从公有云对象存储迁移到回私有化 MinIO需要了解的所有信息

我们上一篇文章《如何从 AWS S3 遣返到 MinIO》的反响非常出色 - 我们已经接到了数十个企业的电话,要求我们提供遣返建议。我们已将这些回复汇总到这篇新文章中,其中我们更深入地研究了与遣返相关的成本和节省,以便您更轻松地进行自己的分析。对许多人来说,数据迁移是一项艰巨的任务。在实践中,他们的目标是将新数据引入 MinIO,并利用他们的甜蜜时间从云中迁移旧数据,或者将其留在原地而不增长。
遣返概览
要从 AWS S3 发回数据,您将遵循以下一般准则:
-
查看数据要求:确定需要从 AWS S3 返回的特定存储桶和对象。确保您逐个桶了解业务需求和合规性要求。
-
确定遣返目的地:您已经决定遣返到 MinIO,现在您可以选择在本地数据中心或其他云提供商或托管设施中运行 MinIO。使用 #1 中的要求,您将选择硬件或实例来满足预测的存储、传输和可用性需求。
-
数据传输:计划并执行从 AWS S3 到 MinIO 的数据传输。只需使用 MinIO 的内置批量复制或使用 MinIO 客户端进行镜像(有关详细信息,请参阅如何从 AWS S3 遣返到 MinIO)。您还可以使用其他几种方法进行数据传输,例如使用 AWS DataSync、AWS Snowball 或 TD SYNNEX 数据迁移,或者直接使用 AWS API。
-
数据访问和权限:确保为每个存储桶的返还数据设置适当的访问控制和权限。这包括用于管理用户访问、身份验证和授权的 IAM 和存储桶策略,以确保数据的安全性。
-
对象锁定:在迁移后保留对象锁定保留和法律保留策略至关重要。目标对象存储必须以与 Amazon S3 相同的方式解释规则。如果您不确定,请要求对目标对象存储实现进行 Cohasset Associates 合规性评估。
-
数据生命周期管理:为返还的数据定义并实施数据生命周期管理策略。这包括定义保留策略、备份和恢复过程以及基于每个存储桶的数据归档做法。
-
数据验证:验证传输的数据以确保其完整性和完整性。执行必要的检查和测试,以确保数据已成功传输,没有任何损坏或丢失。传输后,源和目标之间的对象名称、ETag 和元数据、校验和以及对象数量都匹配。
-
更新应用程序和工作流:好消息是,如果您遵循云原生原则来构建应用程序,那么您所要做的就是为新的 MinIO 端点重新配置它们。但是,如果您的应用程序和工作流旨在与 AWS 生态系统配合使用,请进行必要的更新以适应返回的数据。这可能涉及更新配置、重新配置集成或在某些情况下修改代码。
-
监控和优化:持续监控和优化遣返的数据环境,以确保最佳性能、成本效益并遵守数据管理最佳实践。
遣返步骤
在制定云遣返预算和规划时,需要考虑许多因素。幸运的是,我们的工程师已经与许多客户合作过,我们已经为您制定了详细的计划。我们的客户已经遣返了从少量工作负载到数百 PB 的所有内容。
最大的规划任务是考虑围绕网络、租用带宽、服务器硬件、未选择要遣返的数据的归档成本以及管理和维护自己的云基础架构的人力成本等方面的选择。估算这些成本并为其制定计划。云遣返成本将包括将数据从云移回数据中心的数据出口费用。这些费用故意高到足以迫使云锁定。请注意这些高昂的出口费用 - 它们证实了离开公共云的经济论点,因为随着您管理的数据量的增长,出口费用也会增加。因此,如果您要遣返,尽早采取行动是值得的。
我们将重点关注必须移动的数据和元数据 - 这是遣返所需工作的 80%。元数据包括存储桶属性和策略(基于访问/私有密钥的访问管理、生命周期管理、加密、匿名公有访问、对象锁定和版本控制)。
现在让我们专注于数据(对象)。对于要迁移的每个命名空间,请清点要移动的存储桶和对象。您的 DevOps 团队可能已经知道哪些存储桶包含重要的当前数据。您还可以使用 Amazon S3 清单。在较高级别上,这将如下所示:
| Namespace(命名空间) | 总桶数 | 对象总数 | 对象总大小 (GB) | 每日总上传量 (TB) | 每日总下载量 (TB) |
|---|---|---|---|---|---|
| NS-001型 | 166 | 47,751,258 | 980,014.48 | 50.04 | 14.80 |
