飞桨paddlespeech语音唤醒推理C INT8 定点实现
前面的文章(飞桨paddlespeech语音唤醒推理C定点实现)讲了INT16的定点实现。因为目前商用的语音唤醒方案推理几乎都是INT8的定点实现,于是我又做了INT8的定点实现。
实现前做了一番调研。量化主要包括权重值量化和激活值量化。权重值由于较小且均匀,还是用最大值非饱和量化。最大值法已不适合8比特激活值量化,用的话误差会很大,识别率等指标会大幅度的降低。激活值量化好多方案用的是NVIDIA提出的基于KL散度(Kullback-Leibler divergence)的方法。我也用了这个方法做了激活值的量化。这个方法用的是饱和量化。下图给出了最大值非饱和量化和饱和量化的区别。
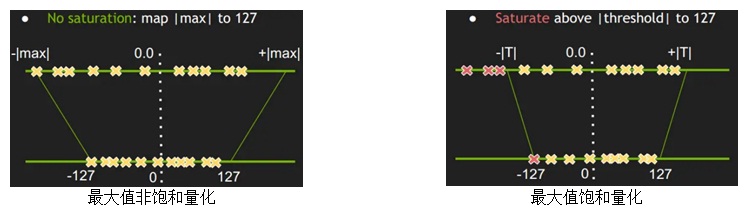
从上图看出,最大值非饱和量化时,把绝对值的最大值|MAX|量化成127,|MAX|/127就是量化scale。激活值的分布范围一般都比较广, 这种情况下如果直接使用最大值非饱和量化, 就会把离散点噪声给放大从而影响模型的精度,最好是找到合适的阈值|T|,将|T|/127作为量化scale,把识别率等指标的降幅控制在一个较小的范围内,这就是饱和量化。KL散度法就是找到这个阈值|T|的一种方法,已广泛应用于8比特量化的激活值量化中。
KL散度又称为相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。 KL散度值越小,代表两种分布越相似,量化误差越小;反之,KL散度值越大,代表两种分布差异越大,量化误差越大。 把KL散度用在激活值的量化上就是来衡量不同的INT8分布与原来的FP32分布之间的差异程度。KL散度的公式如下:
![]()
其中P,Q分别称为实际分布和量化分布, KL散度越小, 说明两个分布越接近。
使用KL散度方法前需要做如下准备工作:
1,从验证集选取一个子集。这个子集应该具有代表性,多样性。
2,把这个子集输入到模型进行前向推理, 并收集模型中各个Layer的激活值。
对于每层激活值,寻找阈值的步骤如下:
1, 用直方图将激活值分成N个bin(NVIDIA用的是2048), 每个bin内的值表示在此bin内激活值的个数,从而得到参考样本。
2, 不断地截断参考样本,长度从128开始到N, 截断区外的值加到截断样本的最后一个值之上,从而得到分布P。求得分布P的概率分布。
3, 创建分布Q,其元素的值为截断样本P的int8量化值, 将Q样本长度拓展到和原样本P具有相同长度。求得Q的概率分布 并计算P、Q的KL散度值。
4, 循环步骤2和3, 就能不断地构造P和Q并计算相对熵,最后找到最小(截断长度为M)的相对熵,阈值|T|就等于(M + 0.5)*一个bin的长度。|T|/127就是量化scale,根据这个量化scale得到激活值的量化值。
实现前读了腾讯ncnn的INT8定点实现,看有什么可借鉴的。 发现它不是一个纯定点的实现,即里面有部分是float的,当时觉得里面最关键的权重和激活值都是定点运算了,部分浮点运算可以接受, 我也先做一个非纯定点的实现,把参数个数较少的bias用浮点表示。 接下来就开始做INT8的定点实现了,还是基于不带BN的浮点实现(飞桨paddlespeech语音唤醒推理C浮点实现)。依旧像INT16定点实现时那样,一层一层的去调,评估指标还是欧氏距离。调试时还是用一个音频文件去调。方便调试出问题时找到原因以及稳妥起见,我将INT8的定点化分成3步来做。
