICC2Innovus)
吾爱IC社区星友提问:请教星主和各位大佬,对于一个模块如果不加干预工具会让inst挤成一团,后面eco修时序就没有空间了。如果全都加instPadding会导致面积不够overlap,大家一般怎么处理这种问题? 在数字IC后端设计实现中…...

产品经理与产品运营的区别和联系
一、两者的职责区别 产品经理的目的:是创造有价值的产品 产品运营的目的:是让产品能有效的发挥出它应有的价值 二、两者的工作内容区别产品经理的工作内容 产品的经理的目的是创造有价值的产品,因此产品经理的所有工作都是围绕着…...
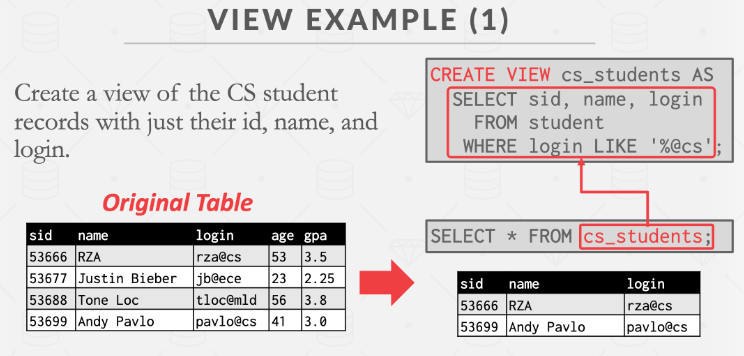
CMU15-445-Spring-2023-分布式DBMS初探(lec21-24)
Lecture #21_ Introduction to Distributed Databases Distributed DBMSs 分布式 DBMS 将单个逻辑数据库划分为多个物理资源。应用程序(通常)并不知道数据被分割在不同的硬件上。系统依靠单节点 DBMS 的技术和算法来支持分布式环境中的事务处理和查询执…...

Arch linux 安装
Arch linux 安装 介绍下载制作iSO启动盘安装arch linux设置字体连接互联网 安装过程磁盘分区设置设置镜像源设置引导文件挂载点安装base等基础软件生成fatab文件更改时区更改编码、语言更改编码更改语言 用户管理设置root密码新建普通用户 安装grub启动网络服务/GDM查看系统网络…...
最新ChatGPT/GPT4科研应用与AI绘图及论文高效写作
详情点击链接:最新ChatGPT/GPT4科研应用与AI绘图及论文高效写作 一OpenAI 1.最新大模型GPT-4 Turbo 2.最新发布的高级数据分析,AI画图,图像识别,文档API 3.GPT Store 4.从0到1创建自己的GPT应用 5. 模型Gemini以及大模型Clau…...

【leetcode】移除元素
大家好,我是苏貝,本篇博客带大家刷题,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 一.暴力求解法二.使用额外数组三.原地修改数组 点击查看题目 一.暴力求解法 若我们不考虑时间复杂度…...
Spring Boot整合Redis的高效数据缓存实践
引言 在现代Web应用开发中,数据缓存是提高系统性能和响应速度的关键。Redis作为一种高性能的缓存和数据存储解决方案,被广泛应用于各种场景。本文将研究如何使用Spring Boot整合Redis,通过这个强大的缓存工具提高应用的性能和可伸缩性。 整合…...
)
FastApi-参数接收的正确使用(2)
前言 本文是该专栏的第2篇,后面会持续分享FastApi以及项目实战的各种干货知识,值得关注。 本文重点介绍,在使用FastApi使用“参数接收”时遇到的三种类型“路径参数”,“查询参数”,“请求体”的相关问题以及相应的解决方案。 具体详细知识点,跟着笔者直接往下看正文。…...
)
三、需求规格说明书(软件工程示例)
1.引言 1.1编写目的 1.2项目背景 1.3定义 1.4参考资料 2.任务概述 2.1目标 2.2运行环境 2.3条件与限制 3.数据描述 3.1静态数据 3.2动态数据 3.3数据库介绍 3.4数据词典 3.5数据采集 4.功能需求 …...

Elasticsearch 查询语句概述
目录 1. Match Query 2. Term Query 3. Terms Query 4. Range Query 5. Bool Query 6. Wildcard Query 7. Fuzzy Query 8. Prefix Query 9. Aggregation Query Elasticsearch 是一个基于 Lucene 的搜索引擎,提供了丰富的查询DSL(Domain Specifi…...

kafka简单介绍和代码示例
“这是一篇理论文章,给大家讲一讲kafka” 简介 在大数据领域开发者常常会听到MQ这个术语,该术语便是消息队列的意思, Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年…...