| NS-001型 | 44 | 24,320,810 | 615,033.35 | 23.84 | 675.81 |
| NS-002型 | 648 | 88,207,041 | 601,298.91 | 328.25 | 620.93 |
| NS-001型 | 240 | 68,394,231 | 128,042.16 | 62.48 | 12.45 |
下一步是按命名空间列出每个存储桶及其要迁移的每个存储桶的属性。请注意在该存储桶中存储和读取数据的应用程序。根据使用情况,将每个存储桶分类为热层、暖层或冷层数据。
在删节版中,这看起来像
| 存储桶名称 | 性能 | 应用 | 热/温/冷层 |
|---|---|---|---|
| A | Copy and paste JSON here | Spark, Iceberg, Dremio | 热 |
| B | Copy and paste JSON here | Elastic | 温 |
| C | Copy and paste JSON here | Elastic 弹性的快照 | 冷 |
此时,您需要做出一些关于数据生命周期管理的决定,请密切关注,因为这是节省 AWS 费用的好方法。根据访问频率将每个存储桶中的对象分类为热、暖或冷。一个省钱的好地方是将冷层存储桶直接迁移到 S3 Glacier – 没有理由为了再次上传而产生下载出口费用。
根据要遣返的数据量,您可以通过几个选项来选择迁移方式。我们建议您在新的 MinIO 集群上加载和处理新数据,同时随着时间的推移将热数据和温数据复制到新集群。当然,复制对象所需的时间和带宽将取决于要复制的对象的数量和大小。
在这里,计算要从 AWS S3 传回的总数据将非常有帮助。查看您的库存,并计算所有分类为热桶和暖桶的总大小。
| 说明 |
|---|
| 热层和暖层数据总数 = 1,534,096.7 GB |
| 可用带宽 = 10 Gbps |
| 所需的最短传输时间(总对象大小/可用带宽)= 14.2 天 |
根据上述总额计算数据出口费用。我使用的是标价,但您的组织可能有资格享受 AWS 的折扣。我也使用 10 Gbps 作为连接带宽,但您可能或多或少可以使用。最后,我的假设是,三分之一的 S3 数据将仅转移到 S3 Glacier Deep Archive。
| 说明 |
|---|
| 分层到 S3 Glacier 的总数据 = 767048.337GB |
| S3 到 S3 Glacier 的传输费用(0.05 USD/1000 个对象)= 3773.11USD |
| S3 Glacier Deep Archive 月度存储费 = 760 USD |
不要忘记为 S3 Glacier Deep Archive 的使用量制定预算。
| 说明 |
|---|
| 要传输的总数据 = 1,534,096.7 GB |
| 前 10 TB,0.09 USD/GB = 900 USD |
| 接下来的 100 TB,0.07 USD/GB = 70000 USD |
| 超过 150 TB 的额外容量,0.05 USD/GB = 69205 USD |
| 接下来的 40 TB,价格为 0.085 USD/GB = 3400 USD |
| 出口总费用 = 143,504 USD |
为简单起见,上述计算既不包括每个对象操作的费用(0.40 美元/1 百万美元),也不包括 LISTing 的成本(5 美元/1 百万美元)。对于非常大的遣返项目,我们还可以在通过网络发送对象之前对其进行压缩,从而为您节省一些出口费用。
另一种选择是使用 AWS Snowball 传输对象。每个 Snowball 设备都是 80TB,因此我们事先知道需要 20 个设备来进行遣返工作。每台设备的费用包括 10 天的使用时间,外加 2 天的运输费用。额外天数为每台设备 30 美元。
| 说明 |
|---|
| 20 Snowball 设备服务费 ($300 ea) = $6,000 |
| R/T 运费(3-5 天,每台 400 美元)= 8,000 美元 |
| S3 数据输出(0.02 USD/GB)= 30682 USD |
