机器学习核心算法
目录
逻辑回归
算法原理
决策树
决策树算法概述
树的组成
决策树的训练与测试
切分特征
衡量标准--熵
信息增益
决策树构造实例
连续值问题解决
预剪枝方法
分类与回归问题解决
决策树解决分类问题步骤
决策树解决回归问题步骤
决策树代码实例
集成算法
Bagging模型
使用Bagging模型的示例代码
Boosting模型
AdaBoost
Stacking模型
支持向量机
决策边界
距离的计算
数据标签定义
优化的目标
目标函数
拉格朗日乘子法
SVM求解
SVM求解实例
soft-margin
低维不可分问题
逻辑回归
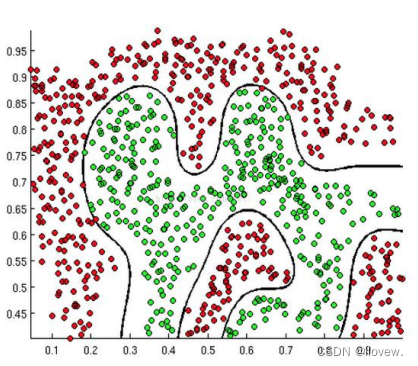
逻辑回归是一种用于解决二分类问题的机器学习分类算法。它通过将输入特征与权重相乘,并加上偏置项,然后将结果通过一个称为“sigmoid函数”的激活函数进行转换,得到一个介于0和1之间的概率值。这个概率值表示样本属于正类的概率。
算法原理


决策树
决策树算法是一种有监督学习算法,它通过构建树形结构的模型来进行决策。决策树的原理是基于特征选择和节点划分的思想。
特征选择是指从所有特征中选择一个最优的特征作为当前节点的划分标准。常用的特征选择方法有信息增益、信息增益比、基尼指数等。这些方法都是通过计算特征对于分类结果的重要性来选择最优特征。
节点划分是指根据选定的特征将数据集划分为不同的子集。每个子集对应一个分支,分支上的样本具有相同的特征值。节点划分的目标是使得每个子集中的样本尽可能属于同一类别,即增加纯度。
决策树的构建过程是递归的,从根节点开始,根据特征选择和节点划分的原则,逐步构建子树,直到满足终止条件。终止条件可以是达到预定的树深度、节点中的样本数小于某个阈值或者节点中的样本属于同一类别。
决策树算法概述
决策树算法是一种基于树形结构的分类学习方法。它通过对数据集进行递归地划分,构建一颗由多个判断节点组成的树。每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
决策树算法的概述如下:
1. 选择最佳划分属性:根据某个评价指标(如信息增益、基尼指数等),选择最佳的属性作为当前节点的划分属性。
2. 划分数据集:根据划分属性的取值,将数据集划分为多个子集,每个子集对应一个分支。
3. 递归构建子树:对每个子集,重复步骤1和步骤2,递归地构建子树,直到满足终止条件(如节点中的样本属于同一类别,或者没有更多属性可供划分)。
4. 剪枝处理:为了避免过拟合,可以对构建好的决策树进行剪枝处理,即去掉一些不必要的节点和分支。
5. 预测分类结果:根据构建好的决策树,对新样本进行分类预测。
决策树算法的优点包括易于理解和解释、能够处理离散型和连续型属性、能够处理多分类问题等。然而,决策树算法也存在一些缺点,如容易过拟合、对噪声敏感等。
树的组成
- 根节点:第一个选择点
- 非叶子节点与分支:中间过程
- 叶子节点:最终的决策结果

决策树的训练与测试
- 训练阶段:从给定的训练集构造出来一棵树(从跟节点开始选择特征,如何进行特征切分)
- 测试阶段:根据构造出来的树模型从上到下去走一遍就好了
- 一旦构造好了决策树,那么分类或者预测任务就很简单了,只需要走一遍就可以了,那么难点就在于如何构造出来一颗树,这就没那么容易了,需 要考虑的问题还有很多的!
切分特征
- 问题:根节点的选择该用哪个特征呢?接下来呢?如何切分呢?
- 想象一下:我们的目标应该是根节点就像一个老大似的能更好的切分数据 (分类的效果更好,根节点下面的节点自然就是二当家了
- 目标:通过一种衡量标准,来计算通过不同特征进行分支选择后的分类 情况,找出来最好的那个当成根节点,以此类推。
衡量标准--熵
- 熵是表示随机变量不确定性的度量 (解释:说白了就是物体内部的混乱程度,比如杂货市场里面什么都有 那肯定混乱呀,专卖店里面只卖一个牌子的那就稳定多啦)
- 熵用来衡量一组数据的平均信息量或平均不确定性。如果数据的可能取值越多,即数据的分布越均匀,那么熵就越大;相反,如果数据的可能取值越少,即数据的分布越集中,熵就越小。
- 熵的计算公式可以表示为H(X) = -Σ(p(x) * log2(p(x))),其中X是随机变量,p(x)是X取值为x的概率。这个公式将每个可能取值的概率与其对应的信息量(以2为底的对数)相乘,并对所有可能取值进行求和。熵的单位通常以比特(bit)来衡量。
![]()
熵是衡量信息或数据的不确定性和随机性的量化指标。熵的大小与不确定性成正比,即越大的熵表示数据越随机、越不确定。而越小的熵则表示数据越有序、越确定。可以将熵看作数据中所包含的信息量,当熵最大时,数据中的每个元素都是等概率出现的,难以从中获得有用的信息;而当熵最小时,数据中的每个元素都具有确定性,从中获得的信息量很小。
在机器学习中,熵经常用于衡量分类问题中的不确定性。在决策树算法中,通过计算每个特征的熵来选择分裂节点,以达到最佳的分类效果。熵可以帮助我们理解数据的分布情况和模型的性能,同时也可以作为评估模型预测结果质量的指标之一。
信息增益
信息增益是一种用于决策树算法中的指标,用于衡量特征对于分类任务的重要性。它衡量了在划分数据集之前和之后,分类的不确定性减少的程度。信息增益越大,表示使用该特征进行划分能够获得更多的信息,从而更好地分类数据。
计算信息增益的步骤如下:
1. 计算划分前的数据集的信息熵(Entropy)作为基准。
2. 对于每个特征,计算该特征划分后的加权平均信息熵。
3. 计算每个特征的信息增益,即划分前的信息熵减去划分后的加权平均信息熵。
决策树构造实例
数据:14天打球情况
特征:4种环境变化——outlook、temperature、humidity、windy;标签为 play
目标:构造决策树
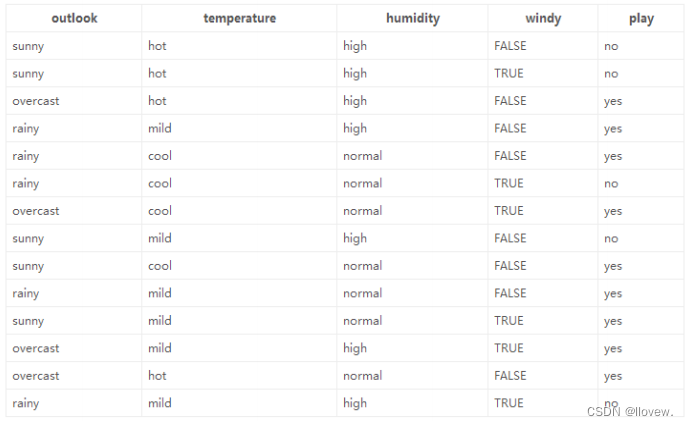
划分方式:4种
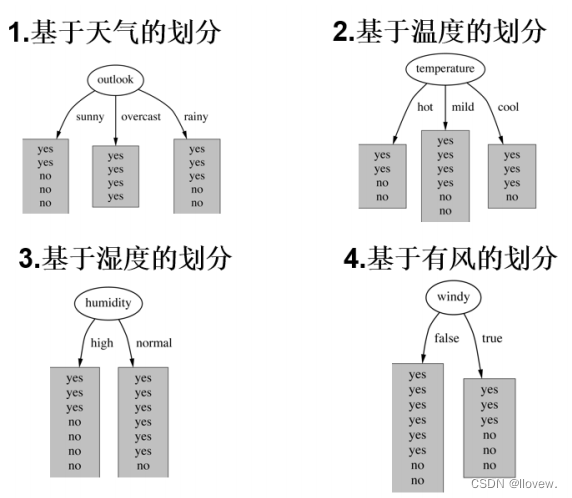
问题:谁当根节点呢?
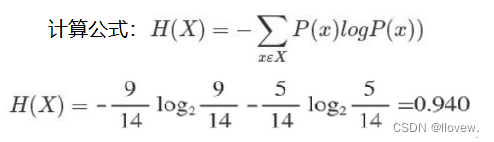

