猿创征文 | 项目整合KafkaStream实现文章热度实时计算

个人简介:
> 📦个人主页:赵四司机
> 🏆学习方向:JAVA后端开发
> ⏰往期文章:SpringBoot项目整合微信支付
> 🔔博主推荐网站:牛客网 刷题|面试|找工作神器
> 📣种一棵树最好的时间是十年前,其次是现在!
> 💖喜欢的话麻烦点点关注喔,你们的支持是我的最大动力。
前言:
最近在做一个基于SpringCloud+Springboot+Docker的新闻头条微服务项目,用的是黑马的教程,现在项目开发进入了尾声,我打算通过写文章的形式进行梳理一遍,并且会将梳理过程中发现的Bug进行修复,有需要改进的地方我也会继续做出改进。这一系列的文章我将会放入微服务项目专栏中,这个项目适合刚接触微服务的人作为练手项目,假如你对这个项目感兴趣你可以订阅我的专栏进行查看,需要资料可以私信我,当然要是能给我点个小小的关注就更好了,你们的支持是我最大的动力。
如果你想要一个可以系统学习的网站,那么我推荐的是牛客网,个人感觉用着还是不错的,页面很整洁,而且内容也很全面,语法练习,算法题练习,面试知识汇总等等都有,论坛也很活跃,传送门链接:牛客刷题神器
目录
一:Springboot集成Kafka Stream
1.设置配置类信息
2.修改application.yml文件
3.新增配置类,创建KStream对象,进行聚合
二:热点文章实时计算
1.实现思路
2.环境搭建
2.1:在文章微服务中集成Kafka生产者配置
2.2:记录用户行为
2.3:定义Stream实现消息接收并聚合
2.4:重新计算文章分值并更新Redis缓存数据
2.5:设置监听类
三:功能测试
一:Springboot集成Kafka Stream
1.设置配置类信息
package com.my.kafka.config;import lombok.Getter;
import lombok.Setter;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;
import org.springframework.kafka.config.KafkaStreamsConfiguration;import java.util.HashMap;
import java.util.Map;/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);}
}可能你会有这样的疑问,前面介绍Kafka时候不是直接在yml文件里面设置参数就行了吗?为什么这里还要自己写配置类呢?是因为Spring对KafkaStream的集成并不是很好,所以我们才需要自己去写配置类信息。需要注意的一点是,配置类中必须添加@EnableKafkaStreams这一注解。
2.修改application.yml文件
kafka:hosts: 192.168.200.130:9092group: ${spring.application.name}3.新增配置类,创建KStream对象,进行聚合
package com.my.kafka.stream;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;
import java.util.Arrays;@Slf4j
@Configuration
public class KafkaStreamHelloListener {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//创建KStream对象,同时指定从那个topic中接收消息KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> Arrays.asList(value.split(" ")))//根据value进行聚合分组.groupBy((key,value)->value)//聚合计算时间间隔.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//求单词的个数.count().toStream()//处理后的结果转换为string字符串.map((key,value)->{System.out.println("key:"+key+",value:"+value);return new KeyValue<>(key.key().toString(),value.toString());})//发送消息.to("itcast-topic-out");return stream;}
}这里实现的功能还是计算单词个数,假如你有其他计算需求你可以更改里面的逻辑代码以符合你的需求。该类可注入StreamBuilder,其返回值必须是KStream且放入Spring容器中(添加了@Bean注解)。
二:热点文章实时计算
1.实现思路
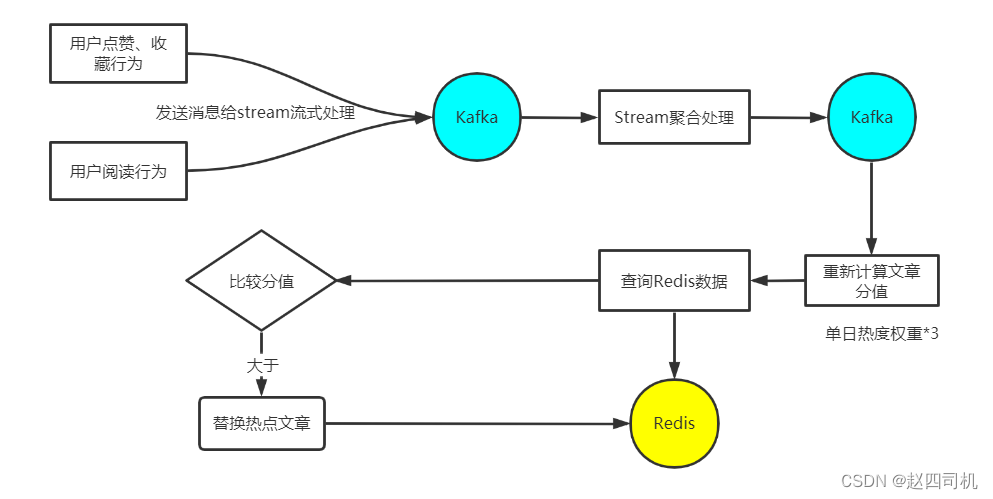
实现思路很简单,当用户有点赞、收藏、阅读等行为记录时候,就将消息发送给Kafka进行流式处理,随后Kafka再进行聚合并重新计算文章分值,除此之外还需要更新数据库中的数据。需要注意的是,按常理来说当天的文章热度权重是要比非当天的文章热度权重大的,因此当日文章的热度权重需要乘以3,随后查询Redis中的数据,假如该文章分数大于Redis中最低分文章,这时候就需要进行替换操作,更新Redis数据。
2.环境搭建
2.1:在文章微服务中集成Kafka生产者配置
(1)修改nacos,增加内容:
kafka:bootstrap-servers: 49.234.52.192:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerhosts: 49.234.52.192:9092group: ${spring.application.name}(2)定义相关实体类、常量
package com.my.model.mess;import lombok.Data;@Data
public class UpdateArticleMess {/*** 修改文章的字段类型*/private UpdateArticleType type;/*** 文章ID*/private Long articleId;/*** 修改数据的增量,可为正负*/private Integer add;public enum UpdateArticleType{COLLECTION,COMMENT,LIKES,VIEWS;}
}2.2:记录用户行为
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
/*** 读文章行为记录(阅读量+1)* @param map* @return*/
public ResponseResult readBehavior(Map map) {if(map == null || map.get("articleId") == null) {return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}Long articleId = Long.parseLong((String) map.get("articleId"));ApArticle apArticle = getById(articleId);if(apArticle != null) {//获取文章阅读数Integer views = apArticle.getViews();if(views == null) {views = 0;}//调用Kafka发送消息UpdateArticleMess mess = new UpdateArticleMess();mess.setArticleId(articleId);mess.setType(UpdateArticleMess.UpdateArticleType.VIEWS);mess.setAdd(1);kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(mess));//更新文章阅读数LambdaUpdateWrapper<ApArticle> luw = new LambdaUpdateWrapper<>();luw.eq(ApArticle::getId,articleId);luw.set(ApArticle::getViews,views + 1);update(luw);}return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}/*** 用户点赞* @param map* @return*/
@Override
public ResponseResult likesBehavior(Map map) {if(map == null || map.get("articleId") == null) {return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}Long articleId = Long.parseLong((String) map.get("articleId"));Integer operation = (Integer) map.get("operation");ApArticle apArticle = getById(articleId);UpdateArticleMess mess = new UpdateArticleMess();mess.setArticleId(articleId);mess.setType(UpdateArticleMess.UpdateArticleType.LIKES);if(apArticle != null) {//获取文章点赞数Integer likes = apArticle.getLikes();if(likes == null) {likes = 0;}//更新文章点赞数LambdaUpdateWrapper<ApArticle> luw = new LambdaUpdateWrapper<>();luw.eq(ApArticle::getId,articleId);if(operation == 0) {//点赞log.info("用户点赞文章...");luw.set(ApArticle::getLikes,likes + 1);//分值增加mess.setAdd(1);} else {//取消点赞log.info("用户取消点赞文章...");luw.set(ApArticle::getLikes,likes - 1);//分值减少mess.setAdd(-1);}//调用Kafka发送消息kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(mess));update(luw);}return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}/*** 用户收藏* @param map* @return*/
