基于Word2vec词聚类的关键词实现
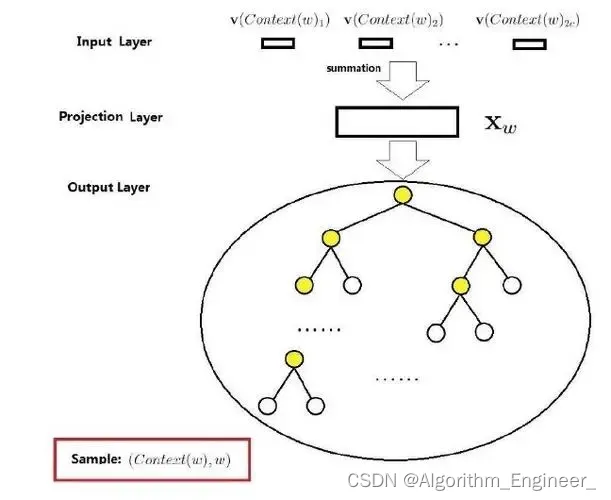
一.基于Word2vec词聚类的关键词步骤
基于Word2Vec的词聚类关键词提取包括以下步骤:
1.准备文本数据:收集或准备文本数据,可以是单一文档或文档集合,涵盖关键词提取的领域。2.文本预处理:清洗文本数据,去除无关字符、标点符号,将文本转换为小写等。进行分词,将文本划分为词语。3.训练Word2Vec模型:使用预处理后的文本数据训练Word2Vec模型。可以使用现有的库如gensim,也可以自行实现Word2Vec模型的训练。定义模型的参数,如词向量维度、窗口大小、最小词频等。4.获取词向量:通过训练好的Word2Vec模型获取每个词语的词向量。5.词聚类:使用聚类算法对词向量进行聚类,将相似的词语分为同一簇。常用的聚类算法包括K-Means、DBSCAN等。定义聚类的数量(簇数)。6.获取每个聚类的代表词:对每个聚类,选择代表性的词语作为关键词。这可以通过计算每个聚类的中心或其他代表性指标来实现。7.输出关键词:将每个聚类的代表词作为关键词输出,得到最终的关键词列表。
整个流程的核心在于使用Word2Vec模型得到词向量,然后通过聚类算法将相似的词语归为一簇,最终提取每个簇的代表性词语作为关键词。这种方法能够捕捉词语之间的语义关系,提高关键词的表达力。
二.基于Word2vec词聚类的关键词的代码实现
词向量的预处理
# coding=utf-8
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') # 忽略警告
import codecs
import pandas as pd
import numpy as np
import jieba # 分词
import jieba.posseg
import gensim # 加载词向量模型
# 返回特征词向量bai
def word_vecs(wordList, model):name = []vecs = []for word in wordList:word = word.replace('\n', '')try:if word in model: # 模型中存在该词的向量表示name.append(word.encode('utf8').decode("utf-8"))vecs.append(model[word])except KeyError:continuea = pd.DataFrame(name, columns=['word'])b = pd.DataFrame(np.array(vecs, dtype='float'))return pd.concat([a, b], axis=1)
# 数据预处理操作:分词,去停用词,词性筛选
def data_prepare(text, stopkey):l = []# 定义选取的词性pos = ['n', 'nz', 'v', 'vd', 'vn', 'l', 'a', 'd']seg = jieba.posseg.cut(text) # 分词for i in seg:# 去重 + 去停用词 + 词性筛选if i.word not in l and i.word\not in stopkey and i.flag in pos:# print i.wordl.append(i.word)return l
# 根据数据获取候选关键词词向量
def build_words_vecs(data, stopkey, model):idList, titleList, abstractList = data['id'], data['title'], data['abstract']for index in range(len(idList)):id = idList[index]title = titleList[index]abstract = abstractList[index]l_ti = data_prepare(title, stopkey) # 处理标题l_ab = data_prepare(abstract, stopkey) # 处理摘要# 获取候选关键词的词向量words = np.append(l_ti, l_ab) # 拼接数组元素words = list(set(words)) # 数组元素去重,得到候选关键词列表wordvecs = word_vecs(words, model) # 获取候选关键词的词向量表示# 词向量写入csv文件,每个词400维data_vecs = pd.DataFrame(wordvecs)data_vecs.to_csv('result/vecs/wordvecs_' + str(id) + '.csv', index=False)print ("document ", id, " well done.")
def main():# 读取数据集dataFile = 'data/text.csv'data = pd.read_csv(dataFile)# 停用词表stopkey = [w.strip() for w in codecs.open('data/stopWord.txt', 'r', encoding='utf-8').readlines()]# 词向量模型inp = 'wiki.zh.text.vector'model = gensim.models.KeyedVectors.load_word2vec_format(inp, binary=False)build_words_vecs(data, stopkey, model)
if __name__ == '__main__':main()
基于word2vec的关键词提取
# coding=utf-8
import os
from sklearn.cluster import KMeans