同理计算其余三个特征的增益

信息增益不适合解决特征较多的非常稀疏的特征例如数据中的ID列。

连续值问题解决
贪婪算法是一种基于贪婪策略的算法,它在每一步选择中都采取当前状态下最优的选择,而不考虑全局最优解。贪婪算法通常适用于求解最优化问题,其中问题的解可以通过一系列局部最优选择来构建。
贪婪算法的概述如下:
1. 初始化:选择一个初始解作为当前解。
2. 选择:从可行解集合中选择一个局部最优解作为当前解的下一步。
3. 更新:更新当前解为新的局部最优解。
4. 终止条件:重复步骤2和步骤3,直到满足终止条件。
贪婪算法的特点是简单、高效,并且通常能够在较短的时间内找到一个近似最优解。然而,由于贪婪算法只考虑局部最优解,而不考虑全局最优解,因此不能保证一定能够找到全局最优解。
贪婪算法在许多问题中都有应用,例如最短路径问题、背包问题、赫夫曼编码等。它可以通过选择当前状态下的最优解来解决这些问题,从而得到一个近似最优解。
例如,以下体重哪些属于适合打篮球那些不适合打篮球。
首先将数据进行从小到大排序:60 70 75 85 90 95 100 120 125 220,若进行“二分”则可能有9个分界点,分别计算分割后的增益找到最优解。实际上就是“离散化”过程。
预剪枝方法
- 为什么要剪枝:决策树过拟合风险很大,理论上可以完全分得开数据 (想象一下,如果树足够庞大,每个叶子节点不就一个数据了嘛)
- 剪枝策略:预剪枝,后剪枝
预剪枝:边建立决策树边进行剪枝的操作(更实用)限制深度,叶子节点个数,叶子节点样本数,设置信息增益量将不达标的减去等
预剪枝(pre-pruning)是在决策树构建过程中,在每个节点上进行判断,如果当前节点的划分不能带来决策树泛化性能的提升,就停止划分并将当前节点标记为叶子节点。预剪枝的优点是构建速度快,但可能会导致欠拟合,即决策树无法充分利用训练数据的特征。
后剪枝:当建立完决策树后来进行剪枝操作,通过一定的衡量标准(叶子节点越多,损失越大)
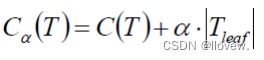
后剪枝(post-pruning)是在决策树构建完成后,通过剪枝操作来减小决策树的复杂度,提高泛化能力。后剪枝的过程是先从决策树的叶子节点开始,逐个尝试剪枝,然后通过交叉验证等方法评估剪枝前后的决策树性能,如果剪枝后性能没有显著下降,则进行剪枝操作。后剪枝的优点是可以充分利用训练数据的特征,但剪枝过程较为复杂,训练开销较大。
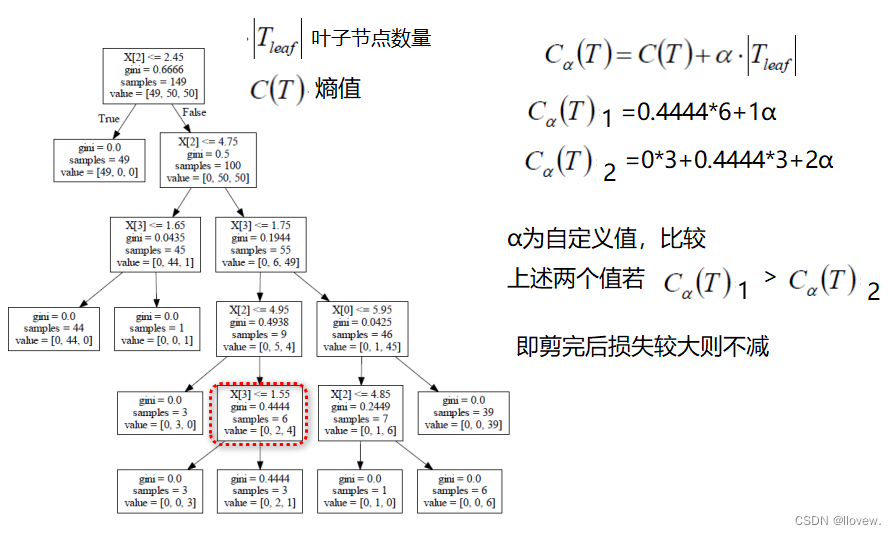
分类与回归问题解决
决策树解决分类问题步骤
决策树是一种常用的解决分类问题的算法。它通过构建一棵树来对数据进行分类。决策树的构建过程是基于特征的划分,每个内部节点代表一个特征,每个叶节点代表一个类别。
决策树的构建过程如下:
1. 选择一个特征作为根节点,将数据集按照该特征的取值进行划分。
2. 对每个子数据集,重复步骤1,选择一个最佳的特征作为子节点,并继续划分数据集。
3. 重复步骤2,直到满足终止条件,例如所有数据属于同一类别或者数据集为空。
决策树的分类过程如下:
1. 对于一个新的样本,从根节点开始,根据样本的特征值选择相应的子节点。
2. 继续在子节点中进行选择,直到到达叶节点。
3. 将叶节点所代表的类别作为预测结果。
决策树的优点是易于理解和解释,可以处理离散和连续特征,对缺失值也有一定的容忍度。然而,决策树容易过拟合,特别是当树的深度较大时。为了避免过拟合,可以使用剪枝技术,如预剪枝和后剪枝。
决策树解决回归问题步骤
决策树可以通过构建回归树来解决回归问题。回归树是将数据空间划分为多个子空间,并为每个子空间分配一个预测值。下面是决策树解决回归问题的步骤:
1. 选择一个特征和一个切分点,将数据集划分为两个子集。
2. 对于每个子集,计算目标变量的平均值作为预测值。
3. 计算划分后的子集的均方误差(MSE)。
4. 选择最佳的特征和切分点,使得划分后的子集的均方误差最小化。
5. 重复步骤1-4,直到满足停止条件(例如达到最大深度或子集中的样本数量小于阈值)。
6. 最终得到一个回归树,可以用于预测新的数据样本。
通过构建回归树,决策树可以根据输入特征预测连续型目标变量的值。回归树的构建方法与分类树类似,但是在每个节点上使用的划分准则不同。回归树使用均方误差(MSE)作为划分准则,以最小化预测值与真实值之间的差异。
决策树代码实例
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
from math import log
import operatordef createDataSet():# 四组特征,一个标签dataSet = [[0, 0, 0, 0, 'no'],[0, 0, 0, 1, 'no'],[0, 1, 0, 1, 'yes'],[0, 1, 1, 0, 'yes'],[0, 0, 0, 0, 'no'],[1, 0, 0, 0, 'no'],[1, 0, 0, 1, 'no'],[1, 1, 1, 1, 'yes'],[1, 0, 1, 2, 'yes'],[1, 0, 1, 2, 'yes'],[2, 0, 1, 2, 'yes'],[2, 0, 1, 1, 'yes'],[2, 1, 0, 1, 'yes'],[2, 1, 0, 2, 'yes'],[2, 0, 0, 0, 'no']]# 第一列年龄、第二列工作等级、第三列买没买房、第四列贷款记录、第五列会不会带给用户labels = ['F1-AGE', 'F2-WORK', 'F3-HOME', 'F4-LOAN']return dataSet, labels# 创建树模型
# 参数:数据集、标签(列名)、根节点排列
def createTree(dataset,labels,featLabels):# 1.判断节点标签是否一致(停止条件)# 将dataset中的数据按行依次放入example中,# 然后取得example中的最后一列元素,将这些元素放入列表classList中。classList = [example[-1] for example in dataset]# 2.计算列表中元素是否完全相同,即是否全为yes或者全为no(停止条件)if classList.count(classList[0]) == len(classList):# 返回第一个元素值即相同类别值return classList[0]# 3.当dataSet数据集中的值只剩下一列标签时,说明数据集已遍历完成,返回最多的类别if len(dataset[0]) == 1:# majorityCnt()函数计算每列中最多的类别return majorityCnt(classList)# chooseBestFeatureToSplit()函数选择最好的特征进行分割# 4.遍历整个数据集选择最优的特征,结果返回一个索引值bastFeat = chooseBestFeatureToSplit(dataset)# 5.获取索引值实际对应的名称bastFeatLabel = labels[bastFeat]# 6.得到树模型的根节点featLabels.append(bastFeatLabel)# 7.构建树模型整体结构,第一次得到根节点随后依次嵌套myTree = {bastFeatLabel:{}}# 8.每完成一次删除当前索引del labels[bastFeat]# 统计当前列中有多少不一样的值,例如只有0和1则树模型分为两个分支若含有多个则分为多个分支# 获取当前列的所有特征featValue = [example[bastFeat] for example in dataset]# 去除重复值,得到具体的分支个数uniqueVals = set(featValue)# 对于每个分支再进行分支for value in uniqueVals:# 切分完之后的labelssublabels = labels[:]# 在当前最好的节点下继续构建分支# splitDataSet()函数切分当前的数据集# featLabels控制树模型的特征先用哪个后用哪个myTree[bastFeatLabel][value] = createTree(splitDataSet(dataset, bastFeat, value), sublabels, featLabels)return myTree# 计算每列中最多的类别