@Override
public ResponseResult collBehavior(Map map) {if(map == null || map.get("entryId") == null) {return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}Long articleId = Long.parseLong((String) map.get("entryId"));Integer operation = (Integer) map.get("operation");ApArticle apArticle = getById(articleId);//消息载体UpdateArticleMess mess = new UpdateArticleMess();mess.setArticleId(articleId);mess.setType(UpdateArticleMess.UpdateArticleType.COLLECTION);if(apArticle != null) {//获取文章收藏数Integer collection = apArticle.getCollection();if(collection == null) {collection = 0;}//更新文章收藏数LambdaUpdateWrapper<ApArticle> luw = new LambdaUpdateWrapper<>();luw.eq(ApArticle::getId,articleId);if(operation == 0) {//收藏log.info("用户收藏文章...");luw.set(ApArticle::getCollection,collection + 1);mess.setAdd(1);} else {//取消收藏log.info("用户取消收藏文章...");luw.set(ApArticle::getCollection,collection - 1);mess.setAdd(-1);}//调用Kafka发送消息kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(mess));update(luw);}return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}
这一步主要是当用户对文章进行访问、点赞、评论或者收藏时候就会更新数据库中的记录,同时还要将该行为记录封装并发送至Kafka。
2.3:定义Stream实现消息接收并聚合
package com.my.article.stream;import com.alibaba.fastjson.JSON;
import com.my.common.constans.HotArticleConstants;
import com.my.model.mess.ArticleVisitStreamMess;
import com.my.model.mess.UpdateArticleMess;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;@Configuration
@Slf4j
public class HotArticleStreamHandler {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//接收消息KStream<String,String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);//聚合流式处理stream.map((key,value)->{UpdateArticleMess mess = JSON.parseObject(value, UpdateArticleMess.class);//重置消息的key:1234343434 和 value: likes:1return new KeyValue<>(mess.getArticleId().toString(),mess.getType().name()+":"+mess.getAdd());})//按照文章id进行聚合.groupBy((key,value)->key)//时间窗口 每十秒聚合一次.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))/*自行地完成聚合的计算*/.aggregate(new Initializer<String>() {/*** 初始方法,返回值是消息的value*/@Overridepublic String apply() {return "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";}/*真正的聚合操作,返回值是消息的value*/}, new Aggregator<String, String, String>() {/*** 聚合并返回* @param key 文章id* @param value 重置后的value ps:likes:1* @param aggValue "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0"* @return aggValue格式*/@Overridepublic String apply(String key, String value, String aggValue) {//用户没有进行任何操作if(StringUtils.isBlank(value)){return aggValue;}String[] aggAry = aggValue.split(",");//收藏、评论、点赞、阅读量初始值int col = 0,com=0,lik=0,vie=0;for (String agg : aggAry) {//for --> COLLECTION:0String[] split = agg.split(":");//split[0]:COLLECTION,split[1]:0/*获得初始值,也是时间窗口内计算之后的值第一次获取到的值为0*/switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:col = Integer.parseInt(split[1]);break;case COMMENT:com = Integer.parseInt(split[1]);break;case LIKES:lik = Integer.parseInt(split[1]);break;case VIEWS:vie = Integer.parseInt(split[1]);break;}}/*累加操作*/String[] valAry = value.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){case COLLECTION:col += Integer.parseInt(valAry[1]);break;case COMMENT:com += Integer.parseInt(valAry[1]);break;case LIKES:lik += Integer.parseInt(valAry[1]);break;case VIEWS:vie += Integer.parseInt(valAry[1]);break;}String formatStr = String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);log.info("文章的id:{}",key);log.info("当前时间窗口内的消息处理结果:{}",formatStr);//必须返回和apply()的返回类型return formatStr;}}, Materialized.as("hot-article-stream-count-001")).toStream().map((key,value)->{return new KeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));})//发送消息.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);return stream;}/*** 格式化消息的value数据* @param articleId 文章id* @param value 聚合结果* @return String*/public String formatObj(String articleId,String value){ArticleVisitStreamMess mess = new ArticleVisitStreamMess();mess.setArticleId(Long.valueOf(articleId));//COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0String[] valAry = value.split(",");for (String val : valAry) {String[] split = val.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:mess.setCollect(Integer.parseInt(split[1]));break;case COMMENT:mess.setComment(Integer.parseInt(split[1]));break;case LIKES:mess.setLike(Integer.parseInt(split[1]));break;case VIEWS:mess.setView(Integer.parseInt(split[1]));break;}}log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));return JSON.toJSONString(mess);}