一次解决ForkJoinPool日志追踪的辛酸经历
本文主要分享了一次解决ForkJoinPool日志追踪的辛酸经历。历时3个月终于找到通用的解决方案,以此文分享给有需要的你。 一、需求背景 1.某日,某同事根据日志ID排查生产环境问题过程中,发现日志不全 2.经排查发现中间有很多线程为ForkJoinP…...
VM使用教程--SDK取图 视频笔记
本笔记均由海康机器人官网的V学院视频中记录所得,属于省流大师了[doge] 图像采集 图像采集包括1图像源,2多图采集,3输出图像,4缓存图像,5光源 1图像源 图像源包括本地图像,相机采图,SDK 本…...
)
11.spring boot 启动源码(一)
目录 概述SpringApplication静态方法构造方法run 实例方法配置文件Actuator 工作原理*EndpointAutoConfigurationBeansEndpointAutoConfigurationShutdownEndpointAutoConfiguration结束概述 spring boot 版本 2.6.13 spring boot 启动源码(一) 涉及 SpringApplication 中静态…...
【微服务】springcloud集成sleuth与zipkin实现链路追踪
目录 一、前言 二、分布式链路调用问题 三、链路追踪中的几个概念 3.1 什么是链路追踪 3.2 常用的链路追踪技术 3.3 链路追踪的几个术语 3.3.1 span 编辑 3.3.2 trace 3.3.3 Annotation 四、sluth与zipkin概述 4.1 sluth介绍 4.1.1 sluth是什么 4.1.2 sluth核心…...

【202期】新版VMware虚拟机汉化包
VMR虚拟机自从2025年被博通收购后,从新版开始官方就不再支持中文了。所以今天给各位找到了一个简体中文语言包,使用方式也是非常简单。解压与准备全部解压好之后,打开解压好的目录。执行汉化处理双击这个脚本文件进行汉化前的处理。复制到安装…...

RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流
RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流 在实时视频监控、在线直播等场景中,RTSP协议因其低延迟和可靠性成为主流选择。本文将深入探讨如何从零构建一个RTSP客户端播放器,重点解决H264 RTP流的接收、解析与渲染难题。不同于简单…...

终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案
终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案 【免费下载链接】Original-Prusa-i3 Original Prusa i3 MK2 3D printer printed parts 项目地址: https://gitcode.com/gh_mirrors/or/Original-Prusa-i3 Original Prusa i3 MK3S是一款由PRUS…...

高性能自动化网页信息提取工具实战指南:大规模目标扫描与安全检测技术方案
高性能自动化网页信息提取工具实战指南:大规模目标扫描与安全检测技术方案 【免费下载链接】URLFinder 一款快速、全面、易用的页面信息提取工具,可快速发现和提取页面中的JS、URL和敏感信息。 项目地址: https://gitcode.com/gh_mirrors/ur/URLFinder…...

OpenHarmony系统定制:实现开机自启动应用与Launcher替换实战
1. 项目概述:为OpenHarmony设备定义“开机即用”的体验最近在基于触觉智能的RK3566开发板上折腾OpenHarmony 4.1,一个很实际的需求浮出水面:如何让系统开机后,默认就打开我指定的应用?这不仅仅是开发者的自娱自乐&…...

ATxmega时钟与GPIO配置详解:从原理到实战代码
1. 项目概述:从零开始认识ATxmage的时钟与GPIO最近在整理一些嵌入式开发的入门资料,发现很多刚接触ATxmage系列微控制器的朋友,拿到开发板后往往第一步就卡在了最基础的时钟配置和引脚操作上。这其实很正常,因为这两个模块是整个系…...

别再折腾了!Windows 11下TeX Live 2024 + VS Code配置LaTeX环境保姆级教程
别再折腾了!Windows 11下TeX Live 2024 VS Code配置LaTeX环境保姆级教程 对于科研人员和学术写作者来说,LaTeX始终是专业排版的不二之选。但传统LaTeX编辑器如TeXstudio虽然功能全面,却难以融入现代开发者的工作流。本文将带你用VS Code搭建…...

PMP认证深度解析:从知识体系到实战应用的全方位指南
1. 项目概述:从“认证”到“职业语言”的深度解码当你在项目管理圈子里待久了,会发现一个有趣的现象:无论大家来自哪个行业——是互联网大厂的产品研发,还是传统制造业的产线升级,甚至是大型活动的策划执行——只要聊到…...

利用Taotoken多模型能力为AIGC应用动态选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型能力为AIGC应用动态选择最佳模型 在构建内容生成类应用时,开发者常常面临一个核心挑战:…...

对比官方原价Taotoken活动价带来的Token成本优化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方原价与Taotoken活动价带来的Token成本优化感受 1. 引言:开发者视角下的模型调用成本 对于频繁使用大模型API进…...