def majorityCnt(classList):classCount = {}# 遍历classList中的每个元素vote。# 如果vote不在classCount的键中,就将vote作为键添加到classCount中,# 并将对应的值设为1。如果vote已经在classCount的键中,就将对应的值加1for vote in classList:if vote not in classCount.keys(): classCount[vote] = 0classCount[vote] += 1# 函数使用sorted函数对classCount进行排序,按照值的大小进行降序排序,并返回排序后的结果中的第一个元素的第一个值sortedclassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)# 返回出现最多的return sortedclassCount[0][0]# 选择最好的特征进行分割
"""
1.首先,获取数据集中特征的数量,即numFeatures = len(dataset) - 1。
2.然后,计算整个数据集的熵,即baseEntropy = calcShannonEnt(dataset)。熵是衡量数据集的无序程度的指标。
3.接下来,初始化最佳信息增益为0,最佳特征索引为-1。
4.使用一个循环遍历每个特征:
4-1.获取当前特征的所有取值,即featList = [example[i] for example in dataset]。
4-2将特征的取值转化为集合,即uniqueVals = set(featList)。
4-3初始化新的熵为0。
4-4对于每个特征取值,将数据集按照当前特征的取值进行划分,得到子数据集subDataSet。
4-5计算子数据集的概率,即prob = len(subDataSet)/float(len(dataset))。
4-6计算子数据集的熵,即newEntropy += prob * calcShannonEnt(subDataSet)。
4-7计算信息增益,即infoGain = baseEntropy - newEntropy。
4-8如果当前信息增益大于最佳信息增益,则更新最佳信息增益和最佳特征索引。
5.返回最佳特征索引bestFeature。
"""
# 函数的输入参数是一个数据集dataset,函数的返回值是一个整数,表示最佳特征的索引
def chooseBestFeatureToSplit(dataset):# 获取数据集中特征的数量numFeatures = len(dataset[0]) - 1"""计算熵值,利用信息增益找到最优特征"""# 原始熵值# calcShannonEnt()计算熵值函数baseEntropy = calcShannonEnt(dataset)# 设置信息增益值bestInfoGain = 0# 设置最好特征bestFeature = -1# 遍历每个特征for i in range(numFeatures):# 获取当前列特征featList = [example[i] for example in dataset]# 获取唯一个数uniqueVals = set(featList)newEntropy = 0# 遍历特征中的每个值for val in uniqueVals:# 得到划分好的数据subDataSet = splitDataSet(dataset, i, val)# 计算实际熵值prob = len(subDataSet) / float(len(dataset))# 更新熵值newEntropy += prob * calcShannonEnt(subDataSet)# 定义新的信息增益值infoGain = baseEntropy - newEntropyif (infoGain > bestInfoGain):bestInfoGain = infoGainbestFeature = ireturn bestFeature# 切分数据集
def splitDataSet(dataset, axis, val):# 创建一个空列表,用于存储划分后的子集retDataSet = []# 遍历数据集中的每个样本for featVec in dataset:# 如果样本的第axis个特征值等于给定的特征值valif featVec[axis] == val:# 将样本中除了第axis个特征之外的特征值存储到reducedFeatVec中reducedFeatVec = featVec[:axis]# 将样本中第axis个特征之后的特征值添加到reducedFeatVec中reducedFeatVec.extend(featVec[axis + 1:])# 将划分后的样本添加到retDataSet中retDataSet.append(reducedFeatVec)# 返回划分后的子集return retDataSet# 计算熵值
def calcShannonEnt(dataset):# 所有数量numexamples = len(dataset)# 每个标签出现的次数,即yes出现多少个,no出现多少个labelCounts = {}# 对于每个样本进行遍历查看为yes还是nofor featVec in dataset:# 查看当前样本的标签值currentlabel = featVec[-1]# 当前样本不在字典中if currentlabel not in labelCounts.keys():labelCounts[currentlabel] = 0labelCounts[currentlabel] += 1# 设置原始熵值为0,通过具体计算改变熵值shannonEnt = 0# 有多少类别就遍历多少次for key in labelCounts:# 概率值 = 个数/总数prop = float(labelCounts[key]) / numexamples# shannonEnt += -prop * log(prop, 2)shannonEnt -= prop * log(prop, 2)return shannonEnt# 决策树绘制