}这一步是最难但是也是最重要的,首先我们接收到消息之后需要先对其key和value进行重置,因为这时候接收到的数据是一个JSON字符串格式的UpdateArticleMess对象,我们需要将其重置为key value键值对的格式。也即将其格式转化成key为文章id,value为用户行为记录,如key:182738789987,value:LIKES:1,表示用户对该文章点赞一次。随后选择对文章id进行聚合,每10秒钟聚合一次,需要注意的是,apply()函数中返回结构必须是“COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0”格式。
2.4:重新计算文章分值并更新Redis缓存数据
@Service
@Transactional
@Slf4j
public class ApArticleServiceImpl extends ServiceImpl<ApArticleMapper, ApArticle> implements ApArticleService {/*** 更新文章分值,同时更新redis中热点文章数据* @param mess*/@Overridepublic void updateScore(ArticleVisitStreamMess mess) {//1.获取文章数据ApArticle apArticle = getById(mess.getArticleId());//2.计算文章分值Integer score = computeScore(apArticle);score = score * 3;//3.替换当前文章对应频道热点数据replaceDataToRedis(apArticle,score,ArticleConstas.HOT_ARTICLE_FIRST_PAGE + apArticle.getChannelId());//4.替换推荐频道文章热点数据replaceDataToRedis(apArticle,score,ArticleConstas.HOT_ARTICLE_FIRST_PAGE + ArticleConstas.DEFAULT_TAG);}/*** 根据权重计算文章分值* @param apArticle* @return*/private Integer computeScore(ApArticle apArticle) {Integer score = 0;if(apArticle.getLikes() != null){score += apArticle.getLikes() * ArticleConstas.HOT_ARTICLE_LIKE_WEIGHT;}if(apArticle.getViews() != null){score += apArticle.getViews();}if(apArticle.getComment() != null){score += apArticle.getComment() * ArticleConstas.HOT_ARTICLE_COMMENT_WEIGHT;}if(apArticle.getCollection() != null){score += apArticle.getCollection() * ArticleConstas.HOT_ARTICLE_COLLECTION_WEIGHT;}return score;}/*** 替换数据并存入到redis* @param apArticle 文章信息* @param score 文章新的得分* @param key redis数据的key值*/private void replaceDataToRedis(ApArticle apArticle,Integer score, String key) {String articleListStr = cacheService.get(key);if(StringUtils.isNotBlank(articleListStr)) {List<HotArticleVo> hotArticleVos = JSON.parseArray(articleListStr, HotArticleVo.class);boolean flag = true;//如果缓存中存在该文章,直接更新文章分值for (HotArticleVo hotArticleVo : hotArticleVos) {if(hotArticleVo.getId().equals(apArticle.getId())) {if(key.equals(ArticleConstas.HOT_ARTICLE_FIRST_PAGE + apArticle.getChannelId())) {log.info("频道{}缓存中存在该文章,文章{}分值更新{}-->{}",apArticle.getChannelName(),apArticle.getId(),hotArticleVo.getScore(),score);} else {log.info("推荐频道缓存中存在该文章,文章{}分值更新{}-->{}",apArticle.getId(),hotArticleVo.getScore(),score);}hotArticleVo.setScore(score);flag = false;break;}}//如果缓存中不存在该文章if(flag) {//缓存中热点文章数少于30,直接增加if(hotArticleVos.size() < 30) {log.info("该文章{}不在缓存,但是文章数少于30,直接添加",apArticle.getId());HotArticleVo hotArticleVo = new HotArticleVo();BeanUtils.copyProperties(apArticle,hotArticleVo);hotArticleVo.setScore(score);hotArticleVos.add(hotArticleVo);} else {//缓存中热点文章数大于或等于30//1.排序hotArticleVos = hotArticleVos.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());//2.获取最小得分值HotArticleVo minScoreHotArticleVo = hotArticleVos.get(hotArticleVos.size() - 1);if(minScoreHotArticleVo.getScore() <= score) {//3.移除分值最小文章log.info("替换分值最小的文章...");hotArticleVos.remove(minScoreHotArticleVo);HotArticleVo hotArticleVo = new HotArticleVo();BeanUtils.copyProperties(apArticle,hotArticleVo);hotArticleVo.setScore(score);hotArticleVos.add(hotArticleVo);}}}//重新排序并缓存到redishotArticleVos = hotArticleVos.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());cacheService.set(key,JSON.toJSONString(hotArticleVos));if(key.equals(ArticleConstas.HOT_ARTICLE_FIRST_PAGE + apArticle.getChannelId())) {log.info("成功刷新{}频道中热点文章缓存数据",apArticle.getChannelName());} else {log.info("成功刷新推荐频道中热点文章缓存数据");}}}
}
这一步主要是逻辑处理部分,在这里我们需要完成对文章的得分进行重新计算并根据计算结果更新Redis中的缓存数据。计算到得分之后,我们需要分别对不同频道和推荐频道进行处理,但是处理流程相同。首先我们会先判断缓存中的数据有没有满30条,如果没满则直接该文章添加到缓存中作为热榜文章;如果缓存中已满30条数据,这时候就要分两种情况处理,如果缓存中存在该文章数据,则直接对其得分进行更新,如若不然则需要将该文章分值与缓存中的最低分进行比较,如果改文章得分比最低分高则直接进行替换,否则不做处理。最后还需要对缓存中的数据重新排序并再次发送到Reids中。
2.5:设置监听类
package com.my.article.listener;import com.alibaba.fastjson.JSON;
import com.my.article.service.ApArticleService;
import com.my.common.constans.HotArticleConstants;
import com.my.model.mess.ArticleVisitStreamMess;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;@Component
@Slf4j
public class ArticleIncrHandleListener {@Autowiredprivate ApArticleService apArticleService;@KafkaListener(topics = HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC)public void onMessage(String mess){if(StringUtils.isNotBlank(mess)){ArticleVisitStreamMess articleVisitStreamMess = JSON.parseObject(mess, ArticleVisitStreamMess.class);apArticleService.updateScore(articleVisitStreamMess);}}
}三:功能测试
打开App端对一篇文章进行浏览并点赞收藏