| Snowball 总费用 = 38981.93 USD |
AWS 将向您收取标准请求、存储和数据传输费率,以读取和写入 AWS 服务,包括 Amazon S3 和 AWS Key Management Service (KMS)。使用 Amazon S3 存储类时,还有其他注意事项。对于 S3 导出作业,从 S3 传输到 Snow Family 设备的数据按 LIST、GET 等操作的标准 S3 费用计费。您还需要为 Amazon CloudWatch Logs、Amazon CloudWatch 指标和 Amazon CloudWatch Events 支付标准费率。
现在我们知道迁移如此庞大的数据量需要多长时间以及成本。根据时间和费用的组合,就哪种方法满足您的需求做出业务决策。
在这一点上,我们还知道在本地或托管设施中运行 MinIO 所需的硬件要求。根据上述 1.5PB 存储要求,估计数据增长,并查阅我们的推荐硬件和配置页面和为您的 MinIO 部署选择最佳硬件。
第一步是在 MinIO 中重新创建 S3 存储桶。无论您选择如何迁移对象,您都必须这样做。虽然 S3 和 MinIO 都使用服务器端加密来存储对象,但您不必担心迁移加密密钥。您可以使用 MinIO KES 连接到您选择的 KMS 来管理加密密钥。这样,在 MinIO 中创建加密租户和存储桶时,将自动为您生成新密钥。
有多个选项可以复制对象:批量复制和 mc mirror 。我之前的博客文章《如何从 AWS S3 遣返到 MinIO》包含了这两种方法的详细说明。您可以将对象直接从 S3 复制到本地 MinIO,或使用在 EC2 上运行的临时 MinIO 集群查询 S3,然后镜像到本地 MinIO。
通常,客户将我们编写的工具与 AWS Snowball 或 TD SYNNEX 的数据迁移硬件和服务结合使用,以移动大量数据(超过 1 PB)。
MinIO 最近与 Western Digital 和 TD SYNNEX 合作推出了 Snowball 替代方案。客户可以安排窗口来接收 Western Digital 硬件,并在租赁期间支付他们需要的费用。更重要的是,该服务不依赖于特定的云,这意味着企业可以使用该服务将数据移入、移出云和跨云移动数据,所有这些都使用无处不在的 S3 协议。有关该服务的其他详细信息,请访问TD SYNNEX网站的“数据迁移服务”页面。
可以使用 get-bucket S3 API 调用读取存储桶元数据(包括策略和存储桶属性),然后在 MinIO 中进行设置。当您注册 MinIO SUBNET 时,我们的工程师将与您一起从 AWS S3 迁移以下设置:基于访问密钥/私有密钥的访问管理、生命周期管理策略、加密、匿名公有访问、不可变性和版本控制。关于版本控制的一点是,迁移数据时通常不会保留 AWS 版本 ID,因为每个版本 ID 都是一个内部 UUID。这对客户来说很大程度上不是问题,因为对象通常是按名称调用的。但是,如果需要 AWS 版本 ID,那么我们有一个扩展程序可以将其保留在 MinIO 中,并帮助您启用它。
请特别注意 IAM 和存储桶策略。S3 不会是 AWS 基础设施中唯一被您抛弃的部分。在访问 S3 存储桶时,您将拥有大量服务账户供应用程序使用。这将是列出和审核所有服务帐户的好时机。然后,您可以决定是否在标识提供者中重新创建它们。如果您选择自动化,则使用 Amazon Cognito 与外部 OpenID Connect IDP 和 AD/LDAP 共享 IAM 信息。
特别注意数据生命周期管理,例如对象保留、对象锁定和归档/分层。在每个存储桶上运行一个 get-bucket-lifecycle-configuration 以获取人类可读的生命周期规则 JSON 列表。您可以使用 MinIO 控制台或 MinIO 客户端 (mc) 轻松重新创建 AWS S3 设置。使用 和 get-object-legal-hold get-object-lock-configuration 等命令来查明需要特殊安全和治理处理的对象。
当我们讨论生命周期时,让我们先谈谈备份和灾难恢复。是否希望复制到其他 MinIO 集群以进行备份和灾难恢复?
