机器学习 | 如何利用集成学习提高机器学习的性能?
目录
初识集成学习
Bagging与随机森林
Otto Group Product(实操)
Boosting集成原理
初识集成学习
集成学习(Ensemble Learning)是一种通过组合多个基本模型来提高预测准确性和泛化能力的机器学习方法。它通过将多个模型的预测结果进行整合或投票来做出最终的预测决策。

集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的。
Bagging与随机森林
Bagging(Bootstrap Aggregating)是一种常见的集成学习方法,旨在通过构建多个基本模型并对它们的预测结果进行组合来提高整体性能。
Bagging的关键思想在于通过对训练数据集的重采样,生成多个相互独立的基本模型,并利用这些模型的集体智慧来提高整体的预测准确性和泛化能力。由于每个基本模型都是在不同的数据子集上独立训练的,因此可以减小模型之间的相关性,从而减少过拟合的风险。
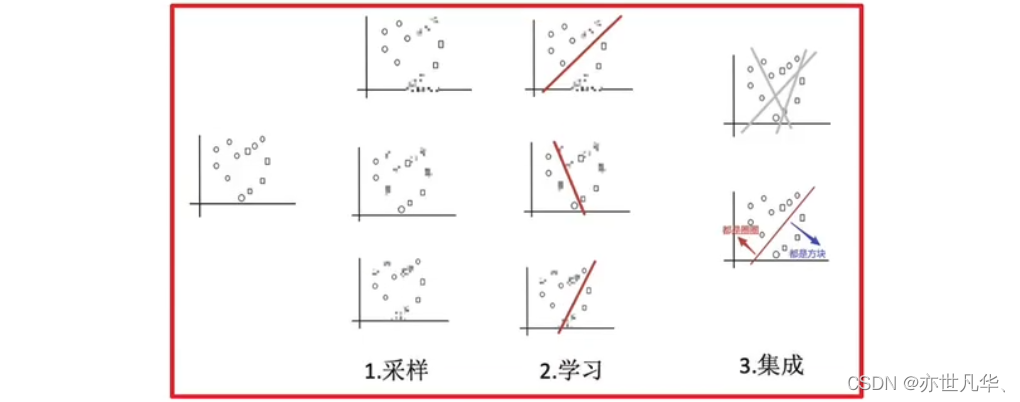
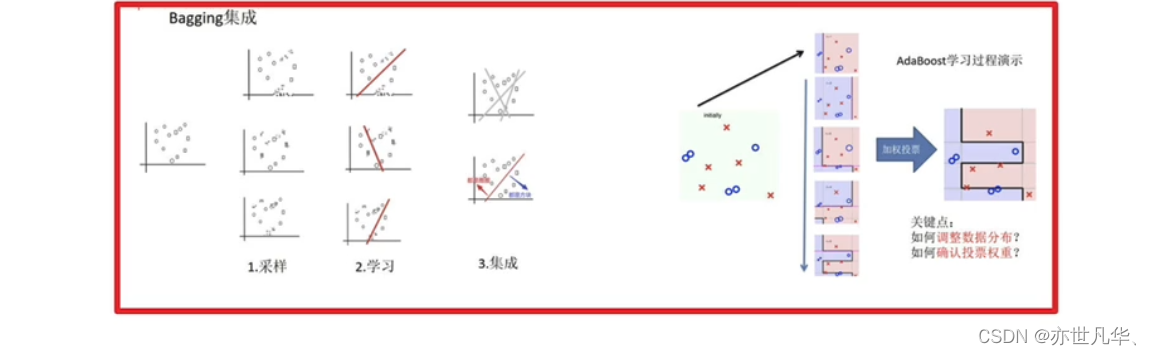
如下我们想把圆和方块进行分类:
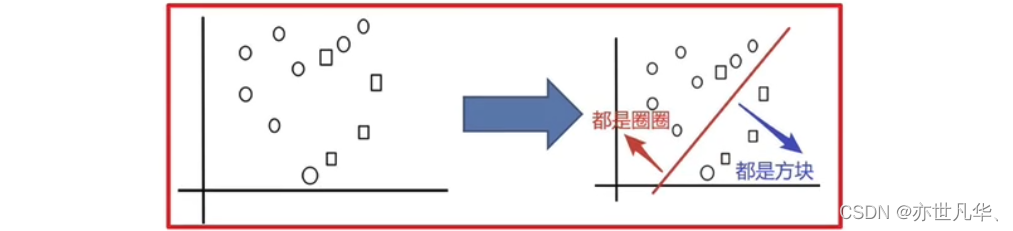
接下来采样不同的数据集:
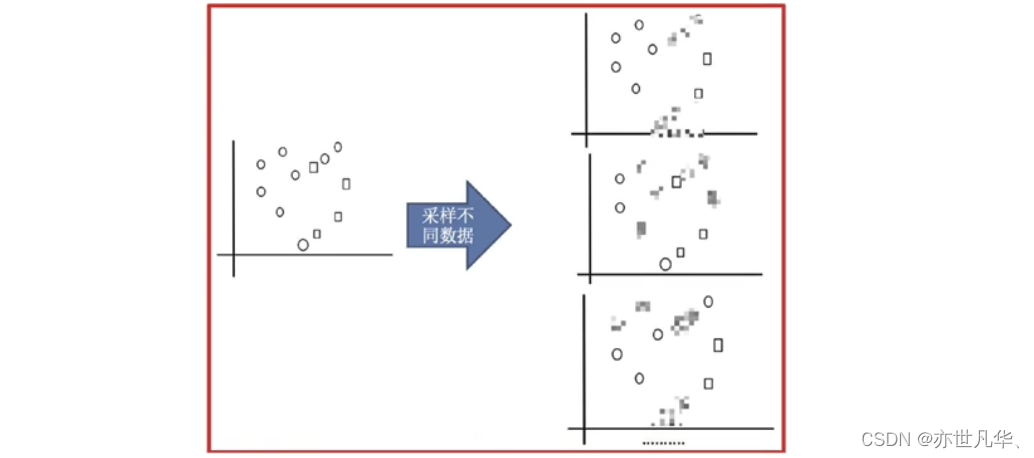
接下来训练分类器:
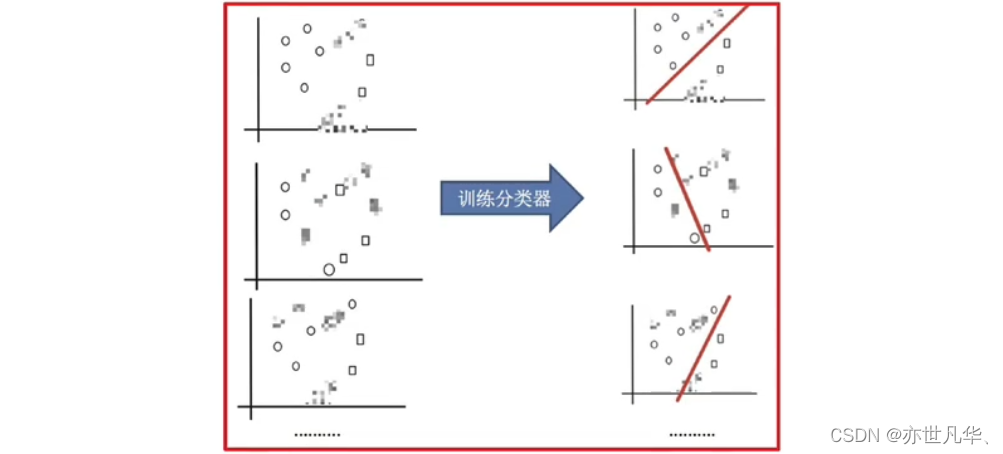
平均投票,获取最终结果:
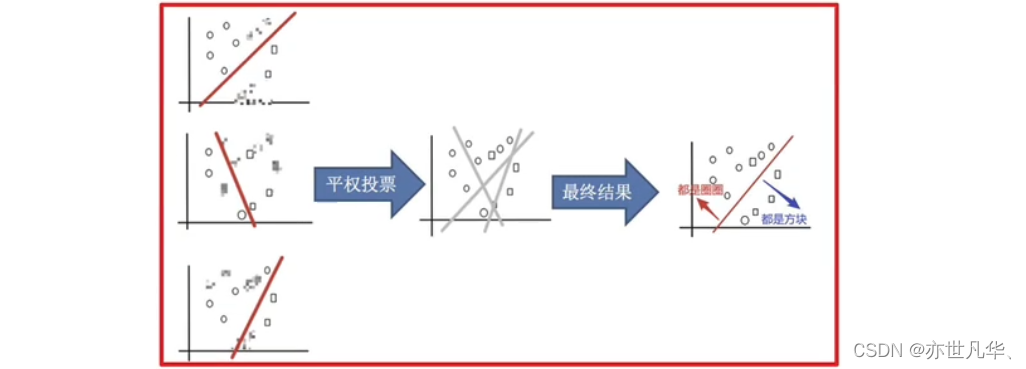
主要实现过程总结:
随机森林:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。随机森林 = Bagging + 决策树 :
例如,如果你训练了5个树,其中有4个树的结果是True,1个树的结果是False,那么最终投票结果就是True