到控制台查看日志信息
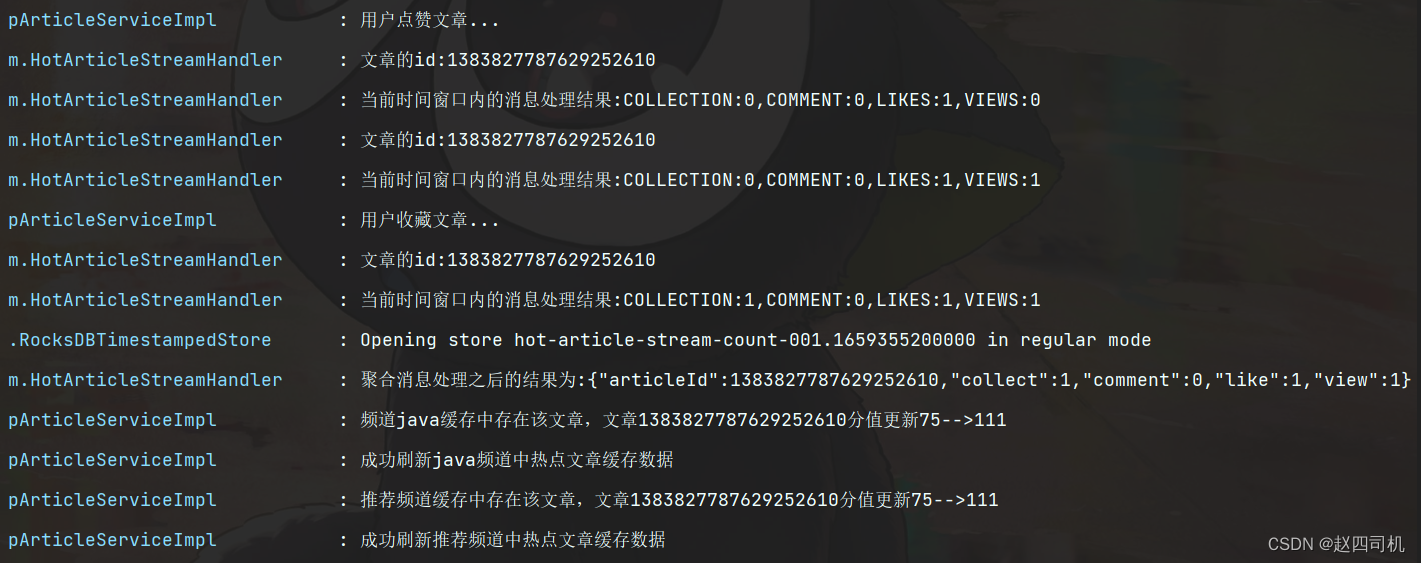
可以看到 成功记录用户行为并且将文章得分进行了更改,其处理流程是这样的,首先接收到的是用户的点赞数据,随后接收到用户的浏览记录,最后接收到的是用户的收藏记录,由于前面提到的消息处理是增加而不是更新,所以最后我们可以看到时间窗口处理结果为COLLECTION:1,COMMENT:0,LIKES:1,VIEWS:1,10秒钟之后就会对消息进行聚合,假如这10秒之内还有其他用户也进行了点赞阅读操作,这时候就会继续将消息增加在原来处理结果上面,过了10秒之后就会进行一次聚合处理,也即拿着这批数据进行数据更新操作。
至此该项目的开发就告一段落了,后续有什么优化我会再发文介绍。
友情链接: 牛客网 刷题|面试|找工作神器
相关文章:
猿创征文 | 项目整合KafkaStream实现文章热度实时计算
个人简介: > 📦个人主页:赵四司机 > 🏆学习方向:JAVA后端开发 > ⏰往期文章:SpringBoot项目整合微信支付 > 🔔博主推荐网站:牛客网 刷题|面试|找工作神器 > &#…...
状态压缩 笔记
棋盘式的f[i][j]中表示状态的j可以是状态本身也可以是在合法状态state中的下标 用状态本身比较方便,用下标比较省空间 用下标的话可以开id[M]数组记录一下 蒙德里安的梦想 求把 NM的棋盘分割成若干个 12的长方形,有多少种方案。 例如当 N2࿰…...