将对象从 AWS S3 复制到 MinIO 后,验证数据完整性非常重要。执行此操作的最简单方法是使用 MinIO 客户端对 S3 中的旧存储桶和 MinIO 上的新存储桶运行 mc diff 。这将计算存储桶之间的差异,并仅返回缺少或不同的对象的列表。此命令采用源存储桶和目标存储桶的参数。为方便起见,您可能希望为 S3 和 MinIO 创建别名,这样您就不必不断键入完整的地址和凭证。例如:
mc diff s3/bucket1 minio/bucket1 好消息是,您所要做的就是将现有应用程序指向新的 MinIO 端点。可以在一段时间内逐个应用重写配置。在对象存储中迁移数据比文件系统对数据的干扰要小,只需将 URL 更改为从新集群读/写即可。请注意,如果您以前依赖 AWS 服务来支持您的应用程序,那么这些服务将不会出现在您的数据中心中,因此您必须将它们替换为它们的开源等效项并重写一些代码。例如,Athena 可以替换为 Spark SQL、Apache Hive 和 Presto、Kinesis 和 Apache Kafka 以及 AWS Glue 和 Apache Airflow。
如果您的 S3 迁移是将整个应用程序移动到本地的更大工作的一部分,那么您很可能使用 S3 事件通知在新数据到达时调用下游服务。如果是这种情况,请不要害怕 - MinIO 也支持事件通知。此处最直接的迁移是实现自定义 Webhook 来接收通知。但是,如果您需要更持久和更具弹性的目标,请使用 Kafka 或 RabbitMQ 等消息传递服务。我们还支持将事件发送到 PostgreSQL 和 MySQL 等数据库。
现在您已经完成了遣返,是时候将注意力转向存储操作、监控和优化了。好消息是,MinIO 不需要优化——我们已经在软件中内置了优化功能,因此您知道您的硬件获得了最佳性能。您需要开始监视新的 MinIO 集群,以持续评估资源利用率和性能。MinIO 通过 Prometheus 端点公开指标,您可以在选择的监控和警报平台中使用该端点。有关监控的更多信息,请参阅使用 Prometheus 和 Grafana 进行多云监控和警报,以及使用 OpenTelemetry、Flask 和 Prometheus 使用 MinIO 的指标。
总结
向云提供商开空白支票的日子已经一去不复返了,这已不是什么秘密。许多企业目前正在评估他们的云支出,以寻找潜在的节省。现在,您拥有开始从 AWS S3 迁移到 MinIO 所需的一切,包括具体的技术步骤和财务框架。
相关文章:
从公有云对象存储迁移到回私有化 MinIO需要了解的所有信息
我们上一篇文章《如何从 AWS S3 遣返到 MinIO》的反响非常出色 - 我们已经接到了数十个企业的电话,要求我们提供遣返建议。我们已将这些回复汇总到这篇新文章中,其中我们更深入地研究了与遣返相关的成本和节省,以便您更轻松地进行自己的分析。…...
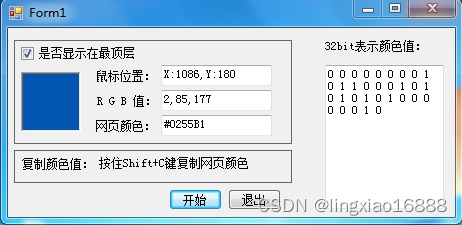
C#颜色拾取器
1,目的: 获取屏幕上任意位置像素的色值。 2,知识点: 热键的注册与注销。 /// <summary>/// 热键注册/// </summary>/// <param name"hWnd">要定义热键的窗口的句柄 </param>/// <param name"id…...
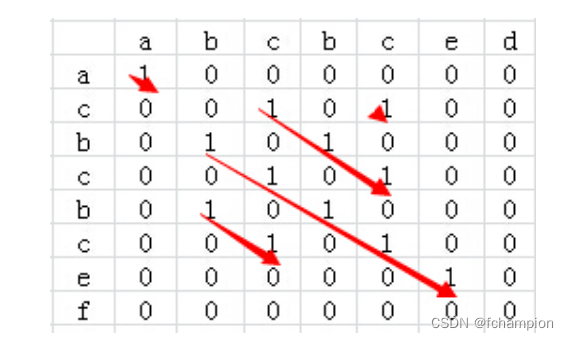
最长公共子串的问题(正常方法和矩阵法,动态规划)
题目: 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符…...