随机森林够造过程中的关键步骤(M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2)随机去选出m个特征,m<<M,建立决策树
在随机森林构造过程中,如果进行有放回的抽样,我们会发现,总是有一部分样本我们选不到。随机森林的Bagging过程,对于每一颗训练出的决策树gt,与数据集D有如下关系:
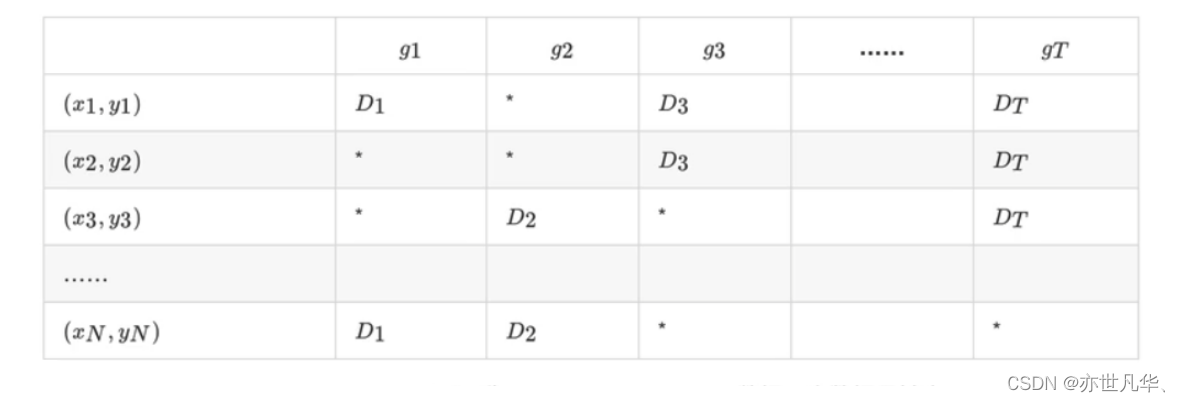
对于星号的部分,即是没有选择到的数据,称之为Out-of-bag(OOB)数据,当数据足够多,对于任意一组数据(n,yn)是包外数据的概率为:
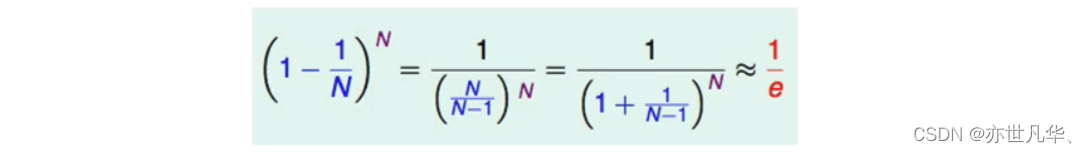
由于基分类器是构建在训练样本的自助抽样集上的,只有约63.2%原样本集出现在中,而剩余的36.8%的数据作为包外数据,可以用于基分类器的验证集。 经验证,包外估计是对集成分类器泛化误差的无偏估计。
1)当基学习器是决策树时,可使用包外样本来辅助剪枝,或用于估计决策树中各结点的后验概率以辅助对零训练样本结点的处理。
2)当基学习器是神经网络时,可使用包外样本来辅助早期停止以减小过拟合。
bagging集成优点:Bagging +决策树/线性回归/逻辑回归/深度学习...= bagging集成学习方法。经过上面方式组成的集成学习方法:1)均可在原有算法上提高约2%左在的泛化正确率 2)简单,方便,通用。
Otto Group Product(实操)
背景介绍:奥托集团是世界上最大的电子商务公司之一,在20多个国家设有子公司。该公司每天都在世界各地销售数百万种产品,所以对其产品根据性能合理的分类非常重要。
不过,在实际工作中,工作人员发现,许多相同的产品得到了不同的分类。本案例要求,你对奥拓集团的产品进行正确的分分类。尽可能的提供分类的准确性。其地址为:地址 。
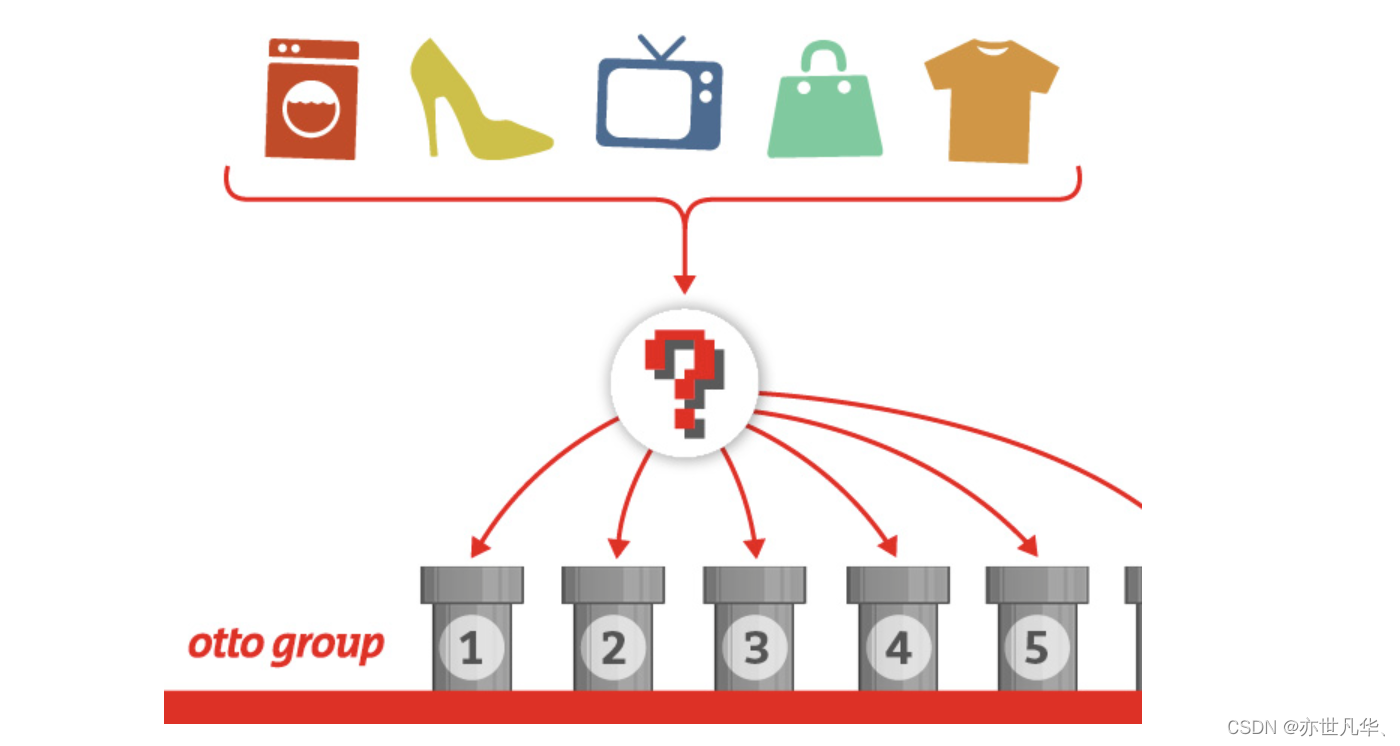
本案例中,数据集包含大约200,000种产品的93个特征。其目的是建立一个能够区分otto公司主要产品类别的预测模型。有产品共被分成九个类别(例如时装,电子产品等),如下:

id — 产品id;feat_1,feat_2,..,feat_93 - 产品的各个特征;target - 产品被划分的类别
本案例中,最后结果使用多分类对数损失进行评估。
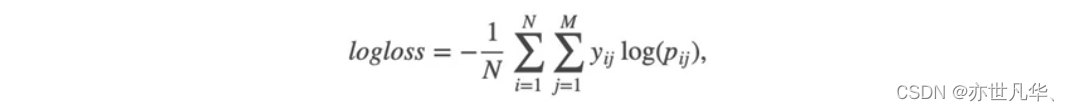