Java 数据结构篇-实现二叉搜索树的核心方法
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 二叉搜索树的概述 2.0 二叉搜索树的成员变量及其构造方法 3.0 实现二叉树的核心接口 3.1 实现二叉搜索树 - 获取值 get(int key) 3.2 实现二叉搜索树 - 获取最小…...
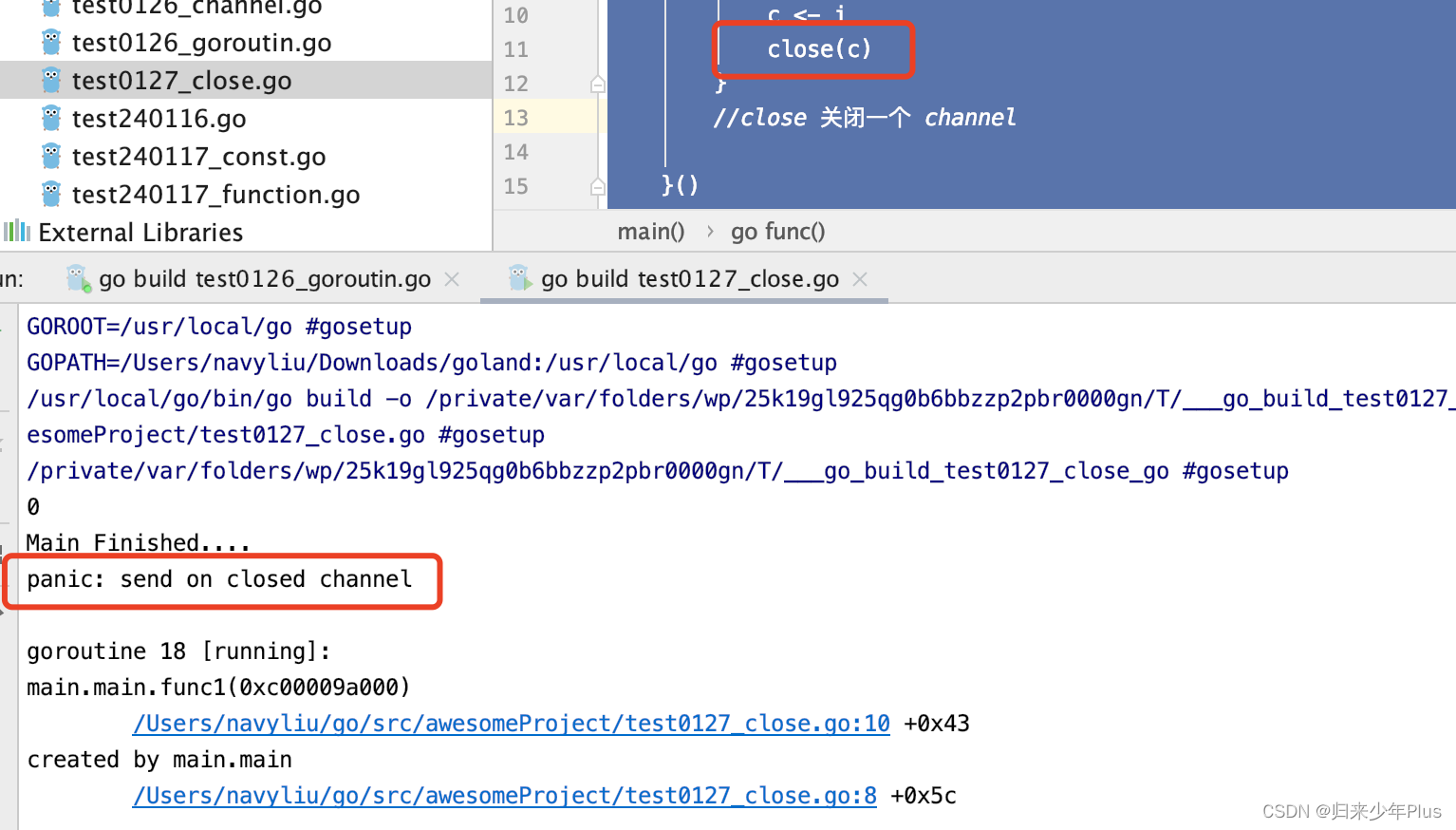
go语言(二十一)---- channel的关闭
channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显示的结束range循环之类的,才去关闭channel。关闭channel后,无法向channel再发送数据,(引发pannic错误后,导致接收…...
【PyQt】01-PyQt下载
文章目录 前言静态库 一、PyQt是什么?二、安装1.Windows环境下安装安装PyQt5Designer 2.Liunx环境下安装 总结 前言 拜吾师 PyQt5 快速入门 静态库 补充一点知识: Windows: .lib Linux: .a .so(动态库) 简单描述PyQt就是python调用C的Qt文…...