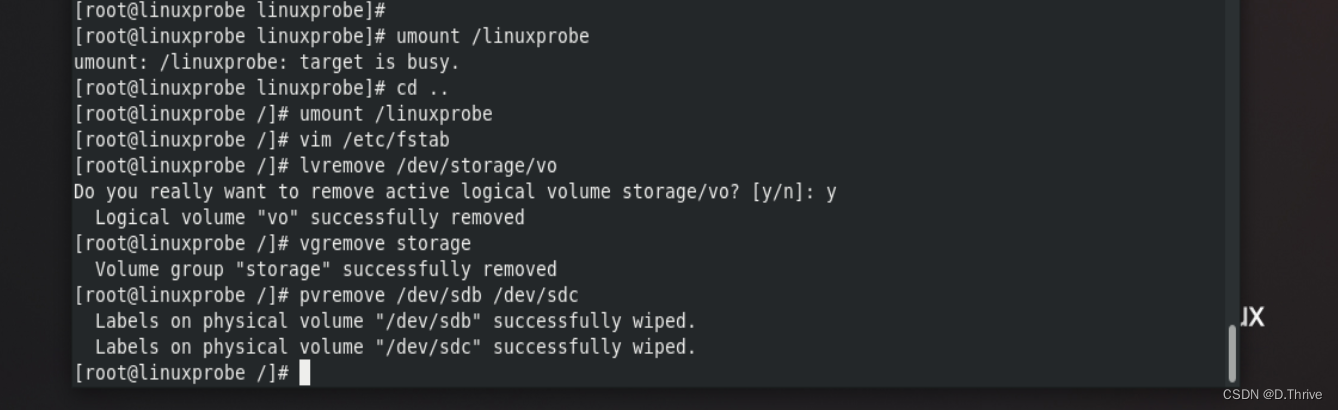
Linux实验记录:使用LVM(逻辑卷管理器)
前言: 本文是一篇关于Linux系统初学者的实验记录。 参考书籍:《Linux就该这么学》 实验环境: VmwareWorkStation 17——虚拟机软件 RedHatEnterpriseLinux[RHEL]8——红帽操作系统 备注: 硬盘分好区或者部署为RAID磁盘阵列…...
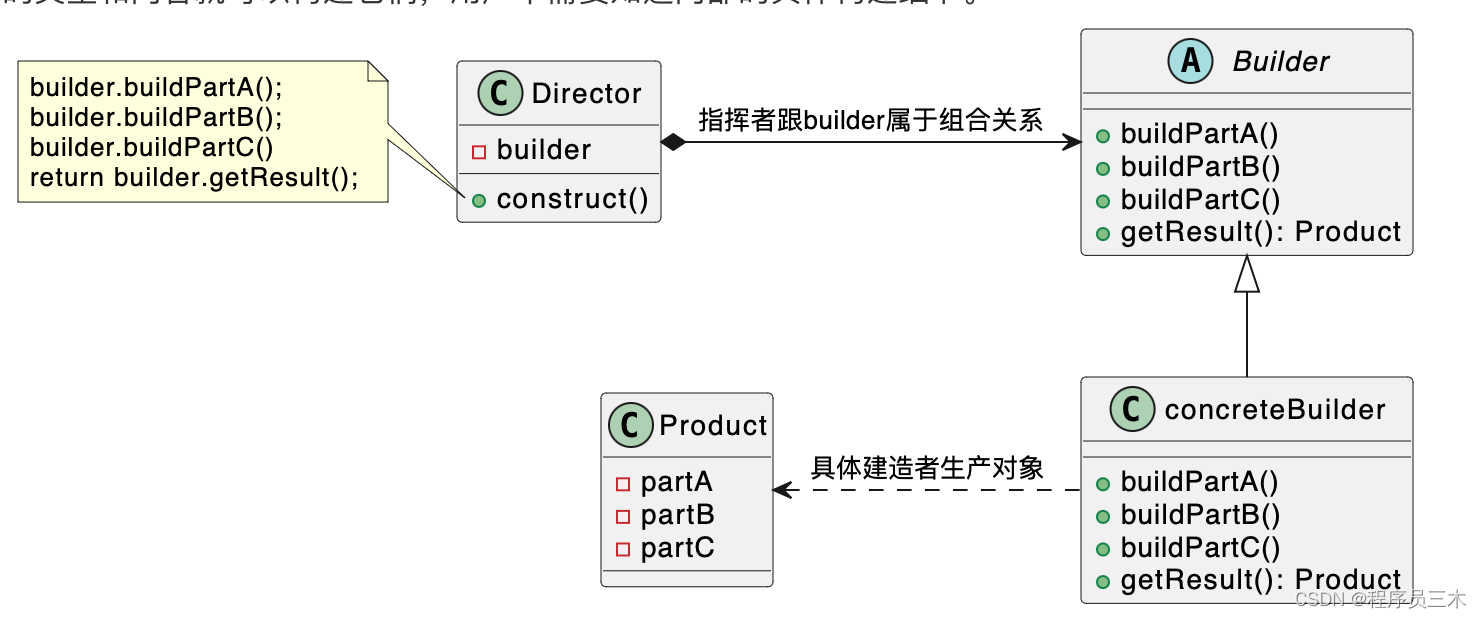
[设计模式Java实现附plantuml源码~创建型] 复杂对象的组装与创建——建造者模式
前言: 为什么之前写过Golang 版的设计模式,还在重新写Java 版? 答:因为对于我而言,当然也希望对正在学习的大伙有帮助。Java作为一门纯面向对象的语言,更适合用于学习设计模式。 为什么类图要附上uml 因为很…...