import pandas as pd
import numpy as np
import math
# 对词向量采用K-means聚类抽取TopK关键词
def words_kmeans(data, topK):words = data["word"] # 词汇vecs = data.iloc[:, 1:] # 向量表示kmeans = KMeans(n_clusters=1, random_state=10).fit(vecs)labels = kmeans.labels_ # 类别结果标签labels = pd.DataFrame(labels, columns=['label'])new_df = pd.concat([labels, vecs], axis=1)vec_center = kmeans.cluster_centers_ # 聚类中心# 计算距离(相似性) 采用欧几里得距离(欧式距离)distances = []vec_words = np.array(vecs) # 候选关键词向量,dataFrame转arrayvec_center = vec_center[0] # 第一个类别聚类中心,本例只有一个类别length = len(vec_center) # 向量维度for index in range(len(vec_words)): # 候选关键词个数cur_wordvec = vec_words[index] # 当前词语的词向量dis = 0 # 向量距离for index2 in range(length):dis += (vec_center[index2] - cur_wordvec[index2]) * \(vec_center[index2] - cur_wordvec[index2])dis = math.sqrt(dis)distances.append(dis)distances = pd.DataFrame(distances, columns=['dis'])# 拼接词语与其对应中心点的距离result = pd.concat([words, labels, distances], axis=1)# 按照距离大小进行升序排序result = result.sort_values(by="dis", ascending=True)# 抽取排名前topK个词语作为文本关键词wordlist = np.array(result['word'])# 抽取前topK个词汇word_split = [wordlist[x] for x in range(0, topK)]word_split = " ".join(word_split)return word_split
if __name__ == '__main__':# 读取数据集dataFile = 'data/text.csv'articleData = pd.read_csv(dataFile)ids, titles, keys = [], [], []rootdir = "result/vecs" # 词向量文件根目录fileList = os.listdir(rootdir) # 列出文件夹下所有的目录与文件# 遍历文件for i in range(len(fileList)):filename = fileList[i]path = os.path.join(rootdir, filename)if os.path.isfile(path):# 读取词向量文件数据data = pd.read_csv(path, encoding='utf-8')# 聚类算法得到当前文件的关键词artile_keys = words_kmeans(data, 5)# 根据文件名获得文章id以及标题(shortname, extension) = os.path.splitext(filename)t = shortname.split("_")article_id = int(t[len(t) - 1]) # 获得文章id# 获得文章标题artile_tit = articleData[articleData.id == article_id]['title']print(artile_tit)print(list(artile_tit))artile_tit = list(artile_tit)[0] # series转成字符串ids.append(article_id)titles.append(artile_tit)keys.append(artile_keys.encode("utf-8").decode("utf-8"))# 所有结果写入文件result = pd.DataFrame({"id": ids, "title": titles, "key": keys}, columns=['id', 'title', 'key'])result = result.sort_values(by="id", ascending=True) # 排序result.to_csv("result/word2vec.csv", index=False, encoding='utf_8_sig')相关文章:
基于Word2vec词聚类的关键词实现
一.基于Word2vec词聚类的关键词步骤 基于Word2Vec的词聚类关键词提取包括以下步骤: 1.准备文本数据:收集或准备文本数据,可以是单一文档或文档集合,涵盖关键词提取的领域。2.文本预处理:清洗文本数据,去除…...
开源项目_大模型应用_Chat2DB
1 基本信息 项目地址:https://github.com/chat2db/Chat2DBStar:10.7K 2 功能 Chat2DB 是一个智能且多功能的 SQL 客户端和报表工具,适用于各种数据库。 对于那些平时会用到数据库,但又不是数据库专家的程序员来说,…...