不一样的味觉体验:精酿啤酒与烤肉的绝妙搭配
在繁华的都市生活中,人们总是在寻找那份与众不同的味觉享受。当夏日的微风轻轻拂过,你是否想过,与三五好友围坐在一起,拿着Fendi Club啤酒与烤肉的绝妙搭配,畅谈生活点滴,感受那份惬意与自在? F…...

linux系统ansible的jiaja2的语法和简单剧本编写
jianja2语法和简单剧本 jinja2语法Jinja default()设定if语句for语句 ansiblejiaja2的使用ansible目录结构:tasks目录下文件内容:nginx模板文件ansible变量文件ansible主playbook文件测试并执行:查看检测执行结果 剧本编写安装apache安装mysq…...

Three.js PBR 物理渲染
详解 Three.js PBR 物理渲染 Three.js 是一个流行的基于 WebGL 的 JavaScript 库,专门用于创建和运行三维动画和游戏。其中很关键的一部分是物理渲染(PBR)。本文将深入探讨 Three.js 的 PBR 渲染,并为初学者提供实用的指导。 什…...
POSIX(包含程序的可移植性) -- 详解
1. 什么是 POSIX 参考链接–知乎 POSIX 标准包含了进程管理、文件管理、网络通信、线程和同步、信号处理等方面的功能。 这些接口定义了函数、数据类型和常量等,为开发者提供了一个可移植的方法来与操作系统进行交互。 2. 谁遵守这个标准 遵守 POSIX 标准的主要是…...
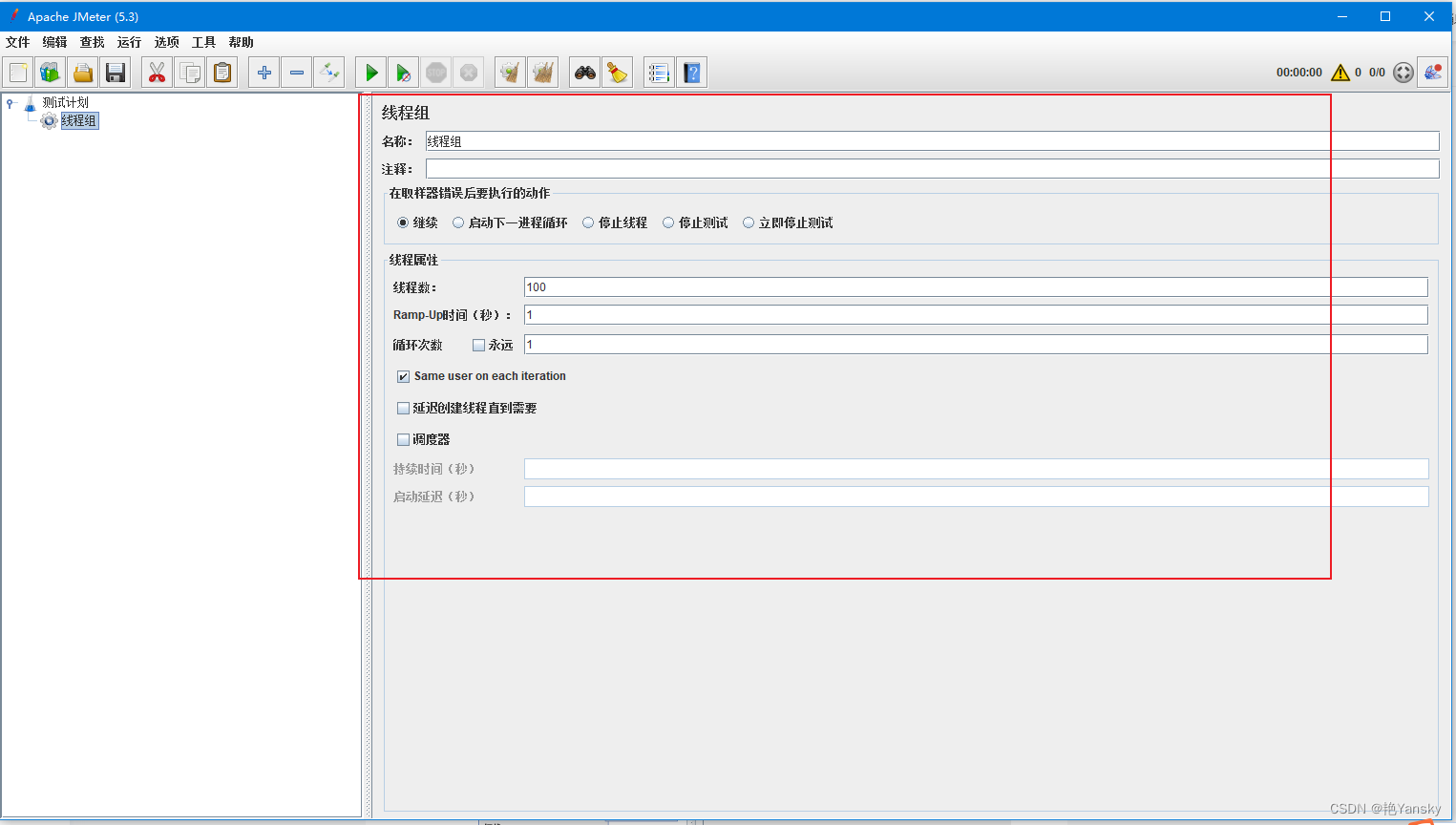
Jmeter学习系列之五:基础线程组(Thread Group)
前言 线程组是一系列线程的集合,每一个线程代表着一个正在使用应用程序的用户。在 jmeter 中,每个线程意味着模拟一个真实用户向服务器发起请求。 在 jmeter 中,线程组组件运行用户设置线程数量、初始化方式等等配置。 例如,如果你设置线程数为 100,那么 jmeter 将创建…...

