python字典和集合——笔记
一、介绍
1、泛映射类型
collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为dict和其他类似的类型定义形式接口(在Python 2.6到Python 3.2的版本中,这些类还不属于collections.abc模块,而是隶属于collections模块)。

然而,非抽象映射类型一般不会直接继承这些抽象基类,它们会直接对dict或是collections.UserDict进行扩展。
这些抽象基类的主要作用是作为形式化的文档,它们定义了构建一个映射类型所需要的最基本的接口。然后它们还可以跟isinstance一起被用来判定某个数据是不是广义上的映射类型。
isinstance(my_dict, abc.Mapping)
Out[138]: True
标准库里的所有映射类型都是利用dict来实现的,因此它们有个共同的限制,即只有可散列的数据类型才能用作这些映射里的键。
1.1如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__( )方法。另外可散列对象还要有__eq__( )方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的……
原子不可变数据类型(str、bytes和数值类型)都是可散列类型,frozenset也是可散列的,因为根据其定义,frozenset里只能容纳可散列类型。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
tt=(1,2,[30,40])
t1=(1,2,(30,40))
hash(tt)
TypeError: unhashable type: 'list'
hash(t1)
Out[142]: -3907003130834322577
1.2 创建字典的不同方式
a = dict(one=1, two=2, three=3)
b = {'one':1,'two':2, 'three':3}
c = dict(zip(['one', 'two', 'three'], [1,2,3]))
d = dict([('two', 2), ('one', 1), ('three',3)])
e = dict({'three':3, 'one':1, 'two':2})
a==b==c==d==e
Out[148]: True
2、字典推导
字典推导(dictcomp)可以从任何以键值对作为元素的可迭代对象中构建出字典。下面就展示了利用字典推导可以把一个装满元组的列表变成了字典。
country = ['China', 'Brazil', 'Russia', 'Japan']
country_code={co:len(co) for co in country}
country_code
Out[154]: {'China': 5, 'Brazil': 6, 'Russia': 6, 'Japan': 5}
3、映射类型的常见方法
# 返回国家对应的值,没有的话返回-1
country_code.get('China',-1)
Out[155]: 5
country_code.get('USA',-1)
Out[156]: -1
# 返回country_code中的所有键值对
country_code.items()
Out[157]: dict_items([('China', 5), ('Brazil', 6), ('Russia', 6), ('Japan', 5)])
# 随机返回一个键值对,并从字典中移除它
country_code.popitem()
Out[158]: ('Japan', 5)
country_code
Out[159]: {'China': 5, 'Brazil': 6, 'Russia': 6}
# 返回brazil所对应的值,并删除这个键值对。 如果没有,则返回默认值
country_code.pop('Brazil')
Out[160]: 6
country_code.pop('Brazil',-1)
Out[161]: -1
country_code
Out[162]: {'China': 5, 'Russia': 6}
OrderedDict.popitem()会移除字典里最先插入的元素(先进先出);同时这个方法还有一个可选的last参数,若为真,则会移除最后插入的元素(后进先出)
4、映射的弹性键查询
有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的。
- 一个是通过defaultdict这个类型而不是普通的dict
- 另一个是给自己定义一个dict的子类,然后在子类中实现__missing__方法。
4.1 defaultdict:处理找不到的键的一个选择
在实例化一个defaultdict的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在__getitem__碰到找不到的键的时候被调用,让__getitem__返回某种默认值。
比如,我们新建了这样一个字典:dd=defaultdict(list),如果键’new-key’在dd中还不存在的话,表达式dd[‘new-key’]会按照以下的步骤来行事。
(1)调用list( )来建立一个新列表。
(2)把这个新列表作为值,'new-key’作为它的键,放到dd中。
(3)返回这个列表的引用。
而这个用来生成默认值的可调用对象存放在名为default_factory的实例属性里。
import collections
names = collections.defaultdict(list)
names['1班'].append('李明')
names
Out[166]: defaultdict(list, {'1班': ['李明']})names.get('2班').append('李明')
Traceback (most recent call last):
AttributeError: 'NoneType' object has no attribute 'append'
defaultdict里的default_factory只会在__getitem__里被调用,在其他的方法里完全不会发挥作用。比如,dd是个defaultdict,k是个找不到的键, dd[k]这个表达式会调用default_factory创造某个默认值,而dd.get(k)则会返回None。