1,depthwise以及pointwise等卷积函数的激活值数据以及参数等均是用float的(即函数参数相对浮点实现不变),在函数内部根据激活值和权重参数量化scale将激活值和权重量化为INT8,然后做定点运算。做完定点运算后再根据激活值和权重参数量化scale将输出的激活值反量化为float值。每层算完后结果都会去跟浮点实现做比较,用欧氏距离去评估。只有欧氏距离较小才算OK。
2,权重参数的量化事先做好。将上面第一步函数的参数中权重参数从float变为int8。在函数里根据激活值的量化scale只做激活值的量化。做完定点运算后再根据激活值和权重参数量化scale将输出的激活值反量化为float值。每层算完后结果都会去跟浮点实现做比较,用欧氏距离去评估。只有欧氏距离较小才算OK。
3,将上面第二步函数的参数中激活值参数也从float变为int8,这样激活值参数和权重参数就都是INT8。函数中权重和激活值就没有量化过程只有定点运算了。激活值得到后再根据当前层和下一层的激活值量化scale重量化为下一层需要的INT8值。需要注意的是在用欧氏距离评估每一层时要把激活值的INT8值转换为float值,因为评估时是与浮点实现作比较。
经过上面三步后一个不是纯的INT8的定点实现就完成了。以depthwise卷积函数为例来看看卷积层的处理:
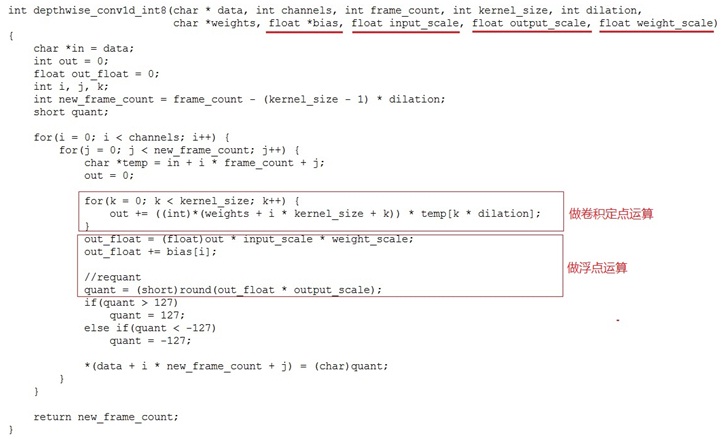
从函数实现可以看出,偏置bias未做量化,是浮点参与运算的,权重和激活值做完定点乘累加后结果再转回浮点与bias做加法运算,最后做重量化把激活值结果变成INT8的值给下层使用。Input_scale/output_scale/weight_scale都是事先算好保存在数组里,当前层的output_scale就是下一层的Input_scale。
等模型调试完成后依旧是在INT16实现用的那个大的数据集(有两万五千多音频文件)上对INT8定点实现做全面的评估,看唤醒率和误唤醒率的变化。跟INT16实现比,唤醒率下降了0.9%,误唤醒率上升了0.6%。说明INT8定点化后性能没有出现明显的下降。
INT8定点实现是在PC上调试的,但我们最终是要用在audio DSP(ADSP,主频只有200M)上,我就在ADSP上搭了个KWS的DEMO,重点关注在模型上。试验下来发现运行一次模型推理(上面的INT8实现)需要近1.2秒,这是没办法部署的,需要优化。调查后发现很少的浮点运算却花了很长的时间。我们用的ADSP没有FPU(浮点运算单元),全是用软件来做浮点运算的,因此要把上面实现里的浮点运算全部改成定点的,主要包括bias以及各种scale的量化。考虑到模型中bias参数个数较少以及保证精度,我用INT32对bias以及scale做量化。看了这几种值的绝对值最大值后,简单起见,确定Q格式均为Q6.25。在卷积函数中,input_scale和weight_scale总是相乘后使用,因此可以看成一个值,相乘后再去做量化。最终一个纯定点的depthwise 卷积函数如下:

再去用那个大数据集(有两万五千多音频文件)上对INT8纯定点实现做全面的评估,看唤醒率和误唤醒率的变化。跟不是纯的INT8实现比,唤醒率和误唤醒率均没什么变化。再把这个纯定点的模型在ADSP上跑,做完一次推理用了不到400ms的时间。这样一个纯定点的INT8实现就完成了。然而这只是一个base,后面还需要继续优化,把运行时间降下来。事后想想如果模型运行在主频高的处理器上(如ARM),推理中有少部分浮点运算是可以的,如果运行在主频低的处理器上(如我上面说的ADSP,只有200M),且没有FPU,模型推理一定要是全定点的实现。
相关文章:
飞桨paddlespeech语音唤醒推理C INT8 定点实现
前面的文章(飞桨paddlespeech语音唤醒推理C定点实现)讲了INT16的定点实现。因为目前商用的语音唤醒方案推理几乎都是INT8的定点实现,于是我又做了INT8的定点实现。 实现前做了一番调研。量化主要包括权重值量化和激活值量化。权重值由于较小且…...

go 面试题分享
1 判断字符串中字符是否全都不同 问题描述 请实现一个算法,确定一个字符串的所有字符【是否全都不同】。这里我们要 求【不允许使用额外的存储结构】。给定一个string,请返回一个bool 值,true代表所有字符全都不同,false代表存在相同的字…...
华为VRP系统简介
因为现在国内主流是华为、华三、锐捷的设备趋势,然后考的证书也是相关的,对于华为设备的一个了解也是需要的。 一、VRP概述 华为的VRP(通用路由平台)是华为公司数据通信产品的通用操作系统平台,作为华为公司从低端到核心的全系列路由器、以太…...
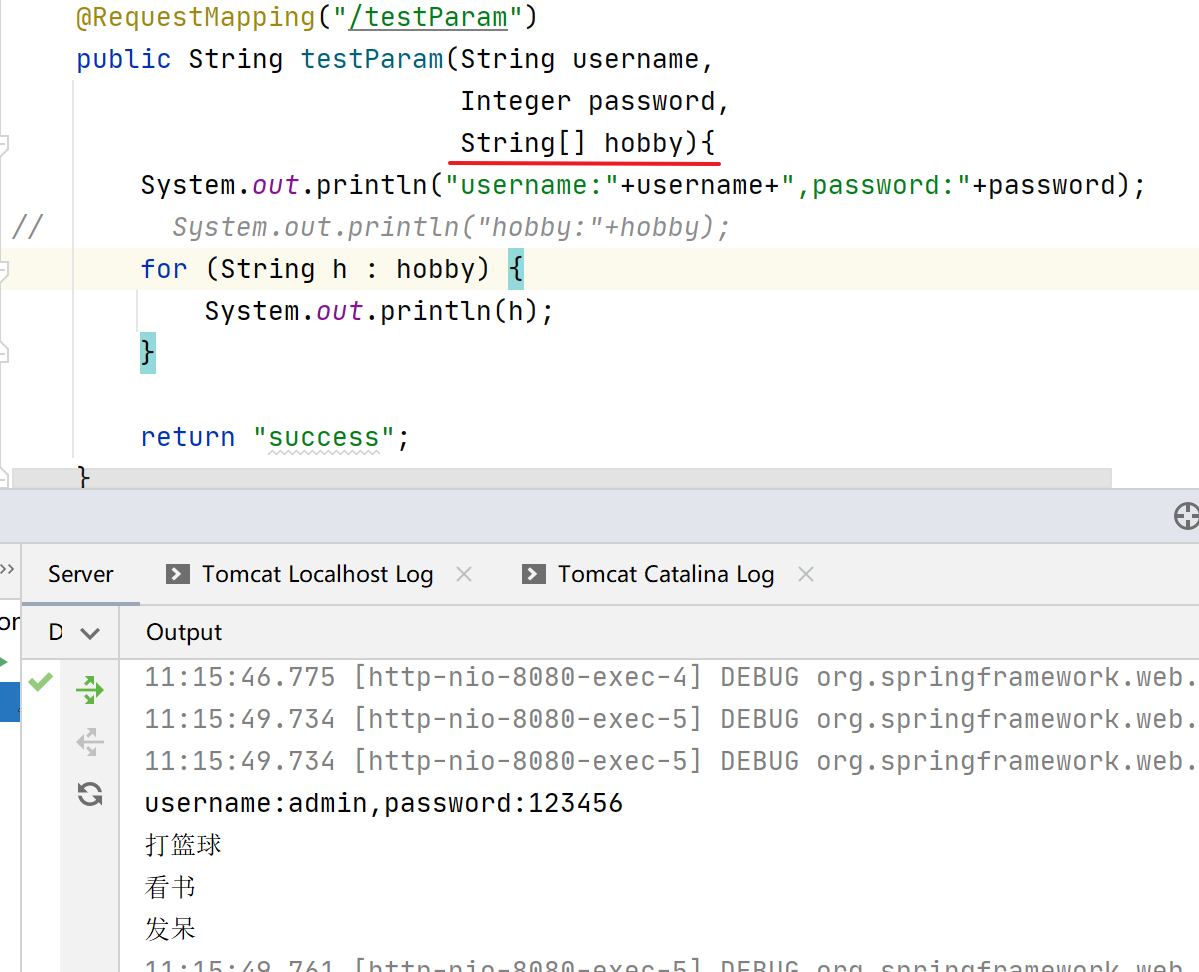
SpringMVC实现对网页的访问,在请求控制器中创建处理请求的方法
目录 测试HelloWorld RequestMapping注解 RequestMapping注解的位置 RequestMapping注解的value属性 RequestMapping注解的method属性 SpringMVC支持路径中的占位符(重点) SpringMVC获取请求参数 1、通过ServletAPI获取 2、通过控制器方法的形参…...