接下来通过代码进行实现,以下是实现本次案例的相关重要操作:
数据获取:
# 导入第三方库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns获取数据集数据,对数据进行一个查看:
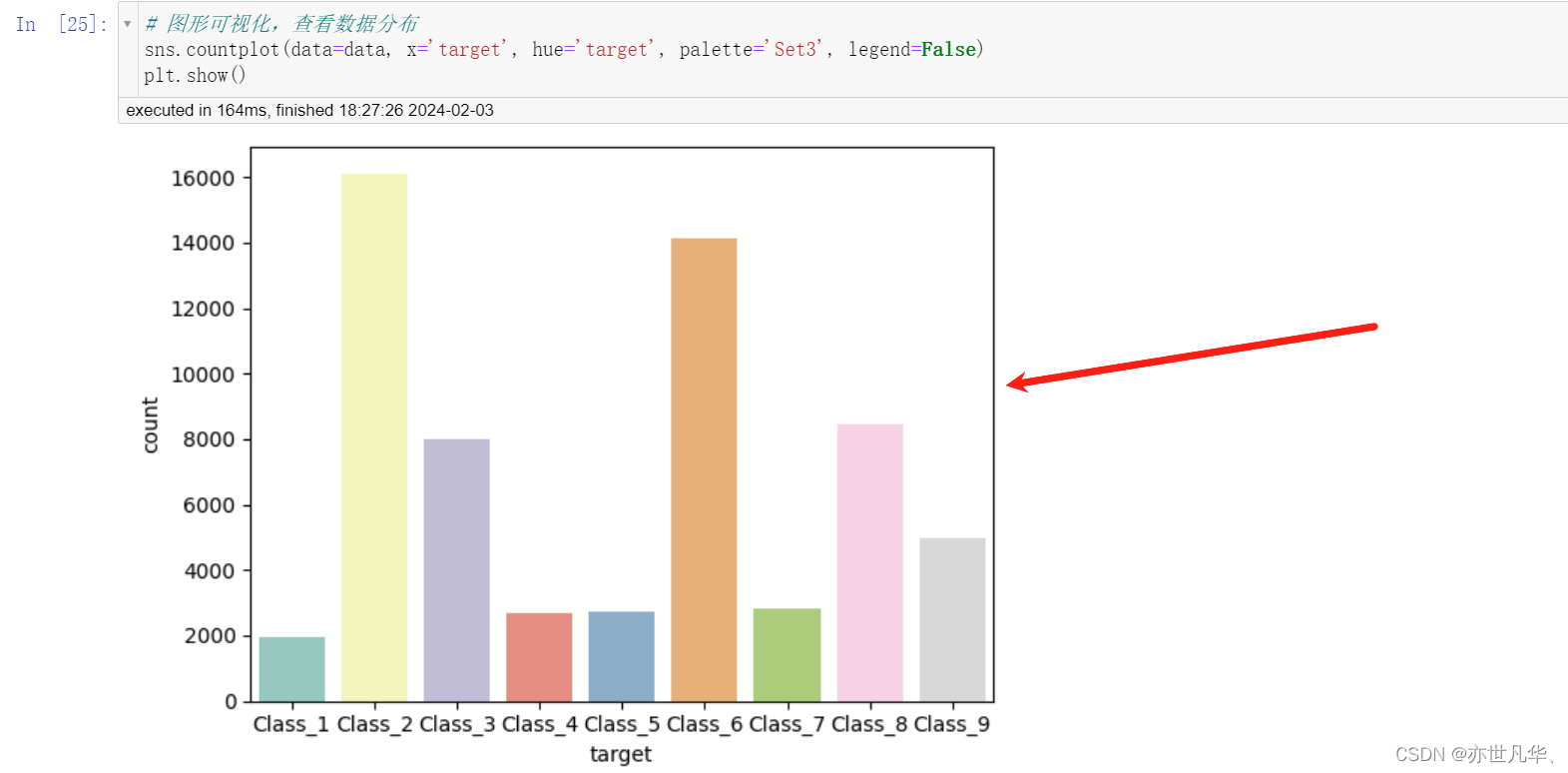
通过seaborn可视化库,可以看到我们数据类别不均衡
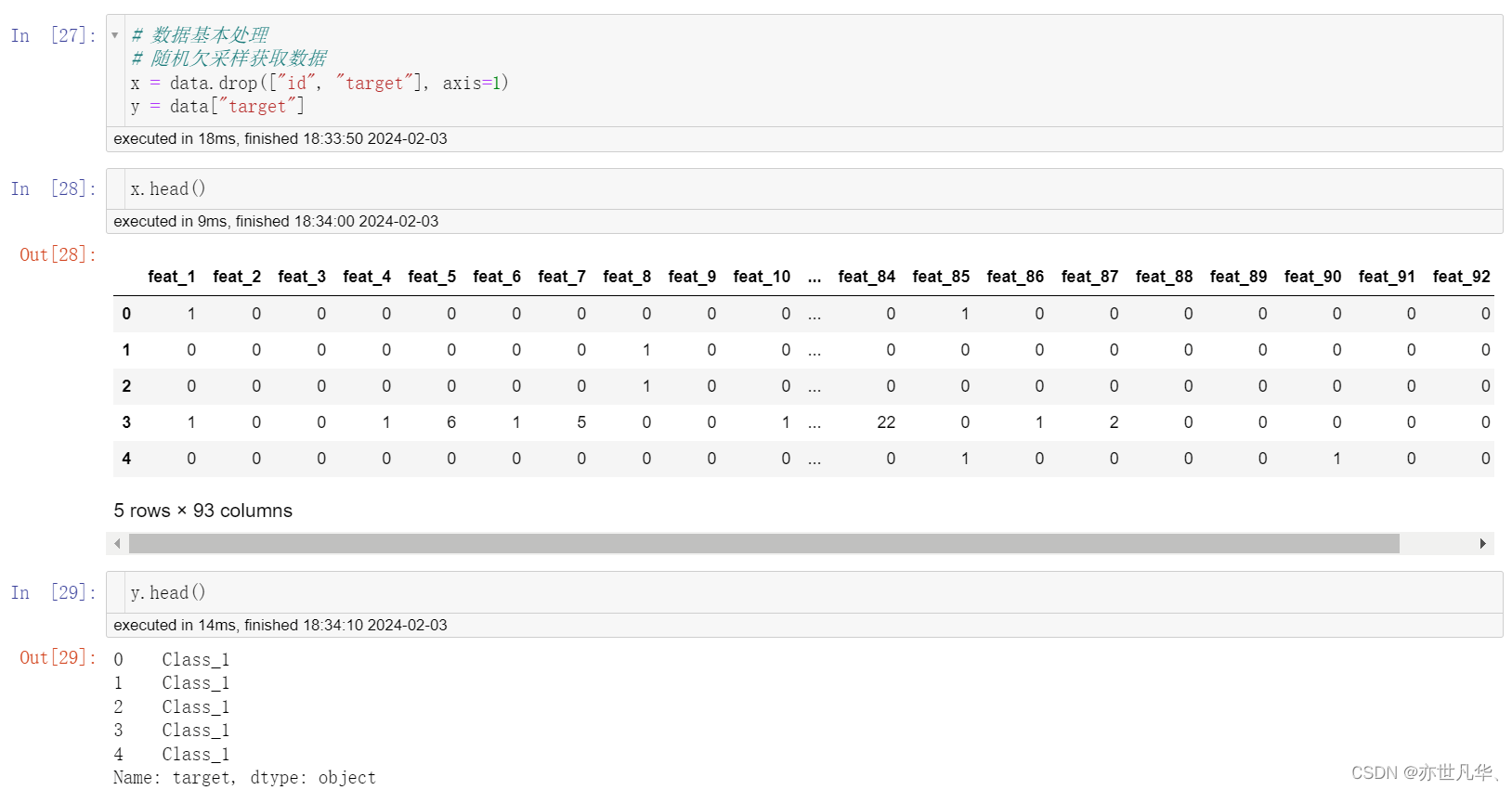
数据基本处理:
接下来通过随机欠采样获取数据:
接下来通过这段代码的作用是从imblearn库中导入RandomUnderSampler类,用于进行随机欠采样(Random Under Sampling)。如果没有该库,终端执行如下命令进行安装:
pip install imbalanced-learn -i https://pypi.mirrors.ustc.edu.cn/simple
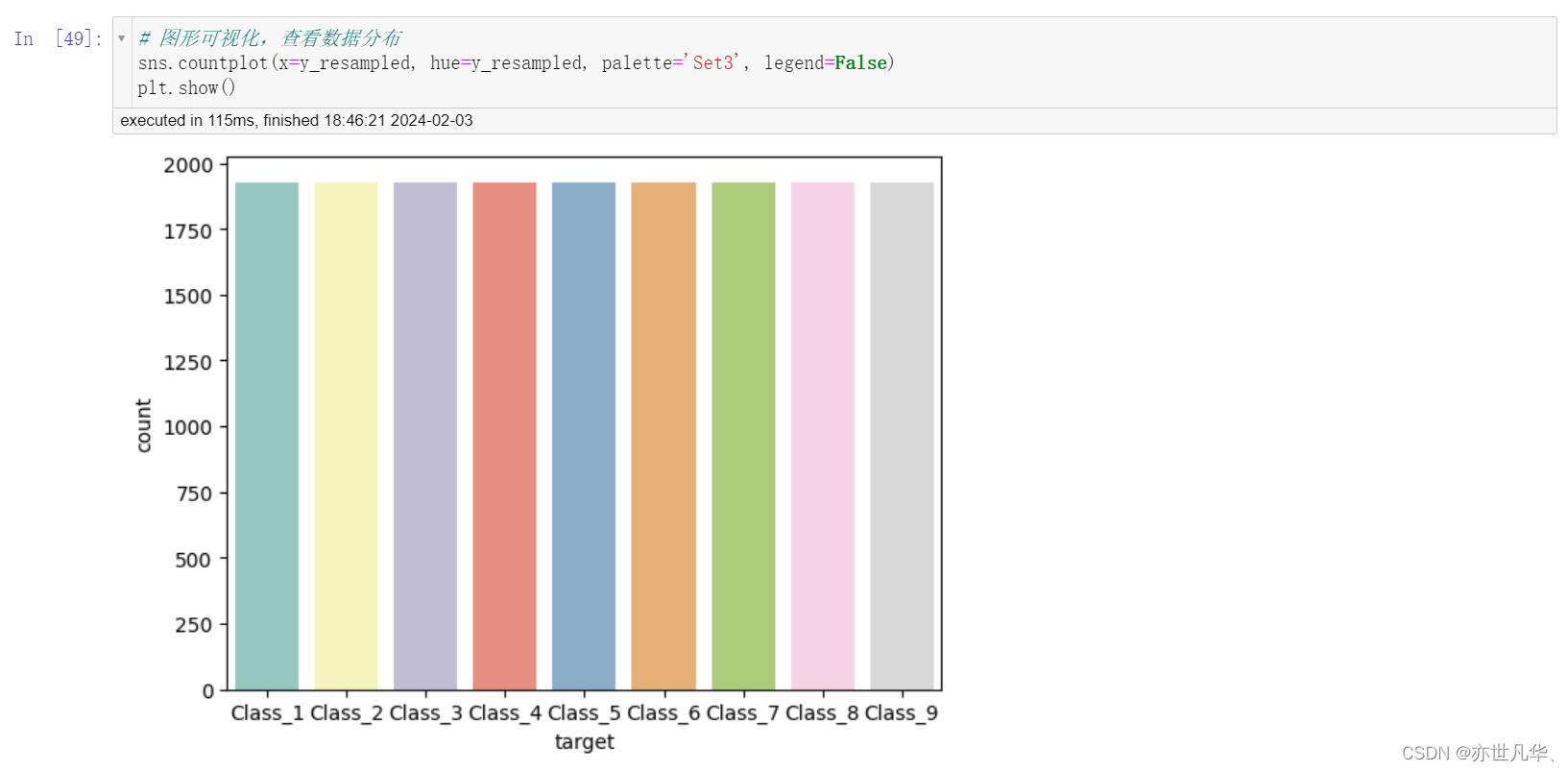
通过图形可视化查看数据:
接下来把标签数据转化为数字:

开始分割数据:

模型训练:
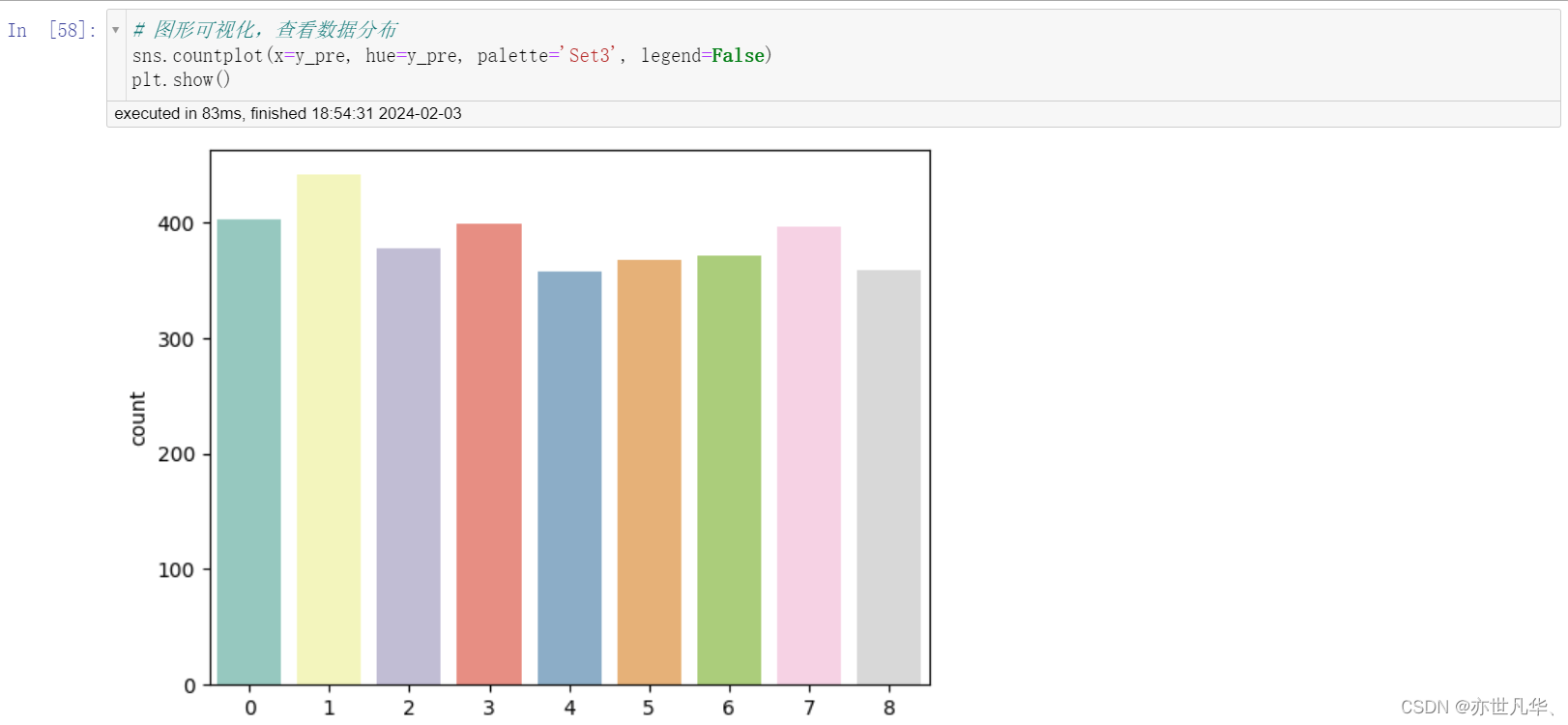
通过可视化查看数据变化:
模型评估:
使用OneHotEncoder对象对y_pre进行独热编码转换。y_pre也是一个一维数组,通过reshape(-1, 1)转换为二维列向量的形式,并使用fit_transform方法进行独热编码转换。最后,将转换后的编码结果赋值给y_pre1。
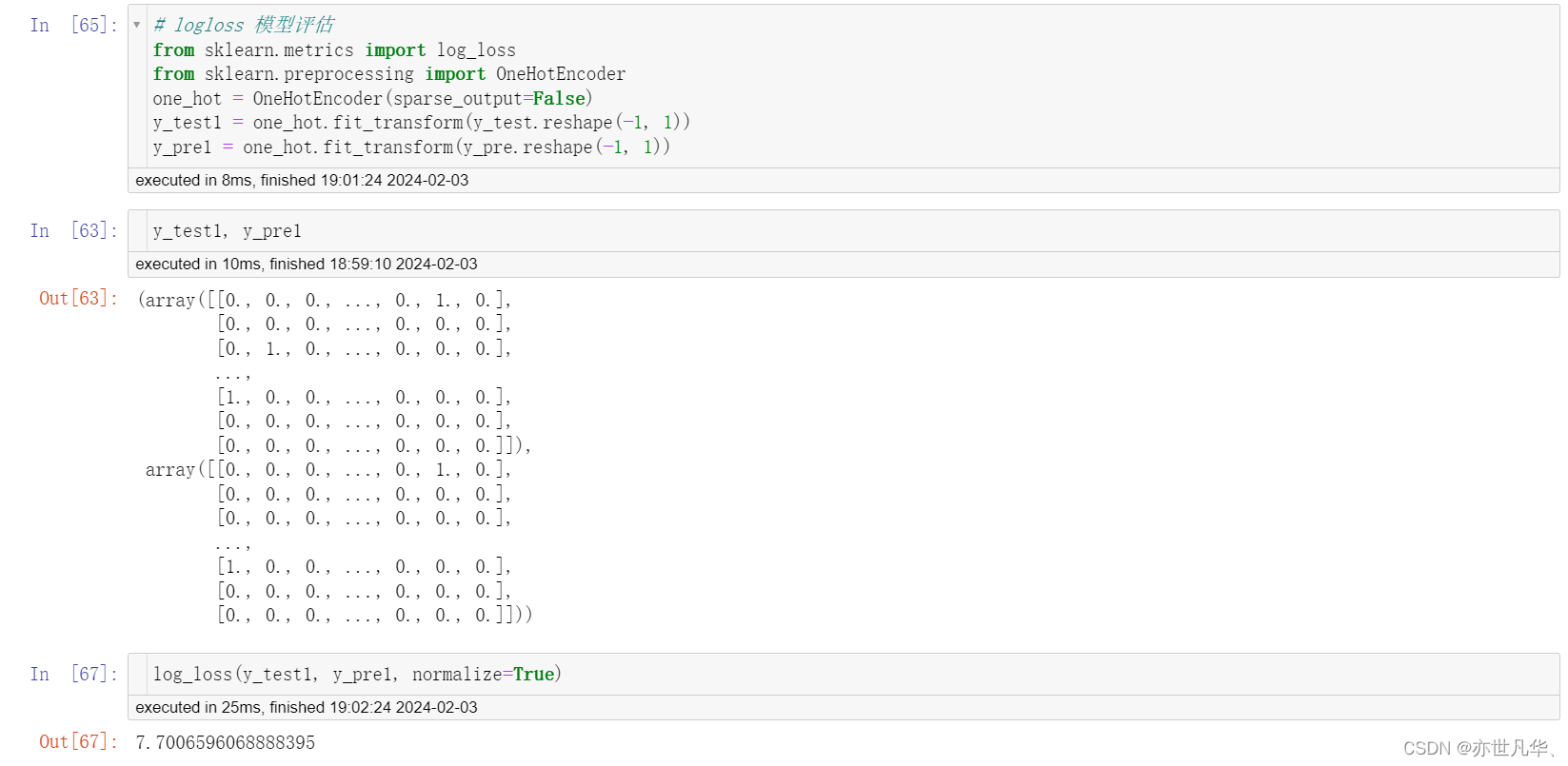
rf是一个随机森林分类器对象,通过调用predict_proba方法,将测试集x_test作为输入,返回了每个样本所属于每个类别的概率估计值。
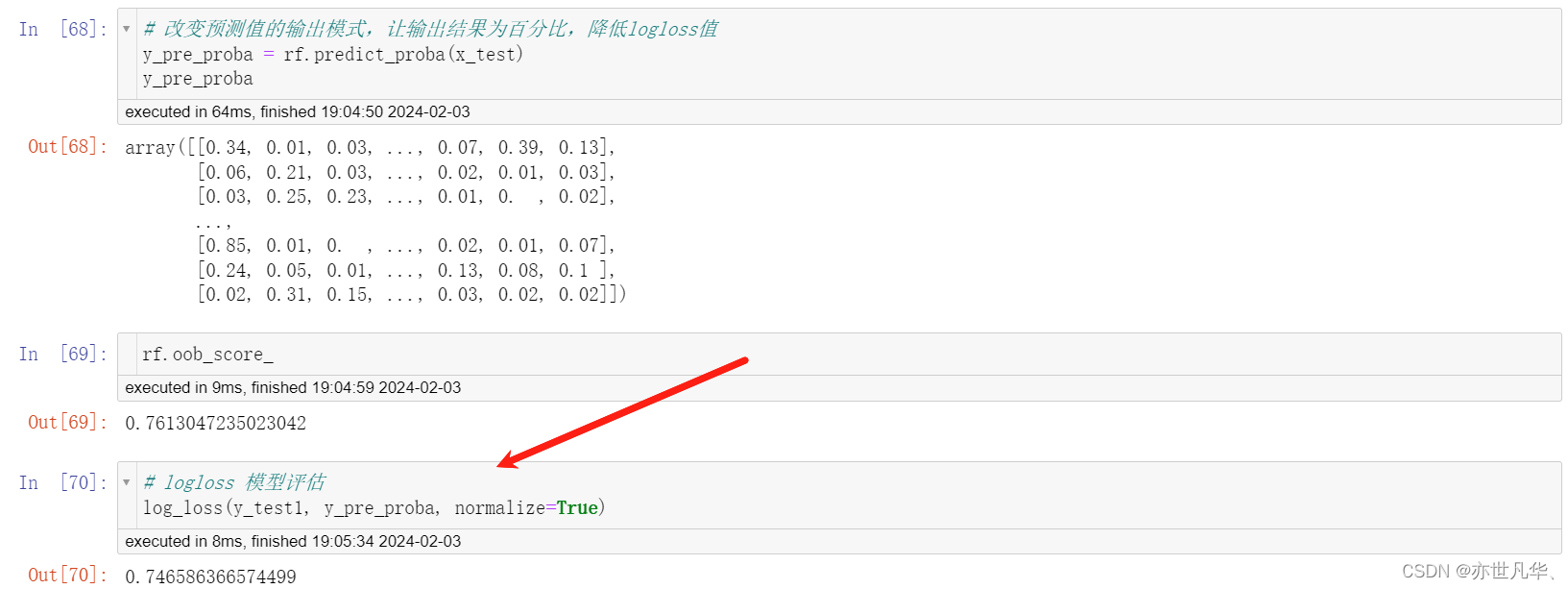
模型调优:
在机器学习中,模型调优的目的是通过对模型参数的设置和调整来提高模型的性能,接下来对模型调优的超参数进行测试:
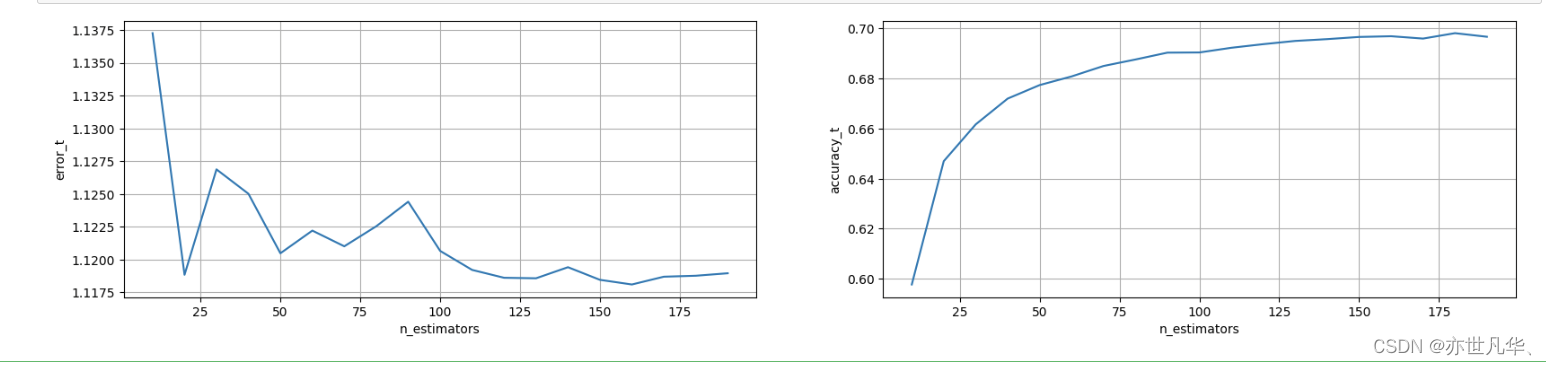
# 模型调优——确定最优的 n_estimators
# 确定n_estimators的取值范围
tuned_parameters = range(10, 200, 10)
# 创建添加accuracy的一个numpy
accuracy_t=np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy
error_t=np.zeros(len(tuned_parameters))
# 调优过程实现
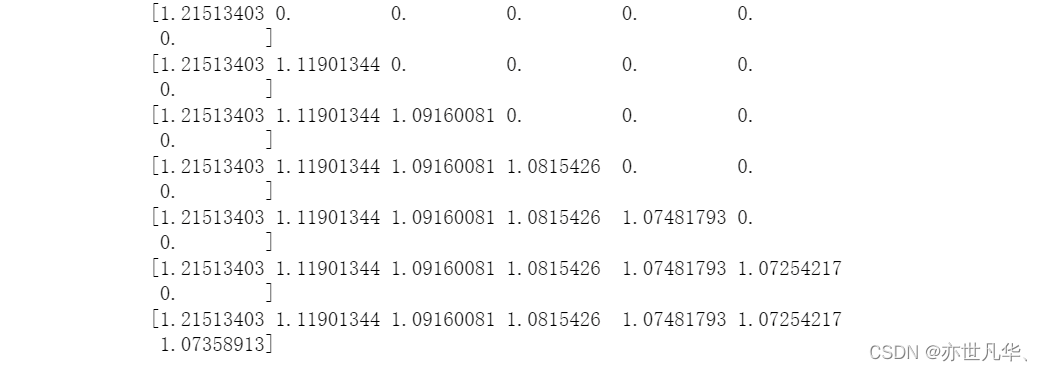
for j,one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=one_parameter, max_depth=10, max_features=10, min_samples_leaf=10, oob_score=True, random_state=0, n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, normalize=True)print(error_t)得出的结果如下:

#优化结果过程可视化
fig,axes =plt.subplots(nrows=1,ncols=2,figsize=(20, 4), dpi=100)axes[0].plot(tuned_parameters,error_t)
axes[1].plot(tuned_parameters,accuracy_t)axes[0].set_xlabel("n_estimators")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("n_estimators")
axes[1].set_ylabel("accuracy_t")axes[0].grid(True)
axes[1].grid(True)plt.show()经过图像展示,最后确定n_estimators=175的时候,表现效果不错
# 模型调优——确定最优的max_features
# 确定n_estimators的取值范围
tuned_parameters = range(5, 40, 5)
# 创建添加accuracy的一个numpy
accuracy_t=np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy
error_t=np.zeros(len(tuned_parameters))
# 调优过程实现
for j,one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=175, max_depth=10, max_features=one_parameter, min_samples_leaf=10, oob_score=True, random_state=0, n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, normalize=True)print(error_t)得出的结果如下:
#优化结果过程可视化
fig,axes =plt.subplots(nrows=1,ncols=2,figsize=(20, 4), dpi=100)axes[0].plot(tuned_parameters,error_t)
axes[1].plot(tuned_parameters,accuracy_t)axes[0].set_xlabel("max_features")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("max_features")
axes[1].set_ylabel("accuracy_t")axes[0].grid(True)
axes[1].grid(True)plt.show()经过图像展示,最后确定max_feature=15的时候,表现效果不错

# 模型调优——确定最优的max_depth
# 确定n_estimators的取值范围
tuned_parameters = range(10, 100, 10)
# 创建添加accuracy的一个numpy
accuracy_t=np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy
error_t=np.zeros(len(tuned_parameters))
# 调优过程实现
for j,one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=175, max_depth=one_parameter, max_features=15, min_samples_leaf=10, oob_score=True, random_state=0, n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, normalize=True)print(error_t)得出的结果如下:
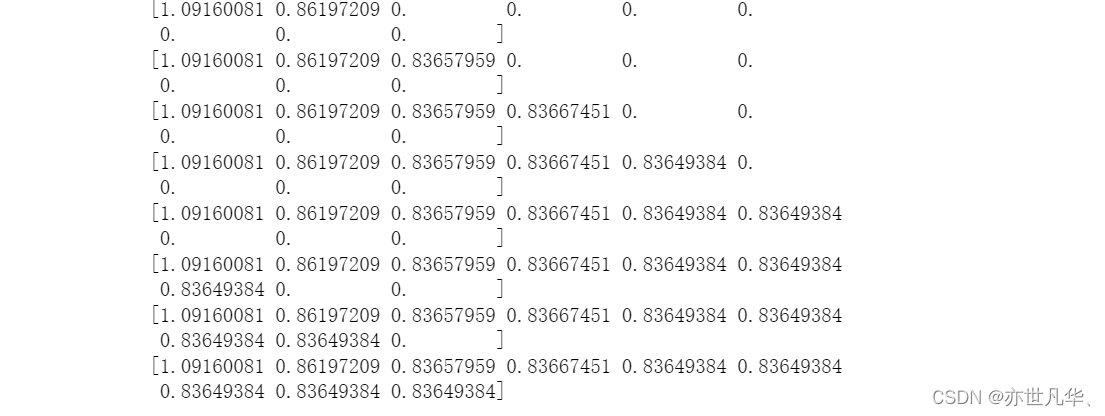
#优化结果过程可视化
fig,axes =plt.subplots(nrows=1,ncols=2,figsize=(20, 4), dpi=100)axes[0].plot(tuned_parameters,error_t)
axes[1].plot(tuned_parameters,accuracy_t)axes[0].set_xlabel("max_depth")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("max_depth")
axes[1].set_ylabel("accuracy_t")axes[0].grid(True)
axes[1].grid(True)plt.show()经过图像展示,最后确定max_depth=30的时候,表现效果不错

# 模型调优——确定最优的min_sample_leaf
# 确定n_estimators的取值范围
tuned_parameters = range(1, 10, 2)
# 创建添加accuracy的一个numpy
accuracy_t=np.zeros(len(tuned_parameters))
# 创建添加error的一个numpy
error_t=np.zeros(len(tuned_parameters))
# 调优过程实现
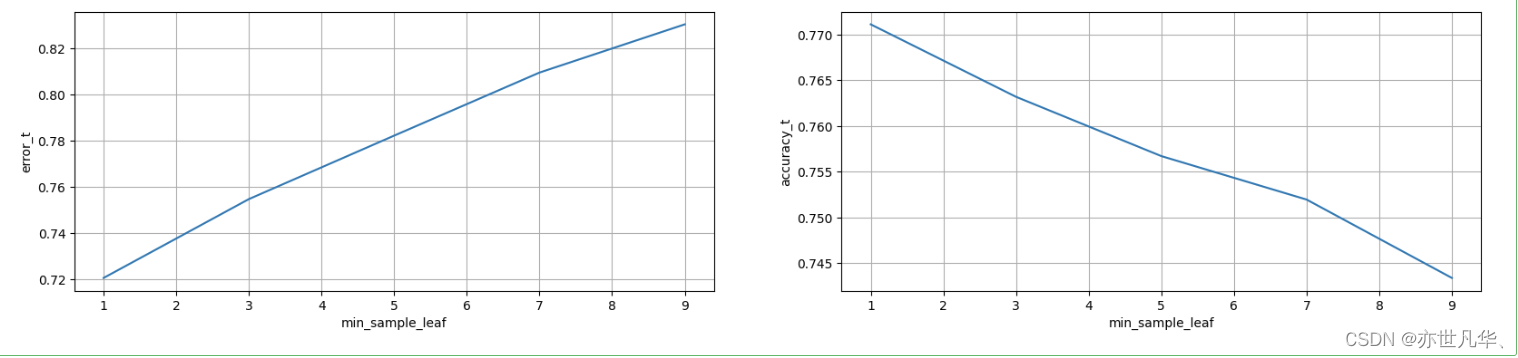
for j,one_parameter in enumerate(tuned_parameters):rf2 = RandomForestClassifier(n_estimators=175, max_depth=30, max_features=15, min_samples_leaf=one_parameter, oob_score=True, random_state=0, n_jobs=-1)rf2.fit(x_train, y_train)# 输出accuracyaccuracy_t[j] = rf2.oob_score_# 输出log_lossy_pre = rf2.predict_proba(x_test)error_t[j] = log_loss(y_test, y_pre, normalize=True)print(error_t)得出的结果如下:

#优化结果过程可视化
fig,axes =plt.subplots(nrows=1,ncols=2,figsize=(20, 4), dpi=100)axes[0].plot(tuned_parameters,error_t)
axes[1].plot(tuned_parameters,accuracy_t)axes[0].set_xlabel("min_sample_leaf")
axes[0].set_ylabel("error_t")
axes[1].set_xlabel("min_sample_leaf")
axes[1].set_ylabel("accuracy_t")axes[0].grid(True)
axes[1].grid(True)plt.show()经过图像展示,最后确定min_sample_leaf=1的时候,表现效果不错
由此我们确定了最有的模型数据为:
n_estimators=175;max_depth=30;max_features=15;min_samples_leaf=1
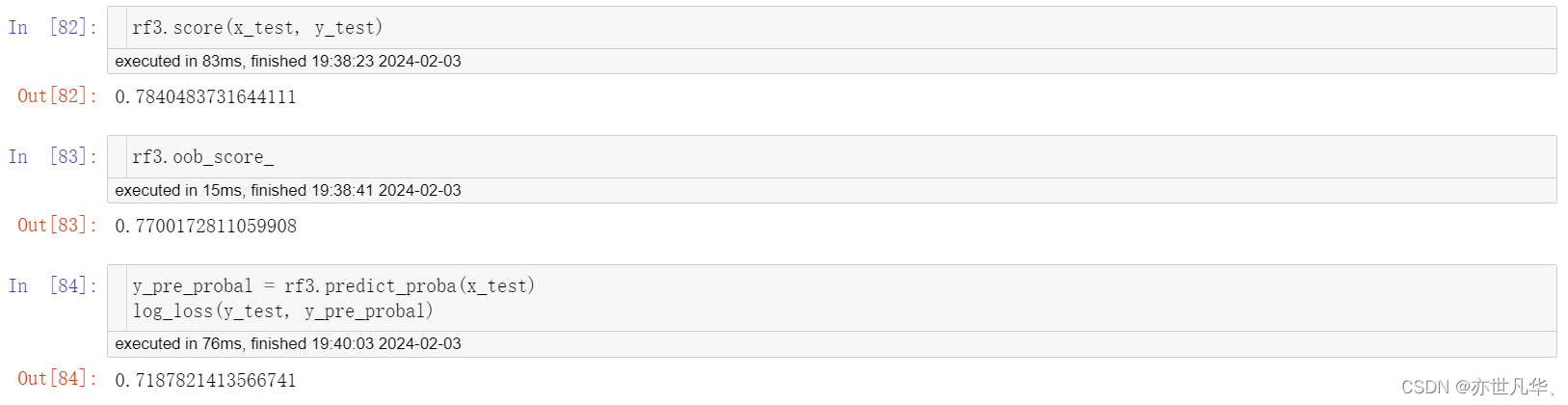
通过获得到的具体的数据,再次模型训练:
rf3 = RandomForestClassifier(n_estimators=175, max_depth=30, max_features=15, min_samples_leaf=1, oob_score=True, random_state=40, n_jobs=-1)
rf3.fit(x_train, y_train)最终获得到的数据如下:
提交最终结果:
我们根据kaggle平台竞赛要求我们提交的格式进行对最终结果的数据处理:
这里我们先把id这一列数据删掉:

接下来对数据进行处理:
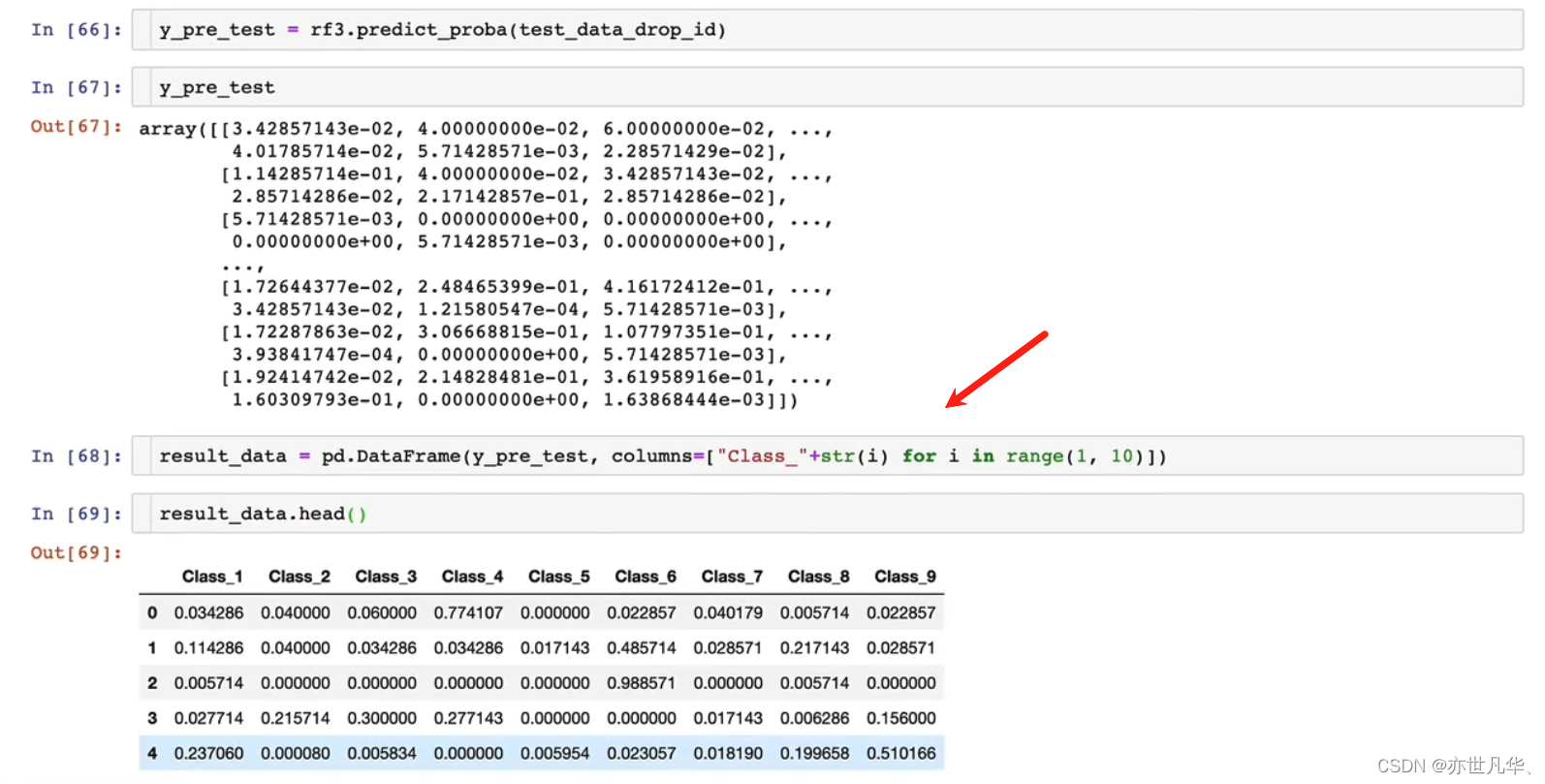
接下来我们在第一列添加一个id属性,然后把数据进行保存:
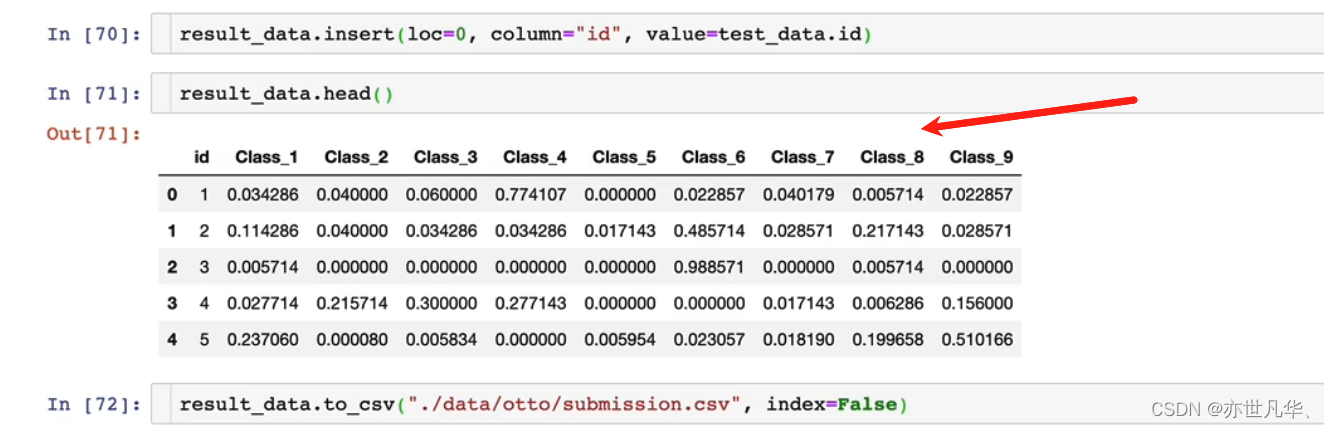
回到我们的浏览器,找到相应的位置就能看到我们保存好的文件,然后回到kaggle网站上提交作品即可:

Boosting集成原理
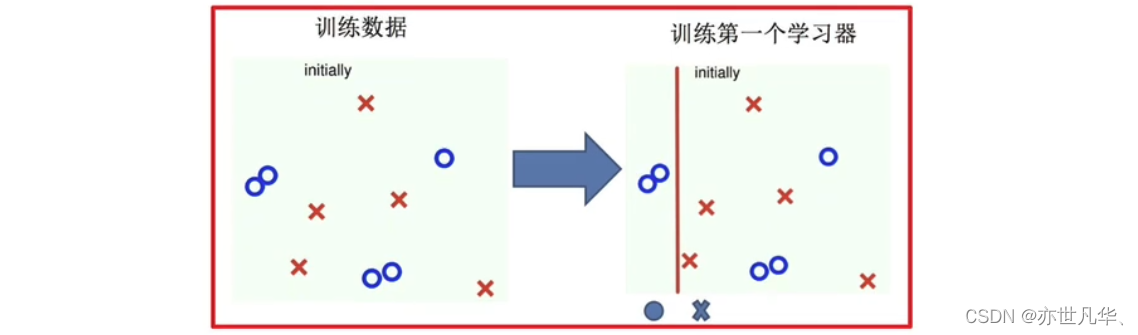
Boosting是一种常见的集成学习方法,它通过串行地训练多个弱分类器(或回归器)并将它们合并为一个强分类器(或回归器)。Boosting的核心思想是依次训练模型,每一次训练都会调整样本的权重,使得前一轮中被错误分类的样本在下一轮中得到更多的关注。因此,Boosting可以在弱分类器的基础上构建出准确度更高的强分类器。
简而言之:随着学习的积累从弱到强,每新加入一个弱学习器,整体能力就会得到提升。其代表算法:Adaboost,GBDT,XGBoost,LightGBM等。其训练的实现过程如下:
训练第一个学习器:
调整数据分布:
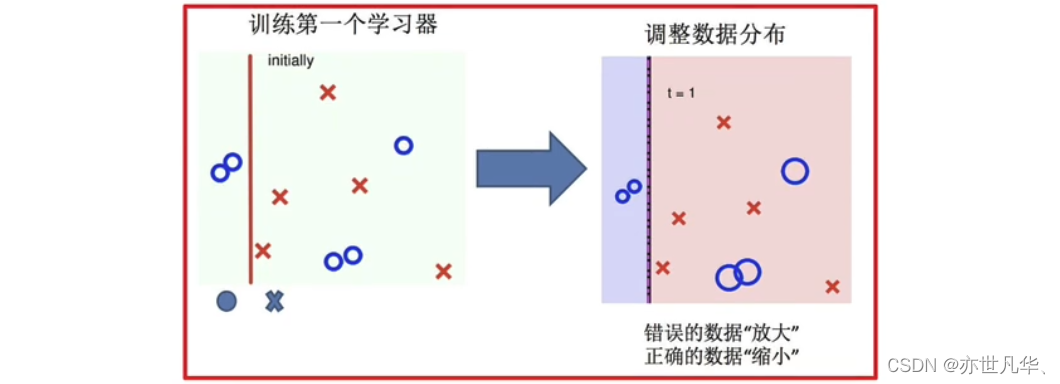
训练第二个学习器:
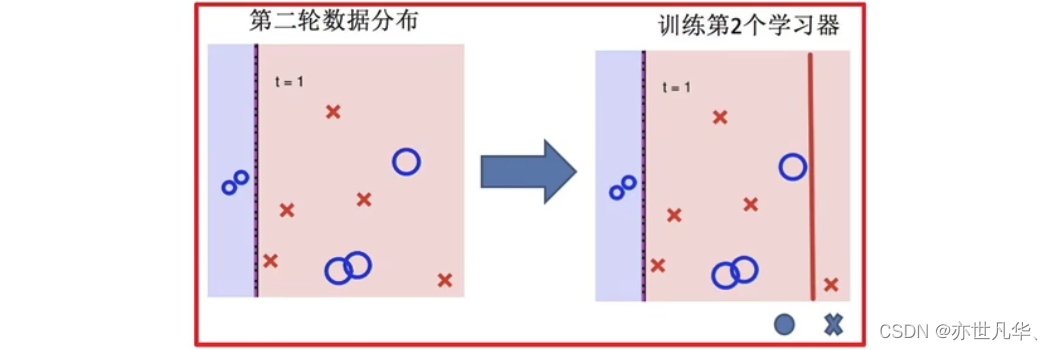
再次调整分布:
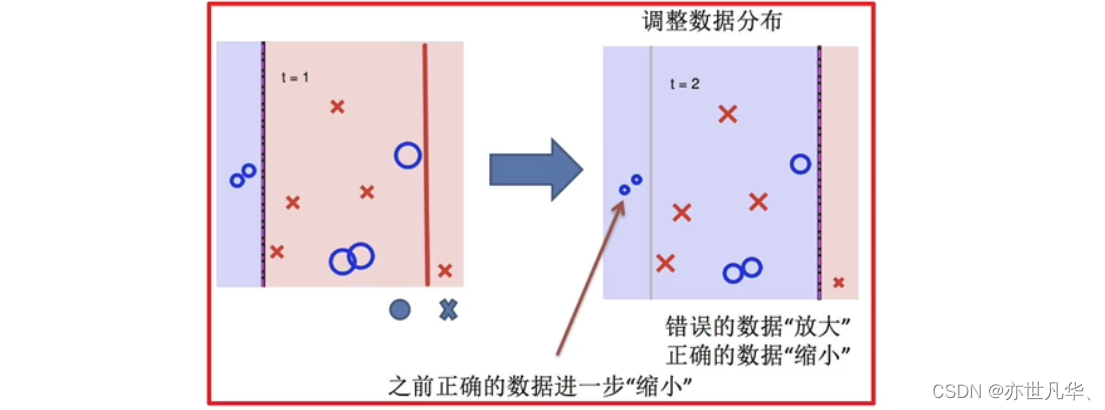
依次训练学习器,调整数据分布:
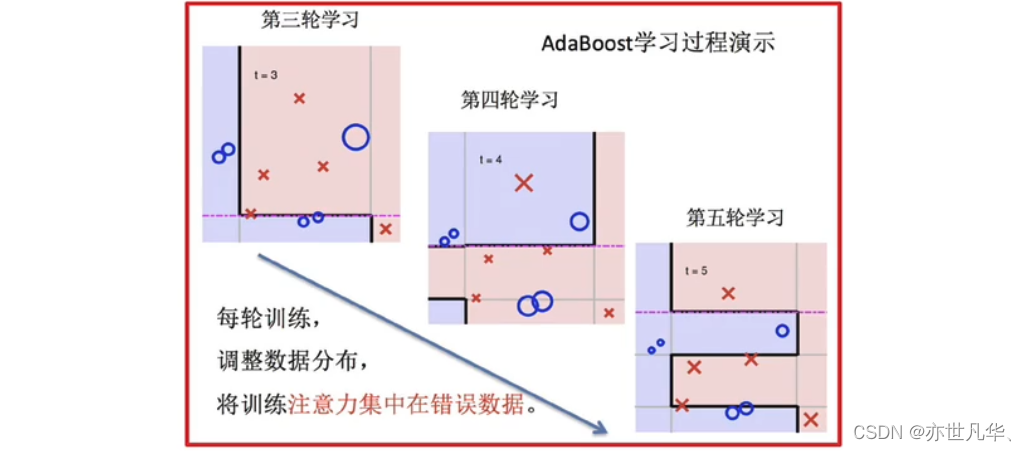
整体实现过程:
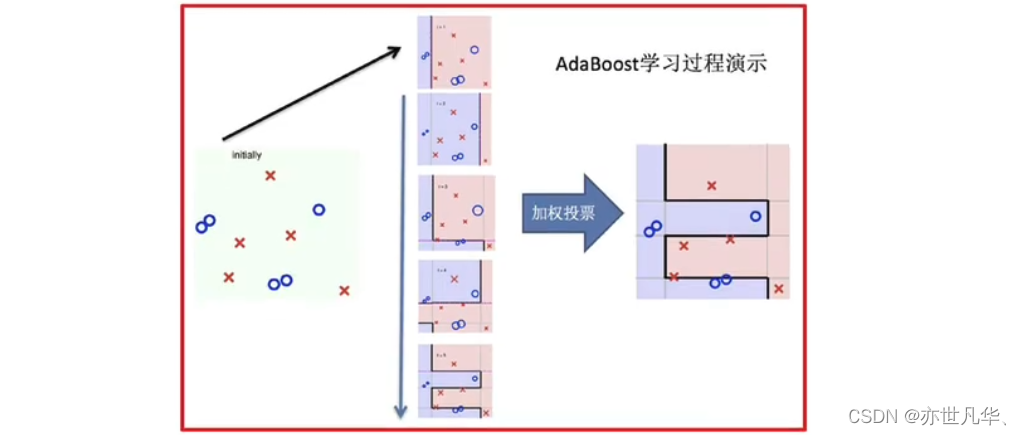
bagging集成与boosting集成的区别:
1)数据方面:
Bagging:对数据进行采样训练;Boosting:根据前一轮学习结果调整数据的重要性。
2)投票方面:
Bagging:所有学习器平权投票;Boosting:对学习器进行加权投票。
3)学习顺序:
Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序。
4)主要作用:
Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差);
Boosting主要用于提高训练精度(解决欠拟合,也可以说降低偏差)
Adaboost介绍:




GBDT介绍:


XGBoost介绍:

LightGBM介绍:
LightGBM是一个基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的机器学习框架。它是由微软开发的高效、分布式的梯度提升框架,以速度快和高准确率而闻名。
LightGBM的设计目标是解决大规模数据集和高维特征的机器学习问题。它在传统的梯度提升决策树算法的基础上进行了优化,引入了一些创新的技术和策略,以提供更好的性能和可扩展性。
相关文章:
机器学习 | 如何利用集成学习提高机器学习的性能?
目录 初识集成学习 Bagging与随机森林 Otto Group Product(实操) Boosting集成原理 初识集成学习 集成学习(Ensemble Learning)是一种通过组合多个基本模型来提高预测准确性和泛化能力的机器学习方法。它通过将多个模型的预测结果进行整合或投票来做…...

[Python] 什么是PCA降维技术以及scikit-learn中PCA类使用案例(图文教程,含详细代码)
什么是维度? 对于Numpy中数组来说,维度就是功能shape返回的结果,shape中返回了几个数字,就是几维。索引以外的数据,不分行列的叫一维(此时shape返回唯一的维度上的数据个数),有行列…...

npm 淘宝镜像正式到期,更新使用成功
npm 淘宝镜像原网址:https://registry.npm.taobao.org/ npm 淘宝镜像更新后网址:https://registry.npmmirror.com 过程: 部署 nuxt docker 容器的时候,报以下错: npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CE…...
python_蓝桥杯刷题记录_笔记_全AC代码_入门2
前言 现在正式进入蓝桥杯的刷题啦,用python来做算法题,因为我之前其实都是用C来做题的,但是今年的话我打算换python来试试,很明显因为也才这学期接触python 加上之前C做题也比较菜,所以我打算用python重新来做题&#…...
备战蓝桥杯---数据结构与STL应用(入门4)
本专题主要是关于利用优先队列解决贪心选择上的“反悔”问题 话不多说,直接看题: 下面为分析: 很显然,我们在整体上以s[i]为基准,先把士兵按s[i]排好。然后,我们先求s[i]大的开始,即规定选人数…...
2023_12蓝桥杯STEMA 考试 Scratch 中级试卷解析
2023蓝桥杯STEMA 考试 Scratch 中级试卷(12 月)解析 由于没有原始文件,这里使用的角色和背景和实际题目会有所差异,已经尽量还原原题,以下代码仅供参考。吐槽一句:蓝桥杯越来越变态了!\(`Δ’)/\(`Δ’)/\(`Δ’)/孩子学习速度永远也赶不上内卷的速度。 一、选择…...

从编程中理解:大脑中的杏仁核
编程和神经科学在某种程度上可以相互借鉴,尤其是在模拟大脑功能时。让我们以Unity游戏引擎中的C#代码为例,结合金庸武侠小说中的人物形象来构建一个类比故事,探讨如何通过编程模拟大脑中杏仁核的作用。 假设在一款名为“脑海江湖”的Unity游戏中,主角张无忌(代指玩家角色…...
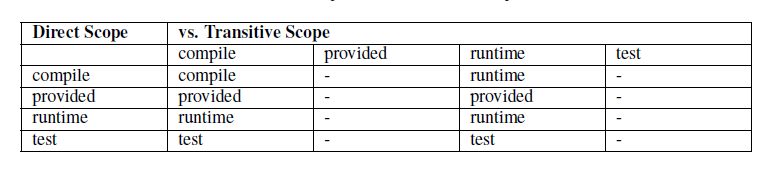
Maven dependency中的scope
Maven的一个哲学是惯例优于配置(Convention Over Configuration), Maven默认的依赖配置项中,scope的默认值是compile。 scope的分类 compile(默认) 含义: compile 是默认值,如果没有指定 scope 值,该元素…...