所有这一切背后的功臣其实是特殊方法__missing__。它会在defaultdict遇到找不到的键的时候调用default_factory,而实际上这个特性是所有映射类型都可以选择去支持的
4.2 特殊方法__missing__
所有的映射类型在处理找不到的键的时候,都会牵扯到__missing__方法。这也是这个方法称作“missing”的原因。虽然基类dict并没有定义这个方法,但是dict是知道有这么个东西存在的。也就是说,如果有一个类继承了dict,然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,Python就会自动调用它,而不是抛出一个KeyError异常。
missing__方法只会被__getitem__调用(比如在表达式d[k]中)。提供__missing__方法对get或者__contains_(in运算符会用到这个方法)这些方法的使用没有影响。这也是我在上一节最后的警告中提到,defaultdict中的default_factory只对__getitem__有作用的原因。
示例 StrKeyDict0在查询的时候把非字符串的键转换为字符串
class StrKeyDict0(dict):def __missing__(self, key):if isinstance(key, str):raise KeyError(key)return self[str(key)]def get(self, key, default=None):try:return self[key]except KeyError:return default
d = StrKeyDict0([('2', 'two'),('4', 'four')])
d['2']
Out[170]: 'two'
d[4]
Out[171]: 'four'
d[1]
Traceback (most recent call last):
KeyError: '1'
d.get('2')
Out[173]: 'two'
d.get(4)
Out[174]: 'four'
d.get(1, 'N/A')
Out[175]: 'N/A'5、字典的变种
这一节总结了标准库里collections模块中,除了defaultdict之外的不同映射类型。
5.1 collections.OrderedDict:这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict的popitem方法默认删除并返回的是字典里的最后一个元素,但是如果像my_odict.popitem(last=False)这样调用它,那么它删除并返回第一个被添加进去的元素。
5.2 collections.ChainMap:该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。在collections文档介绍ChainMap对象的那一部分里有一些具体的使用示例,其中包含了下面这个Python变量查询规则的代码片段:
import collections
chain_map = collections.ChainMap({'a':1, 'b':2},{'c':3},{'d':4})
all_dict = dict(chain_map)
all_dict
Out[5]: {'d': 4, 'c': 3, 'a': 1, 'b': 2}
5.3 Counter:这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。Counter实现了+和-运算符用来合并记录,还有像most_common([n])这类很有用的方法。
ct = collections.Counter('ababdadfawwwwweijisafl')
ct
Out[7]: Counter({'a': 5, 'b': 2,'d': 2,'f': 2,'w': 5,'e': 1, 'i': 2,'j': 1,'s': 1, 'l': 1})
ct.update('ddddddeeeeeee')
ct
Out[9]: Counter({'a': 5, 'b': 2, 'd': 8, 'f': 2, 'w': 5,'e': 8,'i': 2,'j': 1,'s': 1,'l': 1})
ct.most_common(3)
Out[10]: [('d', 8), ('e', 8), ('a', 5)]
5.4 collections.UserDict:就创造自定义映射类型来说,以UserDict为基类,总比以普通的dict为基类要来得方便。
import collections
class StrKeyDict(collections.UserDict):def __missing__(self, key):if isinstance(key,str):raise KeyError(key)return self[str(key)]def __contains__(self, key):return str(key) in self.datadef __setitem__(self, key, item):self.data[str(key)] = item
因为UserDict继承的是MutableMapping,所以StrKeyDict里剩下的那些映射类型的方法都是从UserDict、MutableMapping和Mapping这些超类继承而来的。特别是最后的Mapping类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。以下两个方法值得关注。
- MutableMapping.update:这个方法不但可以为我们所直接利用,它还用在__init__里,让构造方法可以利用传入的各种参数(其他映射类型、元素是(key, value)对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用self[key]=value来添加新值的,所以它其实是在使用我们的__setitem__方法。
- Mapping.get:在StrKeyDict0中,我们不得不改写get方法,好让它的表现跟__getitem__一致。而在示例3-8中就没这个必要了,因为它继承了Mapping.get方法,
6、不可变映射类型
标准库里所有的映射类型都是可变的,但有时候你会有这样的需求,比如不能让用户错误地修改某个映射。从Python 3.3开始,types模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
from types import MappingProxyType