c++循环解释
在C中,循环是一种重复执行特定代码块的结构。它允许程序多次执行相同的代码,直到满足特定条件为止。 C中有三种主要类型的循环结构: while循环:在开始执行循环前,判断条件是否为真。如果条件为真,则执行循…...
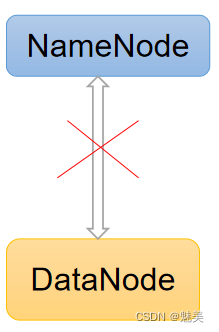
Hadoop3.x基础(2)- HDFS
来源:B站尚硅谷 目录 HDFS概述HDFS产出背景及定义HDFS优缺点HDFS组成架构HDFS文件块大小(面试重点) HDFS的Shell操作(开发重点)基本语法命令大全常用命令实操准备工作上传下载HDFS直接操作 HDFS的API操作HDFS的API案例…...
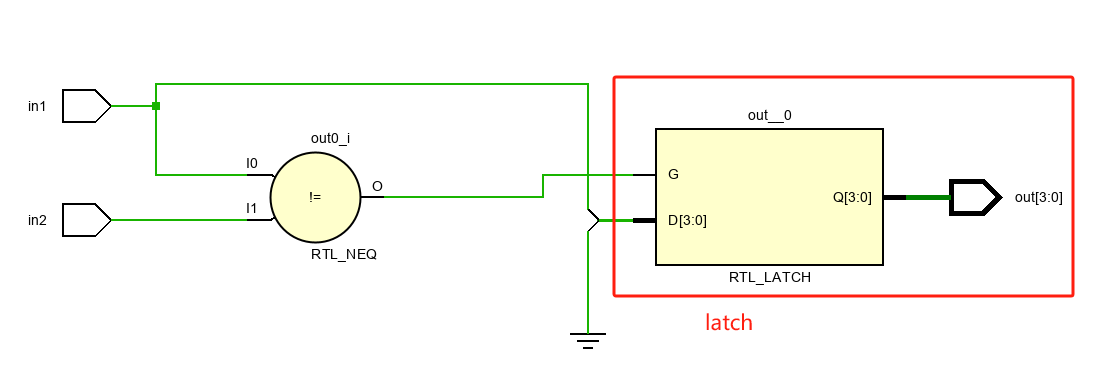
04 避免 Latch 的产生
Latch 是什么 latch 即锁存器,是一种对电平敏感的存储单元电路,和寄存器一样都是基本存储单元,但是寄存器是边沿触发的存储器,锁存器是电平触发的存储器。 组合逻辑电路和时序逻辑电路 在数字电路中将逻辑电路分成两大类&#…...