def getNumLeafs(myTree):numLeafs = 0firstStr = next(iter(myTree))secondDict = myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':numLeafs += getNumLeafs(secondDict[key])else: numLeafs +=1return numLeafsdef getTreeDepth(myTree):maxDepth = 0firstStr = next(iter(myTree))secondDict = myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__=='dict':thisDepth = 1 + getTreeDepth(secondDict[key])else: thisDepth = 1if thisDepth > maxDepth: maxDepth = thisDepthreturn maxDepthdef plotNode(nodeTxt, centerPt, parentPt, nodeType):arrow_args = dict(arrowstyle="<-")font = FontProperties(fname=r"c:\windows\fonts\simsunb.ttf", size=14)createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',xytext=centerPt, textcoords='axes fraction',va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font)def plotMidText(cntrPt, parentPt, txtString):xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)def plotTree(myTree, parentPt, nodeTxt):decisionNode = dict(boxstyle="sawtooth", fc="0.8")leafNode = dict(boxstyle="round4", fc="0.8")numLeafs = getNumLeafs(myTree)depth = getTreeDepth(myTree)firstStr = next(iter(myTree))cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)plotMidText(cntrPt, parentPt, nodeTxt)plotNode(firstStr, cntrPt, parentPt, decisionNode)secondDict = myTree[firstStr]plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalDfor key in secondDict.keys():if type(secondDict[key]).__name__=='dict':plotTree(secondDict[key],cntrPt,str(key))else:plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalWplotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalDdef createPlot(inTree):fig = plt.figure(1, facecolor='white') #创建figfig.clf() #清空figaxprops = dict(xticks=[], yticks=[])createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移plotTree(inTree, (0.5,1.0), '') #绘制决策树plt.show()if __name__ == '__main__':dataset, labels = createDataSet()featLabels = []myTree = createTree(dataset,labels,featLabels)createPlot(myTree)集成算法
集成学习(Ensemble learning)是一种通过组合多个弱分类器来构建一个强分类器的机器学习算法。它通过在数据上构建多个模型,并将所有模型的建模结果集成起来,以获得更好的回归或分类表现。集成学习在各个机器学习领域都有广泛的应用,例如市场营销模拟、客户统计、疾病风险预测等。
集成学习可以分为三类算法:装袋法(Bagging)、提升法(Boosting)和堆叠法(Stacking)。
装袋法的核心思想是构建多个相互独立的评估器,然后对它们的预测结果进行平均或多数表决来决定集成评估器的结果。常见的装袋法算法有随机森林(Random Forest)。
提升法中,基评估器是相关的,是按顺序一一构建的。它的核心思想是通过多次迭代,结合弱评估器的力量对难以评估的样本进行预测,从而构建一个强评估器。常见的提升法算法有梯度提升树(Gradient Boosting Tree)和XGBoost。
堆叠法的特点是使用第一阶段的预测结果作为下一阶段的特征,以提高模型的非线性表达能力和降低泛化误差。堆叠法的目标是同时降低模型的偏差和方差。
总结起来,集成学习通过组合多个模型的建模结果,以获得更好的回归或分类表现。装袋法通过构建多个相互独立的评估器来决定集成评估器的结果,提升法通过迭代构建强评估器,堆叠法通过使用预测结果作为特征来提高模型的表达能力。
- 目的:让机器学习效果更好,单个不行,群殴走起
- Bagging:训练多个分类器取平均
- Boosting:从弱学习器开始加强,通过加权来进行训练
- Stacking:聚合多个分类或回归模型(可以分阶段来做)
Bagging模型
Bagging模型是一种集成学习方法,它通过对训练集进行有放回的随机抽样,构建多个基学习器并通过对基学习器的预测结果进行投票或平均来得到最终的预测结果。Bagging模型的主要步骤如下:
-
随机抽样:从训练集中有放回地随机抽取一定数量的样本,构成新的训练集。
-
基学习器训练:使用新的训练集训练多个基学习器。每个基学习器可以使用不同的算法或参数设置。
-
预测结果集成:对于分类问题,可以通过投票的方式来集成基学习器的预测结果;对于回归问题,可以通过平均的方式来集成基学习器的预测结果。
-
公式:
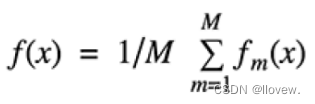
Bagging模型的优点包括:
- 可以降低模型的方差,提高模型的泛化能力。
- 可以减少过拟合的风险。
- 可以处理高维数据和大规模数据集。
Bagging模型的缺点包括:
- 可能增加模型的偏差,导致模型的准确性下降。
- 训练和预测的时间和内存消耗较大。
说白了就是并行训练一堆分类器,最典型的代表就是随机森林。随机:数据采样随机,特征选择随机;森林:很多个决策树并行放在一起。之所以要进行随机,是要保证泛化能力,如果树都一样,那就没意义了。
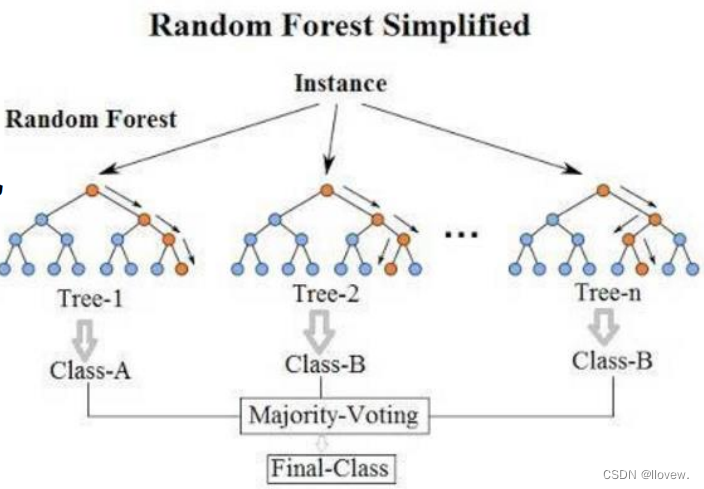
使用Bagging模型的示例代码
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier# 创建基学习器
base_estimator = DecisionTreeClassifier()# 创建Bagging模型
bagging_model = BaggingClassifier(base_estimator=base_estimator, n_estimators=10)# 训练模型
bagging_model.fit(X_train, y_train)# 预测结果
y_pred = bagging_model.predict(X_test)Boosting模型