d = {1:'A'}
d_proxy = MappingProxyType(d)
d_proxy
Out[12]: mappingproxy({1: 'A'})
d_proxy[1]
Out[13]: 'A'
d_proxy[2] = 'b'
Traceback (most recent call last):
TypeError: 'mappingproxy' object does not support item assignment
d[2] = 'c'
d_proxy
Out[16]: mappingproxy({1: 'A', 2: 'c'})
7、集合论
集合的本质是许多唯一对象的聚集。因此,集合可以用于去重
l = ['spam', 'spam', 'eggs', 'spam']
set(l)
Out[18]: {'eggs', 'spam'}
list(set(l))
Out[19]: ['spam', 'eggs']
除了保证唯一性,集合还实现了很多基础的中缀运算符。给定两个集合a和b,a | b返回的是它们的合集,a & b得到的是交集,而a-b得到的是差集。
7.1 集合字面量
除空集之外,集合的字面量——{1}、{1, 2},等等——看起来跟它的数学形式一模一样。如果是空集,那么必须写成set( )的形式。
7.2 集合操作
集合的数学运算:这些方法或者会生成新集合,或者会在条件允许的情况下就地修改集合。
# 定义集合
a = {1, 2, 3, 4, 5, 6}
b = {4,5,6,7,8,9,20}
# 求交集操作
a.__and__(b)
Out[25]: {4, 5, 6}
a&b
Out[26]: {4, 5, 6}
# 把a更新为a与b的交集
a.__iand__(b)
Out[28]: {4, 5, 6}
a
Out[29]: {4, 5, 6}
a &= b
Out[30]: {4, 5, 6}
# a和b的并集
a|b
Out[30]: {4, 5, 6, 7, 8, 9, 20}
a.__or__(b)
Out[32]: {4, 5, 6, 7, 8, 9, 20}
# 把a更新为a和b的并集
a.__ior__(b)
Out[33]: {4, 5, 6, 7, 8, 9, 20}
a
Out[34]: {4, 5, 6, 7, 8, 9, 20}
# 求a和b的差集
a -b
Out[37]: set()
a.__sub__(b)
Out[38]: set()
# 把a更新为a和b的差集
a -= b
a
Out[40]: set()
8、set和dict的背后
8.1 字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。
因为Python会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python中可以用hash( )方法来做这件事情,接下来会介绍这一点。
- 内置的hash( )方法可以用于所有的内置类型对象。如果是自定义对象调用hash( )的话,实际上运行的是自定义的__hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果1==1.0为真,那么hash(1)==hash(1.0)也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的。
- 如果search_key和found_key不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。[插图]若这次找到的表元是空的,则同样抛出KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。
8.2 dict的实现及其导致的结果
8.2.1 下面的内容会讨论使用散列表给dict带来的优势和限制都有哪些。 - 键必须是可散列的: 一个可散列的对象必须满足以下要求。(1)支持hash( )函数,并且通过__hash__( )方法所得到的散列值是不变的。(2)支持通过__eq__( )方法来检测相等性。(3)若a==b为真,则hash(a)hash(b)也为真。所有由用户自定义的对象默认都是可散列的,因为它们的散列值由id( )来获取,而且它们都是不相等的。
**如果你实现了一个类的__eq__方法,并且希望它是可散列的,那么它一定要有个恰当的__hash__方法,保证在ab为真的情况下hash(a)==hash(b)也必定为真。否则就会破坏恒定的散列表算法,导致由这些对象所组成的字典和集合完全失去可靠性,这个后果是非常可怕的。另一方面,如果一个含有自定义的__eq__依赖的类处于可变的状态,那就不要在这个类中实现__hash__方法,因为它的实例是不可散列的** - 字典在内存上的开销巨大:由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
- 键查询很快:dict的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。
- 键的次序取决于添加顺序:当往dict里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由dict([(key1, value1), (key2,value2)])和dict([(key2,value2), (key1, value1)])得到的两个字典,在进行比较的时候,它们是相等的;但是如果在key1和key2被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的。
8.3 set的实现以及导致的结果
set和frozenset的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。在set加入到Python之前,我们都是把字典加上无意义的值当作集合来用的。 - 集合里的元素必须是可散列的
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里已有元素的次序。
相关文章:
python字典和集合——笔记
一、介绍 1、泛映射类型 collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为dict和其他类似的类型定义形式接口(在Python 2.6到Python 3.2的版本中,这些类还不属于collections.abc模块,而是隶属于coll…...