【国产MCU】-认识CH32V307及开发环境搭建
认识CH32V307及开发环境搭建 文章目录 认识CH32V307及开发环境搭建1、CH32V307介绍2、开发环境搭建3、程序固件下载1、CH32V307介绍 CH32V307是沁恒推出的一款基于32位RISC-V设计的互联型微控制器,配备了硬件堆栈区、快速中断入口,在标准RISC-V基础上大大提高了中断响应速度…...

python flask request教程
request 一、传json1、resquest.get_data()与resquest.data2、request.get_json()3、request.json["imageURL"]二、传file1、request.files["file"]2、request.form["username"]3、request.form.get(username)与2等价,其他get()与[]也相同三、其…...

UE5 Chaos系统 学习笔记
记得开插件: 1、锚点场(构造场) 在锚点场范围内的物体静止且不被其他力场损坏 需要在Geometry Collection的初始化场把构造场设置过去 2、ClusterStrain 破裂效果的力 3、DisableField chaos破裂后的模拟物理在绿色范围内禁止行为和模拟物…...

MkDocs 部署指南
简介 MkDocs 可以同时编译多个 markdown 文件,形成书籍一样的文件。有多种主题供你选择,很适合项目使用。 MkDocs 是快速,简单和华丽的静态网站生成器,可以构建项目文档。文档源文件在 Markdown 编写,使用单个 YAML …...

【Java 设计模式】行为型之访问者模式
文章目录 1. 定义2. 应用场景3. 代码实现结语 访问者模式(Visitor Pattern)是一种行为型设计模式,用于在不改变被访问元素的类的前提下定义对这些元素的新操作。访问者模式将数据结构与作用于结构上的操作解耦,使得操作集合可以灵…...
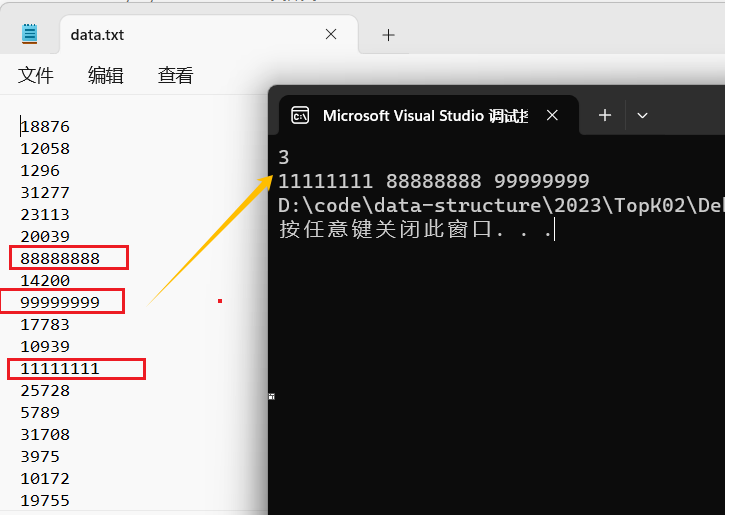
堆和堆排序【数据结构】
目录 一、堆1. 堆的存储定义2. 初始化堆3. 销毁堆4. 堆的插入向上调整算法 5. 堆的删除向下调整算法 6. 获取堆顶数据7. 获取堆的数据个数8. 堆的判空 二、Gif演示三、 堆排序1. 堆排序(1) 建大堆(2) 排序 2.Topk问题 四、完整代码1.堆的代码Heap.cHeap.htest.c 2. 堆排序的代码…...
【全程录屏GPT3.5升级4.0】2024最新GPT4升级订阅详细指南
前言:为什么要升级GPT4.0,下图是来自GPT4.0的官方回答,可以看出,GPT4无愧于是一个大版本升级的。 一、视频教程 记录了普通用户使用WildCrad从GPT3.5升级到4.0的全部过程,感兴趣可以前往观看:https://www.…...