【线性代数与矩阵论】范数理论
范数理论 2023年11月16日 文章目录 范数理论1. 向量的范数2. 常用向量范数3. 向量范数的等价性4. 矩阵的范数5. 常用的矩阵范数6. 矩阵范数与向量范数的相容性7. 矩阵范数诱导的向量范数8. 由向量范数诱导的矩阵范数9. 矩阵范数的酉不变性10. 矩阵范数的等价性11. 长方阵的范数…...

【C++】priority_queue模拟实现过程中值得注意的点
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C》《Linux》《算法》 🌝每一个不曾起舞的日子,都是对生命的辜负 前言 本篇文章旨在记录博主在模…...
Git提交 ssh: connect to host github.com port 22: Connection timed out解决方案
你们好,我是金金金。 场景 之前都是好好的,不知道今天为什么提交代码就这样了 排查 根据英文可以看出,ssh端口号被拒绝了,22号端口不行,那就换一个端口 造成error的原因 ssh端口被拒绝 解决 找到.ssh文件ÿ…...

Java调用WebService接口,SOAP协议HTTP请求返回XML对象
Java调用Web service接口SOAP协议HTTP请求,解析返回的XML字符串: 1. 使用Java的HTTP库发送SOAP请求,并接收返回的响应。 可以使用Java的HttpURLConnection、Apache HttpClient等库。 2. 将返回的响应转换为字符串。 3. 解析XML字符串&…...

Django框架二
一、模型层及ORM 1.模型层定义 负责跟数据库之间进行通信 2.Django配置mysql 安装mysqlclient,mysqlclient版本最好在13.13以上 pip3 install mysqlclient DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: "mysite1",USER:root,PASSWO…...

工业相机与镜头参数及选型
文章目录 1、相机成像系统模型1.1 视场1.2 成像简化模型 2、工业相机参数2.1 分辨率2.2 靶面尺寸2.3 像元尺寸2.4 帧率/行频2.5 像素深度2.6 动态范围2.7 信噪比2.8 曝光时间2.9 相机接口 3、工业镜头参数3.1 焦距3.2 光圈3.3 景深3.4 镜头分辨率3.5 工作距离(Worki…...
VSCode使用Makefile Tools插件开发C/C++程序
提起Makefile,可能有人会觉得它已经过时了,毕竟现在有比它更好的工具,比如CMake,XMake,Meson等等,但是在Linux下很多C/C源码都是直接或者间接使用Makefile文件来编译项目的,可以说Makefile是基石…...

用C语言验证“三门定理”
#include <stdio.h> #include <stdbool.h> #include <stdlib.h> #include <time.h>// 一个源自博弈论的数学游戏问题: // 参赛者会看见三扇门, // 其中一扇门的里面有一辆汽车, // 选中里面是汽车的那扇门࿰…...
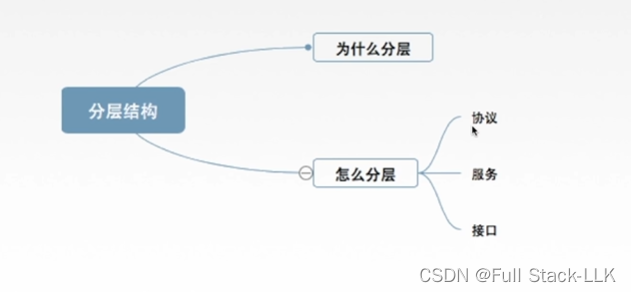
计算机网络-分层结构,协议,接口,服务
文章目录 总览为什么要分层怎样分层正式认识分层概念小结 总览 为什么要分层 发送文件前要做的准备工作很多 把这个准备工作分层小问题解决,也就分层解决 怎样分层 每层相互独立,每层做的工作不同 界面自然清晰,层与层之间的接口能够体现…...