TEX:显示文本
文章目录字体选择字体fontspec宏包根据字体形状控制字体为不同的字体形状选择不同的特征为不同的字体大小状选择不同的特征中文字体选择xeCJK宏包字体选择与设置XELATEX字体名查找字体集与符号居中与缩进居中单边调整两边缩进诗歌缩进列表itemize样例enumerate样例description样…...

SS-ELM-AE与S2-BLS相关论文阅读记录
Broad learning system for semi-supervised learning 摘要:本文认为,原始BLS采用的稀疏自编码器来生成特征节点是一种无监督学习方法,这意味着忽略了标注数据的一些信息,并且难以保证同类样本之间的相似性和相邻性,同…...

ESP32设备驱动-MAX6675冷端补偿K热电偶数字转换器
MAX6675冷端补偿K热电偶数字转换器 1、MAX6675介绍 MAX6675执行冷端补偿并将来自K型热电偶的信号数字化。 数据以 12 位分辨率、SPI™ 兼容的只读格式输出。 该转换器可将温度解析为 0.25C,读数高达 +1024C,并且在 0C 至 +700C 的温度范围内具有 8 LSB 的热电偶精度。 MAX…...
)
Python基础知识汇总(字符串四)
目录 字母的大小写转换 lower()方法 upper()方法 删除字符串中的空格和特殊字符 strip()方法...

C语言学习笔记——指针(初阶)
前言 指针可以说是C语言基础语法中最难的理解的知识之一,很多新手(包括我)刚接触指针时都觉得很难。在我之前发布的笔记中都穿插运用了指针,但是我一直没有专门出一期指针的笔记,这是因为我确实还有些细节至今还不太清…...

阿赵的MaxScript学习笔记分享十二《获取和导出各种数据》
大家好,我是阿赵,周日的早上继续分享MaxScript学习笔记,这是第十二篇,获取和导出各种数据 1、导出数据的目的 使用3DsMax建立3D模型后,很多时候需要输出模型到别的引擎去使用,常用的格式有Obj、FBX、SLT等…...

react-draggable实现拖拽详解
react-draggable属性常用属性属性列表事件列表举例首先安装 react-draggable实现移动希望小编写的能够帮助到你😘属性 常用属性 属性默认值介绍axisxhandle拖动的方向,可选值 x ,y,bothhandle无指定拖动handle的classposition无handle的位置࿰…...

01.进程和线程的区别
进程和线程的区别进程和线程是计算机中的两个核心概念,它们都是用来实现并发执行的方式,但是它们在实现并发的方式和资源管理方面有一些重要的区别。进程是一个程序的运行实例。每个进程都有自己的内存空间、代码、数据和系统资源(如文件描述…...