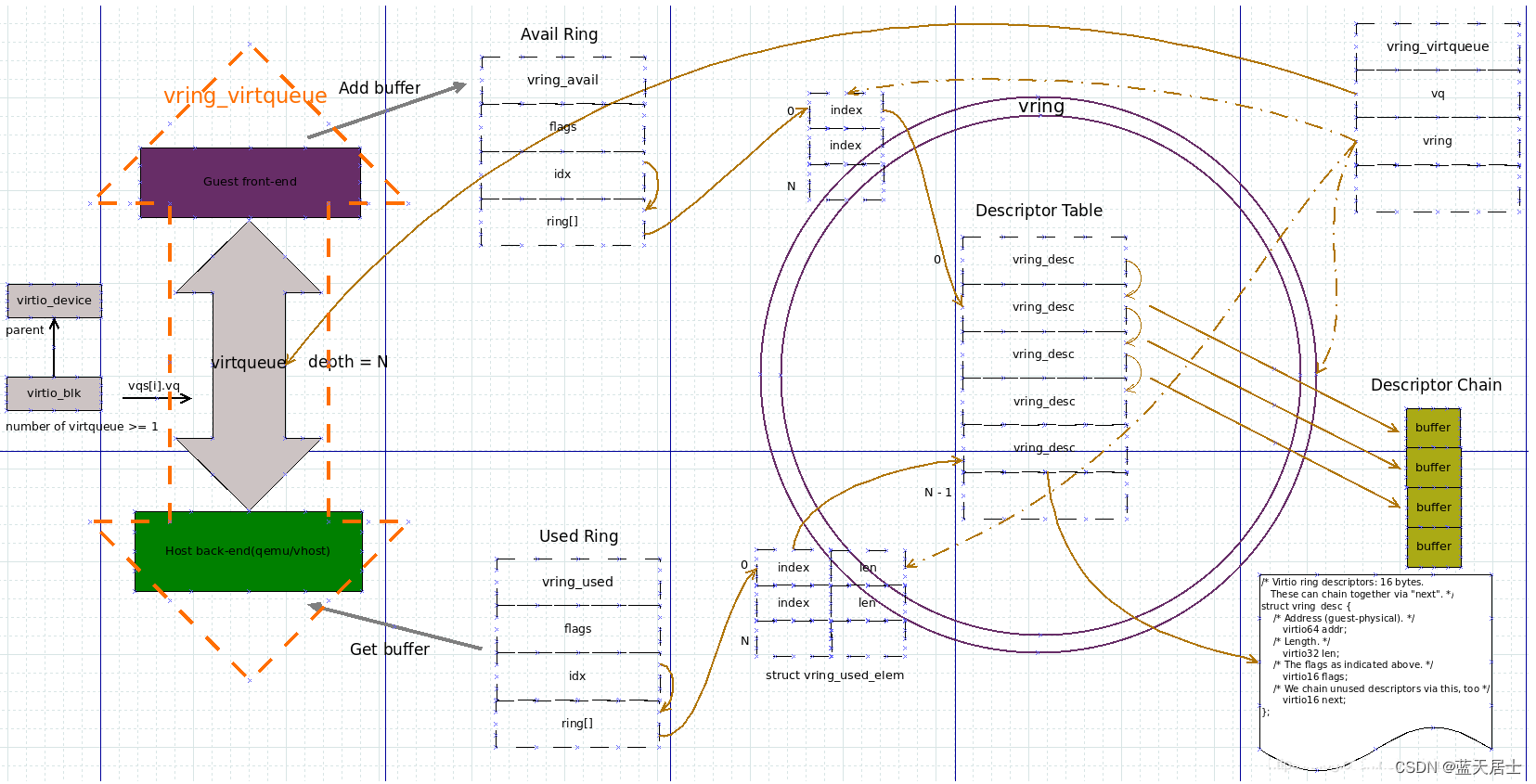
中移(苏州)软件技术有限公司面试问题与解答(4)—— virtio所创建的设备1
接前一篇文章:中移(苏州)软件技术有限公司面试问题与解答(0)—— 面试感悟与问题记录 本文参考以下文章: VirtIO实现原理——PCI基础 VirtIO实现原理——virtblk设备初始化 特此致谢! 本文对…...