前端开发 2: CSS
在前端开发中,CSS(层叠样式表)是一种用于描述网页样式的语言。它控制着网页的布局、颜色、字体等外观效果。在本篇博客中,我将为你介绍 CSS 的基础知识和常用技巧,帮助你更好地掌握前端开发中的样式设计。 CSS 基础知…...
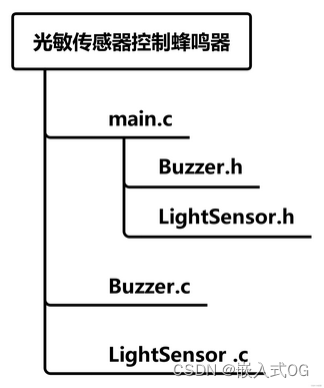
嵌入式-Stm32-江科大基于标准库的GPIO4个小实验
文章目录 一 、硬件介绍二 、实验:LED闪烁、LED流水灯、蜂鸣器提示2.1 需求1:面包板上的LED以1s为周期进行闪烁。亮0.5s,灭0.5s.....2.2 需求2: 8个LED实现流水灯2.3 需求3:蜂鸣器不断地发出滴滴、滴滴.....的提示音。蜂鸣器低电平触发。 三、…...
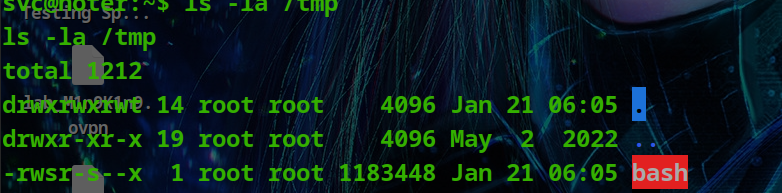
HackTheBox - Medium - Linux - Noter
Noter Noter 是一种中型 Linux 机器,其特点是利用了 Python Flask 应用程序,该应用程序使用易受远程代码执行影响的“节点”模块。由于“MySQL”守护进程以用户“root”身份运行,因此可以通过利用“MySQL”的用户定义函数来利用它来获得RCE并…...
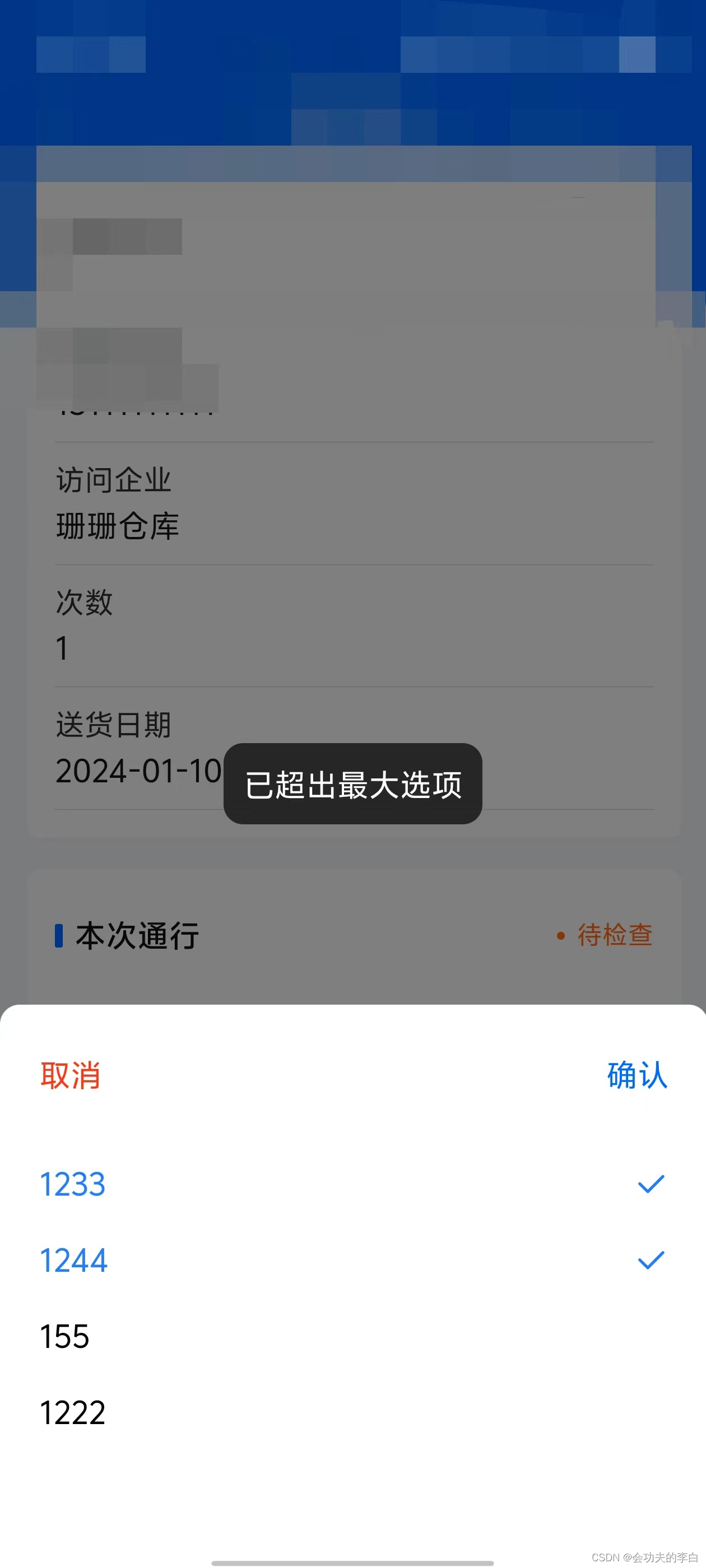
Uniapp多选Popup(弹出层)
uniapp中多选组件很少,故个人简单开发了一个,可简单使用,也可根据个人需求稍微改进 支持的功能 单选多选(默认)限制选择数量默认选中禁用选项 属性说明 属性默认值说明singlefalsetrue为开启单选,否则为…...