逻辑优化-rewrite
简介 逻辑综合中的rewrite算法是一种常见的优化算法,其主要作用是通过对逻辑电路的布尔函数进行等效变换,从而达到优化电路面积、时序和功耗等目的。本文将对rewrite算法进行详细介绍,并附带Verilog代码示例。 一、算法原理 rewrite算法的…...
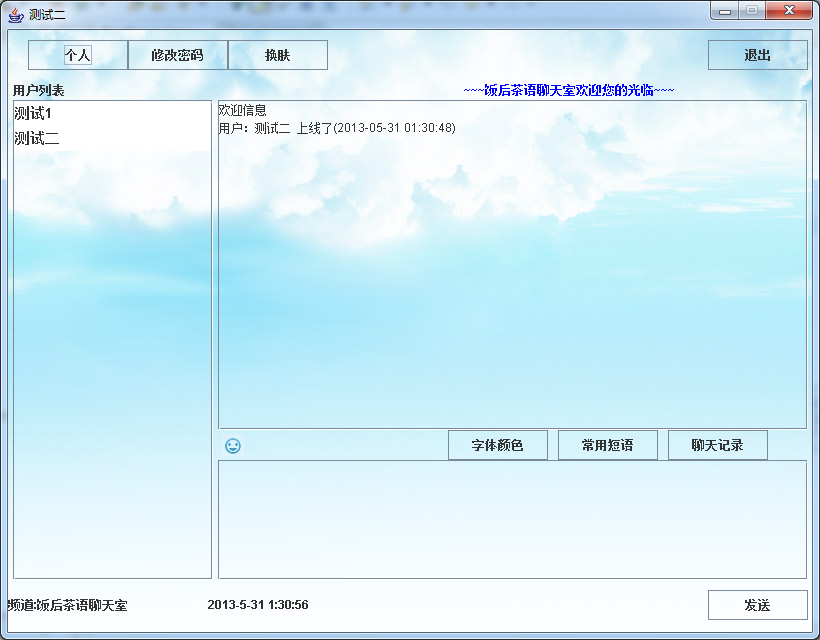
文件传输与聊天系统设计
技术:Java等摘要:本文介绍了一种基于TCP/IP协议使用Socket技术实现的聊天室系统,包括私聊功能和文件传输功能,对系统的主要模块进行了分析,并对系统实现过程中遇到的关键性技术进行了阐述,最后对系统进行了…...
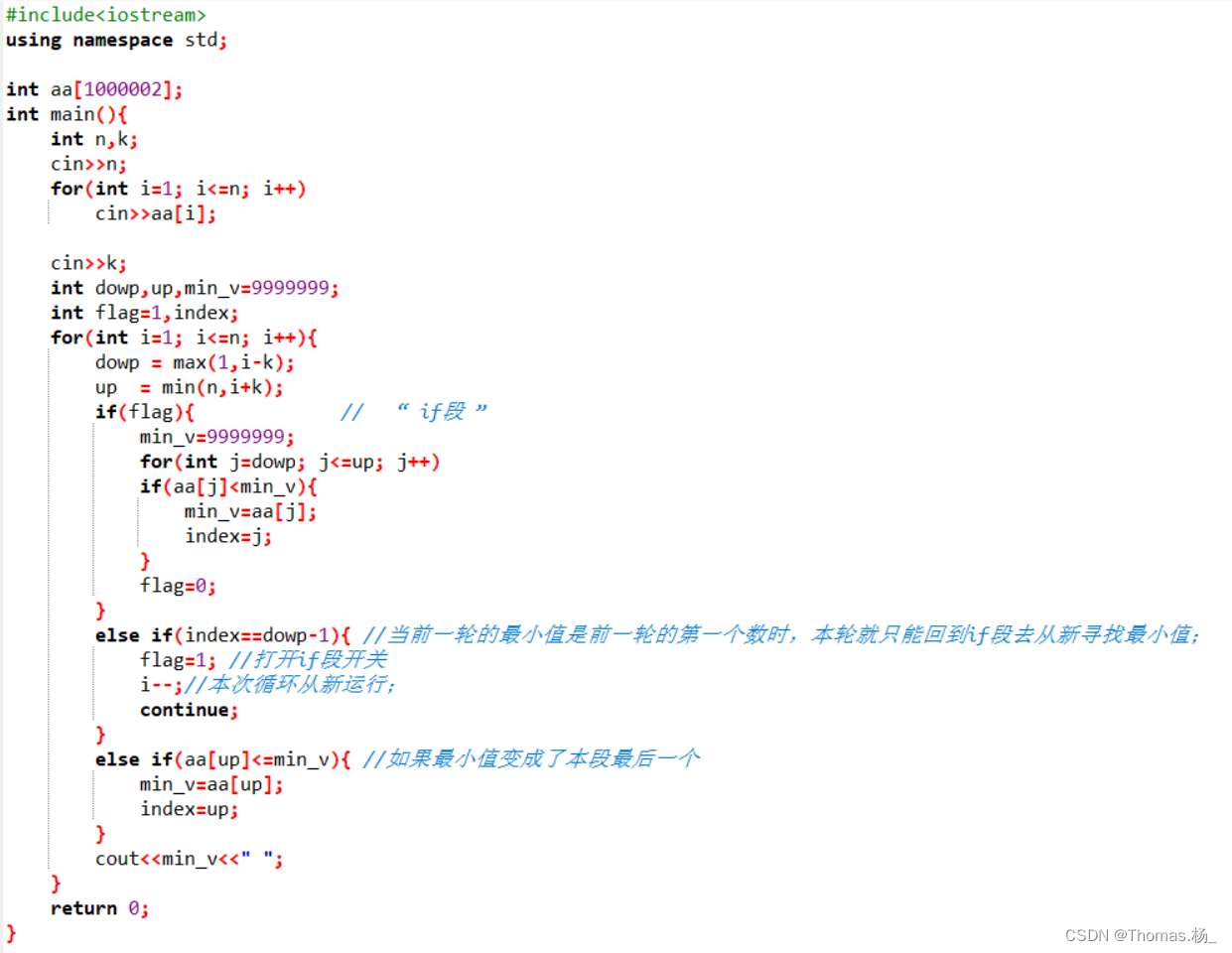
蓝桥杯第十四届校内赛(第三期) C/C++ B组
一、填空题 (一)最小的十六进制 问题描述 请找到一个大于 2022 的最小数,这个数转换成十六进制之后,所有的数位(不含前导 0)都为字母(A 到 F)。 请将这个数的十进制形式作…...