》笔记5)
《动手学深度学习(PyTorch版)》笔记5
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过,…...

QT中wchar_t类型如何输出
在Qt中,通常使用QString来处理字符串,而不是wchar_t。QString是Qt中用于处理Unicode字符串的类。如果你有wchar_t类型的字符串,你可以将其转换为QString进行输出。 以下是一个简单的例子: #include <QCoreApplication> #i…...
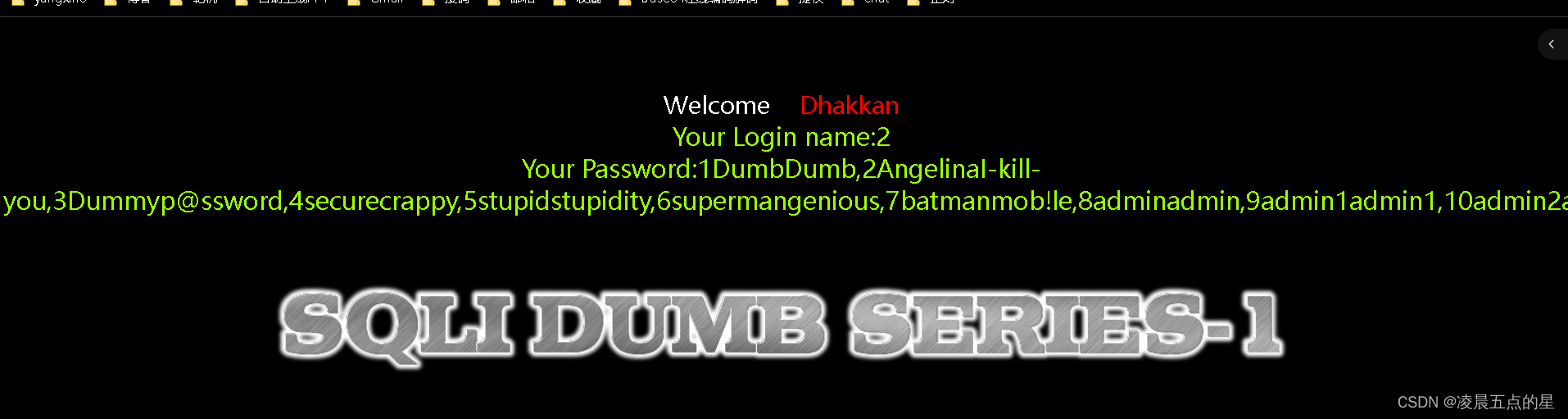
网络安全04-sql注入靶场第一关
目录 一、环境准备 1.1我们进入第一关也如图: 编辑 二、正式开始第一关讲述 2.1很明显它让我们在标签上输入一个ID,那我们就输入在链接后面加?id1 编辑 2.2链接后面加个单引号()查看返回的内容,127.0.0.1/sqli/less-1/?id1,id1 …...
微服务理解篇
一 :架构演变 1 单体架构: 简单理解为一个服务涵盖所有需求功能2 垂直架构: 按照业务功能将单体架构拆分成小模块服务, 如:订单系统,用户系统,商品系统 ##缺点 引入分布式事务,分布式锁等,优点:模块解耦## 垂直拆分:根据业务层级拆分,比如商城的订单系统,用户系统,商品系统…...

项目篇:基于TCP通信模型的外卖软件实现
一、基本成员及功能实现 本项目主要由服务器,消费者,商家,外卖员组成。基本的功能如下。 对所有人: 1、可以注册登录 2、可以修改个人信息 3、可以销户 商家: 1、注册时需要填写售卖商品信息 2、可以修改商品信…...

深入浅出 diffusion(2):pytorch 实现 diffusion 加噪过程
我在上篇博客深入浅出 diffusion(1):白话 diffusion 原理(无公式)中介绍了 diffusion 的一些基本原理,其中谈到了 diffusion 的加噪过程,本文用pytorch 实现下到底是怎么加噪的。 import torch…...
【软件测试】学习笔记-构建并执行 JMeter 脚本的正确姿势
有些团队在组建之初往往并没有配置性能测试人员,后来随着公司业务体量的上升,开始有了性能测试的需求,很多公司为了节约成本会在业务测试团队里选一些技术能力不错的同学进行性能测试,但这些同学也是摸着石头过河。他们会去网上寻…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...