什么是网络安全?网络安全概况
网络安全涉及保护我们的计算机网络、设备和数据免受未经授权的访问或破坏。 这个领域包括多种技术、过程和控制措施,旨在保护网络、设备和数据免受攻击、损害或未授权访问。网络安全涉及多个方面,包括但不限于信息安全、应用程序安全、操作系统安全等 …...
c语言小游戏之扫雷
目录 一:游戏设计理念及思路 二:初步规划的游戏界面 三:开始扫雷游戏的实现 注:1.创建三个文件,test.c用来测试整个游戏的运行,game.c用来实现扫雷游戏的主体,game.h用来函数声明和包含头文…...

如何本地安装Python Flask并结合内网穿透实现远程开发
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

在线App封装技术:HTML5的新生命
HTML5封装的魅力所在HTML5带来了丰富的多媒体功能、地理位置服务、离线存储等特性,使得Web应用的体验更加接近原生App。封装HTML5到App中,可以大大缩短开发周期,降低开发成本,并且一次编写,多平台运行,极大…...
Spring Boot 4.0:构建云原生Java应用的前沿工具
目录 前言 Spring Boot简介 Spring Boot 的新特性 1. 支持JDK 17 2. 集成云原生组件 3. 响应式编程支持 4. 更强大的安全性 5. 更简化的配置 Spring Boot 的应用场景 1. 云原生应用开发 2. 响应式应用程序 3. 安全性要求高的应用 4. JDK 17的应用 总结 作…...

三分钟解锁B站缓存:m4s-converter视频转换全解析
三分钟解锁B站缓存:m4s-converter视频转换全解析 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站下架视频而烦恼吗…...

对比软件模拟I2C:实测GD32F303硬件I2C读写AT24C02的性能与代码差异
硬件I2C与软件模拟I2C实战对比:以GD32F303驱动AT24C02为例 在嵌入式开发中,I2C总线因其简单的两线制结构和多主从设备支持特性,成为传感器、存储芯片等外设的常用接口。面对硬件I2C控制器和GPIO模拟两种实现方式,开发者常陷入选择…...

华为防火墙双出口场景下基于IP-Link的GRE over IPSec高可用方案实战
1. 华为防火墙双出口高可用方案实战指南 企业网络多出口环境下的VPN高可用性一直是网络工程师的痛点。去年我负责某连锁企业总部与30家分支的VPN改造项目,就遇到过主链路中断导致收银系统瘫痪的尴尬情况。今天要分享的这套基于IP-Link的GRE over IPSec方案ÿ…...

IL-4/IL-4R信号通路及其靶向治疗研究进展
摘要白介素-4(interleukin-4, IL-4)是一种多效细胞因子,通过特异性结合细胞表面的IL-4受体(IL-4 receptor, IL-4R)发挥生物学效应。IL-4/IL-4R信号通路在特应性皮炎、哮喘及恶性肿瘤等疾病的病理过程中发挥重要作用。近…...


CMOS概率计算芯片设计与工程实践
1. CMOS概率计算芯片的核心设计理念概率计算作为一种新兴的计算范式,正在突破传统冯诺依曼架构的局限。我们团队开发的这款440节点CMOS芯片,其核心创新点在于将物理启发的随机性与标准CMOS工艺完美结合。不同于传统计算机的确定性计算方式,每…...

猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载
猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想保存网页上…...

内网手机远程桌面:解锁高效协同的数字密钥
在数字化办公与生活深度融合的当下,人们对于信息获取与设备操控的便捷性需求持续攀升。当我们身处内网环境,却渴望随时随地操控远端的电脑设备,内网手机远程桌面技术便如同一把精准的数字密钥,打破空间与网络的束缚,为…...

CodeWF Toolbox:一个用 Avalonia + Prism 做出来的开发者工具箱
今天这篇文章,站长来聊聊我自己开发的 CodeWF Toolbox,CodeWF 工具箱。熟悉我的朋友一般都叫我“站长”,因为我还有一个网站:CodeWF。这个工具箱也是围绕我平时写代码、维护网站、整理资料、排查问题时反复遇到的需求做出来的。它…...

从电话到流媒体:聊聊G.711、G.726这些老牌音频编码为啥还在用?
从电话到流媒体:G.711与G.726音频编码的生存之道 在数字音频技术日新月异的今天,MP3、AAC、Opus等现代编码格式早已成为流媒体和消费级应用的标配。然而,当你拆开一台最新的IP电话机,或是调试某款工业级语音设备时,大概…...