嵌入式学习第十四天!(结构体、共用体、枚举、位运算)
1. 结构体: 1. 结构体类型定义: 嵌入式学习第十三天!(const指针、函数指针和指针函数、构造数据类型)-CSDN博客 2. 结构体变量的定义: 嵌入式学习第十三天!(const指针、函数指针和…...
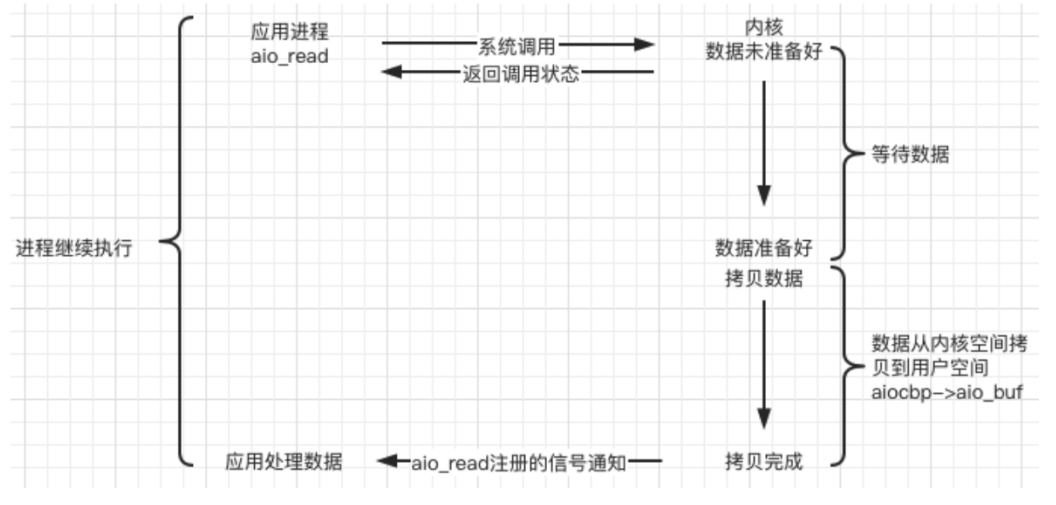
Unix/Linux上的五种IO模型
a.阻塞 blocking 调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作。 注意:阻塞并不是函数的行为,而是跟文件描述符有关。通…...
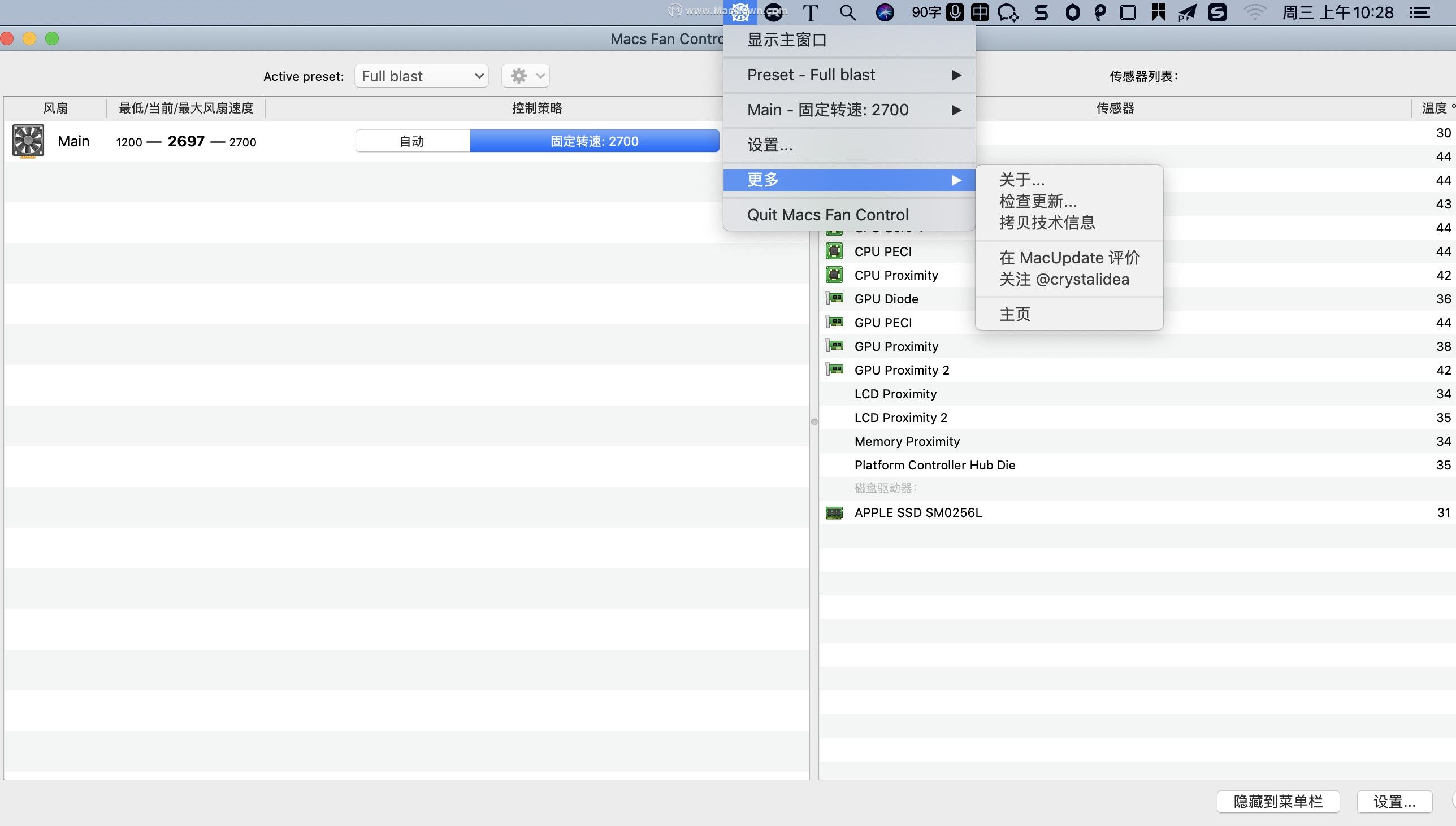
电脑风扇控制温度软件 Macs Fan Control Pro 中文
Macs Fan Control Pro是一款专为Mac用户设计的风扇控制软件,旨在提供更精细的风扇转速控制和温度监控。这款软件通过实时监测Mac内部硬件的温度,自动或手动调整风扇的转速,以确保系统温度保持在理想范围内。 Macs Fan Control Pro提供了直观…...