Boosting模型是一种集成学习方法,它通过串行训练多个弱学习器来构建一个强学习器。Boosting模型的主要思想是通过迭代的方式,每一轮迭代都根据前一轮的结果来调整样本的权重,使得前一轮分类错误的样本在下一轮中得到更多的关注。最终,将所有弱学习器的预测结果进行加权组合,得到最终的预测结果。
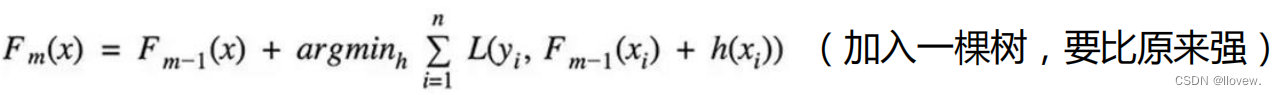
在Boosting模型中,有几个经典的算法被广泛应用,包括AdaBoost、GBDT和XGBoost。
1. AdaBoost(Adaptive Boosting)是一种最早提出的Boosting算法。它通过迭代训练多个弱分类器,每一轮迭代都根据前一轮的分类结果来调整样本的权重,使得前一轮分类错误的样本在下一轮中得到更多的关注。最终,将所有弱分类器的预测结果进行加权组合,到最终的预测结果。
2. GBDT(Gradient Boosting Decision Tree)是一种基于决策树的Boosting算法。它通过迭代训练多个决策树模型,每一轮迭代都根据前一轮的残差来训练下一棵决策树。最终,将所有决策树的预测结果进行加权组合,得到最终的预测结果。
3. XGBoost(eXtreme Gradient Boosting)是一种基于GBDT的Boosting算法的优化版本。它在GBDT的基础上引入了正则化项和二阶导数信息,进一步提高了模型的性能和泛化能力。
这些Boosting模型在机器学习和数据挖掘领域都有广泛的应用,可以用于分类问题和回归问题。
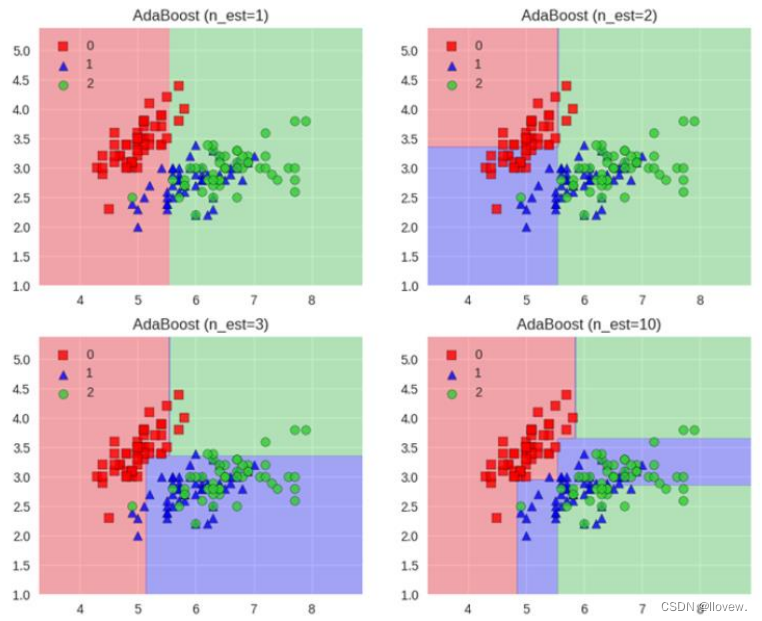
AdaBoost
AdaBoost(Adaptive Boosting)是一种集成学习方法,它通过组合多个弱学习器来构建一个强学习器。它的核心思想是通过迭代训练一系列弱分类器,并根据每个弱分类器的表现来调整样本的权重,使得在下一轮训练中更加关注被前一轮分类错误的样本。最终,将这些弱分类器的结果进行加权组合,得到一个更准确的分类结果。
AdaBoost的训练过程如下:
1. 初始化样本权重,使得每个样本的权重相等。
2. 迭代训练弱分类器。在每一轮迭代中,根据当前样本权重训练一个弱分类器,并计算分类错误率。
3. 根据分类错误率计算弱分类器的权重,错误率越低的弱分类器权重越高。
4. 更新样本权重,增加被错误分类的样本的权重,减少被正确分类的样本的权重。
5. 重复步骤2-4,直到达到预定的迭代次数或分类错误率达到要求。
6. 将所有弱分类器的结果进行加权组合,得到最终的分类结果。
AdaBoost的优点是能够提高分类的准确性,并且对于弱分类器的选择没有太多限制。然而,它也有一些缺点,比如对噪声敏感,容易过拟合,以及对弱分类器的训练时间较长。
- Adaboost会根据前一次的分类效果调整数据权重
- 解释:如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重
- 最终的结果:每个分类器根据自身的准确性来确定各自的权重,再合体
- 工作流程:首先每一次切一刀、然后合在一起、最终弱分类器这就升级了
Stacking模型
Stacking模型是一种集成学习方法,它将多个单一模型以一定的方式组合起来,以获得更好的预测性能。Stacking模型的基本思想是将多个不同的基础模型进行堆叠,其中一个模型作为最终的预测模型,而其他模型则作为该模型的输入。
Stacking模型的训练过程分为两个阶段。首先,使用训练数据对每个基础模型进行训练。然后,使用这些基础模型的预测结果作为输入,再训练一个元模型(也称为组合模型或次级模型)。元模型使用基础模型的预测结果作为特征,以生成最终的预测结果。
Stacking模型的优点在于它可以结合各个单项预测模型的优点,从而提高整体的预测性能。通过使用不同类型的基础模型,Stacking模型可以捕捉到不同模型的优势,并在预测中进行综合利用。
- 堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
- 可以堆叠各种各样的分类器(KNN,SVM,RF等等)
- 分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
- 为了刷结果,不择手段
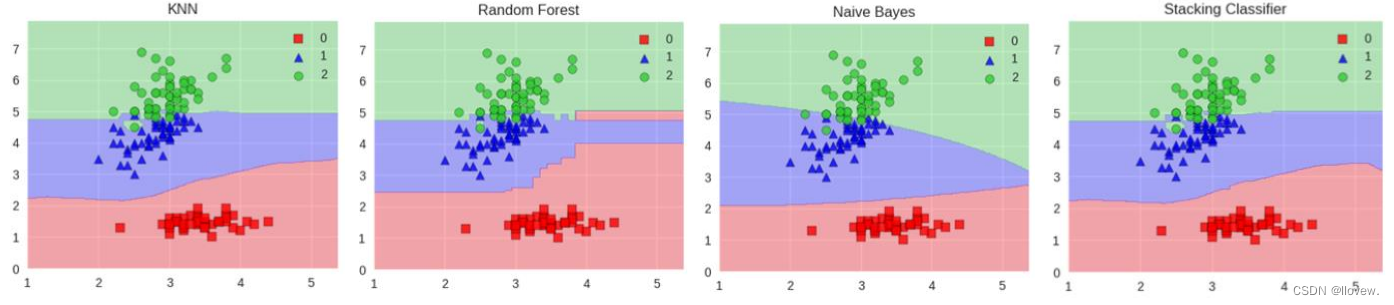
范例: 假设我们有三个基础模型:模型A、模型B和模型C。我们使用训练数据对这三个模型进行训练,并得到它们的预测结果。然后,我们将这些预测结果作为特征,再训练一个元模型D。最终,我们可以使用元模型D来进行预测。
# 训练基础模型
model_A.fit(X_train, y_train)
model_B.fit(X_train, y_train)
model_C.fit(X_train, y_train)# 得到基础模型的预测结果
pred_A = model_A.predict(X_test)
pred_B = model_B.predict(X_test)
pred_C = model_C.predict(X_test)# 将基础模型的预测结果作为特征,训练元模型
X_meta = np.column_stack((pred_A, pred_B, pred_C))
model_D.fit(X_meta, y_train)# 使用元模型进行预测
pred_final = model_D.predict(X_meta_test)支持向量机
支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法,主要用于分类和回归问题。其原理基于统计学习理论中的结构风险最小化原则。
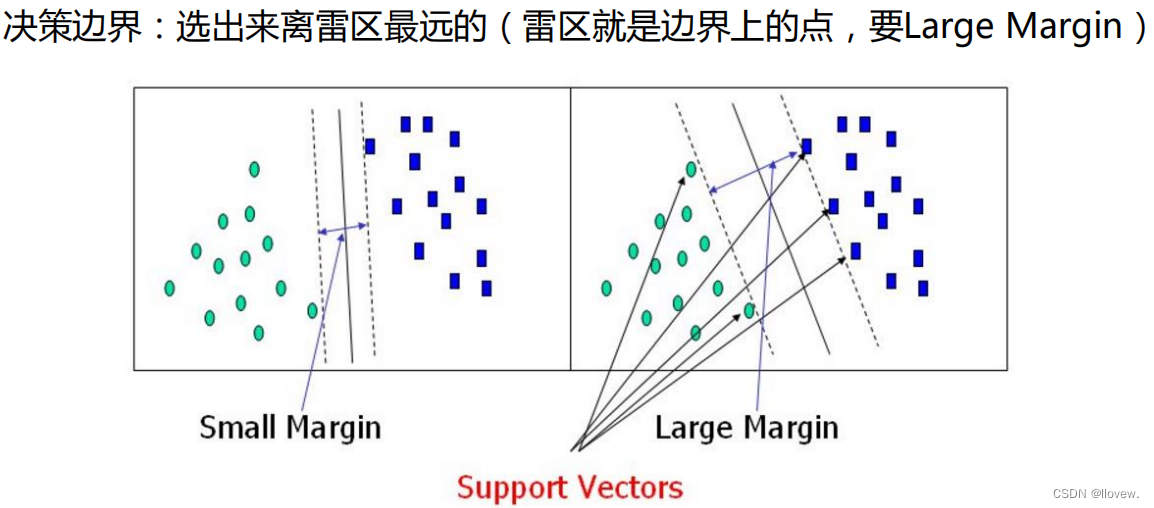
SVM的目标是找到一个最优的超平面,能够将不同类别的样本点在特征空间中划分开来,并且使得两侧距离最近的样本点到超平面的距离最大化。这些距离最近的样本点被称为支持向量。
具体来说,SVM的原理可以概括为以下几个步骤:
- 1. 数据准备:首先,将训练数据表示为特征向量的形式,并进行标记,以便区分不同的类别。
- 2. 特征空间映射:将数据映射到高维特征空间,通过使用核函数(Kernel Function)来实现。常用的核函数有线性核、多项式核和高斯核等。
- 3. 构建超平面:在特征空间中,寻找一个超平面,使得不同类别的样本点尽可能地分开,并且使得支持向量到超平面的距离最大化。
- 4. 分类预测:对于新的未知样本点,根据其在特征空间中的位置,判断其所属的类别。
SVM具有以下特点和优势:
- - 可以解决线性可分和线性不可分的问题,通过选择合适的核函数进行映射。
- - 在处理高维数据时表现优秀,可以有效地处理特征空间维度较高的问题。
- - 通过最大化支持向量到超平面的距离,具有较好的鲁棒性和泛化能力。
- - 适用于小样本情况,对于样本数量较少的问题仍能取得较好的效果。
需要注意的是,SVM的训练过程涉及到优化问题的求解,通常采用凸优化算法进行求解,例如序列最小优化(SMO)算法。
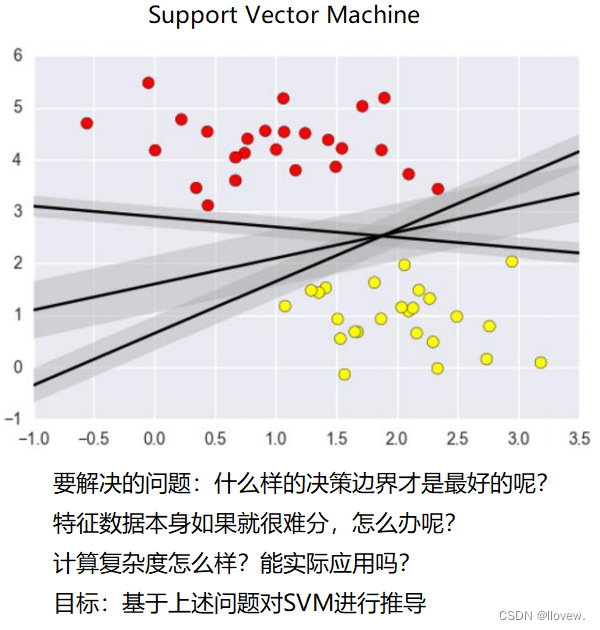
决策边界
在支持向量机(SVM)中,决策边界是通过找到能够将不同类别样本分开的最优超平面来实现的。这个最优超平面被选为距离两个不同类别的样本最远的点的平均位置。这些最远的点被称为支持向量,它们决定了决策边界的位置。
决策边界的形状可以是线性的,也可以是非线性的。在线性可分的情况下,决策边界是一个直线或超平面。在非线性可分的情况下,可以使用核函数将数据映射到高维空间中,从而使其在高维空间中线性可分。决策边界的选择对分类器的性能和泛化能力有很大影响。一个合理的决策边界可以更好地区分不同类别的样本,并对新样本进行准确分类。
距离的计算