有关平方或高次方的公式整理一元高次方程的求解
Part.I Introduction 这篇博文记录一下数学中常用的有关平方或高次方的一些公式。 Chap.I 一些结论 下面一部分汇总了一些重要的结论 完全平方公式:(ab)2a22abb2(ab)^2a^22abb^2(ab)2a22abb2平方差公式:a2−b2(ab)(a−b)a^2-b^2(ab)(a-b)a2−b2(ab)(…...

Java笔记3
ArrayListArrayList<String> list new Arraylist<>();<>是泛型表示存放的数据类型,注意不能是基本数据类型;增删改查增:add 返回值为true删:remove 1.直接删元素2.根据索引删元素改:set(…...

Leetcode.2202 K 次操作后最大化顶端元素
题目链接 Leetcode.2202 K 次操作后最大化顶端元素 Rating : 1717 题目描述 给你一个下标从 0开始的整数数组 nums,它表示一个 栈 ,其中 nums[0]是栈顶的元素。 每一次操作中,你可以执行以下操作 之一 : 如果栈非空…...

JAVA知识点全面总结3:String类的学习
三.String类学习 1.String,StringBuffer,StringBuilder的区别? 2.字符串拼接用加号的原理 ? 3.字符串常量池如何理解? 4.String的intern方法理解? 5.String的equals方法和compareTo方法的使用…...