初谈C++:引用
文章目录 前言概述引用特性应用场景做参数做返回值 传值、传引用效率比较引用和指针的区别 前言 在学习C语言的时候会遇到指针,会有一级指针、二级指针…很容易让人头昏脑胀。在C里面,引入了引用的概念,会减少对指针的使用。引用相当于给一个…...

C++ 数论相关题目 博弈论:拆分-Nim游戏
给定 n 堆石子,两位玩家轮流操作,每次操作可以取走其中的一堆石子,然后放入两堆规模更小的石子(新堆规模可以为 0 ,且两个新堆的石子总数可以大于取走的那堆石子数),最后无法进行操作的人视为失…...

EDR、SIEM、SOAR 和 XDR 的区别
在一个名为网络安全谷的神秘小镇,居住着四位守护者,他们分别是EDR(艾迪)、SIEM(西姆)、SOAR(索亚)和XDR(艾克斯)。他们各自拥有独特的能力,共同守…...
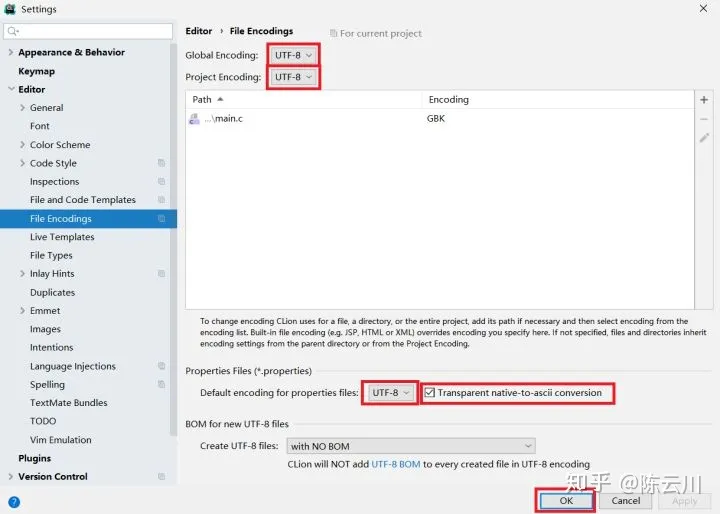
修复idea,eclipse ,clion控制台中文乱码
控制台乱码问题主要原因并不在编译器IDE身上,还主要是Windows的控制台默认编码问题。。。 Powershell,cmd等默认编码可能不是UTF-8,无需改动IDE的settings或者properties(这治标不治本),直接让Windows系统…...

怎样使用Oxygen XML Editor将MS Word转换成DITA
▲ 搜索“大龙谈智能内容”关注公众号▲ 前阵子分享过一篇文章:《如何将Word/PDF转成高质量XML》。 文章中分享了将Word/PDF转换成高质量XML的思路和大体步骤。有朋友问:有什么工具可以做这个数据转换,具体怎么操作呢? 今天就来…...
【云上建站】快速在云上构建个人网站3——网站选型和搭建
快速在云上构建个人网站3——网站选型和搭建 一、网站选型二、云市场镜像方式一:方式二:1. 进入ECS实例详情页面,点击停止,确保更换操作系统的之前ECS实例处于已停止状态,点击更换操作系统,进行镜像配置。2…...