数据标签定义

优化的目标

目标函数

拉格朗日乘子法

SVM求解

SVM求解实例

soft-margin

低维不可分问题
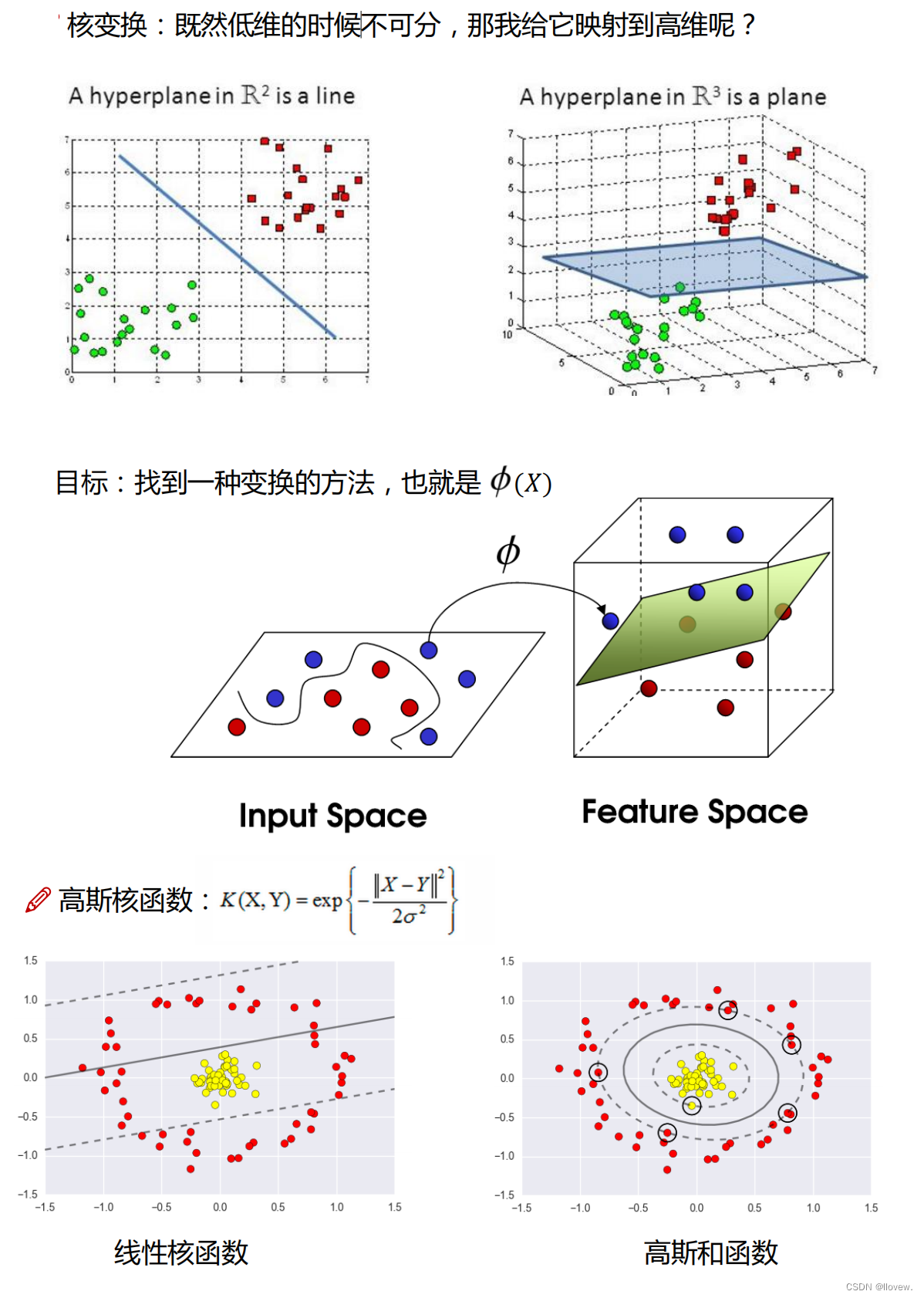 点击进入核变换详解
点击进入核变换详解
相关文章:
机器学习核心算法
目录 逻辑回归 算法原理 决策树 决策树算法概述 树的组成 决策树的训练与测试 切分特征 衡量标准--熵 信息增益 决策树构造实例 连续值问题解决 预剪枝方法 分类与回归问题解决 决策树解决分类问题步骤 决策树解决回归问题步骤 决策树代码实例 集成算法 Baggi…...

libjsoncpp 的编译和交叉编译
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

【Unity美术】如何用3DsMax做一个水桶模型
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

如何用一根网线和51单片机做简单门禁[带破解器]
仓库:https://github.com/MartinxMax/Simple_Door 支持原创是您给我的最大动力… 原理 -基础设备代码程序- -Arduino爆破器程序 or 51爆破器程序- 任意选一个都可以用… —Arduino带TFT屏幕——— —51带LCD1602——— 基础设备的最大密码长度是0x7F,因为有一位…...

在 VUE 项目中,使用 Axios 请求数据时,提示跨域,该怎么解决?
在 VUE 项目开发时,遇到个问题,正常设置使用 Axios 库请求数据时,报错提示跨域问题。 那在生产坏境下,该去怎么解决呢? 其可以通过以下几种方式去尝试解决: 1、设置允许跨域请求的响应头 1.1 在响应头中…...
1.【Vue3】前端开发引入、Vue 简介
1. 前端开发引入 1.1 前端开发前置知识 通过之前的学习,已经通过 SpringBoot 和一些三方技术完成了大事件项目的后端开发。接下来开始学习大事件项目的前端开发,前端部分借助两个框架实现: Vue3(一个 JS 框架)基于 …...

一起学习ETCD系列——运维操作之etcdctl使用
文章目录 概要一、命令二、实操2.1、基本操作2.2、watch2.3、租约2.4、分布式锁2.5、角色2.6、用户2.7、认证2.8、集群 概要 本文主要用来总结ETCD客户端ctcdctl的命令操作,在运维过程中可能常常用到的。 一、命令 etcd工具 etcdctl官方命令示例 [roottest etcd…...