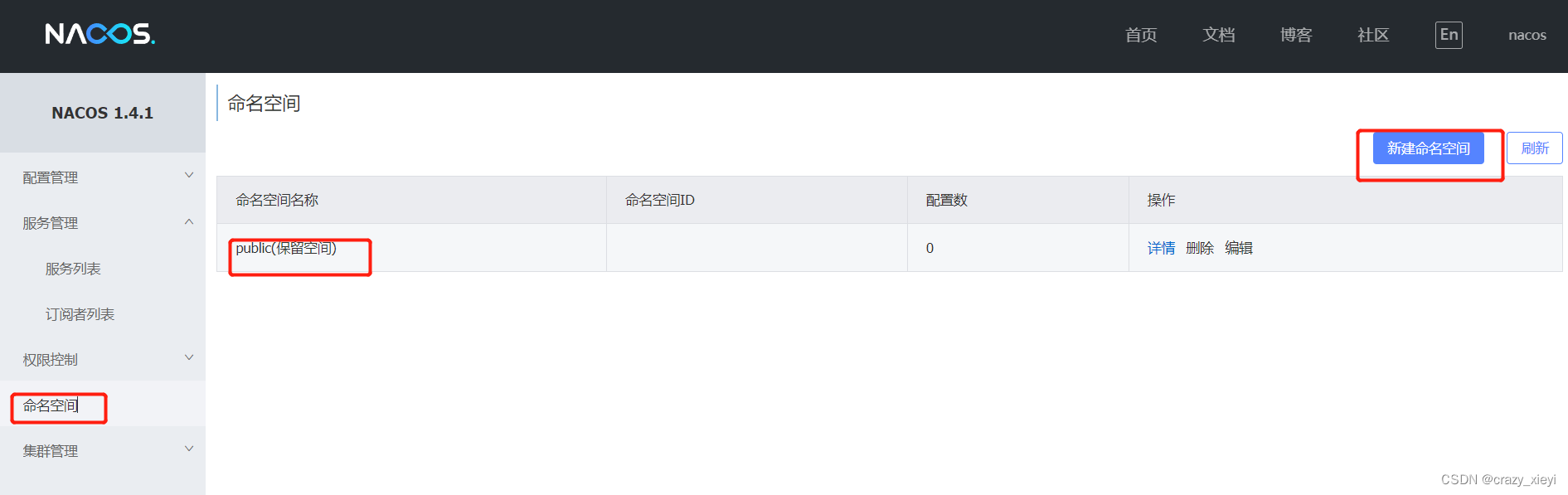
Eureka注册中心和Nacos注册中心详解以及Nacos与Eureka有什么区别?
目录:前言Eureka注册中心Nacos注册中心Nacos与Eureka有什么区别?前言提供接口给其它微服务调用的微服务叫做服务提供者,而调用其它微服务提供的接口的微服务则是服务消费者。如果服务A调用了服务B,而服务B又调用了服务C࿰…...

Web3D发展趋势以及Web3D应用场景
1,Web3D发展趋势随着互联网的快速发展,Web3D技术也日渐成熟,未来发展趋势也值得关注。以下是Web3D未来发展趋势的七个方面:可视化和可交互性的增强:Web3D可以为三维数据提供可视化和可交互性的增强,将极大地…...

2023-3-4 刷题情况
按位与为零的三元组 题目描述 给你一个整数数组 nums ,返回其中 按位与三元组 的数目。 按位与三元组 是由下标 (i, j, k) 组成的三元组,并满足下述全部条件: 0 < i < nums.length 0 < j < nums.length 0 < k < nums.l…...
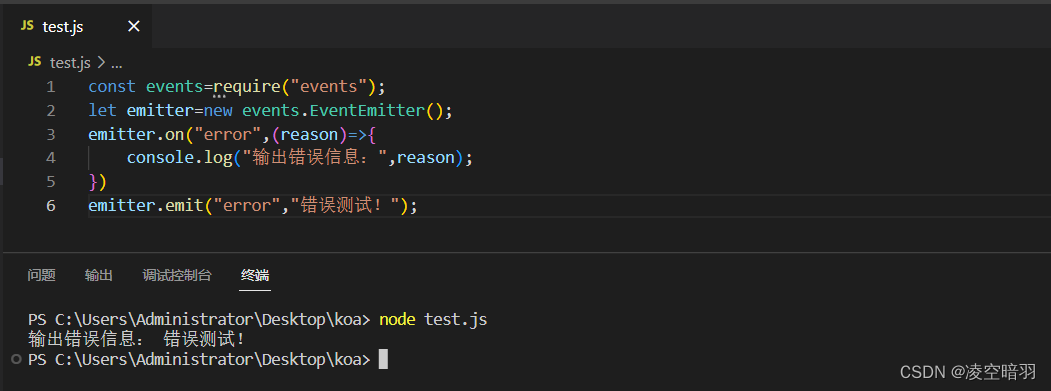
前端面试总结
1.引言 最近参加了大量的招聘会,投递了大量的简历,整整体会了从“随便找个厂上一下”——“还是的找个大厂”——“没人要”——“急了急了,海投一波”——“工资有点尬”——“海投中…”。简单说一下自己的一些感受吧,现在的前端属实有点尴…...