给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数
这个算法的核心思想是通过交换操作,将每个数放到它应该在的位置上。然后再次遍历数组,找到第一个不在正确位置上的数,其索引加一即为缺失的最小正整数。 def first_missing_positive(nums):n len(nums)# 第一次遍历,将数组中的每…...
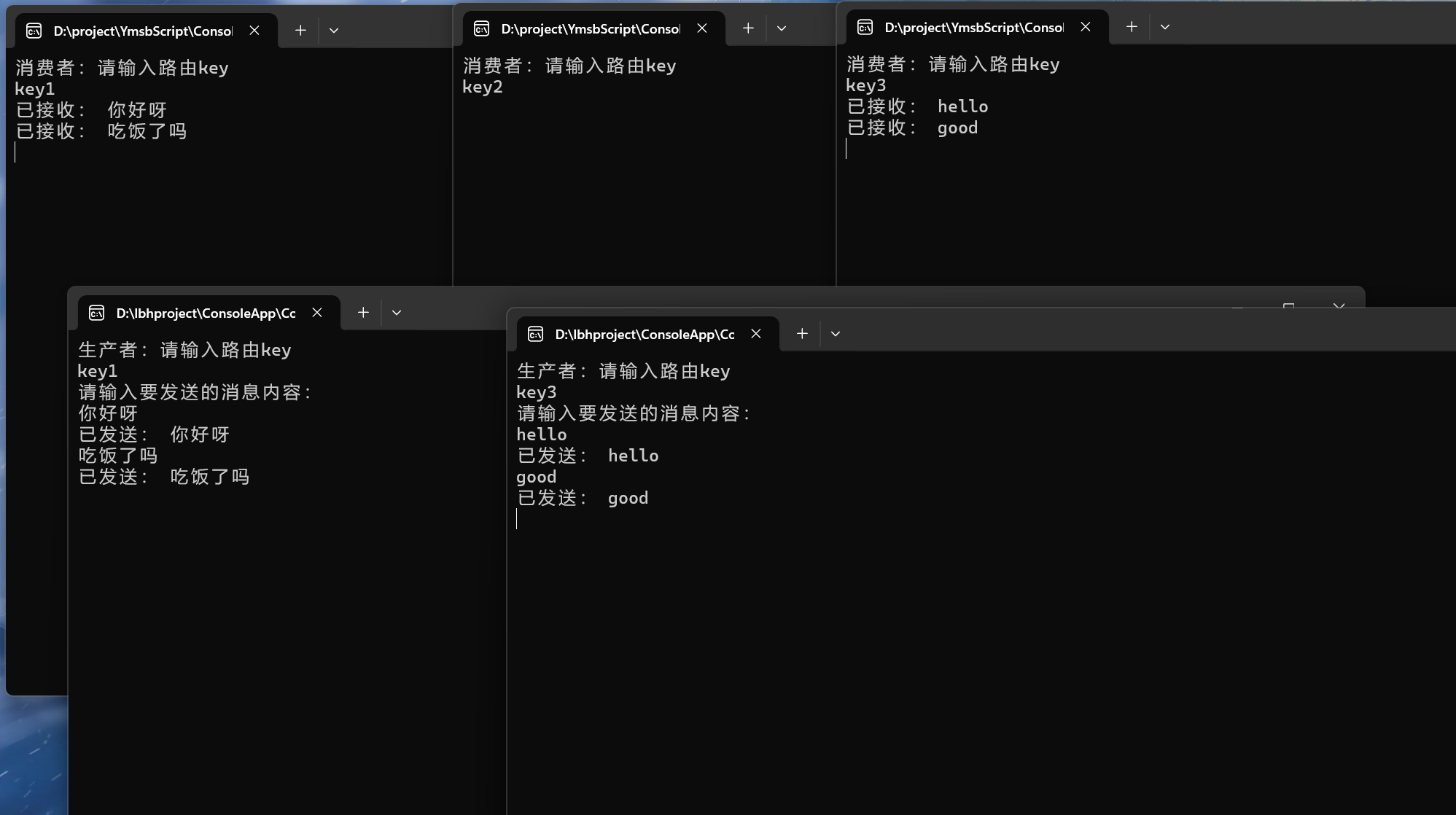
C#使用RabbitMQ-4_路由模式(直连交换机)
简介 RabbitMQ中的路由模式是一种根据Routing Key有条件地将消息筛选后发送给消费者的模式。在路由模式中,生产者向交换机发送消息时,会指定一个Routing Key。交换机接收生产者的消息后,根据消息的Routing Key将其路由到与Routing Key完全匹…...

PyTorch 之 nn.Parameter
文章目录 使用方法:为什么使用 nn.Parameter:示例使用: 在 PyTorch 中,nn.Parameter 是一个类,用于将张量包装成可学习的参数。它是 torch.Tensor 的子类,但被设计成可以被优化器更新的参数。通过将张量包装…...
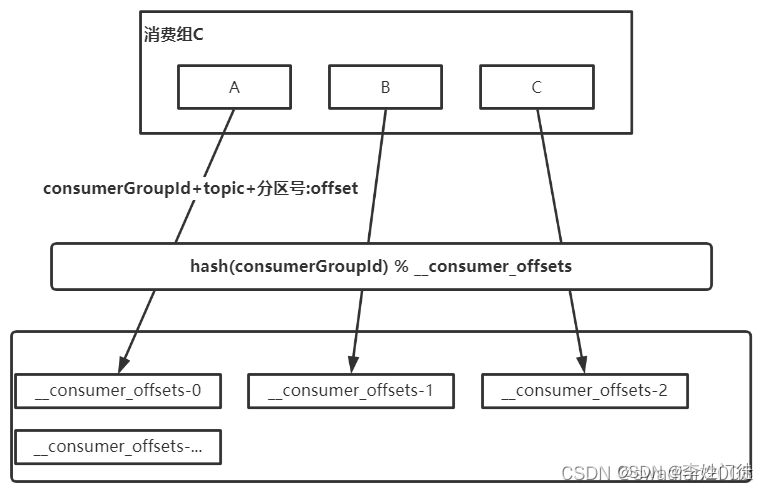
KAFKA高可用架构涉及常用功能整理
KAFKA高可用架构涉及常用功能整理 1. kafka的高可用系统架构和相关组件2. kafka的核心参数2.1 常规配置2.2 特殊优化配置 3. kafka常用命令3.1 常用基础命令3.1.1 创建topic3.1.2 获取集群的topic列表3.1.3 获取集群的topic详情3.1.4 删除集群的topic3.1.5 获取集群的消费组列表…...