Spring Security 存储密码之 JDBC
Spring Security的JdbcDaoImpl实现了UserDetailsService接口,通过使用JDBC提供支持基于用户名和密码的身份验证。 JdbcUserDetailsManager扩展了JdbcDaoImpl,通过UserDetailsManager接口提供UserDetails的管理功能。 当Spring Security配置为接受用户名/密码进行身份验证时,…...
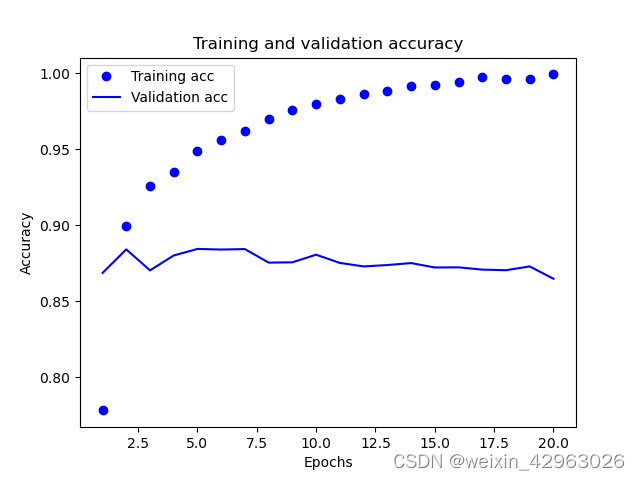
第3章-python深度学习——(波斯美女)
第3章 神经网络入门 本章包括以下内容: 神经网络的核心组件 Keras 简介 建立深度学习工作站 使用神经网络解决基本的分类问题与回归问题 本章的目的是让你开始用神经网络来解决实际问题。你将进一步巩固在第 2 章第一个示例中学到的知识,还会将学到的…...
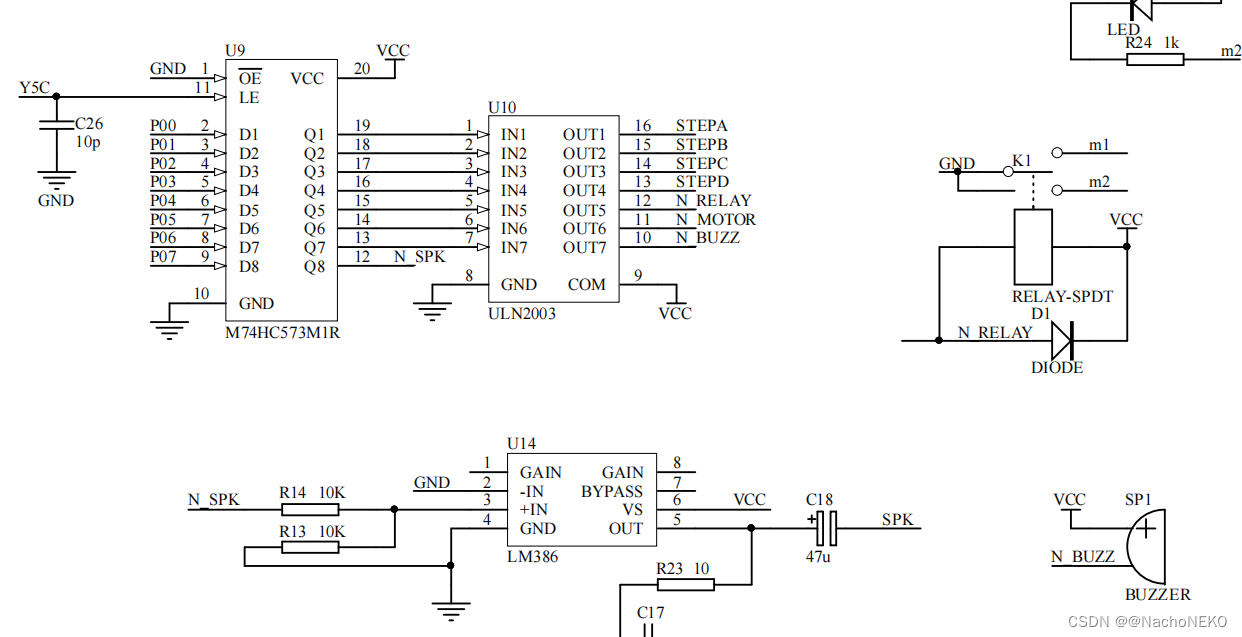
蓝桥杯备战——4.继电器/蜂鸣器
1.分析原理图 最好自己先去查查138以及ULN2003的使用方法,我这里直接讲思路。 由上图我们可以看到如果138输入ABC101,则输出Y50,此时若WR通过跳线帽接地则Y5C1 ,于是573(U9)处于输出跟随输入P0状态,此时若P061,则573输出Q71&am…...

Redis高级特性之地理空间索引
Redis的地理空间索引是一种功能强大的工具,用于存储和查询地理空间数据。这个特性主要通过Redis的地理空间数据类型 - GeoSet(地理集合)来实现。在这篇文章中,我们将探索Redis地理空间数据类型的使用和应用。 1. Redis GeoSet 简…...

R语言【taxlist】——as():将 taxlist 对象强制转换为 list 对象
Package taxlist version 0.2.4 Description 可以应用 S4 对象到 list 对象的强制转换来探索它们的内容,避免由它们的验证引起的错误。 Usage S4_to_list(x) Argument 参数【x】:一个 taxlist 类对象或任意 S4 类。 Details 将 taxlist 对象强制转换…...

使用POI生成word文档的table表格
文章目录 使用POI生成word文档的table表格1. 引入maven依赖2. 生成table的两种方式介绍2.1 生成一行一列的table2.2 生成固定行列的table2.3 table合并列2.4 创建多个table存在的问题 使用POI生成word文档的table表格 1. 引入maven依赖 <dependency><groupId>org.…...

C# 继承、多态性、抽象和接口详解:从入门到精通
C# 继承 在 C# 中,可以将字段和方法从一个类继承到另一个类。我们将“继承概念”分为两类: 派生类(子类) - 从另一个类继承的类基类(父类) - 被继承的类 要从一个类继承,使用 : 符号。 在以…...
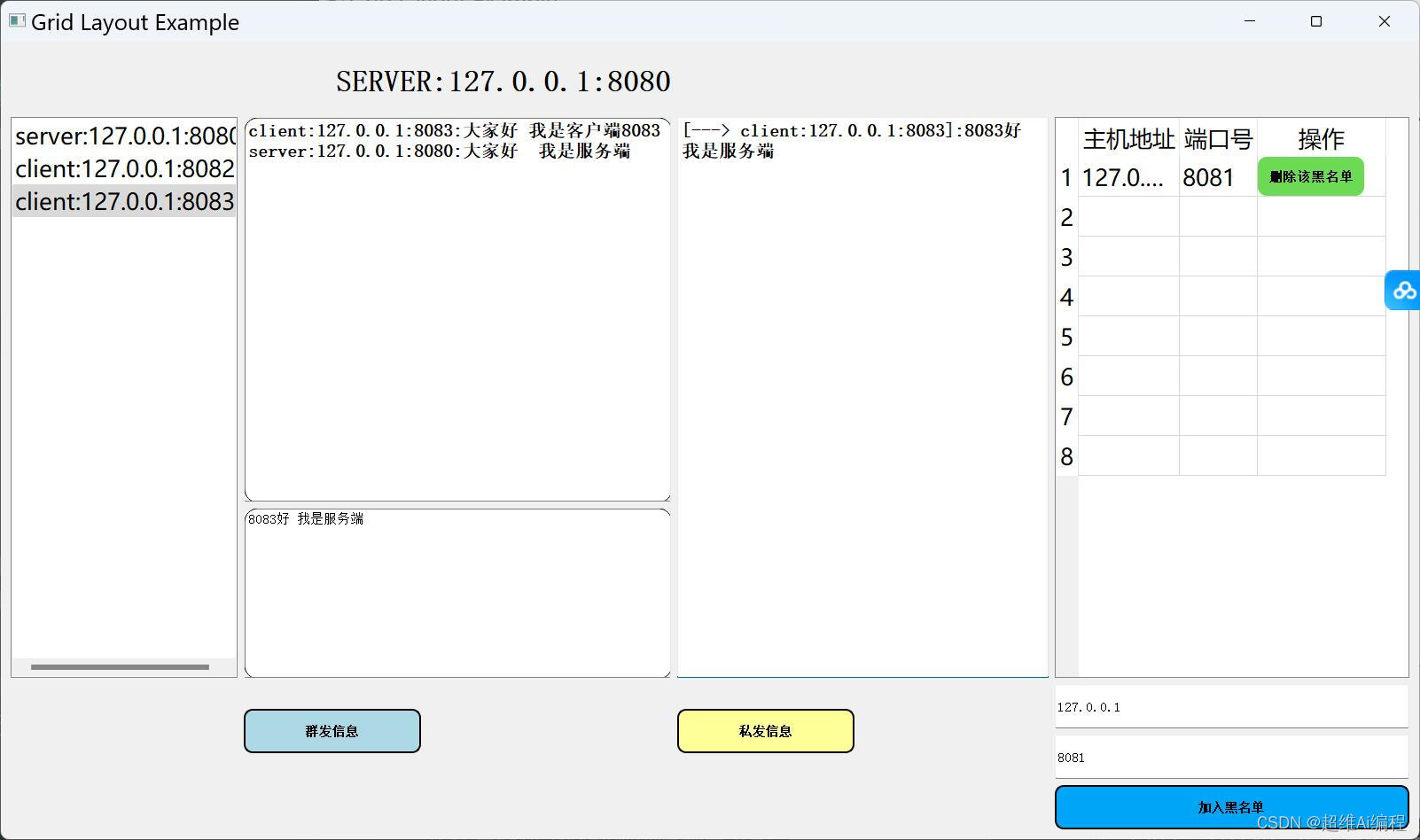
python在线聊天室(带聊天保存)
python Socket在线聊天室(带聊天保存) 需求功能 1.聊天信息保存功能(服务端会把信息保存到一个txt里面) 2.使用pyqt5框架作为一个可视化界面 3.具备一个服务端和多个客户端的功能 4.具备离线加入黑名单(离线踢出) 5.具备在线加入黑名单(在线加入黑名单被踢出) 6.具备群聊功能…...

jenkins+gitlab实现Android自动打包填坑之旅
一.背景 1.首先你需要知道你想要实现的Android自动打包的Android项目的一些环境配置及需要使用的一些开发版本。 声明:本文 Android项目基于:1.jdk11 2.SDK无要求 3.gradle无要求(同Manven一样为项目自动化构建开源工具) 注&am…...