STM32压力传感器统一驱动:BMP280/MS5803/ADS1115/SDP3x
目录 一、4 款传感器 典型应用场景 二、统一软件工程接口(标准 C 语言,可直接用) 1. 通用结构体(所有传感器统一格式) 三、4 款传感器 完整驱动 校准接口 1. BMP280 气压 / 温度 应用:环境气压、高度…...

C语言函数返回值的设计哲学与实践
1. C语言函数返回值的本质与设计哲学在嵌入式开发领域摸爬滚打十几年,我见过太多因为函数返回值设计不当导致的"血案"。记得刚入行时调试一个串口通信模块,就因为误判了第三方库的返回值逻辑,整整浪费了两天时间。C语言的函数返回值…...

AI在测试中的应用:从测试用例生成到缺陷预测
随着软件开发流程向敏捷与DevOps的持续演进,软件测试面临着迭代周期缩短、系统复杂度飙升的双重压力。传统的测试方法,高度依赖人工经验与重复劳动,在效率、覆盖率和预测性上逐渐显现瓶颈。人工智能技术的引入,正从辅助工具演变为…...

STM32除零运算不崩溃的机制与配置解析
1. STM32单片机除零运算不崩溃的底层机制解析 在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源而广受欢迎。许多从传统PC平台转向嵌入式开发的工程师都会发现一个有趣的现象:在STM32上执行除零操作时,程序竟然不会像在PC上那…...

光流法在气象雷达中的应用:从原理到外推实践
光流法在气象雷达中的应用:从原理到外推实践 气象雷达作为现代气象监测的核心工具,其回波数据蕴含着丰富的天气系统动态信息。如何从这些看似静态的图像序列中提取运动规律,进而预测未来短时内的天气变化,一直是气象学界和工程界关…...

LCC-LCC无线充电恒流/恒压闭环移相控制仿真 Simulink仿真模型,LCC-LCC谐振...
LCC-LCC无线充电恒流/恒压闭环移相控制仿真 Simulink仿真模型,LCC-LCC谐振补偿拓扑,闭环移相控制 1. 输入直流电压350V,负载为切换电阻,分别为50-60-70Ω,最大功率3.4kW,最大效率为93.6% 2. 闭环PI控制&…...

别再瞎调了!FOC电机控制中,采样电阻选型和PCB布局的5个实战避坑点
FOC电机控制实战指南:采样电阻选型与PCB布局的5个关键避坑点 在无刷电机控制领域,FOC(磁场定向控制)算法凭借其优异的动态性能和效率表现,已成为工业驱动、消费电子和机器人关节的主流方案。然而,许多工程师…...
)
Doris集群部署避坑指南:3FE+3BE配置全流程(含Java环境配置与常见问题解决)
Doris集群部署实战:3FE3BE高可用架构搭建与深度调优 在企业级数据分析场景中,Doris凭借其出色的实时分析性能和高并发处理能力,已成为众多企业的首选OLAP引擎。本文将基于3FE(Frontend)3BE(Backend…...

Visual C++运行库一键修复终极指南:快速解决系统依赖问题
Visual C运行库一键修复终极指南:快速解决系统依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中不可或缺的组件…...

告别照相馆!AI头像生成器教你免费制作高质量职业头像
告别照相馆!AI头像生成器教你免费制作高质量职业头像 1. 为什么选择AI生成职业头像? 在当今数字化求职环境中,一张专业的头像照片已经成为简历不可或缺的部分。传统照相馆拍摄存在三个主要痛点: 成本高昂:专业摄影工…...