机器人跨模态感知:用视觉替代触觉实现非抓取操作
1. 项目概述:当机器人“看不见”接触时,如何让它“感觉”到?在机器人移动操作领域,尤其是非抓取操作(比如推、拉、滑动物体),精确感知机器人与物体之间的接触状态至关重要。传统的解决方案依赖于…...

量子计算中的李群与李代数:从数学基石到时间最优控制实践
1. 从对称性到量子操控:李群与李代数的核心角色 在量子信息处理的世界里,我们每天都在与“对称性”打交道。一个量子比特的旋转,一个多体纠缠态的演化,甚至一个量子算法的设计,其背后都隐藏着一种优美的数学结构——连…...
)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)
Windows电脑C盘告急?手把手教你将Ollama模型库搬家到D盘(附环境变量配置详解)当你在Windows上玩转Ollama大模型时,C盘空间像被黑洞吞噬般迅速告急?别急着删文件或重装系统,今天带你用5分钟完成模型库的无痛…...

保险智能体部署失败率高达73%?揭秘头部险企AI Agent上线前必须完成的3个合规校验步骤
更多请点击: https://codechina.net 第一章:保险智能体部署失败率高达73%?揭秘头部险企AI Agent上线前必须完成的3个合规校验步骤 近期多家头部保险机构联合发布的《2024保险AI落地白皮书》指出,AI Agent在核心承保、核保与理赔场…...

汽车电子系统中GIC-600AE与CMN-600AE互连的安全机制解析
1. CMN-600AE与GIC-600AE互连机制解析在汽车电子系统中,CoreLink GIC-600AE中断控制器与CMN-600AE互连网络的协同工作对实现功能安全至关重要。这两个IP核的配合使用需要特别关注消息路由机制和保护方案的兼容性。GIC-600AE内部组件(如ITS中断转换服务和…...

【企业级AI Agent操作安全白皮书】:基于ISO/IEC 27001与NIST AI RMF的6类操作审计红线
更多请点击: https://codechina.net 第一章:AI Agent自主操作软件的定义与安全治理边界 AI Agent自主操作软件是指具备感知环境、规划决策、调用工具(如API、CLI、GUI自动化接口)并闭环执行任务能力的智能体系统。其核心特征在于…...

SLAM技术路线收敛?不,多模态融合正在重启路线之争
过去几年,SLAM技术路线确实呈现出明确的收敛趋势:纯视觉SLAM逐渐成熟,基于3DGS的实时建图成为新范式,激光SLAM也固化为工业场景的稳健选择。大家一度认为,算法架构的选择题已经做完。然而,多模态融合的深入…...

计算机网络基础:TCP/IP 与 HTTP 核心知识
摘要:计算机网络是后台开发和 AI 基础设施面试的重要考点。本文从 OSI 七层模型出发,重点讲解 TCP 三次握手/四次挥手、HTTP/HTTPS 协议、以及 WebSocket 和 RESTful API 设计,并结合 Python 代码展示 Socket 编程和简单的 HTTP 服务器实现。…...

Unity发行版DLL调试:破解IL2CPP元数据加密与mono.dll符号映射
1. 为什么发行版Unity游戏的DLL调试总卡在“找不到符号”这一步?你打包完一个Unity项目,导出为Windows独立发布版本,双击运行一切正常——但当你兴冲冲地用DnSpy打开GameAssembly.dll或Assembly-CSharp.dll,想设个断点看看登录逻辑…...

解决Claude Code密钥被封与Token不足的替代接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code密钥被封与Token不足的替代接入方案 对于频繁使用Claude Code编程助手的开发者而言,开发流程中突然遇到…...