洛谷B3625迷宫寻路
迷宫寻路 题目描述 机器猫被困在一个矩形迷宫里。 迷宫可以视为一个 n m n\times m nm 矩阵,每个位置要么是空地,要么是墙。机器猫只能从一个空地走到其上、下、左、右的空地。 机器猫初始时位于 ( 1 , 1 ) (1, 1) (1,1) 的位置,问能否…...
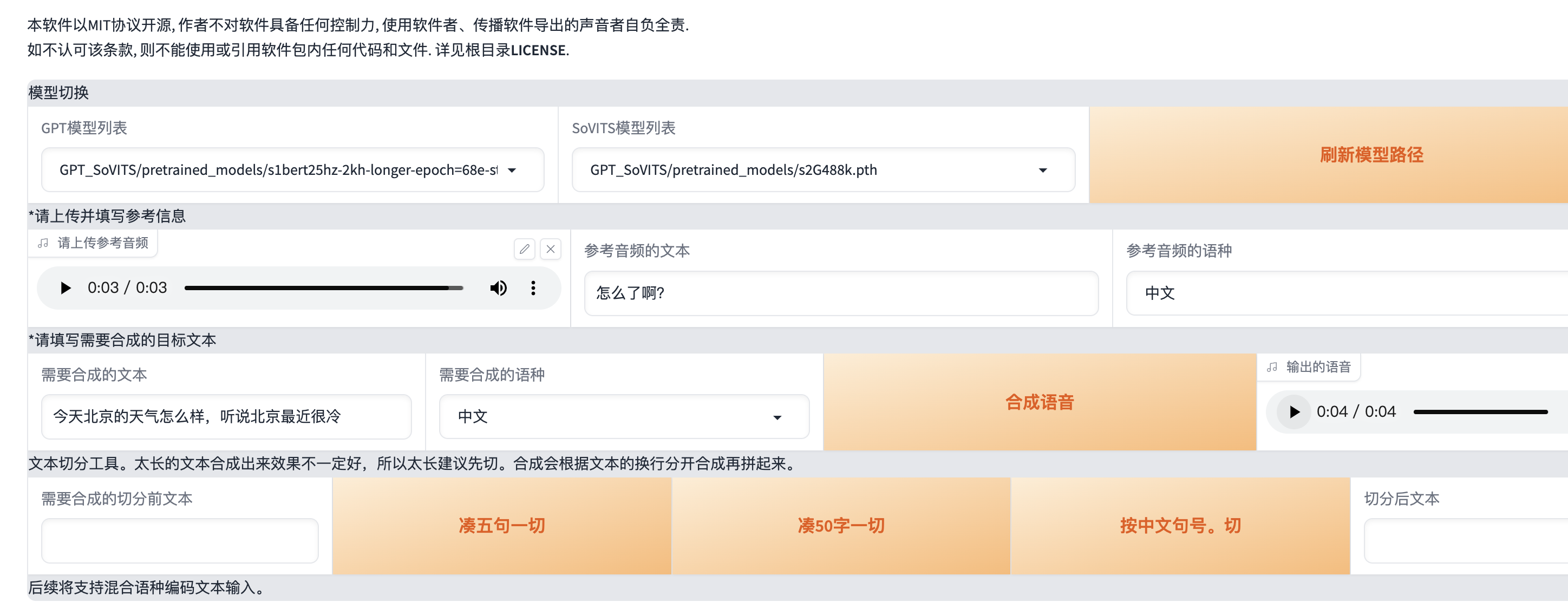
GPT-SoVITS 测试
开箱直用版(使用 AutoDL) step1 打开地址 https://www.codewithgpu.com/i/RVC-Boss/GPT-SoVITS/GPT-SoVITS-Official 选择 AutoDL创建实例,选择 3080ti 机器 step2 创建好实例之后,进入命令行,输入命令 echo {}>…...
人工智能:更多有用的 Python 库
目录 前言 推荐 JupyterLab 入门 复杂的矩阵运算 其它人工智能和机器学习的 Python 库 前言 在这篇文章中,我们将了解更多的矩阵操作,同时再介绍几个人工智能 Python 库。 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&#x…...

Linux BIO如何下发到HDD?
在Linux操作系统中,当创建一个Block I/O请求(BIO)时,它会被封装成适合硬件交互的数据结构,并通过内核存储子系统传递到对应的硬件控制器上,如SAS(Serial Attached SCSI)HBAÿ…...

深度揭秘ControlNet-v1-1 FP16模型:5大实战技巧突破SD1.5显存瓶颈
深度揭秘ControlNet-v1-1 FP16模型:5大实战技巧突破SD1.5显存瓶颈 【免费下载链接】ControlNet-v1-1_fp16_safetensors 项目地址: https://ai.gitcode.com/hf_mirrors/comfyanonymous/ControlNet-v1-1_fp16_safetensors ControlNet-v1-1_fp16_safetensors作…...

GPT-SoVITS语音克隆镜像评测:5秒样本实现高质量声音复刻
GPT-SoVITS语音克隆镜像评测:5秒样本实现高质量声音复刻 1. 引言:声音克隆技术的新突破 在虚拟助手、有声读物和数字人应用爆发的今天,语音克隆技术正变得越来越重要。传统语音合成系统往往需要数小时的录音样本才能训练出可用的声音模型&a…...

5个实用技巧:让waifu2x-caffe成为你的图像超分辨率利器
5个实用技巧:让waifu2x-caffe成为你的图像超分辨率利器 【免费下载链接】waifu2x-caffe waifu2xのCaffe版 项目地址: https://gitcode.com/gh_mirrors/wa/waifu2x-caffe waifu2x-caffe是一个基于Caffe深度学习框架的图像超分辨率与降噪工具,专为W…...

深度解析:数据挖掘核心任务与实战应用场景
深度解析:数据挖掘核心任务与实战应用场景前言一、数据挖掘核心定义二、数据挖掘标准执行流程(CRISP-DM 流程图)流程节点说明:三、数据挖掘的主要任务(6大核心分类)1. 分类分析:预测已知类别2. …...

OpenClaw+Qwen3.5-9B长文本处理:128K上下文资料归档实践
OpenClawQwen3.5-9B长文本处理:128K上下文资料归档实践 1. 为什么需要自动化资料归档 作为一名经常需要阅读大量文献的研究人员,我长期被两个问题困扰:一是PDF里的关键信息难以快速提取,二是不同来源的资料无法自动归类。直到发…...

Python EXE解包工具终极指南:轻松提取源代码的完整教程
Python EXE解包工具终极指南:轻松提取源代码的完整教程 【免费下载链接】python-exe-unpacker A helper script for unpacking and decompiling EXEs compiled from python code. 项目地址: https://gitcode.com/gh_mirrors/py/python-exe-unpacker Python …...
RC5引入的Script运行能力)
MAF快速入门(21)RC5引入的Script运行能力
大家好,我是Edison。最近我一直在跟着圣杰的《.NETAI智能体开发进阶》课程学习MAF开发多智能体工作流,我强烈推荐你也上车跟我一起出发!上一篇,我们了解下.NET 10新推出的File-Based App模式,它和MAF一起可以形成一个强…...

FPGA新手避坑指南:UART、SPI、I2C三大串行协议到底怎么选?
FPGA新手避坑指南:UART、SPI、I2C三大串行协议到底怎么选? 第一次接触FPGA开发时,面对琳琅满目的通信协议选择,很多新手都会感到无从下手。UART、SPI、I2C这三种最常见的串行协议各有特点,但选错协议可能导致项目延期、…...

如何参与Splide开源轮播组件:完整社区贡献指南
如何参与Splide开源轮播组件:完整社区贡献指南 【免费下载链接】splide Splide is a lightweight, flexible and accessible slider/carousel written in TypeScript. No dependencies, no Lighthouse errors. 项目地址: https://gitcode.com/gh_mirrors/sp/splid…...

3分钟快速破解:百度网盘提取码智能获取工具终极指南
3分钟快速破解:百度网盘提取码智能获取工具终极指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到加密资源都要手动搜索,既耗时又低效。…...