Android 双卡适配 subId 相关方法
业务场景 双卡设备进行网络等业务时,需要正确操作对应的卡。 执行卡业务和主要是使用subId和 PhoneId/SlotId进行区分隔离。 代码举例 初始化subId //初始化subId private int mSubId SubscriptionManager.INVALID_SUBSCRIPTION_ID;//1、通过intent传值&#x…...
使用Logstash将MySQL中的数据同步至Elasticsearch
目录 1 使用docker安装ELK 1.1 安装Elasticsearch 1.2 安装Kibana 1.3 安装Logstash 2 数据同步 2.1 准备MySQL表和数据 2.2 运行Logstash 2.3 测试 3 Logstash报错(踩坑)记录 3.1 记录一 3.1.1 报错信息 3.1.2 报错原因 3.1.3 解决方案 3.2 记录二 3.2.1 报错信…...
 更新)
米贸搜|Facebook公共主页反馈分数(ACE) 更新
前段时间Meta改进了公共主页反馈分数的仪表板,发现有部分广告主似乎没有接受到这条动态,今天为大家整理出更新内容,方便各位广告主了解学习! Meta重新设计了公共主页反馈分数仪表板,以便广告主能更轻松地了解总体反馈…...

代码随想录算法训练营第三十七天| 738.单调递增的数字、968.监控二叉树
738.单调递增的数字 题目链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 解题思路:一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum[i - 1]--,然…...
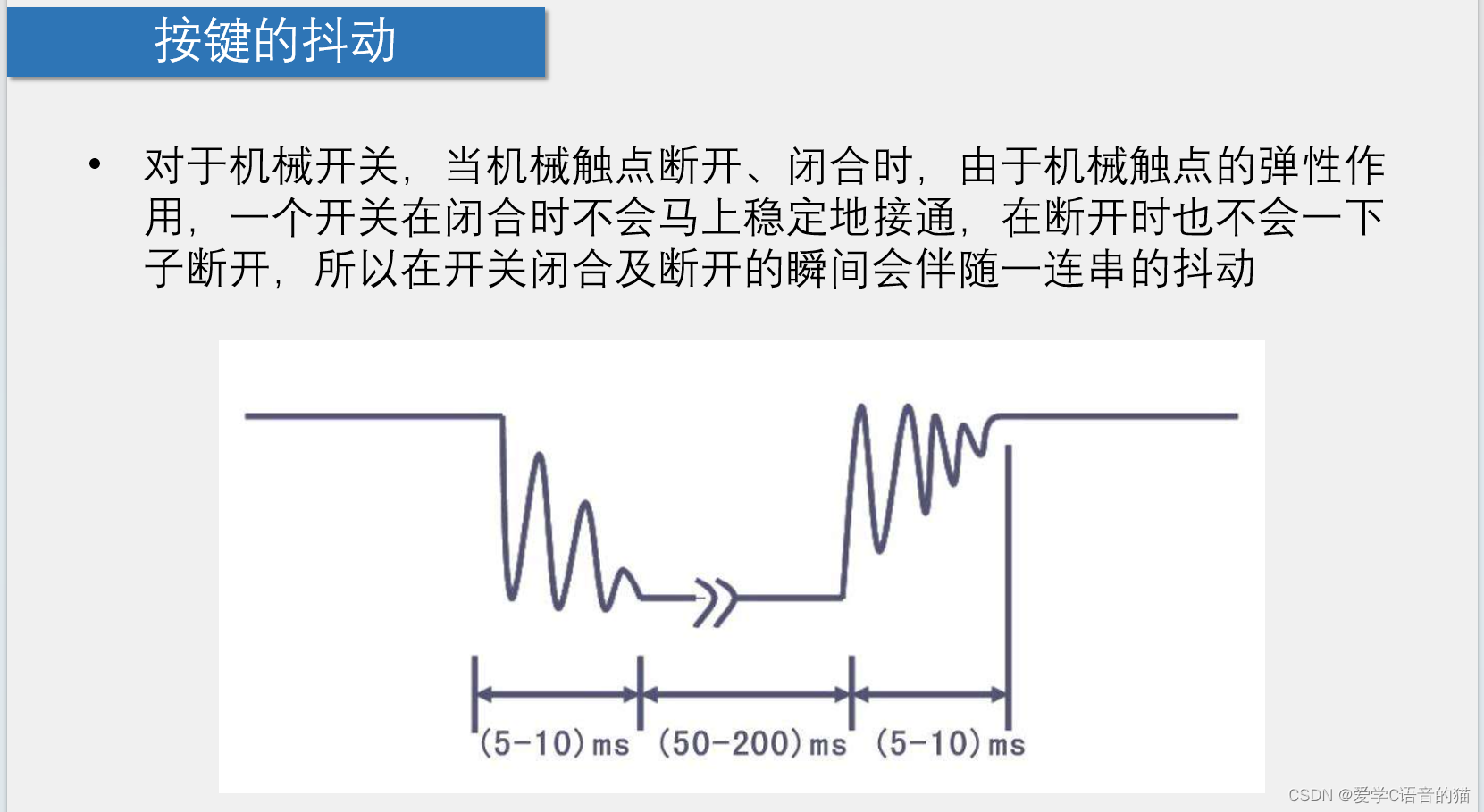
51单片机编程应用(C语言):独立按键
目录 1.独立按键介绍 2.独立按键控制LED亮灭 1.1按下时LED亮,松手LED灭(按一次执行亮灭) 1.2首先按下时无操作,松手时LED亮(再按下无操作,所以LED亮),松手LED灭(松手时…...
小程序定制开发前,应该考虑些什么?
引言 在移动互联网时代,小程序已经成为许多企业和个人推广业务、提供服务的理想平台。然而,在进行小程序定制开发之前,开发者和业务方需要细致入微地考虑一系列关键因素,以确保最终的小程序既能满足用户需求,又能够顺…...
2024/2/1学习记录
echarts 为柱条添加背景色: 若想设置折线图的点的样式,设置 series.itemStyle 指定填充颜色就好了,设置线的样式设置 lineStyle 就好了。 在折线图中倘若要设置空数据,用 - 表示即可,这对于其他系列的数据也是 适用的…...