代码随想录算法训练营DAY11 | 栈与队列 (2)
一、LeetCode 20 有效的括号 题目链接:20.有效的括号https://leetcode.cn/problems/valid-parentheses/ 思路:遇到左括号直接进栈;遇到右括号判断站顶是否有匹配的括号,没有就返回flase,有就将栈顶元素出栈࿱…...

【Spring实战】33 Spring Boot3 集成 Nacos 配置中心
文章目录 1. 配置中心定义2. 解决哪些问题3. 常用的配置中心4. 使用示例1)没引入 Nacos 配置中心2)引入依赖3)配置Nacos连接信息4)在 Nacos 上配置属性5)在 Spring Boot 中使用配置6)启动服务&验证7&am…...
ElementUI安装与使用指南
Element官网-安装指南 提醒一下:下面实例讲解是在Mac系统演示的; 一、开发环境配置 电脑需要先安装好node.js和vue2或者vue3 安装Node.js Node.js 中文网 安装node.js命令:brew install node node.js安装完后,输入࿱…...
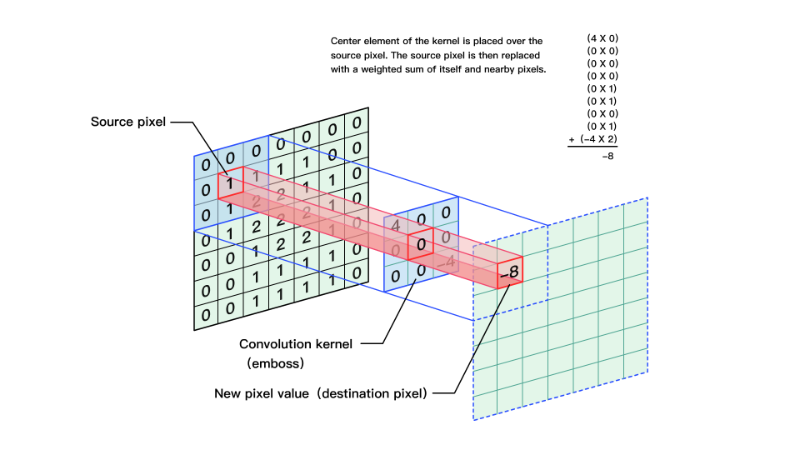
Opencv——图片卷积
图像滤波是尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,是图像预处理中不可缺少的操作,其处理效果的好坏将直接影响到后续图像处理和分析的有效性和可靠性。 线性滤波是图像处理最基本的方法,它允许我们对图像进行处理,产生很多不同的效果。首先,我们需要一个二…...
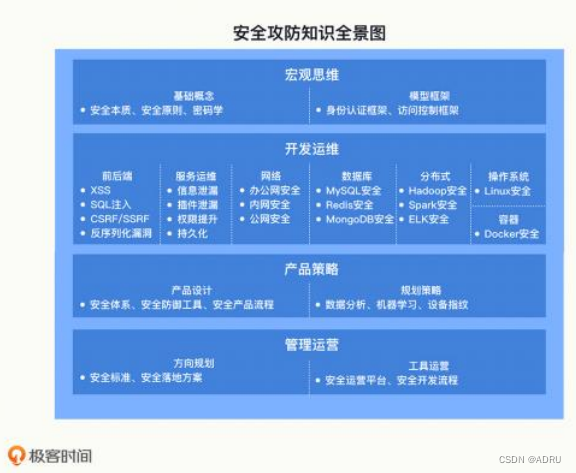
项目安全-----加密算法实现
目录 对称加密算法 AES (ECB模式) AES(CBC 模式)。 非对称加密 对称加密算法 对称加密算法,是使用相同的密钥进行加密和解密。使用对称加密算法来加密双方的通信的话,双方需要先约定一个密钥,加密方才能加密&#…...
只用一台服务器部署上线(宝塔面板) 前后端+数据库
所需材料 工具:安装宝塔面板服务器至少一台、域名一个 前端:生成dist文件(前端运行build命令) 后端:生成jar包(maven运行package命令) 准备: 打开宝塔面板,点击进入软…...

《Pandas 简易速速上手小册》第8章:Pandas 高级数据分析技巧(2024 最新版)
文章目录 8.1 使用 apply 和 map 函数8.1.1 基础知识8.1.2 重点案例:客户数据清洗和转换8.1.3 拓展案例一:产品评分调整8.1.4 拓展案例二:地址格式化 8.2 性能优化技巧8.2.1 基础知识8.2.2 重点案例:大型销售数据分析8.2.3 拓展案…...

计算机网络_1.6.2 计算机网络体系结构分层的必要性
1.6.2 计算机网络体系结构分层的必要性 一、五层原理体系结构每层各自主要解决什么问题1、物理层2、数据链路层3、网络层4、运输层5、应用层 二、总结三、练习 笔记来源: B站 《深入浅出计算机网络》课程 本节主要介绍实现计算机网络需要解决哪些问题?以…...
跟着cherno手搓游戏引擎【18】抽象Shader、项目小修改
抽象: Shader.h: #pragma once #include <string>namespace YOTO {class Shader {public:virtual~Shader()default;virtual void Bind()const0;virtual void UnBind()const0;static Shader* Create(const std::string& vertexSrc, const std::string&am…...

每日OJ题_算法_模拟②_力扣495. 提莫攻击
目录 力扣495. 提莫攻击 解析代码 力扣495. 提莫攻击 495. 提莫攻击 难度 简单 在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 当提莫攻击艾希,…...

freertos 源码分析二 list链表源码
list.c 一、链表初始化 void vListInitialise( List_t * const pxList ) { pxList->pxIndex ( ListItem_t * ) &…...
Peter算法小课堂—Dijkstra最短路算法
大家好,我们人见人爱、花见花开、车见车爆胎的Peter Pan来啦,hia~hia~hia。今天,我们今天来学习毒瘤的最短路算法啦。啊这……什么是Dijkstra算法?长文警告⚠ 正经点啊 手算样例 大家思考一下,你在手算样例的时候&am…...

SEO_本地商家必备的SEO实战方法
SEO对本地商家的重要性 在当今数字化时代,为了在竞争激烈的市场中脱颖而出,本地商家必须掌握一些SEO(搜索引擎优化)技巧。SEO不仅可以提升网站的搜索引擎排名,还能够有效地吸引更多的本地客户。本文将详细探讨本地商家…...

DeerFlow GPU算力优化:vLLM加速Qwen3-4B推理性能调优
DeerFlow GPU算力优化:vLLM加速Qwen3-4B推理性能调优 1. 引言:当深度研究遇上推理瓶颈 想象一下,你正在使用一个强大的AI研究助手,它能帮你搜索资料、分析数据、撰写报告,甚至生成播客。但每次你提出一个稍微复杂点的…...

避免技术债:Agent 代码库的模块化设计与工程规范
避免技术债:Agent 代码库的模块化设计与工程规范 关键词 Agent技术栈、技术债消解、模块化第一性原理、分层-事件驱动架构、多Agent协作规范、DevOps for AI Agents、可持续迭代工程实践摘要 本文以「Agent代码库的技术债本质」为第一性原理切入点,系统性…...

OpenClaw插件开发指南:为百川2-13B-4bits定制飞书会议纪要生成器
OpenClaw插件开发指南:为百川2-13B-4bits定制飞书会议纪要生成器 1. 为什么需要定制会议纪要生成器 去年参加完一场跨部门会议后,我花了整整两小时整理会议纪要。当时就想:如果能自动提取关键信息、生成结构化摘要该多好。尝试过几个SaaS工…...
)
微信小程序物流查询插件接入全攻略:从资质申请到waybill_token获取(附完整代码)
微信小程序物流查询插件深度接入指南:全流程解析与实战代码 最近在帮一个电商客户优化小程序时,发现物流查询功能直接影响了30%的用户留存率。微信官方提供的物流查询插件确实能解决这个问题,但接入过程中遇到的坑比想象中多得多。今天就把完…...

鸿子铭:电脑上录视频后出现这个电流声得怎么处理?
大家好,我是鸿子铭。可能我们在电脑上做视频的时候可能会电流声,或者说我们在录视频之后,它也会出现这个沙沙这个声音。出现这个问题,我们该如何去解决呢?其实解决的方法有两点,在电脑上只要调试这两点的话…...

OpenClaw技能市场巡礼:Top10 SecGPT-14B相关安全自动化模块
OpenClaw技能市场巡礼:Top10 SecGPT-14B相关安全自动化模块 1. 为什么需要安全自动化模块? 去年处理服务器日志时,我发现自己每天要重复执行相同的命令:grep筛选关键错误、awk提取时间戳、手动比对不同节点的告警时间差。这种重…...

OpenClaw沙盒方案:千问3.5-35B-A3B-FP8云端测试环境搭建
OpenClaw沙盒方案:千问3.5-35B-A3B-FP8云端测试环境搭建 1. 为什么需要沙盒测试环境 上周我在尝试将OpenClaw接入本地部署的千问模型时,遇到了一个典型问题:模型推理占用了大量显存,导致我的开发机几乎无法进行其他操作。更糟的…...

SAP BP创建供应商主数据保姆级教程:从分组Z005到统驭科目2241039801的完整配置流程
SAP BP供应商主数据创建实战指南:从分组配置到统驭科目设置的深度解析 在SAP系统中,供应商主数据的准确创建是财务和采购业务流程的基石。不同于传统的供应商创建方式,BP(Business Partner)事务码提供了一种更为统一和…...

单片机老鸟的汇编优化:给那个255上限的脉冲计数器升个级
单片机老鸟的汇编优化:给那个255上限的脉冲计数器升个级 在嵌入式开发领域,脉冲计数是一个经典而实用的功能模块。许多开发者都曾用51单片机实现过基础版本——通过T1计数器接收脉冲信号,将计数值显示在数码管上。但当我们翻看这些"教科…...