10个React状态管理库推荐
本文将为您推荐十款实用的React状态管理库,帮助您打造出高效、可维护的前端应用。让我们一起看看这些库的魅力所在! 在前端开发中,状态管理是至关重要的一环。React作为一款流行的前端框架,其强大的状态管理功能备受开发者青睐。…...

从0开始写android
系列文章目录 文章目录 一、 从0开始实现 onCreate 的setContentView二、 从0 开始实现 onMeasure三、 从0 开始实现 onLayout四、 从0 开始实现 onDraw总结 前言 接上文,测量完View树的每个节点View的宽和高后,开始布局。 一、ViewRootImpl 的调用栈…...
使用pygame建立一个简单的使用键盘方向键移动的方块小游戏
import pygame import sys# 初始化pygame pygame.init()# 设置窗口大小 screen_size (640, 480) # 创建窗口 screen pygame.display.set_mode(screen_size) # 设置窗口标题 pygame.display.set_caption("使用键盘方向键移动的方块的简单小游戏")# 设置颜色 bg_colo…...

在RK3568开发板上搭建NFS服务器:打通ARM与X86文件共享
1. 项目概述:为什么要在RK3568上折腾NFS?手头有一块瑞芯微RK3568的开发板,性能不错,四核A55的架构,跑个轻量级服务器绰绰有余。最近在做一个边缘计算相关的原型验证,需要在开发板和我的主力工作站之间频繁地…...

2026年想做美缝施工?专业靠谱的美缝施工究竟哪家好?
在装修领域,美缝施工虽看似是小工程,却对家居整体美观度和实用性影响重大。然而,美缝行业乱象丛生,让众多业主在选择美缝施工团队时犯了难。2026年若想做美缝施工,怎样才能选到专业靠谱的团队呢?下面为大家…...

从低空协议劫持实战看 MAVLink 二进制审计在飞控发布环节的必要性
攻防实测复盘:协议劫持漏洞成因解析无人机接管攻击的本质不是高危漏洞,而是协议与生俱来的默认信任逻辑。近期多项低空攻防实测中,攻击者依托通用射频采集设备,即可持续捕获空口无线交互数据,实现对飞行设备的非正常控…...

数据结构——带懒标记的线段树
一、什么是线段树?线段树是一种二叉树数据结构,用于高效地处理区间查询和区间更新操作。核心思想:将数组分成若干个区间(线段),每个节点代表一个区间,通过合并子节点的信息来得到父节点的信息。…...

Taotoken Token Plan套餐如何帮助个人开发者控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐如何帮助个人开发者控制预算 应用场景类,聚焦个人开发者或学生用户,其AI调用需求波…...
)
别再死记硬背了!用Unity可视化工具一步步拆解A*寻路算法(附完整C#源码)
用Unity可视化工具玩转A*寻路算法:从理论到实战的沉浸式学习 在游戏开发的世界里,路径规划算法就像是一位隐形的向导,决定着NPC如何绕过障碍物找到玩家,或是战略游戏中单位如何选择最优行军路线。A*算法作为其中最耀眼的明星&…...

终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查
终极指南:如何用Continue实现AI驱动的代码检查与PR自动化审查 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue Contin…...

vue3+python基于Django框架的铁路博物馆展览系统的设计与实现67350649
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键技术实现部署方案项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目背景 …...

Unity军事资源包的战术语义架构与实战集成指南
1. 这个资源包不是“拿来就能用”的万能钥匙,而是需要你亲手校准的战术装备“POLYGON Military”——光看名字,很多人第一反应是:Unity Asset Store上那个标着“POLYGON”风格、封面全是迷彩涂装M4和悍马车的军事资源包。它确实存在ÿ…...

影刀RPA跨境店群运营架构:TikTok Shop矩阵多节点高并发调度与Python环境隔离实战
大家好,我是林焱。 太有意思了,刚刷朋友圈,看到一个在跨境圈子里被疯狂转发的消息。 有几个当年和我一样,在职业技术学院念工程出身的 00 后学弟,最近跑回母校干了件特别硬核的事。 他们没有像传统的成功校友那样&a…...